mapreduce与yarn
文章目录
- 一、MapReduce
- 1.1、MapReduce思想
- 1.2、MapReduce实例进程
- 1.3、MapReduce阶段组成
- 1.4、MapReduce数据类型
- 1.5、MapReduce关键类
- 1.6、MapReduce执行流程
- 1.6.1、Map阶段执行流程
- 1.6.2、Map的shuffle阶段执行流程
- 1.6.3、Reduce阶段执行流程
- 1.7、MapReduce实例WordCount
- 二、YARN
- 2.1、YARN简介
- 2.2、功能说明
- 2.3、YARN架构、组件
- 2.4、YARN执行流程
- 2.5、YARN资源调度器Schedule
一、MapReduce
1.1、MapReduce思想
- MapReduce的思想核心是“先分再合,分而治之”。
- 所谓“分而治之”就是把一个复杂的问题,按照一定的分解方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。
- Map表示第一阶段:负责拆分:即把复杂的任务分解为若干个“简单的子任务”来进行并行处理。可以进行拆分的前提是这些小人物可以并行计算,彼此之间几乎没有依赖关系。
- Reduce表示第二阶段,负责合并:即对map阶段的结果进行全局汇总。
1.2、MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类:
- MRAppMaster: 负责整个MR程序的过程调度及状态协调。
- MapTask: 负责map阶段的整个数据处理流程。
- Reduce:负责reduce阶段的整个数据处理流程。
1.3、MapReduce阶段组成
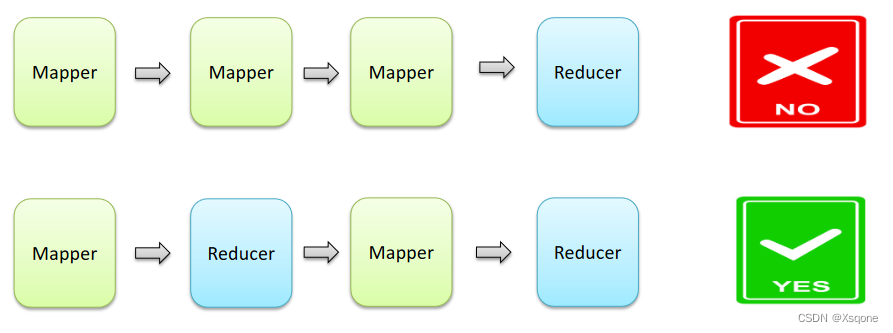
- 一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段。
- 如果业务逻辑复杂,只能使用多个MapReduce查询串行运行。
1.4、MapReduce数据类型
- 整个MapReduce程序中,数据都是以KV键值对的形式流传的。
1.5、MapReduce关键类
- GenericOptionsParser是为Hadoop框架解析命令行参数的工具类。
- InputFormat接口,实现类包括:Fileinputformat 等,主要作用于文件为输入及切割。
- Mapper将输入的kv对映射成中间数据kv对集合。Maps将输入记录转变为中间记录。
- Reducer根据key将中间数据集合处理合并为更小的数据结果集。
- Partitioner对数据安装key进行分区。
- OutputCllector文件的输出。
- Combiner本地聚合,本地化的reduce。
1.6、MapReduce执行流程
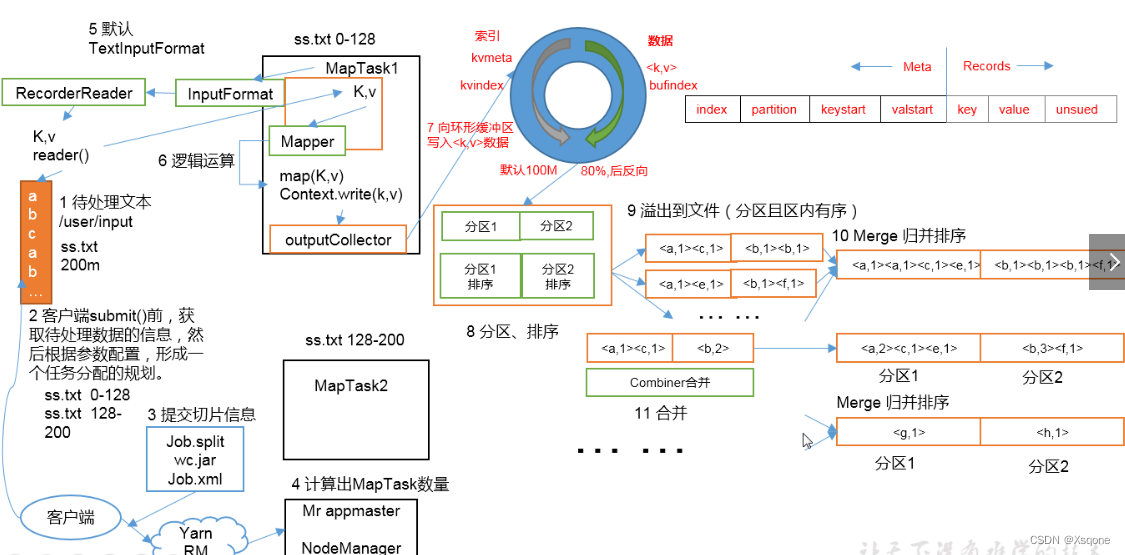

1.6.1、Map阶段执行流程
- 在MapReduce程序读取文件的输入目录上存放相应文件。
- 按照一定的标准逐个进行逻辑切片,形成切片规划
默认Split size = Block size(128M),每一个切片由一个MapTask处理。
切片会有1.1的冗余(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1配就会划分为一块切片) - 提交信息给yarn
包含(切片,jar包,以及job运行相关参数)。 - yarn启动MRAPPmaster根据切片个数计算出需要的MapTask数量。
- 使用客户端指定的InputFormat来读取数据,返回对应的<k,v>键值对
InputFormat默认使用子类TextInputFormat的createRecordReader(规则为LineRecordReader)来逐行读取数据。
返回的<k,v>键值对:k为偏移量,v为偏移量的内容。 - 将<k,v>键值对传给客户端定义的map方法,做逻辑运算。
1.6.2、Map的shuffle阶段执行流程
- map运算完后将结果<k,v>写入环形缓冲区
