数据分析之面试题目汇总
1、解释数据清洗的过程及常见的清洗方法。
数据清洗是指在数据分析过程中对数据进行检查、处理和纠正的过程;是数据预处理的一步,用于处理数据集中的无效、错误、缺失或冗余数据
常见的清洗方法包括:处理缺失值、处理异常值、去除重复值、统一数据格式等。
- 处理缺失值:可以删除包含缺失值的数据行,或使用插值(如均值、中位数或回归模型)进行填充。
- 处理异常值:可以使用统计方法(如3σ原则或箱线图)检测异常值,并选择删除或修正异常值。
- 处理重复值:可以检测和删除数据集中的重复记录。
- 处理格式错误:可以使用字符串处理函数或正则表达式等方法来处理格式不正确的数据。
- 处理不一致的数据:可以进行数据转换或归一化,使数据符合一致的格式和单位。
2、什么是缺失值(Missing Values),如何处理缺失值?
缺失值是指数据集中某些观测值或特征的数据为空缺的情况。
处理缺失值的方法有:删除缺失值、填充缺失值(使用平均值、中位数、众数、插值等方法填充)、使用模型进行缺失值预测填充等。
- 删除缺失值:如果缺失值的比例很小,可以考虑将包含缺失值的数据行删除。
- 填充缺失值:可以使用均值、中位数、众数等统计量来填充数值型特征的缺失值;对于分类特征,可以使用出现频率最高的类别进行填充;对于时间序列数据,可以使用前后数值的插值进行填充。
- 预测填充:可以使用机器学习算法(如随机森林、KNN等)预测缺失值进行填充。
3、解释一下数据归一化和标准化
数据归一化和标准化都是将数据转换到一定的范围或分布上的方法。
- 数据归一化(Normalization)通常将数据缩放到0到1的范围内。最常见的归一化方法是使用最小-最大缩放(Min-Max Scaling),公式为:(x - min) / (max - min),其中x为原始值,min为最小值,max为最大值。
- 数据标准化(Standardization)将数据转换为均值为0,标准差为1的标准正态分布。标准化可以通过减去均值、除以标准差来实现。标准化后的数据具有零均值和单位方差,更适合某些机器学习算法的使用。
4、什么是异常值(Outliers),如何检测和处理异常值?
异常值是指与其他观测值明显不同的异常数据点。
异常值可以通过统计方法(如箱线图、Z-score、3σ原则等)和机器学习算法(如孤立森林、LOF算法等)来检测。处理异常值的方法包括删除异常值、替换为特定的值或进行修正等。
- 统计方法:如基于均值和标准差的Z-score方法,将与均值相距较远的数据视为异常值。
- 箱线图:根据数据的分位数范围判断异常值,超出上下界的数据被认为是异常值。
- 机器学习方法:如孤立森林、LOF(局部离群因子)算法等,基于数据的密度和距离来检测异常值。
处理异常值的方法包括删除异常值、替换为特定的值(如均值或中位数)或使用插值方法进行修正。
5、你使用过哪些数据可视化工具和技术?
包括但不仅限于:
- 数据可视化工具:Tableau、Power BI、matplotlib、ggplot等。
- 编程语言:Python、R、JavaScript等。
- 可视化技术:折线图、柱状图、散点图、饼图、热力图、地图可视化等。
6、什么是关联规则(Association Rules)分析?如何使用它来发现数据中的关联关系?
关联规则(Association Rules)分析是一种用于发现数据中的关联关系的技术。它可以通过挖掘数据集中的频繁项集和关关联规则包含两个部分:前项(Antecedent)和后项(Consequent),它们之间用箭头表示。规则的形式通常是“前项 -> 后项”,表示前项的出现与后项的出现有一定的关联。
关联规则发现的过程包括以下步骤:
- 扫描数据集,统计每个项的出现频率,找出频繁项集。
- 根据频繁项集生成关联规则,计算规则的支持度和置信度。
- 根据支持度和置信度设定阈值,筛选出高置信度的关联规则。
关联规则的支持度(Support)表示在数据集中同时包含前项和后项的概率,置信度(Confidence)表示在出现了前项的情况下,同时出现后项的概率。
关联规则分析可以应用于许多领域,例如:
- 零售业:可以发现购物篮中的关联商品,进行交叉销售和商品搭配的推荐。
- 金融领域:可以发现不同金融产品之间的关联关系,进行个性化的理财建议。
- 营销领域:可以发现用户行为和用户属性之间的关联关系,优化营销策略。
7、解释一下线性回归(Linear Regression)和逻辑回归(Logistic Regression)的原理。
线性回归(Linear Regression)是一种用于建立连续型目标变量与自变量之间线性关系的回归分析方法。它基于最小二乘法来拟合一个线性模型,通过求解模型参数来建立线性回归方程。
逻辑回归(Logistic Regression)是一种用于建立分类模型的回归分析方法。它虽然名字中带有“回归”,但实际上是一种分类算法,用于预测二分类或多分类的概率。逻辑回归使用逻辑函数(sigmoid函数)来将线性模型的输出映射到0到1之间,表示概率值。
8、如何评估机器学习模型的性能?列举几个常见的评估指标。
评估机器学习模型的性能是判断模型好坏的重要指标。常见的评估指标包括:
分类问题:
- 准确率(Accuracy):分类正确的样本占总样本的比例。
- 精确率(Precision):真正例占所有预测为正例的样本的比例。
- 召回率(Recall):真正例占所有真正例的样本的比例。
- F1分数(F1 Score):精确率和召回率的调和平均值,综合考虑了分类器的准确性和召回率。
回归问题:
- 均方误差(Mean Squared Error,MSE):观测值与预测值之差的平方的均值。
- 均方根误差(Root Mean Squared Error,RMSE):MSE的平方根。
- 平均绝对误差(Mean Absolute Error,MAE):观测值与预测值之差的绝对值的均值。
8、什么是过拟合(Overfitting)和欠拟合(Underfitting),如何解决这些问题?
