基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统
目录
1、EFK简介
2、EFK框架
2.1、Fluentd系统架构
2.2、Elasticsearch系统架构
2.3、Kibana系统架构
3、Elasticsearch接口
4、EFK在虚拟机中安装步骤
4.1、安装elasticsearch
4.2、安装kibana
4.3、安装fluentd
4.4、进入kibana创建索引
5、Fluentd配置介绍
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html Elasticsearch,Fluentd和Kibana(EFK)可以进行收集,索引,搜索和可视化日志数据。Elasticsearch负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。今天就来详细介绍一下使用Elasticsearch,Fluentd和Kibana搭建日志管理系统的详细过程。
https://blog.csdn.net/chenlycly/category_11931267.html Elasticsearch,Fluentd和Kibana(EFK)可以进行收集,索引,搜索和可视化日志数据。Elasticsearch负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。今天就来详细介绍一下使用Elasticsearch,Fluentd和Kibana搭建日志管理系统的详细过程。
1、EFK简介

Elasticsearch,Fluentd和Kibana(EFK)可以进行收集,索引,搜索和可视化日志数据。Elasticsearch负责数据的存储和索引,Fluentd负责数据的调整、过滤、传输,Kibana负责数据的展示。
fluentd实时收集日志,把日志作为JSON stream,可以同时从多台server上收集大量日志,易于安装,有灵活的插件机制和缓冲,支持日志转发。它统一实现了每一环节的数据传输,只需要关注数据处理的逻辑,也不用学习各种API,通过配置就可以实现实时增量数据的流出和流入。
Elasticsearch提供了一个分布式多用户能力的全文搜索引擎。基于RESTful web接口,且提供持久存储、统计等多项功能。可用于全文搜索、结构化搜索、分析以及将这三者混合使用,通过简单的配置就可以做数据复制和分片,并且,它在NRT(Near Real Time)方面做了一些优化,使得应用在实时性方面有很好的表现。
Kibana 是一个基于浏览器页面的 ElasticSearch 前端展示工具,内置了各种查询和聚合操作,并拥有图形化展示功能。使用它对日志进行高效地搜索、可视化、分析等各种操作。可以通过各种图表进行高级数据分析及展示。
2、EFK框架
EFK日志处理系统的流程框架如下所示:

具体的流程为:fluentd进行日志的收集,数据来源可以自己设置为容器日志或者存储在本地文件的日志文件,收集之后发送给Elasticsearch进行统一的管理、搜索等操作,最后kibana将结果展示在web界面上。
日志的处理流程可以简化为:

当考虑健壮性时,需要复杂配置,如图:
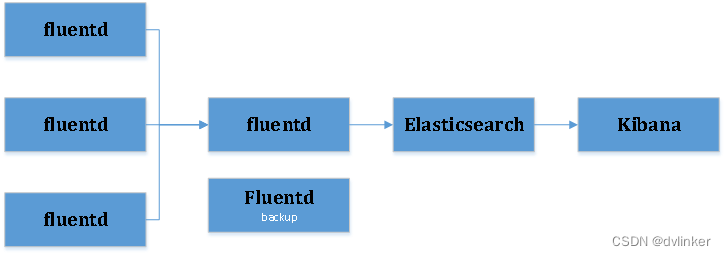
多了一层fluentd,以及备选的点,这样日志收集的过程更加稳定以及可靠。
2.1、Fluentd系统架构

fluentd系统如下图所示:
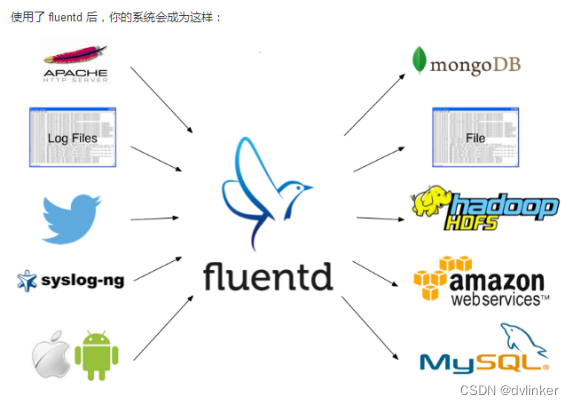
fluentd的数据流简单,从数据源获取,进行集中,然后发送到输出的地方,流程:输入input --> 处理filter(不是必须的) --> 输出output
input:读取日志内容。
output:输出,常见的有mongodb,elasticsearch,kafka等,只需安装相关的插件即可。
详细结构如下图所示:

