C++学习笔记--函数重载(2)
文章目录
- 1.3、Function Templates Handling
- 1.3.1、Template Argument Deduction
- 1.3.2、Template Argument Substitution
- 1.4、Overload Resolution
- 1.4.1、Candidate functions
- 1.4.2、Viable functions
- 1.4.3、Tiebreakers
- 1.5、走一遍完整的流程
- 1.6、Name Mangling
- 1.7、总结
1.3、Function Templates Handling
Name Lookup 查找的名称若是包含函数模板,那么下一步就需要将这些函数模板实例化。
模板实例化有两个步骤,第一个步骤是 Template Argument Deduction,对模板参数进行推导;第二个步骤是 Template Argument Substitution,使用推导出来的类型对模板参数进行替换。
下面两节分别介绍模板参数推导与替换的细节。
1.3.1、Template Argument Deduction
模板参数本身是抽象的类型,并不真正存在,因此需要根据调用的实参进行推导,从而将类型具体化。
TAD 就描述了如何进行推导,规则是怎样的。
先来看一个简单的例子,感受一下基本规则。
template <class T, class U = double>
void f(T t = 0, U u = 0) {
}int main() {f(1, 'c'); // f<int, char>(1, 'c');f(1); // f<int, double>(1, 0)f(); // error: T cannot be duducedf<int>(); // f<int, double>(0, 0)f<int, char>(); // f<int, char>(0, 0)
}
调用的实参是什么类型,模板参数就自动推导为所调用的类型。如果模板参数具有默认实参,那么可以从其推导,也可以显式指定模板参数,但若没有任何参数,则不具备推导上下文,推导失败。
这里存在令许多人都比较迷惑的一点,有些时候推导的参数并不与调用实参相同。
比如:
template <class T>
void f(T t) {}int main() {const int i = 1;f(i); // T deduced as int, f<int>(int)
}
这里实参类型是 const int,但最后推导的却是 int。
这是因为,推导之时,所有的 top-level 修饰符都会被忽略,此处的 const 为 top-level const,于是 const 被丢弃。本质上,其实是因为传递过去的参数变量实际上是新创建的拷贝变量,原有的修饰符不应该影响拷贝之后的变量。
那么,此时如何让编译器推导出你想要的类型呢?
第一种办法,显示指定模板参数类型。
f<const int>(i); // OK, f<const int>(const int)
第二种办法,将模板参数声明改为引用或指针类型。
template <class T>
void f(T& t) { }
f(i); // OK, f<const int>(const int&)
为什么改为引用或指针就可以推导出带 const 的类型呢?
这是因为此时变量不再是拷贝的,它们访问的依旧是实参的内存区域,如果忽略掉 const,它们将能够修改 const 变量,这会导致语义错误。
因此,如果你写出这样的代码,推导将会出错:
template <class T>
void f(T t1, T* t2) { }int main() {const int i = 1;f(i, &i); // Error, T deduced as both int and const int
}
因为根据第一个实参,T 被推导为 int,而根据第二个实参,T 又被推导为 const int,于是编译失败。
若你显示指定参数,那么将可以消除此错误,代码如下:
template <class T>
void f(T t1, T* t2) { }int main() {const int i = 1;f<const int>(i, &i); // OK, T has const int type
}
此时,T 的类型只为 const int,冲突消除,于是编译成功。
下面介绍可变参数模板的推导规则。
看如下例子:
template <class T, class... Ts>
void f(T, Ts...) {
}template <class T, class... Ts>
void g(Ts..., T) {
}int main() {f(1, 'c', .0); // f<int, char, double>(int, char, double)//g(1, 'c', .0); // error, Ts is not deduced
}
此处规则为:参数包必须放到参数定义列表的最末尾,TAD 才会进行推导。
但若是参数包作为类模板参数出现,则不必遵循此顺序也可以正常推导。
template <class...>
struct Tuple {};template <class T, class... Ts>
void g(Tuple<Ts...>, T) {
}g(Tuple<int>{}, .0); // OK, g<int, double>(Tuple<int>, double)
如果函数参数是一个派生类,其继承自类模板,类模板又采用递归继承,则推导实参为其直接基类的模板参数。示例如下:
template <class...> struct X;
template <> struct X<> {};
template <class T, class... Ts>
struct X<T, Ts...> : X<Ts...> {};
struct D : X<int> {};template <class... Ts>
int f(const X<Ts...>&) {return {};
}int main() {int x = f(D()); // deduced as f<int>, not f<>
}
这里,最终推导出来的类型为 f,而非 f<>。
下面介绍 forwarding reference 的推导规则。
对于 forwarding reference,如果实参为左值,则模板参数推导为左值引用。看一个不错的例子:
template <class T> int f(T&& t);
template <class T> int g(const T&&);int main() {int i = 1;//int n1 = f(i); // #1, f<int&>(int&)//int n2 = f(0); // #2, f<int>(int&&);int n3 = g(i); // #3, g<int>(const int&&)// error: bind an rvalue reference to an lvalue
}
此处,f() 的参数为 forwarding reference,g() 的参数为右值引用。
因此,当实参为左值时,f() 的模板参数被推导为 int&,g() 的模板参数则被推导为 int。而左值无法绑定到右值,于是编译出错。
再来看另一个例子:
template <class T>
struct A {template <class U>A(T&& t, U&& u, int*); // #1A(T&&, int*); // #2
};template <class T> A(T&&, int*) -> A<T>; // #3
对于 #1,U&& 为 forwarding reference,而 T&& 并不是,因为它不是函数模板参数。
于是,当使用 #1 初始化对象时,若第一个实参为左值,则 T&& 被推导为右值引用。由于左值无法绑定到右值,遂编译出错。但是第二个参数可以为左值,U 会被推导为左值引用,次再施加引用折叠,最终依旧为左值引用,可以接收左值实参。
若要使类模板参数也变为 forwarding reference,可以使用 CTAD,如 #3 所示。此时,T&& 为forwarding reference,第一个实参为左值时,就可以正常触发引用折叠。
1.3.2、Template Argument Substitution
TAD 告诉编译器如何推导模板参数类型,紧随其后的就是使用推导出来的类型替换模板参数,将模板实例化。
这两个步骤密不可分,故在上节当中其实已经涉及了部分本节内容,这里进一步扩展。
这里只讲三个重点。
第一点,模板参数替换存在失败的可能性。
模板替换并不总是会成功的,比如:
struct A { typedef int B; };template <class T> void g(typename T::B*) // #1
template <class T> void g(T); // #2g<int>(0); // calls #2
Name Lookup 查找到了 #1 和 #2 的两个名称,然后对它们进行模板参数替换。然而,对于 #1 的参数替换并不能成功,因为 int 不存在成员类型 B,此时模板参数替换失败。
但是编译器并不会进行报错,只是将其从重载集中移除。这个特性就是广为熟知的SFINAE(Substitution Failure Is Not An Error),后来大家发现该特性可以进一步利用起来,为模板施加约束。
比如根据该原理可以实现一个 enable_if 工具,用来约束模板。
namespace mylib {template <bool, typename = void>struct enable_if {};template <typename T>struct enable_if<true, T> {using type = T;};template <bool C, typename T = void>using enable_if_t = typename enable_if<C, T>::type;
} // namespace mylibtemplate <typename T, mylib::enable_if_t<std::same_as<T, double>, bool> = true>
void f() {std::cout << "A\n";
}template <typename T, mylib::enable_if_t<std::same_as<T, int>, bool> = true>
void f() {std::cout << "int\n";
}int main() {f<double>(); // calls #1f<int>(); // calls #2
}
enable_if 早已加入了标准,这个的工具的原理就是利用模板替换失败的特性,将不符合条件的函数从重载集移除,从而实现正确的逻辑分派。
SFINAE 并非是专门针对类型约束而创造出来的,使用起来比较复杂,并不直观,已被 C++20的 Concepts 取代。
第二点,关于 trailing return type 与 normal return type 的本质区别。
这二者的区别本质上就是 Name Lookup 的区别:normal return type 是按照从左到右的词法顺序进行查找并替换的,而 trailing return type 因为存在占位符,打乱了常规的词法顺序,这使得它们存在一些细微的差异。
比如一个简单的例子:
namespace N {using X = int;X f();
}N::X N::f(); // normal return type
auto N::f() -> X; // trailing return type
根据前面讲述的 Qualified Name Lookup 规则,normal return type 的返回值必须使用 N::X,否则将在全局查找。而 trailing return type 由于词法顺序不同,可以省略这个命名空间。
当然 trailing return type 也并非总是比 normal return type 使用起来更好,看如下例子:
template <class T> struct A { using X = typename T::X; };
// normal return type
template <class T> typename T::X f(typename A<T>::X);
template <class T> void f(...);// trailing return type
template <class T> auto g(typename A<T>::X) -> typename T::X;
template <class T> void g(...);int main() {f<int>(0); // #1 OKg<int>(0); // #2 Error
}
通常来说,这两种返回类型只是形式上的差异,是可以等价使用的,但此处却有着细微而本质的区别。
#1 都能成功调用,为什么改了个返回形式,#2 就编译出错了?
这是因为:
在模板参数替换的时候,normal return type 遵循从左向右的词法顺序,当它尝试替换 T::X,发现实参类型 int 并没有成员 X,于是依据 SFINAE,该名称被舍弃。然后,编译器发现通用版本的名称可以成功替换,于是编译成功。
而 #2 在模板参数替换的时候,首先跳过 auto 占位符,开始替换函数参数。当它尝试使用 int 替换 A::X 的时候,发现无法替换。但是 A::X 并不会触发 SFINAE,而是产生 hard error,于是编译失败。
简单来说,此处,normal return type 在触发 hard error 之前就触发了 SFINAE,所以可以成功编译。
第三点,forwarding reference 的模板参数替换要点。
看一个例子:
template <class T>
