【2023最新B站评论爬虫】用python爬取上千条哔哩哔哩评论
文章目录
- 一、爬取目标
- 二、展示爬取结果
- 三、爬虫代码
- 四、同步视频
- 五、附完整源码
您好,我是 @马哥python说,一枚10年程序猿。
一、爬取目标
之前,我分享过一些B站的爬虫:
【Python爬虫案例】用Python爬取李子柒B站视频数据
【Python爬虫案例】用python爬哔哩哔哩搜索结果
【爬虫+情感判定+Top10高频词+词云图】"谷爱凌"热门弹幕python舆情分析
但我学习群中小伙伴频繁讨论B站评论的爬取,所以,再分享一个B站视频评论的爬虫。
二、展示爬取结果
首先,看下部分爬取数据:

爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
三、爬虫代码
导入需要用到的库:
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
定义一个请求头:
# 请求头
headers = {'authority': 'api.bilibili.com','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',# 需定期更换cookie,否则location爬不到'cookie': "需换成自己的cookie值",'origin': 'https://www.bilibili.com','referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548','sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-site','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
请求头中的cookie是个很关键的参数,如果不设置cookie,会导致数据残缺或无法爬到数据。
那么cookie如何获取呢?打开开发者模式,见下图:

由于评论时间是个十位数:

所以开发一个函数用于转换时间格式:
def trans_date(v_timestamp):"""10位时间戳转换为时间字符串"""timeArray = time.localtime(v_timestamp)otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)return otherStyleTime
向B站发送请求:
response = requests.get(url, headers=headers, ) # 发送请求
接收到返回数据了,怎么解析数据呢?看一下json数据结构:
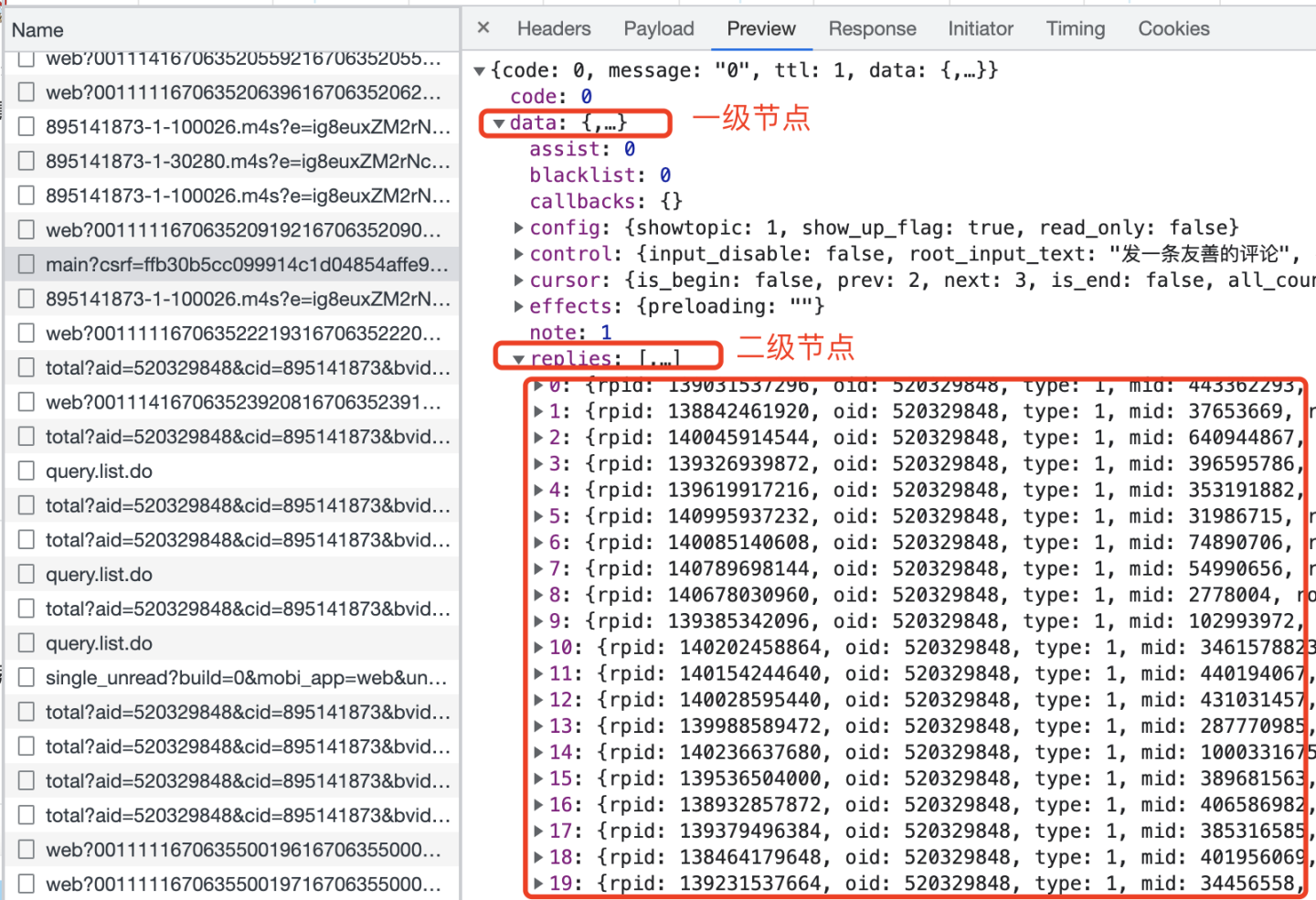
0-19个评论,都存放在replies下面,replies又在data下面,所以,这样解析数据:
data_list = response.json()['data']['replies'] # 解析评论数据
这样,data_list里面就是存储的每条评论数据了。
接下来吗,就是解析出每条评论里的各个字段了。
我们以评论内容这个字段为例:
comment_list = [] # 评论内容空列表
# 循环爬取每一条评论数据
for a in data_list:# 评论内容comment = a['content']['message']comment_list.append(comment)
其他字段同理,不再赘述。
最后,把这些列表数据保存到DataFrame里面,再to_csv保存到csv文件,持久化存储完成:
# 把列表拼装为DataFrame数据
df = pd.DataFrame({'视频链接': 'https://www.bilibili.com/video/' + v_bid,'评论页码': (i + 1),'评论作者': user_list,'评论时间': time_list,'IP属地': location_list,'点赞数': like_list,'评论内容': comment_list,
})
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding=‘utf_8_sig’,否则可能会产生乱码问题!
下面,是主函数循环爬取部分代码:(支持多个视频的循环爬取)
# 随便找了几个"世界杯"相关的视频ID
bid_list = ['BV1DP411g7jx', 'BV1M24y117K3', 'BV1nt4y1N7Kj']
# 评论最大爬取页(每页20条评论)
max_page = 30
# 循环爬取这几个视频的评论
for bid in bid_list:# 输出文件名outfile = 'b站评论_{}.csv'.format(now)# 转换aidaid = bv2av(bid=bid)# 爬取评论get_comment(v_aid=aid, v_bid=bid)
四、同步视频
演示视频:
【2023爬虫演示】用python抓取上千条「卡塔尔世界杯」B站评论!
五、附完整源码
附完整代码: 【B站评论爬虫】用python爬取上千条哔哩哔哩评论
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。
相关文章:
【2023最新B站评论爬虫】用python爬取上千条哔哩哔哩评论
文章目录 一、爬取目标二、展示爬取结果三、爬虫代码四、同步视频五、附完整源码 您好,我是 马哥python说,一枚10年程序猿。 一、爬取目标 之前,我分享过一些B站的爬虫: 【Python爬虫案例】用Python爬取李子柒B站视频数据 【Pyt…...

mysql设置max_sp_recursion_depth,sql_mode
mysql 中设置 @@max_sp_recursion_depth select @@max_sp_recursion_depth; 今天在mysql 写存储过程递归调用时,发现老是报错(recovery limit 0(as set by the max_sp_recursion_depth));后来百度下发现 max_sp_recursion_depth设置不对; 这个修改涉及到全局和session级修…...
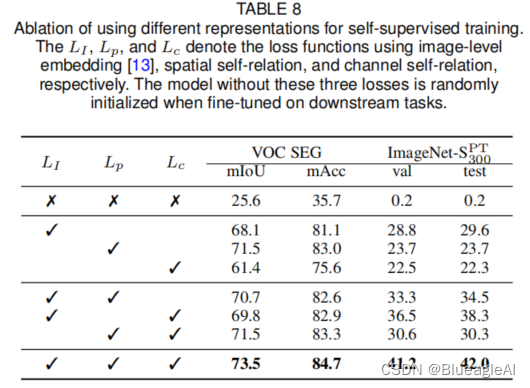
论文阅读:SERE: Exploring Feature Self-relation for Self-supervised Transformer
Related Work Self-supervised 学习目的是在无人工标注的情况下通过自定制的任务(hand-crafted pretext tasks)学习丰富的表示。 Abstract 使用自监督学习为卷积网络(CNN)学习表示已经被验证对视觉任务有效。作为CNN的一种替代…...