- 过拟合(Overfitting)指的是模型在训练数据上表现很好,但在未见过的数据上表现较差。
- 欠拟合(Underfitting)则指在训练数据和测试数据上模型的表现都较差。**
解决过拟合问题的方法包括:
- 增加训练数据量。
- 减少模型复杂度,如减少特征数量或降低模型的层数。
- 使用正则化技术,如L1正则化和L2正则化,限制模型参数的大小。
- 使用交叉验证来选择合适的模型参数。
- 使用集成学习方法,如随机森林和梯度提升树,减少模型的方差。
解决欠拟合问题的方法包括:
- 增加模型复杂度,如增加特征数量或增加模型的层数。
- 使用更复杂的模型,如深度神经网络。
- 调整模型的超参数,如学习率、正则化参数等。
- 增加训练数据量。
在选择模型时,需要根据具体问题的特点和数据集的情况来选择合适的模型。常见的机器学习模型包括线性回归、逻辑回归、决策树、支持向量机、随机森林、梯度提升树等。
9、特征选择时要考虑哪些方面的内容。
在选择特征时,可以考虑以下几个方面:
- 目标变量的相关性:选择与目标变量相关性较高的特征。
- 特征之间的相关性:避免选择高度相关的特征,以减少冗余信息。
- 特征的可解释性:选择具有实际意义和可解释性的特征。
- 特征的稳定性:选择在不同数据集上表现稳定的特征。
特征选择的方法包括:
- 相关性分析:计算特征与目标变量之间的相关系数或互信息,选择相关性较高的特征。
- 方差分析:计算特征的方差,选择方差较大的特征。
- 嵌入式方法:在模型训练过程中自动选择特征,如L1正则化、决策树的特征重要性等。
- 递归特征消除:通过递归地训练模型并剔除最不重要的特征来选择特征。
10、解释一下数据抽样的方法和应用场景。
数据抽样是从一个大的数据集中选择一个子集作为代表性样本的过程。
常见的数据抽样方法包括简单随机抽样、分层抽样、系统抽样和群集抽样等。
简单随机抽样(Simple Random Sampling):从总体中随机选择样本,每个样本被选择的概率相等,确保样本的代表性。
分层抽样(Stratified Sampling):将总体划分为若干个相互独立的层,然后从每个层中进行简单随机抽样,以保证每个层的特征都得到充分的反映。
系统抽样(Systematic Sampling):从总体中选择一个起始点,然后每隔一定的间隔选择一个样本,例如选择第k个样本,直到达到预定的样本数量。
群集抽样(Cluster Sampling):将总体划分为若干个群集,然后随机选择若干群集作为样本,对所选群集中的所有个体进行观察。
数据抽样可应用于以下场景:
- 当数据集过大,无法一次处理时,可以抽取一个代表性样本来进行分析。
- 当数据采集成本较高时,可以通过抽样降低数据采集的成本。
- 当需要进行数据预处理、模型训练和验证时,可以使用抽样来加快计算速度。
- 在推荐系统中,通过用户抽样来评估推荐算法的效果。
11、如何处理大规模数据集?列举一些常见的大数据处理工具或技术。
处理大规模数据集时,可以采用以下常见的大数据处理工具或技术:
- Apache Hadoop:提供分布式存储和计算的框架,适用于处理大规模结构化和非结构化数据。
- Apache Spark:基于内存的分布式计算框架,提供高性能和可扩展性,适用于数据分析和机器学习。
- Apache Kafka:用于高吞吐量的实时数据流处理和消息传输的分布式流平台。
- HBase:分布式的、高可扩展性的NoSQL数据库,适用于实时读写大规模数据。
- Amazon S3:亚马逊提供的对象存储服务,适用于大规模数据的持久性存储和访问。
12、解释一下数据仓库(Data Warehouse)和数据湖(Data Lake)的区别。
数据仓库(Data Warehouse)和数据湖(Data Lake)是两种不同的数据存储架构和管理模式:
- 数据仓库是一个集中的、经过处理和清洗的数据存储区域,用于支持业务决策和报表生成。数据仓库通常采用结构化的、预定义的模式来存储数据,并通过ETL(抽取、转换和加载)过程将数据从源系统抽取到仓库中。
- 数据湖是一种存储原始、未经处理的海量数据的架构,它接受任何类型和格式的数据,并保留数据的原始形态。数据湖的数据通常以原始的、未加工的状态存储,不依赖于预定义的模式。数据湖可以支持更灵活和实时的数据分析和挖掘,适用于数据科学和探索性分析。
主要体现在以下几个方面
- 数据结构和模式:数据仓库通常采用预定义的模式和结构来组织数据,数据湖则可以接收任意格式和结构的数据,不要求预定义模式。
- 数据处理方式:数据仓库经过ETL(抽取、转换、加载)和清洗等过程后,数据被处理为可分析的形式。数据湖保留原始的数据形态,可以在需要时进行处理和转换。