struct S {static void g(T&& t) {}static void g(const T& t) {}
};template <class T> void f(T&& t) {}
template <class T> void f(const T& t) {}int main() {int i = 1;f<int&>(i); // #1 OKS<int&>::g(i); // #2 Error
}
为什么 #1 可以通过编译,而 #2 却不可以呢?
首先来分析 #2,编译失败其实显而亦见。
由于调用显式指定了模板参数,所以其实并没有参数推导,int& 用于替换模板参数。对于 T&&,替换为 int&&&,1 折叠后变为 int&;对于 const T&,替换为 const (int&)&,等价于 int& const&,而C++ 不支持 top-level reference,int& const 声明本身就是非法的,所以 const 被抛弃,剩下 int&&,折叠为 int&。
于是重复定义,编译错误。
而对于 #1,它包含两个函数模板。若是同时替换,那么它们自然也会编译失败。但是,根据 4.3将要介绍的规则:如果都是函数模板,那么更特殊的函数模板胜出。const T& 比 T&& 更加特殊,因此 f(T&&) 最终被移除,只存在 f(const T&) 替换之后的函数,没有错误也是理所当然。
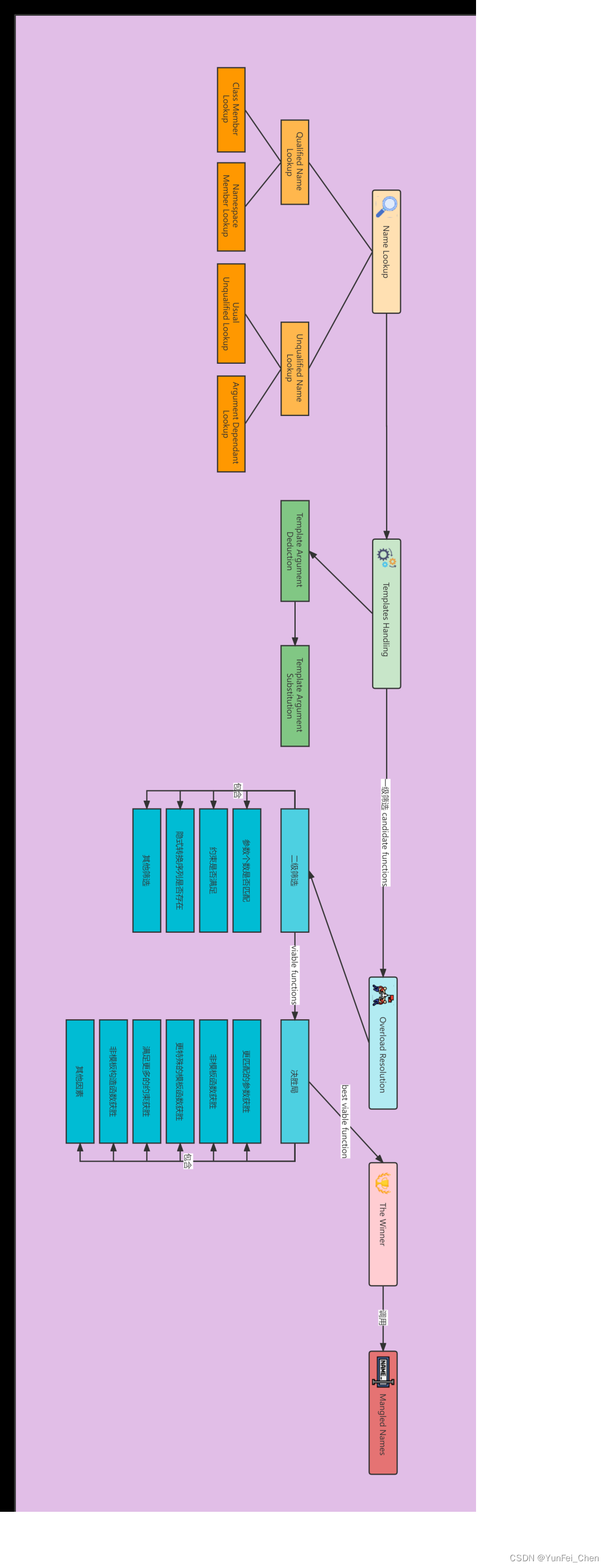
1.4、Overload Resolution
经过 Name Lookup 和 Template Handling 两个阶段,编译器搜索到了所有相关重载函数名称,这些函数就称为 candidate functions(候选函数)。
前文提到过,Name Lookup 仅仅只是进行名称查找,并不会检查这些函数的有效性。因此,candidate functions 只是「一级筛选」的结果。
重载决议,就是要在一级筛选的结果之上,选择出最佳的那个匹配函数。
比如:参数个数是否匹配?实参和形参的类型是否相同?类型是否可以转换?这些都属于筛选准则。
因此,这一步也可以称之为「二级筛选」。根据筛选准则,剔除掉无效函数,剩下的结果就称为viable functions(可行函数)。
存在 viable functions,就表示已经找到可以调用的声明了。但是,这个函数可能存在多个可用版本,此时,就需要进行「终极筛选」,选出最佳的匹配函数,即 best viable function。终极筛选在标准中也称为 Tiebreakers(决胜局)。
终极筛选之后,如果只会留下一个函数,这个函数就是最终被调用的函数,重载决议成功;否则的话重载决议失败,程序错误。
接下来,将从一级筛选开始,以一个完整的例子,为大家串起整个流程,顺便加深对前面各节内容的理解。
1.4.1、Candidate functions
一级筛选的结果是由 Name Lookup 查找出来的,包含成员和非成员函数。
对于成员函数,它的第一个参数是一个额外的隐式对象参数,一般来说就是 this 指针。
对于静态成员函数,大家都知道它没有 this 指针,然而事实上它也存在一个额外的隐式对象参数。究其原因,就是为了重载决议可以正常运行。
可以看如下例子来进行理解。
struct S {void f(long) {std::cout << "member version\n";}static void f(int) {std::cout << "static member version\n";}
};
int main() {S s;s.f(1); // calls static member version
}
此时,这两个成员函数实际上为:
f(S&, long); // member version
f(implicit object parameter, int); // static member version
如果静态成员函数没有这个额外的隐式对象,那么其一,将可以定义一个参数完全相同的非静态成员;其二,重载决议将无法选择最佳的那个匹配函数(此处 long 需要转换,不是最佳匹配函数)。
静态成员的这个隐式对象参数被定义为可以匹配任何参数,仅仅用于在重载决议阶段保证操作的一致性。
对于非成员函数,则可以直接通过 Unqualified Name Lookup 和 Qualified Name Lookup 找到。同时,模板实例化后也会产生成员或非成员函数,除了有些因为模板替换失败被移除,剩下的名称共同组成了 candidate functions。
1.4.2、Viable functions
二级筛选要在 candidate functions 的基础上,通过一些筛选准则来剔除不符合要求的函数,留下的就是 viable functions。
筛选准则主要看两个方面,一个是看参数匹配程度,另一个是看约束满足程度。
约束满足就是看是否满足 Concepts,这是 C++20 之后新增的一项检查。
具体的检查流程如下所述。
第一步,看参数个数是否匹配。
假设实参个数为 N,形参个数为 M,则存在三种比较情况。
如果 N 等于 M,这种属于个数完全匹配,此类函数将被留下。
如果 N 小于 M,此时就需要看 candidate functions 是否存在默认参数,如果不存在,此类函数被淘汰。
如果 N 大于 M,此时就需要看 candidate functions 是否存在可变参数,如果不存在,此类函数被淘汰。
第二步,是否满足约束。
第一轮淘汰过后,剩下的函数如果存在 Concepts 约束,这些约束应该被满足。如果不满足,此类函数被淘汰。
第三步,看参数是否匹配。
实参类型可能和 candidate functions 完全匹配,也可能不完全匹配,此时这些参数需要存在隐式转换序列。可以是标准转换,也可以是用户自定义转换,也可以是省略操作符转换。
这三步过后,留下的函数就称为 viable functions,它们都有望成为最佳匹配函数。
1.4.3、Tiebreakers
终极筛选也称为决胜局,重载决议的最后一步,将进行更加严格的匹配。
第一,它会看参数的匹配程度。
如前所述,实参类型与 viable functions 可能完全匹配,也可能需要转换,此时就存在更优的匹配选项。
C++ 的类型转换有三种形式,标准转换、自定义转换和省略操作符转换。
标准转换比自定义转换更好,自定义转换比省略操作符转换更好。
对于标准转换,可以看下表。
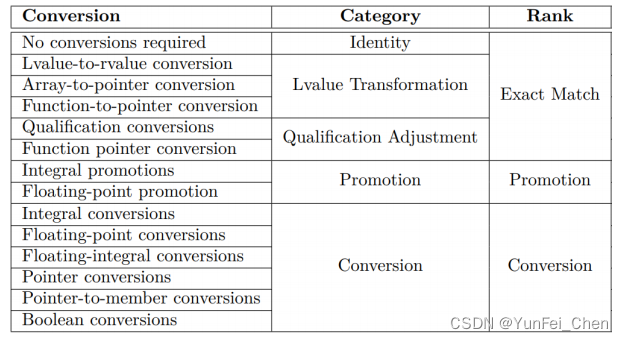
它们的匹配优先级也是自上往下的,即 Exact Match 比 Promotion 更好,Promotion 比 Conversion更好,可以理解为完全匹配、次级匹配和低级匹配。
看一个简单的例子:
void f(int);
void f(char);
int main() {f(1); // f(int) wins
}
此时,viable functions 就有两个。而实参类型为 int,f(int) 不需要转换,而 f(char) 需要将 int 转换为 char,因此前者胜出。
如果实参类型为 double,由于 double 转换为 int 和 char 属于相同等级,因此谁也不比谁好,产生 ambiguous。
再来看一个例子:
void f(const int*, short);
void f(int*, int);int main() {int i;short s = 0;f(&i, s); // #1 Error, ambiguousf(&i, 1L); // #2 OK, f(int*, int) winsf(&i, 'c'); // #3 OK, f(int*, int) wins
}
这里存在两个 viable functions,存在一场决胜局。
#1 处调用,第一个实参类型为 int,第二个实参类型为 short。对于前者来说,f(int, int) 是更好的选择,而对于后者来说,f(const int*, short) 才是更好的选择。此时将难分胜负,因此产生 ambiguous。
#2 处调用,第二个实参类型为 long,打成平局,但 f(int*, int) 在第一个实参匹配中胜出,因此最终被调用。
#3 处调用,第二个实参类型为 char,char 转换为 int 比转换为 short 更好,因此 f(int*, int) 依旧胜出。
对于派生类,则子类向直接基类转换是更好的选择。
struct A {};
struct B : A {};
struct C : B {};void f(A*) {std::cout << "A*";
}
void f(B*) {std::cout << "B*";
}int main() {C* pc;f(pc); // f(B*) wins
}
这里,C 向 B 转换,比向 A 转换更好,所以 f(B*) 胜出。
最后再来看一个例子,包含三种形式的转换。
struct A {operator int();
};void f(A) {std::cout << "standard conversion wins\n";
}void f(int) {std::cout << "user defined conversion wins\n";
}void f(...) {std::cout << "ellipsis conversion wins\n";
}int main() {A a;f(a);
}
最终匹配的优先级是从上往下的,标准转换是最优选择,自定义转换次之,省略操作符转换最差。
第二,如果同时出现模板函数和非模板函数,则非模板函数胜出。
例子如下:
void f(int) {std::cout << "f(int) wins\n";
}template <class T>
void f(T) {std::cout << "function templates wins\n";
}int main() {f(1); // calls f(int)
}
但若是非模板函数还需要参数转换,那么模板函数将胜出,因为模板函数可以完全匹配。
第三,如果都是函数模板,那么更特殊的模板函数胜出。
什么是更特殊的函数模板?其实指的就是更加具体的函数模板。越抽象的模板参数越通用,越具体的越特殊。举个例子,语言、汉语和普通话,语言可以表示汉语,汉语可以表示普通话,因此语言比汉语更抽象,汉语比普通话更抽象,普通话比汉语更特殊,汉语又比语言更特殊。
越抽象越通用,越具体越精确,越精确就越可能是实际的调用需求,因此更特殊的函数模板胜出。
比如在 3.2 节第三点提到的例子,const T& 为何比 T&& 更特殊呢?这是因为,若形参类型为T,实参类型为 const U,则 T 可以推导为 const U,前者就可以表示后者。若是反过来,形参类型为const T,实参类型为 U,此时就无法推导。因此 const T& 要更加特殊。
第四,如果都函数都带有约束,那么满足更多约束的获胜。
例子如下:
template<typename T> concept C1 = requires(T t) { --t; };
template<typename T> concept C2 = C1<T> && requires(T t) { *t; };template<C1 T> void f(T); // #1
template<C2 T> void f(T); // #2
template<class T> void g(T); // #3
template<C1 T> void g(T); // #4int main() {f(0); // selects #1f((int*)0); // selects #2g(true); // selects #3 because C1<bool> is not satisfiedg(0); // selects #4
}
第五,如果一个是模板构造函数,一个是非模板构造函数,那么非模板版本获胜。
例子如下:
template <class T>
struct S {S(T, T, int); // #1template <class U> S(T, U, int); // #2
};int main() {// selects #1, generated from non-template constructorS s(1, 2, 3);
}
究其原因,还是非模板构造函数更加特殊。
以上所列的规则都是比较常用的规则,更多规则大家可以参考 cppreference。
通过这些规则,就可以找出最佳匹配的那个函数。如果最后只剩下一个 viable function,那么它就是 best viable function。如果依旧存在多个函数,那么 ambiguous。
大家也许还不是特别清楚上述流程,那么接下来,我将以一个完整的例子来串起整个流程。
1.5、走一遍完整的流程
一个完整的示例,代码如下:
namespace N {struct Base {};struct Derived : Base { void foo(Base* s, char); }; // #1void foo(Base* s, char); // #2void foo(Derived* s, int, bool = true); // #3void foo(Derived* s, short); // #4
}struct S {N::Derived* d;S(N::Derived* deri) : d{deri} {}operator N::Derived*() const { return d; }
};void foo(S); // #5
template <class T> void foo(T* t, int c); // #6
void foo(...); // #7int main() {N::Derived d;foo(&d, 'c'); // which one will be matched?
}
最终哪个函数能够胜出,让我们来逐步分析。
第一步,编译器会进行 Name Lookup,查找名称。如下图。

