大数据-玩转数据-Flink状态编程(上)
一、Flink状态编程
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。
SparkStreaming在状态管理这块做的不好, 很多时候需要借助于外部存储(例如Redis)来手动管理状态, 增加了编程的难度。
Flink的状态管理是它的优势之一。
二、什么是状态
在流式计算中有些操作一次处理一个独立的事件(比如解析一个事件), 有些操作却需要记住多个事件的信息(比如窗口操作)。
流式计算分为无状态计算和有状态计算两种情况。
无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收水位数据,并在水位超过指定高度时发出警告。
在简单聚合、窗口聚合、处理函数的应用,都会有状态的身影出现。在Flink这样的分布式系统中,我们不仅需要定义出状态在任务并行时的处理方式,还需要考虑如何持久化保存、以便发生故障时能正确地恢复,这就需要一套完整的管理机制来处理所有状态。
三、为什么需要管理状态
下面的几个场景都需要使用流处理的状态功能:
去重: 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
检测: 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
聚合: 对一个时间窗口内的数据进行聚合分析,分析一个小时内水位的情况
更新机器学习模型: 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
四、Flink中的状态分类
Managed State
状态管理方式 Flink Runtime托管, 自动存储, 自动恢复, 自动伸缩
状态数据结构 Flink提供多种常用数据结构, 例如:ListState, MapState等
使用场景 绝大数Flink算子。
Raw State
状态管理方式 用户自己管理
状态数据结构 字节数组: byte[]
使用场景 所有算子
从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State一般是在已有算子和Managed State不够用时,用户自定义算子时使用。
在我们平时的使用中Managed State已经足够我们使用。

对Managed State继续细分,它又有2种类型
Operator State(算子状态)
Keyed State(键控状态)
Operator State
适用用算子类型: 可用于所有算子: 常用于source, sink,
例如:FlinkKafkaConsumer
状态分配:一个算子的子任务对应一个状态
创建和访问方式: 实现CheckpointedFunction或ListCheckpointed(已经过时)接口
横向扩展 :并发改变时有多重重写分配方式可选: 均匀分配和合并后每个得到全量
支持的数据结构: ListState,UnionListStste和BroadCastState
Keyed State
适用用算子类型: 只能用于用于KeyedStream上的算子
状态分配 :一个Key对应一个State: 一个算子会处理多个Key, 则访问相应的多个State
创建和访问方式:重写RichFunction, 通过里面的RuntimeContext访问w
横向扩展 :并发改变, State随着Key在实例间迁移
支持的数据结构:ValueState, ListState,MapState ReduceState, AggregatingState
五、算子状态的使用
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
注意: 算子子任务之间的状态不能互相访问
Operator State的实际应用场景不如Keyed State多,它经常被用在Source或Sink等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证Flink应用的Exactly-Once语义。
Flink为算子状态提供三种基本数据结构:
列表状态(List state),将状态表示为一组数据的列表
联合列表状态(Union list state),也是将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。一种是均匀分配(List state),另外一种是将所有 State 合并为全量 State 再分发给每个实例(Union list state)。
广播状态(Broadcast state)
是一种特殊的算子状态. 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
三种状态的实现

六、键控状态的使用
键控状态是根据输入数据流中定义的键(key)来维护和访问的,只能用于KeyedStream(keyBy算子处理之后)。相同key的所有数据都会访问相同的状态。
键控状态支持的数据类型

