tcp字节传输(java)-自定义包头和数据识别
1、背景
tcp传输的时候会自动拆包,因此服务端接收的数据段可能跟客户端发送过来的数据段长度不一致,比如客户端一次发送10000个字节。但是服务端接收了两次才接收完整(例如第一次接收6000字节,第二次接收4000字节)。但是服务端每次必须要接收完所有的字节才能进行处理,而且客户端每次发的数据长度都不一致。
于是经过协商,客户端每次发送数据段时,在数据段前加10个字节(后面统一称数据包头),前6个字节为数据包起始标识符,后4个字节为此次发送数据段的长度。
2、难点
因为tcp会拆包,所以数据段前的10个字节可能会出现在任何位置,也可能会出现在两次tcp传输过程中。另外如果包头前6个字节不是指定的标识,要向后顺延,直到找出包头。
3、思路
1)使用两个ByteBuffer对象,一个记录数据段前的10个字节,该对象仅创建一次。另一个ByteBuffer对象存储去除包头后的完整的数据段信息,该对象在每次接收新的包头时,都会根据包头的后4个字节重新创建(因为jvm的自动垃圾回收,所以这里不用担心内存溢出问题)。
2)接收完整的数据段后,如果还有多余数据则使用迭代方式处理。
4、java代码实现
1、这里只列出了核心代码,相关逻辑需要自己补全2、创建tcp服务端代码
try (ServerSocket ss = new ServerSocket(port)) {while (true) {Socket socket = ss.accept();new SocketHandler(socket, eqpmtId, port, save).start();}
} catch (Exception e) {log.error("TCP服务端创建异常,端口为{},异常为\n", this.port, e);
}3、tcp服务端详细处理代码
@Slf4j
class SocketHandler extends Thread {private Socket socket;private String eqpmtId;private Integer port;private boolean save;public SocketHandler(Socket socket, String eqpmtId, Integer port, boolean save) {this.socket = socket;this.eqpmtId = eqpmtId;this.port = port;this.save = save;}@Overridepublic void run() {log.info("与{},{}建立消息socket通信", eqpmtId, port);try (InputStream inputStream = socket.getInputStream();FileOutputStream os = new FileOutputStream(new File("D:\\tmp-data\\" + System.currentTimeMillis() + ".h264"));) {byte[] buffer = new byte[64 * 1024];int len = 0;ByteBuffer dataBuffer = null;ByteBuffer headBuffer = ByteBuffer.allocate(10);while (socket.isConnected() && !socket.isClosed()) {if ((len = inputStream.read(buffer)) != -1) {log.info("收到数据包len={}", len);try {dataBuffer = getDataBuffer(buffer, 0, len, headBuffer, dataBuffer);} catch (Exception e) {log.error("接收数据异常,重新开始接收...\n",e);headBuffer.clear();dataBuffer.clear();}} else {log.info("没有数据,休眠1秒,否则cpu会飙升");Thread.sleep(1000);}}} catch (Exception e) {log.error("socket传输异常,异常为\n", this.port, e);}log.info("关闭与},{}消息socket通信", eqpmtId, port);}private ByteBuffer getDataBuffer(byte[] buffer, int start, int end, ByteBuffer headBuffer, ByteBuffer dataBuffer) {int offset = start;int tmpLen = 0;//先找到包头if (headBuffer.position() < headBuffer.capacity()) {//当前数组长小于包头长度有,整个数组放入头缓存后返回int len = end - offset;if (len < headBuffer.capacity() - headBuffer.position()) {headBuffer.put(buffer, offset, len);return dataBuffer;}tmpLen = headBuffer.capacity() - headBuffer.position();headBuffer.put(buffer, offset, headBuffer.capacity() - headBuffer.position());offset = offset + tmpLen;//包头缓存填充满了,判断包头是否正确if (!isHead(headBuffer.array())) {//包头不正确,则不断向后移位直到找到包头log.info("包头有问题,向后移动一位继续校验");int headLastIndex = headBuffer.capacity() - 1;for (; offset < end; offset++) {for (int i = 0; i < headLastIndex; i++) headBuffer.put(i, headBuffer.get(i + 1));headBuffer.put(headLastIndex, buffer[offset]);if (isHead(headBuffer.array())) break;}//移位结束确认是找到了包头还是当前数组已经遍历完if (!isHead(headBuffer.array())) {headBuffer.position(headLastIndex);return dataBuffer;}}//包头正确后,解析获取数据包有多长,并创建对应的缓存对象int dataLen = dataLen(headBuffer.array());log.info("包头设定长度为{}", dataLen);dataBuffer = ByteBuffer.allocate(dataLen);}if (offset == end) return dataBuffer;//如果可以填充满数据缓存对象,则发送数据包,并清理缓存if (end - offset >= dataBuffer.capacity() - dataBuffer.position()) {tmpLen = dataBuffer.capacity() - dataBuffer.position();dataBuffer.put(buffer, offset, dataBuffer.capacity() - dataBuffer.position());offset = offset + tmpLen;/** 收到完整数据包,进行处理,注意这里的函数要替换成自己的处理逻辑 **/sendData(dataBuffer, null);dataBuffer.clear();headBuffer.clear();if (offset == end) return dataBuffer;//迭代处理剩下的数据return getDataBuffer(buffer, offset, end, headBuffer, dataBuffer);}//如果不能填充慢数据缓存对象,则整个数据放入后返回dataBuffer.put(buffer, offset, end - offset);return dataBuffer;}//判断是否为包头public boolean isHead(byte[] buffer) {if (buffer == null || buffer.length < 10) return false;int b1 = buffer[0];int b2 = buffer[1];int b3 = buffer[2];int b4 = buffer[3];int b5 = buffer[4];int b6 = buffer[5];String s = "" + b1 + b2 + b3 + b4 + b5 + b6;if ("001001".equals(s)) return true;return false;}//判断数据包的长度(ByteUtil用的hutool工具包里的类,也可以自己实现)public int dataLen(byte[] buffer) {return ByteUtil.bytesToInt(new byte[]{buffer[6], buffer[7], buffer[8], buffer[9]});}}相关文章:
-自定义包头和数据识别)
tcp字节传输(java)-自定义包头和数据识别
1、背景 tcp传输的时候会自动拆包,因此服务端接收的数据段可能跟客户端发送过来的数据段长度不一致,比如客户端一次发送10000个字节。但是服务端接收了两次才接收完整(例如第一次接收6000字节,第二次接收4000字节)。但…...

