Python 算法交易实验48 表字段设计
说明
虽然说的是表,实际上用的是Mongo集合
基于ADBS(APIFunc DataBase Service)可以构造一个供后续研究、生产长时间使用的数据基础,这个基础包括了:
- 1 队列服务。通过队列,数据可以通过API实现零担和批量两种模式的快速存储。
- 2 灵活ETL。通过AETL,使用者可以实现高复杂性的操作,但从设计和实现上又非常灵活,这是一种基于图的分解和构建。
- 3 监控与可视化。可以实时看到数据的流入和流转。
ADBS通过简单的设置就可以不断扩展。
内容
其实也是权衡了一下,还是决定按照标准的步骤来推进量化,而不是通过离线代码、松散的实验来推进。
最初在设计ADBS的时候,除了功能性的考虑,也加入了规范性的考虑。一旦操作可以按流程进行,那么工作效率就会提升,可靠性也会提高。
搭建量化研究、生产体系的过程应该也是和搞架构一样,是一个结构性很强,耗时也很长的过程,所以最好按严谨的结构推进。至于核心的方法,在一开始反而可以简单,以跑通为目标。
架构中的算法(方法),或者算法(方法)中的架构总是互相交杂,缠绕在一起的。
本次的目的很简单,就是确定入库原始数据的表字段结构。
本质上,ADBS的数据库使用Mongo,并不会对字段进行太多约束,这里的表字段结构仅仅是从逻辑上约束。
这种约束是具有意义的,后续会有一系列的处理程序,如果能够对输入有所预期,那么在处理时也会比较容易设计。正如APIFunc中的设计经验:从样例数据开始设计总是方便、可靠的,而这里的表字段,也是这个大项目的样例数据表头。
Step1 DataETL 原始数据与基本衍生
Step1: In
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | rec_id | 是整个项目的主键,由下面的若干字段联合而成 ( market , code , data_slot) |
| 2 | data_slot | int, 数据时隙,是以分钟为单位的计时法,是记录数据的时间 |
| 3 | data_dt | str, 数据时间,是 YYYY-MM-DD HH:MM:SS 格式的字符时间,起到校验作用 |
| 4 | code | str, 证券代码,应该是唯一的 |
| 5 | market | str, 市场,与code联合形成绝对唯一的代码 |
| 6 | open | float, 开盘价 |
| 7 | close | float,收盘价 |
| 8 | high | float, 高点 |
| 9 | low | float, 低点 |
| 10 | vol | int, 成交量 |
| 11 | amt | float, 成交金额 |
| 12 | trades | int, 成交笔数 |
| 13 | float_capital | int, 流通值 |
第一步入库后,ADBS允许执行ETL,在这个时候允许做通用的特征项,这个特征项是与回顾周期相关的。
初始阶段,我打算手工指定若干个周期。
- 1 短期: 60,120, 240(一个交易日)
- 2 中期:600,1200,2400(十个交易日)
- 3 长期:6000,12000, 24000(一百个交易日)
Step1: Out
这些周期会形成一波新的变量,以下用T指代某个周期(原始的变量会同步被转存)
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | open_T | T的开盘价 |
| 2 | high_T | T的最高价 |
| 3 | low_T | T的最低价 |
| 4 | close_T | T的收盘价 |
| 5 | vol_T | T的成交量 |
| 6 | amt_T | T的成交金额 |
| 7 | trades_T | T的交易笔数 |
| 8 | vol_T_mean | T的平均(每时隙)成交量 |
| 9 | amt_T_mean | T的平均成交金额 |
| 10 | trades_T | T的平均成交笔数 |
Step2 Signals 信号生成
这个比较有意思,出现了第二个ADBS。
Step2.In = Step1.Out
通常来说,AETL允许对平面化的数据进行足够复杂的操作,但是,但需要的操作是深度式的时候,就需要进行级联了。
在设计ADBS时,为了确保复用性、稳定性,所以约定了每个ADBS只管一个step。第一个step中已经完成了原始数据,以及若干周期的简单衍生。
在这个step中,主要根据上一个step中生成的基本变量,生成交易信号。
这里探讨一个小问题:有没有可能在step1中同时完成交易信号?