2.2、Elasticsearch系统架构

Elasticsearch作用:fluentd将过滤后的日志内容发给全文搜索服务ElasticSearch,提供检索功能。Elasticsearch 的rest请求的传递流程如下所示:

用户发起http请求,Elasticsearch 的9200端口接受请求后,传递给对应的RestAction。RestAction做的事情很简单,将rest请求转换为RPC的TransportRequest,然后调用NodeClient,相当于用客户端的方式请求RPC服务,只不过transport层会对本节点的请求特殊处理。
2.3、Kibana系统架构

Kibana是一个强大的数据展示工具。大多数情况下,不需要开发任何代码,就可以得到一个Dashboard。使用 Kibana 来查询,浏览并且可以与存储在 Elasticsearch indices(索引)中的数据交互。需要做的是:
(1)把数据放到ES中
(2)是在Kibana页面上配置报表模版,或按照规则写一套报表模版。
kibana的工作流程如下:

3、Elasticsearch接口
多种语言都可以使用 REST API 通过端口 9200 和 Elasticsearch 进行通信,REST请求和应答是典型的JSON(JavaScript对象 符号)格式。通常情况下,一个REST请求包含一个JSON文件,其回复也是一个JSON文件。
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'。
其中被 < > 标记的部分分别为:
VERB:适当的 HTTP 方法 或 谓词 : GET`、 `POST`、 `PUT`、 `HEAD 或者 `DELETE`。
PROTOCOL:http 或者 https`(如果你在 Elasticsearch 前面有一个 `https 代理)。
HOST:Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。
PORT:运行 Elasticsearch HTTP 服务的端口号,默认是 9200。
PATH:API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm。
QUERY_STRING:任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)。
BODY:一个 JSON 格式的请求体 (如果请求需要的话)。
GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT。
在请求的查询串参数中加上 pretty 参数,这将会调用 Elasticsearch 的 pretty-print 功能,该功能 使得 JSON 响应体更加可读。但是, _source 字段不能被格式化打印出来。相反,我们得到的 _source 字段中的 JSON 串,刚好是和我们传给它的一样。例如:
curl -XGET http://localhost:9200/website/blog/123 -d ‘{...}’
一个查询语句的典型结构:
curl -XGET http://localhost:9200/search -d ‘
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
} ‘
要启用表头,添加 ?v 参数即可。
Elasticsearch集群个数:应该始终被配置为 master 候选节点的法定个数(大多数个)。法定个数就是 ( master 候选节点个数 / 2) + 1。Elasticsearch 自己会输出很多日志,都放在 ES_HOME/logs 目录下。默认的日志记录等级是 INFO。
4、EFK在虚拟机中安装步骤
4.1、安装elasticsearch
首先,安装JDK或者openJDK(这里以openJDK为例),然后安装elasticsearch,最后启动elasticsearch:
[root@elk elk]# yum install java-1.8.0-openjdk -y[root@elk elk]# wget -c https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.3/elasticsearch-2.3.3.rpm[root@elk elk]# yum localinstall elasticsearch-2.3.3.rpm –y[root@elk elk]# systemctl daemon-reload[root@elk elk]# systemctl enable elasticsearch[root@elk elk]# systemctl start elasticsearch修改防火墙,开放9200和9300端口:
[root@elk elk]# firewall-cmd --permanent --add-port={9200/tcp,9300/tcp}[root@elk elk]# firewall-cmd –reload4.2、安装kibana
[root@elk elk]# wget https://download.elastic.co/kibana/kibana/kibana-4.5.1-1.x86_64.rpm[root@elk elk]# yum localinstall kibana-4.5.1-1.x86_64.rpm –y[root@elk elk]# systemctl enable kibana[root@elk elk]# systemctl start kibana修改防火墙,对外开放tcp/5601:
[root@elk elk]# firewall-cmd --permanent --add-port=5601/tcp[root@elk elk]# firewall-cmd --reload打开浏览器测试访问kibana的首页http://localhost:5601/
4.3、安装fluentd
安装前查看当前最大打开文件数:
$ ulimit -n如果查看到的是1024,那么这个数值是不足的,则需要修改配置文件提高数值
vi /etc/security/limits.conf设置值如下:
root soft nofile 65536
root hard nofile 65536
* soft nofile 65536
* hard nofile 65536
然后重启系统。
4.3.1、安装fluentd
执行如下命令(命令将会自动安装td-agent,td-agent即为fluentd):
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh | sh启动td-agent:
$ /etc/init.d/td-agent start$ /etc/init.d/td-agent status或者
$ systemctl start td-agent$ systemctl status td-agent简单demo测试HTTP logs:
curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test
安装必要的插件:
$ /usr/sbin/td-agent-gem install fluent-plugin-elasticsearch$ /usr/sbin/td-agent-gem install fluent-plugin-typecast$ /usr/sbin/td-agent-gem install fluent-plugin-secure-forward$ systemctl restart td-agent如果上面直接安装不了,则要gem插件(安装rubygems)。
4.3.2、配置td-agent
使docker生成的日志输出到elasticsearch,修改td-agent的配置
$ vi /etc/td-agent/td-agent.conf修改内容为如下(这里没有填写端口,默认使用9200端口)
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match alpine:**>
@type elasticsearch
logstash_format true
flush_interval 10s # for testing
host 127.0.0.1
</match>
重启td-agent:
$ systemctl restart td-agent启动docker镜像,这里使用alpine做测试:
docker run --log-driver=fluentd --log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}" alpine:3.3 echo "helloWorld"检查fluentd是否正常转发数据,检查td-agent日志,如果最后出现如下一行,则表明正常连接elasticsearch。/var/log/td-agent/td-agent.log中最后一行如下:
2017-12-26 00:40:37 -0500 [info]: #0 Connection opened to Elasticsearch cluster => {:host=>"127.0.0.1", :port=>9200, :scheme=>"http"}
2017-12-26 01:22:42.071896593 -0500 debug.test: {"json":"message"}
4.3.3、fluentd使用
td-agent默认将配置收集来自http的日志,并将日志转储到/var/log/td-agent/td-agent.log,如果需要配置fluent接收docker日志,则在/etc/td-agent/td-agent.conf中增加,并重启td-agent,systemctl restart td-agent
<match docker.**>
type stdout
</match>
配置docker使用fluent为log-driver,有两种方法,指定特定的容器或者配置docker daemon将所有容器日志均存储到fluent中。
方法1:指定容器
docker run --log-driver=fluentd --log-opt fluentd-address=myhost.local:24224
方法2: 设置全局log-driver
docker daemon --log-driver=fluentd
至此,已经成功将docker的日志交给fluent处理。
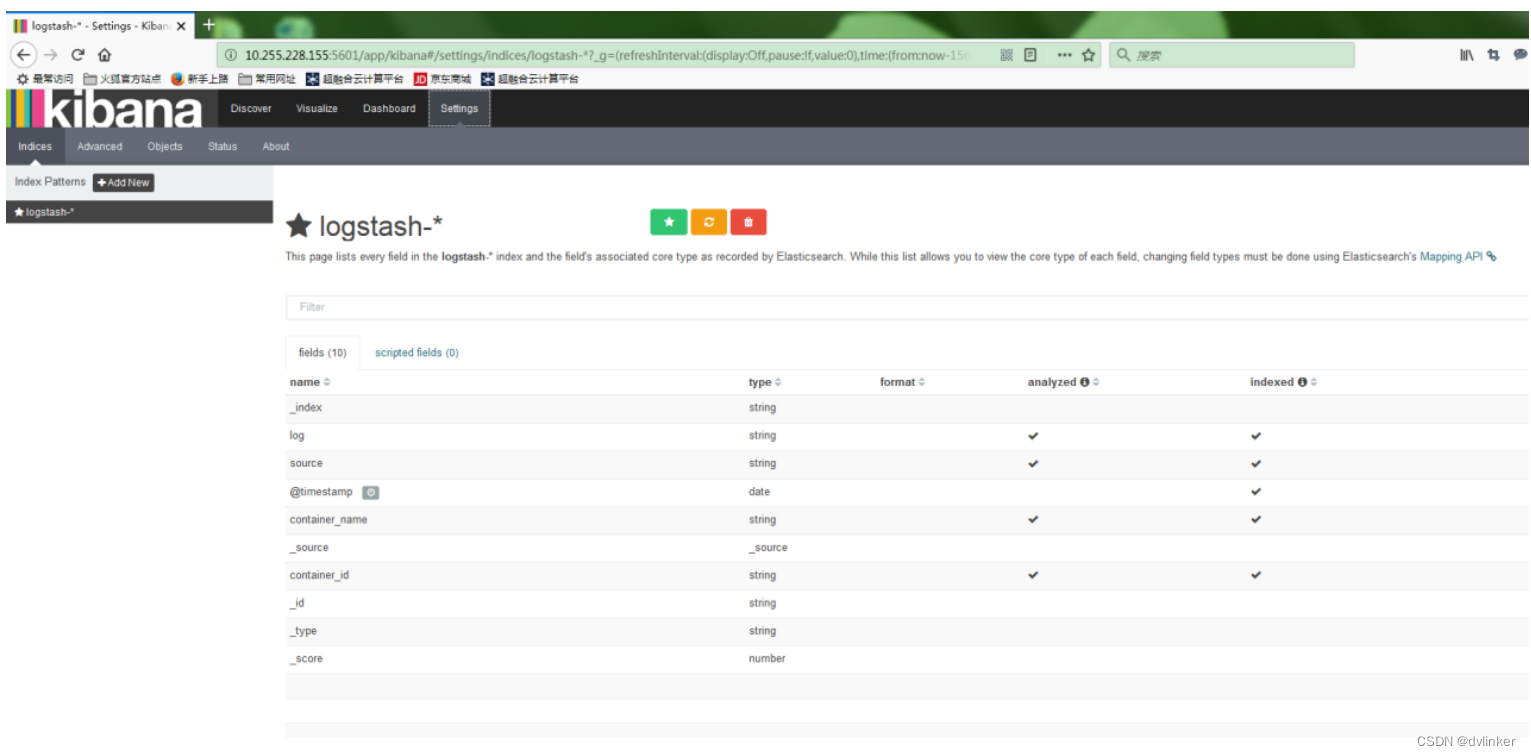
4.4、进入kibana创建索引
访问页面:http://localhost:5601/
点击“create”,即可看到如下设置:
5、Fluentd配置介绍
配置文件为vi /etc/td-agent/td-agent.conf,配置文件主要由以下指令组成:
1)source 决定输入源.
2)match 决定输出目的地.
3)filter 决定事件处理管道.
4)system 设置系统广泛的配置.
5)label 输出分组和筛选内部路由
6)@include 包括其他文件.
source: 输入源包括http和forward,http将fluentd转换为http端点以接收传入的http消息,forward将fluentd转换为TCP端点,以接受TCP包。当然,它可以同时出现。每个源指令必须包含一个类型参数,类型参数指定要使用的输入插件。
match: 告诉fluentd做什么,match指令使用匹配的标记查找事件,并处理它们。最常用的匹配指令是将事件输出到其他系统。Fluentd的标准输出插件包括文件file和转发forward。让我们将这些添加到配置文件中。每个匹配指令必须包含匹配模式和类型参数。只有带有与模式匹配的标记的事件才会被发送到输出目的地. 广泛的匹配模式应该在严格的匹配模式之后定义。
流程就是source 收集日志,然后由串联的 filter 做流式的处理,最后交给 match 进行分发。同时还可以用 label 将任务分组,用 error 处理异常,用 system 修改运行参数。日志存储的格式,根据源不同,比如源是docker的syslog,格式就是syslog的日志形式按配置修改,主要的格式化配置都在配置文件中的 format 这段配置里,主要采用正则表达式拆分数据到自定义的以 <> 包围起来的属性中。
相关文章:
基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统
目录 1、EFK简介 2、EFK框架 2.1、Fluentd系统架构 2.2、Elasticsearch系统架构 2.3、Kibana系统架构 3、Elasticsearch接口 4、EFK在虚拟机中安装步骤 4.1、安装elasticsearch 4.2、安装kibana 4.3、安装fluentd 4.4、进入kibana创建索引 5、Fluentd配置介绍 VC常…...

