人工智能基础-趋势-架构

在过去的几周里,我花了一些时间来了解生成式人工智能基础设施的前景。在这篇文章中,我的目标是清晰概述关键组成部分、新兴趋势,并重点介绍推动创新的早期行业参与者。我将解释基础模型、计算、框架、计算、编排和矢量数据库、微调、标签、合成数据、人工智能可观测性和模型安全性。
我的目标是以简单直接的方式理解和解释这些概念。此外,我希望能够利用这些知识来进行未来的增长投资。
在这篇文章的结尾,我将通过说明两家公司如何以一致的方式利用基础设施堆栈来连接所有这些概念。
大型语言和基础模型
让我们从大型语言模型开始。简而言之,LLM是使用大量文本和代码(包括书籍、文章、网站和代码片段)进行训练的计算机程序。LLM的最终目标是真正理解单词和短语的含义,并擅长生成新句子。它与深度学习结合起来实现这一点。
基础模型是这些LLM的别称,发挥着至关重要的作用,因为它们为广泛的应用提供了基础。在这项研究中,正如其名称本身所暗示的那样,我们将把大部分精力集中在这个基础方面。
这些模型利用巨大的数据集来学习各种任务。虽然他们偶尔会犯错误或表现出偏见,但他们的能力和效率正在不断提高。
为了将这个概念变为现实,让我们考虑一个实际的例子。想象一下,您是一名作家,正在为故事寻找新的想法。通过在模型中输入几个单词,它可以生成潜在概念的列表。我利用它来接收有关本文标题的建议。同样,面对问题的科学家可以通过输入几个单词来利用基础模型的力量,从大量数据中发现所需的信息。
基础模型引发了人工智能系统开发的重大转变。它们为聊天机器人和其他人工智能界面提供动力,它们的进步很大程度上归功于自我监督和半监督学习。现在,这些术语的确切含义是什么?
在自我监督学习中,模型通过根据频率和上下文破译单词含义来从未标记的数据中学习。另一方面,半监督学习涉及使用标记和未标记数据的组合来训练模型。标记数据是指已将特定信息分配给数据的实例,例如带有自行车和汽车标记图像的数据集。然后,该模型可以使用标记图像区分两者,并进一步完善对未标记图像的理解。我很快就会深入探讨微调的概念。
现在,当涉及到在基础模型之上构建应用程序时,出现了一个关键的考虑因素:开发人员应该选择开源模型还是封闭模型?
开源人工智能模型的底层代码和架构可公开访问,任何人都可以免费使用、修改和分发。这种开放性营造了一个协作环境,开发人员和研究人员可以在其中为模型改进做出贡献,使其适应新的用例,或将其集成到自己的项目中。
另一方面,闭源人工智能模型将其代码和架构保持私有,限制公众的自由访问。这些模型的使用、修改和分发通常由开发它的公司严格控制。此方法旨在保护知识产权、维持质量控制并确保负责任的使用。尽管外部开发人员和研究人员无法直接为模型改进或调整做出贡献,但他们通常可以通过拥有模型的实体提供的预定义接口或 API 与模型进行交互。
在开放模型和封闭模型之间进行选择可能会带来挑战。选择开源解决方案意味着承担管理基础设施需求的责任,例如处理能力、数据存储和网络安全,这些需求通常由封闭模型提供商提供。
在撰写本文的过程中,我想了解这些模型的独特优势和卖点。最重要的是,我向该领域的建设者寻求见解。
虽然我遇到的观点可能有所不同,但在选择基本模型时出现了一些关键主题:应用程序所需的精度、开发人员团队处理自己的基础设施的准备程度,以及如果没有进行足够的探索,则倾向于坚持熟悉的内容。没有进行过。
首先,准确性至关重要。根据模型需要完成的任务,错误的容忍度可能会有所不同。例如,销售聊天机器人可以处理偶尔出现的错误,使其适合在现有基础模型的基础上构建。然而,考虑一下自动驾驶汽车的情况,其中的错误可能会带来灾难性的后果。
其次,云托管发挥着重要作用。对于旨在维持精益运营的敏捷初创公司来说,处理计算能力、数据存储和技术复杂性可能会分散他们对核心目标的注意力。这就是为什么许多初创公司选择在 Chat-GPT 等现成的闭源平台之上进行构建。另一方面,在基础设施管理方面拥有内部专业知识的大公司可能会倾向于开源路线,以保留对各个方面的控制并更深入地了解系统的结果。
最后,业务目标发挥影响力。不同的公司有不同的议程,这可能会影响决策过程。例如,Zoom 投资并利用了 Anthropic,这是一种针对企业用例和安全性量身定制的模型。虽然 Anthropic 可能不具备比 OpenAI 更优秀的系统,但 Zoom 可能希望避免其数据被与 Teams 竞争的 OpenAI/微软使用的风险。这些战略考虑因素在确定合作伙伴公司选择构建其系统时发挥着重要作用。
大型语言模型 (LLM) 的前景不断扩大。这里有一些领先的模型,例如 OpenAI 的 GPT4 和 DALL-E、Cohere、Anthropic 的 Claude、Meta AI 的 LLaMA、StabilityAI、MosaicML 和 Inflection AI。
OpenAI 是人工智能行业的基石,以其在 GPT4 和 DALL-E 方面的进步而闻名。ChatGPT 是一种闭源模型,具有令人印象深刻的对话式 AI 界面,使机器人能够与人进行复杂的对话,而 DALL-E 可以根据文本描述生成独特的图像。
MosaicML 是一家开源人工智能初创公司,开发了一个用于训练大型语言模型和部署生成式人工智能工具的平台。最近被 Databricks 收购的 MosaicML 独特的开源方法将继续帮助组织创建自己的语言模型。
Meta AI对AI领域的贡献LLaMA是一个开源模型。通过鼓励其他研究人员使用 LLaMA,Facebook 旨在促进新应用程序的开发并提高语言模型的准确性。
StabilityAI 以 Dance Diffusion 和 Stable Diffusion 等系统而闻名,是开源音乐和图像生成系统的领导者。他们的目标是激发全球创造力。该公司还拥有 MedARC,这是医疗人工智能贡献的基础模型。
Anthropic 是一家由 OpenAI 资深人士共同创立的闭源公司,它创建了 Claude,一种安全且功能强大的语言模型。Claude 作为处理数据的新模型脱颖而出,为负责任的人工智能树立了早期基准。
Inflection 是一家资金雄厚的人工智能基础模型初创公司,其大胆的愿景是为每个人打造“个人人工智能”,最近其强大的语言模型为 Pi 对话代理提供了动力。该公司得到了微软、里德霍夫曼、比尔盖茨、埃里克施密特和英伟达的支持。
最后,加拿大初创公司 Cohere 提供了专为企业使用而设计的可靠且可扩展的大型语言模型。他们的模型满足企业的特定要求,确保可靠性和可扩展性。
半导体、芯片、云托管、推理、部署