pyspark 系统找不到指定的路径; \Java\jdk1.8.0_172\bin\java
使用用具PyCharm 2023.2.1 1:pyspark 系统找不到指定的路径, Java not found and JAVA_HOME environment variable is not set. Install Java and set JAVA_HOME to point to the Java installation directory. 解决方法:配置正确环境变量…...

UE4 Physics Constraint Actor 实现钟摆效果
放入场景,然后将一个球体放入场景 选择小球 将小球改为Movable 选择模拟物理,并将小球移除平衡点 就实现了...

UE4/UE5 动画控制
工程下载 https://mbd.pub/o/bread/ZJ2cm5pu 蓝图控制sequence播放/倒播动画: 设置开启鼠标指针,开启鼠标事件 在场景中进行过场动画制作 设置控制事件...

Springboot整合shiro
导入依赖 <!-- 引入springboot的web项目的依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency> <!-- shiro --><depende…...

阻塞/非阻塞、同步/异步(网络IO)
1.阻塞/非阻塞、同步/异步(网络IO) 【思考】典型的一次 IO 的两个阶段是什么? 数据就绪 和 数据读写 数据就绪 :根据系统 IO 操作的就绪状态 阻塞 非阻塞 数据读写 :根据应用程序和内核的交互方式 同步 异步 陈硕:在处理 IO …...

为什么大家会觉得考PMP没用?
一是在于PMP这套知识体系,是一套底层的项目管理逻辑框架,整体是比较抽象的。大家在学习工作之后,会有人告诉你很多职场的一些做事的规则,比如说对于沟通,有人就会告诉如何跟客户沟通跟同事相处等等,这其实就…...

AVR128单片机 USART通信控制发光二极管显示
一、系统方案 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 void port_init(void) { PORTA 0xFF; DDRA 0x00;//输入 PORTB 0xFF;//低电平 DDRB 0x00;//输入 PORTC 0xFF;//低电平 DDRC 0xFF;//输出 PORTE 0xFF; DDRE 0xfE;//输出 PO…...

