pytorch搭建squeezenet网络的整套工程,及其转tensorrt进行cuda加速
本来,前辈们用caffe搭建了一个squeezenet的工程,用起来也还行,但考虑到caffe的停更后续转trt应用在工程上时可能会有版本的问题所以搭建了一个pytorch版本的。
以下的环境搭建不再细说,主要就是pyorch,其余的需要什么pip install什么。
网络搭建
squeezenet的网络结构及其具体的参数如下:

后续对着这张表进行查看每层的输出时偶然发现这张表有问题,一张224×224的图片经过7×7步长为2的卷积层时输出应该是109×109才对,而不是这个111×111。所以此处我猜测要不是卷积核的参数有问题,要不就是这个输出结果有问题。我对了下下面的结果,发现都是从这个111×111的结果得出来的,这个结果没问题;但是我又对了下原有caffe版本的第一个卷积层用的就是这个7×7/2的参数,卷积核也没问题。这就有点矛盾了…这张表出自作者原论文,论文也是发表在顶会上,按道理应该不会有错才对。才疏学浅,希望大家有知道咋回事的能告诉我一声,这里我就还是用这个卷积核的参数了。

squeezenet有以上三个版本,我对了下发现前辈用的是中间这个带有简单残差的结构,为了进行对比这里也就用这个结构进行搭建了。
如下为网络结构的代码:
import torch
import torch.nn as nnclass Fire(nn.Module):def __init__(self, in_channel, squzee_channel, out_channel):super().__init__()self.squeeze = nn.Sequential(nn.Conv2d(in_channel, squzee_channel, 1),nn.ReLU(inplace=True))self.expand_1x1 = nn.Sequential(nn.Conv2d(squzee_channel, out_channel, 1), nn.ReLU(inplace=True))self.expand_3x3 = nn.Sequential(nn.Conv2d(squzee_channel, out_channel, 3, padding=1),nn.ReLU(inplace=True))def forward(self, x):x = self.squeeze(x)x = torch.cat([self.expand_1x1(x),self.expand_3x3(x)], 1)return xclass SqueezeNet_caffe(nn.Module):"""mobile net with simple bypass"""def __init__(self, class_num=5):super().__init__()self.stem = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=96, kernel_size=7, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(3, 2, ceil_mode=True))self.fire2 = Fire(96, 16, 64)self.fire3 = Fire(128, 16, 64)self.fire4 = Fire(128, 32, 128)self.fire5 = Fire(256, 32, 128)self.fire6 = Fire(256, 48, 192)self.fire7 = Fire(384, 48, 192)self.fire8 = Fire(384, 64, 256)self.fire9 = Fire(512, 64, 256)self.maxpool = nn.MaxPool2d(3, 2, ceil_mode=True)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Conv2d(512, class_num, kernel_size=1), nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)) )def forward(self, x):x = self.stem(x)f2 = self.fire2(x)f3 = self.fire3(f2) + f2f4 = self.fire4(f3)f4 = self.maxpool(f4)f5 = self.fire5(f4) + f4f6 = self.fire6(f5)f7 = self.fire7(f6) + f6f8 = self.fire8(f7)f8 = self.maxpool(f8)f9 = self.fire9(f8) + f8x = self.classifier(f9)x = x.view(x.size(0), -1)return xdef squeezenet_caffe(class_num=5):return SqueezeNet_caffe(class_num=class_num)
然后其余的整个工程代码就是pytorch搭建dataset、dataloader,每轮的前向、计算loss、反向传播等都是一个差不多的套路,就不在这里码出来了,直接放上链接,大家有需要可以直接下载(里面也集成了其他的分类网络)。
数据处理
dataset我用的是torchvision.datasets.ImageFolder,所以用目录名称作为数据集的label,目录结构如下:

将每一类的图片都放在对应的目录中,验证集以及测试集的数据集也是按照这样的格式。
运行命令
训练命令:
python train.py -net squeezenet_caffe -gpu -b 64 -t_data 训练集路径 -v_data 验证集路径 -imgsz 100
-net后面跟着是网络类型,都集成了如下的分类网络:

