MyBatis-Plus学习笔记总结
一、查询
构造器分为QueryWrapper和LambdaQueryWrapper
创建实体类User
package com.system.mybatisplus.model;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;import java.io.Serializable;@TableName("user") // 指定表名,如果表名和类名一致,可以省略
@Data // 使用Lombok简化开发
public class User implements Serializable { // 实现序列化接口@TableId(type = IdType.AUTO)private Long id;@TableField("name") // 指定表字段名,如果字段名和属性名一致,可以省略private String name;// @TableField(select = false) // select = false 表示查询时不查询该字段private Integer age;private String email;@TableField(exist = false) // exist = false 表示该字段不是数据库字段,但是可以使用private Boolean isOnline;
}编写mapper接口UserMapper
package com.system.mybatisplus.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.system.mybatisplus.model.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;@Mapper // 此注解用于标记这是一个mybatis的mapper类,否则会报错,因为没有加@Mapper
public interface UserMapper extends BaseMapper<User> {// 继承BaseMapper// 根据名称查询User selectByName(@Param("name") String name);
}
编写service及其实现类
package com.system.mybatisplus.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.system.mybatisplus.model.User;
// 需要继承IService
public interface UserService extends IService<User> {}
package com.system.mybatisplus.service.impl;import com.baomidou.mybatisplus.extension.service.IService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.system.mybatisplus.mapper.UserMapper;
import com.system.mybatisplus.model.User;
import com.system.mybatisplus.service.UserService;
import org.springframework.stereotype.Service;@Service // 此注解用于标记这是一个service类,否则会报错,因为没有加@Service
// 此处继承ServiceImpl(ServiceImpl实现了IService接口),同时实现UserService接口
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
1、等值查询
查询条件必须完全匹配才行,可以拼接多个eq
@Testvoid testEq() {// 1、创建条件构造器QueryWrapper<User> wrapper = new QueryWrapper<>();// 2、设置条件,指定字段名和字段值wrapper.eq("name", "jone");// 3、执行查询,使用selectOne方法,查询结果只能有一条,否则报错,如果查询结果有多条,使用selectList方法System.out.println(userMapper.selectList(wrapper));}
@Testvoid testEq() {// 简写System.out.println(userMapper.selectList(new QueryWrapper<User>().eq("name", "jone")));}
相当于执行了如下SQL
SELECT id,name,age,email FROM user WHERE (name = ?)
可以使用LambdaQueryWrapper
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getName, "jone"); // 等价于wrapper.eq("name", "jone"); 但是这样写更安全,因为不会出现字段名写错的情况
System.out.println(userMapper.selectList(wrapper));
同时多个查询条件,必须同时满足才行
@Testvoid testEq() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.eq(User::getName, "jone").eq(User::getAge, 19); // 相当于并列条件System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (name = ? AND age = ?)
空值null的判断与处理
当某个查询条件值为空时,不参与拼接
一般用于多条件查询中
@Testvoid testNull() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();String name = "jone";// 查询条件是否为null的判断wrapper.eq(name != null, User::getName, name); // 如果name不为空,就加入条件,否则不加入条件System.out.println(userMapper.selectOne(wrapper));}
多条件查询也可以使用allEq
使用HashMap存储查询条件,就没法使用LambdaQueryWrapper
@Testvoid testAllEq() {QueryWrapper<User> wrapper = new QueryWrapper<>();HashMap<String, Object> map = new HashMap<>();map.put("name", "jone");map.put("age", 19);wrapper.allEq(map, false); // 等价于wrapper.eq("name", "jone").eq("age", 19); 如果第二个参数为false,表示如果map中有null值,就不加入条件System.out.println(userMapper.selectList(wrapper));}
除了eq,还有ne,即不等值查询
@Testvoid testNe() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.ne("name", "jone"); // 不等于System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (name <> ?) <> 不等于
2、范围查询
- gt 大于
@Testvoid testGt() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.gt("age", 20); // 大于,适用于数据类型为数字的字段和日期类型的字段System.out.println(userMapper.selectList(wrapper));}
- ge 大于等于
@Testvoid testGe() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.ge("age", 20); // 大于等于,适用于数据类型为数字的字段和日期类型的字段System.out.println(userMapper.selectList(wrapper));}
- lt 小于
@Testvoid testLt() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.lt("age", 20); // 小于,适用于数据类型为数字的字段和日期类型的字段System.out.println(userMapper.selectList(wrapper));}
- le 小于等于
@Testvoid testLe() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.le("age", 20); // 小于等于,适用于数据类型为数字的字段和日期类型的字段System.out.println(userMapper.selectList(wrapper));}
- between
@Testvoid testBetween() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.between(User::getAge, 18, 20); // 适用于数据类型为数字的字段和日期类型的字段, 包含18和20System.out.println(userMapper.selectList(wrapper));}
- notBetween
@Testvoid testNotBetween() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.notBetween(User::getAge, 18, 20); // 适用于数据类型为数字的字段和日期类型的字段, 不包含18和20System.out.println(userMapper.selectList(wrapper));}
3、模糊查询
- like
@Testvoid testLike() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.like(User::getName, "j"); // 模糊查询System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (name LIKE %j%)
- notLike
查询名称中不含 j的,不区分大小写
@Testvoid testLike() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.notLike(User::getName, "j"); // 模糊查询System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (name NOT LIKE %j%)
- likeLeft
区分大小写
@Testvoid testLikeLeft() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.likeLeft(User::getName, "j"); // 左模糊查询, 等价于wrapper.like(User::getName, "%j")System.out.println(userMapper.selectList(wrapper));}
- likeRight
