实训笔记9.1
实训笔记9.1
- 9.1笔记
- 一、项目开发流程一共分为七个阶段
- 1.1 数据产生阶段
- 1.2 数据采集存储阶段
- 1.3 数据清洗预处理阶段
- 1.4 数据统计分析阶段
- 1.5 数据迁移导出阶段
- 1.6 数据可视化阶段
- 二、项目的数据产生阶段
- 三、项目的数据采集存储阶段
- 四、项目数据清洗预处理的实现
- 4.1 清洗预处理规则
- 4.1.1 数据清洗规则
- 4.1.2 数据预处理规则
- 4.2 技术选项
- 4.3 代码实现
- 五、项目的数据统计分析阶段
- 5.1 概念和技术选项
- 5.2 Hive数据仓库进行统计分析时两个核心概念
- 5.2.1 数据仓库分层
- 5.2.2 数据仓库建模
- 5.3 数据统计分析的实现(最好把所有的HQL代码写到一个SQL文件中,最后统一执行运行) 统计分析必须启动HDFS和YARN
- 5.3.1 构建ODS层
- 5.3.2 构建DWD层
- 5.3.3 构建ADS层
- 5.4 统计分析部署和运行
- 六、项目的数据迁移导出阶段
- 6.1 概念
- 6.2 数据迁移导出的技术选型
- 6.3 数据迁移导出的开发实现
- 七、项目的数据可视化阶段
- 7.1 概念
- 7.2 数据可视化常用技术
- 7.2.1 代码可视化
- 7.2.2 第三方工具可视化
- 7.3 阿里云DataV的使用的步骤
- 八、项目的任务调度阶段
- 8.1 概念
- 8.2 技术
- 8.3 项目技术选项:azkaban技术
- 8.4 azkaban的使用
- 8.4.1 azkaban配置任务调度主要涉及到一个压缩包,两个配置文件
- 8.4.2 案例
- 8.5 项目中使用azkaban进行任务调度
- 8.6 安装azkaban的一些报错
- 九、【项目补充点】
- 9.1 模拟其他年份,其他月份,其他日期的数据
9.1笔记
一、项目开发流程一共分为七个阶段
1.1 数据产生阶段
1.2 数据采集存储阶段
1.3 数据清洗预处理阶段
1.4 数据统计分析阶段
1.5 数据迁移导出阶段
1.2~1.5:大数据开发阶段
1.3~1.5:周期性调度执行,三个阶段需要通过azkaban任务调度工具进行自动化周期调度执行,
(项目的第7个阶段,任务调度阶段)
1.6 数据可视化阶段
二、项目的数据产生阶段
数据产生主要目的是为了模拟真实业务场景下的数据产生的流程。因为项目的数据应该是来自于白龙马电商网站的用户在网站界面上的行为触发之后然后由网站的后端自动记录用户的行为数据到日志文件中。
主要借助JavaSE中集合+随机数+IO流+for循环+时间格式类
【注意】数据产生不是我们大数据工作人员的任务(不一定),在开发大数据项目时,数据来源一般都是已经存在的
三、项目的数据采集存储阶段
项目中产生的数据是海量的,而且默认情况下项目产生的用户行为数据是记录在日志文件当中,但是日志文件中的数据不是持久化保存的、而且也无法存储大量的数据。但是数据中隐含了很多的价值信息。因此我们需要将网站产生的大批量的日志文件采集存储到大数据环境中进行持久化、海量化存储。
技术:Flume+HDFS
四、项目数据清洗预处理的实现
4.1 清洗预处理规则
4.1.1 数据清洗规则
- 一条用户行为数据如果字段个数不足16,那么数据不完整,舍弃
- 一条用户行为数据中如果响应状态码大于等于400的,那么数据访问错误,舍弃
- 一条用户行为数据中省份 纬度 经度 年龄以-填充的,那么代表数据缺失,舍弃
4.1.2 数据预处理规则
- 预处理规则:清洗完成的数据中最后在输出时,有很多的字段我们不需要的,因此我们需要对部分数据进行舍弃,对需要保留的字段数据以\001特殊字符分割输出
4.2 技术选项
MapReduce技术
4.3 代码实现
【注意】
因为我们只需要做数据的清洗预处理操作,不涉及到聚合操作,因此我们只需要一个Mapper阶段即可,不需要reduce阶段
MapReduce数据清洗预处理是周期性调度执行的,一天执行一次,第二天处理前一天采集存储的数据,前一天采集存储的数据是以时间为基准的动态目录下存放,因此MR程序处理数据时,输入数据的目录必须得是昨天时间的目录。
【注意】会在第二天处理前一天的数据,一般会在第二天的凌晨去处理第一天采集存储的数据。(任务调度的事情)
MR程序处理完成的数据输出到HDFS上,但是数据清洗预处理完成的数据给Hive做统计分析的,Hive我们也是一天执行一次,Hive是在数据清洗预处理完成之后执行的。 MR程序处理完成的数据输出到HDFS上时,也必须以基于时间的动态目录存放
- 创建Maven项目,引入MR的编程依赖
- 编写MR程序的Mapper程序和Driver驱动程序