为什么5G 要分离 CU 和DU?(4G分离RRU 和BBU)
在 Blog 一文中,5G--BBU RRU 如何演化到 CU DU?_5g rru_qq_38480311的博客-CSDN博客 解释了4G的RRU BBU 以及 5G CU DU AAU,主要是讲了它们分别是什么。但是没有讲清楚 为什么,此篇主要回答why。 4G 为什么分离基站为 RRU 和 BBU…...

Python中的数据输入
获取键盘输入 input语句 使用input()可以从键盘获取输入,使用一个变量来接收 print("你是谁?") name input() print(f"我知道了,你是{name}")# print("你是谁?") name input("你是谁&…...

cms系统稳定性压力测试出现TPS抖动和毛刺的性能bug【杭州多测师_王sir】
一、并发线程数100,分10个阶梯,60秒加载时间,运行1小时进行压测,到10分钟就出现如下 二、通过jstat -gcutil 16689 1000进行监控...

【UE】材质描边、外发光、轮廓线
原教学视频链接: ue4 材质描边、外发光、轮廓线_哔哩哔哩_bilibili 步骤 1. 首先新建一个材质,这里命名为“Mat_outLine” 在此基础上创建一个材质实例 2. 在视口中添加一个后期处理体积 设置后期处理体积为无限范围 点击添加一个数组 选择“资产引用”…...

百模大战,打响AI应用生态的新赛点
点击关注 文|郝鑫 黄小艺,编|刘雨琦 “宇宙中心”五道口,又泛起了昔日的光芒。 十字路口一角的华清嘉园里,各种互联网大佬们,王兴、程一笑、张一鸣等人的创业传说似乎还有余音,后脚搬进来的AI…...
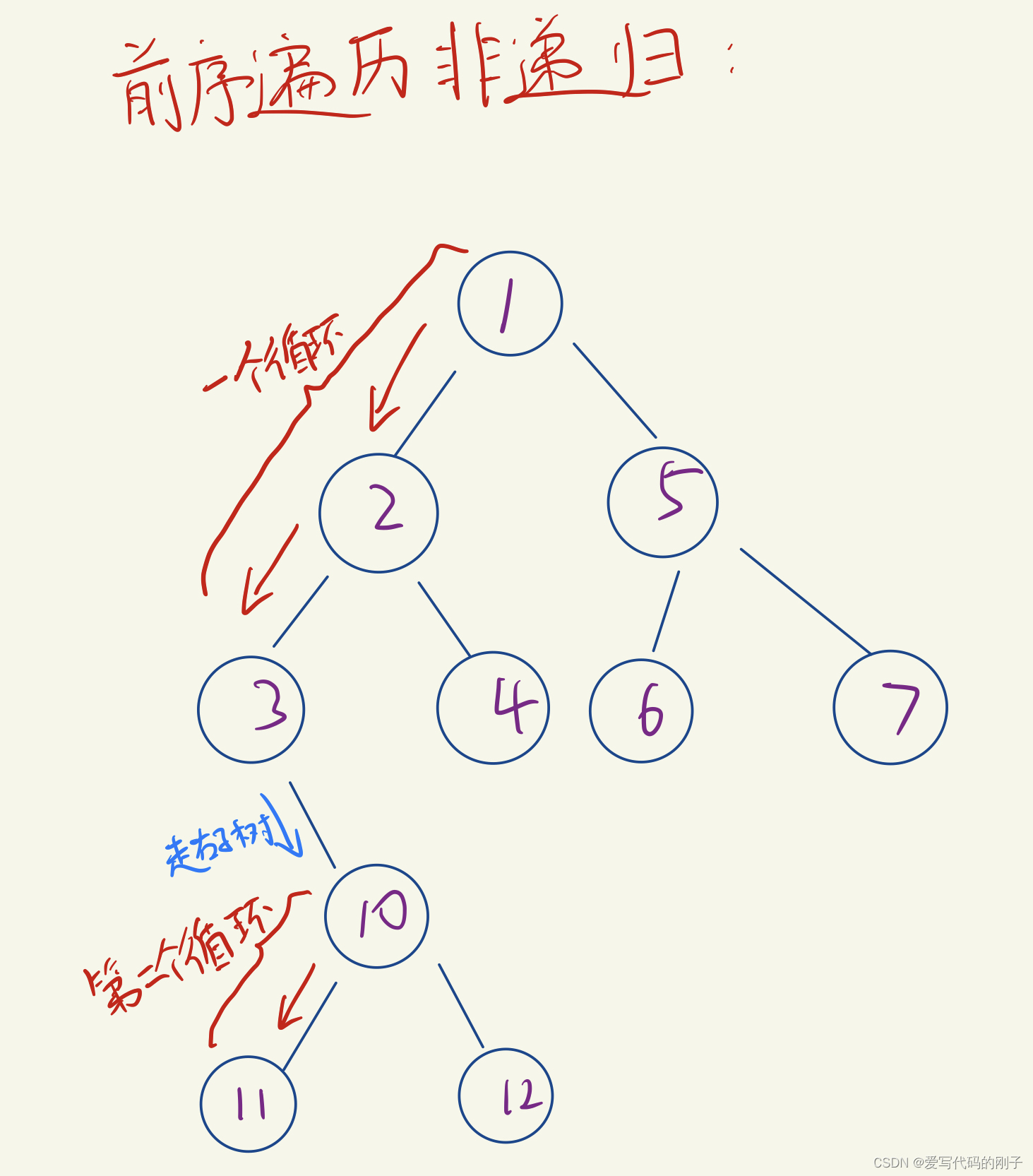
【C++二叉树】进阶OJ题
【C二叉树】进阶OJ题 目录 【C二叉树】进阶OJ题1.二叉树的层序遍历II示例代码解题思路 2.二叉搜索树与双向链表示例代码解题思路 3.从前序与中序遍历序列构造二叉树示例代码解题思路 4.从中序与后序遍历序列构造二叉树示例代码解题思路 5.二叉树的前序遍历(非递归迭…...