- 数据可用性和灵活性:数据仓库通常具有高度整合和预处理的特点,提供了高度可用和一致的数据。数据湖则着重于原始数据的积累和数据的灵活使用,能够快速适应不同的分析需求。
- 数据访问和权限控制:数据仓库通常有严格的访问和权限控制,通过用户名和密码等来限制访问权限。数据湖较灵活,可以设置不同的访问层次和权限控制。
- 数据使用目的:数据仓库通常用于支持业务决策和报表生成,提供预定义的分析模型和指标。数据湖提供了更广泛的数据探索和数据科学应用的可能性。
13、如何进行 A/B 测试?解释一下它的原理和流程。
A/B测试是一种通过比较两个或多个版本的实验来评估策略、功能或设计的效果的方法。其原理和流程如下:
原理:A/B测试基于假设,将用户分成多个群体,每个群体被随机分配到不同的实验条件(如A组和B组),然后比较不同组之间的表现差异,从而判断是否存在显著效果
流程
- 目标设定:明确要评估的指标、设定实验的目标。
- 选择变量:选择需要测试的变量,例如页面布局、按钮颜色等。
- 划分用户群体:将用户随机分为两个(或多个)群体,A组和B组,使得每个群体具有相似的特征。
- 设计实验:针对A组和B组设计不同的实验条件,例如对A组采用原来的设计,对B组采用新的设计。
- 实施实验:将实验条件应用到相应的群体中,并记录结果数据。
- 分析结果:分析两个群体的结果数据,比较各组的指标(如转化率、点击率等)是否存在显著差异。
- 得出结论:根据结果数据,判断新设计是否对指标有积极影响,决定是否采用新设计。
14、什么是时间序列分析(Time Series Analysis)?列举一些常见的时间序列预测方法。
时间序列分析是一种统计方法,用于分析随时间变化的数据。它关注数据的时间顺序和相关模式,用于预测未来的数值。常见的时间序列预测方法包括:
- 移动平均法:根据过去一段时间窗口内的平均值进行预测。
- 指数平滑法:基于历史数据的平滑指数加权平均进行预测。
- ARIMA模型:自回归移动平均模型,用于建立时间序列数据的线性关系模型。
- 季节性分解法:将时间序列数据分解为趋势、季节性和随机成分,通过对这些成分建模进行预测。
- LSTM:长短期记忆网络,一种适用于时间序列预测的深度学习模型。
15、解释一下主成分分析(Principal Component Analysis,PCA)的原理和应用。
主成分分析(PCA)是一种常用的降维技术,用于将高维数据转换为低维空间。
原理是通过线性变换将原始特征投影到新的特征空间,使得投影后的变量之间没有相关性,从而最大程度地保留原始数据的方差。主成分是新特征空间的线性组合,按照方差递减的顺序排序。
PCA的应用包括:
- 数据压缩:通过PCA将高维数据转换为低维表示,可以减少存储和计算的成本。
- 数据可视化:通过PCA将高维数据可视化在二维或三维空间中,帮助直观理解数据的分布和结构。
- 特征选择:通过PCA确定最重要的主成分,对数据特征进行选择和排名。
- 噪声过滤:通过PCA过滤掉数据中的噪声和冗余信息,提高数据质量和模型性能。
- 特征提取:通过PCA提取出的主成分,可以用于训练机器学习模型或进行其他分析任务,减少输入特征的数量。
16、什么是Z-score及要注意的事项。
Z-score(Z值)是统计学中用于度量某个数值与其所在数据集平均值之间的偏离程度的标准化分数。它表示一个数值与平均值之间的差异,以标准差为单位进行度量。
计算Z-score的公式为: Z = (X - μ) / σ
其中:
- Z是Z-score值;
- X是要计算Z-score的数值;
- μ是数据集的平均值(均值);
- σ是数据集的标准差。
Z-score通过将原始数据转换为与平均值之间的差异,以标准差为度量单位来进行比较和分析。
Z-score的值可以表示一个数值相对于整个数据分布的位置和偏离程度:
- 当Z-score为0时,表示该数值与平均值相等;
- 当Z-score为正值时,表示该数值大于平均值;
- 当Z-score为负值时,表示该数值小于平均值。
Z-score常用于统计分析和异常值检测。通过计算Z-score,可以对数据进行标准化,使得不同数据集之间可以进行比较和综合分析。在异常值检测中,可以使用Z-score来判断某个数值与平均值之间的偏离程度,从而标识是否存在异常值。
- 需要注意的是,Z-score的计算基于数据的正态分布假设。如果数据不满足正态分布,Z-score的应用可能会受到限制。
- 此外,Z-score的值越大(绝对值越大),表示数值与平均值的偏离程度越大。一般来说,Z-score大于3或小于-3可以被认为是显著偏离平均值的值。
