Kafka详解
目录
一、消息系统
1、点对点的消息系统
2、发布-订阅消息系统
二、Apache Kafka 简介
三、Apache Kafka基本原理
3.1 分布式和分区(distributed、partitioned)
3.2 副本(replicated )
3.3 整体数据流程
3.4 消息传送机制
四、Apache Kafka 集群架构
五、Apache Kafka核心组件详解
1. producer(生产者)
2. topic(主题)
3. partition(分区)
4. consumer(消费者)
5. consumer group(消费者组)
6. partition replicas(分区副本)
7. segment文件
8. message的物理结构
六、ZooKeeper 的作用
6.1 kafka如何利用zookeeper来进行leader的选举?
6.2 Kafka 在 ZooKeeper 中保存了哪些信息?
6.3 Kafka 客户端如何找到对应的 Broker?
6.4 zookeeper小结
七、Apache Kafka 工作流程
7.1 发布 - 订阅消息的工作流程
7.2 队列消息/用户组的工作流
八、Apache Kafka副本同步机制
8.1 副本同步队列(ISR)
8.2 副本不同步的异常情况
九、kafka消费者组的作用
9.1 共享消息队列模式
缺点:
9.2 发布订阅模式
缺点:
9.3 Kafka 如何桥接这两种模型?
消费群体
重新平衡
用例实现:
结论
Q&A:
Kafka与ZooKeeper关系
Kafka在ZooKeeper中保存元数据信息
Kafka 客户端如何找到对应的 Broker?
消费者组的优势
1. 高性能
2. 消费模式灵活
3. 故障容灾
4. 小结
1. 需求场景分析
2. 物理机数量评估
3. 磁盘选择
4. 内存评估
5. CPU压力评估
6. 网络需求评估
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如 Flume),然后对于收集到的数据如何存储(典型的分布式文件系统 HDFS、分布式数据库 HBase、NoSQL 数据库 Redis),其次存储的数据不是存起来就没事了,要通过计算从中获取有用的信息,这就涉及到计算模型(典型的离线计算 MapReduce、流式实时计算Storm、Spark),或者要从数据中挖掘信息,还需要相应的机器学习算法。在这些之上,还有一些各种各样的查询分析数据的工具(如 Hive、Pig 等)。除此之外,要构建分布式应用还需要一些工具,比如分布式协调服务 Zookeeper 等等。
这里,我们讲到的是消息系统,Kafka 专为分布式高吞吐量系统而设计,其他消息传递系统相比,Kafka 具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
一、消息系统
首先,我们理解一下什么是消息系统:消息系统负责将数据从一个应用程序传输到另外一个应用程序,使得应用程序可以专注于处理逻辑,而不用过多的考虑如何将消息共享出去。
分布式消息系统基于可靠消息队列的方式,消息在应用程序和消息系统之间异步排队。实际上,消息系统有两种消息传递模式:一种是点对点,另外一种是基于发布-订阅(publish-subscribe)的消息系统。
1、点对点的消息系统
在点对点的消息系统中,消息保留在队列中,一个或者多个消费者可以消耗队列中的消息,但是消息最多只能被一个消费者消费,一旦有一个消费者将其消费掉,消息就从该队列中消失。这里要注意:多个消费者可以同时工作,但是最终能拿到该消息的只有其中一个。最典型的例子就是订单处理系统,多个订单处理器可以同时工作,但是对于一个特定的订单,只有其中一个订单处理器可以拿到该订单进行处理。
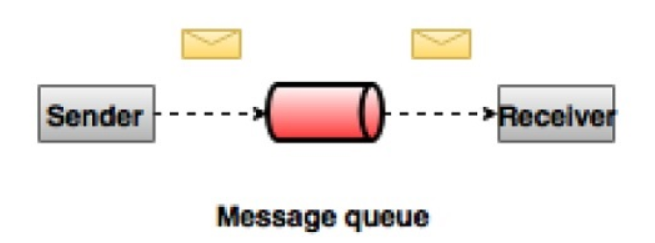
2、发布-订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。

二、Apache Kafka 简介
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
关键术语:
(1)生产者和消费者(producer和consumer):消息的发送者叫 Producer,消息的使用者和接受者是 Consumer,生产者将数据保存到 Kafka 集群中,消费者从中获取消息进行业务的处理。

(2)broker:Kafka 集群中有很多台 Server,其中每一台 Server 都可以存储消息,将每一台 Server 称为一个 kafka 实例,也叫做 broker。
(3)主题(topic):一个 topic 里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
(4)分区(partition):每个 topic 都可以分成多个 partition,每个 partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
(5)偏移量(Offset):一个分区对应一个磁盘上的文件,而消息在文件中的位置就称为 offset(偏移量),offset 为一个 long 型数字,它可以唯一标记一条消息。由于kafka 并没有提供其他额外的索引机制来存储 offset,文件只能顺序的读写,所以在kafka中几乎不允许对消息进行“随机读写”。
综上,我们总结一下 Kafka 的几个要点:
-
kafka 是一个基于发布-订阅的分布式消息系统(消息队列)
-
Kafka 面向大数据,消息保存在主题中,而每个 topic 有分为多个分区
-
kafka 的消息数据保存在磁盘,每个 partition 对应磁盘上的一个文件,消息写入就是简单的文件追加,文件可以在集群内复制备份以防丢失
-
即使消息被消费,kafka 也不会立即删除该消息,可以通过配置使得过一段时间后自动删除以释放磁盘空间
-
kafka依赖分布式协调服务Zookeeper,适合离线/在线信息的消费,与 storm 和 spark 等实时流式数据分析常常结合使用
三、Apache Kafka基本原理
通过之前的介绍,我们对 kafka 有了一个简单的理解,它的设计初衷是建立一个统一的信息收集平台,使其可以做到对信息的实时反馈。Kafka is a distributed,partitioned,replicated commit logservice。接下来我们着重从几个方面分析其基本原理。
3.1 分布式和分区(distributed、partitioned)
我们说 kafka 是一个分布式消息系统,所谓的分布式,实际上我们已经大致了解。消息保存在 Topic 中,而为了能够实现大数据的存储,一个 topic 划分为多个分区,每个分区对应一个文件,可以分别存储到不同的机器上,以实现分布式的集群存储。另外,每个 partition 可以有一定的副本,备份到多台机器上,以提高可用性。
总结起来就是:一个 topic 对应的多个 partition 分散存储到集群中的多个 broker 上,存储方式是一个 partition 对应一个文件,每个 broker 负责存储在自己机器上的 partition 中的消息读写。
3.2 副本(replicated )
kafka 还可以配置 partitions 需要备份的个数(replicas),每个 partition 将会被备份到多台机器上,以提高可用性,备份的数量可以通过配置文件指定。
这种冗余备份的方式在分布式系统中是很常见的,那么既然有副本,就涉及到对同一个文件的多个备份如何进行管理和调度。kafka 采取的方案是:每个 partition 选举一个 server 作为“leader”,由 leader 负责所有对该分区的读写,其他 server 作为 follower 只需要简单的与 leader 同步,保持跟进即可。如果原来的 leader 失效,会重新选举由其他的 follower 来成为新的 leader。
至于如何选取 leader,实际上如果我们了解 ZooKeeper,就会发现其实这正是 Zookeeper 所擅长的,Kafka 使用 ZK 在 Broker 中选出一个 Controller,用于 Partition 分配和 Leader 选举。
另外,这里我们可以看到,实际上作为 leader 的 server 承担了该分区所有的读写请求,因此其压力是比较大的,从整体考虑,有多少个 partition 就意味着会有多少个leader,kafka 会将 leader 分散到不同的 broker 上,确保整体的负载均衡。
3.3 整体数据流程
Kafka 的总体数据流满足下图,该图可以说是概括了整个 kafka 的基本原理。

(1)数据生产过程(Produce)
对于生产者要写入的一条记录,可以指定四个参数:分别是 topic、partition、key 和 value,其中 topic 和 value(要写入的数据)是必须要指定的,而 key 和 partition 是可选的。
对于一条记录,先对其进行序列化,然后按照 Topic 和 Partition,放进对应的发送队列中。如果 Partition 没填,那么情况会是这样的:a、Key 有填。按照 Key 进行哈希,相同 Key 去一个 Partition。b、Key 没填。Round-Robin 来选 Partition。
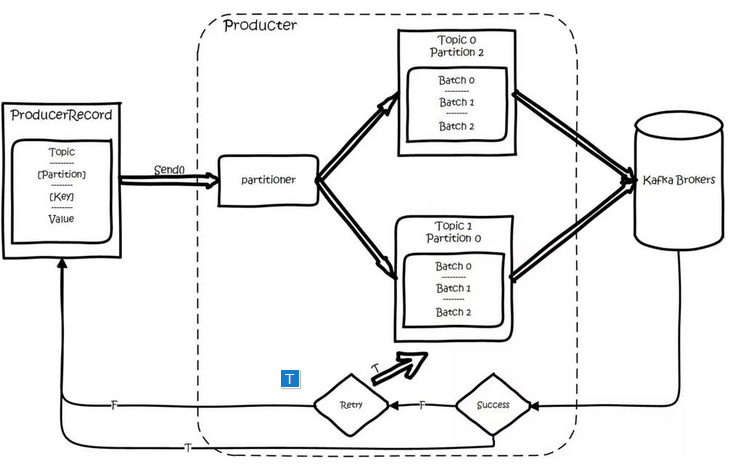
producer 将会和Topic下所有 partition leader 保持 socket 连接,消息由 producer 直接通过 socket 发送到 broker。其中 partition leader 的位置( host : port )注册在 zookeeper 中,producer 作为 zookeeper client,已经注册了 watch 用来监听 partition leader 的变更事件,因此,可以准确的知道谁是当前的 leader。producer client通过broker代理的本地缓存获取到最新的leader broker是哪个,然后找到对应的broker,发送消息。
producer 端采用异步发送:将多条消息暂且在客户端 buffer 起来,并将他们批量的发送到 broker,小数据 IO 太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。
(2)数据消费过程(Consume)
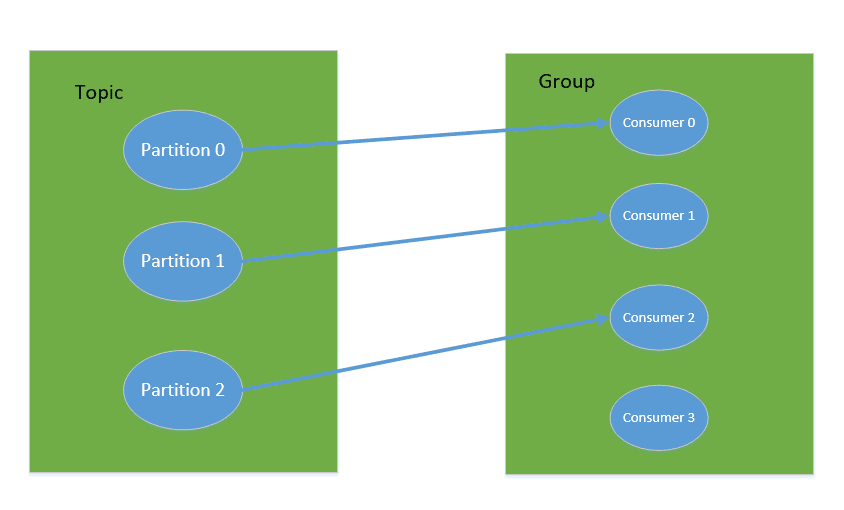
对于消费者,不是以单独的形式存在的,每一个消费者属于一个 consumer group,一个 group 包含多个 consumer。特别需要注意的是:订阅 Topic 是以一个消费组来订阅的,发送到 Topic 的消息,只会被订阅此 Topic 的每个 group 中的一个 consumer 消费。
如果所有的 Consumer 都具有相同的 group,那么就像是一个点对点的消息系统;如果每个 consumer 都具有不同的 group,那么消息会广播给所有的消费者。
具体说来,这实际上是根据 partition 来分的,一个 Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者是关联到一个 partition 的,因此有这样的说法:对于一个 topic,同一个 group 中不能有多于 partitions 个数的 consumer 同时消费,否则将意味着某些 consumer 将无法得到消息。
同一个消费组的两个消费者不会同时消费一个 partition。
在 kafka 中,采用了 pull 方式,即 consumer 在和 broker 建立连接之后,主动去 pull(或者说 fetch )消息,首先 consumer 端可以根据自己的消费能力适时的去 fetch 消息并处理,且可以控制消息消费的进度(offset)。
partition 中的消息只有一个 consumer 在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见 kafka broker 端是相当轻量级的。当消息被 consumer 接收之后,需要保存 Offset 记录消费到哪,以前保存在 ZK 中,由于 ZK 的写性能不好,以前的解决方法都是 Consumer 每隔一分钟上报一次,在 0.10 版本后,Kafka 把这个 Offset 的保存,从 ZK 中剥离,保存在broker的一个名叫 consumeroffsets topic 的 Topic 中,由此可见,consumer 客户端也很轻量级。
3.4 消息传送机制
Kafka 支持 3 种消息投递语义,在业务中,常常都是使用 At least once 的模型。
-
At most once:最多一次,消息可能会丢失,但不会重复。
-
At least once:最少一次,消息不会丢失,可能会重复。
-
Exactly once:只且一次,消息不丢失不重复,只且消费一次。
四、Apache Kafka 集群架构
看看下面的插图。 它显示Kafka的集群图。