C++——vector:resize与reserve的区别,验证写入4GB大数据时相比原生操作的效率提升
resize和reserve的区别 reserve:预留空间,但不实例化元素对象。所以在没有添加新的对象之前,不能引用容器内的元素。而要通过调用push_back或者insert。 resize:改变容器元素的数量,且会实例化对象(指定或…...

基础配置xml
# 配置端口 server.port8081# 文件上传配置 # 是否支持文件上传 spring.servlet.multipart.enabledtrue # 是否支持文件写入磁盘 spring.servlet.multipart.file-size-threshold0 # 上传文件的临时目录 spring.servlet.multipart.locationd:/opt/tmp # 最大支持上传文件大小 sp…...

win环境安装SuperMap iserver和配置许可
SuperMap iServer是我国北京超图公司研发的基于跨平台GIS内核的云GIS应用服务器产品,通过服务的方式,面向网络客户端提供与专业GIS桌面产品相同功能的GIS服务,能够管理、发布多源服务,包括REST服务、OGC服务等。 SuperMap iserve…...

【Apollo学习笔记】——规划模块TASK之PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZER(一)
文章目录 TASK系列解析文章前言PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZER功能介绍PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZER相关配置PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZER流程确定优化变量定义目标函数定义约束ProcessSetUpStatesAndBoundsOptimizeByQPCheckSpeedLimitF…...

pytest parametrize多参数接口请求及展示中文响应数据
编写登陆接口 app.py from flask import Flask, request, jsonify, Responseapp Flask(__name__)app.route(/login, methods[POST]) def login():username request.form.get(username)password request.form.get(password)# 在这里编写你的登录验证逻辑if username admin…...