- 在本地测试运行无问题之后,需要将代码打成jar包上传到大数据环境中在YARN上运行 必须启动YARN
五、项目的数据统计分析阶段
5.1 概念和技术选项
统计分析就是基于我们清洗预处理完成的高质量,从不同的数据纬度聚合数据,或者对数据进行计算得到我们感兴趣的一些指标或者是对网站运营发展有关的一些指标。
统计分析进行数据计算时,可能涉及到大量的聚合操作以及一些排名、排序等等操作,而这些操作也都是数据计算,那么我们就可以使用大数据计算框架完成,而大数据计算框架MapReduce如果要聚合、排序、分组等操作,MR代码就会非常的复杂。因此我们一般做统计分析时有一个想法,既能计算大量的数据,还能快速简单的进行数据的聚合、排名、分组等操作。就可以使用Hive数据仓库技术完成。
【注意】基本上到现在为止,如果我们要做大数据统计分析,不是直接使用大数据计算框架(MapReduce、Spark、Flink),因为大数据统计分析涉及到大量的聚合、排序、分组等等操作,操作如果直接使用大数据计算框架代码会非常的复杂。基本上都是使用类SQL(表面上写的是类SQL语句,底层还是大数据计算框架)的方式进行大数据统计分析的。
Hadoop—Hive
Spark—Spark SQL
Flink—Flink SQL
5.2 Hive数据仓库进行统计分析时两个核心概念
5.2.1 数据仓库分层
数据仓库建模是用来梳理表和表之间的关系的,便于我们后期进行统计分析。数据仓库分层是我们使用数据仓库进行统计分析的开发流程。
数据仓库分层从最底层开始到最高层主要有如下三层(不同的公司基于三层更加细致的分层)
- ODS层(数据贴源层)
如果我们要使用Hive数据仓库做统计分析,首先我们需要把清洗预处理完成的数据导入到Hive中加载成为一个数据表,ODS层指的就是把清洗预处理完成的数据原模原样的导入到Hive中,导入进来之后这些表组成了ODS层
-
DW层(数据仓库层)–Hive统计分析的核心 数据仓库建模的阶段
-
DWD层(明细宽表层)
- 把ODS层的数据表可以再次处理一下构建成为一个明细宽表、
- 明细宽表一般会把ODS层的字段拆分成更加细粒度的字段,便于我们后期好做统计分析(时间字段)
-
DIM层(纬表层)
-
纬度表如果比较多,那么纬度表单独划分到DW的DIM层
- ADS层(数据应用层)
将统计分析的结果以指标表的形式存储到ADS层
5.2.2 数据仓库建模
建模的目的是为了方便我们后期统计分析
在使用Hive进行数据统计分析时,首先必须先把清洗预处理完成的数据加载到Hive中成为数据表,而且一般在真实的企业项目中,清洗预处理完成数据不止一个,各种各样的数据,数据和数据之间都是有关系的。
所谓的数据仓库建模就是我们在对数据进行清洗预处理的时候,清洗预处理完成之后的多个数据之间的关系梳理建模
-
数据仓库建模的名词解释
- 事实表:一张表中基本全都是外键,如果我们需要查询数据,需要将这个表和各个对应的其它数据表进行关联查询才能得到我们想要的数据 订单表
- 维度表:事实表中外键对应的详细信息存储的表,而且他也是我们统计分析时纬度信息 用户表 商品表
-
数据仓库模型建立有很多种方式的,主要分为
-
3NF数据仓库建模
-
纬度建模
-
星型模型
事实表直接与纬度表关联,而且只有一级关联
-
雪花模型
事实表直接与维度表关联,纬度表拆分出更加细致的一些纬度表
-
星座模型
在一个数仓中,事实表有多个,每一个事实表都有它自己对应的纬度表,纬度表还有它的二级纬度表
-
-
如何完成建模?数据清洗预处理的时候,把数据处理成为合适的模型结构
5.3 数据统计分析的实现(最好把所有的HQL代码写到一个SQL文件中,最后统一执行运行) 统计分析必须启动HDFS和YARN
5.3.1 构建ODS层
ODS层指的是我们把清洗预处理完成的数据不加以任何的处理,直接原模原样的在Hive中构建与之对应的表格,并且把数据装载到表格当中
清洗预处理完成的数据格式以\001特殊字符分割的,这样的话可以避免分隔符和字段的中一些符号冲突,导致装载数据到Hive出现串行的问题。
Hive中数据表有很多分类的:内部表、外部表、分区表、分桶表
考虑:数据统计分析一天执行一次,也就意味着我们每天处理完成的数据都需要往Hive的ODS层的数据表导入一份,如何区分ODS层导入的数据是哪一天?需要构建一个分区表(基于时间的)。外部表
5.3.2 构建DWD层
DWD明细宽表层就是把ODS层的数据表字段拆分成为更加细粒度的字段,便于我们后期的统计分析。 DWD层说白了就是在ODS的数据表基础之上在多增加一些冗余字段,但是方便我们后期操作了
- ODS层的字段如下:

-
可以拆分的字段主要有两个
-
时间字段:后期需要基于细粒度的时间做统计分析
年
月
日
时
-