下表描述了上图中显示的每个组件。
| 组件 | 说明 |
| Broker(代理) | Kafka集群通常由多个代理组成以保持负载平衡。 Kafka代理是无状态的,所以他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。 Kafka经纪人领导选举可以由ZooKeeper完成。 |
| ZooKeeper | ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后生产者和消费者采取决定并开始与某些其他代理协调他们的任务。 |
| Producers(生产者) | 生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。 |
| Consumers(消费者) | 因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。 |
五、Apache Kafka核心组件详解
1. producer(生产者)
producer主要是用于生产消息,是kafka当中的消息生产者,生产的消息通过topic进行归类,保存到kafka的broker里面去。
2. topic(主题)
kafka将消息以topic为单位进行归类;
topic特指kafka处理的消息源(feeds of messages)的不同分类;
topic是一种分类或者发布的一些列记录的名义上的名字。kafka主题始终是支持多用户订阅的;也就是说,一 个主题可以有零个,一个或者多个消费者订阅写入的数据;
在kafka集群中,可以有无数的主题;
生产者和消费者消费数据一般以主题为单位。更细粒度可以到分区级别。
3. partition(分区)
kafka当中,topic是消息的归类,一个topic可以有多个分区(partition),每个分区保存部分topic的数据,所有的partition当中的数据全部合并起来,就是一个topic当中的所有的数据。
一个broker服务下,可以创建多个分区,broker数与分区数没有关系;
在kafka中,每一个分区会有一个编号:编号从0开始。
每一个分区内的数据是有序的,但全局的数据不能保证是有序的。(有序是指生产什么样顺序,消费时也是什么样的顺序)
4. consumer(消费者)
consumer是kafka当中的消费者,主要用于消费kafka当中的数据,消费者一定是归属于某个消费组中的。
5. consumer group(消费者组)
消费者组由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。
每个消费者都属于某个消费者组,如果不指定,那么所有的消费者都属于默认的组。
每个消费者组都有一个ID,即group ID。组内的所有消费者协调在一起来消费一个订阅主题( topic)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个消费者(consumer)来消费,可以由不同的消费组来消费。
partition数量决定了每个consumer group中并发消费者的最大数量。如下图:

如上面左图所示,如果只有两个分区,即使一个组内的消费者有4个,也会有两个空闲的。
如上面右图所示,有4个分区,每个消费者消费一个分区,并发量达到最大4。
在来看如下一幅图:

如上图所示,不同的消费者组消费同一个topic,这个topic有4个分区,分布在两个节点上。左边的 消费组1有两个消费者,每个消费者就要消费两个分区才能把消息完整的消费完,右边的 消费组2有四个消费者,每个消费者消费一个分区即可。
总结下kafka中分区与消费组的关系:
消费组: 由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。 某一个主题下的分区数,对于消费该主题的同一个消费组下的消费者数量,应该小于等于该主题下的分区数。
如:某一个主题有4个分区,那么消费组中的消费者应该小于等于4,而且最好与分区数成整数倍 1 2 4 这样。同一个分区下的数据,在同一时刻,不能同一个消费组的不同消费者消费。
总结:分区数越多,同一时间可以有越多的消费者来进行消费,消费数据的速度就会越快,提高消费的性能。
6. partition replicas(分区副本)
kafka 中的分区副本如下图所示:

副本数(replication-factor):控制消息保存在几个broker(服务器)上,一般情况下副本数等于broker的个数。
一个broker服务下,不可以创建多个副本因子。创建主题时,副本因子应该小于等于可用的broker数。
副本因子操作以分区为单位的。每个分区都有各自的主副本和从副本;
主副本叫做leader,从副本叫做 follower(在有多个副本的情况下,kafka会为同一个分区下的所有分区,设定角色关系:一个leader和N个 follower),处于同步状态的副本叫做in-sync-replicas(ISR);
follower通过拉的方式从leader同步数据。 消费者和生产者都是从leader读写数据,不与follower交互。
副本因子的作用:让kafka读取数据和写入数据时的可靠性。
副本因子是包含本身,同一个副本因子不能放在同一个broker中。
如果某一个分区有三个副本因子,就算其中一个挂掉,那么只会剩下的两个中,选择一个leader,但不会在其他的broker中,另启动一个副本(因为在另一台启动的话,存在数据传递,只要在机器之间有数据传递,就会长时间占用网络IO,kafka是一个高吞吐量的消息系统,这个情况不允许发生)所以不会在另一个broker中启动。
如果所有的副本都挂了,生产者如果生产数据到指定分区的话,将写入不成功。
lsr表示:当前可用的副本。
7. segment文件
一个partition当中由多个segment文件组成,每个segment文件,包含两部分,一个是 .log 文件,另外一个是 .index 文件,其中 .log 文件包含了我们发送的数据存储,.index 文件,记录的是我们.log文件的数据索引值,以便于我们加快数据的查询速度。
索引文件与数据文件的关系
既然它们是一一对应成对出现,必然有关系。索引文件中元数据指向对应数据文件中message的物理偏移地址。
比如索引文件中 3,497 代表:数据文件中的第三个message,它的偏移地址为497。
再来看数据文件中,Message 368772表示:在全局partiton中是第368772个message。
注:segment index file 采取稀疏索引存储方式,减少索引文件大小,通过mmap(内存映射)可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
.index 与 .log 对应关系如下:

Kafka中采用了稀疏索引的方式读取索引,kafka每当写入了4k大小的日志(.log),就往index里写入一个记录索引。其中会采用二分查找。
上图左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……
那么为什么在index文件中这些编号不是连续的呢?这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。 这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。 但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
value 代表的是在全局partiton中的第几个消息。
以索引文件中元数据 3,497 为例,其中3代表在右边log数据文件中从上到下第3个消息,497表示该消息的物理偏移地址(位置)为497(也表示在全局partiton表示第497个消息-顺序写入特性)。
log日志目录及组成 kafka在我们指定的log.dir目录下,会创建一些文件夹;名字是 (主题名字-分区名) 所组成的文件夹。 在(主题名字-分区名)的目录下,会有两个文件存在,如下所示:
#索引文件
00000000000000000000.index
#日志内容
00000000000000000000.log
在目录下的文件,会根据log日志的大小进行切分,.log文件的大小为1G的时候,就会进行切分文件;如下:
-rw-r--r--. 1 root root 389k 1月 17 18:03 00000000000000000000.index
-rw-r--r--. 1 root root 1.0G 1月 17 18:03 00000000000000000000.log
-rw-r--r--. 1 root root 10M 1月 17 18:03 00000000000000077894.index
-rw-r--r--. 1 root root 127M 1月 17 18:03 00000000000000077894.log
在kafka的设计中,将offset值作为了文件名的一部分。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局 partion的最大offset(偏移message数)。数值最大为64位long大小,20位数字字符长度,没有数字就用 0 填充。
通过索引信息可以快速定位到message。通过index元数据全部映射到内存,可以避免segment File的IO磁盘操作;
通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
稀疏索引:为了数据创建索引,但范围并不是为每一条创建,而是为某一个区间创建;好处:就是可以减少索引值的数量。 不好的地方:找到索引区间之后,要得进行第二次处理。
8. message的物理结构
生产者发送到kafka的每条消息,都被kafka包装成了一个message
message 的物理结构如下图所示:

所以生产者发送给kafka的消息并不是直接存储起来,而是经过kafka的包装,每条消息都是上图这个结构,只有最后一个字段才是真正生产者发送的消息数据。
六、ZooKeeper 的作用
Apache ZooKeeper 它是一个非常特殊的中间件,为什么这么说呢?一般来说,像中间件类的开源产品,大多遵循“做一件事,并做好它。”这样的 UNIX 哲学,每个软件都专注于一种功能上。而 ZooKeeper 更像是一个“瑞士军刀”,它提供了很多基本的操作,能实现什么样的功能更多取决于使用者如何来使用它。
ZooKeeper 作为一个分布式的协调服务框架,主要用来解决分布式集群中,应用系统需要面对的各种通用的一致性问题。ZooKeeper 本身可以部署为一个集群,集群的各个节点之间可以通过选举来产生一个 Leader,选举遵循半数以上的原则,所以一般集群需要部署奇数个节点。
ZooKeeper 最核心的功能是,它提供了一个分布式的存储系统,数据的组织方式类似于 UNIX 文件系统的树形结构。由于这是一个可以保证一致性的存储系统,所以你可以放心地在你的应用集群中读写 ZooKeeper 的数据,而不用担心数据一致性的问题。分布式系统中一些需要整个集群所有节点都访问的元数据,比如集群节点信息、公共配置信息等,特别适合保存在 ZooKeeper 中。
在这个树形的存储结构中,每个节点被称为一个“ZNode”。ZooKeeper 提供了一种特殊的 ZNode 类型:临时节点。这种临时节点有一个特性:如果创建临时节点的客户端与 ZooKeeper 集群失去连接,这个临时节点就会自动消失。在 ZooKeeper 内部,它维护了 ZooKeeper 集群与所有客户端的心跳,通过判断心跳的状态,来确定是否需要删除客户端创建的临时节点。
ZooKeeper 还提供了一种订阅 ZNode 状态变化的通知机制:Watcher,一旦 ZNode 或者它的子节点状态发生了变化,订阅的客户端会立即收到通知。
利用 ZooKeeper 临时节点和 Watcher 机制,我们很容易随时来获取业务集群中每个节点的存活状态,并且可以监控业务集群的节点变化情况,当有节点上下线时,都可以收到来自 ZooKeeper 的通知。
此外,我们还可以用 ZooKeeper 来实现业务集群的快速选举、节点间的简单通信、分布式锁等很多功能。
ZooKeeper 用于存储关于 Kafka 集群的各种元数据:
-
它维护每个分区每个消费者组的最后一个偏移位置,以便消费者可以在发生故障时快速从最后一个位置恢复(尽管现代客户端将偏移存储在单独的 Kafka 主题中)。
-
它跟踪主题、分配给这些主题的分区数量以及领导者/追随者在每个分区中的位置。
-
它还管理集群中不同主题的访问控制列表 (ACL)。ACL 用于强制访问或授权。
下面来看一下 Kafka 是如何来使用 ZooKeeper 的。
6.1 kafka如何利用zookeeper来进行leader的选举?
Kafka的leader选举详细过程如下:
-
当Kafka集群启动时,每个代理节点(Broker)都会实例化一个KafkaController类。
-
第一个启动的代理节点会在Zookeeper系统里面创建一个临时节点/Controller,并写入该节点的注册信息,使其成为控制器。
-
其他代理节点陆续启动时,也会尝试在Zookeeper系统里面创建/controller节点。但由于/controller节点已经存在,所以会抛出创建/controller节点失败的异常信息。
-
创建失败的代理节点会根据返回的结果,判断出在Kafka集群中已经有一个控制器被创建成功了,所以放弃创建/controller节点。
-
其他代理节点会在控制器上注册相应的监听器,监听各自代理节点的状态变化。当监听到节点状态变化时,会触发相应的监听函数进行处理。
-
当某个分区的leader节点宕机时,该分区上的follower节点会感知到leader节点的宕机,并在Zookeeper中重新创建相应的节点。
-
竞争领导者选举过程开始,每个follower节点尝试创建Zookeeper中的相应节点(如/topic/partition/controller),并写入该节点的注册信息。
-
如果多个follower同时创建节点,Zookeeper将只承认第一个成功创建的节点,其他节点会再次尝试创建。
-
第一个成功创建节点的follower将成为新的leader节点。
-
如果ISR集合中没有其他副本,Kafka会从所有副本中选择一个具有最新数据的副本作为新的leader。
-
如果新的leader是旧数据的副本,它会在接管分区之前从其他副本中拉取最新的数据,然后从最新的记录开始提供服务,而不会回滚数据。
如果当Kafka的一个节点(Broker)宕机后,Kafka会经历以下过程:
在Kafka中,如果分区leader节点在同步数据时宕机,但数据尚未同步到所有副本,其中一个是新的,一个是旧的数据,那么在选取新的leader节点时,Kafka会选择具有最新数据的副本作为新的leader。
Kafka的选举机制会优先选择ISR(In-Sync Replica)集合中的副本。ISR是指与leader同步的副本集合,它们的数据同步状态与leader最接近,并且它们与leader副本的网络通信延迟最小。如果ISR集合中没有可用的副本,Kafka会从所有副本中选择一个具有最新数据的副本作为新的leader。
如果新的leader是旧数据的副本,它会在接管分区之前从其他副本中拉取最新的数据。这被称为“从干净状态启动”,意味着该副本从最新的记录开始提供服务,而不会回滚数据。
开发者可以通过调整Kafka配置来控制这种情况下的行为。例如,可以通过设置unclean.leader.election.enable参数来控制是否允许从旧数据副本中选举新的leader。如果设置为true,Kafka将允许从旧数据副本中选举新的leader。如果设置为false,Kafka将只选择最新的数据副本作为新的leader。
6.2 Kafka 在 ZooKeeper 中保存了哪些信息?
首先我们来看一下 Kafka 在 ZooKeeper 都保存了哪些信息,我把这些 ZNode 整理了一张图方便你来学习。

你可能在网上看到过和这个图类似的其他版本的图,这些图中绘制的 ZNode 比我们这张图要多一些,这些图大都是描述的 0.8.x 的旧版本的情况,最新版本的 Kafka 已经将消费位置管理等一些原本依赖 ZooKeeper 实现的功能,替换成了其他的实现方式。
图中圆角的矩形是临时节点,直角矩形是持久化的节点。
我们从左往右来看,左侧这棵树保存的是 Kafka 的 Broker 信息,/brokers/ids/[0…N],每个临时节点对应着一个在线的 Broker,Broker 启动后会创建一个临时节点,代表 Broker 已经加入集群可以提供服务了,节点名称就是 BrokerID,节点内保存了包括 Broker 的地址、版本号、启动时间等等一些 Broker 的基本信息。如果 Broker 宕机或者与 ZooKeeper 集群失联了,这个临时节点也会随之消失。
右侧部分的这棵树保存的就是主题和分区的信息。/brokers/topics/ 节点下面的每个子节点都是一个主题,节点的名称就是主题名称。每个主题节点下面都包含一个固定的 partitions 节点,pattitions 节点的子节点就是主题下的所有分区,节点名称就是分区编号。
每个分区节点下面是一个名为 state 的临时节点,节点中保存着分区当前的 leader 和所有的 ISR 的 BrokerID。这个 state 临时节点是由这个分区当前的 Leader Broker 创建的。如果这个分区的 Leader Broker 宕机了,对应的这个 state 临时节点也会消失,直到新的 Leader 被选举出来,再次创建 state 临时节点。
6.3 Kafka 客户端如何找到对应的 Broker?
那 Kafka 客户端如何找到主题、队列对应的 Broker 呢?其实,通过上面 ZooKeeper 中的数据结构,你应该已经可以猜的八九不离十了。是的,先根据主题和队列,在右边的树中找到分区对应的 state 临时节点,我们刚刚说过,state 节点中保存了这个分区 Leader 的 BrokerID。拿到这个 Leader 的 BrokerID 后,再去左侧的树中,找到 BrokerID 对应的临时节点,就可以获取到 Broker 真正的访问地址了。
Kafka 的客户端并不会去直接连接 ZooKeeper,它只会和 Broker 进行远程通信,那我们可以合理推测一下,ZooKeeper 上的元数据应该是通过 Broker 中转给每个客户端的。
客户端真正与服务端发生网络传输是在 org.apache.kafka.clients.NetworkClient#poll 方法中实现的,我们一直跟踪这个调用链:
NetworkClient#poll() -> DefaultMetadataUpdater#maybeUpdate(long) -> DefaultMetadataUpdater#maybeUpdate(long, Node)
直到 maybeUpdate(long, Node) 这个方法,在这个方法里面,Kafka 构造了一个更新元数据的请求:
private long maybeUpdate(long now, Node node) {String nodeConnectionId = node.idString();if (canSendRequest(nodeConnectionId, now)) {// 构建一个更新元数据的请求的构造器Metadata.MetadataRequestAndVersion metadataRequestAndVersion = metadata.newMetadataRequestAndVersion();inProgressRequestVersion = metadataRequestAndVersion.requestVersion;MetadataRequest.Builder metadataRequest = metadataRequestAndVersion.requestBuilder;log.debug("Sending metadata request {} to node {}", metadataRequest, node);// 发送更新元数据的请求sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);return defaultRequestTimeoutMs;}//...
}
这段代码先构造了更新元数据的请求的构造器,然后调用 sendInternalMetadataRequest() 把这个请求放到待发送的队列中。这里面有两个地方我需要特别说明一下。
第一点是,在这个方法里面创建的并不是一个真正的更新元数据的 MetadataRequest,而是一个用于构造 MetadataRequest 的构造器 MetadataRequest.Builder,等到真正要发送请求之前,Kafka 才会调用 Builder.buid() 方法把这个 MetadataRequest 构建出来然后发送出去。而且,不仅是元数据的请求,所有的请求都是这样来处理的。
第二点是,调用 sendInternalMetadataRequest() 方法时,这个请求也并没有被真正发出去,依然是保存在待发送的队列中,然后择机来异步批量发送。
请求的具体内容封装在 org.apache.kafka.common.requests.MetadataRequest 这个对象中,它包含的信息很简单,只有一个主题的列表,来表明需要获取哪些主题的元数据,另外还有一个布尔类型的字段 allowAutoTopicCreation,表示是否允许自动创建主题。
然后我们再来看下,在 Broker 中,Kafka 是怎么来处理这个更新元数据的请求的。
Broker 处理所有 RPC 请求的入口类在 kafka.server.KafkaApis#handle 这个方法里面,我们找到对应处理更新元数据的方法 handleTopicMetadataRequest(RequestChannel.Request),这段代码是用 Scala 语言编写的:
def handleTopicMetadataRequest(request: RequestChannel.Request) {val metadataRequest = request.body[MetadataRequest]val requestVersion = request.header.apiVersion// 计算需要获取哪些主题的元数据val topics =// 在旧版本的协议中,每次都获取所有主题的元数据if (requestVersion == 0) {if (metadataRequest.topics() == null || metadataRequest.topics.isEmpty)metadataCache.getAllTopics()elsemetadataRequest.topics.asScala.toSet} else {if (metadataRequest.isAllTopics)metadataCache.getAllTopics()elsemetadataRequest.topics.asScala.toSet}// 省略掉鉴权相关代码// ...val topicMetadata =if (authorizedTopics.isEmpty)Seq.empty[MetadataResponse.TopicMetadata]else// 从元数据缓存过滤出相关主题的元数据getTopicMetadata(metadataRequest.allowAutoTopicCreation, authorizedTopics, request.context.listenerName,errorUnavailableEndpoints, errorUnavailableListeners)// ...// 获取所有 Broker 列表val brokers = metadataCache.getAliveBrokerstrace("Sending topic metadata %s and brokers %s for correlation id %d to client %s".format(completeTopicMetadata.mkString(","),brokers.mkString(","), request.header.correlationId, request.header.clientId))// 构建 Response 并发送sendResponseMaybeThrottle(request, requestThrottleMs =>new MetadataResponse(requestThrottleMs,brokers.flatMap(_.getNode(request.context.listenerName)).asJava,clusterId,metadataCache.getControllerId.getOrElse(MetadataResponse.NO_CONTROLLER_ID),completeTopicMetadata.asJava))}
这段代码的主要逻辑是,先根据请求中的主题列表,去本地的元数据缓存 MetadataCache 中过滤出相应主题的元数据,也就是我们上面那张图中,右半部分的那棵树的子集,然后再去本地元数据缓存中获取所有 Broker 的集合,也就是上图中左半部分那棵树,最后把这两部分合在一起,作为响应返回给客户端。
Kafka 在每个 Broker 中都维护了一份和 ZooKeeper 中一样的元数据缓存,并不是每次客户端请求元数据就去读一次 ZooKeeper。由于 ZooKeeper 提供了 Watcher 这种监控机制,Kafka 可以感知到 ZooKeeper 中的元数据变化,从而及时更新 Broker 中的元数据缓存。
这样就完成了一次完整的更新元数据的流程。通过分析代码,可以证实,我们开始的猜测都是没有问题的。
6.4 zookeeper小结
ZooKeeper是一个分布式的协调服务,它的核心服务是一个高可用、高可靠的一致性存储,在此基础上,提供了包括读写元数据、节点监控、选举、节点间通信和分布式锁等很多功能,这些功能可以极大方便我们快速开发一个分布式的集群系统。
但是,ZooKeeper 也并不是完美的,在使用的时候你需要注意几个问题:
-
不要往 ZooKeeper 里面写入大量数据,它不是一个真正意义上的存储系统,只适合存放少量的数据。依据服务器配置的不同,ZooKeeper 在写入超过几百 MB 数据之后,性能和稳定性都会严重下降。
-
不要让业务集群的可用性依赖于 ZooKeeper 的可用性,什么意思呢?你的系统可以使用 Zookeeper,但你要留一手,要考虑如果 Zookeeper 集群宕机了,你的业务集群最好还能提供服务。因为 ZooKeeper 的选举过程是比较慢的,而它对网络的抖动又比较敏感,一旦触发选举,这段时间内的 ZooKeeper 是不能提供任何服务的。
Kafka 主要使用 ZooKeeper 来保存它的元数据、监控 Broker 和分区的存活状态,并利用 ZooKeeper 来进行选举。
Kafka 在 ZooKeeper 中保存的元数据,主要就是 Broker 的列表和主题分区信息两棵树。这份元数据同时也被缓存到每一个 Broker 中。客户端并不直接和 ZooKeeper 来通信,而是在需要的时候,通过 RPC 请求去 Broker 上拉取它关心的主题的元数据,然后保存到客户端的元数据缓存中,以便支撑客户端生产和消费。
可以看到,目前 Kafka 的这种设计,集群的可用性是严重依赖 ZooKeeper 的,也就是说,如果 ZooKeeper 集群不能提供服务,那整个 Kafka 集群也就不能提供服务了,这其实是一个不太好的设计。
如果你需要要部署大规模的 Kafka 集群,建议的方式是,拆分成多个互相独立的小集群部署,每个小集群都使用一组独立的 ZooKeeper 提供服务。这样,每个 ZooKeeper 中存储的数据相对比较少,并且如果某个 ZooKeeper 集群故障,只会影响到一个小的 Kafka 集群,故障的影响面相对小一些。
Kafka 的开发者也意识到了这个问题,目前正在讨论开发一个元数据服务来替代 ZooKeeper,可以看一下他们的Proposal。
且kafka已经在2.8后逐步抛弃zookeeper:
为什么Kafka在2.8版本中会“抛弃”Zookeeper
深度解读:Kafka 放弃 ZooKeeper,消息系统兴起二次革命
七、Apache Kafka 工作流程
到目前为止,我们讨论了 Kafka 的核心概念。 让我们现在来看一下 Kafka 的工作流程。
Kafka 只是分为一个或多个分区的主题的集合。Kafka 分区是消息的线性有序序列,其中每个消息由它们的索引(称为偏移)来标识。Kafka 集群中的所有数据都是不相连的分区联合。 传入消息写在分区的末尾,消息由消费者顺序读取。 通过将消息复制到不同的代理提供持久性。
Kafka 以快速,可靠,持久,容错和零停机的方式提供基于pub-sub 和队列的消息系统。 在这两种情况下,生产者只需将消息发送到主题,消费者可以根据自己的需要选择任何一种类型的消息传递系统。 让我们按照下一节中的步骤来了解消费者如何选择他们选择的消息系统。
7.1 发布 - 订阅消息的工作流程
以下是 Pub-Sub 消息的逐步工作流程 -
-
生产者定期向主题发送消息。
-
Kafka 代理存储为该特定主题配置的分区中的所有消息。 它确保消息在分区之间平等共享。 如果生产者发送两个消息并且有两个分区,Kafka 将在第一分区中存储一个消息,在第二分区中存储第二消息。
-
消费者订阅特定主题。
-
一旦消费者订阅主题,Kafka 将向消费者提供主题的当前偏移,并且还将偏移保存在 Zookeeper 系统中(现在保存在一个叫__consumer_offsets-xx的topic中)。
在kafka的log文件中有很多以 __consumer_offsets_的文件夹;总共50个;
由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka已推荐将consumer的位移信息保存在Kafka内部的topic中,即__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
__consumer_offsets 是 kafka 自行创建的,和普通的 topic 相同。它存在的目的之一就是保存 consumer 提交的位移。 __consumer_offsets 的每条消息格式大致如图所示