电视连续剧 ffmpeg 批量去掉片头片尾
思路: 一、用python获取每集的总时长 二、把每集的时间,拼接成想要的ffmpeg的剪切命令命令。 1、用python获取每集的总时长 1,安装moviepy库,直接安装太慢,换成国内的源 pip install moviepy -i http://mirrors.aliyu…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...
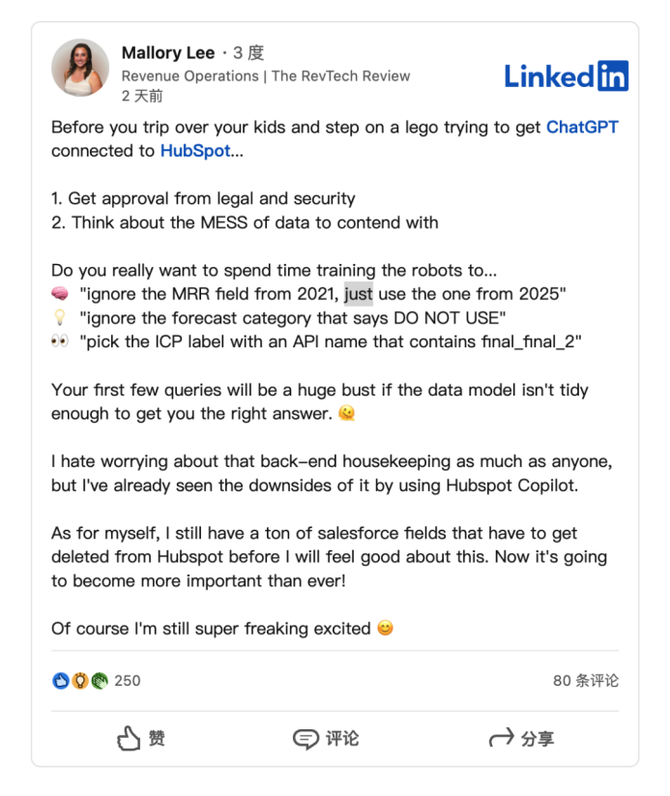
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...
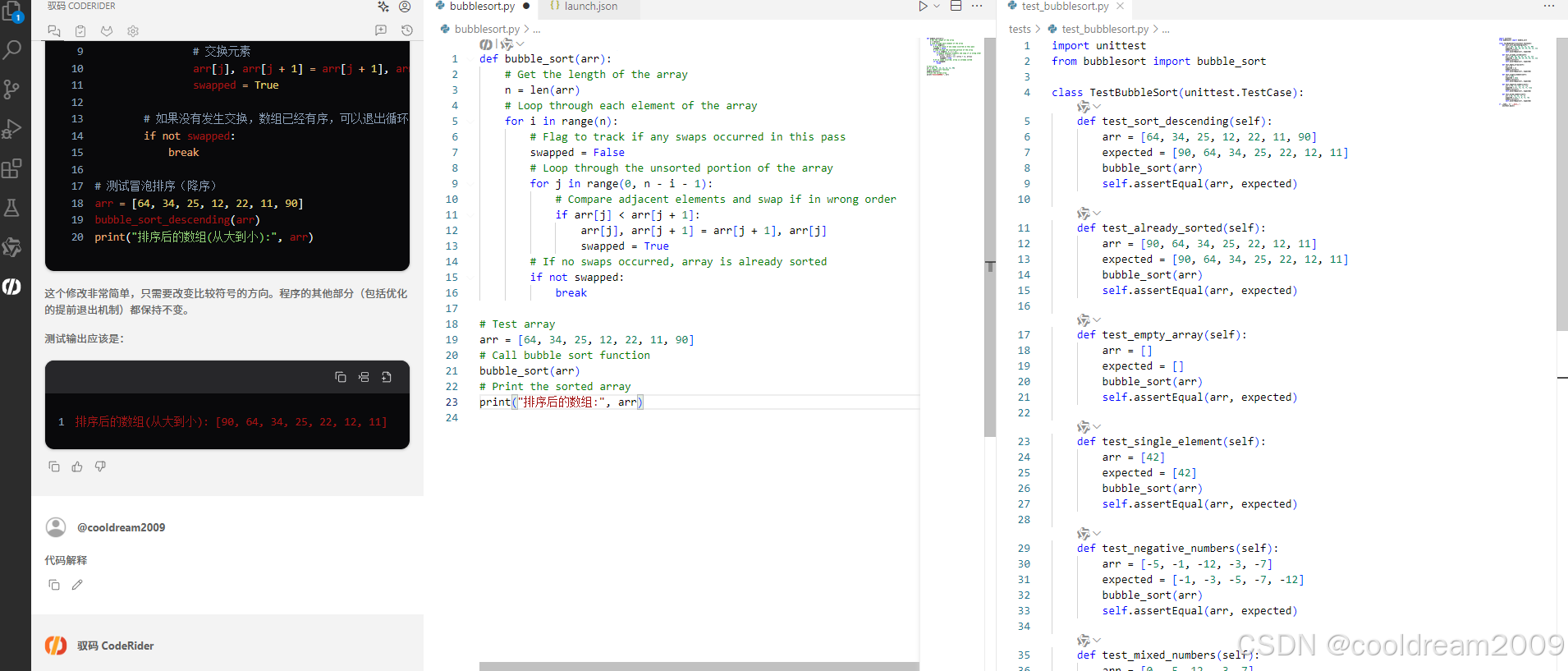