理论上可能,但是真要这么做会非常麻烦,甚至会因为新的尝试而破坏旧的,运行中的东西。在上一步中,已经根据过去若干个周期进行了统计。在很多传统的新号计算方法里,会对若干周期的统计值,再进行若干周期统计。从阶数上来说是 T2T^2T2, 从计算的顺序来说肯定也是计算两次。
对具体的计算指标我回头再翻翻书,正好没带在身边。
| 序号 | 字段名 | 解释 |
|---|---|---|
| 1 | SOME_buy_T_t | 使用T周期对 t周期进行计算生成的买入信号 |
| 2 | SOME_sell_T_t | 使用T周期对 t周期进行计算生成的卖出信号 |
后续生成买入信号可能会有很多很多组,从周期上来说分为短期、长期等,从原理来说分为回归、周期以及动量。
Step2.Out 输出买卖的信号
到这一步,故事显然还没有结束。
Step3 Decision 交易信号与指令
Step3.In = Step2.Out 注意,交易信号与原始的价格无关(Step1.Out)
生成买入信号并不能允许直接交易,仅从决策角度看,就需要进行纵向和横向的参考。
例如,信号经常会出现毛刺噪声,如果仅仅一次买入信号就买入的话很容出错,所以会从纵向上进行持续观察,我称之为冷静时间。
除此之外,从宏观角度,我们还需要知道长周期趋势。这样的目的是为了避免在低概区交易,以及避免系统风险(断崖式、持续下跌)。
除了纵向,还要考虑横向的其他维度
未来肯定是多种方法的信号并存的,所以除了自身维度的信号判断之外,也可以考虑一种投票机制,来辅助作出交易决策。
决策作出之后,在真实的交易之前,还有一些小的步骤需要完成,就是交易指令。可以简单理解为加滑点进行买卖交易的策略,这个可以暂时略过。
不同的策略可能会基于同样的信号操作,所以要增加策略名来区别。策略名也可以按三级命名来操作。
Step3.Out 输出买卖的决定,以及交易信号
Step4 Trade 交易的撮合与记录
基于上一刻的决定和这一刻的数据进行操作
这里的输入有两个:
Step4.In = Step1.Out ~ 标的的时隙数据( open, close, high, low) &
Step3.Out ~ 在上个时隙作出交易决策 (target_price, amt, buy/sell)
我们总是先做好决定,然后再采取行动,无论这个先后差距长或者短,总是如此。量化不过是用更精细,更准确的方法来千百次的替代我们完成这个过程。
如果Step3中没有Open的决策(Open Orders),那么这一步就可以直接略过。反之,如果有决策没有被实现,那么Step4就会看在当前时隙是否可以完成。