遥感数据与作物模型同化应用:PROSAIL模型、DSSAT模型、参数敏感性分析、数据同化算法、模型耦合、精度验证等主要环节
查看原文>>>遥感数据与作物模型同化实践技术应用 基于过程的作物生长模拟模型DSSAT是现代农业系统研究的有力工具,可以定量描述作物生长发育和产量形成过程及其与气候因子、土壤环境、品种类型和技术措施之间的关系,为不同条件下作物生长发育及…...
Navicat15工具连接PostgreSQL15失败
1.错误现象及原因 错误现象: 错误原因: postgresql 15版本中 pg_database 系统表把 datlastsysoid 列删除了,所以造成了此错误。 2.解决方法 (1)将Navicat工具更新到官网最新版本。 (2)更换…...

开源AI家庭自动化助手-手机控制家庭智能家居服务
产品简介 将本地控制和隐私放在首位的开源家庭自动化。由全球开发者和 DIY 爱好者社区提供支持。非常适合在 Raspberry Pi 或本地服务器上运行。 功能介绍 1. 控制面板在控制面板,你可以查看家庭的灯光,温度,门铃,音响…...

解决CSS定位错乱/疑难杂症的终极绝招==》从样式污染开始排查
我们接手他人或者第三方项目的时候,有时候会遇到一些莫名其妙的问题: 明明自己的样式写的没有问题,但是网页上却显示的乱七八糟的,或者效果完全出不来。 案例如下: 这里只用了很典型的flex弹性布局,并没有…...