注意:
a)所有的类型都有clear(), 清空当前key的状态
b)这些状态对象仅用于用户与状态进行交互.
c)状态不是必须存储到内存, 也可以存储在磁盘或者任意其他地方
d)从状态获取的值与输入元素的key相关
七、状态后端
状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端。
状态后端主要负责两件事:
本地(taskmanager)的状态管理
将检查点(checkpoint)状态写入远程存储
状态后端的分类及配置
状态后端作为一个可插入的组件, 没有固定的配置, 我们可以根据需要选择一个合适的状态后端。
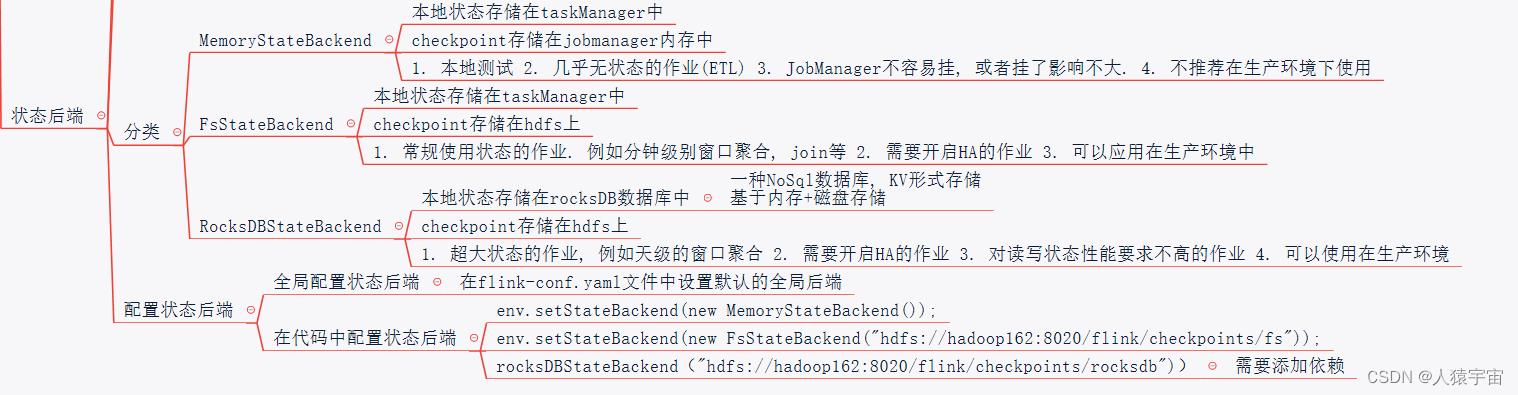
MemoryStateBackend
内存级别的状态后端(默认),
存储方式:本地状态存储在TaskManager的内存中, checkpoint 存储在JobManager的内存中.
特点:快速, 低延迟, 但不稳定
使用场景: 1. 本地测试 2. 几乎无状态的作业(ETL) 3. JobManager不容易挂, 或者挂了影响不大. 4. 不推荐在生产环境下使用
FsStateBackend
存储方式: 本地状态在TaskManager内存, Checkpoint时, 存储在文件系统(hdfs)中
特点: 拥有内存级别的本地访问速度, 和更好的容错保证
使用场景: 1. 常规使用状态的作业. 例如分钟级别窗口聚合, join等 2. 需要开启HA的作业 3. 可以应用在生产环境中
RocksDBStateBackend
将所有的状态序列化之后, 存入本地的RocksDB数据库中.(一种NoSql数据库, KV形式存储)
存储方式: 1. 本地状态存储在TaskManager的RocksDB数据库中(实际是内存+磁盘) 2. Checkpoint在外部文件系统(hdfs)中.
使用场景: 1. 超大状态的作业, 例如天级的窗口聚合 2. 需要开启HA的作业 3. 对读写状态性能要求不高的作业 4. 可以使用在生产环境
八、案例列表状态
package com.lyh.flink09;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.List;public class state_programe1_s {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);env.socketTextStream("hadoop100",9999).map(new MyMapFunctin()).print();env.execute();}public static class MyMapFunctin implements MapFunction<String,Long>, CheckpointedFunction {private Long count = 0L;private ListState<Long> state;@Overridepublic Long map(String value) throws Exception {count++;return count;}// 初始化时会调用这个方法,向本地状态中填充数据. 每个子任务调用一次@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("initialize.....");state = context.getOperatorStateStore().getListState(new ListStateDescriptor<Long>("state",Long.class));for (Long c : state.get()) {count += c;}}// Checkpoint时会调用这个方法,我们要实现具体的snapshot逻辑,比如将哪些本地状态持久化@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {System.out.println("snapshot.....");state.clear();state.add(count);}}
}
九、案例广播状态