这里假设了Step3中已经发出了自动化交易请求,实际上目前对于个人投资者用接口直接交易还是不太方便,但我们可以假定如此。
当target_price处于high和low之间时,交易被完成,否则就轮空。
轮空状态下,会有一些对应的处理方法。例如大量Open Orders是否要发起告警,或者是要调低目标价。
从整体上来看,Step4或者产生1/n个close order,或者什么也不做。
Step4.Out(if any) 输出完结订单
这样结束了吗?显然还不…
Step5 Watch 观察序列变化及干预
Always Watch Back
Step5.In = Step4.Out
Dalio在《原则》里有提到桥水的量化模型,当上线之后人就不干预了,直到触碰规则。所以,量化是一种 Run… Until …的模式。
我们会让策略上线,一定是有我们的期望,这既包括了好的期望,也包括了坏的准备。如同正态分布,我们不认为策略会超过3个西格玛。
因此,我们需要持续的观察,来确保一切尽在掌握。
Step5会在每个时间点进行回看,主要从几方面比较:
- 1 最大回撤是否超标
- 2 最大正收益是否超标(是的,我觉得这个也要看)
- 3 交易周期
- 4 资金敞口
- 5 超额收益
Step5.Out 收益曲线、回撤曲线等
这部分的结果会输出到我portal的dash board里。
Ending
总的说起来,这是一个由5个ADBS构成的处理流。我觉得这样才比较好解释,为啥之前总是半途而废:强行用简单的处理办法去容纳复杂问题就好比用一个杯子去装一壶水。分治其实是唯一的办法,分治核心在于结构。
以下是工作流的基本框架
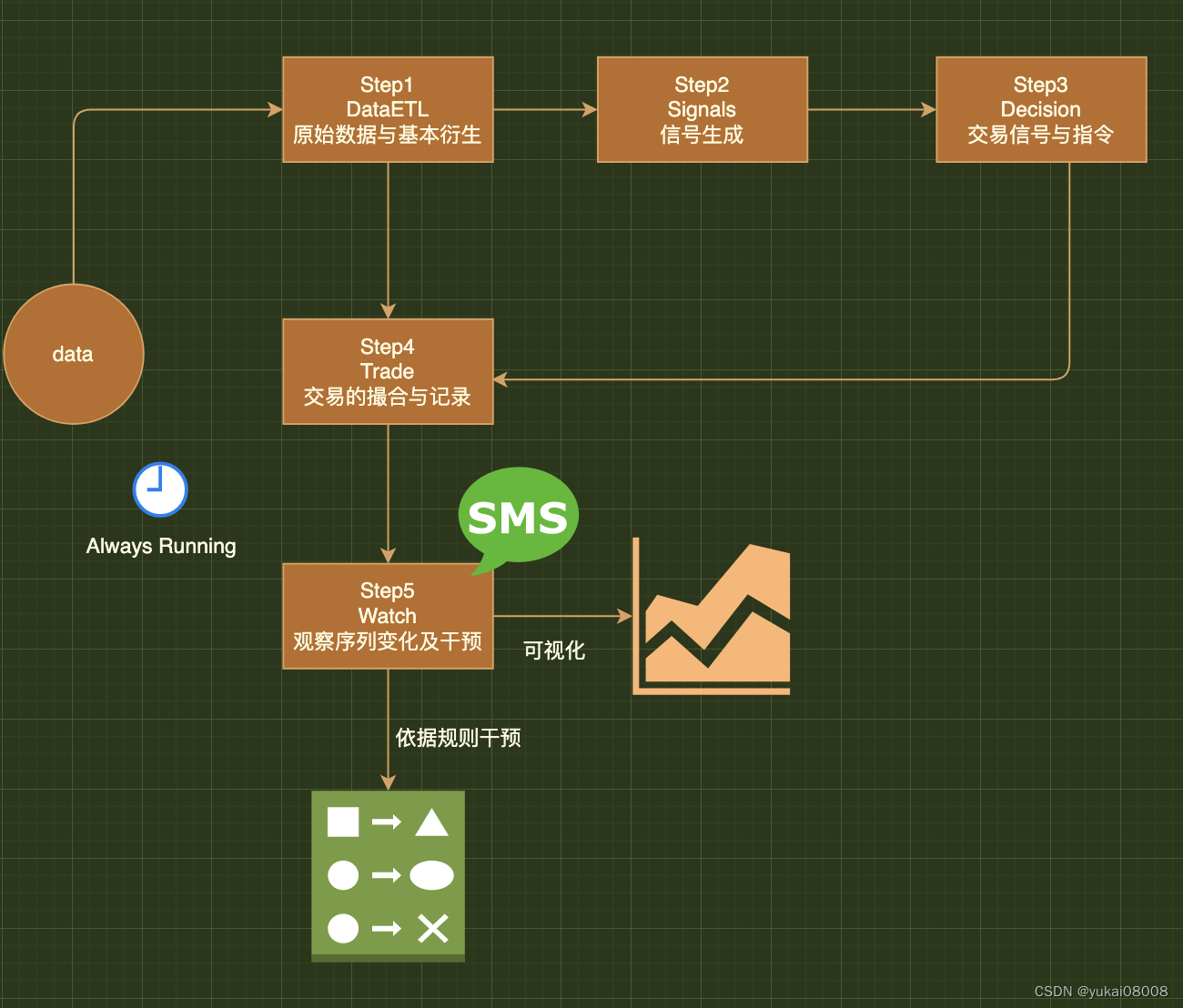
还有许多未尽部分,例如策略的中途叠加、多模型协同、生成式估计、自动优化等,这些在“1”完成了之后会逐步的进行迭代。
本次完成了“0”的突破-转变,算0.1吧。
相关文章:
Python 算法交易实验48 表字段设计
说明 虽然说的是表,实际上用的是Mongo集合 基于ADBS(APIFunc DataBase Service)可以构造一个供后续研究、生产长时间使用的数据基础,这个基础包括了: 1 队列服务。通过队列,数据可以通过API实现零担和批量两种模式的快速存储。2 …...

库存管理系统-课后程序(JAVA基础案例教程-黑马程序员编著-第六章-课后作业)
【案例6-1】 库存管理系统 【案例介绍】 1.任务描述 像商城和超市这样的地方,都需要有自己的库房,并且库房商品的库存变化有专人记录,这样才能保证商城和超市正常运转。 本例要求编写一个程序,模拟库存管理系统。该系统主要包…...