来源URL字段:后期统计站内站外的流量占比,站内站外的对比是基于HOST主机名/域名——HOST
-
DWD层这个数据表就属于我们Hive的自有表了,因此明细宽表我们构建成为内部分区表即可
明细宽表中没有数据,明细宽表中的数据从什么地方来?因为DWD层是基于ODS层建立的,因此DWD层的数据需要从ODS层查询获得。 需要从ODS层对应的数据表中查询指定的数据添加到DWD层当中(注意一下分区的问题)。
5.3.3 构建ADS层
ADS层其实就是我们基于DW数据仓库库构建的DWD和DIM层的数据表,进行查询,通过聚合、分组、排序等等操作统计相关的指标,得到指标数据,然后将指标数据存储到一个Hive数据表中。
-
基于时间纬度的指标
-
统计网站每年的用户的流量
网站每天都会产生数据,每一天数据一增加,那么当前年份的用户访问量必然增加一天的数据
思路:不是针对明细宽表某一个分区的数据进行统计分析,而是针对于明细宽表中整体数据集进行统计分析(所有的分区进行操作)
实现:因为在明细宽表中已经拆分除了visit_year字段,因此我们只需要根据visit_year分区聚合数据即可得到,每一年的用户访问量
select visit_year,count(*) from dwd_user_behavior_detail group by visit_year; -
统计网站每一年不同月份的用户流量
- 实现同上
- 区别:分组时,需要根据年和月来分组
-
统计网站每一年不同月份下每天用户的访问量
- 实现同上
- 区别:分组的时候,需要根据年、月、日三个字段来分组
-
统计网站每一年不同月份下每天的每小时用户的访问量
- 实现同上
- 区别:分组的时候,需要根据年、月、日、时四个字段来分组
-
统计网站每一年每一个月的流量相比于上个月的比例:开窗函数(上边界和下边界),针对每一年不同月份的用户流量指标的二次分析结果
select temp.*,concat(round(temp.flow/temp.before_month_flow,1)*100,"%") as rate from (select * ,first_value(flow) over(partition by visit_year order by visit_month asc rows between 1 PRECEDING and CURRENT ROW) as before_month_flowfrom ads_month_flow ) as temp
-
-
基于地理纬度的指标
-
统计网站不同省份每天用户的流量
- 数据统计分析每天执行一次,每天都要统计不同省份在当天的用户流量占比情况
- 统计两种方式
- 针对明细宽表的数据集整体进行聚合统计
- 上面这种方式不太友好,8.31号我要统计,按道理来说只需要统计8.30号采集的数据即可,8.29号的数据不需要统计了
- 但是如果针对数据集整体统计的话,8.29号的结果会重新计算一遍
- 指标表添加数据时需要覆盖添加
- 只针对当前时间分区的数据进行统计
- 节省资源
- 指标表的数据需要追加添加即可
- 针对明细宽表的数据集整体进行聚合统计
-
统计网站不同省份每月/每年用户流量
针对的就是数据集整体 而非某一个分区
-
每天访问量TOP10的省份
针对的不是明细宽表 而是我们的前面统计不同省份每天用户流量指标(二次分析),指标统计出来之后需要覆盖添加
需要使用排名函数
ads_province_day_flowselect temp.date_time, temp.province, temp.flow from{ select *, row_number() over(partition by data_time order by flow desc) as rank_num from ads_province_day_flow } as temp where temp.rank_num <=10;
-
-
基于用户纬度的指标
-
统计网站不同年龄段用户的流量
明细宽表当中,存在一个字段代表的是用户的年龄,而用户年龄都是大于等于18岁,小于100岁。
基于年龄这个字段,我想查看一下网站不同年龄段的用户情况
用户年龄段
- 青年:18-44
- 中年:45-59
- 中老年:60-79
- 老年:80岁以上
【注意】案例针对是数据集整体,不参杂时间的纬度概念,指标需要覆盖添加的
需要用到hive中的分支函数
-
统计网站每年/每月/每天的不同年龄段的用户访问量
-
统计每天网站的独立访客数
- 独立访客数其实就是IP地址,一个IP算一个独立访客,只需要把每天的ip地址去重之后求一个总数,得到每天的独立访客数
- 针对某一个分区的,指标数据就是追加
-
统计网站每月、每年的独立访问数
