Flink面试题
一 基础篇
Flink的执行图有哪几种?分别有什么作用
Flink中的执行图一般是可以分为四类,按照生成顺序分别为:StreamGraph-> JobGraph-> ExecutionGraph->物理执行图。

1)StreamGraph
顾名思义,这里代表的是我们编写的流程序图。通过Stream API生成,这是执行图的最原始拓扑数据结构。

2)JobGraph
StreamGraph在Client中经过算子chain链合并等优化,转换为JobGraph拓扑图,随后被提交到JobManager中。

3)ExecutionGraph
JobManager中将JobGraph进一步转换为ExecutionGraph,此时ExecutuonGraph根据算子配置的并行度转变为并行化的Graph拓扑结构。

4)物理执行图
比较偏物理执行概念,即JobManager进行Job调度,TaskManager最终部署Task的图结构。

Flink的窗口机制
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window,例如:每30秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。
我们举个具体的场景来形象地理解不同窗口的概念。假设,淘宝网会记录每个用户每次购买的商品个数,我们要做的是统计不同窗口中用户购买商品的总数。下图给出了几种经典的窗口切分概述图:
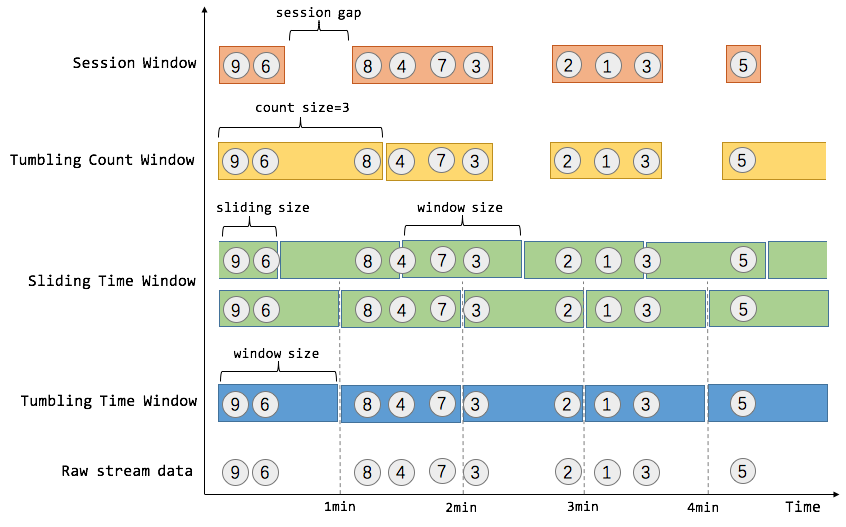
上图中,raw data stream 代表用户的购买行为流,圈中的数字代表该用户本次购买的商品个数,事件是按时间分布的,所以可以看出事件之间是有time gap的。Flink 提供了上图中所有的窗口类型,下面我们会逐一进行介绍。
Time Window
就如名字所说的,Time Window 是根据时间对数据流进行分组的。这里我们涉及到了流处理中的时间问题,时间问题和消息乱序问题是紧密关联的,这是流处理中现存的难题之一,我们将在后续的 EventTime 和消息乱序处理 中对这部分问题进行深入探讨。这里我们只需要知道 Flink 提出了三种时间的概念,分别是event time(事件时间:事件发生时的时间),ingestion time(摄取时间:事件进入流处理系统的时间),processing time(处理时间:消息被计算处理的时间)。Flink 中窗口机制和时间类型是完全解耦的,也就是说当需要改变时间类型时不需要更改窗口逻辑相关的代码。
Tumbling Time Window
如上图,我们需要统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被成为翻滚时间窗口(Tumbling Time Window)。翻滚窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。通过使用 DataStream API,我们可以这样实现:
// Stream of (userId, buyCnt)val buyCnts: DataStream[(Int, Int)] = ...val tumblingCnts: DataStream[(Int, Int)] = buyCnts// key stream by userId.keyBy(0) // tumbling time window of 1 minute length.timeWindow(Time.minutes(1))// compute sum over buyCnt.sum(1) Sliding Time Window
但是对于某些应用,它们需要的窗口是不间断的,需要平滑地进行窗口聚合。比如,我们可以每30秒计算一次最近一分钟用户购买的商品总数。这种窗口我们称为滑动时间窗口(Sliding Time Window)。在滑窗中,一个元素可以对应多个窗口。通过使用 DataStream API,我们可以这样实现:
val slidingCnts: DataStream[(Int, Int)] = buyCnts.keyBy(0) // sliding time window of 1 minute length and 30 secs trigger interval.timeWindow(Time.minutes(1), Time.seconds(30)).sum(1)Count Window
Count Window 是根据元素个数对数据流进行分组的。
Tumbling Count Window
当我们想要每100个用户购买行为事件统计购买总数,那么每当窗口中填满100个元素了,就会对窗口进行计算,这种窗口我们称之为翻滚计数窗口(Tumbling Count Window),上图所示窗口大小为3个。通过使用 DataStream API,我们可以这样实现:
// Stream of (userId, buyCnts)val buyCnts: DataStream[(Int, Int)] = ...val tumblingCnts: DataStream[(Int, Int)] = buyCnts// key stream by sensorId.keyBy(0)// tumbling count window of 100 elements size.countWindow(100)// compute the buyCnt sum .sum(1)Sliding Count Window
当然Count Window 也支持 Sliding Window,虽在上图中未描述出来,但和Sliding Time Window含义是类似的,例如计算每10个元素计算一次最近100个元素的总和,代码示例如下。
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts.keyBy(0)// sliding count window of 100 elements size and 10 elements trigger interval.countWindow(100, 10).sum(1)Session Window
在这种用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃的周期),由非活跃的间隙分隔开。如上图所示,就是需要计算每个用户在活跃期间总共购买的商品数量,如果用户30秒没有活动则视为会话断开(假设raw data stream是单个用户的购买行为流)。Session Window 的示例代码如下:
// Stream of (userId, buyCnts)val buyCnts: DataStream[(Int, Int)] = ...val sessionCnts: DataStream[(Int, Int)] = vehicleCnts.keyBy(0)// session window based on a 30 seconds session gap interval .window(ProcessingTimeSessionWindows.withGap(Time.seconds(30))).sum(1)一般而言,window 是在无限的流上定义了一个有限的元素集合。这个集合可以是基于时间的,元素个数的,时间和个数结合的,会话间隙的,或者是自定义的。Flink 的 DataStream API 提供了简洁的算子来满足常用的窗口操作,同时提供了通用的窗口机制来允许用户自己定义窗口分配逻辑。下面我们会对 Flink 窗口相关的 API 进行剖析。
Flink中的时间概念
Flink在流处理程序支持不同的时间概念。分别为Event Time/Processing Time/Ingestion Time,也就是事件时间、处理时间、提取时间。
从时间序列角度来说,发生的先后顺序是:
事件时间(Event Time)----> 提取时间(Ingestion Time)----> 处理时间(Processing Time)复制
Event Time 是事件在现实世界中发生的时间,它通常由事件中的时间戳描述。
Ingestion Time 是数据进入Apache Flink流处理系统的时间,也就是Flink读取数据源时间。
Processing Time 是数据流入到具体某个算子 (消息被计算处理) 时候相应的系统时间。也就是Flink程序处理该事件时当前系统时间。
但是我们讲解时,会从后往前讲解,把最重要的Event Time放在最后。
处理时间
是数据流入到具体某个算子时候相应的系统时间。
这个系统时间指的是执行相应操作的机器的系统时间。当一个流程序通过处理时间来运行时,所有基于时间的操作(如: 时间窗口)将使用各自操作所在的物理机的系统时间。
ProcessingTime 有最好的性能和最低的延迟。但在分布式计算环境或者异步环境中,ProcessingTime具有不确定性,相同数据流多次运行有可能产生不同的计算结果。因为它容易受到从记录到达系统的速度(例如从消息队列)到记录在系统内的operator之间流动的速度的影响(停电,调度或其他)。
提取时间
IngestionTime是数据进入Apache Flink框架的时间,是在Source Operator中设置的。每个记录将源的当前时间作为时间戳,并且后续基于时间的操作(如时间窗口)引用该时间戳。
提取时间在概念上位于事件时间和处理时间之间。与处理时间相比,它稍早一些。IngestionTime与ProcessingTime相比可以提供更可预测的结果,因为IngestionTime的时间戳比较稳定(在源处只记录一次),所以同一数据在流经不同窗口操作时将使用相同的时间戳,而对于ProcessingTime同一数据在流经不同窗口算子会有不同的处理时间戳。
与事件时间相比,提取时间程序无法处理任何无序事件或后期数据,但程序不必指定如何生成水位线。
在内部,提取时间与事件时间非常相似,但具有自动时间戳分配和自动水位线生成功能。