package com.lyh.flink09;import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;public class state_broad1_s {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(3);DataStreamSource<String> dataStream = env.socketTextStream("hadoop100", 9999);DataStreamSource<String> controlStream = env.socketTextStream("hadoop100", 8888);MapStateDescriptor<String, String> stateDescriptor = new MapStateDescriptor<>("state", String.class, String.class);// 广播流BroadcastStream<String> broadcastStream = controlStream.broadcast(stateDescriptor);dataStream.connect(broadcastStream).process(new BroadcastProcessFunction<String, String, String>() {@Overridepublic void processElement(String value, ReadOnlyContext ctx, Collector<String> out) throws Exception {// 从广播状态中取值, 不同的值做不同的业务ReadOnlyBroadcastState<String, String> state = ctx.getBroadcastState(stateDescriptor);if ("1".equals(state.get("switch"))) {out.collect("切换到1号配置....");} else if ("0".equals(state.get("switch"))) {out.collect("切换到0号配置....");} else {out.collect("切换到其他配置....");}}@Overridepublic void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception {BroadcastState<String, String> state = ctx.getBroadcastState(stateDescriptor);// 把值放入广播状态state.put("switch", value);}}).print();env.execute();}}
相关文章:
大数据-玩转数据-Flink状态编程(上)
一、Flink状态编程 有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。 SparkStreaming在状态管理这块做的不好, 很多时候需要借助于外部存储(例如Redis)来手动管理状态, 增加了编…...
主动获取用户的ColaKey接口
主动获取用户的ColaKey接口 一、主动获取用户的ColaKey接口二、使用步骤1、接口***重要提示:建议使用https协议,当https协议无法使用时再尝试使用http协议***2、请求参数 三、 请求案例和demo1、请求参数例子(POST请求,参数json格式)2、响应返…...
C#写一个UDP程序判断延迟并运行在Centos上
服务端 using System.Net.Sockets; using System.Net;int serverPort 50001; Socket server; EndPoint client new IPEndPoint(IPAddress.Any, 0);//用来保存发送方的ip和端口号CreateSocket();void CreateSocket() {server new Socket(AddressFamily.InterNetwork, SocketT…...
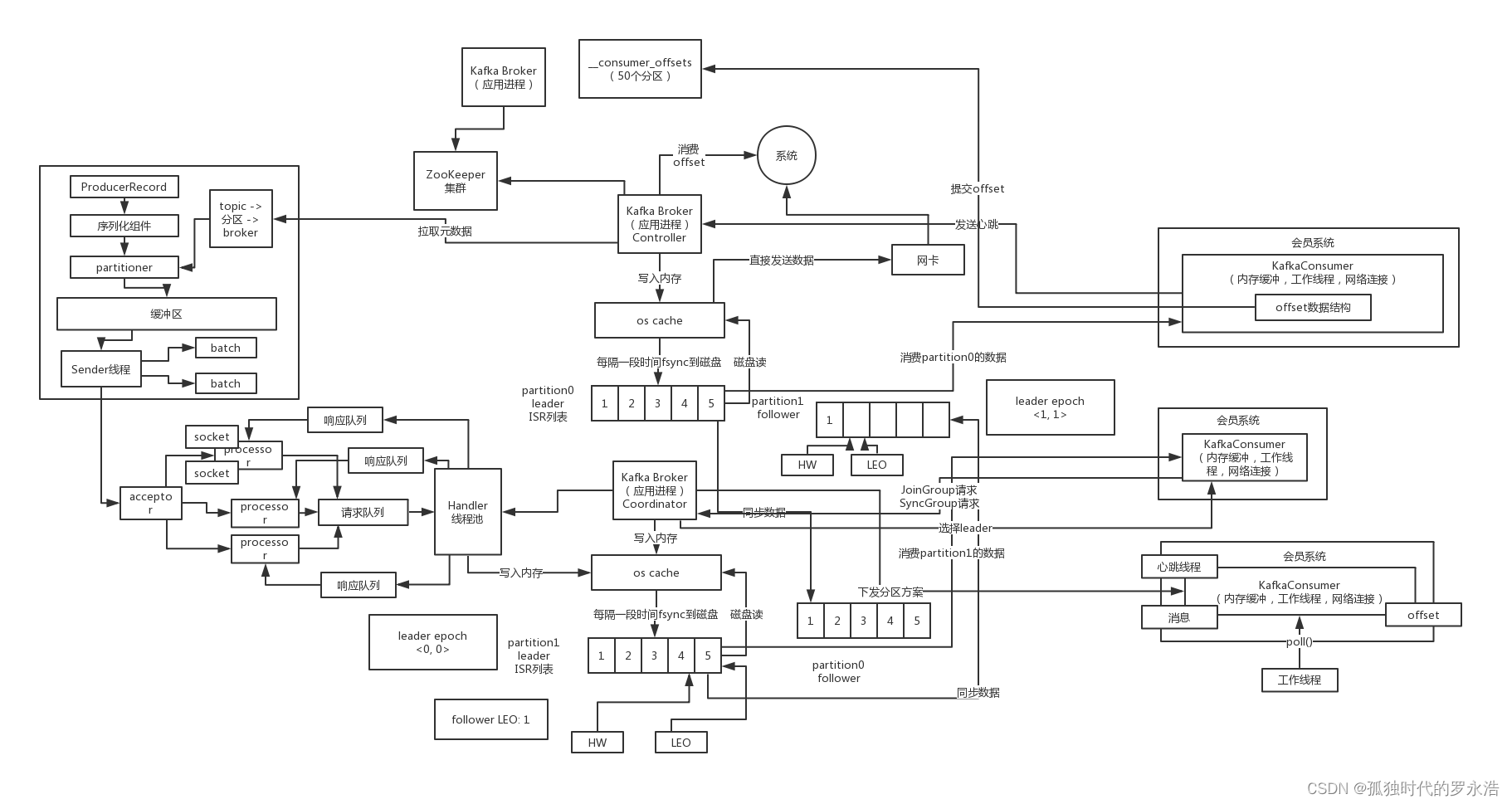
Kafka核心原理第二弹——更新中
架构原理 一、高吞吐机制:Batch打包、缓冲区、acks 1. Kafka Producer怎么把消息发送给Broker集群的? 需要指定把消息发送到哪个topic去 首先需要选择一个topic的分区,默认是轮询来负载均衡,但是如果指定了一个分区key&#x…...