环形缓冲区默认100M(内存) - 进行分区、排序
- 溢出到文件(分区且区内有序)
到达80%进行溢写到磁盘,在缓冲区中数据进行反向写。 - Merge归并排序。
把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。 - Combiner合并。
在程序中可以选用,在reduce前进行预先处理数据。
1.6.3、Reduce阶段执行流程
- 在MapTask任务完成后,启动相应数量的ReduceTask,并告知ReduceTask处理数据分区。
- ReduceTask进程启动后,从MapTask拉取数据
- 进行归并排序,按照相同key的KV为一组,调用客户端定义的reduce()方法进行逻辑运算。
- 运算完毕后,使用OutPutFormat将结果输出到文件。
默认为TextOutputFormat的RecordWriter方法
1.7、MapReduce实例WordCount
WordCountDriver
package org.example.workcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @program: hadoopstu* @interfaceName WordCountDriver* @description:* @author: 太白* @create: 2023-02-06 12:16**/
public class WordCountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(WordCountDriver.class);job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);
// 指定map输入的文件路径FileInputFormat.setInputPaths(job, new Path("E:\\lovejava\\student\\hadoopstu\\in\\workcount.txt"));
// 指定reduce输出的文件路径Path path = new Path("E:\\lovejava\\student\\hadoopstu\\in\\out1");FileSystem fileSystem = FileSystem.get(path.toUri(), configuration);if (fileSystem.exists(path)) {fileSystem.delete(path, true);}FileOutputFormat.setOutputPath(job,path);job.waitForCompletion(true);}
}WordCountMapper
package org.example.workcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @program: hadoopstu* @interfaceName WordCountMapper* @description:* @author: 太白* @create: 2023-02-06 12:16**/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text text = new Text();IntWritable intWritable = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {System.out.println("WordCountMapper stage key:"+key+"value:"+value);String[] words = value.toString().split(" ");for (String word : words) {text.set(word);intWritable.set(1);context.write(text,intWritable);}}
}WordCountReduce