在这里插入图片描述
可以想象成一个 KV 格式的消息,key 就是一个三元组:group.id+topic+分区号,而 value 就是 offset 的值。
考虑到一个 kafka 生成环境中可能有很多consumer 和 consumer group,如果这些 consumer 同时提交位移,则必将加重 __consumer_offsets 的写入负载,因此 kafka 默认为该 topic 创建了50个分区,并且对每个 group.id做哈希求模运算Math.abs(groupID.hashCode()) % numPartitions,从而将负载分散到不同的 __consumer_offsets 分区上。
一般情况下,当集群中第一次有消费者消费消息时会自动创建__consumer_offsets,它的副本因子受 offsets.topic.replication.factor 参数的约束,默认值为3(注意:该参数的使用限制在0.11.0.0版本发生变化),分区数可以通过 offsets.topic.num.partitions 参数设置,默认值为50。
-
消费者将定期请求 Kafka (如100 Ms)新消息。
-
一旦 Kafka 收到来自生产者的消息,它将这些消息转发给消费者。
-
消费者将收到消息并进行处理。
-
一旦消息被处理,消费者将向 Kafka 代理发送确认。
-
一旦 Kafka 收到确认,它将偏移更改为新值,并在 Zookeeper 中更新它(现在保存在一个叫__consumer_offsets-xx的topic中)。 由于偏移在 Zookeeper 中维护,消费者可以正确地读取下一封邮件,即使在服务器暴力期间。
-
以上流程将重复,直到消费者停止请求。
-
消费者可以随时回退/跳到所需的主题偏移量,并阅读所有后续消息。
7.2 队列消息/用户组的工作流
在队列消息传递系统而不是单个消费者中,具有相同组 ID 的一组消费者将订阅主题。 简单来说,订阅具有相同 Group ID 的主题的消费者被认为是单个组,并且消息在它们之间共享。 让我们检查这个系统的实际工作流程。
-
生产者以固定间隔向某个主题发送消息。
-
Kafka存储在为该特定主题配置的分区中的所有消息,类似于前面的方案。
-
单个消费者订阅特定主题,假设 Topic-01 为 Group ID 为 Group-1 。
-
Kafka 以与发布 - 订阅消息相同的方式与消费者交互,直到新消费者以相同的组 ID 订阅相同主题Topic-01 1 。
-
一旦新消费者到达,Kafka 将其操作切换到共享模式,并在两个消费者之间共享数据。 此共享将继续,直到用户数达到为该特定主题配置的分区数。
-
一旦消费者的数量超过分区的数量,新消费者将不会接收任何进一步的消息,直到现有消费者取消订阅任何一个消费者。 出现这种情况是因为 Kafka 中的每个消费者将被分配至少一个分区,并且一旦所有分区被分配给现有消费者,新消费者将必须等待。
-
此功能也称为使用者组。 同样,Kafka 将以非常简单和高效的方式提供两个系统中最好的。
八、Apache Kafka副本同步机制
Kafka中主题的每个Partition有一个预写式日志文件,每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中,Partition中的每个消息都有一个连续的序列号叫做offset, 确定它在分区日志中唯一的位置。
Kafka每个topic的partition有N个副本,其中N是topic的复制因子。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个Broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replicas中。其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。
如下图所示,Kafka集群中有4个broker, 某topic有3个partition,且复制因子即副本个数也为3:
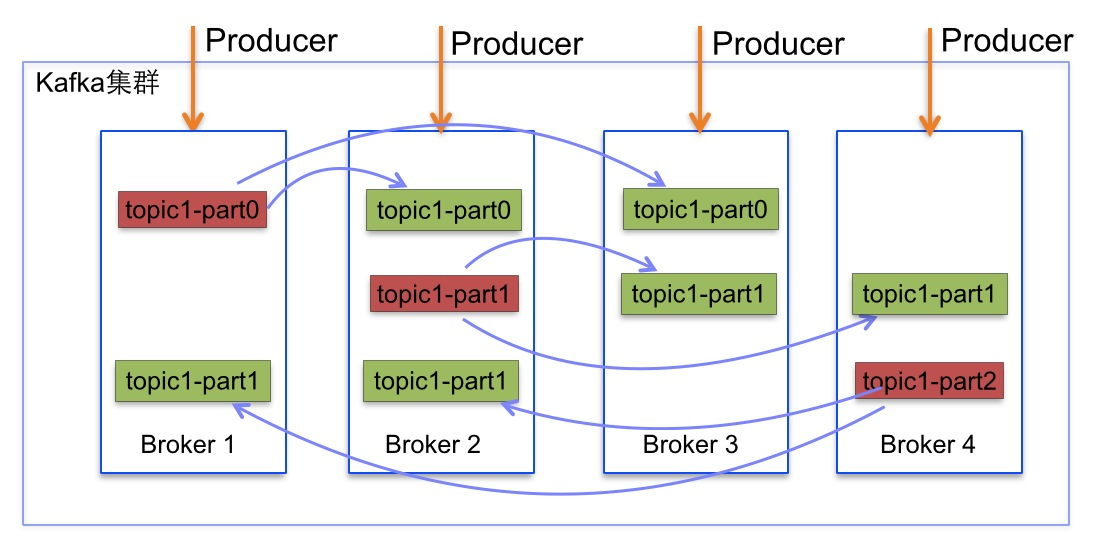
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列,具体可参考下节)中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。
8.1 副本同步队列(ISR)
所谓同步,必须满足如下两个条件:
副本节点必须能与zookeeper保持会话(心跳机制)
副本能复制leader上的所有写操作,并且不能落后太多。(卡住或滞后的副本控制是由 replica.lag.time.max.ms 配置)
默认情况下Kafka对应的topic的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常应用中将其值(由broker的参数offsets.topic.replication.factor指定)大小设置为大于1,比如3。 所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
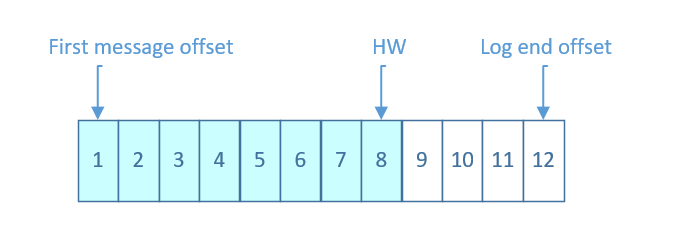
上一节中的HW俗称高水位,是HighWatermark的缩写,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broKer的读取请求,没有HW的限制。
下图详细的说明了当producer生产消息至broker后,ISR以及HW和LEO的流转过程:
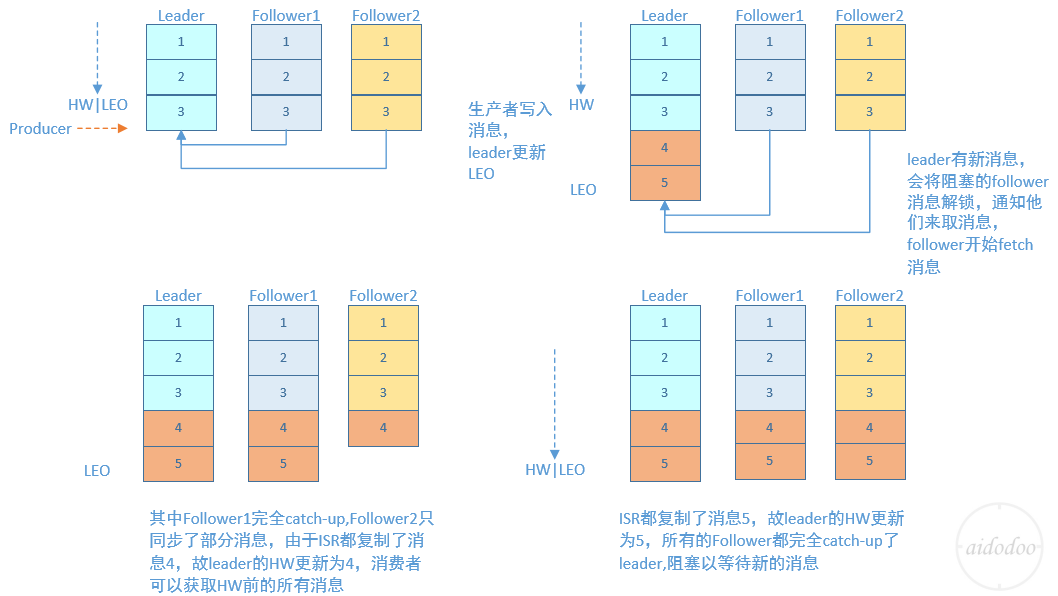
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。目前有两个地方会对这个Zookeeper的节点进行维护:
Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
8.2 副本不同步的异常情况
慢副本:在一定周期时间内follower不能追赶上leader。最常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度。
卡住副本:在一定周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死亡。
新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了leader日志。
由此我们可以得知,kafka是如何保证数据的高可用的。
九、kafka消费者组的作用
关于kafka的消费者组的概念和作用,首先,概念很好理解,就是一些消费者具有共同的group id,比如有5个消费者都订阅了 topicA,则我们可以将5个消费者放到 groupA中并将这个group命名为“groupA”,则此时groupA的消费者组的id就是“groupA”。
那么为啥要有 消费者组这种设定呢?主要原因在于:
首先,传统的消息传递模型分为两类,
原文来自:Scalability of Kafka Messaging using Consumer Groups - Cloudera Blogblog.cloudera.com/scalability-of-kafka-messaging-using-consumer-groups/
9.1 共享消息队列模式