如果有n卡则-gpu使用gpu训练,-b是batch size,-imgsz是数据的input尺寸即resize的尺寸。
测试命令:
python test.py -net squeezenet_caffe -weights 训练好的模型路径 -gpu -b 64 -data 测试集路径 -imgsz 100
出现问题
一开始进行训练一切正常,到后面却忽然画风突变:

loss忽然大幅度上升,acc也同一时刻大幅度下降,然后数值不变呈斜率为0的一条直线。估计是梯度爆炸了(也是到这一步我先从网络结构找原因,对本文的第一张表一层一层对参数和结果才发现表中的问题),网络结构对完没问题,于是打印每个batch的梯度,顺便使用clip进行剪枝限定其最大阈值。
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()grad_max = 0
grad_min = 10
for p in net.parameters():# 打印每个梯度的模,发现打印太多了一直刷屏所以改为下面的print最大最小值# print(p.grad.norm())gvalue = p.grad.norm()if gvalue > grad_max:grad_max = gvalueif gvalue < grad_min:grad_min = gvalue
print("grad_max:")
print(grad_max)
print("grad_min:")
print(grad_min)
# 将梯度的模clip到小于10的范围
torch.nn.utils.clip_grad_norm(p,10)optimizer.step()
按道理来说应该会有所改善,但结果是,训练几轮之后依旧出现这个问题。
但是,果然梯度在曲线异常的时候数值也是异常的:

刚开始正常学习的时候梯度值基本上都在e-1数量级的,曲线异常阶段梯度值都如图所示无限接近0,难怪不学习。
我们此时看一下tensorboard,我将梯度的最大最小值write进去,方便追踪:

可以发现在突变处梯度值忽然爆炸激增,猜测原因很可能是学习率太大了,动量振动幅度太大了跳出去跳不回来了。查看设置的学习率超参发现初始值果然太大了(0.1),于是改为0.01。再次运行后发现查看其tensorboard:

这回是正常的了。
但其实我放大查看了梯度爆炸点的梯度值:

发现其最大值没超过10,所以我上面的clip没起到作用,我如果将阈值改成2,结果如下:

发现起到了作用,但曲线没那么平滑,可能改成1或者再小一些效果会更好。但我觉得还是直接改学习率一劳永逸比较简单。
Pytorch模型转TensorRT模型
在训练了神经网络之后,TensorRT可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。TensorRT通过combines
layers,kernel优化选择,以及根据指定的精度执行归一化和转换成最优的matrix math方法,改善网络的延迟、吞吐量以及效率。
总之,通俗来说,就是训练的模型转trt后可以在n卡上高效推理,对于实际工程应用更加有优势。
首先将pth转onnx:
# pth->onnx->trtexec
# (optional) Exporting a Model from PyTorch to ONNX and Running it using ONNX Runtime
import torchvision
import torch,os
from models.squeezenet_caffe import squeezenet_caffebatch_size = 1 # just a random numbercurrent_dir=os.path.dirname(os.path.abspath(__file__)) # 获取当前路径
device = 'cuda' if torch.cuda.is_available() else 'cpu'model = squeezenet_caffe().cuda()model_path='/data/cch/pytorch-cifar100-master/checkpoint/squeezenet_caffe/Monday_04_September_2023_11h_48m_33s/squeezenet_caffe-297-best.pth' # cloth
state_dict = torch.load(model_path, map_location=device)
print(1)
# mew_state_dict = OrderedDict()
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in state_dict.items() if (k in model_dict and 'fc' not in k)}
model_dict.update(pretrained_dict)
print(2)
model.load_state_dict(model_dict)
model.eval()
print(3)
# output = model(data)# Input to the model
x = torch.randn(batch_size, 3, 100, 100, requires_grad=True)
x = x.cuda()
torch_out = model(x)# Export the model
torch.onnx.export(model, # model being runx, # model input (or a tuple for multiple inputs)"/data/cch/pytorch-cifar100-master/checkpoint/squeezenet_caffe/Monday_04_September_2023_11h_48m_33s/squeezenet_caffe-297-best.onnx", # where to save the model (can be a file or file-like object)export_params=True, # store the trained parameter weights inside the model fileopset_version=10, # the ONNX version to export the model todo_constant_folding=True, # whether to execute constant folding for optimizationinput_names = ['input'], # the model's input namesoutput_names = ['output'], # the model's output namesdynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes'output' : {0 : 'batch_size'}})
只需要修改一下输入输出的路径和输入的size即可。
然后是onnx转trt,这里需要自己先安装搭建好tensorrt的环境(环境搭建可能会有点复杂需要编译,有时间单独出一个详细的搭建过程),然后在tensorrt工程下的bin目录下运行命令:
./trtexec --onnx=/data/.../best.onnx --saveEngine=/data.../best.trt --workspace=6000
TensorRT可以提供workspace作为每层网络执行时的临时存储空间,该空间是共享的以减少显存占用(单位是M)。具体的原理可以参考这篇。
前向推理
代码如下:
# 动态推理
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import torchvision.transforms as transforms
from PIL import Imagedef load_engine(engine_path):# TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # INFOTRT_LOGGER = trt.Logger(trt.Logger.ERROR)print('---')print(trt.Runtime(TRT_LOGGER))print('---')with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:return runtime.deserialize_cuda_engine(f.read())# 2. 读取数据,数据处理为可以和网络结构输入对应起来的的shape,数据可增加预处理
def get_test_transform():return transforms.Compose([transforms.Resize([100, 100]),transforms.ToTensor(),# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),transforms.Normalize(mean=[0.4796262, 0.4549252, 0.43396652], std=[0.27888104, 0.28492442, 0.27168077])])image = Image.open('/data/.../dog.jpg')
image = get_test_transform()(image)
image = image.unsqueeze_(0) # -> NCHW, 1,3,224,224
print("input img mean {} and std {}".format(image.mean(), image.std()))
image = np.array(image)path = '/data/.../squeezenet_caffe-297-best.trt'
# 1. 建立模型,构建上下文管理器
engine = load_engine(path)
print(engine)
context = engine.create_execution_context()
context.active_optimization_profile = 0# 3.分配内存空间,并进行数据cpu到gpu的拷贝
# 动态尺寸,每次都要set一下模型输入的shape,0代表的就是输入,输出根据具体的网络结构而定,可以是0,1,2,3...其中的某个头。
context.set_binding_shape(0, image.shape)
d_input = cuda.mem_alloc(image.nbytes) # 分配输入的内存。
output_shape = context.get_binding_shape(1)
buffer = np.empty(output_shape, dtype=np.float32)
d_output = cuda.mem_alloc(buffer.nbytes) # 分配输出内存。
cuda.memcpy_htod(d_input, image)
bindings = [d_input, d_output]# 4.进行推理,并将结果从gpu拷贝到cpu。
context.execute_v2(bindings) # 可异步和同步
cuda.memcpy_dtoh(buffer, d_output)
output = buffer.reshape(output_shape)
y_pred_binary = np.argmax(output, axis=1)
print(y_pred_binary[0])
相关文章:
pytorch搭建squeezenet网络的整套工程,及其转tensorrt进行cuda加速
本来,前辈们用caffe搭建了一个squeezenet的工程,用起来也还行,但考虑到caffe的停更后续转trt应用在工程上时可能会有版本的问题所以搭建了一个pytorch版本的。 以下的环境搭建不再细说,主要就是pyorch,其余的需要什么p…...