当进行Z-score计算时,有几个要注意的方面:
- 数据分布的假设:Z-score的计算基于数据满足正态分布的假设。如果数据不满足正态分布,Z-score的应用可能会受到影响。在非正态分布情况下,可以考虑使用其他的标准化方法或非参数统计方法。
- 数据集大小:Z-score对数据集的大小没有限制,可以用于小样本或大样本。然而,在较小的样本中,极端值(outliers)可能对Z-score的计算产生较大影响,因此需要谨慎处理。
- 数据的标准化:在计算Z-score之前,通常需要对数据进行标准化处理。标准化指将原始数据减去数据集的均值(μ),然后除以数据集的标准差(σ),以确保数据具有零均值和单位方差。
- Z-score的阈值:常见的Z-score阈值为2或3。一般而言,绝对值大于2或3的Z-score被认为是显著偏离平均值的值。这可以作为异常值的参考,但具体的阈值选择要根据具体应用和领域知识进行评估和决策。
需要注意的是,Z-score只提供了一个数值与平均值之间偏离程度的度量,不能单独用于判断数值的重要性或影响。在实际应用中,还需要结合其他分析方法和业务背景进行综合评估和解释
17、什么是高维稀疏数据
高维稀疏数据是指存在大量特征(高维)且其中大部分特征值为零(稀疏)的数据。在高维稀疏数据中,许多特征可能只在一小部分数据样本中出现,而其他特征则在较大部分样本中没有出现。
高维稀疏数据在许多领域中都很常见,如自然语言处理(文本数据)、推荐系统(用户行为数据)、生物信息学(基因表达数据)等。它们具有以下特点:
- 高维性:数据包含许多特征,通常远远超过样本数量。例如,文本数据中的每个单词可以被视为一个特征。
- 稀疏性:在高维数据中,大部分特征值为零。这是因为在真实世界的数据中,特征之间通常不会同时存在。
高维稀疏数据在进行数据处理和分析时面临一些挑战:
- 维数灾难:随着维度的增加,数据变得更加稀疏,导致计算和存储成本的急剧上升。
- 数据稀疏性:稀疏数据使得建模和分析变得更加困难,因为许多传统方法在面对稀疏数据时可能会失效。
针对高维稀疏数据,一些常见的处理方法包括:
- 特征选择:通过选择最相关或最有代表性的特征,降低数据维度,减少噪声和冗余。
- 特征提取:利用降维技术(如主成分分析、因子分析等)将高维特征转换为低维表示,保留最重要的信息。
- 稀疏编码:使用稀疏编码方法对数据进行压缩和表示,以减少存储和计算成本,同时保持原始数据的重要结构。
- 集成方法:结合多个模型或方法,综合利用多个特征选择或特征提取的结果,以提高预测性能。
需要根据具体的问题和数据特点选择适合的方法来处理高维稀疏数据,并结合领域知识和实际需求进行分析和建模
18、指标一致化中包括:极大型(指标的取值越大越好),极小型(指标的取值越小越好),居中型(数值越居中越好),区间型(最终取值落入某一个区间最佳)。居中型和区间型怎么处理。
居中型指标处理:
- 对于居中型指标,数值越居中越好,可以通过计算指标与其理想值之间的差异来进行处理。
- 一种常见的方法是计算指标与理想值的绝对差异或相对差异,并将得到的差异值进行标准化。常用的标准化方法包括将差异值除以指标的标准差或范围,以确保不同指标的差异可比较。
- 对于居中型指标的处理,可能需要根据具体的业务需求和背景,权衡指标的重要性,并确定差异的阈值,以确定指标的一致化程度。
区间型指标处理:
- 区间型指标要求最终指标值落入某一个特定的区间才被认为是最佳的。
- 处理区间型指标的方法可以采用阈值设定和将指标值规范化的方式。
- 一种常见的方法是根据业务需求设定特定的区间阈值,将指标值映射到该区间内。可以考虑使用线性映射或逻辑映射等技术进行转换。
- 通过将指标值规范化到特定区间,可以使得区间型指标具有可比较性,并且有助于评估指标在给定区间内的表现。
19、当数据不满足正态分布时,如何处理使其满足正态分布
- 对数转换(Log Transformation):将数据取对数可以有效地压缩右偏(正偏)分布的数据,使其更接近正态分布。适用于数据严重右偏或含有指数增长的情况。
- 幂次转换(Power Transformation):通过对数据应用幂次函数(例如平方根、平方、反正切等)来改变数据的分布形态。常用的方法包括Box-Cox转换和Yeo-Johnson转换。
- 分位数转换(Quantile Transformation):通过对数据进行分位数映射,将原始数据转换为符合正态分布的数据。常用的方法包括Rank-based方法和分位数函数转换方法。