package org.example.workcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @program: hadoopstu* @interfaceName WordCountReduce* @description:* @author: 太白* @create: 2023-02-06 12:16**/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {System.out.println("reduce stage key:"+key+"values:"+values.toString());int count = 0;for (IntWritable value : values) {count += value.get();}// LongWritable longWritable = new LongWritable();
// longWritable.set(count);LongWritable longWritable = new LongWritable(count);System.out.println("key:"+key+"resultValue:"+longWritable.get());context.write(key,longWritable);}
}二、YARN
2.1、YARN简介
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。
- 是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
- 它的引入为集群在利用率、资源同一管理和数据共享等方面带来巨大好处。
- 可以把Hadoop YARN理解为一个分布式的操作系统平台,而MapReduce等计算程序则相等于云星宇操作系统之上的应用程序,YARN为这些程序提供运算所需的资源。
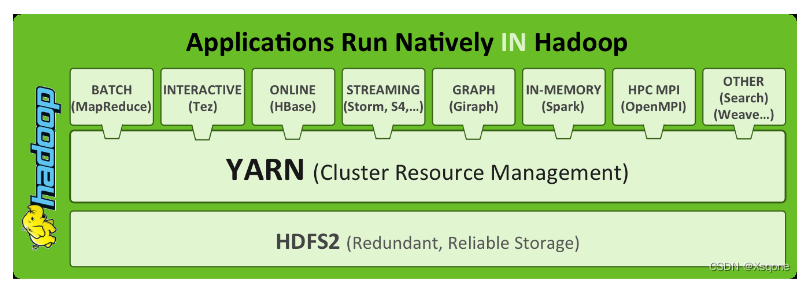
2.2、功能说明
- 资源管理系统:集群的硬件资源,和程序运行相关。比如内存、CPU等。
- 调度平台:多个程序同时申请计算资源如何分配、调度的规则(算法)。
- 通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
2.3、YARN架构、组件
- ResourceManager(RM)
YARN中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。
接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。- NodeManager(NM)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。
根据RM命令,启动Container容器(资源的抽象)、件事容器的资源使用情况。并且向RM主角色会报资源使用情况。- ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM。
负责程序内部各阶段的资源申请,监督程序的执行情况。
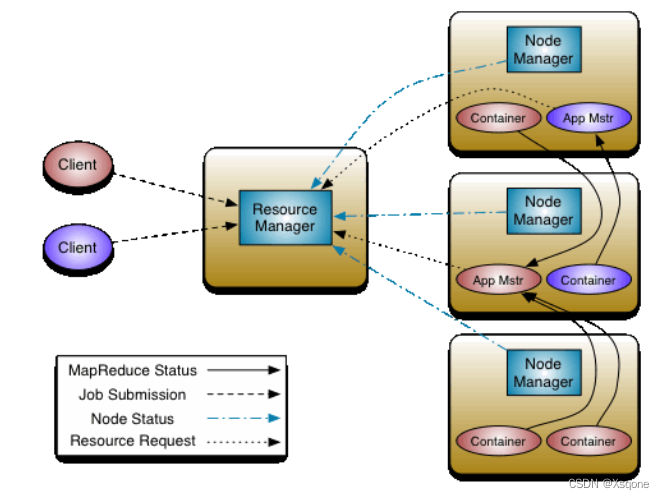
2.4、YARN执行流程
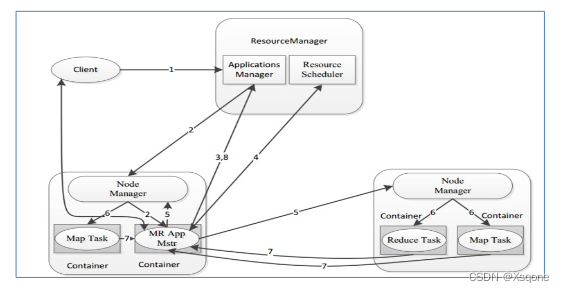
- 用户通过客户端向YARN中ResourceManager提交应用程序。
- ResourceManager为该应用程序分配第一个Container(容器),并与对应的NodeManager通信,要求
它在这个Container中启动这个应用程序的ApplicationMaster。 - ApplicationMaster启动成功之后,首先向ResourceManager注册并保持通信,这样用户可以直接通过ResourceManage查看应用程序的运行状态(处理了百分之几)。
- AM为本次程序内部的各个Task任务向RM申请资源,并监控它的运行状态。
- 一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务。