事件时间
事件时间就是事件在真实世界的发生时间,即每个事件在产生它的设备上发生的时间(当地时间)。比如一个点击事件的时间发生时间,是用户点击操作所在的手机或电脑的时间。
在进入Apache Flink框架之前EventTime通常要嵌入到记录中,并且EventTime也可以从记录中提取出来。在实际的网上购物订单等业务场景中,大多会使用EventTime来进行数据计算。
Flink的watermark
Watermark是Apache Flink为了处理EventTime 窗口计算提出的一种机制,本质上也是一种时间戳。watermark是用于处理乱序事件或延迟数据的,这通常用watermark机制结合window来实现(Watermarks用来触发window窗口计算)。
比如对于late element,我们不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。 可以把Watermark看作是一种告诉Flink一个消息延迟多少的方式。定义了什么时候不再等待更早的数据。
1. 窗口触发条件
上面谈到了对数据乱序问题的处理机制是watermark+window,那么window什么时候该被触发呢?
基于Event Time的事件处理,Flink默认的事件触发条件为:
对于out-of-order及正常的数据而言
watermark的时间戳 > = window endTime
在 [window_start_time,window_end_time] 中有数据存在。
对于late element太多的数据而言
Event Time > watermark的时间戳
WaterMark相当于一个EndLine,一旦Watermarks大于了某个window的end_time,就意味着windows_end_time时间和WaterMark时间相同的窗口开始计算执行了。
就是说,我们根据一定规则,计算出Watermarks,并且设置一些延迟,给迟到的数据一些机会,也就是说正常来讲,对于迟到的数据,我只等你一段时间,再不来就没有机会了。
WaterMark时间可以用Flink系统现实时间,也可以用处理数据所携带的Event time。
使用Flink系统现实时间,在并行和多线程中需要注意的问题较少,因为都是以现实时间为标准。
如果使用处理数据所携带的Event time作为WaterMark时间,需要注意两点:
因为数据到达并不是循序的,注意保存一个当前最大时间戳作为WaterMark时间
并行同步问题
2. WaterMark设定方法
标点水位线(Punctuated Watermark)
标点水位线(Punctuated Watermark)通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件。
在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
定期水位线(Periodic Watermark)
周期性的(允许一定时间间隔或者达到一定的记录条数)产生一个Watermark。水位线提升的时间间隔是由用户设置的,在两次水位线提升时隔内会有一部分消息流入,用户可以根据这部分数据来计算出新的水位线。
在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
举个例子,最简单的水位线算法就是取目前为止最大的事件时间,然而这种方式比较暴力,对乱序事件的容忍程度比较低,容易出现大量迟到事件。
3. 迟到事件
虽说水位线表明着早于它的事件不应该再出现,但是上如上文所讲,接收到水位线以前的的消息是不可避免的,这就是所谓的迟到事件。实际上迟到事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线的预计,导致窗口在它们到达之前已经关闭。
迟到事件出现时窗口已经关闭并产出了计算结果,因此处理的方法有3种:
重新激活已经关闭的窗口并重新计算以修正结果。
将迟到事件收集起来另外处理。
将迟到事件视为错误消息并丢弃。
Flink 默认的处理方式是第3种直接丢弃,其他两种方式分别使用Side Output和Allowed Lateness。
Side Output机制可以将迟到事件单独放入一个数据流分支,这会作为 window 计算结果的副产品,以便用户获取并对其进行特殊处理。
Allowed Lateness机制允许用户设置一个允许的最大迟到时长。Flink 会在窗口关闭后一直保存窗口的状态直至超过允许迟到时长,这期间的迟到事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了 ProcessWindowFunction API 还可能使得每个迟到事件触发一次窗口的全量计算,代价比较大,所以允许迟到时长不宜设得太长,迟到事件也不宜过多,否则应该考虑降低水位线提高的速度或者调整算法。
这里总结机制为:
窗口window 的作用是为了周期性的获取数据。
watermark的作用是防止数据出现乱序(经常),事件时间内获取不到指定的全部数据,而做的一种保险方法。
allowLateNess是将窗口关闭时间再延迟一段时间。
sideOutPut是最后兜底操作,所有过期延迟数据,指定窗口已经彻底关闭了,就会把数据放到侧输出流。
4.例子
假如我们设置10s的时间窗口(window),那么0~10s,10~20s都是一个窗口,以0~10s为例,0为start-time,10为end-time。假如有4个数据的event-time分别是8(A),12.5(B),9(C),13.5(D),我们设置Watermarks为当前所有到达数据event-time的最大值减去延迟值3.5秒
当A到达的时候,Watermarks为max{8}-3.5=8-3.5 = 4.5 < 10,不会触发计算
当B到达的时候,Watermarks为max(12.5,8)-3.5=12.5-3.5 = 9 < 10,不会触发计算
当C到达的时候,Watermarks为max(12.5,8,9)-3.5=12.5-3.5 = 9 < 10,不会触发计算
当D到达的时候,Watermarks为max(13.5,12.5,8,9)-3.5=13.5-3.5 = 10 = 10,触发计算
触发计算的时候,会将A,C(因为他们都小于10)都计算进去,其中C是迟到的。 max这个很关键,就是当前窗口内,所有事件的最大事件。 这里的延迟3.5s是我们假设一个数据到达的时候,比他早3.5s的数据肯定也都到达了,这个是需要根据经验推算。假设加入D到达以后有到达了一个E,event-time=6,但是由于0~10的时间窗口已经开始计算了,所以E就丢了。 从这里上面E的丢失说明,水位线也不是万能的,但是如果根据我们自己的生产经验+侧道输出等方案,可以做到数据不丢失。
Flink分布式快照原理是什么
可靠性是分布式系统实现必须考虑的因素之一。Flink基于Chandy-Lamport分布式快照算法实现了一套可靠的Checkpoint机制,可以保证集群中某些节点出现故障时,能够将整个作业恢复到故障之前某个状态。同时,Checkpoint机制也是Flink实现Exactly-Once语义的基础。
本文将介绍Flink的Checkpoint机制的原理,并从源码层面了解Checkpoint机制是如何实现的(基于Flink 1.10)。
1. 为什么需要Checkpoint
Flink是有状态的流计算处理引擎,每个算子Operator可能都需要记录自己的运行数据,并在接收到新流入的元素后不断更新自己的状态数据。当分布式系统引入状态计算后,为了保证计算结果的正确性(特别是对于流处理系统,不可能每次系统故障后都从头开始计算),就必然要求系统具有容错性。对于Flink来说,Flink作业运行在多个节点上,当出现节点宕机、网络故障等问题,需要一个机制保证节点保存在本地的状态不丢失。流处理中Exactly-Once语义的实现也要求作业从失败恢复后的状态要和失败前的状态一致。
那么怎么保证分布式环境下各节点状态的容错呢?通常这是通过定期对作业状态和数据流进行快照实现的,常见的检查点算法有比如Sync-and-Stop(SNS)算法、Chandy-Lamport(CL)算法。
Flink的Checkpoint机制是基于Chandy-Lamport算法的思想改进而来,引入了Checkpoint Barrier的概念,可以在不停止整个流处理系统的前提下,让每个节点独立建立检查点保存自身快照,并最终达到整个作业全局快照的状态。有了全局快照,当我们遇到故障或者重启的时候就可以直接从快照中恢复,这就是Flink容错的核心。
2. Checkpoint执行流程
Barrier是Flink分布式快照的核心概念之一,称之为屏障或者数据栅栏(可以理解为快照的分界线)。Barrier是一种特殊的内部消息,在进行Checkpoint的时候Flink会在数据流源头处周期性地注入Barrier,这些Barrier会作为数据流的一部分,一起流向下游节点并且不影响正常的数据流。Barrier的作用是将无界数据流从时间上切分成多个窗口,每个窗口对应一系列连续的快照中的一个,每个Barrier都带有一个快照ID,一个Barrier生成之后,在这之前的数据都进入此快照,在这之后的数据则进入下一个快照。
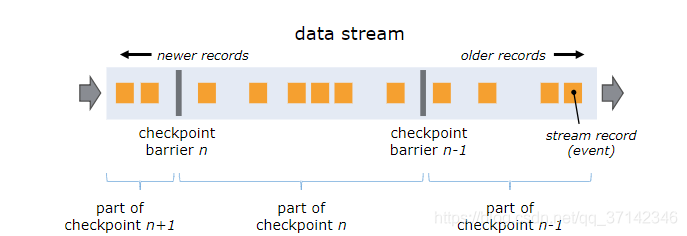
如上图,Barrier-n跟随着数据流一起流动,当算子从输入流接收到Barrier-n后,就会停止接收数据并对当前自身的状态做一次快照,快照完成后再将Barrier-n以广播的形式传给下游节点。一旦作业的Sink算子接收到Barrier n后,会向JobMnager发送一个消息,确认Barrier-n对应的快照完成。当作业中的所有Sink算子都确认后,意味一次全局快照也就完成。
当一个算子有多个上游节点时,会接收到多个Barrier,这时候需要进行Barrier Align对齐操作。