生成式人工智能模型依赖强大的计算资源来训练和生成输出。
虽然我从基础模型开始,GPU 和 TPU(专用芯片)以及云托管确实构成了生成式 AI 基础设施堆栈的基础。
计算是处理数据(并执行计算)的能力,在人工智能系统中发挥着至关重要的作用。GPU、CPU 和 TPU 是不同类型的计算。生成式人工智能堆栈中最重要的是 GPU,它最初是为图形任务而设计的,但在计算密集型操作(例如生成式人工智能的训练网络)方面表现出色。GPU 针对并行计算处理进行了优化,这意味着将大型任务分解为可由多个处理器同时处理的较小任务。AI/ML 任务是高度可并行化的工作负载,因此 GPU 才有意义。
生成式人工智能需要大量的计算资源和大型数据集,这些资源在高性能数据中心进行处理和存储。AWS、Microsoft Azure 和 Google Cloud 等云平台提供可扩展的资源和 GPU,用于训练和部署生成式 AI 模型。
GPU 领导者 Nvidia 的市值最近突破了 1 万亿美元,像 d-Matrix 这样的新进入者正在进入该领域,推出用于生成 AI 的高性能芯片,以帮助推理,即使用训练有素的生成模型对新数据进行预测的过程。d-Matrix 正在构建一款新的推理芯片,与当前的计算加速器相比,使用数字内存计算 (DIMC) 技术可显着降低每个令牌的延迟。d-Matrix 认为,解决内存计算集成问题是提高 AI 计算效率的关键,从而以高效且经济高效的方式处理推理应用程序的爆炸式增长。
Lambda Labs 帮助企业按需部署人工智能模型。Lambda 为电力工程师提供工作站、服务器、笔记本电脑和云服务。最近,Lambda 推出了 GPU Cloud,这是一项专门用于深度学习的 GPU 云服务。
CoreWeave 是一家专注于大规模高度并行化工作负载的专业云服务提供商。该公司已获得 Nvidia 和 GitHub 创始人的资助。其客户包括 Stability AI 等生成式人工智能公司,并支持开源人工智能和机器学习项目。
此外,还有专门的公司致力于支持生成式人工智能。HuggingFace本质上是LLM的GitHub,过名为Hub的协作平台提供全面的AI计算资源,促进模型在主要云平台上的共享和部署。
有趣的是,云提供商正在与关键的基础模型参与者保持一致;微软在 OpenAI 上投入了资源和大量资金,谷歌投资了 Anthropic 并补充了其 Google Brain 计划,亚马逊则与 HuggingFace 结盟。结论是,对于可能想要使用特定基础模型之一的公司来说,AWS 之前基于信用和创新的主导地位不再是默认选项。
编排层/应用程序框架
该堆栈的下一级是应用程序框架,可促进人工智能模型与不同数据源的无缝集成,使开发人员能够快速启动应用程序。
应用程序框架的关键要点是它们加快了生成式人工智能模型的原型设计和使用。
这里最著名的公司是 LangChain,它最初是一个开源项目,后来发展成为一家真正的初创公司。他们引入了一个开源框架,专门用于简化使用LLM的应用程序开发。该框架的核心概念围绕着将各种组件“链接”在一起以创建聊天机器人、生成问答(GQA)和摘要的概念。
我与创始人兼首席执行官哈里森·蔡斯取得了联系。他说:“浪链提供了两大附加值。第一个是抽象的集合,每个抽象代表构建复杂的 LLM 应用程序所需的不同模块。这些模块为该模块内的所有集成/实现提供了标准接口,从而可以通过一行代码轻松切换提供程序。这有助于团队快速试验不同的模型提供者(OpenAI 与 Anthropic)、向量库(Pinecone 与 Chroma)、嵌入模型(OpenAI 与 Cohere)等。第二大附加值是在链中——执行更复杂的 LLM 调用序列以启用 RAG、摘要等的常见方法。”
另一个参与者是 Fixie AI,由苹果和谷歌的前工程负责人创立。Fixie AI 旨在在 OpenAI 的 ChatGPT 等文本生成模型与企业级数据、系统和工作流程之间建立连接。例如,公司可以利用 Fixie AI 将语言模型功能合并到客户支持工作流程中,客服人员可以在其中处理客户票证、自动检索相关购买信息、根据需要发放退款以及生成票证草稿回复。
矢量数据库