针对数据集整体了
-
-
基于终端纬度的指标
-
统计网站用户使用的不同浏览器的占比情况
- 用户行为数据中有一个字段
user_agent,user_agent当中就包含着我们用户使用的浏览器信息情况,基于这个字段统计统计网站不同浏览器的占比情况 - 不统计所有的浏览器,我们只统计一些常见的浏览器的占比 IE、淘宝、火狐、欧朋、QQ浏览器 Safari苹果
- 不同年龄段用户访问量指标是类似的
- 用户行为数据中有一个字段
-
统计网站不同时间段下的不同浏览器的占比情况
-
-
基于来源纬度的指标
- 统计网站每天站内和站外的流量占比
- 用户行为数据中有一个字段referer_url字段,字段代表的是用户访问网站的来源,来源可能是站内的,可能是站外的,现在统计网站站内和站外的来源流量
- 区分站内和站外来源,主要看referer_url中referer_host字段,字段代表来源的域名,如果域名是www.bailongma.com那么代表来源是站内的 如果域名不是白龙马 那么代表来源是站外的针对的是数据集整体,覆盖
- 统计网站不同时间段的站内和站外的流量占比
- 统计网站不同来源网站的占比
- 统计网站每天站内和站外的流量占比
-
指标有很多,可以进行各种自由扩展
5.4 统计分析部署和运行
我们统计分析也是每天执行一次,我们总不能每天运行统计分析,指标代码我们自己手动挨着运行
我们统计分析需要把所有统计分析代码封装到一个xxx.sql文件中,然后到时候统计分析需要执行,我们直接使用hive -f xxx.sql --hiveconf xxx=xxxx
六、项目的数据迁移导出阶段
6.1 概念
现在我们通过Hive数据仓库做的统计分析指标都是在Hive的ADS层存储着。统计的指标的主要目的是为了指导网站的发展和运营的,因此统计完成的数据其中可以做很多操作:基于统计分析的结果进行二次统计分析;基于统计分析的指标结合相关大数据算法做一些数据预测或者数据的深度挖掘;基于统计分析的结果进行可视化大屏的制作。
我们项目中最终需要把统计分析的结果以图表的形式进行可视化展示。
目前现有的可视化技术基本都不太支持从Hive中直接读取数据然后进行可视化展示,但是这些技术支持从RDBMS(MySQL)中读取数据进行可视化展示。
因此我们做可视化大屏之前,需要把Hive数据仓库中ADS层的数据迁移导出到RDBMS关系型数据库当中,然后再借助大数据技术+RDBMS实现数据可视化展示即可
6.2 数据迁移导出的技术选型
我们就是想把Hive数据仓库中数据导出到RDBMS中,目前只学了SQOOP技术
当然除了Sqoop技术以外,还有一个技术DataX(阿里云提供的数据传输工具)
6.3 数据迁移导出的开发实现
要把Hive的数据迁移到MySQL中,SQOOP既可以实现把RDBMS数据迁移到大数据环境(导入),同时也支持把大数据环境数据迁移到RDBMS中(导出)
只需要编写针对性的SQOOP导出数据的命令即可,导出的时候需要注意两个问题:
- MySQL中的必须提前存在和导出的指标表一致的数据表结构
- 导出数据时,有些指标数据追加到MySQL中(针对于分区的指标统计)–sqoop默认导出就是追加的,但是有些指标需要覆盖原先的MySQL数据表(针对整体数据集的指标统计)–sqoop支持不良好,可以通过sqoop把原始MySQL数据表清空,然后再导出
【注意】:后期的话我们做数据可视化,我们需要连接MySQL,我们本次只讲第三方工具的可视化,工具可视化基本上都是支持公网数据库,我们的自己的局域网数据库不支持的。 如何获取带有一个公网IP的MySQL数据库:
- 我们购买一个云服务器,然后在云服务器上自己安装一个MySQL即可。
- 我们直接购买一个云MySQL数据库。
【问题】有部分数据是基于分区统计的,这种数据我们需要追加导出,但是Hive导出数据以文件的形式进行导出的,会把Hive数据表中的所有数据全部导出出去,如果追加导出,数据也会重复。 所以想分区统计的数据也需要覆盖导出的,或者我们在统计基于分区的指标时,我们需要指标表设置成为分区表。
七、项目的数据可视化阶段
7.1 概念
将统计分析的结果以图表的形式进行展示,好处可以直观的看到数据的变化趋势以及数据内部隐藏的一些价值信息
7.2 数据可视化常用技术
7.2.1 代码可视化
编写HTML/CSS/JS/JavaWEB+ECharts+MySQL
- 好处:图表我们想怎么做,想做几个做几个
- 缺点:需要编写代码
7.2.2 第三方工具可视化
- 好处:拖拉拽就可以制作可视化界面
- 缺点:收费、而且图表是有限制
阿里云DataV、腾讯云图可视化、华为云DLV…
7.3 阿里云DataV的使用的步骤
- 关联数据源(连接MySQL)
- 创建可视化大屏