@Testvoid testLikeRight() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// 查找名字以j开头的用户,区分大小写wrapper.likeRight(User::getName, "j"); // 右模糊查询, 等价于wrapper.like(User::getName, "j%")System.out.println(userMapper.selectList(wrapper));}
4、判空查询
- isNull
@Testvoid testIsNull() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.isNull(User::getEmail); // 查找email为null的用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (email IS NULL)
- isNotNull
@Testvoid testIsNull() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.isNotNull(User::getEmail); // 查找email不为null的用户System.out.println(userMapper.selectList(wrapper));}
5、包含查询
- in
@Testvoid testIn() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.in(User::getAge, Arrays.asList(18,19,20)); // 查找年龄为18,19,20的用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (age IN (?,?,?))
- notIn
@Testvoid testNotIn() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.notIn(User::getAge, Arrays.asList(18,19,20)); // 查找年龄不为18,19,20的用户System.out.println(userMapper.selectList(wrapper));}
- inSql
可以编写嵌套查询
@Testvoid testInSql() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.inSql(User::getId, "select id from user where id < 3"); // 查找id小于3的用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (id IN (select id from user where id < 3))
- notInSql
@Testvoid testNotInSql() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.notInSql(User::getId, "select id from user where id < 3"); // 查找id不小于3的用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (id NOT IN (select id from user where id < 3))
6、分组查询
使用groupBy分组
@Testvoid testGroupBy() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.groupBy("age"); // 按照年龄分组// 这里使用字符串的方式,所以只能使用QueryWrapper,不能使用LambdaQueryWrapperwrapper.select("age, count(*) as count"); // 查询年龄和年龄的数量System.out.println(userMapper.selectMaps(wrapper)); // 返回类型为List<Map<String, Object>>}
SELECT age, count(*) as count FROM user GROUP BY age
7、聚合查询
在6的基础上,过滤出count大于等于2的数据,就需要使用having过滤
先分组,再查询,最后过滤
@Testvoid testHaving() {QueryWrapper<User> wrapper = new QueryWrapper<>();wrapper.groupBy("age"); // 按照年龄分组wrapper.select("age, count(*) as count"); // 查询年龄和年龄的数量wrapper.having("count >= 2"); // 查询数量大于等于2的年龄System.out.println(userMapper.selectMaps(wrapper)); // 返回类型为List<Map<String, Object>>}
SELECT age, count(*) as count FROM user GROUP BY age HAVING count >= 2
[{count=2, age=18}, {count=2, age=20}]
8、排序查询
- orderByASC 升序
@Testvoid testOrderByAsc() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.select(User::getId, User::getName, User::getAge); // 查询id, name, age字段wrapper.orderByAsc(User::getAge); // 按照年龄升序排序System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age FROM user ORDER BY age ASC
- orderByDesc 降序
@Testvoid testOrderByDesc() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.select(User::getId, User::getName, User::getAge); // 查询id, name, age字段wrapper.orderByDesc(User::getAge); // 按照年龄降序排序System.out.println(userMapper.selectList(wrapper));}
- orderBy
相比较前面两个,灵活性更高
@Testvoid testOrderBy() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.select(User::getId, User::getName, User::getAge); // 查询id, name, age字段// 第一个参数表示当该字段值为null时,是否还要作为排序条件// 第二个参数表示是否升序排序// 第三个参数表示排序的字段wrapper.orderBy(true, true, User::getAge); // 按照年龄升序排序// 当年龄相同时,按照id降序排序wrapper.orderBy(true, false, User::getId); // 按照id降序排序System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age FROM user ORDER BY age ASC,id DESC
9、逻辑查询
(1)内嵌逻辑查询func
当某个需求的条件有多个时,可以使用func
@Testvoid testFunc() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// func函数需要传入一个Consumer接口,该接口的accept方法接收一个LambdaQueryWrapper对象wrapper.func(new Consumer<LambdaQueryWrapper<User>>() {@Overridepublic void accept(LambdaQueryWrapper<User> userLambdaQueryWrapper) {// 这里需要使用实际开发中的业务逻辑来替换if(true) {userLambdaQueryWrapper.eq(User::getId, 1);}else {userLambdaQueryWrapper.ne(User::getId, 1);}}});System.out.println(userMapper.selectList(wrapper));}
@Testvoid testFunc() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// func函数需要传入一个Consumer接口,该接口的accept方法接收一个LambdaQueryWrapper对象// 使用Lambda表达式来简化代码wrapper.func(userLambdaQueryWrapper -> {// 这里需要使用实际开发中的业务逻辑来替换if(true) {userLambdaQueryWrapper.eq(User::getId, 1);}else {userLambdaQueryWrapper.ne(User::getId, 1);}});System.out.println(userMapper.selectList(wrapper));}
(2)and
正常的拼接默认就是and,表示条件需要同时成立
@Testvoid testAnd() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.gt(User::getAge, 18).lt(User::getAge, 25); // 查询年龄大于18并且小于20的用户System.out.println(userMapper.selectList(wrapper));}
使用and嵌套
通常需要嵌套or
@Testvoid testAnd() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.eq(User::getId, 1).and(userLambdaQueryWrapper -> userLambdaQueryWrapper.eq(User::getAge, 18).or().eq(User::getAge, 20)); // 查询id为1并且年龄为18或20的用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (id = ? AND (age = ? OR age = ?))
(3)or
表示多个条件只需要成立其中之一即可
@Testvoid testOr() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.gt(User::getAge, 25).or().lt(User::getAge, 20); // 查询年龄大于25或小于20的用户System.out.println(userMapper.selectList(wrapper));}
or也可以嵌套
(4)nested
表示嵌套查询
@Testvoid testNested() {// nested表示嵌套查询, 用于构建复杂的查询条件LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.eq(User::getId, 1).nested(userLambdaQueryWrapper -> userLambdaQueryWrapper.eq(User::getAge, 18).or().eq(User::getAge, 20)); // 查询id为1并且年龄为18或20的用户System.out.println(userMapper.selectList(wrapper));}