共享消息队列模式允许来自producer的消息流到达单个消费者。推送到队列的每条消息只能读取一次,并且只能由一个consumer读取。consumer从他们之间共享的队列的末尾拉取消息。共享队列然后从成功拉取的队列中删除消息。
缺点:
一旦一个消费者拉取一条消息,这条信息就会从队列中删除。
消息队列更适合命令式编程,其中消息很像对属于同一域的消费者的命令,而不是事件驱动编程,在事件驱动编程中,单个事件可以导致来自消费者端的多个动作.
虽然多个消费者可以连接到共享队列,但他们必须都属于同一个逻辑域并执行相同的功能。因此,共享消息队列中处理的可扩展性受限于单个消费域。
9.2 发布订阅模式

发布订阅模型允许多个生产者将消息发布到代理托管的topic,这些topic可以被多个消费者订阅。因此,一条消息实际上是被广播给一个主题的所有订阅者。
缺点:
发布者与订阅者的逻辑分离允许松耦合的架构,但规模有限。可扩展性是有限的,因为每个消费者者必须订阅每个分区才能访问来自所有分区的消息。因此,虽然传统的 pub-sub 模型适用于小型网络,但不稳定性随着节点的增长而增加。
解耦的副作用还体现在消息传递的不可靠性上。由于每条消息都广播给所有订阅者,因此很难缩放流的处理,因为消费者彼此不同步。
9.3 Kafka 如何桥接这两种模型?
Kafka 则结合了共享消息队列模式和发布-订阅模型的特点。它通过以下方式实现:
-
使用消费者组(consumer grup)
-
broker保留信息(broker指kafka所在的服务器,一台服务器可以运行一个或多个kafka)
当消费者加入一个组并订阅一个主题时,该组中只有一个消费者实际消费了该主题的每条消息。与传统消息队列不同,消息也由代理保留在其主题分区中。
多个消费者组可以从同一组主题中读取,并在不同时间满足不同的逻辑应用程序域。因此,Kafka 通过属于同一消费者组的消费者提供了高可扩展性的优势,以及同时为多个独立的下游应用程序提供服务的能力。
消费群体
消费者组使 Kafka 可以灵活地同时拥有消息队列和发布订阅模型的优势。属于同一个消费者组的 Kafka 消费者共享一个组 ID。然后,组中的消费者通过确定每个分区仅由组中的单个消费者使用来尽可能公平地划分主题分区。

如果所有消费者都来自同一组,那么 Kafka 模型的功能就像传统的消息队列一样。然后对所有记录和处理进行负载平衡 每条消息将仅由该组的一个使用者使用。每个分区最多连接到一个组中的一个消费者。
当存在多个消费群体时,数据消费模型的流程与传统的发布订阅模型一致。消息被广播到所有消费者组。
也有独占消费者,也就是只有一个消费者的消费群体。这样的消费者必须连接到它需要的所有分区。
理想情况下,分区数等于消费者数。如果消费者数量更多,多余的消费者就会闲置,浪费客户端资源。如果分区数量更多,一些消费者将从多个分区读取,这应该不是问题,除非消息的顺序对用例很重要。Kafka 不保证分区之间的消息排序。它确实提供了分区内的排序。因此,如果 Kafka 仅订阅单个分区,则它可以维护消费者的消息排序。还可以使用处理期间要分组的键对消息进行排序。
Kafka 还通过选择发送给代理的形式确认或抵消交付提交来确保它已到达订阅组,从而消除了有关消息交付可靠性的问题。由于分区只能与消费者组中的消费者具有一对一或多对一的关系,因此避免了消费者组内的消息复制,因为给定的消息一次仅到达组中的一个消费者。
重新平衡
随着消费者组的扩展和缩减,运行中的消费者会在自己之间拆分分区。重新平衡是由分区和消费者之间的所有权转移触发的,这可能是由于消费者或经纪人崩溃或添加主题或分区引起的。它允许从系统中安全地添加或删除消费者。
在启动时,代理被标记为消费者组子集的协调器,这些组从消费者接收RegisterConsumer 请求并返回包含他们应该拥有的分区列表的RegisterConsumer 响应。协调器还启动故障检测以检查消费者是活着还是死了。当消费者未能在会话超时之前向协调器代理发送心跳时,协调器将消费者标记为死亡,并设置重新平衡以发生。可以使用Kafka 服务的session.timeout.ms属性设置此会话时间段。该heartbeat.interval.ms属性使健康的消费者认识到再平衡的发生,以便重新发送RegisterConsumer向协调器请求。
例如,假设 A 组的使用者 C2 发生故障,C1 和 C3 将暂时暂停对来自其分区的消息的消耗,并且这些分区将在它们之间重新分配。从之前的示例中,当消费者 C2 丢失时,会触发重新平衡过程,并将分区重新分配给组中的其他消费者。B 组消费者不受 A 组事件的影响。