- 在大屏上制作图表,根据图表关联数据源的相关数据
【注意】大屏制作的有一个要求、口诀的:越重要的图表放到大屏的中间或者上方,不重要的指标图表放到大屏的下部或者两边。
八、项目的任务调度阶段
8.1 概念
在本次我们项目中,项目是一个纯离线计算项目,项目中除了数据采集存储以及数据可视化是7*24小时不间断运行的,剩余的阶段:数据清洗预处理、数据统计分析、数据迁移导出这三个阶段都是周期性调度执行,而且周期性调度执行还有一个规则,必须先执行数据清洗预处理,然后数据统计分析阶段再基于数据清洗预处理的基础之上运行,数据迁移导出又是基于数据统计分析的结果运行的。
在企业当中,处理的数据量一般是非常庞大的,而且一般情况下,对数据的计算我们都是在每一天的凌晨完成的(凌晨的服务器资源空闲的比较多,计算的时候可利用资源就多了)。我们总不能每天凌晨我们手动启动数据计算任务。
为了解决计算任务的调度问题,我们需要使用到大数据中任务调度技术,任务调度技术可以实现计算的任务的自动调度(定时器),同时任务调度技术还支持进行多任务的依赖串联,任务调度技术还支持失败重试以及任务报警
8.2 技术
- Oozie:apache的开源任务调度系统 oozie比较笨重,配置比较复杂,它的功能比较全面
- azkaban:github上开源的任务调度系统 azkaban比较轻量级,配置非常简单,它的功能和健壮性没有oozie好
- dolphinScheduler:apache上开源的任务调度系统
- Airflow:github上的开源任务调度系统
- crontab:Linux上自带的一个定时器,任务调度 一次只能调度一个任务
8.3 项目技术选项:azkaban技术
azkaban文档
-
自己编译azkaban得到azkaban的安装包
- azkaban-solo.xxxx.tar.gz
- azkaban-web-server.xxxx.tar.gz
- azkaban.exec-server.xxxx.tar.gz
- azkaban.db-xxxx.tar.gz
-
解压安装包、修改配置文件即可
- 解压:webserver和execserver的安装包解压缩到**/opt/app/azkaban-3.85.0**目录下
- 配置MySQL中的azkaban数据库
- 连接MySQL,在MySQL中创建一个azkaban数据库
- 在azkaban数据库中执行
source /azkaba-db.xxxxx/create-all.xxxx.sql - 更改MySQL的配置
max_allowed_packet=1024M
- 修改webserver和execserver的配置文件
- webserver/conf/azkaban.properties
- 时区
- 数据库的连接
- 任务的调度方式
- execserver/conf/azkaban.properties
- 时区
- 数据库的连接
webserver的地址execserver的端口号
- webserver/conf/azkaban.properties
-
需要把azkaban-webserver和azkaban-execserver依赖jar包升级或者引入
-
mysql-connector-java -
derbyweb/exec的lib目录下
-
-
启动azkaban
- 先启动azkaban的execserver并且激活——必须在azkaban的execserver目录下启动
- 启动azkaban的webserver——必须在azkaban的webserver目录下启动
8.4 azkaban的使用
azkaban主要是用来做任务调度的,azkaban支持将多个任务以流的形式串联起来(将多任务之间互相依赖),然后对串联的工作流设置任务调度时间,让流以指定的时间周期性调度执行
同时azkaban还支持对流中每一个任务配置失败重试,某一个流中任务单元执行失败,可以进行特定次数的重试,如果特定次数之后,任务还是失败的,那么我们才会认为任务执行失败。
8.4.1 azkaban配置任务调度主要涉及到一个压缩包,两个配置文件
-
两个配置文件
-
azkaban.project,配置文件中声明azkaban使用的工作流的版本
azkaban-flow-version: 2.0 -
xxx.flow,配置文件中需要指定azkaban的多个任务,以及多任务之间的依赖关系
eg:
fitst.flow
nodes:- name: jobAtype: commandconfig: command: echo 'zs' - name: jobBtype: commanddependsOn:- jobAconfig:command: echo 'ls'second.flow
