Redis——Java中的客户端和API
Java客户端
在大多数的业务实现中,我们还是使用编码去操作Redis,对于命令的学习只是知道这些数据库可以做什么操作,以及在后面学习到了Java的API之后知道什么方法对应什么命令即可。
官方推荐的Java的客户端网页链接如下:
爪哇指南 |雷迪斯 (redis.io)
Redis的客户端
在官方网站中,他推荐使用Jedis作为Java操作Redis的客户端。一部分原因是因为Jedis是以Redis命令作为方法名,学习成本低,简单实用。但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用。
除了Jedis之外,还有一个客户端也被推荐,叫做Lettuce。Lettuce是基于Netty实现的,支持同步,异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式,集群模式和管道模式,这种方式是比较支持在Spring中使用的一种客户端。
还有一个比较特殊的客户端,叫做Redisson。他的存在更偏向于一种工具包,对于Java语言的一些数据类型做了分布式的,可伸缩的封装,让他们更符合Redis的使用场景,Redisson是一个基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、Lock、Semaphore、AtomicLong等强大功能
Jedis
我们首先从Jedis开始入手Java的Redis客户端,首先第一步,我们要引入Redis的依赖:
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency>
创建测试类测试连接
package org.example; import redis.clients.jedis.Jedis; public class Main { public static void main(String[] args) { // 建立连接 Jedis jedis = new Jedis("192.168.80.12",6379); // 设置密码 jedis.auth("123456"); // 选择库 jedis.select(0); // 查询操作 String s = jedis.get("project:user:1"); System.out.println(s); // 释放资源 if(jedis != null){ jedis.close(); } } }
运行结果如下:

Jedis连接池
Jedis本身是不安全的,并且频繁的创建和销毁连接会有损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
创建一个工具类,在工具类中设置连接池和连接对象,并通过工具类的方式获取Jedis连接对象,保证每次获取都是从连接池中获取,并归还到连接池中。
package org.example.Redis; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class RedisConTool { private static final JedisPool jedisPool; static { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // 设置最大连接 jedisPoolConfig.setMaxTotal(8); // 最大空闲连接,是指在没有人连接的时候,最多创建8个空闲连接等待使用 jedisPoolConfig.setMaxIdle(8); // 最小空闲连接,空闲连接是指在没有人连接的时候维护的连接,如果一段时间没有人连接,则关闭所有连接。 jedisPoolConfig.setMinIdle(0); // 设置最长等待时间,当池子中没有可以连接的时候,等待多长时间,默认是-1,也就是一直等待,这里设置200,单位是毫秒,如果在200毫秒内依然没有连接,则报错。 jedisPoolConfig.setMaxWaitMillis(200); // 参数分别是:Jedis主机的IP地址,端口,连接等待时间,密码 jedisPool = new JedisPool(jedisPoolConfig,"192.168.80.12",6379,1000,"123456"); } // 获取Jedis对象 public static Jedis getJedis(){ return jedisPool.getResource(); } }
通过JedisPoolConfig设置连接池的相关信息,通过JedisPool创建连接对象,在创建连接对象的时候,将连接池参数对象传入进去。
通过这个工具类获取Jedis连接对象:
package org.example.Redis; import redis.clients.jedis.Jedis; public class Redis_connection_pooling { public static void main(String[] args) { Jedis jedis = RedisConTool.getJedis(); String s = jedis.get("project:user:1"); System.out.println(s); } }
最后的关闭资源Close方法,当他识别到你使用了连接池的时候,则并不会真正的关闭连接,而是将连接归还到连接池中,有一个returnResource的方法调用。
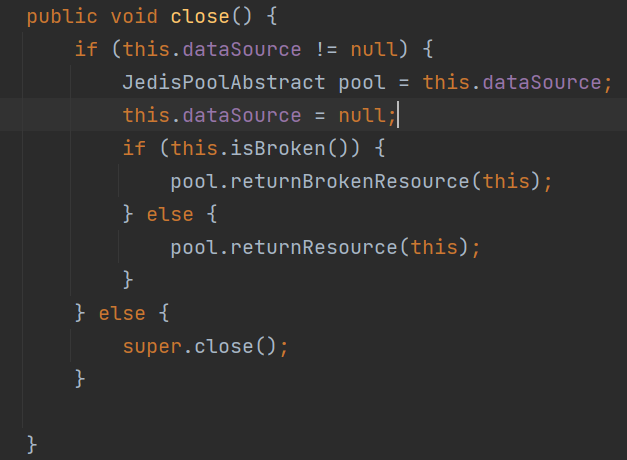
SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis
官网地址Spring Data Redis
- 提供了对不同Redis客户端的整合 (Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的IDKCollection实现
RedisTemplate快速入门
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