- 艾尔兰伯格-约翰逊转换(Erlang-Johnson Transformation):这是一种参数转换方法,通过调整数据的位置和形状参数来使其更接近正态分布。
- Box-Cox变换:Box-Cox变换是一种广泛使用的转换方法,它通过引入一个参数λ来调整数据的形状。适用于对数偏差或指数偏差的数据。
- 选择合适的转换方法需要根据数据的特点和分布偏差来确定。可以使用可视化工具(如直方图、Q-Q图等)来评估转换的效果,并使用统计指标(如偏度、峰度等)来比较转换前后的数据分布。
- 需要指出的是,转换数据并不总能保证得到完全符合正态分布的结果,转换的结果可能仍存在一些偏差或不完美。因此,在进行转换时,应该结合具体的数据和分析需求进行权衡和调整。
20、当数据不满足正态时该如何处理
- 非参数统计方法:非参数统计方法不依赖于数据的分布假设,可以在不转换数据的情况下进行分析。例如,使用基于排名的方法,如Wilcoxon符号秩检验或Mann-Whitney U检验,来比较样本之间的差异。
- 采用鲁棒统计方法:鲁棒统计方法对异常值不敏感,在数据分布不满足正态性的情况下也能提供可靠的结果。例如,使用中位数和四分位数替代均值和标准差。
- 通过数据分箱(Binning):将连续的数据分成离散的区间,可以减少数据分布的偏差和异常值的影响,并使得数据更接近正态分布。可以使用等宽分箱或等频分箱的方法。
- 稳健回归分析:稳健回归方法能够降低异常值对回归结果的影响。例如,使用岭回归(Ridge Regression)或套索回归(Lasso Regression)等稳健回归模型。
- 集成学习方法:通过结合多个模型的预测结果(ensemble methods),可以减少对数据分布假设的依赖性,并得出更准确和稳健的预测结果。常见的集成学习方法包括随机森林(Random Forest)和梯度提升树(Gradient Boosting Tree)等。
21、SW检验与KS检验的目的及使用场景
Shapiro-Wilk检验和Kolmogorov-Smirnov检验是常用的统计检验方法,用于检验数据是否符合某个特定的理论分布,常用于正态性检验。
Shapiro-Wilk检验的目的是检验数据是否来自正态分布。该检验基于数据与正态分布之间的差异进行推断,对小样本和大样本均适用。Shapiro-Wilk检验的原假设是数据符合正态分布,备择假设是数据不符合正态分布。通过计算统计量和对应的p值,可以对原假设进行拒绝与否的判断。如果p值小于显著性水平(如0.05),则可以拒绝原假设,说明数据不符合正态分布。
Kolmogorov-Smirnov检验的目的是检验数据是否符合指定的累积分布函数(CDF),而不仅仅限于正态分布。该检验基于数据与理论分布之间的最大距离进行推断。与Shapiro-Wilk检验相比,K-S检验更加灵活,可以适用于多种理论分布和样本大小。K-S检验的原假设是数据符合理论分布,备择假设是数据不符合理论分布。通过计算统计量和对应的p值,可以对原假设进行拒绝与否的判断。如果p值小于显著性水平(如0.05),则可以拒绝原假设,说明数据不符合指定的理论分布。
使用场景:
- 正态性检验:Shapiro-Wilk检验和K-S检验常用于检验数据是否符合正态分布。这在许多统计方法中是一个重要的前提条件,例如t检验、方差分析等。如果数据不满足正态分布假设,可能需要寻找其他非参数统计方法。
- 分布拟合检验:K-S检验可用于检验数据是否与某个指定的理论分布(如指数分布、对数正态分布等)拟合良好。在拟合概率分布模型时,这种检验可以帮助验证拟合的合理性。
- 数据预处理:正态性检验可以用于判断数据是否需要进行正态化转换。如果数据不符合正态分布,可能需要进行数据转换或选择适用于非正态数据的统计方法。
需要注意的是,正态性检验并不是决定数据是否可以进行统计分析的唯一因素。在实际应用中,还需综合考虑数据的特点、研究目的和具体分析方法来决定是否需要进行分布检验以及如何进行进一步的数据处理。
相关文章:

数据分析之面试题目汇总
1、解释数据清洗的过程及常见的清洗方法。 数据清洗是指在数据分析过程中对数据进行检查、处理和纠正的过程;是数据预处理的一步,用于处理数据集中的无效、错误、缺失或冗余数据 常见的清洗方法包括:处理缺失值、处理异常值、去除重复值、统一…...

【Vue-Element-Admin】级联查询
背景 有两个查询条件:模块、功能点 想实现选择模块后,点击功能点下拉框,查询出对应模块下的功能点列表 查询 listQuery: export default{return{listQuery:{//page:1,//limit:20,//如果想兼容按条件导出,可以定义查询条件age:…...