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...
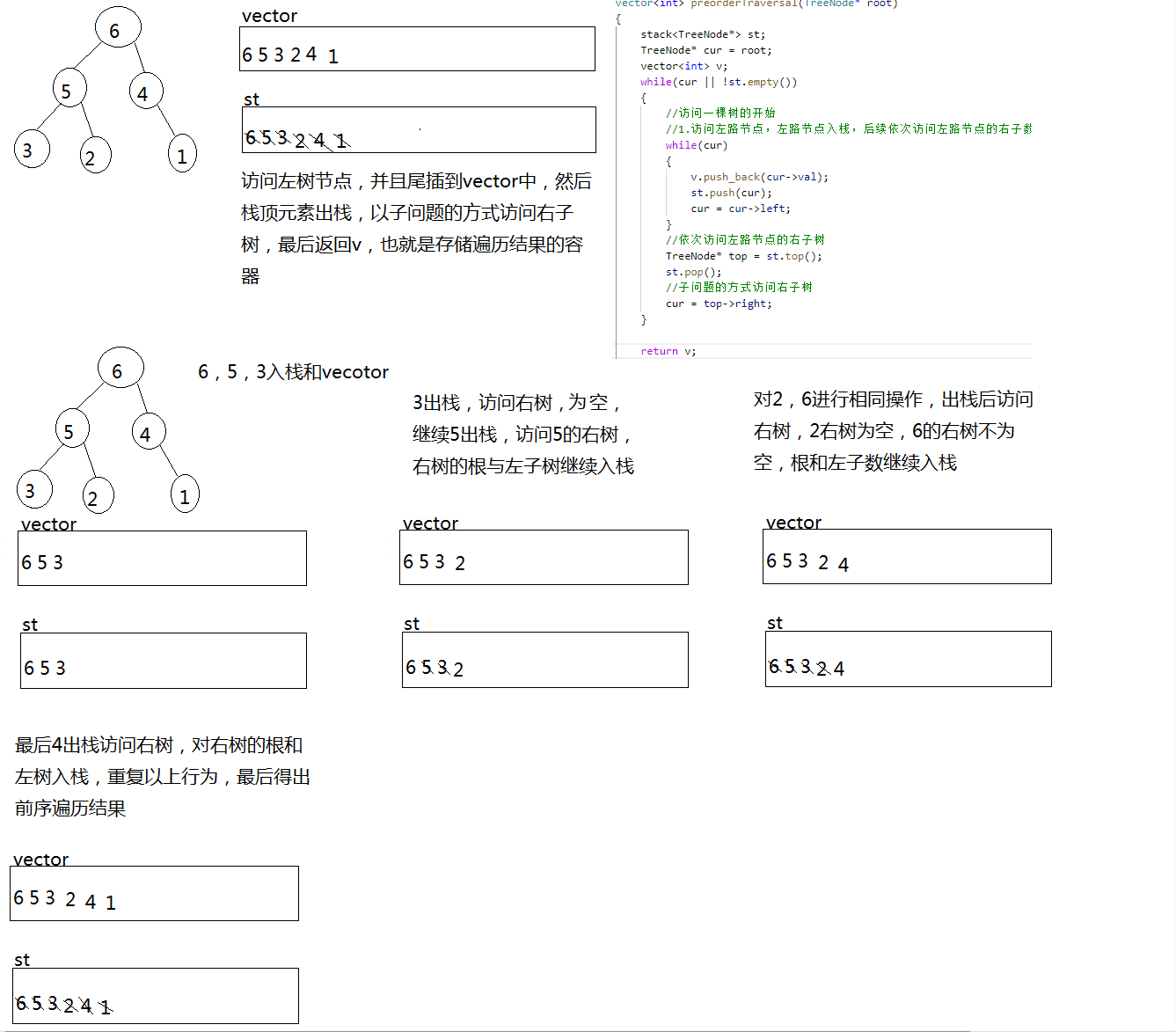
二叉树-144.二叉树的前序遍历-力扣(LeetCode)
一、题目解析 对于递归方法的前序遍历十分简单,但对于一位合格的程序猿而言,需要掌握将递归转化为非递归的能力,毕竟递归调用的时候会调用大量的栈帧,存在栈溢出风险。 二、算法原理 递归调用本质是系统建立栈帧,而非…...

比较数据迁移后MySQL数据库和ClickHouse数据仓库中的表
设计一个MySQL数据库和Clickhouse数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...