SpringDataRedis是集成在SpringBoot中的,所以我们直接创建一个SpringBoot项目去做就可以了,在创建的时候,我们可以直接勾选SpringDataRedis就可以添加对应的依赖:
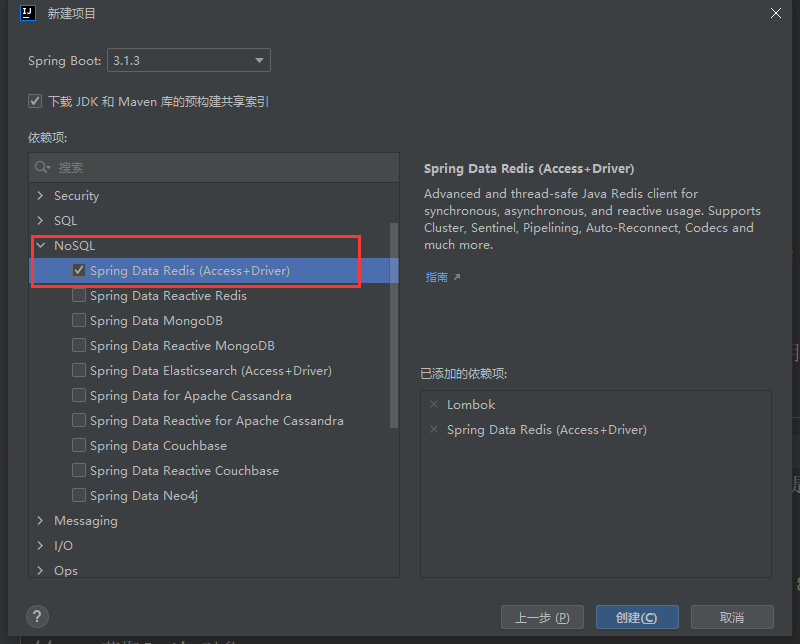
在项目创建完毕之后,我们可以打开Pom文件,然后会看到如下的内容:

如果看到这个Spring-boot-starter-data-redis的依赖就表示这个项目已经使用了Redis的依赖。除了上面的这个依赖,还有一个连接池的依赖需要引入:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- 连接池的依赖--> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency>
然后就是在SpringBoot中常做的一件事,去编写有关Redis的依赖:
# 端口号 spring.data.redis.port=6379 # Redis服务的IP地址 spring.data.redis.host=192.168.80.12 # 密码 spring.data.redis.password=123456 # 最大连接数量 spring.data.redis.lettuce.pool.max-active=8 # 最大空闲连接数量 spring.data.redis.jedis.pool.max-idle=8 # 最小空闲连接数量 spring.data.redis.jedis.pool.min-idle=0 # 连接等待时间 spring.data.redis.jedis.pool.max-wait=100
写好配置文件之后,就可以到测试类中去测试Redis的客户端和配置是否正确:
package Redis; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.ValueOperations; @SpringBootTest class SpringBootRedisApplicationTests { @Autowired RedisTemplate redisTemplate; @Test void contextLoads() { ValueOperations valueOperations = redisTemplate.opsForValue(); valueOperations.set("name","张三"); String s = (String) valueOperations.get("name"); System.out.println(s); } }
在默认情况下,SpringBoot引入Redis之后使用的是Lettuce客户端,如果要改成Jedis客户端,需要在Pom文件中引入Jedis的相关依赖。
基本步骤
SpringDataRedis的使用步骤
- 1.引入spring-boot-starter-data-redis依赖
- 2.在application.yml配置Redis信息
- 3.注入RedisTemplate
SpringDataRedis的序列化方式
RedisTemplate可以接收任意0biect作为值写入Redis,只不过写入前会把Obiect序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
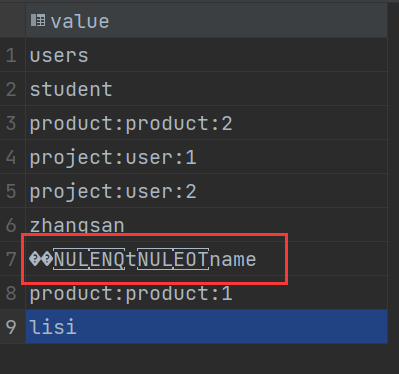
缺点:
- 可读性差
- 内存占用大
SpringDataRedis的序列化方式