10、自定义查询
使用apply函数
可以定制更复杂的查询条件
@Testvoid testApply() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// apply方法用于拼接SQL语句,这里需要使用实际开发中的业务逻辑来替换wrapper.apply("id = 1"); // 查询id为1的用户System.out.println(userMapper.selectList(wrapper));}
11、last
last主要用于分页查询中,需要传入字符串参数
@Testvoid testLast() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.last("limit 1"); // 查询第一个用户System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user limit 1
@Testvoid testLast() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();wrapper.last("limit 0, 2"); // 查询前两条数据System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user limit 0, 2
12、exists
@Testvoid testExists() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// 查询age为18的用户是否存在,如果存在则返回true,否则返回false// 返回true后,会继续执行后面的查询操作wrapper.exists("select id from user where age = 18");System.out.println(userMapper.selectList(wrapper));}
SELECT id,name,age,email FROM user WHERE (EXISTS (select id from user where age = 18))
@Testvoid testNotExists() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// 查询age为18的用户是否不存在,如果不存在则返回true,否则返回false// 返回true后,会继续执行后面的查询操作wrapper.notExists("select id from user where age = 18");System.out.println(userMapper.selectList(wrapper));}
二、主键策略
1、AUTO
需要在表的主键上设置自增,然后在实体类上的对应的属性上加上注解
@TableId(type = IdType.AUTO)
private Long id;
这样设置后,每次增加一条数据时,会自动生成对应的id
2、INPUT
不需要在表的主键上设置自增,每次新增数据时需要自己设置id
@TableId(type = IdType.AUTO)
private Long id;
3、ASSIGN_ID
使用雪花算法可以实现有序、唯一、且不直接暴露排序的数字
@TableId(type = IdType.ASSIGN_ID)
private Long id;
4、NONE
使用该策略表示不指定主键生成策略,而是跟随全局策略,可以在配置文件中使用id-type指定全局主键策略
@TableId(type = IdType.NONE)
private Long id;
5、ASSIGN_UUID
UUID是全局唯一标识符,定义为一个字符串主键,采用32位字符组成,保证始终唯一,需要设置id的类型为字符串
@TableId(type = IdType.ASSIGN_UUID)
private Long id;
三、分页查询
首先需要编写配置类
以下适用于mybatis-plus 3.5以上版本
@Configuration
// @MapperScan("com.system.mybatisplus.mapper") // 如果在启动类上已经配置了,这里就不需要再配置了
public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();// DbType.MYSQL 表示数据库类型是mysqlinterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}
}
测试
@Testvoid testPage() {LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();// 创建一个分页对象,传入两个参数:当前页和每页显示的记录数IPage<User> pageParam = new Page<>(1, 2);// 调用分页查询的方法,将分页对象和查询条件对象传入userMapper.selectPage(pageParam, wrapper);// 从分页对象中获取分页数据System.out.println("总页数:" + pageParam.getPages());System.out.println("总记录数:" + pageParam.getTotal());System.out.println("当前页码:" + pageParam.getCurrent());System.out.println("每页显示的记录数:" + pageParam.getSize());}
一般会自定义查询语句,所以通用的写法如下
controller中
@RestController
public class UserController {@Autowiredprivate UserService userService;@GetMapping("/users/{page}/{limit}")public IPage<User> listPage(@PathVariable("page") Long page, @PathVariable("limit") Long limit) {// 创建一个分页对象,传入两个参数:当前页和每页显示的记录数IPage<User> pageParam = new Page<>(page, limit);// 调用Service中的方法,一般还会传入一个条件查询对象return userService.listPage(pageParam);}
}
Service中
public interface UserService extends IService<User> {IPage<User> listPage(IPage<User> pageParam);
}
@Service // 此注解用于标记这是一个service类,否则会报错,因为没有加@Service
// 此处继承ServiceImpl(ServiceImpl实现了IService接口),同时实现UserService接口
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {@Autowiredprivate UserMapper userMapper;@Overridepublic IPage<User> listPage(IPage<User> pageParam) {return userMapper.selectUserByPage(pageParam);}
}
mapper中
@Mapper // 此注解用于标记这是一个mybatis的mapper类,否则会报错,因为没有加@Mapper
public interface UserMapper extends BaseMapper<User> {// 返回值是一个IPage对象IPage<User> selectUserByPage(IPage<User> pageParam); // 传入分页参数
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.system.mybatisplus.mapper.UserMapper"><select id="selectUserByPage" resultType="com.system.mybatisplus.model.User">select * from user</select>
</mapper>
四、SimpleQuery
SimpleQuery可以对selectList查询后的结果使用Stream流进行了一些封装,使其可以返回一些指定结果,简化了Api的调用。
1、list
例如,查询出所有User的姓名,返回一个List
使用Stream流
@Testvoid testList() {List<User> users = userMapper.selectList(null);// 自己调用Stream的ApiList<String> names = users.stream().map(User::getName).toList();names.forEach(System.out::println);}
使用SimpleQuery的list
// 必须传入一个wrapper,而不能写null
List<String> names = SimpleQuery.list(new LambdaQueryWrapper<User>(), User::getName);names.forEach(System.out::println);
获取年龄为20的用户姓名列表
List<String> names = SimpleQuery.list(new LambdaQueryWrapper<User>().eq(User::getAge, 20), User::getName);System.out.println(names);
[Jack, Billie]
2、map
可以指定键值对
以id为键,user对象为值
Map<Long, User> map = SimpleQuery.keyMap(new LambdaQueryWrapper<>(), User::getId);System.out.println(map);
只查询age为20的User
Map<Long, User> map = SimpleQuery.keyMap(new LambdaQueryWrapper<User>().eq(User::getAge, 20), User::getId);System.out.println(map);
以id为键,name为值
这里需要使用map方法,第二、三个参数分别表示要获得的键、值
Map<Long, String> longUserMap = SimpleQuery.map(new LambdaQueryWrapper<User>(), User::getId, User::getName);System.out.println(longUserMap);
{1=Jone, 2=Jack, 3=Tom, 4=Sandy, 5=Billie, 6=test}
3、group
可以按照字段进行分组
比如,按照年龄进行分组
使用group方法,第二个参数是待分组字段
Map<Integer, List<User>> group = SimpleQuery.group(new LambdaQueryWrapper<User>(), User::getAge);System.out.println(group);
五、逻辑删除
逻辑删除的目的是方便做统计,状态可恢复(用户的可用与禁用)
首先数据库中的表字段添加status