【Python小项目之Tkinter应用】解决Python的Pyinstaller将.py文件打包成.exe可执行文件后文件过大的问题
文章目录 前言1. 创建新项目2.删除原项目中的全部文件3.将要打包的文件放入该项目目录下4.创建虚拟环境5.设置解释器为虚拟环境中的python解释器6.查看是否成功使用虚拟环境中的python解…...

Ab3d.DXEngine 6.0 Crack 2023
Ab3d.DXEngine 不是另一个游戏引擎(如Unity),它强迫您使用其游戏编辑器、其架构,并且需要许多技巧和窍门才能在标准 .Net 应用程序中使用。Ab3d.DXEngine 是一个新的渲染引擎,它是从头开始构建的,旨在用于标…...

Wireshark抓包常用指令
1.常用过滤规则 指定源地址: ip.src 10.0.1.123ip.src 10.0.1.123 && udphttp数据链路层:筛选mac地址为04:f9:38:ad:13:26的数据包----eth.src 04:f9:38:ad:13:26筛选源mac地址为04:f9:38:ad:13:26的数据包----eth.src 04:f9:38:ad:13:26网…...
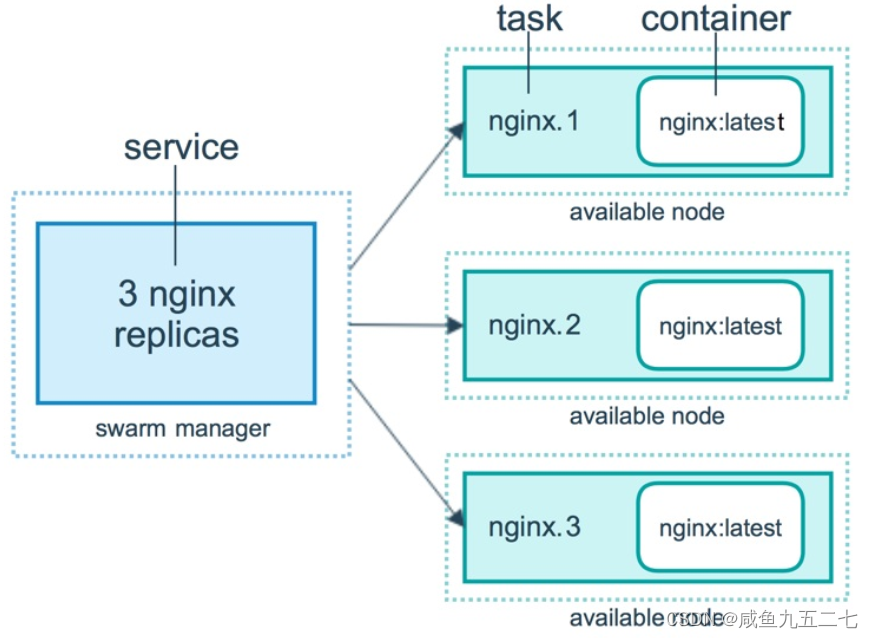
Docker Swarm
Docker Swarm提供 Docker 容器集群服务,是 Docker 官方对容器云生态进行支持的核心方案。将多个 Docker 主机封装为单个大型的虚拟 Docker 主机,快速打造一套容器云平台。 Swarm mode内置 kv 存储功能,提供了众多的新特性,比如&a…...

jupyter notebook安装和删除kernel的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

中级深入--day16
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider) 之间恢宏壮阔的斗争... Day 1 小黄想要某站上所有的电影,写了标准的爬虫(基于HttpClient库),不断地遍历某站的电影列表页面,根据 Html 分析电影名字存进…...
)
【洛谷 P1031】[NOIP2002 提高组] 均分纸牌 题解(贪心)
[NOIP2002 提高组] 均分纸牌 题目描述 有 N N N 堆纸牌,编号分别为 1 , 2 , … , N 1,2,\ldots,N 1,2,…,N。每堆上有若干张,但纸牌总数必为 N N N 的倍数。可以在任一堆上取若干张纸牌,然后移动。 移牌规则为:在编号为 1 …...