可以看到,代码中一共有七个重载函数,但是只会被查找到六个。因为 foo(&d, ’c’) 调用时没有添加任何作用域限定符,所以编译器不会使用 Qualified Name Lookup 进行查找。
在查找到的六个名称当中,其中有三个是通过 ADL 查找到的,还有三个是通过 Usual Unqualified Lookup 查找到的。
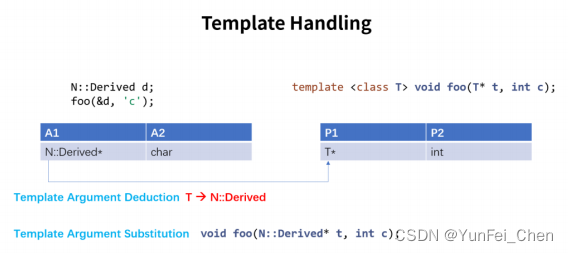
第二步,编译器发现其中包含函数模板,于是进行 Template Handling。如图。
首先,编译器根据调用实参,通过 Template Argument Deduction 推导出实参类型,实参类型如上图 A1 和 A2 所示。
接着,编译器分析函数模板中包含的模板参数,其中 P1 为模板参数。于是,需要进行 Template Argument Substitution,将 P1 替换为实参类型,T 被替换为 N::Derived。
如果模板替换失败,根据 SFINAE,这些函数模板将被移除。
最后,替换完成的函数就和其他的函数一样,它们共同构成了 candidate functions,一级筛选到
此结束。如图。
第三步,编译器正式进入重载决议阶段,比较 candidate functions,选择最佳匹配函数。