nodes:- name: firsttype: commandconfig:command: sh /root/a.shretries: 3retry.backoff: 10000project.flow
nodes:- name: data-cleantype: commandconfig:command: sh /root/project/data-clean/data-clean.shretries: 3retry.backoff: 60000- name: data-analytype: commanddependsOn:- data-cleanconfig: command: sh /root/project/data-analy/data-analy.shretries: 3retry.backoff: 60000- name: data-exporttype: commanddependsOn:- data-analyconfig: command: sh /root/project/data-export/data-export.shretries: 3retry.backoff: 60000
-
-
一个压缩包xxx.zip
压缩包就是我们需要把两个编写好的配置文件打包到一个压缩包中
8.4.2 案例
现在想通过azkaban实现给linux的**/root/a.txt**文件每隔一分钟增加一行zs数据
8.5 项目中使用azkaban进行任务调度
项目中azkaban进行任务调度,主要调度数据清洗预处理程序、数据统计分析程序、数据迁移导出程序
而且这三个任务是有先后依赖关系,先执行数据清洗预处理程序,再执行数据统计分析程序,最后再执行数据迁移导出程序
而且目前三个阶段的代码全部封装成为了sh脚本,只需要执行sh脚本就可以执行三个阶段
8.6 安装azkaban的一些报错
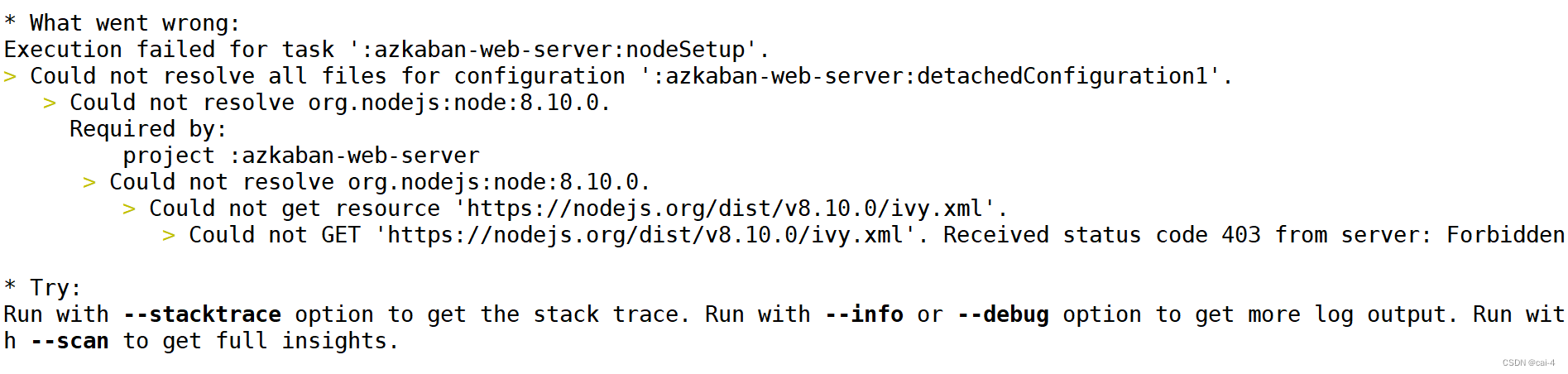
使用yum install -y nodejs 安装一下nodejs
同时在azkaban工作目录下有个azkabanwebserver里面有个build.gra…文件,把里面的node部分的download改为fasle
./gradlew build installDist -x test
博客参考
九、【项目补充点】
9.1 模拟其他年份,其他月份,其他日期的数据
- 只需要通过date -s “时间” 系统时间改成我们想要模拟数据的日期即可
- 把以前产生的userBehavior.log文件删除了
- 然后启动采集程序 启动数据模拟程序
- 处理数据,只需要再把系统时间往后调整一天
【注意】:数据清洗预处理和数据统计分析,底层需要用到MR程序,一定一定要注意MR程序的Map任务的个数和reduce任务的个数,以及每一个map任务和reduce任务占用的内存。
相关文章:
实训笔记9.1
实训笔记9.1 9.1笔记一、项目开发流程一共分为七个阶段1.1 数据产生阶段1.2 数据采集存储阶段1.3 数据清洗预处理阶段1.4 数据统计分析阶段1.5 数据迁移导出阶段1.6 数据可视化阶段 二、项目的数据产生阶段三、项目的数据采集存储阶段四、项目数据清洗预处理的实现4.1 清洗预处…...

汽车SOA架构
文章目录 一、汽车SOA架构的基本概念二、汽车SOA架构的优势三、从设计、开发和测试方面介绍汽车SOA架构四、SOA技术在汽车行业的应用 汽车SOA架构是指汽车软件架构采用面向服务的架构(Service-Oriented Architecture,简称SOA)的设计模式。SOA…...

L1-017 到底有多二 C++解法
题目 一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是偶数…...

motionface respeak视频一键对口型
语音驱动视频唇部动作和视频对口型是两项不同的技术,但是它们都涉及到将语音转化为视觉效果。 语音驱动视频唇部动作(语音唇同步): 语音驱动视频唇部动作是一种人工智能技术,它可以将语音转化为实时视频唇部动作。这…...
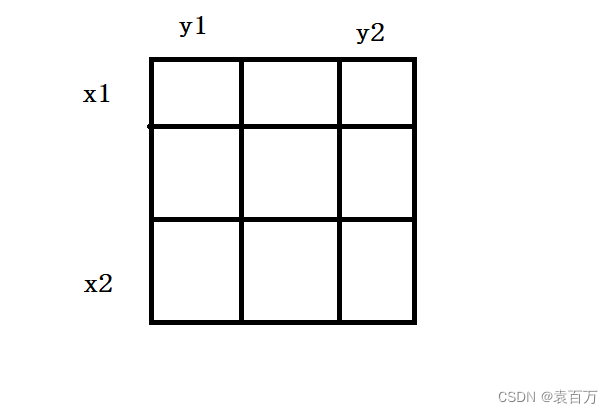
LeetCode——顺时针打印矩形
题目地址 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目解析 按照顺时针一次遍历,遍历外外层遍历里层。 代码如下 class Solution { public:vector<int> spiralOrder(vector<vector<int>>& matrix) {if(…...