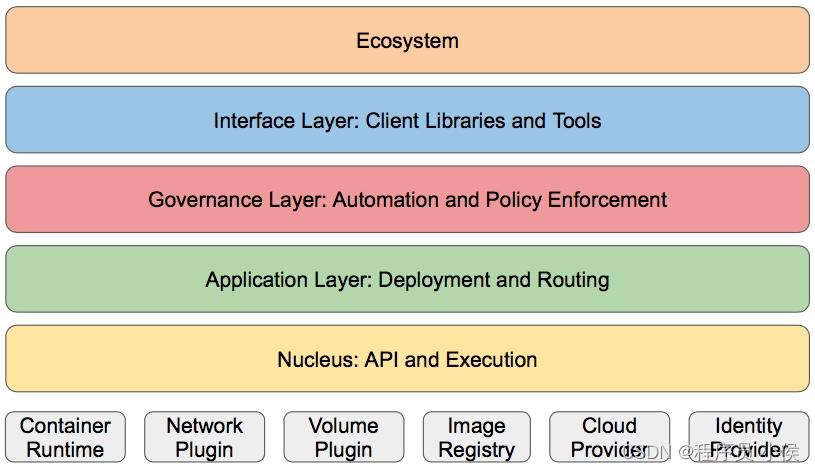
深入探讨Kubernetes(K8s)在云原生架构中的关键作用和应用
文章目录 1. 容器化的应用程序管理2. 自动化扩展和负载均衡3. 容器编排和调度4. 存储管理5. 自动化滚动更新6. 多云和混合云部署7. 监控和日志8. 安全9. 社区支持和生态系统10. 未来展望案例 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 …...

redis zset score 求和
redis zset score 求和 local sum0 local zredis.call(‘ZRANGE’, KEYS[1], 0, -1, ‘WITHSCORES’) for i2, #z, 2 do sumsumz[i] end return sum 例子:lua ~$ redis-cli zadd z 1 a 2 b 3 c 4 d 5 e (integer) 5 ~$ redis-cli eval "local sum0 local zr…...
背景/需求)
springboot属性注入增强(一)背景/需求
一 背景 springboot 在启动时候会将系统的环境变量、项目的启动时设置的属性 、application.yml文件(或application.properties文件)、PropertySource定义的配置文件中的属性加载到Environment对象中,分布式配置中心框架也会把配置加载到Env…...

《PWA实战:如何为你的网站增加离线功能和推送通知》
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

sqli-labs关卡之一(两种做法)
目录 一、布尔盲注(bool注入) 二、时间盲注(sleep注入) 一、布尔盲注(bool注入) 页面没有报错和回显信息,只会返回正常或者不正常的信息,这时候就可以用布尔盲注 布尔盲注原理是先将你查询结果的第一个字符转换为ascii码,再与后面的数字比较…...
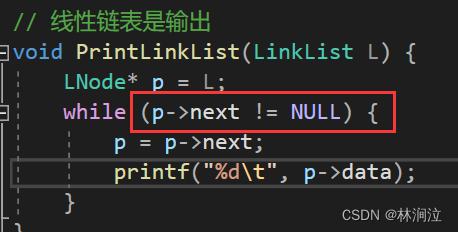
Visual Studio 线性表的链式存储节点输出引发异常:读取访问权限冲突
问题: 写了一个线性表的链式存储想要输出,能够输出,但是会报错:读取访问权限冲突 分析: 当我们输出到最后倒数第二个节点时,p指向倒数第二个节点并输出; 下一轮循环:p指向倒数第二…...

[通用]计算机经典面试题基础篇Day3
[通用]计算机经典面试题基础篇Day3 1、请说明mysql的两种主要引擎 MySQL有多种存储引擎,但最常见的两种主要引擎是InnoDB和MyISAM。 2、说一下mysql这两种引擎的使用场景 MySQL的两种主要引擎,InnoDB和MyISAM,各自适用于不同的使用场景&…...
 牛客 在线编程 Go语言入门)
(Golang) 牛客 在线编程 Go语言入门
文章目录 前言Go的学习资料链接 AC代码01 输出打印GP1 go的第一个程序 02 变量GP2 小明信息GP3 个人信息 03 常量GP4 国家名称 04 指针GP5 值和指针 05 字符串GP6 拼接字符串GP7 字符数量GP8 回文数 06 类型转换GP9 格式化字符串GP10 字符求和 07 运算符GP11 长方形的周长GP12 …...
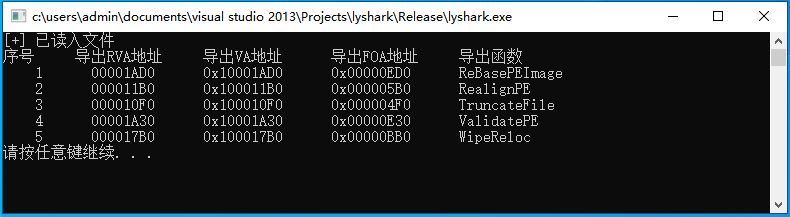
2.6 PE结构:导出表详细解析
导出表(Export Table)是Windows可执行文件中的一个结构,记录了可执行文件中某些函数或变量的名称和地址,这些名称和地址可以供其他程序调用或使用。当PE文件执行时Windows装载器将文件装入内存并将导入表中登记的DLL文件一并装入&…...