- NodeManager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster 查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。
2.5、YARN资源调度器Schedule
-
在理想情况下,应用程序提出的请求将立即得到YARN批准。但是实际中,资源是有限的,并且在繁忙的群集上,应用程序通常将需要等待其某些请求得到满足。YARN调度程序的工作是根据一些定义的策略为应用程序分配资源。
-
在YARN中,负责给应用分配资源的就是Scheduler,它是ResourceManager的核心组件之一。Scheduler完全专用于调度作业,它无法跟踪应用程序的状态。
-
一般而言,调度是一个难题,并且没有一个“最佳”策略,为此,YARN提供了多种调度器和可配置的策略供选择。
-
三种调度器
FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容量调度器)、Fair Scheduler(公平调度器)。 -
Apache版本YARN默认使用Capacity Scheduler。
-
如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置。
关于资源调度器详情请查看
相关文章:
mapreduce与yarn
文章目录一、MapReduce1.1、MapReduce思想1.2、MapReduce实例进程1.3、MapReduce阶段组成1.4、MapReduce数据类型1.5、MapReduce关键类1.6、MapReduce执行流程1.6.1、Map阶段执行流程1.6.2、Map的shuffle阶段执行流程1.6.3、Reduce阶段执行流程1.7、MapReduce实例WordCount二、…...

鲲鹏云服务器上使用 traceroute 命令跟踪路由
traceroute 命令跟踪路由 它由遍布全球的几万局域网和数百万台计算机组成,并通过用于异构网络的TCP/IP协议进行网间通信。互联网中,信息的传送是通过网中许多段的传输介质和设备(路由器,交换机,服务器,网关…...

代码随想录算法训练营第47天 || 198.打家劫舍 || 213.打家劫舍II || 337.打家劫舍III
代码随想录算法训练营第47天 || 198.打家劫舍 || 213.打家劫舍II || 337.打家劫舍III 198.打家劫舍 题目介绍 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统&…...

JVM调优方式
对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数。 1.Full GC 会对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个堆进行回收,所以比较慢,因此应该尽可能减少Full GC的次数。 2.导致Full GC的原因 1)年老…...

机器学习模型监控的 9 个技巧
机器学习 (ML) 模型是非常敏感的软件;它们的成功使用需要进行仔细监控以确保它们可以正常工作。当使用所述模型的输出自动做出业务决策时尤其如此。这意味着有缺陷的模型通常会对终端客户的体验产生真正的影响。因此,监控输入数据(和输出&…...

Linux 实现鼠标侧边键实现代码与网页的前进、后退
前言 之前一直是使用windows进行开发,最近转到linux后使用VsCode编写代码。 但是不像在win环境下,使用鼠标侧边键可以实现代码的前向、后向跳转。浏览网页时也不行(使用Alt Left可以后退)。 修改键盘映射实在没有那么方便&…...

健身蓝牙耳机推荐,推荐五款适合健身的蓝牙耳机
出门运动健身,有音乐的陪伴是我们坚持运动的不懈动力,在健身当中佩戴的耳机,佩戴舒适度以及牢固程度是我们十分需要注意的,还不知道如何选择健身蓝牙耳机,可以看看下面这些运动蓝牙耳机分享。 1、南卡Runner Pro4骨传…...