【极海APM32替代笔记】HAL库低功耗STOP停止模式的串口唤醒(解决进入以后立马唤醒、串口唤醒和回调无法一起使用、接收数据不全的问题)
【极海APM32替代笔记】HAL库低功耗STOP停止模式的串口唤醒(解决进入以后立马唤醒、串口唤醒和回调无法一起使用、接收数据不全的问题) 【STM32笔记】低功耗模式配置及避坑汇总 前文: blog.csdn.net/weixin_53403301/article/details/128216…...
)
Python类变量和实例变量(类属性和实例属性)
无论是类属性还是类方法,都无法像普通变量或者函数那样,在类的外部直接使用它们。我们可以将类看做一个独立的空间,则类属性其实就是在类体中定义的变量,类方法是在类体中定义的函数。 在类体中,根据变量定义的位置不…...

Glide加载图片
使用Glide加载图片,默认情况下在内存中缓存该图片。这样的情况下如果我们保存头像在某个路径,当再次更换头像时可能由于缓存问题,UI上更新的不及时。 默认加载图片方式: Glide.with(context).load(coverPath).error(R.drawable.a…...

有关时间复杂度和空间复杂度的练习
目录 一、消失的数字 二、轮转数组 三、 单选题 一、消失的数字 数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在 O(n) 时间内完成吗? 注意:本题相对书上原题稍作改动 示例 1: 输入…...

linux服务器nfs数据挂载
参考:https://blog.csdn.net/qq_43721935/article/details/119889841?from_wecom1 1、NFS 介绍 NFS 即网络文件系统(Network File-System),可以通过网络让不同机器、不同系统之间可以实现文件共享。通过 NFS,可以访问…...

Python 自动化测试必会技能板块—unittest框架
说到 Python 的单元测试框架,想必接触过 Python 的朋友脑袋里第一个想到的就是 unittest。的确,作为 Python 的标准库,它很优秀,并被广泛应用于各个项目。但其实在 Python 众多项目中,主流的单元测试框架远不止这一个。…...

mysql存储引擎、事务、索引
目录MySQL进阶存储引擎什么是存储引擎常用存储引擎事务什么是事务怎么理解提交事务 和回滚事务事务特性事务的隔离级别索引什么是索引索引的实现原理什么条件下,我们会考虑给字段添加索引呢?什么条件下,索引会失效?索引分类MySQL进阶 存储引…...
毕业论文图片格式、分辨率选择及高质量Word转PDF方法
已知1:毕业论文盲评通常需要提交PDF文件。 已知2:PDF文件太大可能会导致翻页卡顿以及上传盲评网站失败。 已知3:Word转PDF方法不当可能会导致图像模糊。 已知4:打印机分辨率通常为300dpi。 问题1:论文插图分辨率设置…...
华为外包测试2年,不甘被替换,168天的学习转岗成正式员工
我25岁的时候,华为外包测试,薪资13.5k,人在深圳。 内卷什么的就不说了,而且人在外包那些高级精英年薪大几十的咱也接触不到,就说说外包吧。假设以我为界限,25岁一线城市13.5k,那22-24大部分情况…...
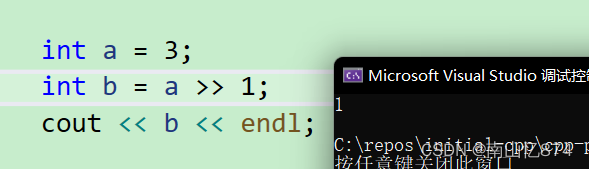
简单的C++:【运算符重载】新手易学
学过C语言的同志们应该都知道位运算符>> 和 << (右移左移),但是这两个运算符在C中还是我们的输入和输出流操作符,那么这是为什么呢?,了解完本篇文章之后,我们再来回答这个问题。 C为…...
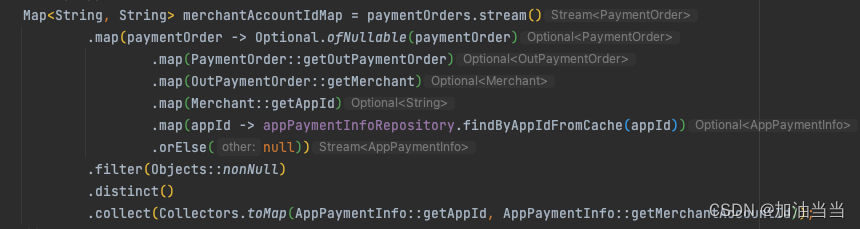
NPE:记一次脑残NPE的排查过程
目录 碎碎念: 如下这行报NPE: 排查过程: 解解方案: 小结: 空指针出现的几种情况: 如何从根源避免空指针: 赋值时自动拆箱出现空指针: 1、变量赋值自动拆箱出现的空指针 2、…...
canvas样式与颜色,字体,图片,状态,形变
色彩 fillStyle color 设置图形的填充颜色。 strokeStyle color 设置图形轮廓的颜色。 备注: 一旦您设置了 strokeStyle 或者 fillStyle 的值,那么这个新值就会成为新绘制的图形的默认值。如果你要给每个图形上不同的颜色,你需要重新设置…...