如上图,一个算子有两个输入流,当算子从一个上游数据流接收到一个Barrier-n后,它不会立即向下游广播,而是先暂停对该数据流的处理,将到达的数据先缓存在Input Buffer中(因为这些数据属于下一次快照而不是当前快照,缓存数据可以不阻塞该数据流),直到从另外一个数据流中接收到Barrier-n,才会进行快照处理并将Barrier-n向下游发送。从这个流程可以看出,如果开启Barrier对齐后,算子由于需要等待所有输入节点的Barrier到来出现暂停,对整体的性能也会有一定的影响。
综上,Flink Checkpoint机制的核心思想实质上是通过Barrier来标记触发快照的时间点和对应需要进行快照的数据集,将数据流处理和快照操作解耦开来,从而最大程度降低快照对系统性能的影响。
Flink的一致性和Checkpoint机制有紧密的关系:
当不开启Checkpoint时,节点发生故障时可能会导致数据丢失,这就是At-Most-Once
当开启Checkpoint但不进行Barrier对齐时,对于有多个输入流的节点如果发生故障,会导致有一部分数据可能会被处理多次,这就是At-Least-Once
当开启Checkpoint并进行Barrier对齐时,可以保证每条数据在故障恢复时只会被重放一次,这就是Exactly-Once
相关文章:
Flink面试题
一 基础篇Flink的执行图有哪几种?分别有什么作用Flink中的执行图一般是可以分为四类,按照生成顺序分别为:StreamGraph-> JobGraph-> ExecutionGraph->物理执行图。1)StreamGraph顾名思义,这里代表的是我们编写…...
Python学习笔记
前言:又从仓库翻出来了一些以前总结的文档,以下内容是我初学Python时网上找的或是图书馆借书抄写的笔记,现在再看有点零散不成体系,但是也还是纪念一下子吧。 Python学习笔记 对于初学编程的人来说,Python可以缩短编…...