在默认情况下,他使用的序列化方式是JdkSerializationRedisSerializer,这种方式会导致出问题,就是他会将字符串也当做Java对象进行处理,从而进行一个序列化的操作,就出现了我们看到的乱码,除了这个默认的选项,我们还可以选择其他的更好用的选项,在序列化key的时候,由于大部分的key都是字符串,所以我们可以使用StringRedisSerializer,这个就是专门用于String类型的序列化,对于值,有可能会存储Java的对象类型,所以选择使用GenericJackson2JsonRedisSerializer序列化器,将对象转换成JSON字符串的方式。
然后接下来的问题就是修改Redis的序列化器,我们选择使用第三方Bean的方式去修改他的序列化器:
package Redis; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.RedisSerializer; @Configuration public class OtherBean { @Bean public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){ // 创建Template RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>(); // 设置连接工厂 redisTemplate.setConnectionFactory(redisConnectionFactory); // 创建序列化工具,这个工具是用来对值进行序列化的工具 GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer(); // 设置key的序列化工具,使用String序列化方式 redisTemplate.setKeySerializer(RedisSerializer.string()); redisTemplate.setHashKeySerializer(RedisSerializer.string()); // 设置value的序列化方式,使用GenericJackson2JsonRedisSerializer进行序列化 redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); redisTemplate.setHashKeySerializer(jackson2JsonRedisSerializer); // 将设置好的Template返回出去 return redisTemplate; } }
然后还需要导入对应的序列化工具的依赖:
<!-- 序列化工具的依赖--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency>
在运行之前,我们要删除之前我们操作的乱码的Key:
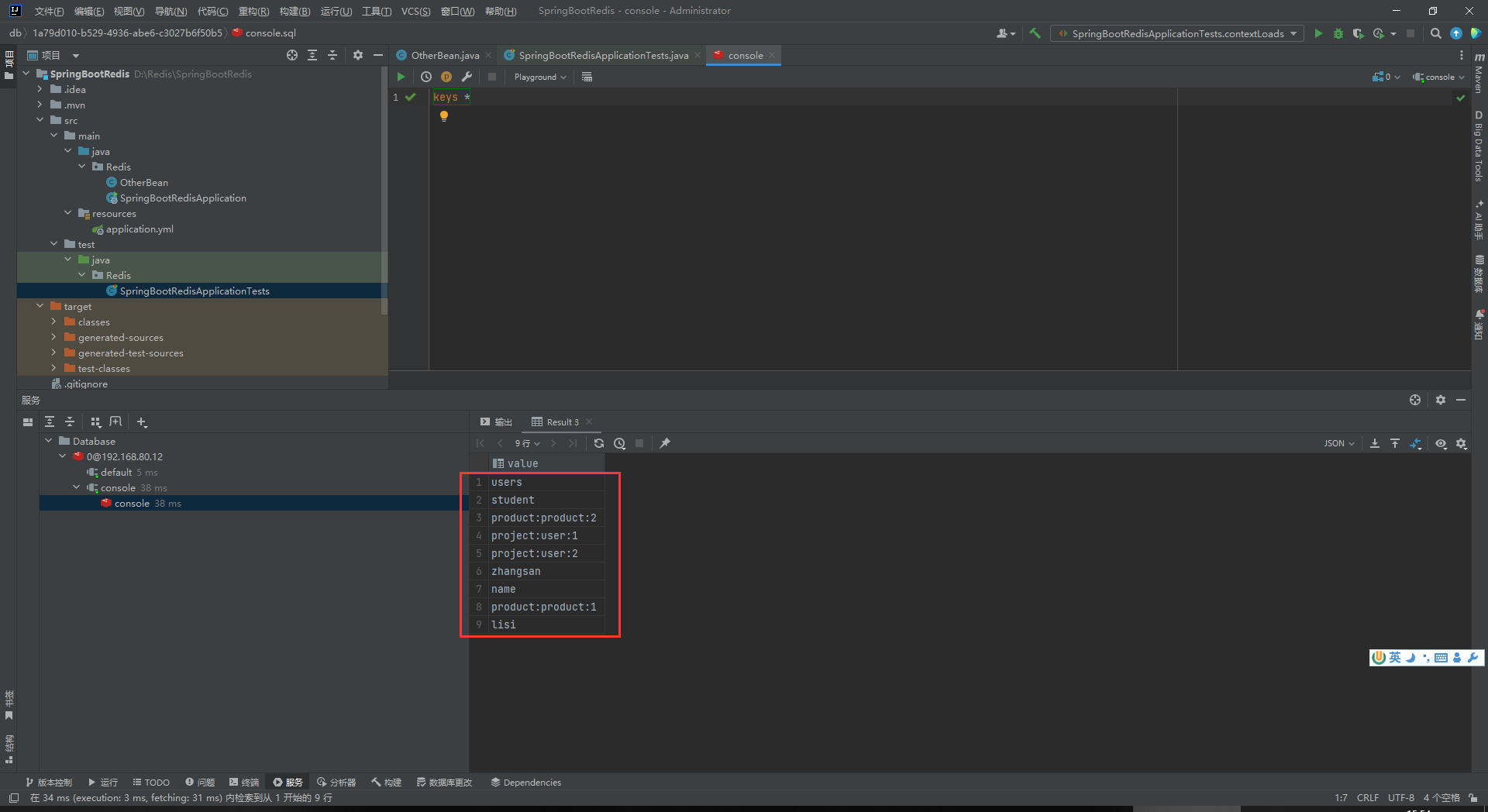
然后看一下现在name的key里面存储的内容是什么:
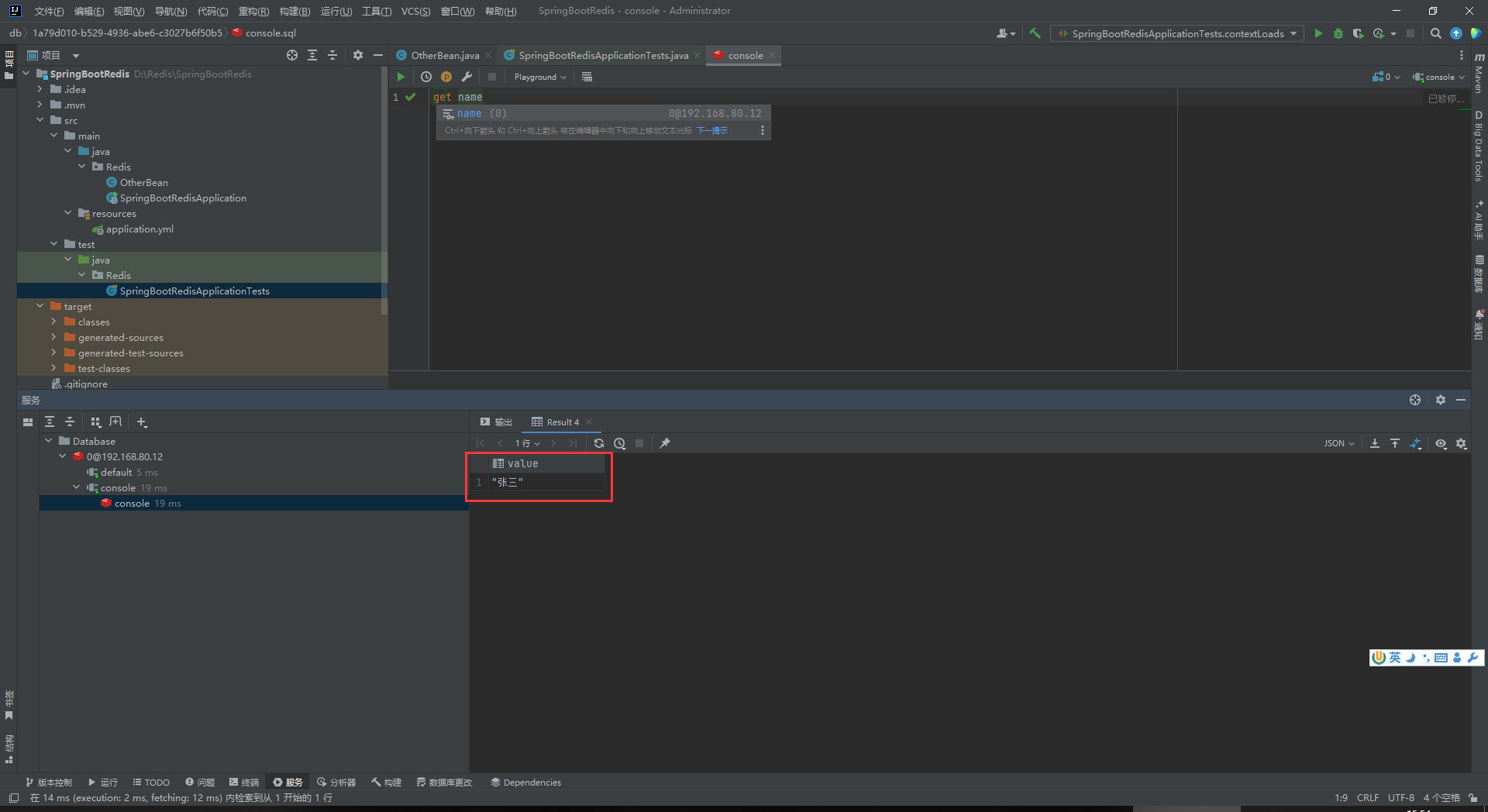
现在name的key里面存储的是“张三”,然后我们修改一下里面的内容:

现在name里面的内容是Jack,然后我们在程序中也修改name的值,如果能修改当前name的值,而不是出现另一个乱码的key,则表示序列化工具使用成功:
package Redis; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.ValueOperations; @SpringBootTest class SpringBootRedisApplicationTests { @Autowired RedisTemplate<String,Object> redisTemplate; @Test void contextLoads() { ValueOperations valueOperations = redisTemplate.opsForValue(); valueOperations.set("name","summer"); String s = (String) valueOperations.get("name"); System.out.println(s); } }
首先,程序运行成功:

然后来到Redis这边查看name的的值:
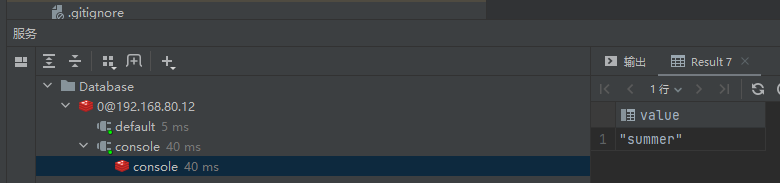
这边的值也被修改:

并且没有出现乱码的key,就表示序列化工具已经正常启动了。
然后我们再来测试一下当传入的值是Java对象的时候,他应该会自动将对象转成JSON字符串的格式:
@Test void testValueIsObject(){ user u = new user(); u.setId(1); u.setName("Jack"); ValueOperations<String, Object> stringObjectValueOperations = redisTemplate.opsForValue(); stringObjectValueOperations.set("user:100",u); user user = (user) stringObjectValueOperations.get("user:100"); System.out.println(user); }
首先,程序运行成功:

其次,我们来到Redis的数据库中查看数据:

key对,value对,然后类型也是对的,那就说明我们的配置全部都是正确的。
并且我们在程序中获取的数据的时候他也会将JSON字符串转换成Java的对象,这样操作就会方便很多。他能实现反序列化的原因是因为在写入数据的时候,他除了写入数据之外,还写入了另一个class属性:

这个属性就指明了他所属类的全属性包名,这样只要这个类存在,那么就可以将数据写入进去。
StringRedisTemplate
使用SpringRedisTemplate的时候我们可以做到自动的序列化与反序列化,也就是从Redis数据库到Java类的过程是全自动的,但是有一个缺点就是在存储的时候他需要额外的存储空间去存储与类相关的信息,这就导致了存储空间的浪费,为了避免这种资源的浪费,我们选择不使用自动化的序列化,而是将Java类手动的序列化成Json字符串,然后在Redis中存储纯净的JSON字符串,然后在读取的时候,手动的反序列化,将JSON转换成Java类,这种方式的可以节省存储空间,并且操作也并不是很麻烦。
那么这时候就需要修改之前的序列化器,因为之前我们的序列化是存储值的时候按照对象的方式序列化,并不是以字符串的方式序列化,但是Redis有一个专门用于存储key和value都是字符串的对象,就是StringRedisTemplate,具体的操作如下:
package Redis; import Redis.pojo.user; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.ValueOperations; @SpringBootTest public class StringRedisTemplateTest { @Autowired private StringRedisTemplate stringRedisTemplate; private final ObjectMapper mapper = new ObjectMapper(); @Test void test() throws JsonProcessingException { // 写入数据 user u = new user(); u.setName("Tom"); u.setId(1); String user = mapper.writeValueAsString(u); ValueOperations<String, String> ops = stringRedisTemplate.opsForValue(); ops.set("user:200",user); // 读取数据 String RedisUser = ops.get("user:200"); user PojoUser = mapper.readValue(RedisUser, user.class); System.out.println(PojoUser); } }
与之前的自动序列化相比,这里多个一个步骤就是使用ObjectMapper将对象和JSON字符串互相转换的过程,其实之后将这个过程做成工具类效果会简单很多。
这样在Redis中存储的数据就是纯净的数据,没有多余的数据去占用资源。
相关文章:
Redis——Java中的客户端和API
Java客户端 在大多数的业务实现中,我们还是使用编码去操作Redis,对于命令的学习只是知道这些数据库可以做什么操作,以及在后面学习到了Java的API之后知道什么方法对应什么命令即可。 官方推荐的Java的客户端网页链接如下: 爪哇…...

Brief. Bioinformatics2021 | sAMP-PFPDeep+:利用三种不同的序列编码和深度神经网络预测短抗菌肽
文章标题:sAMP-PFPDeep: Improving accuracy of short antimicrobial peptides prediction using three different sequence encodings and deep neural networks 代码:https://github.com/WaqarHusain/sAMP-PFPDeep 一、问题 短抗菌肽(sAMPs)&#x…...