堆栈的下一个级别是矢量数据库,它是一种特殊类型的数据库,以有助于查找相似数据的方式存储数据。它通过将每条数据表示为数字列表(称为向量)来实现此目的。
向量中的这些数字对应于数据的特征或属性。例如,如果我们处理图像,向量中的数字可能代表图像的颜色、形状和亮度。在向量数据库中,需要掌握的一个重要术语是嵌入。嵌入是一种数据表示形式,它封装了对于人工智能理解和维持长期记忆至关重要的语义信息,这对于执行复杂任务至关重要。嵌入是一种数据表示形式,它封装了对于人工智能理解和维持长期记忆至关重要的语义信息,这对于执行复杂任务至关重要。
这是一个具体的例子。自行车的图片可以有效地转换为一系列数值,包括尺寸、车轮颜色、车架颜色和车把颜色等特征。这些数字表示有利于无缝存储和分析,比单纯的图像具有优势。结论是矢量数据库具有以机器易于理解的方式处理和存储数据的能力。
这些数据库可以概念化为具有无限列的表。
在我之前构建对话式人工智能的经验中,我主要使用在表中存储数据的关系数据库。然而,矢量数据库擅长表示数据的语义,支持相似性搜索、推荐和分类等任务。
几家公司开发了矢量数据库和嵌入。
Pinecone 是该品类的创造者。他们拥有专为大规模机器学习应用程序设计的分布式矢量数据库。除了生成式人工智能公司之外,它还拥有 Shopify、Gong、Zapier 和 Hubspot 等客户,提供具有 SOC 2 Type II 认证和 GDPR 就绪性的企业级解决方案。GDPR 合规性很重要,因为如果开发人员必须删除记录,在数据库中执行起来并不难,但由于模型的结构方式,从模型中删除不良数据要困难得多。松果还有助于记忆聊天体验。
另一个值得注意的矢量数据库是 Chroma,它是一个专注于高性能相似性搜索的新开源解决方案。Chroma 使开发人员能够向其支持 AI 的应用程序添加状态和内存。许多开发人员表达了对像“ChatGPT 但针对他们的数据”这样的 AI 工具的渴望,而 Chroma 通过实现基于嵌入的文档检索来充当桥梁。自推出以来,Chroma 已获得超过 35,000 次 Python 下载。此外,它的开源符合让人工智能更安全、更一致的目标。
Weaviate 是一个开源矢量数据库,非常适合寻求灵活性的公司。它与其他模型中心兼容,例如 OpenAI 或 HuggingFace。
微调
基础设施堆栈的下一层是微调。在生成人工智能领域,微调涉及针对特定任务或数据集进一步训练模型。此过程增强了模型的性能并对其进行调整以满足该任务或数据集的独特要求。这就像多才多艺的运动员如何专注于特定的运动以在其中取得优异成绩一样;基础广泛的人工智能还可以通过微调将其知识集中在特定任务上。
开发人员在现有模型之上构建新的应用程序。虽然在海量数据集上训练的语言模型可以生成语法正确且流畅的文本,但它们在医学或法律等某些领域可能缺乏精确性。在特定领域的数据集上微调模型,使其能够内化这些领域的独特特征,从而增强其生成相关文本的能力。
这与之前关于作为其他服务和产品平台的基础模型的观点是一致的。微调这些模型的能力是其适应性的关键因素。微调现有模型可以简化流程并且具有成本效益,而不是从头开始(这需要大量的计算能力和大量数据),尤其是在您已经拥有大型特定数据集的情况下。
该领域的一家著名公司是 Weights and Bias。
标签
准确的数据标记对于生成人工智能模型的成功至关重要。
数据可以采取多种形式,包括图像、文本或音频。标签用作数据的描述。例如,自行车的图像可以标记为“自行车”或“自行车”。机器学习的一个比较繁琐的方面是提供一组标签来教导机器学习模型它需要知道什么。
数据标记在机器学习中发挥着重要作用,因为算法从数据中学习。标签的准确性直接影响算法的学习能力。每个人工智能初创公司或企业研发实验室都面临着注释训练数据以教导算法识别什么的挑战。无论是医生通过扫描评估癌症的大小,还是司机在自动驾驶汽车录像中标记街道标志,贴标签都是必要的步骤。
不准确的数据会导致模型结果不准确。
数据标签仍然是许多行业机器学习和人工智能进步的重大挑战和障碍。对于学科专家来说,为此分配时间成本高昂、劳动密集型且具有挑战性,导致一些人在隐私和专业知识限制最小的情况下转向众包平台。它通常被视为“清洁”工作,尽管数据最终控制着模型的行为和质量。在大多数模型架构都是开源的世界中,私有的、领域相关的数据是构建人工智能护城河的最强大的方法之一。