首先,进行二级筛选,筛选掉明显不符合的候选者。
调用参数为 2 个,而第 4 个候选者只有 1 个参数,被踢出局;第 2 个候选者具有 3 个参数,但是它的第三个参数设有缺省值,因此依旧被留下。
此外,这些候选函数也没有任何约束,因此在这一局只剔除了一个函数,剩下的函数就称为viable functions。如图。
viable functions 之所以称为可行函数,就是因为它们其实都可以作为最终的调用函数,只是谁更好而已。
其次,进行终级筛选,即决胜局。在此阶段,需要比较参数的匹配程序。
对于派生类,完全匹配比直接基类好,直接基类比间接基类好,因此第 1 个候选者被踢出局。
第 6 个候选者为省略操作符,它将永远是最后才会被考虑的对象,也是最差的匹配对象。于是,2、3、5 进行决战。
它们的第一个参数都是完全匹配,因此看第二个参数。char 转换为 int 比 short 更好,因此第 3个候选者被踢出局。
剩下第 2、5 个候选者,第 2 个候选者虽然有三个参数,但因为有缺省值,所以并不影响,也不会被作为决胜因素,所以第 5 个候选者暂时还无法取胜。

然后,编译器发现第 2 个候选者为非模板函数,第 5 个候选者为模板函数。模板函数和非模板函数同时出现时,非模板函数胜出,于是第 5 个候选者被踢出局。
最后,只留下了第 2 个候选者,它成为了 best viable function,胜利者。如图:

但是,大家可别以为竞选出胜利者就一定可以调用成功。事实上,它们只针对的是声明,如果函数没有定义,依旧会编译失败。
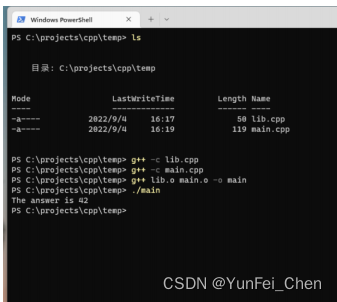
1.6、Name Mangling
重载函数的名称实际上是通过 Name Mangling 生成的新名称,大家如果去看编译后的汇编代码就能够看到这些名称。
像是 Compiler Explorer,它实际上是为了让你看着方便,显示的是优化后的名称,去掉勾选Demangle identifiers 就能够看到实际函数名称。如图。
那么接下来,就来介绍一下 Name Mangling 的实际手法。标准并没有规定具体实现方式,因此编译器的实际可能不尽相同,下面以 gcc 为例进行分析。
下面是使用 gcc 编译过后的一个例子。如图。
如图所示,编译器为每个重载函数都生成一个新名称,新名称是绝对唯一的。
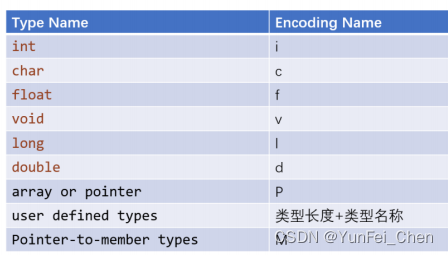
基本的规则如下图所示。如图。

除了基本规则,还有很多比较复杂的规则,这里再举几个常见的名称。
namespace myNS {struct myClass {// mangles as _ZN4myNS7myClass6myFuncEvvoid myFunc() {}};// mangles as _ZN4myNS3fooENS_7myClassEvoid foo(myClass) {}
}template <class T>
void foo(T, int) {}// mangles as _Z3fooIfEvT_i
template void foo(float, int);
规则不难理解,大家可以自己找下规律。其中,I/E 中间的是模板参数,T_ 表示第 1 个模板参数。
由于 C 语言没有重载函数,所以它也没有 Mangling 操作。如果你使用混合编译,即某些文件使用 C 编译,某些文件使用 C++ 编译,就会产生链接错误。
举个例子,有如下代码:
int myFunc(int a, int b) {return a + b;
}// main.cpp
#include <iostream>
int myFunc(int a, int b);int main() {std::cout << "The answer is " << myFunc(41, 1);
}
使用 C++ 编译并链接,结果如下图。如图。
编译器在编译 main.cpp 时,发现其中存在一个未解析的引用 int myFunc(int a, int b);,于是在链接文件 lib.cpp 中找到了该定义。之所以能够找到该定义,是因为这两个文件都是使用 C++ 编译的,编译时 main.cpp 中的声明经过 Name Mangling 变为 _Z6myFuncii,实际查找的并不是 myFunc 这个名称。而 lib.cpp 中的名称也经过了 Name Mangling,因此能够链接成功。
但是,如果其中一个文件使用 C 进行编译,另一个使用 C++ 进行编译,链接时就会出现问题。如图。
由于 main.cpp 是用 C++ 编译的,因此实际查找的名称为 _Z6myFuncii。而 lib.cpp 是用 C 编译的,并没有经过 Name Mangling,它的名称依旧为 myFunc,因此出现未定义的引用错误。
常用解法是使用一个 extern 关键字,告诉编译器这个函数来自 C,不要进行 Name Mangling。
extern "C" int myFunc(int a, int b);
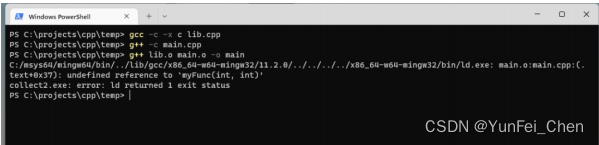
int main() {std::cout << "The answer is " << myFunc(41, 1);
}
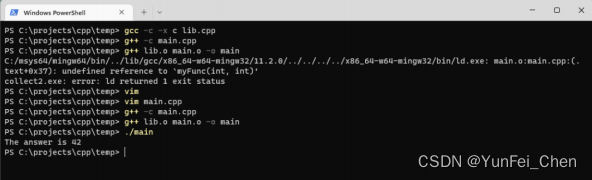
如此一来,就可以解决这个问题。如图。
通常来说,可以使用预处理条件语句,分别提供 C 和 C++ 版本的代码,这样使用任何方式就都可以编译成功。
1.7、总结
未完待续
相关文章:
C++学习笔记--函数重载(2)
文章目录 1.3、Function Templates Handling1.3.1、Template Argument Deduction1.3.2、Template Argument Substitution 1.4、Overload Resolution1.4.1、Candidate functions1.4.2、Viable functions1.4.3、Tiebreakers 1.5、走一遍完整的流程1.6、Name Mangling1.7、总结 1.…...