并使用默认值1,表示未删除
然后Java实体类添加对应的属性
@TableLogic(value = "1", delval = "0") // value是默认值,即未删除,delVal是删除时的值private Integer status;
测试
@Testvoid testLogicDelete() {userMapper.deleteById(4L);System.out.println(userMapper.selectList(null));}
首先执行
UPDATE user SET status=0 WHERE id=? AND status=1
将id为4的user的status更新为0,表示删除
然后再次查询
SELECT id,name,age,email,status FROM user WHERE status=1
查询时都会看status是否为1(未删除)
可以全局配置逻辑删除字段及其值

六、通用枚举
例如,对性别字段使用枚举
0–女性, 1–男性
数据库表中添加字段

Java中编写枚举
public enum GenderEnum {MAN(1, "男"), WOMAN(0, "女");@EnumValue // 表示插入到数据库中的是gender,即0或1private Integer gender;private String genderName;GenderEnum(Integer gender, String genderName){this.gender = gender;this.genderName = genderName;}
}
User属性
private GenderEnum gender; // 必须是gender,对应0或1
测试插入
@Testvoid testEnum() {User user = new User();user.setName("zzs");user.setGender(GenderEnum.MAN); // 使用枚举值userMapper.insert(user);}
测试查询
System.out.println(userMapper.selectList(null));
[User(id=1, name=Jone, age=18, email=test1@baomidou.com, isOnline=null, status=1, gender=MAN), User(id=2,
输出的gender是MAN
七、字段处理器
实体类中使用Map集合作为属性接受前端传递的数据,但是这些数据在数据库中存储时,是使用JSON格式的数据进行存储,JSON本质上是一个字符串,即数据库中的varchar类型。要将实体类的Map类型和数据库中的varchar类型的数据相互转换,可以使用字段处理器来完成。
首先在实体类中添加一个Map集合
private Map<String, String> contact; // 联系方式,可以有两种,即手机号和座机号
在数据库中添加对应的表字段contact,设置为varchar类型。
再次修改实体类,需要添加两个地方
@TableName(value = "user", autoResultMap = true) @TableField(typeHandler = FastjsonTypeHandler.class)
private Map<String, String> contact; // 联系方式,可以有两种,即手机号和座机号
整体代码如下:
// 使用字段处理器,需要 autoResultMap = true
@TableName(value = "user", autoResultMap = true) // 指定表名,如果表名和类名一致,可以省略
@Data
public class User implements Serializable { // 实现序列化接口@TableId(type = IdType.AUTO)private Long id;@TableField("name") // 指定表字段名,如果字段名和属性名一致,可以省略private String name;// @TableField(select = false) // select = false 表示查询时不查询该字段private Integer age;private String email;@TableField(exist = false) // exist = false 表示该字段不是数据库字段,但是可以使用private Boolean isOnline;@TableLogic(value = "1", delval = "0") // value是默认值,即未删除,delVal是删除时的值private Integer status;private GenderEnum gender;// 使用FastjsonTypeHandler@TableField(typeHandler = FastjsonTypeHandler.class)private Map<String, String> contact; // 联系方式,可以有两种,即手机号和座机号
}
添加fastjson依赖
<!-- fastjson--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.31_noneautotype</version></dependency>
测试插入,即Map转JSON
@Testvoid testMapToJson(){User user = new User();user.setName("xxx");user.setAge(23);user.setGender(GenderEnum.MAN);// 添加Map集合Map<String, String> map = new HashMap<>();map.put("phone", "19122345566");map.put("tel", "001-123456");user.setContact(map);userMapper.insert(user);}
在数据库中contact字段存储如下
{"phone":"19122345566","tel":"001-123456"}
测试查询,即JSON转Map
@Testvoid testJsonToMap(){System.out.println(userMapper.selectList(null));}
contact={phone=19122345566, tel=001-123456}
八、自动填充
有一些属性,比如时间,我们可以设置为自动填充
在实体类User中添加两个属性
private Date createTime;private Date updateTime;
数据库对应字段 ,都是datetime类型

需要开启下划线和驼峰映射 map-underscore-to-camel-case: true
# mybatis-plus配置
mybatis-plus:global-config:banner: falseconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 打印sql语句map-underscore-to-camel-case: true # 下划线和小驼峰映射
设置自动填充时间
写一个工具类MyMetaHandler,定义插入和更新数据时怎么自动填充
@Component
public class MyMetaHandler implements MetaObjectHandler {@Overridepublic void insertFill(MetaObject metaObject) {// 插入数据时,两个时间都填充setFieldValByName("createTime", new Date(), metaObject);setFieldValByName("updateTime", new Date(), metaObject);}@Overridepublic void updateFill(MetaObject metaObject) {setFieldValByName("updateTime", new Date(), metaObject);}
}
在属性上写上注解
@TableField(fill = FieldFill.INSERT) // 插入时填充private Date createTime;@TableField(fill = FieldFill.INSERT_UPDATE) // 插入或更新时填充private Date updateTime;
设置时区对应
yml文件中连接数据库修改serverTimezone=Asia/Shanghai
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
数据库中新增查询,设置全局时间
SET GLOBAL time_zone = '+8:00';SELECT NOW(); // 测试,看是否与本地时间相同
测试,是否能够实现时间自动填充
插入新数据时,createTime和updateTime都自动填充
@Test
void testFillTime(){User user = new User();user.setName("nihao");user.setAge(23);user.setGender(GenderEnum.MAN);userMapper.insert(user);
}

修改数据时,updateTime自动修改
@Test
void updateTime(){User user = new User();user.setId(9L);userMapper.updateById(user);
}

九、防止全表更新与删除插件
在实际开发中,全表更新和删除是非常危险的操作,Mybatis-plus提供了一个插件可以防止全表更新。
在mybatis-plus配置类中添加上
interceptor.addInnerInterceptor(new BlockAttackInnerInterceptor());
整体代码
@Configuration
// @MapperScan("com.system.mybatisplus.mapper") // 如果在启动类上已经配置了,这里就不需要再配置了
public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();// DbType.MYSQL 表示数据库类型是mysqlinterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));// 防止全表更新插件interceptor.addInnerInterceptor(new BlockAttackInnerInterceptor());return interceptor;}
}
测试
@Test
void updateBlock(){User user = new User();user.setGender(GenderEnum.MAN);userMapper.update(user, null);
}
以上代码更新时未设置条件,就会导致所有数据的性别改为MAN
但是设置了防止全表更新的插件后,mybatis-plus会自动报错,抛出异常