用例实现:
我们设置了一个 Kafka 主题“推文”的水槽接收器,它分布在两个代理之间。“推文”只有一个分区。
Java 消费者 Consumer0 连接到主题“tweets”和来自控制台的另一个消费者,该消费者与前一个消费者属于同一组 ID。第一个具有组 ID 'group1'。来自控制台的 kafka 消费者的组 ID 为“控制台”。然后我们将两个消费者添加到消费者组“group1”中。因为只有一个partition,所以我们看到组内三个消费者,只有一个消费者,Consumer2继续为组拉取消息。
然后启动 group2 的使用者并连接到相同的主题“推文”。两个消费者以相同的偏移速度阅读。当 group1 中的 Consumer2 关闭时,我们看到经过一段时间后(会话超时)来自第一组的 Consumer1 从最后一个关闭的偏移量 Consumer2 开始。Consumer0 仍然停留在它停止的偏移量处。这表明由于从组中丢失了一个消费者而发生了重新平衡。然而,控制台消费者在消息消费方面不受影响。
在一个主题有多个分区的情况下,我们可以看到,根据启动时分配的分区,属于同一组的许多消费者将处理主题外的消息。保证消息仅在分区内排序,而不是在代理之间排序。当消费者在这种情况下失败时,它正在读取的分区在会话超时启动的重新平衡阶段被重新分配。
结论
共享消息队列允许在单个域中扩展消息处理。发布订阅模型允许向消费者广播消息,但在规模和消息传递方面存在不确定性。Kafka 将消息队列中的处理规模与发布-订阅模型的松散耦合架构结合在一起,通过实现消费者组来实现处理规模、多域支持和消息可靠性。Kafka 中的重新平衡允许消费者在同等程度上保持容错性和可扩展性。
因此,使用 kafka 消费者组来设计流应用程序的消息处理端,可以让用户有效地利用 Kafka 的规模和容错优势。
Q&A:
ZK挂了后kafka还能不能用,ZK存的什么数据?
Kafka与ZooKeeper关系
Zookeeper的作用:
Apache Kafka的一个关键依赖是Apache Zookeeper,它是一个分布式配置和同步服务。 Zookeeper是Kafka代理和消费者之间的协调接口。 Kafka服务器通过Zookeeper集群共享信息。 Kafka在Zookeeper中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在Zookeeper中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper的故障不会影响Kafka集群的状态。 Kafka将恢复状态,一旦Zookeeper重新启动。 这为Kafka带来了零停机时间。 Kafka代理之间的领导者选举也通过使用Zookeeper在领导者失败的情况下完成。
Kafka 主要使用 ZooKeeper 来保存它的元数据、监控 Broker 和分区的存活状态(利用ZooKeeper临时节点以及Watcher机制来监控其集群节点的状态变化),并利用ZooKeeper 来进行选举,保证其高可用性。
Kafka在ZooKeeper中保存元数据信息
其中如图所示 绿色节点为临时节点,其余为持久化节点
左侧树代表着Kafka 的 Broker 信息,/brokers/ids/[0…N],每个临时节点对应着一个在线的 Broker,Broker 启动后会创建一个临时节点,代表Broker 已经加入集群可以提供服务了,节点名称就是 BrokerID,节点内保存了包括Broker 的地址、版本号、启动时间等等一些 Broker 的基本信息。如果 Broker 宕机或者与ZooKeeper 集群失联了,这个临时节点也会随之消失。
右侧部分的这棵树保存的就是主题和分区的信息。/brokers/topics/ 节点下面的每个子节点都是一个主题,节点的名称就是主题名称。每个主题节点下面都包含一个固定的partitions 节点,pattitions 节点的子节点就是主题下的所有分区,节点名称就是分区编号。
每个分区节点下面是一个名为 state 的临时节点,节点中保存着分区当前的 leader 和所有的 ISR 的 BrokerID。这个 state 临时节点是由这个分区当前的 Leader Broker 创建的。如果这个分区的 Leader Broker 宕机了,对应的这个 state 临时节点也会消失,直到新的Leader 被选举出来,再次创建 state 临时节点。
Kafka 客户端如何找到对应的 Broker?
那 Kafka 客户端如何找到主题、队列对应的 Broker 呢?
先根据主题和队列,在右边的树中找到分区对应的 state 临时节点,state 节点中保存了这个分区 Leader 的 BrokerID。拿到这个 Leader 的 BrokerID 后,再去左侧的树中,找到 BrokerID 对应的临时节点,就可以获取到 Broker 真正的访问地址了。
Kafka 在每个 Broker 中都维护了一份和 ZooKeeper 中一样的元数据缓存,并不是每次客户端请求元数据就去读一次 ZooKeeper。由于 ZooKeeper 提供了 Watcher 这种监控机制,Kafka 可以感知到 ZooKeeper 中的元数据变化,从而及时更新 Broker 中的元数据缓存。
即先根据请求中的主题列表,去本地的元数据缓存 MetadataCache 中过滤出相应主题的元数据,也就是我们上面那张图中,右半部分的那棵树的子集,然后再去本地元数据缓存中获取所有 Broker 的集合,也就是上图中左半部分那棵树,最后把这两部分合在一起,作为响应返回给客户端。
所以结论是,如果只有zk挂了,应该不影响kafka的使用。但是如果zk集群和某个kafka leader节点(leader节点承担读写功能)同时不可用了,即触发了leader的选举,因此时zk不可用,会影响kafka的使用
副本做哪些工作,leader承担哪些工作, 副本集是做什么用的
leader承担读写工作,并把数据同步至其他follower节点
partition的replicas副本,只是承担备份的作用,没有读写流量。
所有的副本(replicas)统称为Assigned Replicas,即AR。
ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
只有消费者没有消费组行不行,消费组是用来做什么的
消费者组的优势
1. 高性能
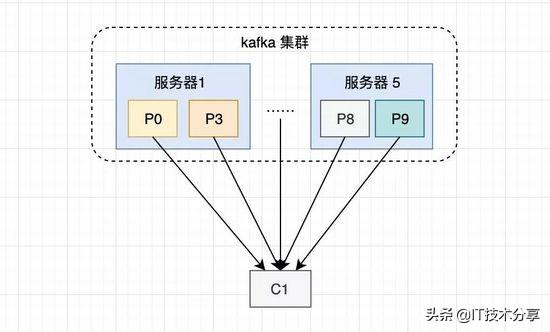
假设一个主题有10个分区,如果没有消费者组,只有一个消费者对这10个分区消费,他的压力肯定大。
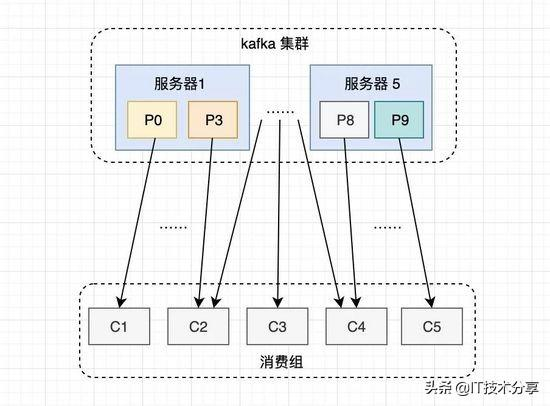
如果有了消费者组,组内的成员就可以分担这10个分区的压力,提高消费性能。
问:那我可以用多个消费者,每个消费者消费一个分区,效果和一个组里的不同消费者消费不同分区是一样的吧,压力不会太大呀?
答:可以用多个消费者,每个消费者消费一个分区。
这样确实可以达到与使用消费者组类似的效果,每个消费者只消费一个分区的数据,可以避免消费者之间的数据冲突和重复消费。同时,由于每个消费者只需要处理一个分区的数据,压力也会相对较小。
然而,这种方式需要手动管理消费者的数量和分区分配,对于大规模的分布式系统而言,可能存在一些挑战和限制。例如,当新增或减少消费者时,需要重新分配分区,可能会导致一些额外的开销和复杂性。
另外,如果使用多个消费者分别消费不同分区的方式,需要注意处理消费者失败的情况。如果某个消费者失败,需要有人工介入来重新分配分区,确保数据能够被正确消费。
相比之下,使用消费者组可以自动处理这些情况,提供更稳定和可靠的数据消费机制。
2. 消费模式灵活
假设有4个消费者订阅一个主题,不同的组合方式就可以形成不同的消费模式。