代码随想录算法训练营Day56 || ● 583. 两个字符串的删除操作 ● 72. 编辑距离
今天接触到了真正的距离,但可以通过增删改操作来逼近。 问题1:583. 两个字符串的删除操作 - 力扣(LeetCode) 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字…...
chrome_elf.dll丢失怎么办?修复chrome_elf.dll文件的方法
Chrome是目前最受欢迎的网络浏览器之一,然而有时用户可能会遇到Chrome_elf.dll丢失的问题。该DLL文件是Chrome浏览器的一个重要组成部分,负责启动和管理程序的各种功能。当Chrome_elf.dll丢失时,用户可能无法正常启动Chrome或执行某些功能。本…...

代码随想录32|738.单调递增的数字,968.监控二叉树,56. 合并区间
738.单调递增的数字 链接地址 class Solution { public:int monotoneIncreasingDigits(int n) {string str to_string(n);int flag str.size();for (int i str.size() - 1; i > 0; i--) {if (str[i] < str[i - 1]) {str[i - 1] - 1;flag i;}}for (int j flag; j <…...
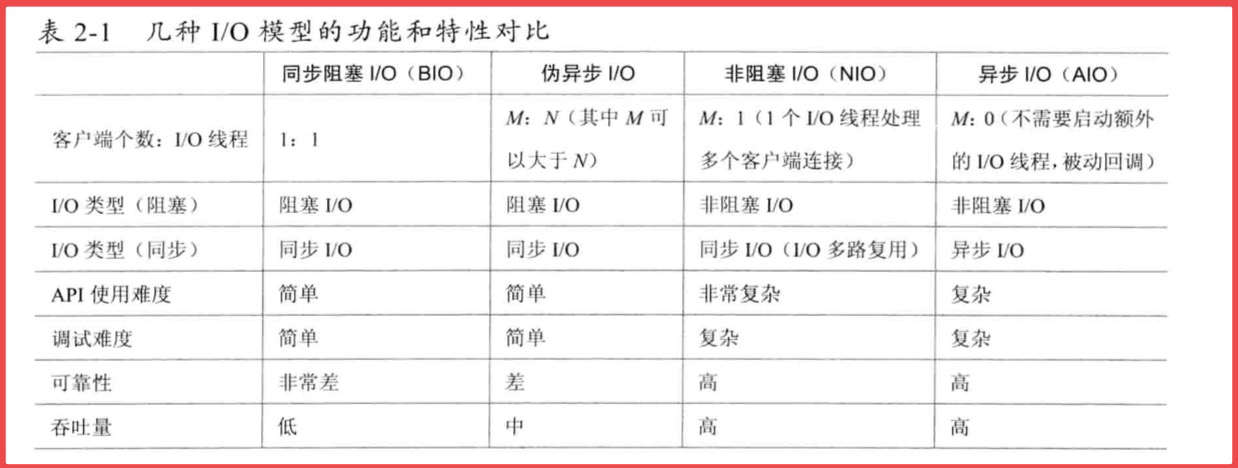
BIO NIO AIO演变
Netty是一个提供异步事件驱动的网络应用框架,用以快速开发高性能、高可靠的网络服务器和客户端程序。Netty简化了网络程序的开发,是很多框架和公司都在使用的技术。 Netty并非横空出世,它是在BIO,NIO,AIO演变中的产物…...
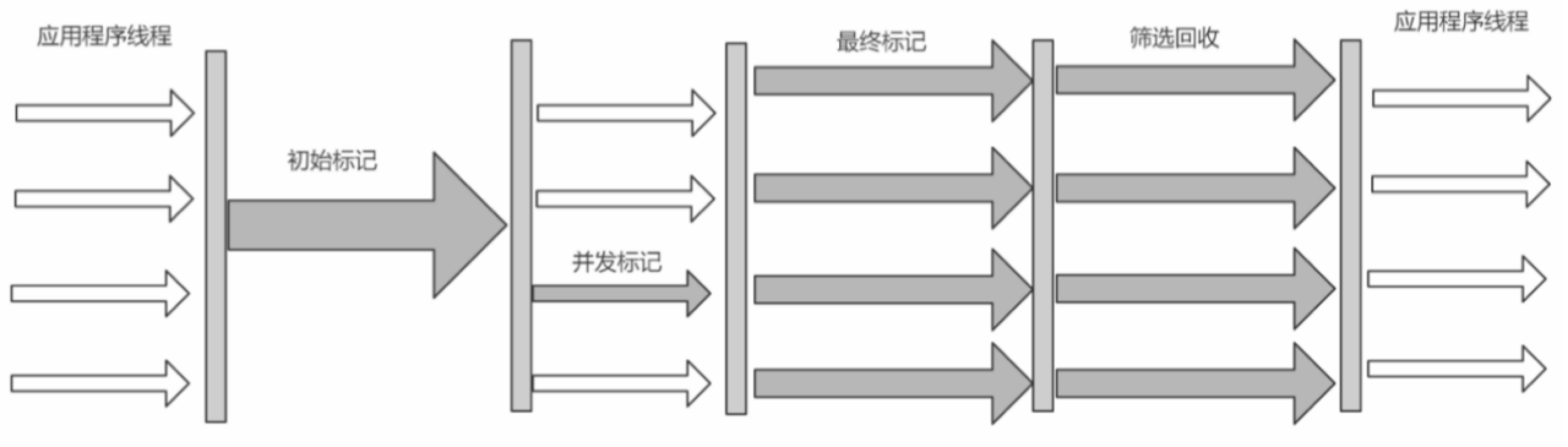
JVM GC垃圾回收
一、GC垃圾回收算法 标记-清除算法 算法分为“标记”和“清除”阶段:标记存活的对象, 统一回收所有未被标记的对象(一般选择这种);也可以反过来,标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象 。它…...