十、逆向工程-MybatisX插件
在idea插件市场中找到插件并且安装

连接数据库,点击红线处


自动生成SQL
在mapper里面写上方法名,然后选中,再Alt+enter

十一、并发问题分析
- 乐观锁
乐观锁是通过表字段完成设计的,其核心思想是,在读取的时候不加锁,其他请求依然可以读取到这个数据,在修改的时候判断这个数据是否有被修改过,如果有被修改过,那么本次请求的修改操作失败。
具体的SQL是这样实现的
update 表 set 字段 = 新值, version = version + 1 where version = 1
这样做不会对数据读取产生影响,并发的效率较高,但是目前看到的数据可能不是真实的数据,是被修改之前的,这在多数情况下是不会产生很大的影响。例如,有时候我们看到某种商品是有库存的,或者都加入到购物车了,但是点进去发现库存不足了。
- 悲观锁
悲观锁是在查询的时候就锁定数据,在这次请求未完成之前,不会释放锁。等到这次请求完毕后,再释放锁,释放了锁之后,其他请求才可以对这条数据完成读写。
这样做能够保证读取到的信息就是当前的信息,保证了信息的准确性,但是并发效率很低。
所以,实际开发中,使用悲观锁的场景很少,因为需要保持效率。
乐观锁实现
首先在数据库中添加字段version,默认值为1

然后在实体类User中添加对应的字段
@Versionprivate Integer version;
在mybatis-plus配置类中添加乐观锁插件
// 乐观锁插件interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
测试并发修改
@Testvoid testLock(){// 模拟操作1的查询User user1 = userMapper.selectById(9L);System.out.println("user1查询结果" + user1);// 模拟操作2的查询User user2 = userMapper.selectById(9L);System.out.println("user2查询结果" + user2);// 模拟操作1的修改user1.setName("zhangsan");userMapper.updateById(user1);// 模拟操作2的修改user2.setName("lisi");userMapper.updateById(user2);}

结果只有操作1修改成功,说明乐观锁生效
都能查询到,但是只有操作1修改成功,因为操作1修改时,version未发生变化,但是操作2修改时,version被操作1修改为2了。
user1查询结果User(id=9, name=nihao, age=23, email=null, isOnline=null, status=1, gender=MAN, contact=null, createTime=Thu Sep 07 08:48:53 CST 2023, updateTime=Thu Sep 07 08:52:48 CST 2023, version=1)user2查询结果User(id=9, name=nihao, age=23, email=null, isOnline=null, status=1, gender=MAN, contact=null, createTime=Thu Sep 07 08:48:53 CST 2023, updateTime=Thu Sep 07 08:52:48 CST 2023, version=1)
十二、代码生成器
打开mybatis-plus的官网,找到代码生成器章节
适用版本:mybatis-plus-generator 3.5.1 及其以上版本,对历史版本不兼容!3.5.1 以下的请参考 代码生成器旧
首先引入依赖
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-generator</artifactId><version>最新版本</version>
</dependency>
本人使用的mybatis-plus版本
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version></dependency>
所以mybatis-plus-generator我也使用3.5.3.1
写个main方法执行
FastAutoGenerator.create("url", "username", "password").globalConfig(builder -> {builder.author("baomidou") // 设置作者.enableSwagger() // 开启 swagger 模式.fileOverride() // 覆盖已生成文件.outputDir("D://"); // 指定输出目录}).dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {int typeCode = metaInfo.getJdbcType().TYPE_CODE;if (typeCode == Types.SMALLINT) {// 自定义类型转换return DbColumnType.INTEGER;}return typeRegistry.getColumnType(metaInfo);})).packageConfig(builder -> {builder.parent("com.baomidou.mybatisplus.samples.generator") // 设置父包名.moduleName("system") // 设置父包模块名.pathInfo(Collections.singletonMap(OutputFile.xml, "D://")); // 设置mapperXml生成路径}).strategyConfig(builder -> {builder.addInclude("t_simple") // 设置需要生成的表名.addTablePrefix("t_", "c_"); // 设置过滤表前缀}).templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板.execute();
十三、SQL分析打印
需要查看执行的SQL语句时,以及了解它的执行时间,方便分析是否出现了慢SQL问题,可以使用mybatis-plus提供的SQL分析打印的功能,来获取SQL语句执行的时间。
首先引入依赖
<!-- SQL分析打印依赖--><dependency><groupId>p6spy</groupId><artifactId>p6spy</artifactId><version>3.9.1</version></dependency>
修改yml文件中连接数据库的驱动和URL
jdbc:p6spy:mysql
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
# 配置数据库
spring:datasource:username: rootpassword: 123456url: jdbc:p6spy:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghaidriver-class-name: com.p6spy.engine.spy.P6SpyDriver #com.mysql.cj.jdbc.Driver
创建