Snorkel AI 是一家加快标签流程的公司。该公司的技术最初是斯坦福人工智能实验室的一项研究计划,旨在克服人工智能的标签瓶颈。Snorkel 的平台帮助主题专家以编程方式(通过一种称为“弱监督”的技术)而不是手动(逐一)标记数据,让人类参与循环,同时显着提高标记效率。这可以将流程从几个月缩短到几小时或几天,具体取决于数据的复杂性,并且从长远来看使模型更易于维护,因为随着数据漂移、发现新的错误模式或业务,可以轻松地重新访问和更新训练标签。目标发生变化。
Snorkel AI 联合创始人兼首席执行官 Alex Ratner 表示:“在预训练和微调等每项以模型为中心的操作背后,都是更重要的以数据为中心的操作,这些操作创建模型实际学习的数据。” “我们的目标是让以数据为中心的人工智能开发不再像手动、临时工作,而更像软件开发,以便每个组织都可以开发和维护适用于其企业特定数据和用例的模型。” Snorkel 以数据为中心的平台还有助于系统地识别模型错误,以便标记工作可以集中在最有影响力的数据片段上。如今,财富 500 强公司在金融、电子商务、保险、电信和医药等数据密集型行业中使用它。
Labelbox 是一家领先的人工智能标签公司。我与首席执行官 Manu Sharma 进行了交谈。Labelbox 帮助 OpenAI、沃尔玛、Stryker 和 Google 等公司标记数据并管理流程。“Labelbox 使基础模型在企业环境中变得有用”。开发人员使用 Labelbox 的模型辅助标记快速将模型预测转化为用于生成 AI 用例的新的自动标记训练数据。
其他公司专门开发用于执行手动注释的界面和劳动力。其中之一是规模,重点关注政府机构和企业。该公司提供视觉数据标记平台,结合软件和人类专业知识,为开发机器学习算法的公司标记图像、文本、语音和视频数据。Scale 雇佣了数以万计的承包商来进行数据标记。他们最初向自动驾驶汽车公司提供标记数据,并将其客户群扩展到政府、电子商务、企业自动化和机器人领域。客户包括 Airbnb、OpenAI、DoorDash 和 Pinterest。
综合数据
合成数据,也称为模仿真实数据的人工创建的数据,在机器学习和人工智能 (AI) 领域提供了多种好处和应用。那么,为什么要考虑使用合成数据呢?
当真实数据不可用或无法利用时,就会出现合成数据的一个主要用例。通过生成与真实数据具有相同特征的人工数据集,您可以开发和测试 AI 模型,而不会损害隐私或遇到数据限制。
使用合成数据有很多优点。
合成数据可以保护隐私,因为它缺乏个人身份信息 (PII) 和 HIPAA 风险。在有效利用数据的同时,确保遵守 GDPR 等数据法规。它通过生成用于训练和部署的数据来实现可扩展的机器学习和人工智能应用程序。合成数据增强了多样性,通过代表不同的人群和场景来最大限度地减少偏见,并促进人工智能模型的公平性和包容性。“条件数据生成”技术和合成数据还可以解决没有足够数据来测试和训练模型的初创公司的“冷启动”问题。公司将需要合成专有数据集,然后使用条件数据生成技术对其进行增强,以填补他们无法在野外收集的边缘情况;这有时被称为模型训练的“最后一英里”。
当谈到合成数据解决方案时,有几家公司提供了可靠的选择。Gretel.ai、Tonic.ai 和 Mostly.ai 是该领域值得注意的例子。
Gretel.ai 允许工程师根据真实数据集生成人工数据集。Gretel 结合了生成模型、隐私增强技术以及数据指标和报告,使企业开发人员和工程师能够按需创建准确且安全的特定领域的合成数据。所有三位创始人都拥有网络安全背景,并曾在美国情报界担任过各种职务,他们的首席技术官是空军的一名入伍军官。
例如,Tonic.ai 将其数据宣传为“真实的虚假数据”,强调合成数据需要尊重和保护真实数据的隐私。他们的解决方案适用于软件测试、机器学习模型训练、数据分析和销售演示。
模型监督/AI可观测性
该堆栈的下一个级别是人工智能可观察性,它涉及监视、理解和解释人工智能模型的行为。简而言之,它确保人工智能模型正常运行并做出公正、无害的决策。
模型监督是人工智能可观察性的一个子集,专门致力于确保人工智能模型符合其预期目的。它涉及验证模型是否没有做出可能有害或不道德的决策。