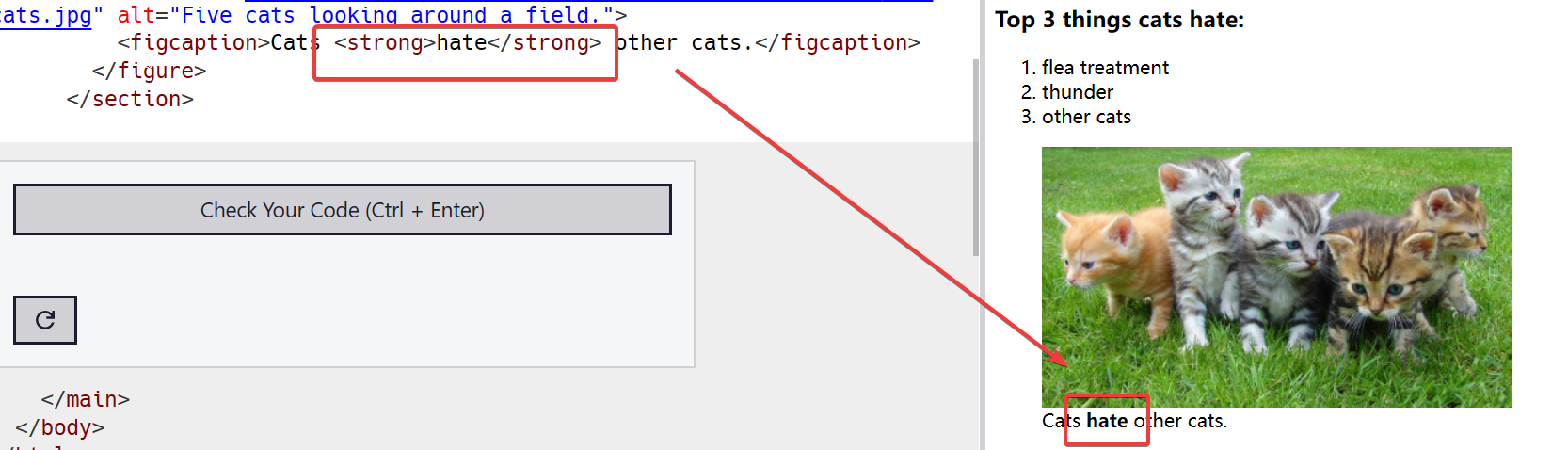
重识html
html 重识html 万维网用url统一资源定位符标识分布因特网上的各种文档 各种概念 URL: 统一资源定位器 它是WWW的统一资源定位标志,就是指网络地址 在WWW上,每一信息资源都有统一的且在网上唯一的地址 网页: 由文字 图片 视频 音乐各种元素排列组…...
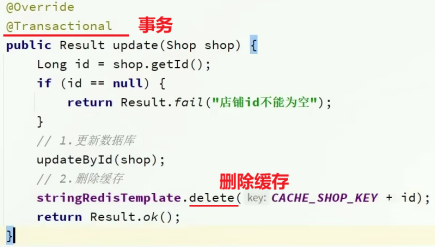
Redis:缓存一致性问题(缓存更新策略)
Redis缓存的一致性1. 缓存1.1 缓存的作用:1.2 缓存的成本:2. 缓存模型3. 缓存一致性问题3.1 引入3.2 解决(1) 先更新数据库,再手动删除缓存(2) 使用事务保证原子性(3) 以Redis中的TTL为兜底3.3 案例:商铺信息查询和更新(1) 查询商…...

spring之声明式事务开发
文章目录一、声明式事务之全注解式开发1、新建springConfig类2、测试程序3、测试结果二、声明式事务之XML实现方式1、配置步骤2、测试程序3、运行结果附一、声明式事务之全注解式开发 基于之前的银行转账系统,将spring.xml配置文件嘎掉,变成全注解式开发…...