module.log=com.p6spy.engine.logging.P6LogFactory,com.p6spy.engine.outage.P6OutageFactory
# 自定义日志打印
logMessageFormat=com.p6spy.engine.spy.appender.SingleLineFormat
#logMessageFormat=com.p6spy.engine.spy.appender.CustomLineFormat
#customLogMessageFormat=%(currentTime) | SQL耗时: %(executionTime) ms | 连接信息: %(category)-%(connectionId) | 执行语句: %(sql)
# 使用控制台记录sql
appender=com.p6spy.engine.spy.appender.StdoutLogger
## 配置记录Log例外
excludecategories=info,debug,result,batc,resultset
# 设置使用p6spy driver来做代理
deregisterdrivers=true
# 日期格式
dateformat=yyyy-MM-dd HH:mm:ss
# 实际驱动
driverlist=com.mysql.cj.jdbc.Driver
# 是否开启慢SQL记录
outagedetection=true
# 慢SQL记录标准 秒
outagedetectioninterval=2
十四、多数据源
首先添加依赖
<!--多数据源依赖 --><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.1.0</version></dependency>
spring:datasource:dynamic:primary: master #设置默认的数据源或者数据源组,默认值即为masterstrict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源datasource:master:url: jdbc:mysql://xx.xx.xx.xx:3306/dynamicusername: rootpassword: 123456driver-class-name: com.mysql.jdbc.Driver # 3.2.0开始支持SPI可省略此配置slave_1:url: jdbc:mysql://xx.xx.xx.xx:3307/dynamicusername: rootpassword: 123456driver-class-name: com.mysql.jdbc.Driverslave_2:url: ENC(xxxxx) # 内置加密,使用请查看详细文档username: ENC(xxxxx)password: ENC(xxxxx)driver-class-name: com.mysql.jdbc.Driver#......省略#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2
# 多主多从 纯粹多库(记得设置primary) 混合配置
spring: spring: spring:datasource: datasource: datasource:dynamic: dynamic: dynamic:datasource: datasource: datasource:master_1: mysql: master:master_2: oracle: slave_1:slave_1: sqlserver: slave_2:slave_2: postgresql: oracle_1:slave_3: h2: oracle_2:
使用 @DS 切换数据源。
@DS 可以注解在方法上或类上,同时存在就近原则 方法上注解 优先于 类上注解。
| 注解 | 结果 |
|---|---|
| 没有@DS | 默认数据源 |
| @DS(“dsName”) | dsName可以为组名也可以为具体某个库的名称 |
相关文章:
MyBatis-Plus学习笔记总结
一、查询 构造器分为QueryWrapper和LambdaQueryWrapper 创建实体类User package com.system.mybatisplus.model;import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableField; import com.baomidou.mybatisplus.annotation.…...

How Language Model Hallucinations Can Snowball
本文是LLM系列文章,针对《How Language Model Hallucinations Can Snowball》的翻译。 语言模型幻觉是如何产生雪球的 摘要1 引言2 为什么我们期待幻觉像滚雪球一样越滚越大?3 实验4 我们能防止雪球幻觉吗?5 相关工作6 结论局限性 摘要 在实…...
autojs修改顶部标题栏颜色
顶部标题栏的名字是statusBarColor 不是toolbar。难怪我搜索半天搜不到 修改之后变成这样了 代码如下: "ui"; importClass(android.view.View); importClass(android.graphics.Color); ui.statusBarColor(Color.parseColor("#ffffff")); ui.…...
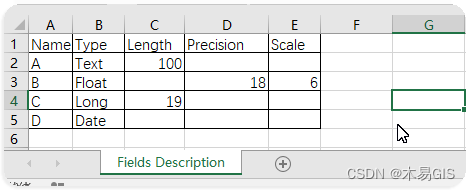
arppy gis 读取text 并批量添加字段 arcpy.AddField_management
arppy gis 读取text 并批量添加字段 arcpy.AddField_management 例:给“省级行政区域”添加“A、B、C、D” 4个字段。 (1)用Excel制作出字段及其描述表,定义字段结构; (2)复制除标题行以为的内…...

Pandas中at、iat函数详解
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 at 函数:通过行名和列名来取值(取行名为a, 列名为A的值) iat 函数:通过行号和列号来取值(取第1行,第1列的值) 本文给出at、iat常见的…...
【Spring Boot】JPA — JPA入门
JPA简介 1. JPA是什么 JPA是Sun官方提出的Java持久化规范,它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据,通过注解或者XML描述“对象-关系表”之间的映射关系,并将实体对象持久化到数据库中,极大地简…...
)
c#反射(Reflection)
当我们在C#中使用反射时,可以动态地获取和操作程序集、类型和成员。下面是一个简单的C#反射示例,展示了如何使用反射来调用一个类的方法: using System; using System.Reflection;public class MyClass {public void MyMethod(){Console.Wri…...

Lua 元表和元方法
一、元表 元表可以修改一个值在面对一个未知操作时的行为,Lua 中使用 table 作为元表的承载。 元表只能给出预先定义的操作集合的行为,比类会更加受限制,不支持继承。 Lua 每一个值都可以有元表 : 表和用户数据类型都具有各自…...
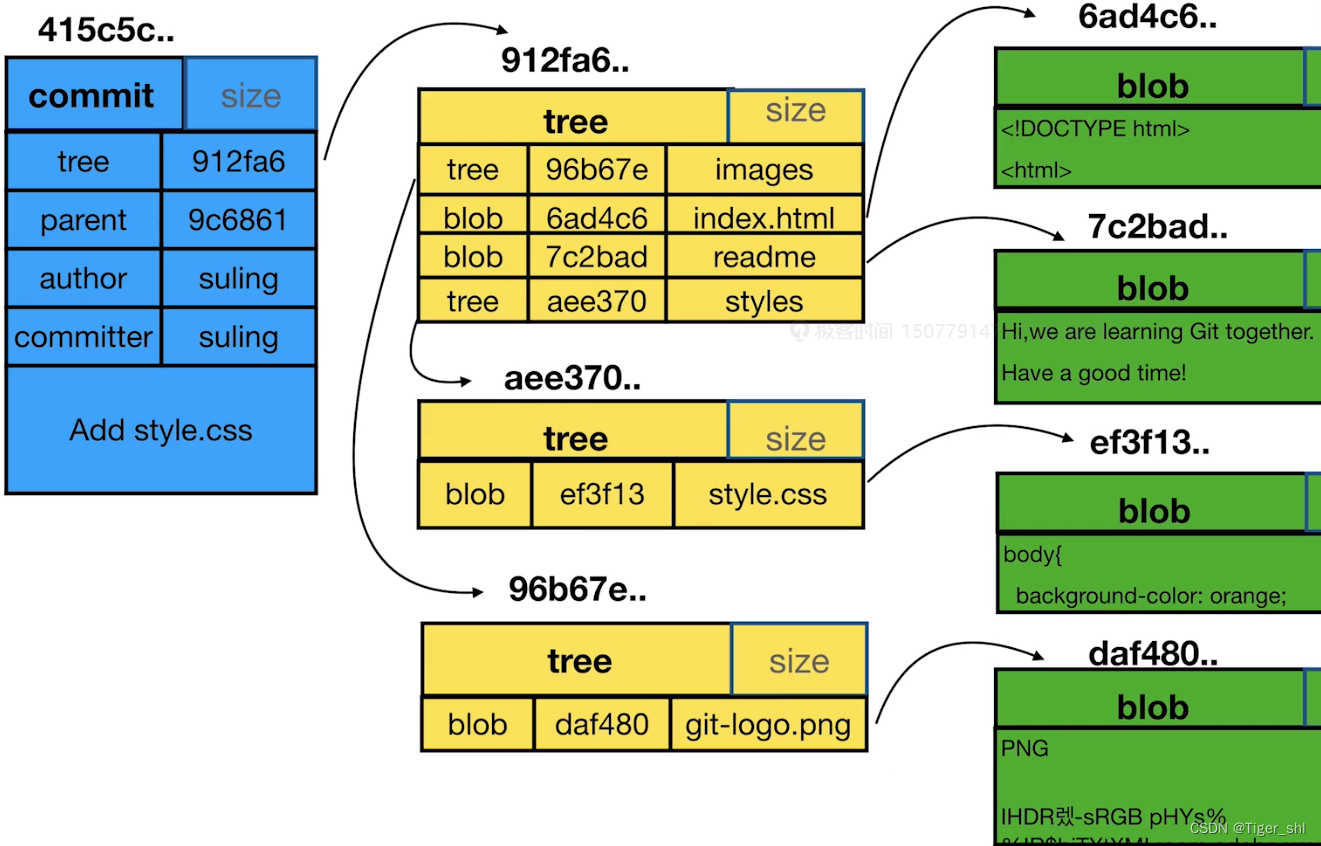
【Git】01-Git基础
文章目录 Git基础1. 简述1.1 版本管理演变1.2 Git的特点 2. Git安装2.1 安装文档2.1 配置user信息 3. 创建仓库3.1 场景3.2 暂存区和工作区 4. 重命名5. 常用git log版本历史5.1 查看当前分支日志5.2 简洁查看日志5.3 查看最近指定条数的日志 6. 通过图形界面工具查看版本7. 探…...