【数据结构】队列知识点总结--定义;基本操作;队列的顺序实现;链式存储;双端队列;循环队列
欢迎各位看官^_^ 目录 1.队列的定义 2.队列的基本操作 2.1初始化队列 2.2判断队列是否为空 2.3判断队列是否已满 2.4入队 2.5出队 2.6完整代码 3.队列的顺序实现 4.队列的链式存储 5.双端队列 6.循环队列 1.队列的定义 队列(Queue)是一种先…...

嵌入式学习之链表
对于链表,要重点掌握链表和数组区别和实现,链表静态添加和动态遍历,链表中pointpoint-next,链表节点个数的查找,以及链表从指定节点后方插入新节点的知识。...
静态代理和动态代理笔记
总体分为: 1.静态代理: 代理类和被代理类需要实现同一个接口.在代理类中初始化被代理类对象.在代理类的方法中调 用被代理类的方法.可以选择性的在该方法执行前后增加功能或者控制访问 2.动态代理: 在程序执行过程中,实用JDK的反射机制,创建代理对象,并动态的指定要…...

[SM6225][Android13]user版本默认允许root和remount
开发平台基本信息 芯片: 高通SM6225版本: Android 13kernel: msm-5.15 问题描述 刚刚从Framework踏入性能的小殿堂,User版本默认是不会开启root权限的,而且一般调试需要设置一下CPU GPU DDR performance模式或者修改一些schedule util等调核调频节点去…...

pyinstaller打包exe,使用wexpect的问题
参考github首先打包wexpect 1.进入wexpect目录执行 pyinstaller __main__.py -n wexpect 会生成dist文件夹 2.python代码A.py中使用wexpect,注意wexpect.spawn前后必须按照下面添加代码 import sys,os,wexpect #spawn前 real_executable sys.executable try:if sy…...
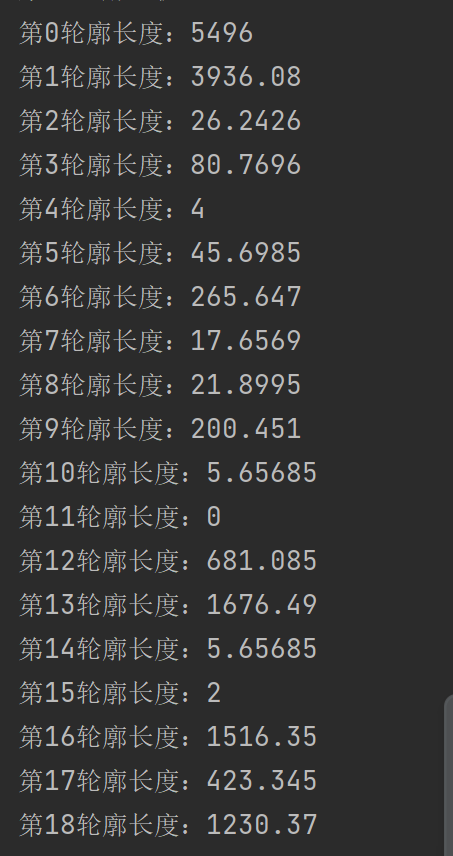
OpenCV(三十三):计算轮廓面积与轮廓长度
1.介绍轮廓面积与轮廓长度 轮廓面积(Contour Area)是指轮廓所包围的区域的总面积。通常情况下,轮廓面积的单位是像素的平方。 轮廓长度(Contour Length)又称周长(Perimeter),表示轮廓…...
9.11作业
实现一个对数组求和的函数,数组通过实参传递给函数 sum0 arr(11 22 33 44 55) Sum() {for i in ${arr[*]}do$((sumi))donereturn $sum } Sum ${arr[*]} var$? echo $var写一个函数,输出当前用户的uid和gid,并使用变量接收结果 Sum() {aid -…...

AI伦理与未来社会:探讨人工智能的道德挑战与机会
引言 引出AI伦理和社会影响的主题,强调AI的快速发展和广泛应用。 概述博客的主要内容:探讨AI的伦理挑战以及它对社会的影响。 第一部分:AI的伦理挑战 算法偏见: 解释什么是算法偏见,以及它为何在AI中成为一个重要问题。…...

Android窗口层级(Window Type)分析
前言 Android的窗口Window分为三种类型: 应用Window,比如Activity、Dialog;子Window,比如PopupWindow;系统Window,比如Toast、系统状态栏、导航栏等等。 应用Window的Z-Ordered最低,就是在系…...

微信小程序基础加强总结
本篇文章给大家带来了关于微信小程序的相关问题,其中主要介绍了一些基础内容,包括了自定义组件、样式隔离、数据、方法和属性等等内容,下面一起来看一下,希望对大家有帮助。 1、自定义组件 1.1、创建组件 在项目的根目录中&…...
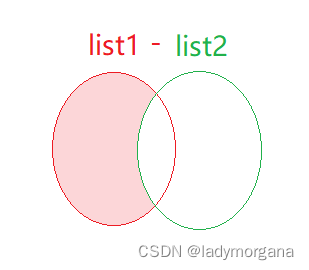
【JAVA - List】差集removeAll() 四种方法实现与优化
一、场景: 二、结论: 1. 四种方法耗时 三、代码: 一、场景: 求差集 List1 - Lsit2 二、结论: 1. 四种方法耗时 初始条件方法名方法思路耗时 List1.size319418 List2.size284900 List..removeAll(Lsit2)1036987ms…...
sql注入基本概念
死在山野的风里,活在自由的梦里 sql注入基本概念 MYSQL基本语法union合并查询2个特性:order by 排序三个重要的信息 Sql Server MYSQL 基本语法 登录 mysql -h ip -u user -p pass基本操作 show databases; 查看数据库crea…...