最适合入门的100个深度学习实战项目
🚨注意🚨:最近经粉丝反馈,发现有些订阅者将此专栏内容进行二次售卖,特在此声明,本专栏内容仅供学习,不得以任何方式进行售卖,未经作者许可不得对本专栏内容行使发表权、署名权、修改…...

AssertionError: 618 columns passed, passed data had 508 columns【已解决】
问题描述 程序中断,报错如下AssertionError: 618 columns passed, passed data had 508 columns Exception has occurred: ValueError 618 columns passed, passed data had 508 columns AssertionError: 618 columns passed, passed data had 508 columnsThe abo…...

166_技巧_Power BI 窗口函数处理连续发生业务问题
166_技巧_Power BI 窗口函数处理连续发生业务问题 一、背景 在生产经营的数据监控中,会有一类指标需要监控是否连续发生,从而根据其在设定区间中的连续频次来评价业务。 例如: 员工连续迟到天数。销售金额连续上升或者下降。用户连续登陆…...

电子科技大学人工智能期末复习笔记(五):机器学习
目录 前言 监督学习 vs 无监督学习 回归 vs 分类 Regression vs Classification 训练集 vs 测试集 vs 验证集 泛化和过拟合 Generalization & Overfitting 线性分类器 Linear Classifiers 激活函数 - 概率决策 ⚠线性回归 决策树 Decision Trees 决策树构建递归…...
使用DDD指导业务设计的总结思考
领域驱动设计(DDD) 是 Eric Evans 提出的一种软件设计方法和思想,主要解决业务系统的设计和建模。DDD 有大量难以理解的概念,尤其是翻译的原因,某些词汇非常生涩,例如:模型、限界上下文、聚合、…...

面试官问:如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。 1、问题分析 首先我们来看看为什么会有这个问题! 我们在日常开发中&am…...

16.数据库Redis
一、基本概念 Redis(Remote Dictionary Server)译为“远程字典服务”,它是一款基于内存实现的键值型 NoSQL 数据库, 通常也被称为数据结构服务器,这是因为它可以存储多种数据类型,比如 string(字…...

【Redis高级-集群分片】
单机安装Redis首先需要安装Redis所需要的依赖:yum install -y gcc tclRedis安装包上传到虚拟机的任意目录:我放到了/tmp目录:解压缩:tar -zxvf /tmp/redis-6.2.4.tar.gz -C /tmp解压后:进入redis目录:cd /t…...

CSDN - CSDN27题解
文章目录幸运数字题目描述解题思路AC代码投篮题目描述解题思路AC代码通货膨胀-x国货币题目描述解题思路AC代码最后一位题目描述解题思路AC代码CSDN编程竞赛报名地址:https://edu.csdn.net/contest/detail/41 这次题目描述刚开始好像有些问题,之后被修正了…...

docker拉取mysql
搜索mysql版本docker search mysql搜索获赞数(星星数量) 大于 1000 的镜像docker search --filterstars1000 mysql搜索官方发布的版本docker search --filter is-officialtrue mysql搜索版本号docker search mysql57拉取docker pull devbeta/mysql57查看下载镜像docker images启…...

在Linux上安装Python3
记录:373场景:在CentOS 7.9操作系统上,安装Python-3.8.9环境。版本:JDK 1.8 Python-3.8.9官网地址:https://www.python.org下载地址:https://www.python.org/ftp/python/1.安装基础依赖1.1安装gcc(1)安装命…...