Type-c诱骗取电芯片大全
随着Type-C的普及和推广,目前市面上的电子设备正在慢慢淘汰micro-USB接口,逐渐都更新成了Type-C接口,micro-USB接口从2007年上市,已经陪伴我们走过十多个年头,如今也慢慢退出舞台。 今天我们评测的产品是市面上Type-C…...
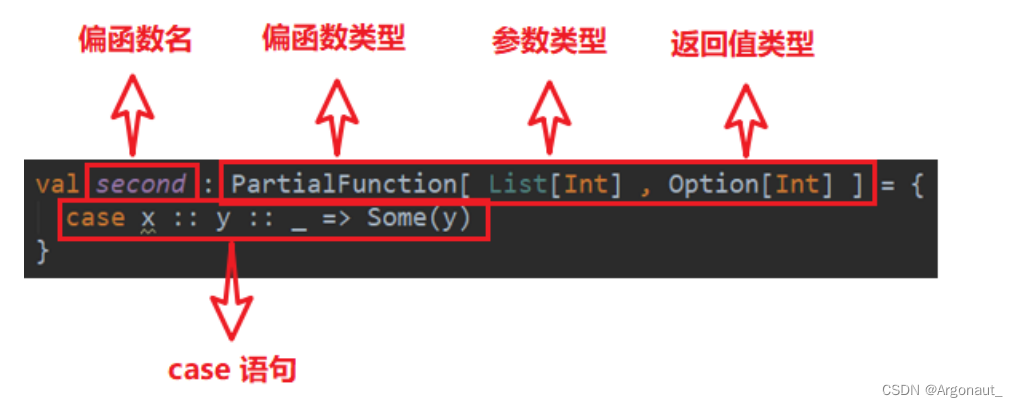
Scala模式匹配详解(第八章:基本语法、模式守卫、模式匹配类型)(尚硅谷笔记)
模式匹配第 8 章 模式匹配8.1 基本语法8.2 模式守卫8.3 模式匹配类型8.3.1 匹配常量8.3.2 匹配类型8.3.3 匹配数组8.3.4 匹配列表8.3.5 匹配元组8.3.6 匹配对象及样例类8.4 变量声明中的模式匹配8.5 for 表达式中的模式匹配8.6 偏函数中的模式匹配(了解)第 8 章 模式匹配 Scal…...
Linux:基于libevent读写管道代码
基于libevent读写管道代码: 读端: #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <string.h> #include <event2/event.h> #include…...

2022年中职网络安全逆向题目整理合集
中职网络安全逆向题目整理合集逆向分析:PE01.exe算法破解:flag0072算法破解:flag0073算法破解:CrackMe.exe远程代码执行渗透测试天津逆向re1 re2逆向分析:PE01.exe FTPServer20220509(关闭链接) FTP用户名:PE01密码…...
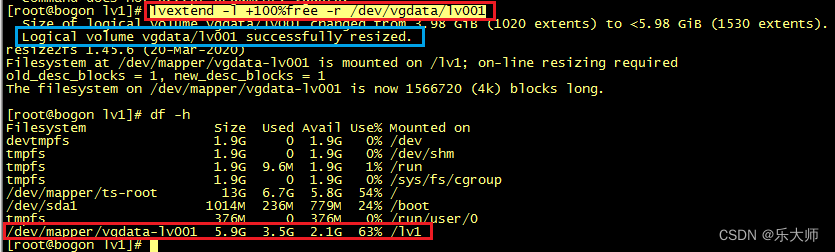
Tencent OS下逻辑卷(LVM)增加硬盘扩容
上一篇文章写了逻辑卷创建以及使用剩余空间为已经创建的逻辑卷扩容。 本篇是针对卷组空间已经用尽时的扩容方法。那就是增加硬盘。 首先我们为虚拟机增加硬盘/dev/sdd 使用fdisk为/dev/sdd分区,方法在上一篇文章已经描述,在此不再赘述。 新增的硬盘使用如下命令添加到卷组…...