数据漂移是另一个需要考虑的重要概念。它指的是数据分布随时间的变化,这可能导致人工智能模型变得不太准确。如果这些变化有利于某些群体,模型可能会变得更加有偏见并导致不公平的决策。随着数据分布的变化,模型的准确性会降低,可能导致错误的预测和决策。人工智能可观测平台提供了应对这些挑战的解决方案。
为了阐明人工智能可观察性的需求,我联系了 Krishna Gade 和 Fiddler.ai 的首席执行官兼首席运营官 Amit Paka。Gade 此前曾担任 Facebook News Feed 的工程负责人,亲眼目睹了企业在理解自己的机器学习模型方面面临的挑战。
“随着这些系统变得更加成熟和复杂,理解它们的运作方式变得极其困难。诸如“为什么我会在我的动态中看到这个故事?”之类的问题 为什么这个新闻故事会疯传?这个消息是真的还是假的?很难回答。” Gade 和他的团队在 Fiddler 开发了一个平台来解决这些问题,提高 Facebook 模型的透明度,并解决“AI 黑匣子”问题。现在,Krishna 和 Amit Paka 推出了 Fiddler 平台,帮助 Thumbtack 甚至 In-Q-Tel(中央情报局的风险基金)等公司提供模型可解释性、现代监控和偏差检测,为企业提供集中的方式来管理这些信息和构建下一代人工智能。Amit 与我分享道:“AI 可观察性对于安全和负责任的 AI 部署变得非常重要。现在它已经成为每个推出人工智能产品的公司的必备品。我们认为,如果没有人工智能可观察性,我们就不会有企业采用人工智能,而人工智能可观察性正在形成人工智能堆栈中关键的第三层。“
Arize 和 WhyLabs 是其他为生产中的LLM创建了强大的可观察性解决方案的公司。这些平台解决了添加护栏的问题,以确保实时为 LLM 申请提供适当的提示和响应。这些工具可以识别并减轻任何 LLM 模型中的恶意提示、敏感数据、有毒反应、有问题的主题、幻觉和越狱尝试。
Aporia 是另一家强调人工智能可观察平台重要性的公司,它认识到信任可能在几秒钟内失去,并需要几个月的时间才能恢复。Aporia 专注于客户终身价值/动态定价,目前正在利用其 LLM 可观察性功能深入研究生成式 AI。
模型安全
堆栈的顶部是模型安全。生成式人工智能的一项重大风险是输出存在偏差。人工智能模型倾向于采用和传播训练数据中存在的偏差。例如,人工智能简历筛选工具偏爱名字为“Jared”且有高中长曲棍球经历的候选人,这揭示了数据集中的偏见。亚马逊也面临着类似的挑战,由于培训数据主要由男性员工组成,他们的人工智能简历筛选工具表现出对男性候选人的内在偏见。
另一个担忧是人工智能的恶意使用。深度造假涉及通过可信但捏造的图像、视频或文本传播虚假信息,可能会成为一个问题。最近发生的一起事件涉及人工智能生成的五角大楼爆炸图像,引起公众的恐惧和困惑。这凸显了人工智能被错误信息武器化的可能性,以及需要采取保障措施来防止此类滥用。
此外,随着人工智能系统的复杂性和自主性的增长,可能会出现意想不到的后果。这些系统可能会表现出开发人员未预料到的行为,从而带来风险或导致不良结果。例如,Facebook 开发的聊天机器人开始发明自己的语言以更有效地进行交流,这是一个意想不到的结果,强调了严格监控和安全预防措施的必要性。
为了减轻这些风险,偏差检测和缓解等技术至关重要。这涉及识别模型输出中的偏差并采取措施将其最小化,例如提高训练数据多样性和应用公平技术。用户反馈机制(用户可以标记有问题的输出)在完善人工智能模型方面发挥着至关重要的作用。对抗性测试和验证通过困难的输入来挑战人工智能系统,以发现弱点和盲点。
强大的智能可帮助企业对其人工智能模型进行压力测试,以避免失败。Robust Intelligence 的主要产品是人工智能防火墙,通过持续的压力测试来保护公司人工智能模型免受错误的影响。有趣的是,这个人工智能防火墙本身就是一个人工智能模型,其任务是预测数据点是否会导致错误的预测。
Arthur AI 于 2019 年首次亮相,其主要目标是通过提供类似于 Robust Intelligence 解决方案的 LLM 防火墙来帮助企业监控其机器学习模型。该解决方案监控并增强模型精度和可解释性。
CredoAI 指导企业了解人工智能的道德影响。他们的重点在于人工智能治理,使企业能够大规模衡量、监控和管理人工智能产生的风险。
最后,Skyflow 提供基于 API 的服务,用于安全存储敏感和个人身份信息。Skyflow 的重点是满足金融科技和医疗保健等各个领域的需求,帮助安全存储信用卡详细信息等关键信息。