巨人互动|游戏出海H5游戏出海规模如何?
H5游戏出海是指将H5游戏推广和运营扩展到国外市场的行为,它的规模受到多个因素的影响。本文小编讲一些关于H5游戏出海规模的详细介绍。 1、市场规模 H5游戏出海的规模首先取决于目标市场的规模。不同国家和地区的游戏市场规模差异很大,有些市场庞大而成…...

【爬虫】实验项目三:验证码处理与识别
目录 一、实验目的 二、实验预习提示 三、实验内容 实验要求 基本要求: 改进要求A: 改进要求B: 四、实验过程 基本要求 五、源码如下 六、资料 一、实验目的 部分网站可能会使用验证机制来阻止用户无效登录或者是验证用户不是用程…...
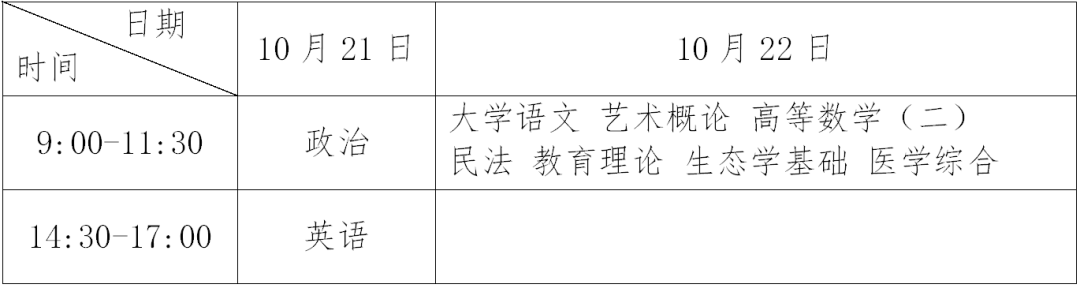
广东成人高考报名将于9月14日开始!
截图来自广东省教育考试院官网* 今年的广东成人高考正式报名时间终于确定了! 报名时间:2023年 9 月14—20日 准考证打印时间:考前一周左右 考试时间:2023年10月21—22日 录取时间:2023年12 月中上旬 报名条件: …...

pytorch中文文档学习笔记
先贴上链接 torch - PyTorch中文文档 首先我们需要安装拥有pytorch的环境 conda指令 虚拟环境的一些指令 查看所有虚拟环境 conda info -e 创建新的虚拟环境 conda create -n env_name python3.6 删除已有环境 conda env remove -n env_name 激活某个虚拟环境 activate env…...

element-ui全局导入与按需引入
全局引入 npm i element-ui -S 安装好depencencies里面可以看到安装的element-ui版本 然后 在 main.js 中写入以下内容: import Vue from vue; import ElementUI from element-ui; import element-ui/lib/theme-chalk/index.css; import App from ./App.vue;Vue.…...

go 地址 生成唯一索引v2 --chatGPT
问:golang 函数 getIndex(n,addr,Hlen,Tlen) 返回index。参数n为index的上限,addr为包含大小写字母数字的字符串,Hlen为截取addr头部的长度,Tlen为截取addr尾部的长度 gpt: 你可以编写一个函数来计算根据给定的参数 n、addr、Hlen 和 Tlen …...