【笔记】《C++性能优化指南》Ch3 测量性能
【笔记】《C性能优化指南》Ch3 测量性能 1. 优化思想1.1 专业的性能测试流程1.2 优化准则1.2.1 90/10规则1.2.2 Amdahl定律 2. 进行实验2.1 记实验笔记2.2 测量基准性能并设定目标2.3 你只能改善你能够测量的 3. 分析程序执行3.1 实现分析器的方式3.2 分析器的优缺点 4. 测量长…...
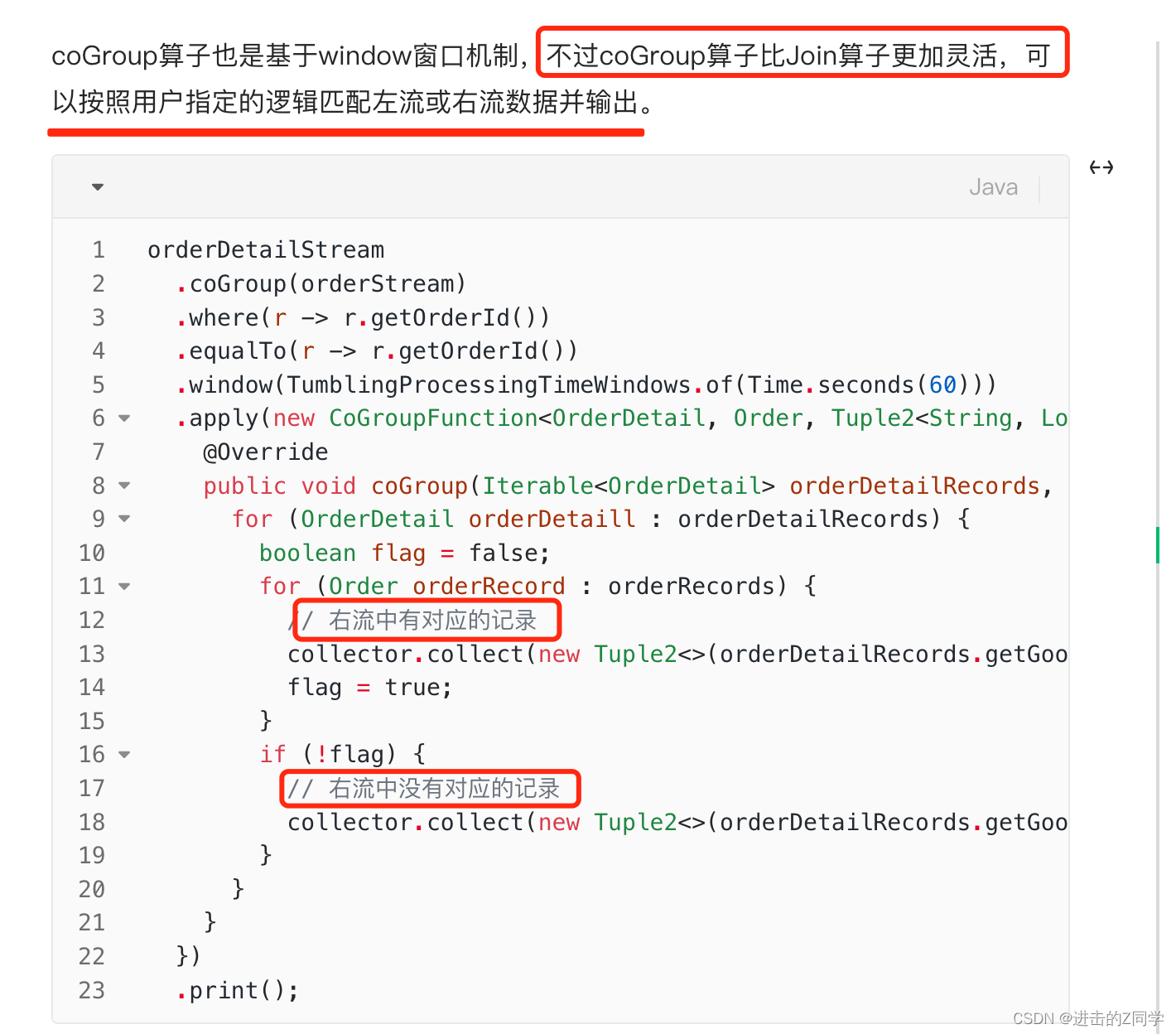
2023大数据面试总结
文章目录 Flink(SQL相关后面专题补充)1. 把状态后端从FileSystem改为RocksDB后,Flink任务状态存储会发生哪些变化?2. Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite?3. watermark 到底…...