【Vue2.0源码学习】生命周期篇-初始化阶段(initState)
文章目录 1. 前言2. initState函数分析3. 初始化props3.1 规范化数据3.2 initProps函数分析3.3 validateProp函数分析3.4 getPropDefaultValue函数分析3.5 assertProp函数分析 4. 初始化methods5. 初始化data6. 初始化computed6.1 回顾用法6.2 initComputed函数分析6.3 defineC…...

专升本英语零基础学习
1. 词法 1.1 名词 名词(n.),是词类的一种,属于实词。他表示人,物,事,地点或抽象概念的统一名称。 1.1 名词的含义 名词(n.),是词类的一种,属于实词。他表示人&#x…...
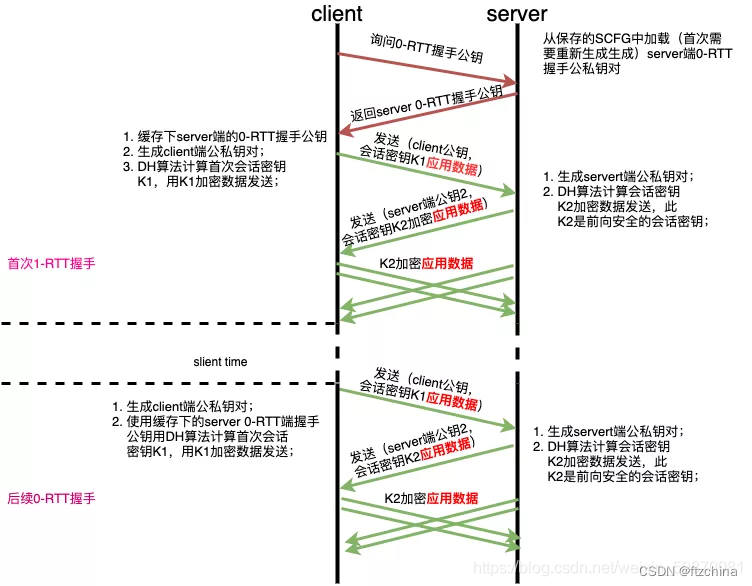
QUIC协议连接详解(二)
目录 一:RTT解释 二:QUIC 1-RTT连接 三:QUIC 0-RTT连接 一:RTT解释 在介绍QUIC协议的连接之前先科普一下什么是RTT。RTT是Round-Trip Time的英文缩写,翻译过来就是一趟来回的时间即往返时延。时间计算即从发送方发送…...

JAVA 经常遇到一些问题【第二部分36~51】
重拾者: 每日记录至目前(记录51种不同场景的问题可参考解决方案) 异常就两部分: 1、excepiton信息: 报错产生的原因 2、at开头表示: 异常产生的代码位置。 欢迎关注本人微信公众号:AIM…...

蓝桥杯打卡Day6
文章目录 N的阶乘基本算术整数查询 一、N的阶乘OI链接 本题思路:本题是关于高精度的模板题。 #pragma GCC optimize(3) #include <bits/stdc.h>constexpr int N1010;std::vector<int> a; std::vector<int> f[N];std::vector<int> mul(in…...

spark集群问题汇总
一、 磁盘问题 问题描述可能原因解决措施core节点磁盘不足, 并且持续增加未开启spark-history的日志清理打开日志清理: spark.history.fs.cleaner.enabled task节点磁盘不足 APP应用使用磁盘过大: 1. 严重的数据倾斜 2. 应用本身数据量大 1. 解决数据倾斜 2. 加大资源, 增加e…...
WebServer 解析HTTP 请求报文
一、TCP 状态转换 浏览器访问网址,TCP传输全过程 二、TCP协议的通信过程 三、TCP 通信流程 // TCP 通信的流程 // 服务器端 (被动接受连接的角色) 1. 创建一个用于监听的套接字- 监听:监听有客户端的连接- 套接字:这…...