这一切如何结合在一起?
为了更深入地了解使用这些工具的领先公司,我采访了Science 首席执行官 Will Manidis。io。ScienceIO 通过构建专为医疗保健打造的最先进的基础模型,正在彻底改变医疗保健行业。数百家最重要的医疗保健组织在其工作流程的核心使用 ScienceIO 模型,这使 Will 对如何在生产中部署LLM有独特的见解。这是他所看到的:
- 计算:ScienceIO 依靠 Lambda Labs 利用本地集群来满足其计算需求。这确保了高效且可扩展的处理能力,比 AWS 或 GCP 等超大规模服务更具成本效益。
- 基础模型:ScienceIO 利用其内部数据创建自己的基础模型。他们业务的核心是 API,该 API 有助于将非结构化医疗数据实时转换为结构化数据(命名实体解析和链接),然后可用于搜索和分析目的。他们的许多客户选择在其工作流程中将 ScienceIO 与更通用的模型链接起来,以执行信息检索和合成等任务。
- Vector:ScienceIO 的核心产品之一是嵌入产品,专为医疗保健领域的高质量嵌入而构建。Will 的核心信念之一是自定义嵌入将变得越来越重要,特别是作为通用模型的补充。ScienceIO 广泛使用 Chroma 来存储和查询这些向量嵌入。
- 编排:对于应用程序开发,ScienceIO 依赖于 LangChain。内部模型存储、版本控制和访问由 Huggingface 提供支持。
- 微调:虽然 ScienceIO 的核心基础模型是专门针对医疗保健数据进行从头训练的,也就是说,他们从未见过成堆的垃圾社交媒体数据或类似数据,但许多客户有兴趣对其进行额外的微调用例。ScienceIO 推出了 Learn & Annotate,这是他们的微调和人机交互解决方案来解决这些用例。
我还与 Innerplay 首席执行官 Pedro Salles Leite 进行了交谈,该公司利用人工智能帮助人们和公司变得更具创造力。Innerplay 帮助公司以更快的方式制作视频,包括剧本创作。
Pedro 八年来一直在研究和构建人工智能用例。关于他的基础设施堆栈,他说他的工作是确保产品对用户有意义……而不是设置编排或基础模型 - 只是增加了另一种复杂性。这是他的堆栈:
- 基础模型:Innerplay 使用 14 种不同的基础模型将想法变为现实。他们使用封闭模型主要是因为“在产品适合市场之前没有 GPU”。
- 矢量数据库:Innerplay 使用矢量数据库来执行处理 PDF 文档等任务。他们从 PDF 生成脚本,需要矢量数据库来完成此操作。
- 微调:Innerplay 非常相信微调。该公司手动准备数据集,但计划使用人工智能来准备数据,以便将来进行微调。
- 原型制作:他们用它来评估输出和比较模型。Spellbook by Scale 通常用于在进入 Python/生产环境之前快速测试机器学习过程中的迭代。
- 人工智能可观察性:他们现在开始考虑人工智能可观察性,以注重隐私的方式改进他们的人工智能。作为一个内容创作平台。佩德罗说,“Innerplay 需要确保人们用它来做善事”。
结论
对生成式人工智能基础设施的探索仅仅触及了表面,技术开发和底层基础组件投资的快速进步是引人注目的。像 MosaicML 这样的公司被以惊人的金额收购,并且该领域的参与者数量不断增加,这表明了该领域的巨大价值和兴趣。
这是一个复杂且不断发展的场景,具有多个层次,从基础模型到微调,从半导体到云托管,从应用程序框架到模型监督。每个层在利用生成式人工智能的力量并使其在各个行业的应用中都发挥着至关重要的作用。在这项研究中,许多从一个领域起步的公司扩展到其他领域。
相关文章:
人工智能基础-趋势-架构
在过去的几周里,我花了一些时间来了解生成式人工智能基础设施的前景。在这篇文章中,我的目标是清晰概述关键组成部分、新兴趋势,并重点介绍推动创新的早期行业参与者。我将解释基础模型、计算、框架、计算、编排和矢量数据库、微调、标签、合…...
Date日期工具类(数据库日期区间问题)
文章目录 前言DateUtils日期工具类总结 前言 在我们日常开发过程中,当涉及到处理日期和时间的操作时,字符串与Date日期类往往要经过相互转换,且在SQL语句的动态查询中,往往月份的格式不正确,SQL语句执行的效果是不同的…...