问道管理:华为产业链股再度拉升,捷荣技术6连板,华力创通3日大涨近70%
华为产业链股6日盘中再度拉升,到发稿,捷荣技能涨停斩获6连板,华映科技亦涨停收成3连板,华力创通大涨超19%,蓝箭电子涨约11%,力源信息涨超4%。 捷荣技能盘中再度涨停,近7日已累计大涨超90%。公司…...
面试设计模式-责任链模式
一 责任链模式 1.1 概述 在进行请假申请,财务报销申请,需要走部门领导审批,技术总监审批,大领导审批等判断环节。存在请求方和接收方耦合性太强,代码会比较臃肿,不利于扩展和维护。 1.2 责任链模式 针对…...
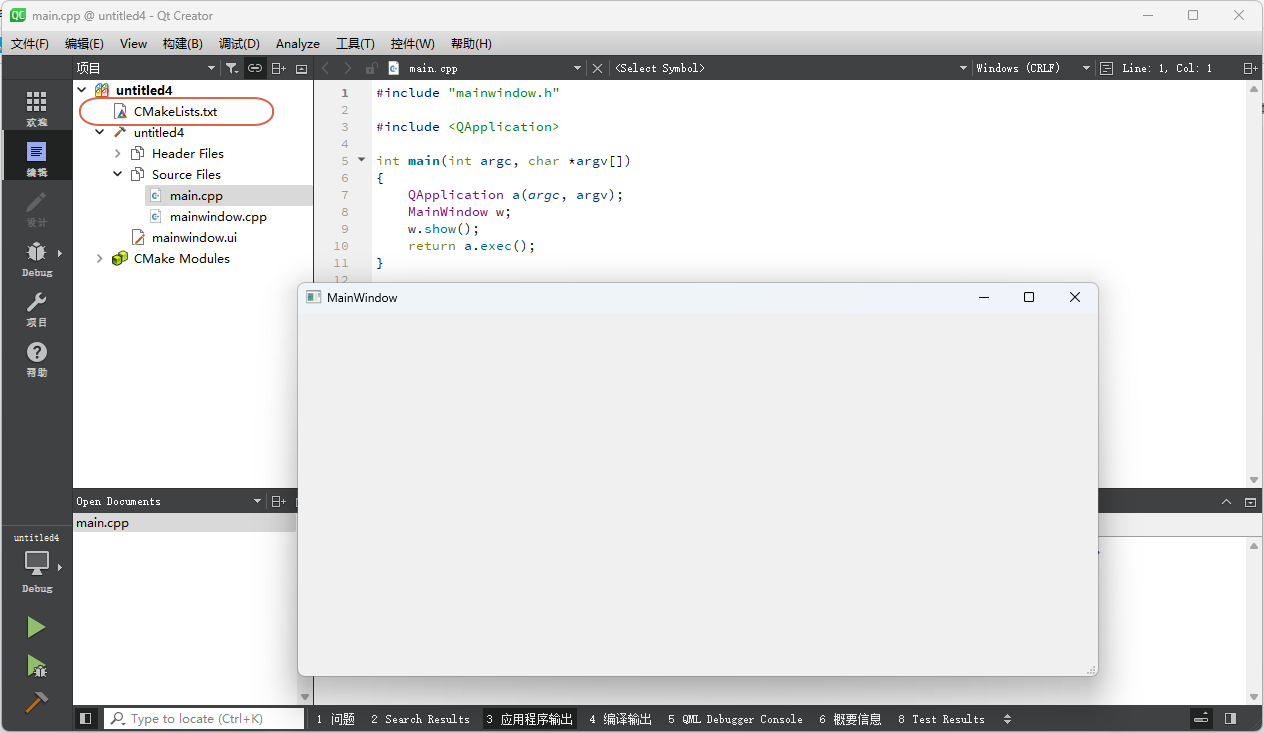
Qt 开发 CMake工程
Qt 入门实战教程(目录) 为何要写这篇文章 目前CMake作为C/C工程的构建方式在开源社区已经成为主流。 企业中也是能用CMake的尽量在用。 Windows 环境下的VC工程都是能不用就不用。 但是,这个过程是非常缓慢的,所以࿰…...
2.k8s账号密码登录设置
文章目录 前言一、启动脚本二、配置账号密码登录2.1.在hadoop1,也就是集群主节点2.2.在master的apiserver启动文件添加一行配置2.3 绑定admin2.4 修改recommended.yaml2.5 重启dashboard2.6 登录dashboard 总结 前言 前面已经搭建好了k8s集群,现在设置下…...

【代表团坐车】Python 实现-附ChatGPT解析
1.题目 某组织举行会议,来了多个代表团同时到达,接待处只有一辆汽车,可以同时接待多个代表团,为了提高车辆利用率,请帮接待员计算可以坐满车的接待方案,输出方案数量。 约束: 1.一个团只能上一辆车,并且代表团人数(代表团数量小于30,每人代表团人数小于30)小于汽车容量…...

【Java】x-easypdf: 一种简单易用的PDF处理库
引言 在处理和生成PDF文档时,有许多库可供选择。其中,x-easypdf是一种简单易用的PDF处理库,可以帮助开发人员轻松地创建、编辑和操作PDF文档。本文将介绍x-easypdf的基本概念、安装方法、主要功能以及使用示例。 安装x-easypdf 要使用x-ea…...