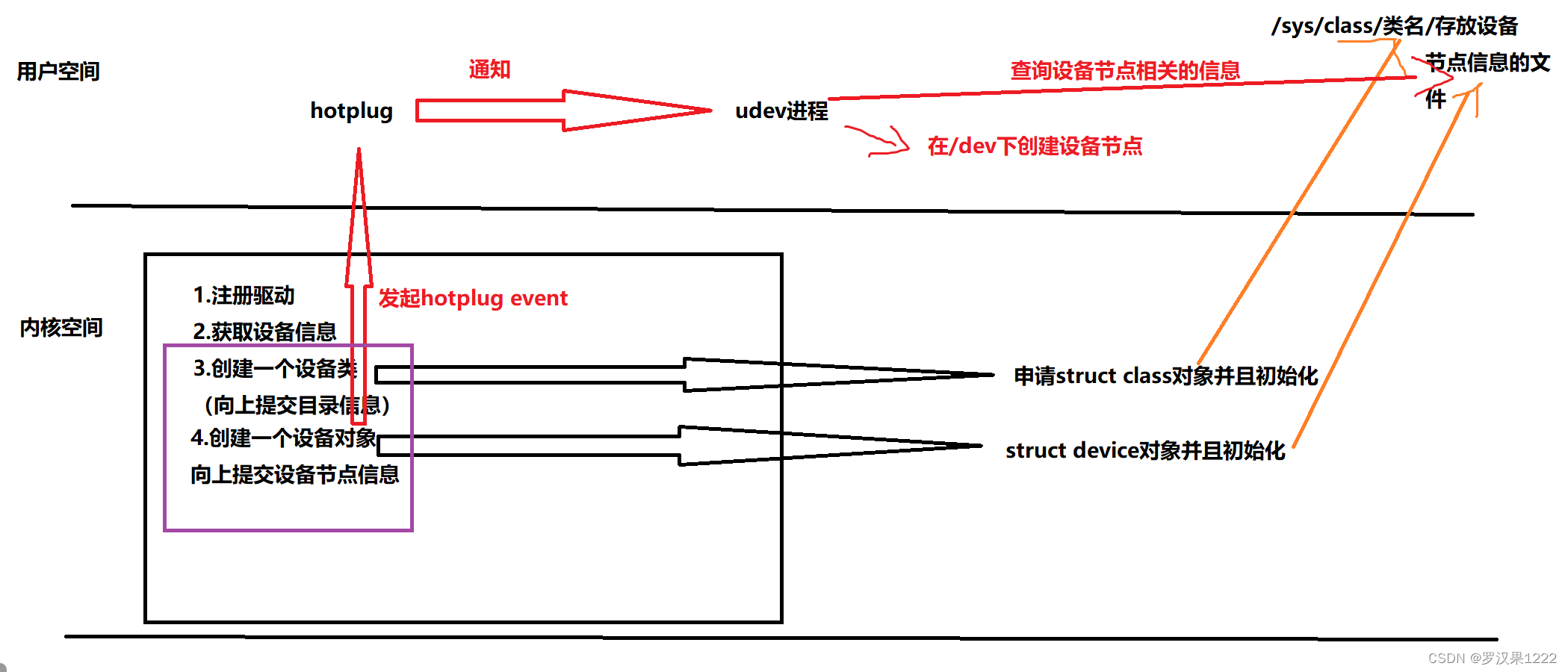
udev自动创建设备节点的机制
流程框图如下 自动创建 1 内核检测到设备插入后,会发送一个uevent事件到内核中,并提供有关硬件设备的信息。 2 udevd守护程序收到uevent事件后,创建一个设备类,(向上提交目录信息),会在内核中…...
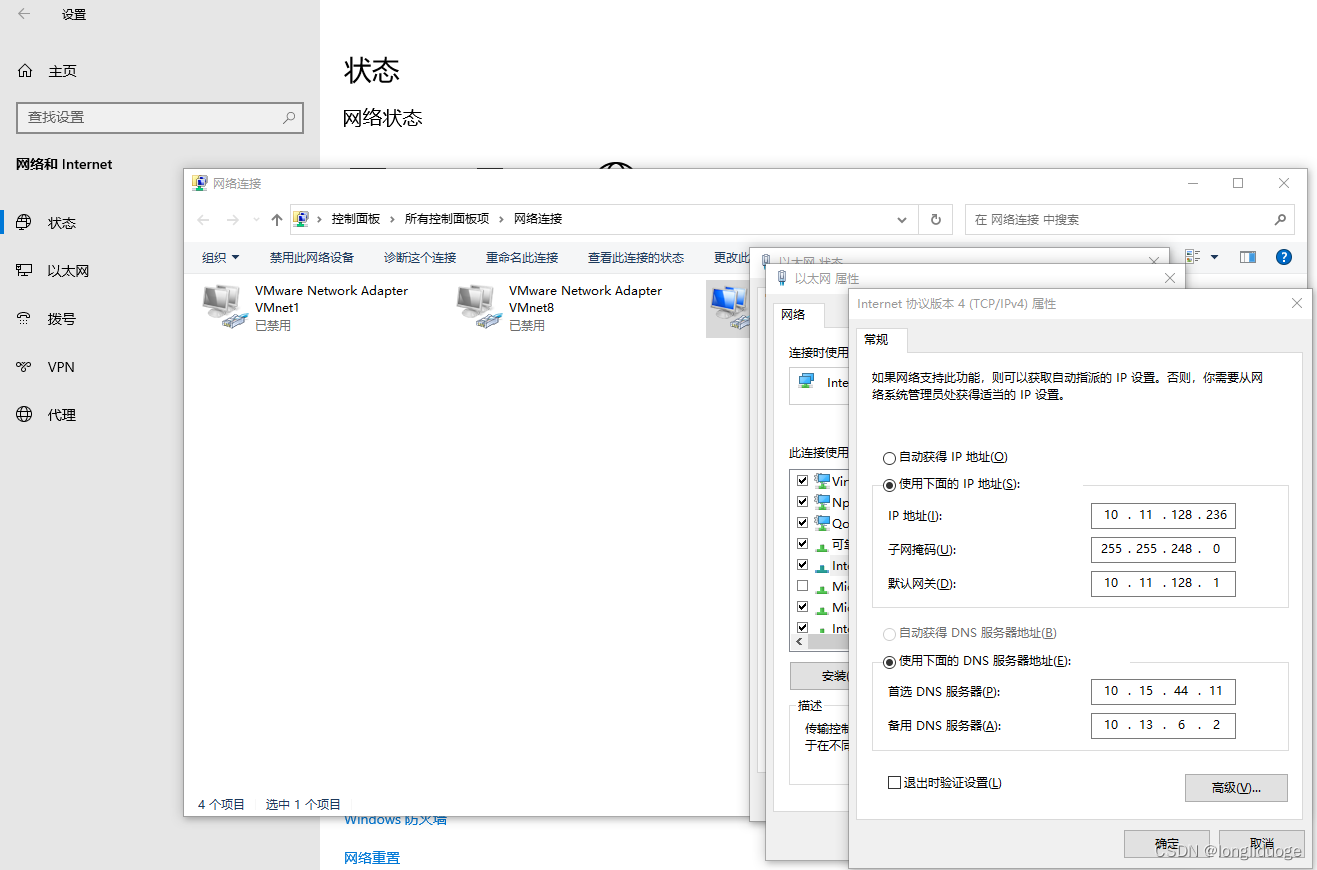
访问局域网内共享文件时报错0x80070043,找不到网络名
我是菜鸡 此篇只为分享一个我遇到的很简单的但是排查了好久的小问题。 我的网络环境是在校园网内, 自己的办公电脑设置了固定IP:10.11.128.236,同事电脑IP为:10.11.128.255 本人需要访问同事在局域网内分享的文件,…...