【精读Uboot】SPL阶段的board_init_r详细分析
对于i.MX平台上的SPL来说,其不会直接跳转到Uboot,而是在SPL阶段借助BOOTROM跳转到ATF,然后再通过ATF跳转到Uboot。 board_init_f会初始化设备相关的硬件,最后进入board_init_r为镜像跳转做准备。下面是board_init_r调用的核心函数…...
canvas绘制渐变色三角形金字塔
项目需求:需要绘制渐变色三角形金字塔,并用折线添加标识 (其实所有直接用图片放上去也行,但是ui没切图,我也懒得找她要,正好也没啥事,直接自己用代码绘制算了,总结一句就是闲的) 最终效果如下图: (以上没用任何图片,都是代码绘制的) 在网上找了,有用canvas绘…...
企业电子招标采购系统源码Spring Boot + Mybatis + Redis + Layui + 前后端分离 构建企业电子招采平台之立项流程图
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外部供…...

Debain JDK8 安装
Debain JDK8 安装 首先请安装依赖: sudo apt-get update && sudo apt-get install -y wget apt-transport-https然后信任 GPG 公钥: wget -O - https://packages.adoptium.net/artifactory/api/gpg/key/public | sudo tee /etc/apt/keyrings/…...

Python序列操作指南:列表、字符串和元组的基本用法和操作
文章目录 序列列表创建列表访问元素修改元素添加和删除元素 range()字符串创建字符串访问字符字符串切片修改字符串 元组创建元组访问元素获取元素数量元组的特点: 可变对象改变对象的值改变变量的指向比较运算符总结 python精品专栏推荐python基础知识(…...
【已更新代码图表】2023数学建模国赛E题python代码--黄河水沙监测数据分析
E 题 黄河水沙监测数据分析 黄河是中华民族的母亲河。研究黄河水沙通量的变化规律对沿黄流域的环境治理、气候变 化和人民生活的影响,以及对优化黄河流域水资源分配、协调人地关系、调水调沙、防洪减灾 等方面都具有重要的理论指导意义。 附件 1 给出了位于小浪底水…...
【前端】CSS-Grid网格布局
目录 一、grid布局是什么二、grid布局的属性三、容器属性1、display①、语句②、属性值 2、grid-template-columns属性、grid-template-rows属性①、定义②、属性值1)、固定的列宽和行高2)、repeat()函数3)、auto-fill关键字4)、f…...