23 种设计模式的通俗解释,看完秒懂
01 工厂方法 追 MM 少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是 MM 爱吃的东西,虽然口味有所不同,但不管你带 MM 去麦当劳或肯德基,只管向服务员说「来四个鸡翅」就行了。麦当劳和肯德基就是生产鸡翅的 Factory 工厂模式&…...
如何做好需求管理?经验方法、模型、工具
需求管理能力是衡量产品经理能力的一个重要指标。因为需求是产品的基石,只有选取恰当的方法进行需求分析及管理,才能更好的构建产品方案,从而输出精准的产品定义。结合本人学习和自身经验,打算将需求管理分”需求挖掘”、”需求分…...
)
怎么用期货做风险对冲(如何利用期货对冲风险)
不同期货市场的同一期货品种的对冲交易怎么做 不同 期货市场 的同一期货品种的 对冲交易 。 因为地域和 制度环境 不同,同一种期货品种在不同市场的同一时间的价格很可能是不一样的,并且也是在不断变化的。 这样在一个市场做多头买进࿰…...

C++标准模板库type_traits源码剖析
一、type_traits源码介绍 1、type_traits是C11提供的模板元基础库。 2、type_traits可实现在编译期计算。包括添加修饰、萃取、判断查询、类型推导等等功能。 3、type_traits提供了编译期的true和false。 二、type_traits的作用 1、根据不同类型,模板匹配不同版本…...