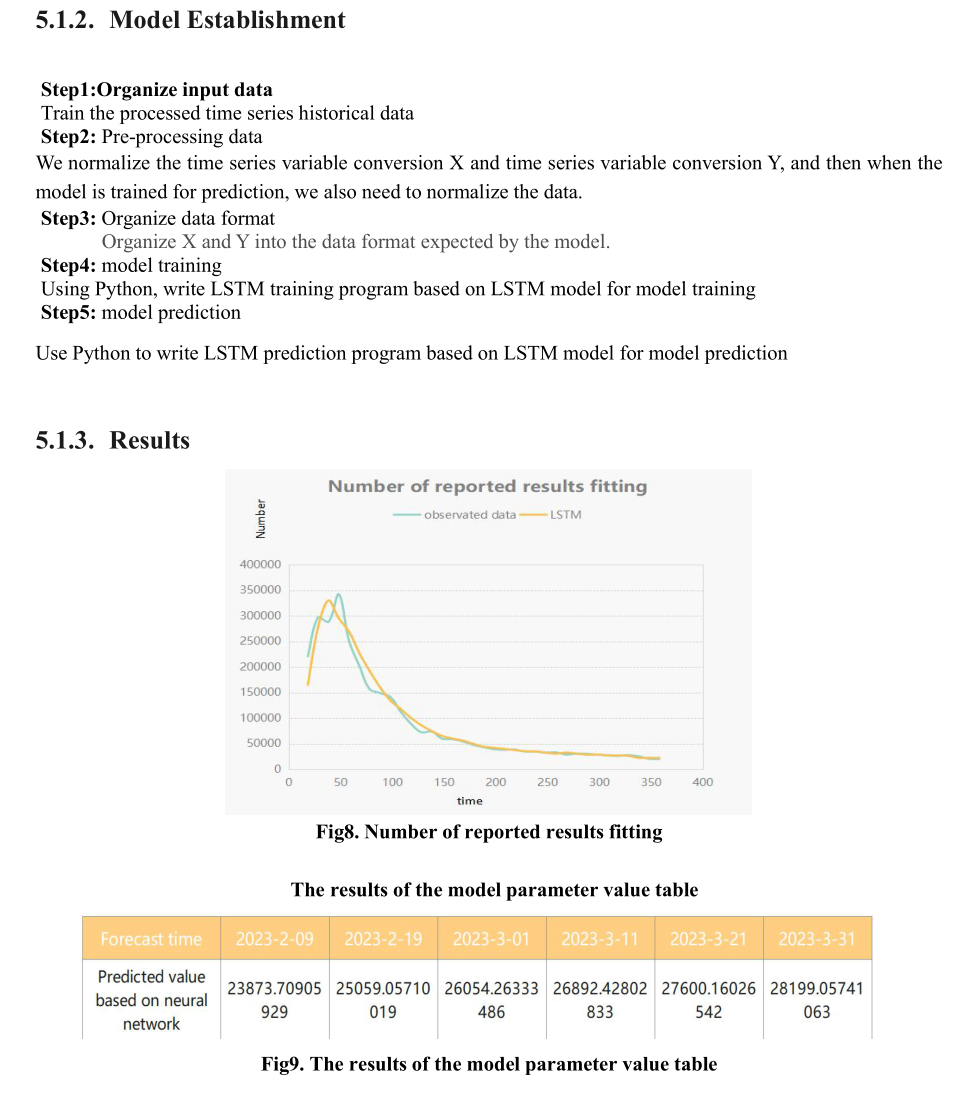
2023美赛参赛经历分享
今天早上登录MCM: The Mathematical Contest in Modeling (comap.com)发现论文提交已经显示Received。虽然这几天连连有开学恶补的期末考试,但还是忙里偷闲趁着新鲜写一篇关于美赛的参赛个人感受。跟我一起打这次美赛的都是软件等专业的hxd,他们之前没有…...

Elasticsearch在Linux中的单节点部署和集群部署
目录一、Elasticsearch简介二、Linux单节点部署1、软件下载解压2、创建用户3、修改配置文件4、切换到刚刚创建的用户启动软件5、测试三、Linux集群配置1、拷贝文件2、修改配置文件3、分别修改文件所有者4、启动三个软件5、测试四、问题总结1、在elasticsearch启动时如果报错内存…...

Scala的变量声明
文章目录变量声明(一)简单说明(二)利用val声明变量1,声明方式2,案例演示(三)利用var声明变量1,声明方式2,案例演示(四)换行输入语句&a…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...