JSON XML
JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)是两种常用的数据交换格式,用于在不同系统之间传输和存储数据。 JSON是一种轻量级的数据交换格式,它使用易于理解的键值对的形式表示数…...

2023年MySQL实战核心技术第四篇
七 . 吃透索引:...
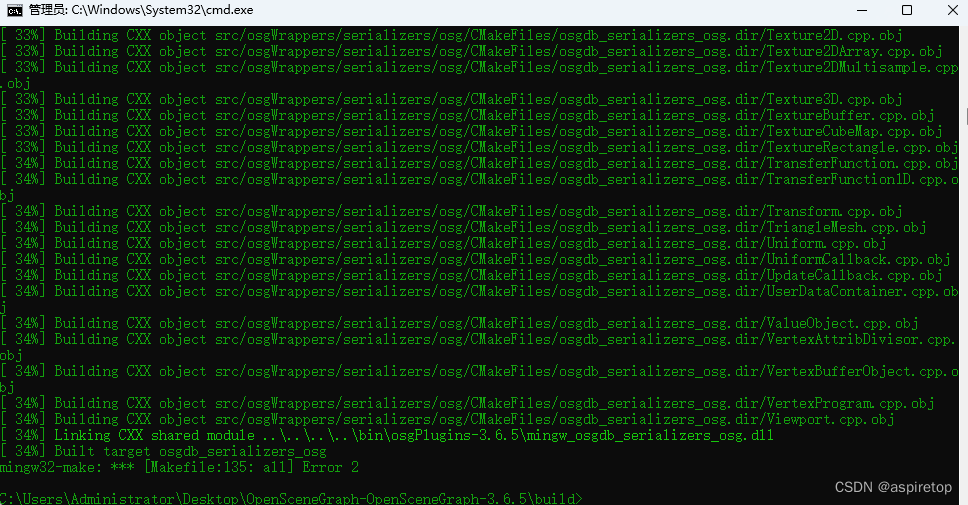
cmake编译(qtcreator)mingw下使用的osg3.6.5
官网下载osg3.6.5源码,先不使用依赖库,直接进行编译 如果generate后报错,显示找不到boost必须库,则手动增加路径。然后先在命令行中使用mingw32-make,如果显示不存在,则需要去环境变量里配置一下这个工具的…...

Python钢筋混凝土结构计算.pdf-混凝土强度设计值
计算原理: 需要注意的是,根据不同的规范和设计要求,上述公式可能会有所差异。因此,在进行混凝土强度设计值的计算时,请参考相应的规范和设计手册,以确保计算结果的准确性和合规性。 代码实现: …...
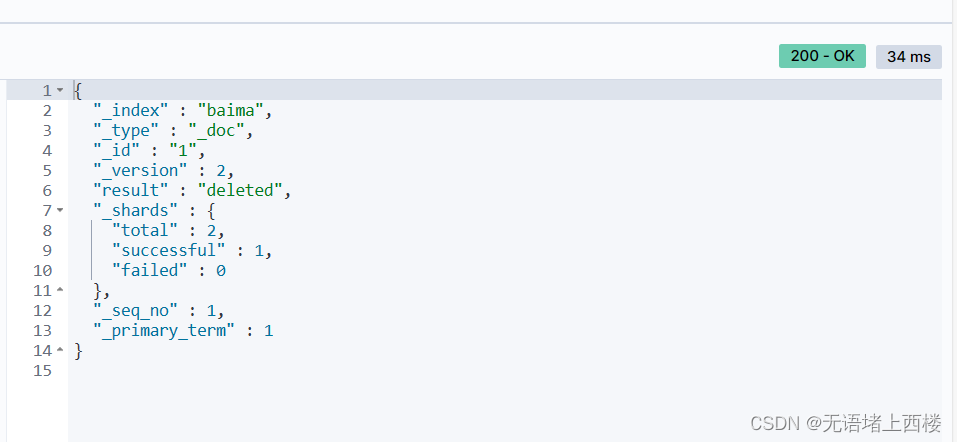
elasticsearch的索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。我们要向es中存储数据,必须先创建“库”和“表”。 mapping映射属性 mapping是对索引库中文档的约束,常见的mapping属性包括: type:字段数据类型,常见的…...