使用4个消费者组,每组里放一个消费者,利用分区在消费者组间共享的特性,就实现了 广播(发布订阅)模式 。

只使用一个消费者组,把4个消费者都放在一起,利用分区在组内成员间互斥的特性,就实现了单播(队列)模式 。
3. 故障容灾
如果只有一个消费者,出现故障后就比较麻烦了,但有了消费者组之后就方便多了。
消费组会对其成员进行管理,在有消费者加入或者退出后,消费者成员列表发生变化,消费组就会执行再平衡的操作。
例如一个消费者宕机后,之前分配给他的分区会重新分配给其他的消费者,实现消费者的故障容错。
4. 小结
消费者组的好处:
-
消费效率更高
-
消费模式灵活
-
便于故障容灾
我们在kafka的log文件中发现了还有很多以 __consumer_offsets_的文件夹;总共50个;
由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka已推荐将consumer的位移信息保存在Kafka内部的topic中,即__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
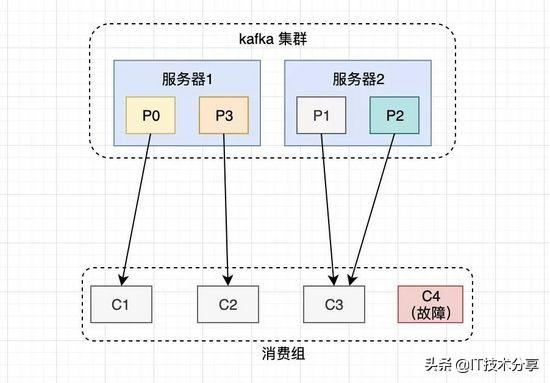
__consumer_offsets 是 kafka 自行创建的,和普通的 topic 相同。它存在的目的之一就是保存 consumer 提交的位移。 __consumer_offsets 的每条消息格式大致如图所示
可以想象成一个 KV 格式的消息,key 就是一个三元组:group.id+topic+分区号,而 value 就是 offset 的值。
考虑到一个 kafka 生成环境中可能有很多consumer 和 consumer group,如果这些 consumer 同时提交位移,则必将加重 __consumer_offsets 的写入负载,因此 kafka 默认为该 topic 创建了50个分区,并且对每个 group.id做哈希求模运算Math.abs(groupID.hashCode()) % numPartitions,从而将负载分散到不同的 __consumer_offsets 分区上。
一般情况下,当集群中第一次有消费者消费消息时会自动创建__consumer_offsets,它的副本因子受 offsets.topic.replication.factor 参数的约束,默认值为3(注意:该参数的使用限制在0.11.0.0版本发生变化),分区数可以通过 offsets.topic.num.partitions 参数设置,默认值为50。
kafka集群对服务器配置的要求
1. 需求场景分析
电商平台,需要每天10亿请求都要发送到Kafka集群上面。二八反正,一般评估出来问题都不大。10亿请求 -> 24 过来的,一般情况下,每天的12:00 到早上8:00 这段时间其实是没有多大的数据量的。80%的请求是用的另外16小时的处理的。16个小时处理 -> 8亿的请求。16 * 0.2 = 3个小时 处理了8亿请求的80%的数据
也就是说6亿的数据是靠3个小时处理完的。我们简单的算一下高峰期时候的qps 6亿/3小时 =5.5万/s qps=5.5万
10亿请求 * 50kb = 46T 每天需要存储46T的数据
一般情况下,我们都会设置两个副本 46T * 2 = 92T Kafka里面的数据是有保留的时间周期,保留最近3天的数据。92T * 3天 = 276T我这儿说的是50kb不是说一条消息就是50kb不是(把日志合并了,多条日志合并在一起),通常情况下,一条消息就几b,也有可能就是几百字节。
2. 物理机数量评估
1)首先分析一下是需要虚拟机还是物理机 像Kafka mysql hadoop这些集群搭建的时候,我们生产里面都是使用物理机。2)高峰期需要处理的请求总的请求每秒5.5万个,其实一两台物理机绝对是可以抗住的。一般情况下,我们评估机器的时候,是按照高峰期的4倍的去评估。如果是4倍的话,大概我们集群的能力要准备到 20万qps。这样子的集群才是比较安全的集群。大概就需要5台物理机。每台承受4万请求。
场景总结:搞定10亿请求,高峰期5.5万的qps,276T的数据,需要5台物理机。
3. 磁盘选择
搞定10亿请求,高峰期5.5万的qps,276T的数据,需要5台物理机。
1)SSD固态硬盘,还是需要普通的机械硬盘,
SSD硬盘:性能比较好,但是价格贵
SATA/SAS盘:某方面性能不是很好,但是比较便宜。SSD硬盘性能比较好,指的是它随机读写的性能比较好。适合MySQL这样集群。**但是其实他的顺序写的性能跟SAS盘差不多。kafka的理解:就是用的顺序写。所以我们就用普通的【机械硬盘】就可以了。
2)需要我们评估每台服务器需要多少块磁盘 5台服务器,一共需要276T ,大约每台服务器 需要存储60T的数据。我们公司里面服务器的配置用的是 11块硬盘,每个硬盘 7T。11 * 7T = 77T
77T * 5 台服务器 = 385T。
场景总结:
搞定10亿请求,需要5台物理机,11(SAS) * 7T
4. 内存评估
搞定10亿请求,需要5台物理机,11(SAS) * 7T
我们发现kafka读写数据的流程 都是基于os cache,换句话说假设咱们的os cashe无限大那么整个kafka是不是相当于就是基于内存去操作,如果是基于内存去操作,性能肯定很好。内存是有限的。1) 尽可能多的内存资源要给 os cache 2) Kafka的代码用 核心的代码用的是scala写的,客户端的代码java写的。都是基于jvm。所以我们还要给一部分的内存给jvm。Kafka的设计,没有把很多数据结构都放在jvm里面。所以我们的这个jvm不需要太大的内存。根据经验,给个10G就可以了。
NameNode: jvm里面还放了元数据(几十G),JVM一定要给得很大。比如给个100G。
假设我们这个10请求的这个项目,一共会有100个topic。100 topic * 5 partition * 2 = 1000 partition 一个partition其实就是物理机上面的一个目录,这个目录下面会有很多个.log的文件。.log就是存储数据文件,默认情况下一个.log文件的大小是1G。我们如果要保证 1000个partition 的最新的.log 文件的数据 如果都在内存里面,这个时候性能就是最好。1000 * 1G = 1000G内存. 我们只需要把当前最新的这个log 保证里面的25%的最新的数据在内存里面。250M * 1000 = 0.25 G* 1000 =250G的内存。
250内存 / 5 = 50G内存 50G+10G = 60G内存
64G的内存,另外的4G,操作系统本生是不是也需要内存。其实Kafka的jvm也可以不用给到10G这么多。评估出来64G是可以的。当然如果能给到128G的内存的服务器,那就最好。
我刚刚评估的时候用的都是一个topic是5个partition,但是如果是数据量比较大的topic,可能会有10个partition。
总结:搞定10亿请求,需要5台物理机,11(SAS) * 7T ,需要64G的内存(128G更好)
5. CPU压力评估
评估一下每台服务器需要多少cpu core(资源很有限)
我们评估需要多少个cpu ,依据就是看我们的服务里面有多少线程去跑。线程就是依托cpu 去运行的。如果我们的线程比较多,但是cpu core比较少,这样的话,我们的机器负载就会很高,性能不就不好。
评估一下,kafka的一台服务器 启动以后会有多少线程?
Acceptor线程 1 processor线程 3 6~9个线程 处理请求线程 8个 32个线程 定时清理的线程,拉取数据的线程,定时检查ISR列表的机制 等等。所以大概一个Kafka的服务启动起来以后,会有一百多个线程。
cpu core = 4个,一遍来说,几十个线程,就肯定把cpu 打满了。cpu core = 8个,应该很轻松的能支持几十个线程。如果我们的线程是100多个,或者差不多200个,那么8 个 cpu core是搞不定的。所以我们这儿建议:CPU core = 16个。如果可以的话,能有32个cpu core 那就最好。
结论:kafka集群,最低也要给16个cpu core,如果能给到32 cpu core那就更好。2cpu * 8 =16 cpu core 4cpu * 8 = 32 cpu core
总结:搞定10亿请求,需要5台物理机,11(SAS) * 7T ,需要64G的内存(128G更好),需要16个cpu core(32个更好)
6. 网络需求评估
评估我们需要什么样网卡?一般要么是千兆的网卡(1G/s),还有的就是万兆的网卡(10G/s)
高峰期的时候 每秒会有5.5万的请求涌入,5.5/5 = 大约是每台服务器会有1万个请求涌入。
我们之前说的,
10000 * 50kb = 488M 也就是每条服务器,每秒要接受488M的数据。数据还要有副本,副本之间的同步
也是走的网络的请求。488 * 2 = 976m/s
说明一下:
很多公司的数据,一个请求里面是没有50kb这么大的,我们公司是因为主机在生产端封装了数据
然后把多条数据合并在一起了,所以我们的一个请求才会有这么大。
说明一下:
一般情况下,网卡的带宽是达不到极限的,如果是千兆的网卡,我们能用的一般就是700M左右。
但是如果最好的情况,我们还是使用万兆的网卡。
如果使用的是万兆的,那就是很轻松。
怎么排查kafka集群的问题,请求(读、写)的流程
参考:
Kafka的协调服务ZooKeeper:实现分布式系统的“瑞士军刀”
关于kafka中的消费者组(consumer group)以及kafka到底用的啥消息传递模式(待续)
真的,搞懂 Kafka 看这一篇就够了!
相关文章:
Kafka详解
目录 一、消息系统 1、点对点的消息系统 2、发布-订阅消息系统 二、Apache Kafka 简介 三、Apache Kafka基本原理 3.1 分布式和分区(distributed、partitioned) 3.2 副本(replicated ) 3.3 整体数据流程 3.4 消息传送机制…...

rabbitmq+springboot实现幂等性操作
文章目录 1.场景描述 1.1 场景11.2 场景2 2.原理3.实战开发 3.1 建表3.2 集成mybatis-plus3.3 集成RabbitMq 3.3.1 安装mq3.3.2 springBoot集成mq 3.4 具体实现 3.4.1 mq配置类3.4.2 生产者3.4.3 消费者 1.场景描述 消息中间件是分布式系统常用的组件,无论是异…...
ubuntu server 更改时区:上海
1. 打开终端,在命令行中以超级用户或具有sudo权限的用户身份运行以下命令: sudo dpkg-reconfigure tzdata 这会打开一个对话框,用于选择系统的时区设置。 2. 在对话框中,使用上下箭头键在地区列表中选择"Asia"&#x…...

java 整合 swagger-ui 步骤
1.在xml 中添加Swagger 相关依赖 <!-- springfox-swagger2 --><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><!-- springfox-swa…...

介绍两款生成神经网络架构示意图的工具:NN-SVG和PlotNeuralNet
对于神经网络架构的可视化是很有意义的,可以在很大程度上帮助到我们清晰直观地了解到整个架构,我们在前面的 PyTorch的ONNX结合MNIST手写数字数据集的应用(.pth和.onnx的转换与onnx运行时) 有介绍,可以将模型架构文件(常见的格式都可以)在线上…...
iOS IdiotAVplayer实现视频分片缓存
文章目录 IdiotAVplayer 实现视频切片缓存一 iOS视频边下边播原理一 分片下载的实现1 分片下载的思路2 IdiotAVplayer 实现架构 三 IdiotAVplayer 代码解析IdiotPlayerIdiotResourceLoaderIdiotDownLoader IdiotAVplayer 实现视频切片缓存 一 iOS视频边下边播原理 初始化AVUR…...

SpringBootWeb请求-响应
HTTP请求 前后端分离 在这种模式下,前端技术人员基于"接口文档",开发前端程序;后端技术人员也基于"接口文档",开发后端程序。 由于前后端分离,对我们后端技术人员来讲,在开发过程中&a…...

List集合详解
目录 1、集合是什么? 1.1、集合与集合之间的关系 2、List集合的特点 3、遍历集合的三种方式 3.1、foreach(增强佛如循环遍历) 3.2、for循环遍历 3.3、迭代器遍历 4、LinkedList和ArrayList的区别 4.1、为什么ArrayList查询会快一些? 4.2、为什么LinkedLi…...
投稿指南【NO.12_8】【极易投中】核心期刊投稿(组合机床与自动化加工技术)
近期有不少同学咨询投稿期刊的问题,大部分院校的研究生都有发学术论文的要求,少部分要求高的甚至需要SCI或者多篇核心期刊论文才可以毕业,但是核心期刊要求论文质量高且审稿周期长,所以本博客梳理一些计算机特别是人工智能相关的期…...

解决git无法上传大文件(50MB)
解决方法 使用LFS解决GitHub无法上传大于50MB的文件 LFS简介 Git LFS(Large File Storage)是 Git 的一个扩展,用于管理大型文件,如二进制文件、图像、音频和视频文件等。它的主要目的是解决 Git 对大型二进制文件的版本控制和存…...
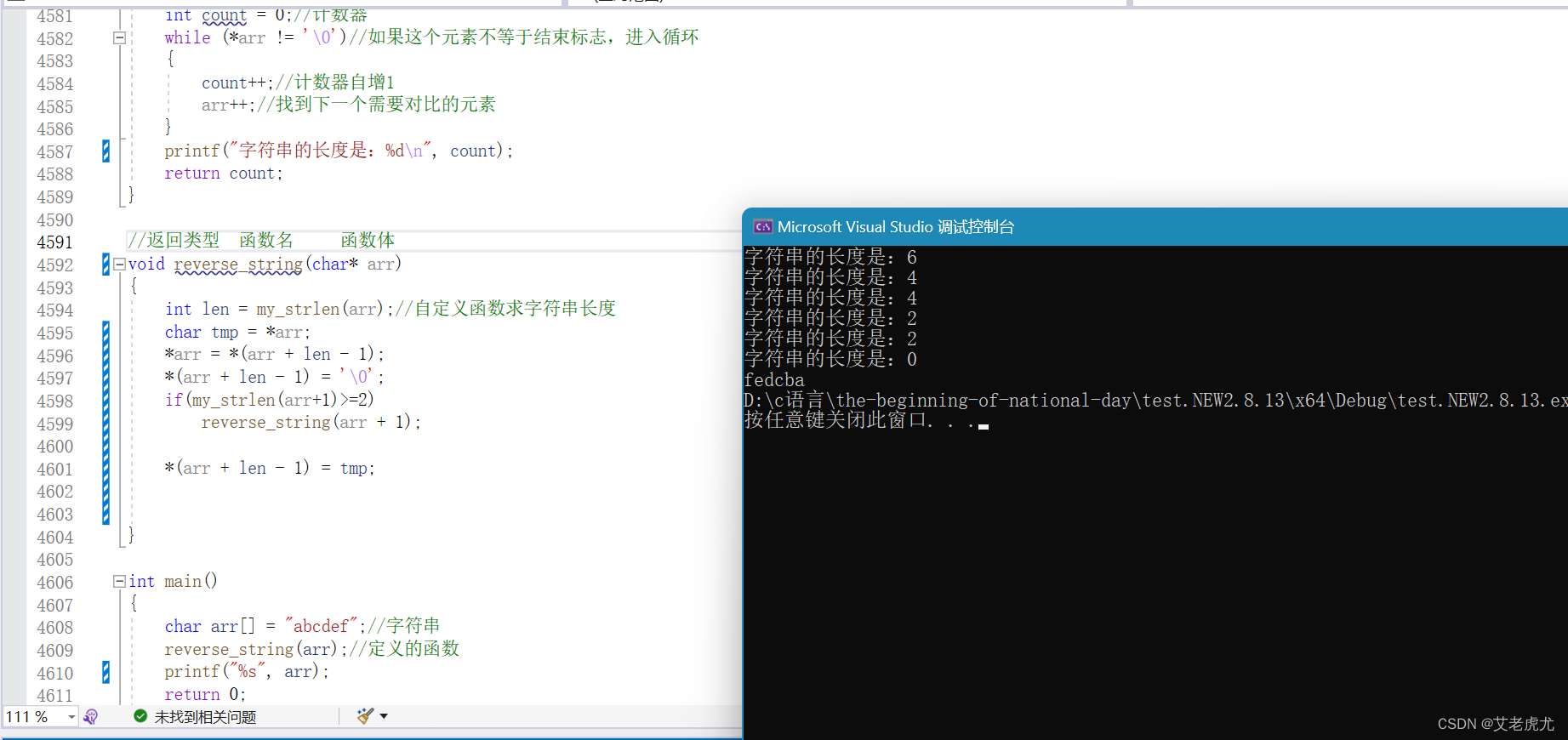
用递归实现字符串逆序(不使用库函数)
文章目录 前言一、题目要求二、解题步骤1.大概框架2.如何反向排列?3.模拟实现strlen4.实现反向排列5.递归实现反向排列 总结 前言 嗨,亲爱的读者们!我是艾老虎尤,今天,我们将探索一个题目,这个题目对新手非…...