1 Linux输入子系统
1 Linux输入子系统 https://www.cnblogs.com/beijiqie1104/p/11418082.html Linux input 子系统详解 https://www.cnblogs.com/yikoulinux/p/15208238.html...
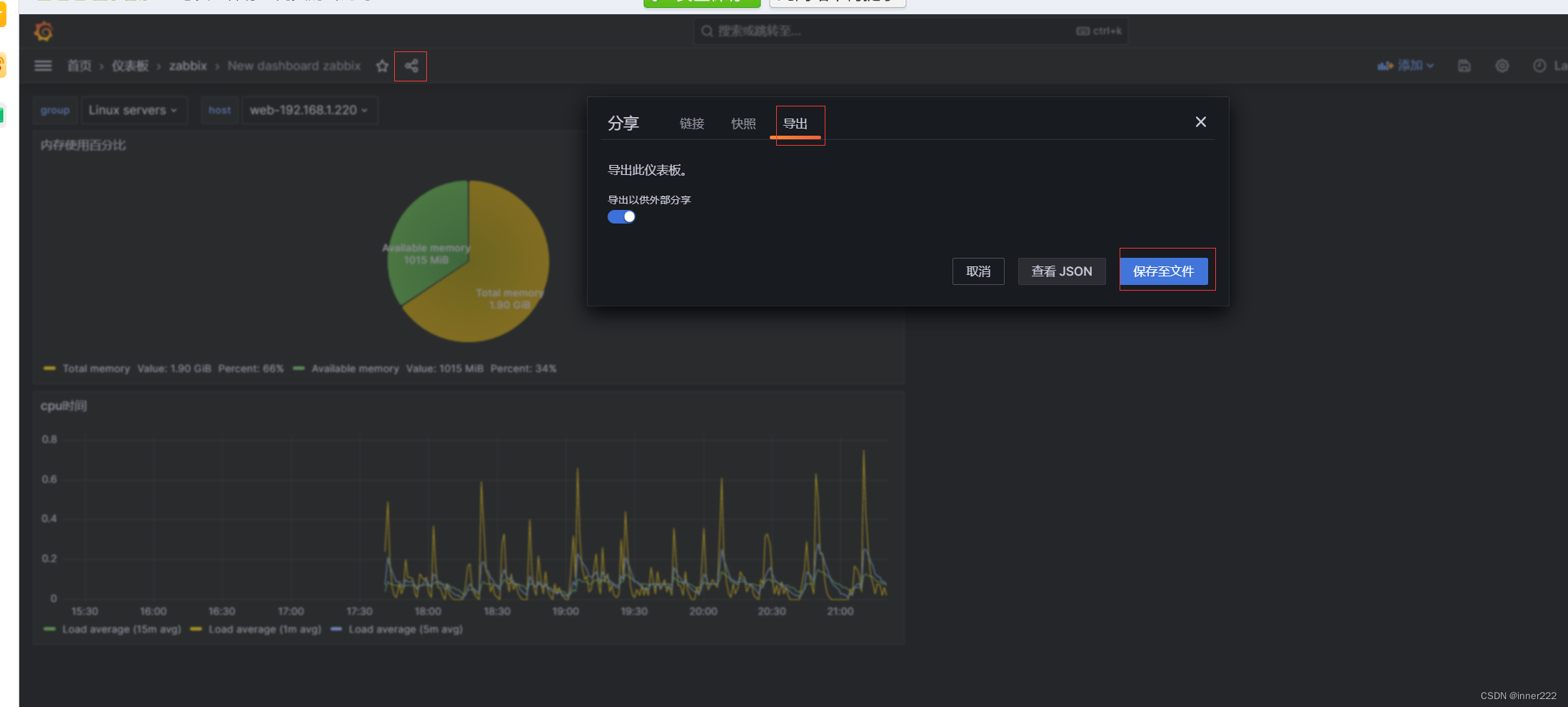
Zabbix 利用 Grafana 进行图形展示
安装grafana和插件 配置zabbix数据源 导入模版 查看数据 1.安装grafana wget https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/Packages/grafana-10.0.0-1.x86_64.rpm [rootrocky8 apps]# yum install grafana-10.0.0-1.x86_64.rpm [rootrocky8 apps]# systemctl sta…...

【LeetCode周赛】LeetCode第362场周赛
LeetCode第362场周赛 与车相交的点判断能否在给定时间到达单元格将石头分散到网格图的最少移动次数 与车相交的点 给你一个下标从 0 开始的二维整数数组 nums 表示汽车停放在数轴上的坐标。对于任意下标 i,nums[i] [starti, endi] ,其中 starti 是第 i…...