Python获取公众号(pc客户端)数据,使用Fiddler抓包工具
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 今天来教大家如何使用Fiddler抓包工具,获取公众号(PC客户端)的数据。 Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,…...
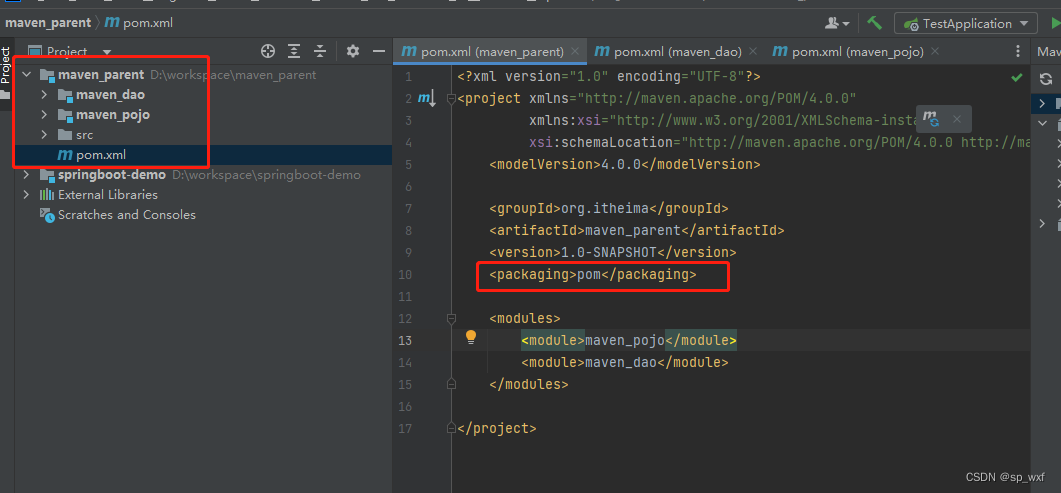
Maven进阶
这里写目录标题1.分模块开发1.1 模块更新后,会造成的影响2.依赖管理2.1 依赖传递2.2 可选依赖(隐藏自己的依赖,不让别人用)2.3 排除依赖(用别人的资源,把不用的去了)3.聚合与继承3.1 为什么要使用聚合工程?3.2 聚合工程开发2.1 聚合工程三级目录1.分模块开发 我们之前做的项目…...
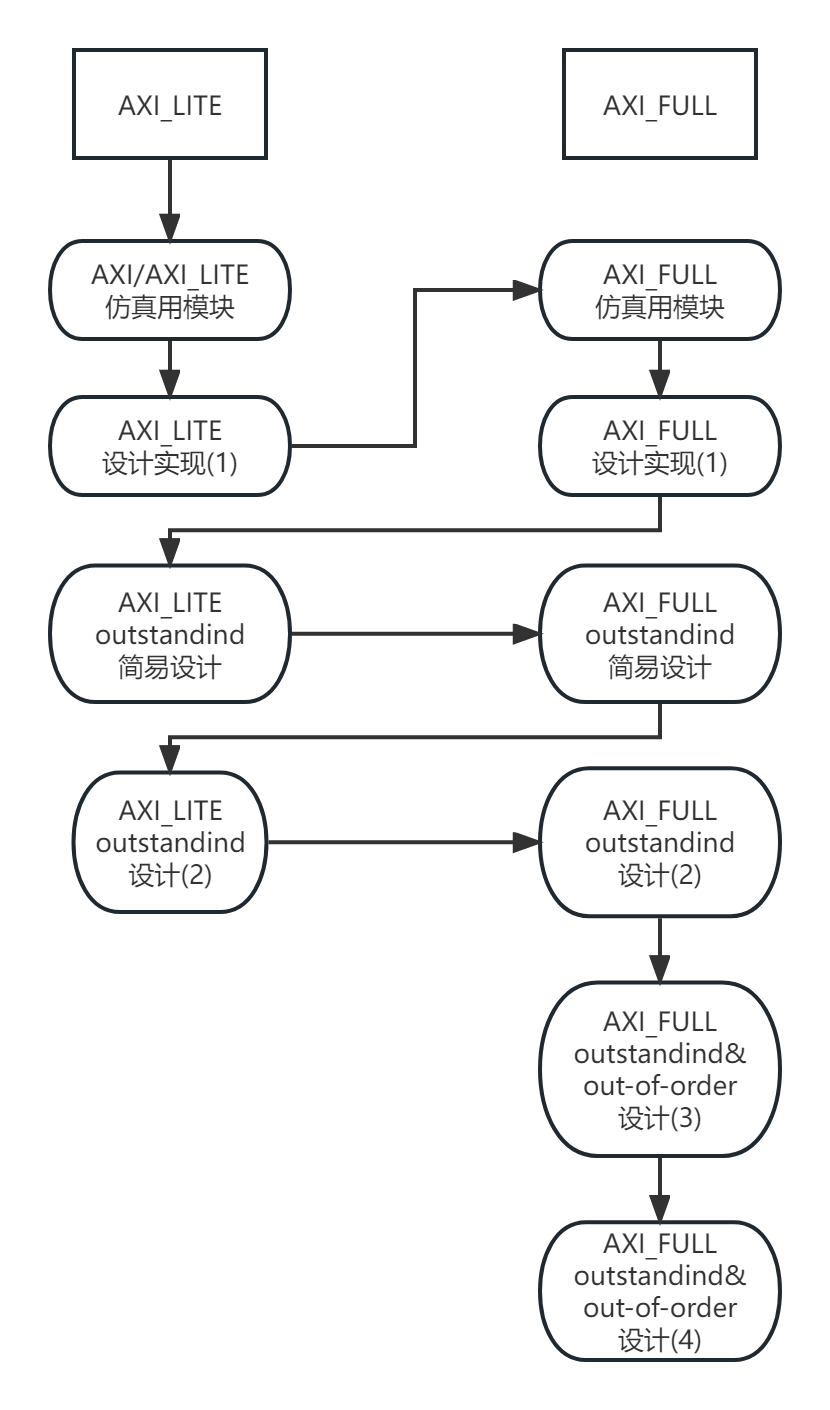
AXI实战(一)-为AXI总线搭建简单的仿真测试环境
AXI实战(一)-搭建简单仿真环境 看完在本文后,你将可能拥有: 一个可以仿真AXI/AXI_Lite总线的完美主端(Master)或从端(Slave)一个使用SystemVerilog仿真模块的船信体验小何的AXI实战系列开更了,以下是初定的大纲安排: 欢迎感兴趣的朋友关注并支持,以下为正文部分 文章目录…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...