SpringMvc进阶
SpringMvc进阶 SpringMVC引言一、常用注解二、参数传递三、返回值 SpringMVC引言 在Web应用程序开发中,Spring MVC是一种常用的框架,它基于MVC(Model-View-Controller)模式,提供了一种结构化的方式来构建可维护和可扩…...
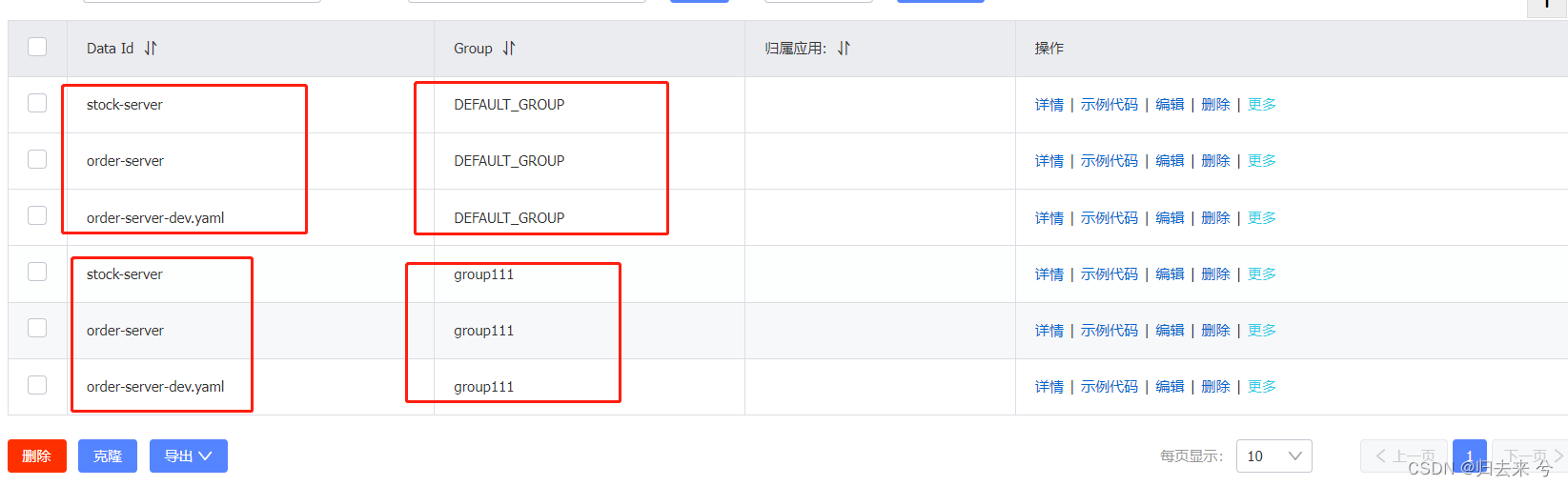
SpringCloud Alibaba 入门到精通 - Nacos
SpringCloud Alibaba 常用组件 一、基础结构搭建1.父工程创建2.子工程创建 二、Nacos:注册中心1.服务端搭建2.注册中心-客户端搭建3.注册中心-管理页面4.注册中心-常用配置5.注册中心-核心功能总结 三、Nacos注册中心集成Load Balancer 、OpenFeign1.Nacos客户端集成…...

new/delete, malloc/free
区别: 首先new/delete是运算符,malloc/free是库函数。malloc/free只开辟内存不初始化;new/delete及开辟内存也初始化。抛出异常的方式:new/delete开辟失败使用抛出bad_alloc;malloc/free通过返回值判断。malloc和new区…...
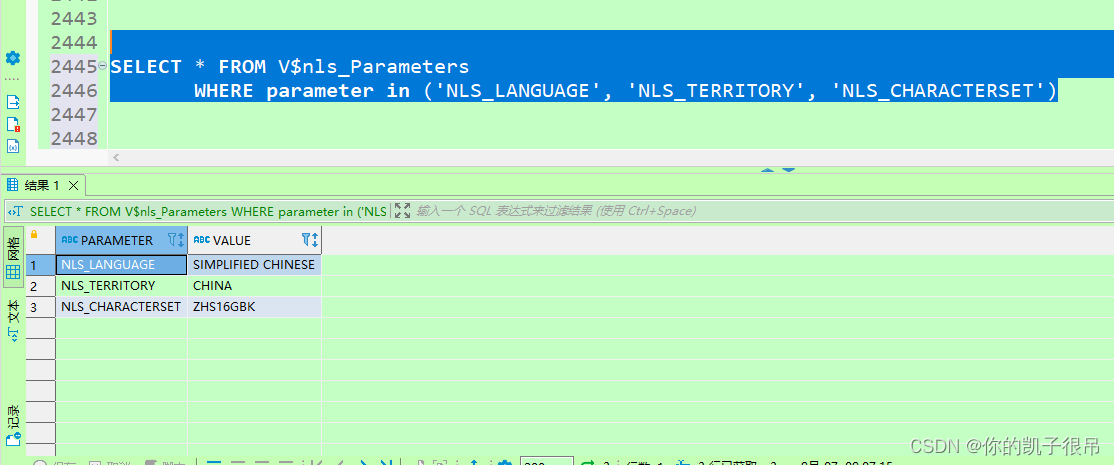
oracle将一个用户的表复制到另一个用户
注:scott用户和scott用户下的源表(EMP)本身就有,无需另行创建。 GRANT SELECT ON SCOTT.emp TO BI_ODSCREATE TABLE ODS_EMP AS SELECT * FROM SCOTT.emphttp://www.bxcqd.com/news/77615.html SQL语句查询要修改密码的用户…...