初学python(一)
一、python的背景和前景 二、 python的一些小事项 1、在Java、C中,2 / 3 0,也就是整数 / 整数 整数,会把小数部分舍掉。而在python中2 / 3 0.66666.... 不会舍掉小数部分。 在编程语言中,浮点数遵循IEEE754标准,不…...
Excel VSTO开发8 -相关控件
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 8 相关控件 在VSTO开发中,Ribbon(或称为Ribbon UI)是指Office应用程序中的那个位于顶部的带有选…...
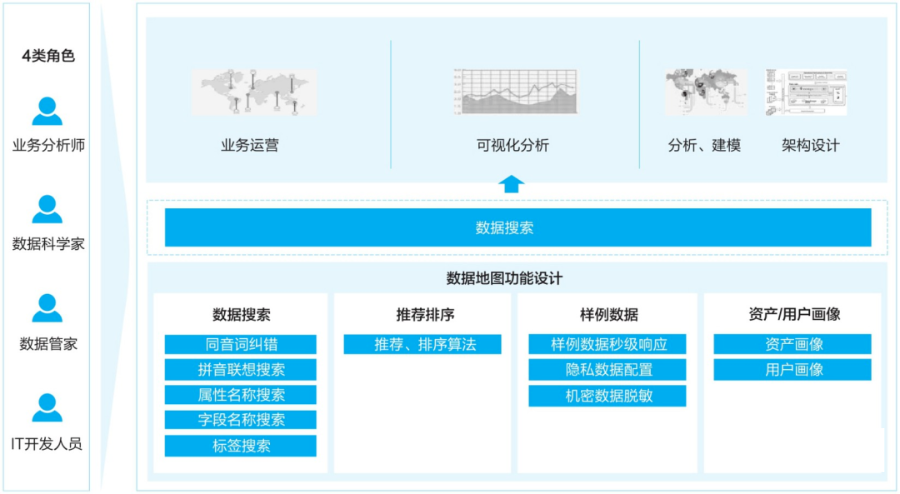
华为数据管理——《华为数据之道》
数据分析与开发 元数据是描述数据的数据,用于打破业务和IT之间的语言障碍,帮助业务更好地理解数据。 元数据是数据中台的重要的基础设施,元数据治理贯彻数据产生、加工、消费的全过程,沉淀了数据资产,搭建了技术和业务…...

Flink CDC 菜鸟教程 -环境篇
本教程将介绍如何使用 Flink CDC 来实现这个需求, 在 Flink SQL CLI 中进行,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE。 系统的整体架构如下图所示: 环境篇 1、 准备一台Linux 2、准备教程所需要的组件 下载 flink-1.13.2 并将其解压至目录 flink-1.13.2 …...
)
【线上问题】linux部署docker应用docker-compose启动报端口占用问题(感觉上没有被占用)
目录 一、问题说明二、排查过程 一、问题说明 1.linux服务器使用的不是root用户权限 2.docker应用服务没有关闭的情况下,做了些重装docker,重启docker等操作 3.docker-compose up -d然后docker logs查看日志报端口被占用 4.netstat -ntpl | grep 端口 也…...
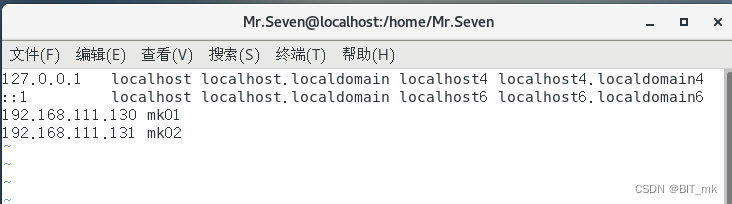
解决虚拟机克隆后IP和命名冲突问题
目录 解决IP冲突问题 解决命名冲突 解决IP冲突问题 克隆后的虚拟机和硬件地址和ip和我们原虚拟机的相同,我们需要重新生成硬件地址和定义ip,步骤如下: (1)进入 /etc/sysconfig/network-scripts/ifcfg-ens33 配置文件…...

分享一个python基于数据可视化的智慧社区服务平台源码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、Node.js、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! …...

[密码学入门]凯撒密码
单表代换 单表:英文26字母的顺序 代换:替换为别的字母并保证解密的唯一性 假如我们让加密方式为所有字母顺序移动3位 import stringstring.ascii_lowercase abcdefghijklmnopqrstuvwxyz b3 加密算法y(xb)mod26 解密算法为x(y-b)mod26 密钥空间26 …...
博客之QQ登录功能(一)
流程图 上图spring social 封装了1-8步需要的工作 1、新建包和书写配置文件 public class QQProperties {//App唯一标 识private String appId "100550231";private String appSecret "69b6ab57b22f3c2fe6a6149274e3295e";//QQ供应商private String…...
)
FPGA实战指南:如何用Stratix 10搭建你的第一个AI加速器(附性能对比)
FPGA实战指南:如何用Stratix 10搭建你的第一个AI加速器(附性能对比) 在AI计算领域,硬件加速器正成为突破性能瓶颈的关键。当GPU的批量处理模式遇到需要低延迟响应的场景时,FPGA凭借其可重构特性和流水线架构展现出独特…...
)
5分钟搞定AI知识库:用Playwright爬取CSDN博客并喂给GPT(附完整配置)
5分钟构建智能知识库:PlaywrightCSDN数据采集实战指南 每次在技术社区搜索解决方案时,你是否也遇到过这样的困扰?收藏的优质文章散落在不同平台,需要时总得反复查找。今天我要分享的这套方案,能让你用开发者熟悉的工具…...

从入门到实战:Python 在网络安全领域的全栈应用指南
Python 在网络安全领域扮演着极其重要的角色——它语法简洁、生态丰富,能快速将想法转化为工具。无论是渗透测试、漏洞研究、安全自动化,还是逆向工程与取证,Python 都是安全从业者的“瑞士军刀”。下面我将从应用领域、常用库、学习路径和实…...

避坑指南:Windows下用llama.cpp部署DeepSeek量化模型遇到的7个典型报错
避坑指南:Windows下用llama.cpp部署DeepSeek量化模型遇到的7个典型报错 在Windows平台上部署量化模型时,开发者常常会遇到各种意想不到的问题。本文将基于真实踩坑经历,详细解析7个典型报错及其解决方案,帮助开发者快速定位并解决…...

零基础玩转Xinference:手把手教你用一行代码切换Qwen、GLM等模型
零基础玩转Xinference:手把手教你用一行代码切换Qwen、GLM等模型 1. 认识Xinference:你的模型切换神器 1.1 什么是Xinference? Xinference(Xorbits Inference)是一个开源平台,它让切换不同AI模型变得像换…...
)
医疗数据分析实战:用T-learner和X-learner评估新药效果(附Python代码)
医疗数据分析实战:用T-learner和X-learner评估新药效果(附Python代码) 在医疗健康领域,评估新药效果是一项复杂而关键的任务。传统的随机对照试验(RCT)虽然被视为金标准,但在实际应用中常常面临…...

Qwen-Image镜像落地实践:RTX4090D驱动的智能客服图文交互模块开发指南
Qwen-Image镜像落地实践:RTX4090D驱动的智能客服图文交互模块开发指南 1. 项目背景与镜像优势 在智能客服系统开发中,图文交互能力正成为提升用户体验的关键。传统方案需要分别部署图像识别和语言理解模块,不仅架构复杂,还面临多…...

用PyAutoGUI实现游戏自动化:从屏幕识图到自动点击的完整实战
用PyAutoGUI实现游戏自动化:从屏幕识图到自动点击的完整实战 游戏自动化一直是开发者们热衷探索的领域,而Python凭借其简洁的语法和丰富的库生态,成为了实现这一目标的理想工具。PyAutoGUI作为Python中最受欢迎的GUI自动化库之一,…...
配置实践与电源管理详解)
【CP AUTOSAR】Pwm(PWMDriver)配置实践与电源管理详解
1. PWM驱动基础与AUTOSAR架构解析 第一次接触AUTOSAR的PWM驱动时,我被各种专业术语搞得晕头转向。后来在实际项目中摸爬滚打才发现,理解PWM在AUTOSAR架构中的定位非常重要。PWM驱动属于MCAL(微控制器抽象层)的组成部分,…...

针对开源开发者的GitHub钓鱼攻击与加密钱包窃取机制研究
摘要 随着开源软件生态系统的日益繁荣,针对开发者群体的定向网络攻击呈现出高度专业化与场景化的趋势。本文以2026年3月爆发的针对OpenClaw项目的GitHub钓鱼攻击为案例,深入剖析了攻击者如何利用社交工程学与代码混淆技术构建的完整攻击链条。研究表明&a…...