为什么需要 TIME_WAIT 状态
还是用一下上一篇文章画的图 TCP 的 11 个状态,每一个状态都缺一不可,自然 TIME_WAIT 状态被赋予的意义也是相当重要,咱们直接结论先行 上文我们提到 tcp 中,主动关闭的一边会进入 TIME_WAIT 状态, 另外 Tcp 中的有 …...

Linux——(第七章)文件权限管理
目录 一、基本介绍 二、文件/目录的所有者 1.查看文件的所有者 2.修改文件所有者 三、文件/目录的所在组 1.修改文件/目录所在组 2.修改用户所在组 四、权限的基本介绍 五、rwx权限详解 1.rwx作用到文件 2.rwx作用到目录 六、修改权限 一、基本介绍 在Linux中&…...

Scala在大数据领域的崛起:当前趋势和未来前景
文章首发地址 Scala在大数据领域有着广阔的前景和现状。以下是一些关键点: Scala是一种具有强大静态类型系统的多范式编程语言,它结合了面向对象编程和函数式编程的特性。这使得Scala非常适合处理大数据,因为它能够处理并发、高吞吐量和复杂…...

前端面试经典题--页面布局
题目 假设高度已知,请写出三栏布局,其中左、右栏宽度各为300px,中间自适应。 五种解决方式代码 浮动解决方式 绝对定位解决方式 flexbox解决方式 表格布局 网格布局 源代码 <!DOCTYPE html> <html lang"en"> <…...

【webrtc】接收/发送的rtp包、编解码的VCM包、CopyOnWriteBuffer
收到的rtp包RtpPacketReceived 经过RtpDepacketizer 解析后变为ParsedPayloadRtpPacketReceived 分配内存,执行memcpy拷贝:然后把 RtpPacketReceived 给到OnRtpPacket 传递:uint8_t* media_payload = media_packet.AllocatePayload(rtx_payload.size());RTC...

Bash常见快捷键
生活在 Bash Shell 中,熟记以下快捷键,将极大的提高你的命令行操作效率。 编辑命令 Ctrl a :移到命令行首Ctrl e :移到命令行尾Ctrl f :按字符前移(右向)Ctrl b :按字符后移&a…...
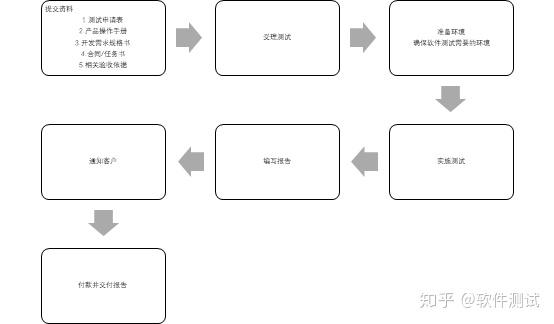
软件验收测试
1. 服务流程 验收测试 2. 服务内容 测试过程中,根据合同要求制定测试方案,验证工程项目是否满足用户需求,软件质量特性是否达到系统的要求。 3. 周期 10-15个工作日 4. 报告用途 可作为进行地方、省级、国家、部委项目的验收࿰…...

Java 与零拷贝
零拷贝是由操作系统实现的,使用 Java 中的零拷贝抽象类库在支持零拷贝的操作系统上运行才会实现零拷贝,如果在不支持零拷贝的操作系统上运行,并不会提供零拷贝的功能。 简述内核态和用户态 Linux 的体系结构分为内核态(内核空间…...

AI性能指标解析:误触率与错误率
简介:随着人工智能(AI)技术的不断发展,它越来越多地渗透到我们日常生活的各个方面。从个人助手到自动驾驶,从语音识别到图像识别,AI正不断地改变我们与世界的互动方式。但你有没有想过,如何准确…...

count(*) 和 count(1) 有什么区别?哪个性能最好?
哪种 count 性能最好? count() 是什么? count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数的作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录由多少条。…...

橡胶密封件为什么会老化?
橡胶密封件以其优良的密封性能被广泛应用于各个行业。然而,随着时间的推移,这些橡胶密封件往往会恶化和老化。在这篇文章中,我们将探讨橡胶密封件老化的原因。 1,导致橡胶密封件老化的主要因素之一是暴露在阳光和紫外线(UV)辐射下…...