把握市场潮流,溯源一流品质:在抖in新风潮 国货品牌驶过万重山
好原料、好设计、好品质、好服务……这个2023,“国货”二字再度成为服饰行业的发展关键词。以消费热潮为翼,越来越多代表性品类、头部品牌展现出独特价值,迎风而上,在抖音电商掀起一轮轮生意风潮。 一个设问是:在抖音…...

【网络教程】Python如何优雅的分割URL
文章目录 URL分割方法是一种用于解析URL字符串的方法,它可以将URL分解成不同的组成部分,如协议、域名、端口、路径等。在Python中,我们可以使用urllib.parse模块中的urlsplit方法来实现URL分割。 使用方法 下面是一个简单的示例代码,演示了如何使用urlsplit方法解析URL字符…...
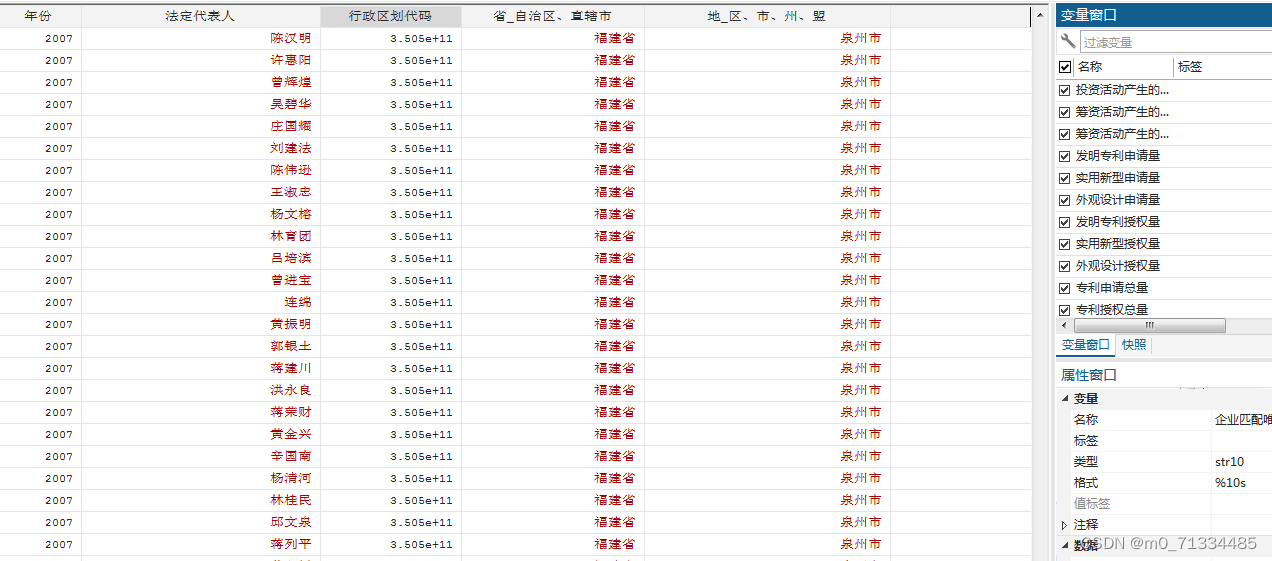
1998-2014年工业企业数据库和绿色专利匹配
1998-2014年工业企业数据库绿色专利匹配 1、时间:1998-2014年 2、样本量:470万 3、来源:工业企业数据库、国家知识产权局、WIPO 4、指标: 企业匹配唯一标识码、组织机构代码、企业名称、年份、法定代表人、法定代表人职务、行…...
Python基于Mirai开发的QQ机器人保姆式教程(亲测可用)
在本教程中,我们将使用Python和Mirai来开发一个QQ机器人,本文提供了三个教学视频,包教包会,本文也很贴心贴了代码和相关文件。话不多说,直接开始教学。 目录 一、安装配置MIrai 图片验证码报错: 二、机器…...
算法笔记:堆
【如无特别说明,皆为最小二叉堆】 1 介绍 2 特性 结构性:符合完全二叉树的结构有序性:满足父节点小于子节点(最小化堆)或父节点大于子节点(最大化堆) 3 二叉堆的存储 顺序存储 二叉堆的有序…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...