E5071C是德科技网络分析仪
描述 E5071C网络分析仪提供同类产品中最高的RF性能和最快的速度,具有宽频率范围和多功能。E5071C是制造和R&D工程师评估频率范围高达20 GHz的RF元件和电路的理想解决方案。特点: 宽动态范围:测试端口的动态范围> 123 dB(典型值)快速测量速度:41毫秒全2端口…...

ViTPose+:迈向通用身体姿态估计的视觉Transformer基础模型 | 京东探索研究院
身体姿态估计旨在识别出给定图像中人或者动物实例身体的关键点,除了典型的身体骨骼关键点,还可以包括手、脚、脸部等关键点,是计算机视觉领域的基本任务之一。目前,视觉transformer已经在识别、检测、分割等多个视觉任务上展现出来…...

Android 播放mp3文件
1,在res/raw中加入mp3文件 2,实现播放类 import android.content.Context; import android.media.AudioManager; import android.media.SoundPool; import android.util.Log;import java.util.HashMap; import java.util.Map;public class UtilSound {pu…...
在OpenStack私有云上安装配置虚拟机
文章目录 零、学习目标一、登录大数据实训云二、创建网络三、创建路由四、添加接口五、创建端口六、添加安全组规则七、创建实例(一)实例规划(二)创建实例 - ied(三)创建实例 - master、slave1与slave2&…...
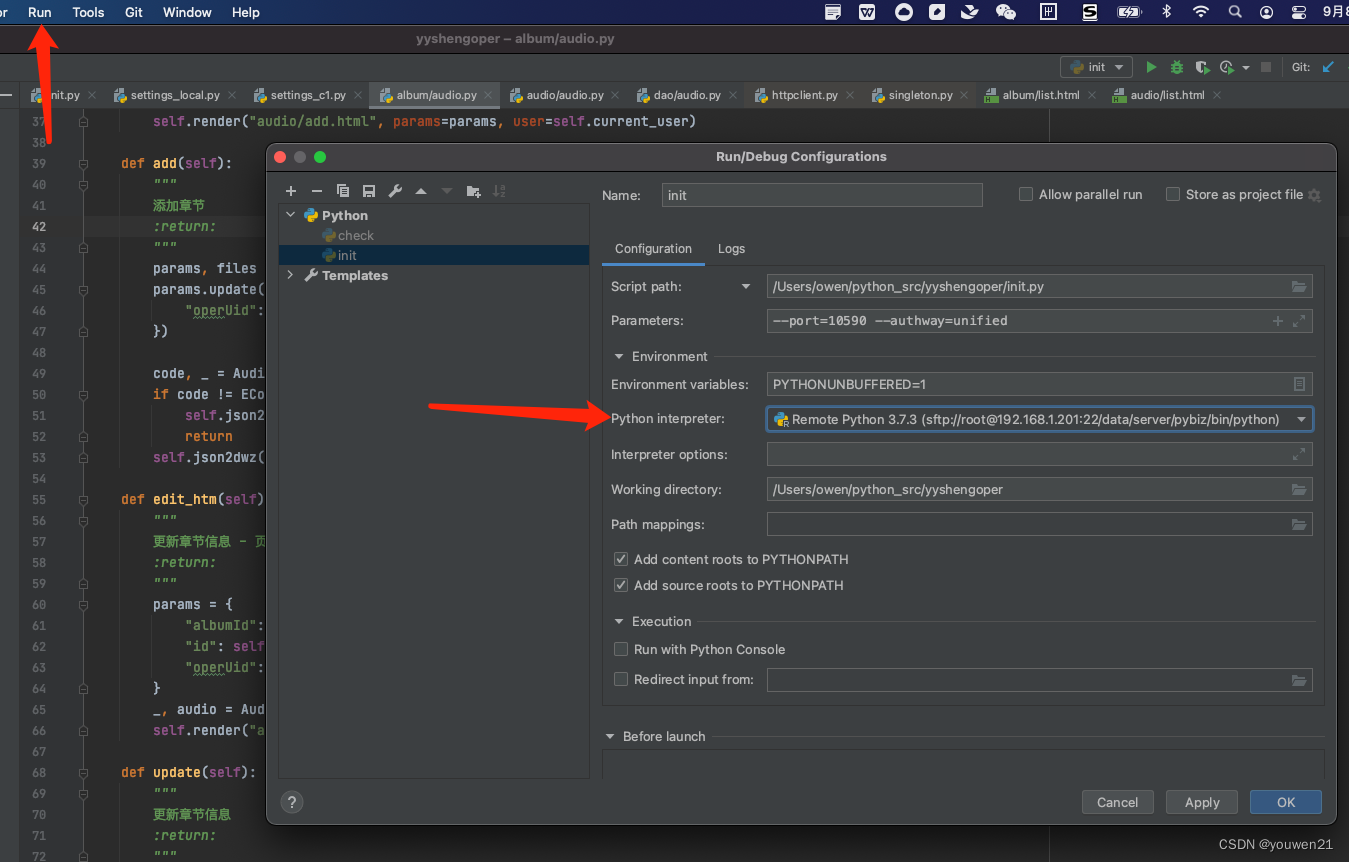
pyCharm远程DEBUG
第一步,添加一个远程机器的解释器 ssh 远程机器解释器添加, 我本地ssh有配置目标机器。 如果没配置,那就选着new server configuration 新增一个。 interpreter 指定远程机器python, (机器上有多个版本python里尤其要…...