Leetcode128. 最长连续序列
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 题解&#…...
K8S:kubeadm搭建K8S+Harbor 私有仓库
文章目录 一.部署规划1.主机规划2.部署流程 二.kubeadm搭建K8S1.环境准备2.安装docker3. 安装kubeadm,kubelet和kubectl4.部署K8S集群(1)初始化(2)部署网络插件flannel(3)创建 pod 资源 5.部署 …...
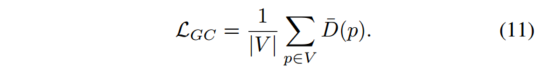
MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask 论文阅读
论文信息 题目:MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask 作者:Weihao Xuan, Ruijie Ren, Siyuan Wu, Changhao Chen 时间:2022 来源: IEEE/SICE International Symposium on System Integration …...

面试求职-面试注意事项
面试技巧和注意事项有哪些? 面试是找工作过程中最重要的一个环节,因为面试成功,你才有可能得到一份工作。求职面试技巧有哪些呢?首先,我们来看看面试注意事项。 企业了解 1、面试前有没有仔细了解过对应企业的情况,…...

sm2 签名验签
目前发现 sm2 有很多实现,比如 gmssl, openssl 1.1.1 ,openssl 3.0,各种代码库实现等等。实践中发现这些实现会出现不能互相验签的情况。后续研究一下。 网上的一些资料,给出了一些 openssl 指令,但是没有标明 openssl 的版本&…...
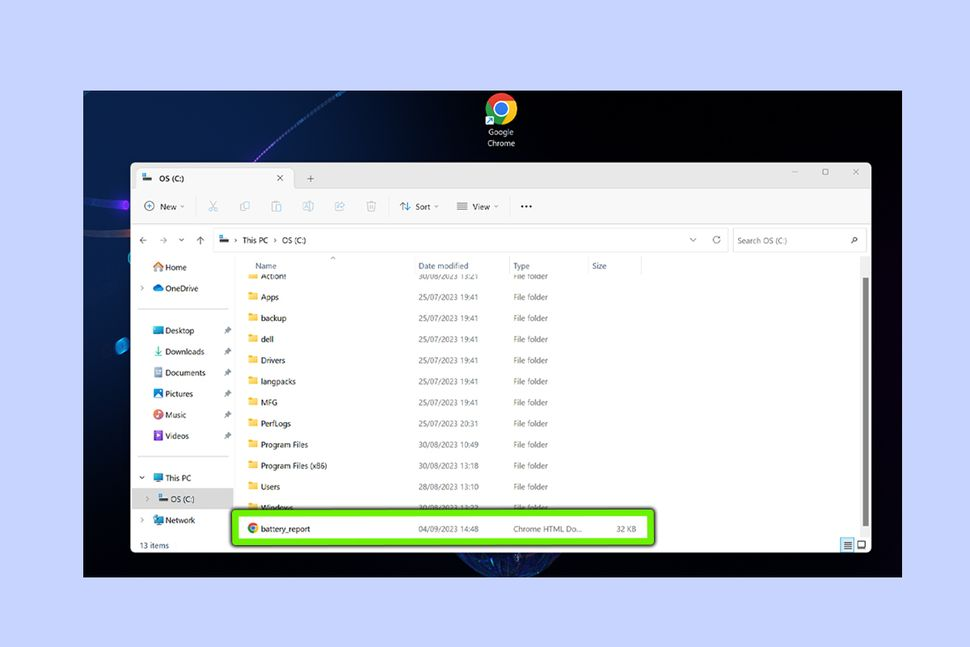
如何检查Windows 11笔记本电脑电池健康状况
如果你拥有一台运行微软最新操作系统的便携式电脑,那么检查Windows 11笔记本电脑的电池健康状况可能很重要。 电池寿命显然是一件大事,无论你是在最好的商务笔记本电脑上工作,还是在目前市场上最好的游戏笔记本电脑上享受马拉松式的Starfiel…...

编程大师-分布式
分布式锁 mysql redis 【IT老齐122】不只setnx,两张图说清Redisson的Redis分布式锁实现_哔哩哔哩_bilibili zk 用这种方式去实现,zookeeper分布式锁,你会吗?_哔哩哔哩_bilibili...

内网隧道代理技术(二十三)之 DNS隧道反弹Shell
DNS隧道反弹Shell DNS隧道 DNS协议是一种请求、应答协议,也是一种可用于应用层的隧道技术。DNS隧道的工作原理很简单,在进行DNS查询时,如果查询的域名不在DNS服务器本机缓存中,就会访问互联网进行查询,然后返回结果。如果在互联网上有一台定制的服务器,那么依靠DNS协议…...

如何利用Socks5代理IP提升网络安全与跨境电商业务
在今天的数字时代,网络安全对于个人和企业来说都至关重要。随着跨境电商和在线游戏等业务的不断发展,保护网络安全变得尤为重要。Socks5代理IP是一项强大的工具,可以帮助您实现更高水平的网络安全,同时促进跨境电商和游戏领域的增…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...