Golang开发--interface的使用
在Go语言中,接口(interface)是一种特殊的类型,它定义了一组方法的集合。接口为实现多态性提供了一种机制,允许不同的数据类型实现相同的方法,从而可以以统一的方式处理这些不同类型的对象。接口在Go中广泛用…...
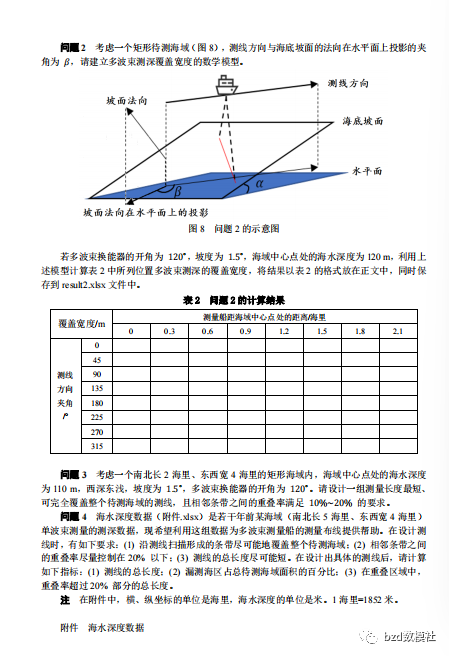
2023 年高教社杯全国大学生数学建模竞赛题目 B 题 多波束测线问题
B 题 多波束测线问题 单波束测深是利用声波在水中的传播特性来测量水体深度的技术。声波在均匀介质中作匀速直线传播,在不同界面上产生反射,利用这一原理,从测量船换能器垂直向海底发射声波信号,并记录从声波发射到信号接收的传播…...

leetcode算法题--生成特殊数字的最少操作
原题链接:https://leetcode.cn/problems/minimum-operations-to-make-a-special-number/description/ 感觉还是比较难想到的。。 func minimumOperations(num string) int {res : len(num)if strings.Contains(num, "0") {res-- }f : func(tail string)…...

数学建模--决策树的预测模型的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 """ 决策树的应用:对泰坦尼克号数据集成员进行预测生死 算法流程还是比较简单的,简单学习一下决策树跟着注释写即可 文章参考:https://zhuanlan.zhihu.com/p/133838427 算法种遇上sklear…...
报错的排查与解决实录)
从TCP连接被重置到下载成功:一次curl (35)报错的排查与解决实录
1. 当curl突然罢工:一次TCP连接重置的离奇遭遇 那天下午,我正在给一台CentOS 7服务器配置Docker环境。按照官方文档的指引,我需要用curl下载Docker Compose二进制文件。输入命令后,终端却弹出了让我心头一紧的报错: cu…...

探索改进型低电压穿越控制策略:光伏并网逆变器的关键突破
改进型低电压穿越控制策略(附带低穿新国标文件)1、限制直流母线过压和网侧过流的两级式三相光伏并网逆变器低电压穿越控制策略 光伏侧:PV板和Boost电路组成 逆变侧:LCL滤波器和电网 2、本仿真在传统两极式三相光伏并网逆变器低电压…...

别再只用Flash了!STM32F103的BKP备份寄存器实战:存20字节数据、做RTC校准、还能当事件记录器
STM32F103的BKP备份寄存器:20字节数据存储的隐藏利器 在嵌入式系统开发中,数据存储一直是个让人头疼的问题。Flash擦写次数有限,EEPROM速度慢,而SRAM掉电就丢数据。但你可能忽略了STM32F103芯片中一个低调却强大的功能——BKP备份…...

避坑指南:POI设置Excel下拉框时常见的5个问题及解决方案
POI实战避坑:Excel下拉框设置的5个典型问题与深度解决方案 在企业级数据导入导出场景中,Excel下拉框是提升数据规范性的重要功能。许多开发者在使用Apache POI实现这一功能时,往往会遇到各种"暗坑"。本文将基于真实项目经验&#x…...

Stable-Diffusion-v1-5-archive部署避坑指南:端口冲突/权限问题/日志轮转设置
Stable-Diffusion-v1-5-archive部署避坑指南:端口冲突/权限问题/日志轮转设置 你是不是也遇到过这种情况:好不容易找到一个经典的Stable Diffusion v1.5镜像,兴冲冲地部署起来,结果要么是端口被占用访问不了,要么是服…...

手把手教你用LangChain调用Qwen3-0.6B:小白也能轻松玩转大模型
手把手教你用LangChain调用Qwen3-0.6B:小白也能轻松玩转大模型 1. 认识Qwen3-0.6B大模型 Qwen3(千问3)是阿里巴巴集团开源的新一代通义千问大语言模型系列中的一员。这个0.6B参数的版本虽然体积相对较小,但已经具备了相当强大的…...

Visual Studio 2022下的MIDI音乐编程:如何用C语言模拟多种乐器音色
Visual Studio 2022下的MIDI音乐编程:如何用C语言模拟多种乐器音色 MIDI技术为数字音乐创作提供了无限可能。在Visual Studio 2022环境中,通过C语言调用Windows底层API,开发者可以构建能够模拟钢琴、吉他、笛子等多种乐器音色的音乐程序。这种…...

CoPaw模型在知识图谱构建中的应用:从非结构化文本中抽取实体与关系
CoPaw模型在知识图谱构建中的应用:从非结构化文本中抽取实体与关系 1. 引言:当知识管理遇上大模型 最近遇到一个头疼的问题:公司技术部门积累了海量的产品文档、技术报告和行业分析,但每次想查某个技术栈的关联信息,…...

CREST分子构象采样工具使用指南
CREST分子构象采样工具使用指南 【免费下载链接】crest Conformer-Rotamer Ensemble Sampling Tool based on the xtb Semiempirical Extended Tight-Binding Program Package 项目地址: https://gitcode.com/gh_mirrors/crest/crest 核心价值:为什么选择CRE…...

RMBG-2.0开源可部署价值:企业私有化部署规避SaaS数据外泄风险
RMBG-2.0开源可部署价值:企业私有化部署规避SaaS数据外泄风险 1. 引言:当你的图片数据成为别人的“训练素材” 想象一下这个场景:你是一家电商公司的运营负责人,每天需要处理上百张商品图片,为即将到来的大促活动准备…...