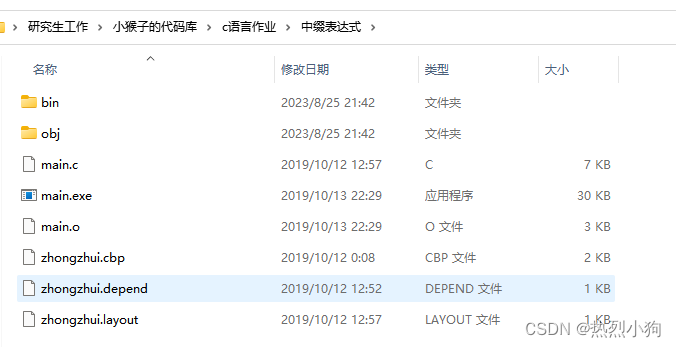
C语言课程作业
本科期间c语言课程作业代码整理: Josephus链表实现 Josephus 层序遍历树 二叉树的恢复 哈夫曼树 链表的合并 中缀表达式 链接:https://pan.baidu.com/s/1Q7d-LONauNLi7nJS_h0jtw?pwdswit 提取码:swit...
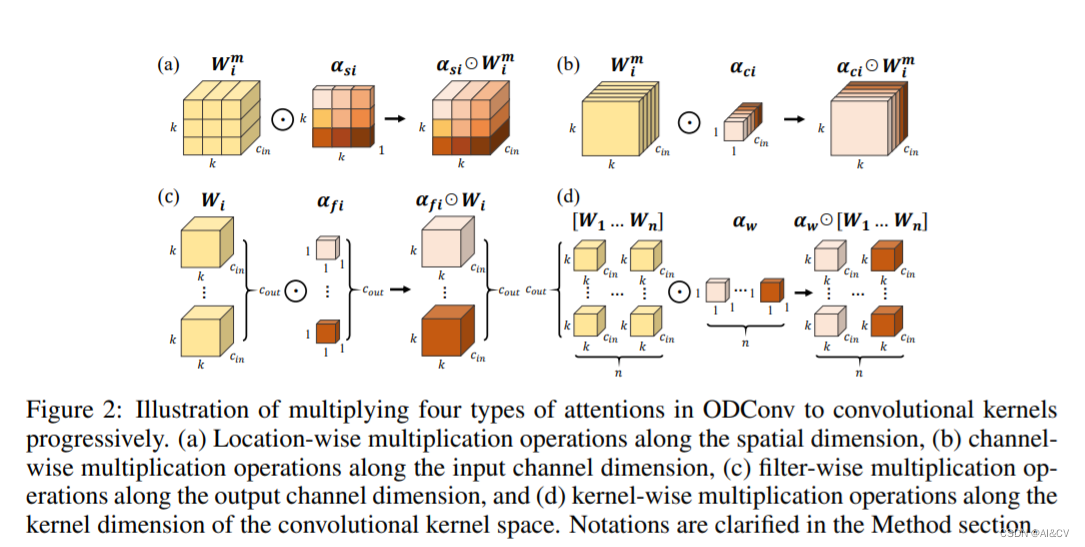
Yolov8魔术师:卷积变体大作战,涨点创新对比实验,提供CVPR2023、ICCV2023等改进方案
💡💡💡本文独家改进:提供各种卷积变体DCNV3、DCNV2、ODConv、SCConv、PConv、DynamicSnakeConvolution、DAT,引入CVPR2023、ICCV2023等改进方案,为Yolov8创新保驾护航,提供各种科研对比实验 &am…...

基于小波神经网络的空气质量预测,基于小波神经网络的PM2.5预测,基于ANN的PM2.5预测
目标 背影 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 小波神经网络(以小波基为传递函数的BP神经网络) 代码链接:基于小波神经网络的PM2.5预测,ann神经网络pm2.5预测资源-CSDN文库 https:/…...

Vue / Vue CLI / Vue Router / Vuex / Element UI
Vue Vue是一种流行的JavaScript前端框架,用于构建用户界面 它被设计为易于学习和使用,并且具有响应式的数据绑定和组件化的架构 Vue具有简洁的语法和灵活的功能,可以帮助开发人员构建高效、可扩展的Web应用程序 它也有一个大型的生态系统和活…...

Lesson4-2:OpenCV图像特征提取与描述---Harris和Shi-Tomas算法
学习目标 理解Harris和Shi-Tomasi算法的原理能够利用Harris和Shi-Tomasi进行角点检测 1 Harris角点检测 1.1 原理 H a r r i s Harris Harris角点检测的思想是通过图像的局部的小窗口观察图像,角点的特征是窗口沿任意方向移动都会导致图像灰度的明显变化ÿ…...
华为云云耀云服务器L实例评测|部署spring项目端口开放问题的解决 服务器项目环境搭建MySQL,Redis,Minio...指南
目录 引出书接上回,部署spring项目,端口访问失败最后排查结果反馈 尝试的几种解决方案【未成功】1.指定tomcat启动ipv4端口2.添加开放端口规则保存规则防火墙相关命令记录 最终成功解决【成功!】用firewall成功了问题来了,如果这里…...