计算机竞赛 基于深度学习的动物识别 - 卷积神经网络 机器视觉 图像识别
文章目录 0 前言1 背景2 算法原理2.1 动物识别方法概况2.2 常用的网络模型2.2.1 B-CNN2.2.2 SSD 3 SSD动物目标检测流程4 实现效果5 部分相关代码5.1 数据预处理5.2 构建卷积神经网络5.3 tensorflow计算图可视化5.4 网络模型训练5.5 对猫狗图像进行2分类 6 最后 0 前言 &#…...

2023-9-8 求组合数(二)
题目链接:求组合数 II #include <iostream> #include <algorithm>using namespace std;typedef long long LL; const int mod 1e9 7; const int N 100010;// 阶乘,阶乘的逆 int fact[N], infact[N];LL qmi(int a, int k, int p) {int res…...

k8s service的一些特性
文章目录 Service分发负载的策略同一端口通过不同协议暴露Headless Service的负载分发策略 Service分发负载的策略 大家都知道,一个service可以对应多个pod,那么一定要有一些方法来把service接收到的请求(负载)转发到pod上。 一般…...

C++中std::enable_if和SFINAE介绍
作为一个标准的C++模板类,我们先看下enable_if的定义: // STRUCT TEMPLATE enable_if template <bool _Test, class _Ty = void> struct enable_if {}; // no member "type" when !_Testtemplate <class _Ty> struct enable_if<true, _Ty> { //…...
华为OD机考算法题:数字加减游戏
目录 题目部分 解读与分析 代码实现 题目部分 题目数字加减游戏难度难题目说明小明在玩一个数字加减游戏,只使用加法或者减法,将一个数字 s 变成数字 t 。 每个回合,小明可以用当前的数字加上或减去一个数字。 现在有两种数字可以用来加减…...

WPF命令
在设计良好的Windows应用程序中,应用程序逻辑不应位于事件处理程序中,而应在更高层的方法中编写代码。其中的每个方法都代表单独的应用程序任务。每个任务可能依赖其他库。 使用这种设计最明显的方式是在需要的地方添加事件处理程序,并使用各…...
Unity中Shader的屏幕抓取 GrabPass
文章目录 前言一、抓取1、抓取指令2、在使用抓取的屏幕前,需要像使用属性一样定义一下,_GrabTexture这个名字是Unity定义好的 前言 Unity中Shader的屏幕抓取 GrabPass 一、抓取 1、抓取指令 屏幕的抓取需要使用一个Pass GrabPass{} GrabPass{“NAME”} 2、在使用…...
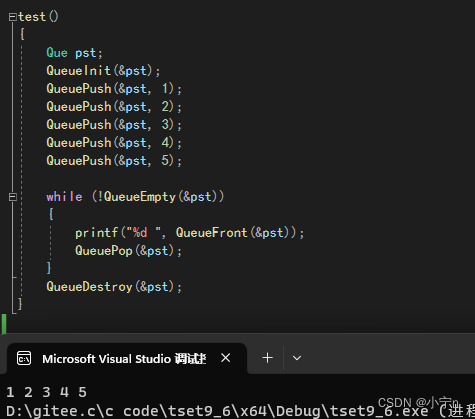
手撕 队列
队列的基本概念 只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头 队列用链表实现 队列的实现 队列的定义 队列…...
【autodl/linux配环境心得:conda/本地配cuda,cudnn及pytorch心得】-未完成
linux配环境心得:conda/本地配cuda,cudnn及pytorch心得 我们服务器遇到的大多数找不到包的问题一,服务器安装cuda和cudnn使用conda在线安装cuda和cudnn使用conda进行本地安装检查conda安装的cuda和cudnn本地直接安装cuda和cudnn方法一&#x…...
macOS Ventura 13.5.2(22G91)发布,附黑/白苹果镜像下载地址
系统介绍(下载请百度搜索:黑果魏叔) 黑果魏叔 9 月 8 日消息,苹果今日向 Mac 电脑用户推送了 macOS 13.5.2 更新(内部版本号:22G91),本次更新距离上次发布隔了 21 天。 本次更新查…...

vue 子组件向父组件传递参数 子传父
子组件中写: this.$emit(RowCount,res.data.RowCount); 父组件中写: getMFGLRowCount(val){ //父组件中的方法: 接收子组件传过来的参数值赋值给父组件的变量 //this.totalCount val; alert("这…...

自然语言处理学习笔记(八)———— 准确率
目录 1.准确率定义 2.混淆矩阵与TP/FN/FP/TN 3. 精确率 4.召回率 5.F1值 6.中文分词的P、R、F1计算 7.实现 1.准确率定义 准确率是用来衡量一个系统的准确程度的值,可以理解为一系列评测指标。当预测与答案的数量相等时,准确率指的是系统做出正确判…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...