Uboot中bootargs以及bootcmd设置
Uboot命令 一、Uboot基础命令 查看帮助信息: uboot#help打印环境变量: uboot#printenv其他命令: uboot#help ? - 帮助命令,等同于 help base - 打印或设置地址偏移量 bdinfo - 打印板级信息结构 boot …...

冠达管理:减肥药概念再度爆发,常山药业两连板,翰宇药业等大涨
减肥药概念12日盘中再度拉升,到发稿,常山药业“20cm”涨停,翰宇药业涨超14%,德展健康涨停,金凯生科涨近9%,争气股份、普利制药、昊帆生物涨约5%,诺泰生物、圣诺生物、华森制药等涨超4%。 常山药…...
实现在外网SSH远程访问内网树莓派的详细教程
文章目录 如何在局域网外SSH远程访问连接到家里的树莓派?如何通过 SSH 连接到树莓派步骤1. 在 Raspberry Pi 上启用 SSH步骤2. 查找树莓派的 IP 地址步骤3. SSH 到你的树莓派步骤 4. 在任何地点访问家中的树莓派4.1 安装 Cpolar4.2 cpolar进行token认证4.3 配置cpol…...

Pytorch框架详解
文章目录 引言1. 安装与配置1.1 如何安装PyTorch1.2 验证安装 2. 基础概念2.1 张量(Tensors)2.1.1 张量的基本特性2.1.2 创建张量2.1.3 张量操作 2.2 自动微分(Autograd)2.2.1 基本使用2.2.2 计算梯度2.2.3 停止追踪历史2.2.4 自定…...

2023年9月制造业NPDP产品经理国际认证报名来这错不了
产品经理国际资格认证NPDP是新产品开发方面的认证,集理论、方法与实践为一体的全方位的知识体系,为公司组织层级进行规划、决策、执行提供良好的方法体系支撑。 【认证机构】 产品开发与管理协会(PDMA)成立于1979年,是…...
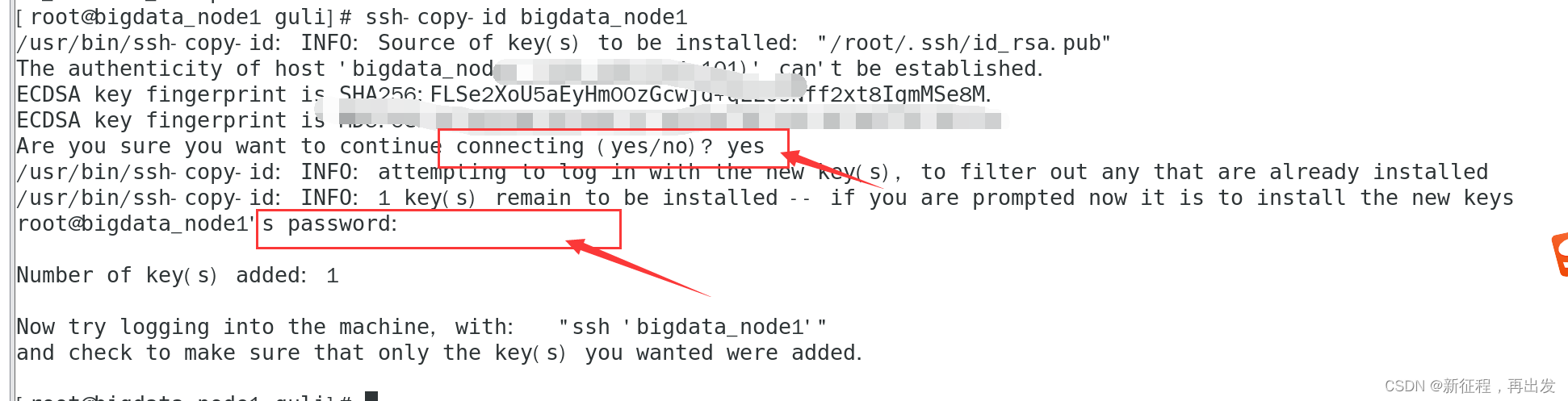
linux(centos7)配置SSH免密登录
给三台机器配置主机名映射 在Windows系统中修改hosts文件,新增以下内容; 192.168.xxx.xxx bigdata_node1 192.168.xxx.xxx bigdata_node2 192.168.xxx.xxx bigdata_node33台Linux的/etc/hosts文件中,填入如下内容。 192.168.xxx.xxx bigda…...
cf 交互题
今天cf遇到了交互题,这个交互题的算法很很很简单,但是在交互上卡了,导致交上的代码都不算罚时。(更伤心了。 所以,现在写一下交互题的做法,印象深刻嘛。 交互题,就是跟机器进行交互。你代码运…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...