C#知识点、常见面试题
相关源码 https://github.com/JackYan666/CSharpCode/blob/main/CSharpCode.cs 0.简要概括 1.For循环删除集合元素可能漏删:从后面往前删除 2.Foreach不能直接修改集合元素:用递归的思想,删除完了的集合重新遍历 3.闭包问题:for循环存在闭包,可以通过使用临时变量解决…...

【STM32】锁存器
问题背景 在学习FSMC控制外部NOR存储器时,看到在NOR复用接口模式下,AD信号[15:0]是复用的。也就是说,若不使用锁存器:当NADV为低时,ADx(x0…15)上出现地址信号Ax,当NADV变高时,ADx上出现数据信号Dx。若使用…...
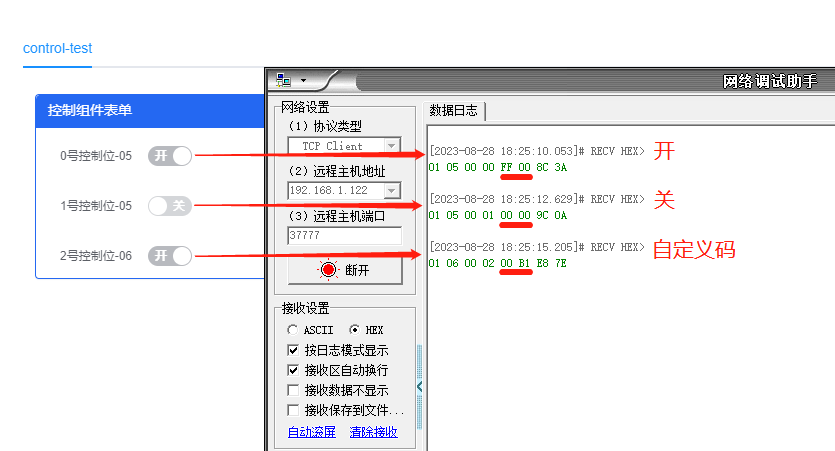
DGIOT-Modbus-RTU控制指令05、06的配置与下发
[小 迪 导 读]:伴随工业物联网在实际应用中普及,Modbus-RTU作为行业内的标准化通讯协议。在为物联网起到采集作用的同时,设备的控制也是一个密不可分的环节。 场景解析:在使用Modbus对设备进行采集后,可以通过自动控制…...
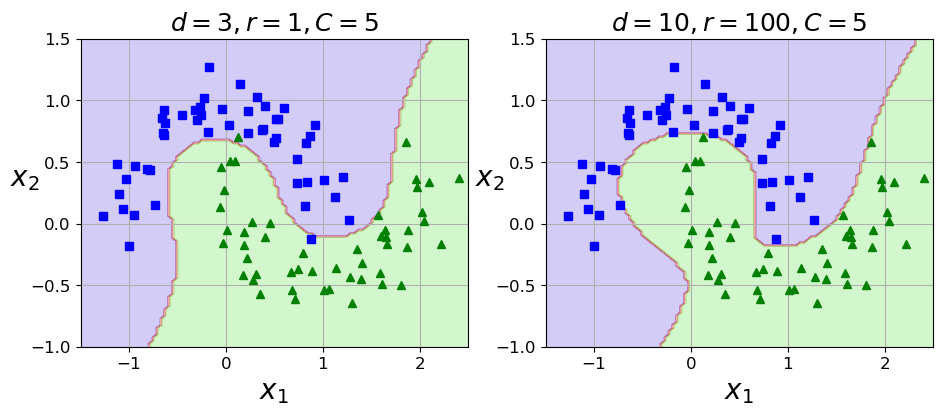
机器学习实战-系列教程8:SVM分类实战3非线性SVM(鸢尾花数据集/软间隔/线性SVM/非线性SVM/scikit-learn框架)项目实战、代码解读
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 SVM分类实战1之简单SVM分类 SVM分类实战2线性SVM SVM分类实战3非线性SVM 4、非线性SVM 4.1 创建非线性数据 from sklearn.data…...

计算机网络-谢希任第八版学习笔记总结
一.计算机网络概述 21世纪三个特点 数字化 信息化 智能化,其中主要是围绕智能化。 网络的常见分类: 电话网络 有线电视网络 计算机网络 互联网:Internet 由数量极大的计算机网络相连接 特点: 共享性 连通性 互联网&…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...