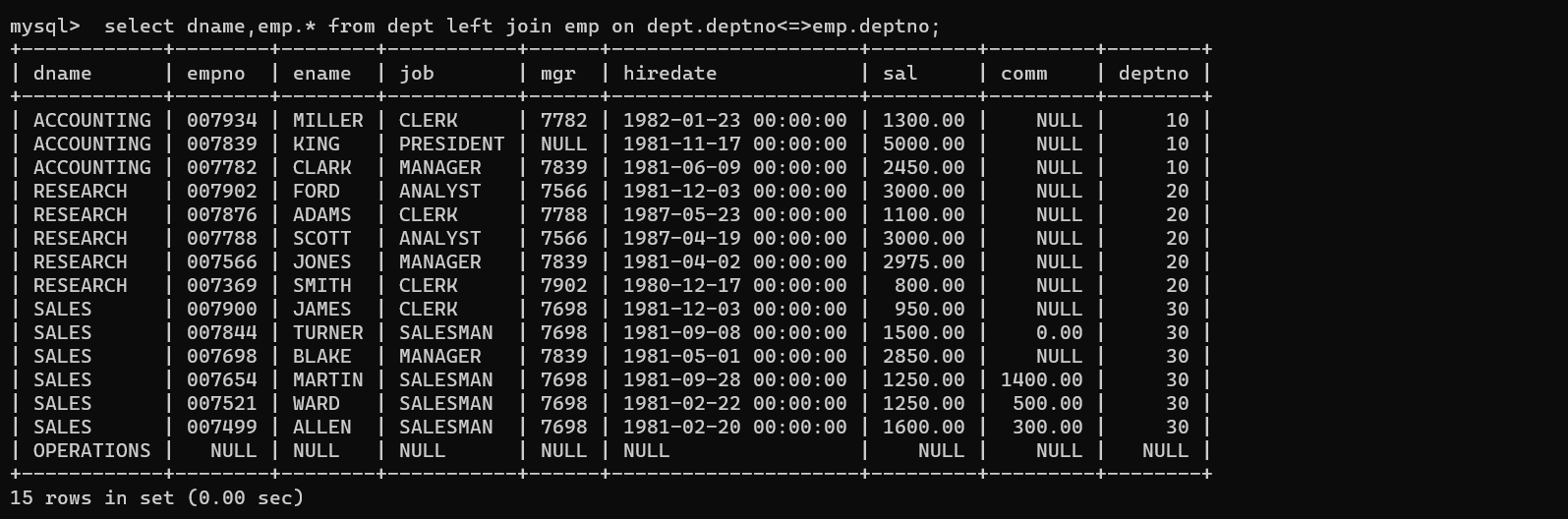
MySQL内外连接
MySQL内外链接 内连接显示SMITH的名字和部门名称 外连接左外连接查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来 右外连接把所有的成绩都显示出来,即使这个成绩没有学生与它对应,也要显示出来列出部门名称…...

sql:SQL优化知识点记录(十四)
(1)索引失效行锁变表锁 建立2个索引 索引是失效后,系统性能会变查,如果涉及到锁的话,行锁会变表锁 有一个问题,当session1用b字段做查询条件因为是varchar类型,需要加双引号,但是没…...

什么是IIFE(Immediately Invoked Function Expression)?它有什么作用?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐IIFE 的基本语法⭐IIFE 的主要作用⭐如何使用 IIFE 来创建私有变量和模块封装⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅…...
(A - D))
Codeforces Round 866 (Div 2)(A - D)
Codeforces Round 866 (Div. 2)(A - D) Dashboard - Codeforces Round 866 (Div. 2) - Codeforces A. Yura’s New Name(思维) 思路:枚举每个下划线 , 计算其前后需要补齐的 ‘^’ 个数 , 注意特判样例四的特殊情况…...
QTday3(QT实现文件对话框保存操作、实现键盘触发事件【WASD控制小球的移动】)
1.实现文件对话框保存操作 #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }void Widget::on_fontBtn_clicked() {//调用QFo…...

WPF基础入门-Class8-资源基础
WPF基础入门 Class8-资源基础 前言:方便各种资源的集中管理和动态效果 静态引用:初始化的时候确定样式,后续不发生改变 动态引用:样式随着引用的内容一起改变 1、新建资源字典.xaml,创建一个边框颜色资源MyBrush和一…...
Axure RP PC电商平台Web端交互原型模板
Axure RP PC电商平台Web端交互原型模板。原型图内容齐全,包含了用户中心、会员中心、优惠券、积分、互动社区、运营推广、内容推荐、商品展示、订单流程、订单管理、售后及服务等完整的电商体系功能架构和业务流程。 在设计尺寸方面,本套模板按照主流的…...

Ubuntu目录和linux内核文件用途
一,目录: 1./:根目录,是整个文件系统的起点 2./bin:binary 二进制可执行文件目录,包含用于系统启动和运行的基本命令 3./boot: 启动加载器目录,包含用于系统启动的内核和引导程序文件。 4./dev: device 设备文件目录&a…...

更快更强更稳定:腾讯向量数据库测评
向量数据库:AI时代的新基座 人工智能在无处不在影响着我们的生活,而人工智能飞速发展的背后是需要对越来越多的海量数据处理,传统数据库已经难以支撑大规模的复杂数据处理。特别是大模型的出现,向量数据库横空出世。NVIDIA CEO黄…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...