Java定时器
对于定时器的设定,想必大家在不少网站或者文章中见到吧,但是所谓的定时器如何去用Java代码来bianx呢??感兴趣的老铁,可以看一下笔者这篇文章哟~~ 所谓的定时器就是闹钟!! 设定一个时间&#x…...

科普js加密时出现的错误
当你在使用Babel解析JavaScript代码时,可能会遇到一个错误信息:“Deleting local variable in strict mode”(在严格模式下删除本地变量)。这个错误信息通常表示你正在尝试删除一个使用let或const关键字声明的变量。在JavaScript的…...

MYSQL优化——B+树讲解
B-/B树看 MySQL索引结构 B-树 B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树.它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图. B-树有如下特点: 所有键值分布在整颗树中; 任何一…...
Rokid Jungle--Station pro
介绍和功能开发 YodaOS-Master操作系统:以交换计算为核心,实现单目SLAM空间交互,具有高精度、实时性和稳定性。发布UXR2.0SDK,为构建空间内容提供丰富的开发套件 多模态交互 算法原子化 多种开发工具协同 多生态支持 骁龙XR2…...
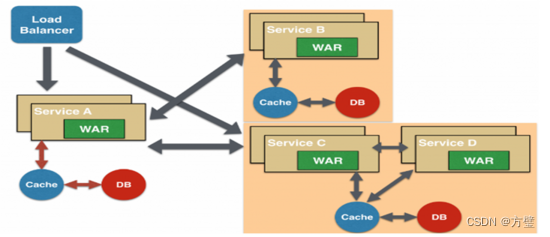
如何实现微服务
一、问题拆解 1.1、客户端如何访问这些服务 原来的Monolithic方式开发,所有的服务都是本地的,UI可以直接调用;现在按功能拆分成独立的服务,跑在独立的虚拟机上的Java进程了。客户端UI如何访问他的? 后台有N个服务&a…...

MySQL如何进行增量备份与恢复?
目录 一、MySQL 介绍 二、增量备份 三、备份恢复 一、MySQL 介绍 MySQL是一款开源的关系型数据库管理系统(RDBMS),它以其可靠性、灵活性和易于使用而备受赞誉。以下是关于MySQL数据库的介绍: MySQL是由瑞典公司MySQL AB开发&…...

微服务框架
一、目标 微服务框架通过组件化的方式提供微服务的开发部署、服务注册发现、服务治理与服务运维等能力。主流的微服务框架有开源的Spring Cloud、Dubbo与Service Mesh等,各大云厂商也基于开源的微服务框架,集成相关的云服务,实现企业级的微服…...
(matplotlib)如何让各个子图ax大小(宽度和高度)相等
文章目录 不相等相等 import matplotlib.pyplot as plt import numpy as np plt.rc(font,familyTimes New Roman) import matplotlib.gridspec as gridspec不相等 我用如下subplots代码画一行四个子图, fig,(ax1,ax2,ax3,ax4)plt.subplots(1,4,figsize(20,10),dpi…...

python http 上传文件
文章目录 改进质量 import random import requests from requests_toolbelt.multipart.encoder import MultipartEncoderurl http://ip:port/email data MultipartEncoder(fields{receiverId: xxxx163.com,mailSubject: mailSubject,content: content,fileList: (file_name, …...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...