微服务框架Go-kit
微服务框架Go-kit go kit简介第一个go kit应用go kit基本概念go kit Endpointsgo kit Endpoint 定义go kit Endpoint 函数签名go kit Endpoint 链式操作go kit Endpoint 请求和响应转换go kit Endpoint 中间件go kit Endpoint 错误处理go kit 传输层go kit HTTP 传输层go kit …...
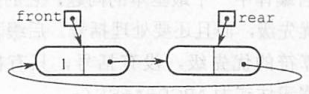
《王道24数据结构》课后应用题——第三章 栈和队列
第三章 【3.1】 03、 假设以I和O分别表示入栈和出操作。栈的初态和终态均为空,入栈和出栈的操作序列可表示为仅由I和O组成的序列,可以操作的序列称为合法序列,否则称为非法序列。 如IOIIOIOO 和IIIOOIOO是合法的,而IOOIOIIO和II…...

查看linux开发板的CPU频率
1)查看CPU可设置的频率列表 cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_frequencies 2)查看CPU当前所使用的频率: cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq 3)设置CPU频率(最高…...

对象模型和this指针(个人学习笔记黑马学习)
1、成员变量和成员函数 #include <iostream> using namespace std; #include <string>//成员变量和成员函数分开存储class Person {int m_A;//非静态成员变量 属于类的对象上的static int m_B;//静态成员变量 不属于类的对象上void func() {} //非静态成员函数 不…...
SpringCloudAlibaba常用组件
SpringCloudAlibaba常用组件 微服务概念 1.1 单体、分布式、集群 单体 ⼀个系统业务量很⼩的时候所有的代码都放在⼀个项⽬中就好了,然后这个项⽬部署在⼀台服务器上就 好了。整个项⽬所有的服务都由这台服务器提供。这就是单机结构。 单体应⽤开发简单,部署测试…...
Shotcut for Mac:一款强大而易于使用的视频编辑器
随着数码相机的普及,视频编辑已成为我们日常生活的一部分。对于许多专业和非专业用户来说,找到一个易于使用且功能强大的视频编辑器是至关重要的。今天,我们将向您介绍Shotcut——一款专为Mac用户设计的强大视频编辑器。 什么是Shotcut&…...
【数学建模】2023数学建模国赛C题完整思路和代码解析
C题第一问代码和求解结果已完成,第一问数据量有点大,经过编程整理出来了单品销售额的汇总数据、将附件2中的单品编码替换为分类编码,整理出了蔬菜各品类随着时间变化的销售量,并做出了这些疏菜品类的皮尔森相关系数的热力图&#…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...