AIGC系列:1.chatgpt可以用来做哪些事情?
上图的意思:神器轩辕剑 那么,在现在AI盛行的信息时代, 你是否知道如何获得和利用ChatGPT这一把轩辕剑来提升你的攻击力和生存能力呢? 故事 程序员小张: 刚毕业,参加工作1年左右,日常工作是C…...
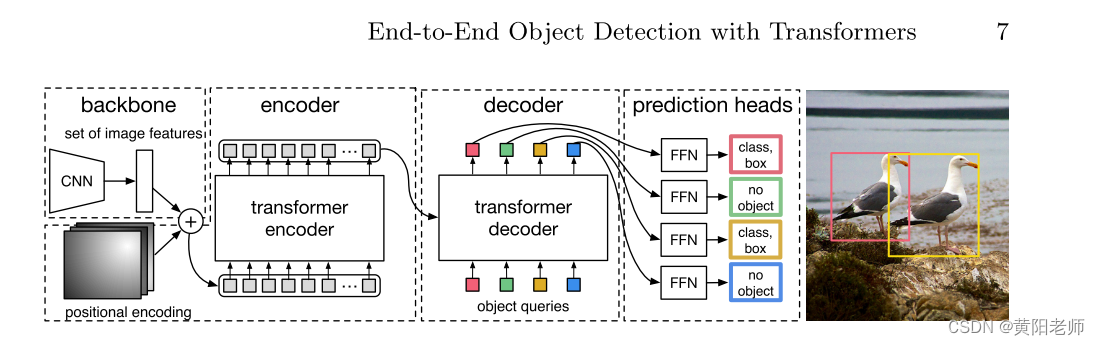
End-to-End Object Detection with Transformers(论文解析)
End-to-End Object Detection with Transformers 摘要介绍相关工作2.1 集合预测2.2 transformer和并行解码2.3 目标检测 3 DETR模型3.1 目标检测集设置预测损失3.2 DETR架构 摘要 我们提出了一种将目标检测视为直接集合预测问题的新方法。我们的方法简化了检测流程,…...

VLC推流实战:用TS格式实现本地音频实时传输的完整指南
VLC推流实战:用TS格式实现本地音频实时传输的完整指南 你是否曾想过,将电脑里收藏的高品质音乐,像网络电台一样,实时推送到家里的另一台设备上播放?或者,在开发一个需要低延迟音频分发的应用原型时…...

MATLAB/Simulink工作目录设置指南:为什么你的模型文件不能放在Program Files下?
MATLAB/Simulink工作目录设置指南:为什么你的模型文件不能放在Program Files下? 你是否曾在Simulink中尝试生成代码或可执行文件时,突然弹出一个令人困惑的报错,提示你“Simulink does not permit you to modify the MATLAB insta…...

2026年人事系统多少钱一套?
2026年人事系统多少钱一套?4类方案价格拆解选型攻略,帮你省30%预算做HR的小夏最近找我吐槽:“看了5家人事系统,价格从3000元/年到30万元不等,到底差在哪?难道贵的就一定好?”其实,人…...

异步处理精髓:AsyncHandler与AsyncCompletionHandler实战指南
异步处理精髓:AsyncHandler与AsyncCompletionHandler实战指南 【免费下载链接】async-http-client Asynchronous Http and WebSocket Client library for Java 项目地址: https://gitcode.com/gh_mirrors/as/async-http-client 在Java开发中,高效…...

终极HTTPSnippet CLI使用手册:命令行参数全解析
终极HTTPSnippet CLI使用手册:命令行参数全解析 【免费下载链接】httpsnippet HTTP Request snippet generator for many languages & libraries 项目地址: https://gitcode.com/gh_mirrors/ht/httpsnippet HTTPSnippet是一款强大的HTTP请求代码生成工具…...

ESP8684-WROOM-04C射频特性深度解析与工程落地指南
ESP8684-WROOM-04C 射频特性深度解析与工程落地指南射频性能是无线模组的核心竞争力,直接决定通信距离、抗干扰能力、功耗表现与系统稳定性。ESP8684-WROOM-04C 作为乐鑫新一代高集成度 Wi-Fi 6 Bluetooth 5.3 双模模组,其射频设计在保持小尺寸封装&…...
)
Windows安装OpenClaw龙虾(新手入门必备)
目录 一、准备工作(必做) 二、方案A:原生PowerShell一键安装(新手首选) 1. 打开管理员PowerShell 2. 解锁脚本执行权限(必做) 3. 一键安装OpenClaw 4. 验证安装 5. 初始化配置࿰…...

Ubuntu22.04下BBR与CUBIC拥塞控制算法的性能对比测试
1. 为什么我们要关心拥塞控制算法? 如果你用过家里的宽带,或者在公司里传过大文件,肯定遇到过这种情况:明明网速标称很高,但下载东西就是时快时慢,看视频也总在缓冲。很多时候,这口“锅”可能不…...

程序员如何做好职业规划?这份思维导图价值百万
程序员如何做好职业规划?这份思维导图价值百万 引入与连接:当代码人生遇到十字路口 “30岁了,还在写业务CRUD,会被淘汰吗?” “学Java还是Python?听说Go语言薪资更高,要不要转?” “技术专家和管理路线,到底该选哪条?” 如果你是程序员,这些问题大概率曾在深夜盘…...
)
实战指南:基于Ansible的Linux等保三级自动化加固方案(CentOS/Kylin)
1. 为什么你需要Ansible来做等保三级加固? 如果你是一名运维或者安全工程师,手头管理着几十甚至上百台CentOS或者Kylin服务器,每次等保检查前,是不是都感觉头皮发麻?一台台服务器登录上去,重复执行那些繁琐…...