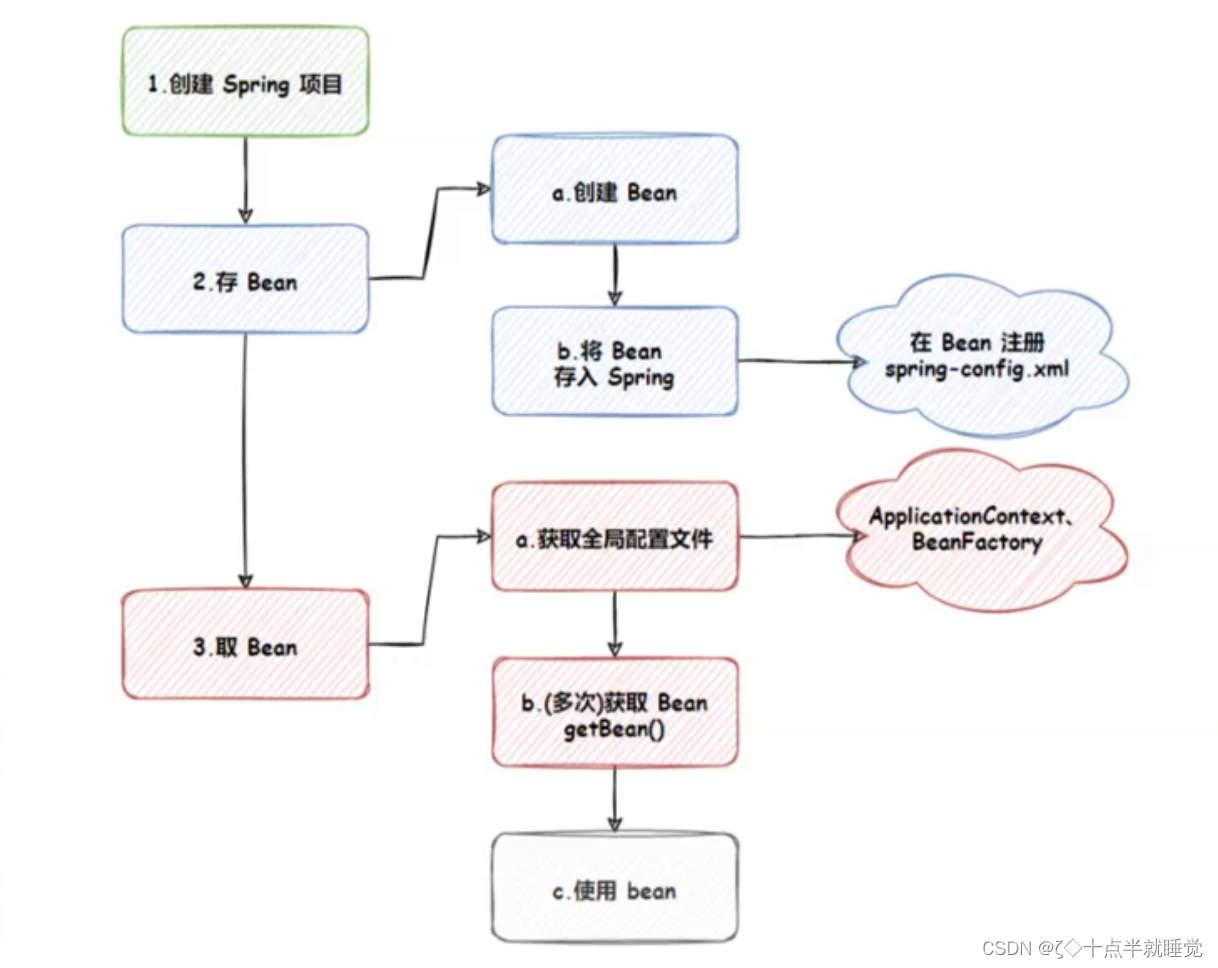
【Java】Spring的创建和使用
Spring的创建和使用 Spring就是一个包含众多工具方法的IOC容器。既然是容器,那么就具备两个最主要的功能: 将对象存储到容器中从容器中将对象取出来 在Java语言当中对象也叫作Bean。 1. 创建Spring项目 创建一个普通maven项目添加Spring框架支持(spri…...
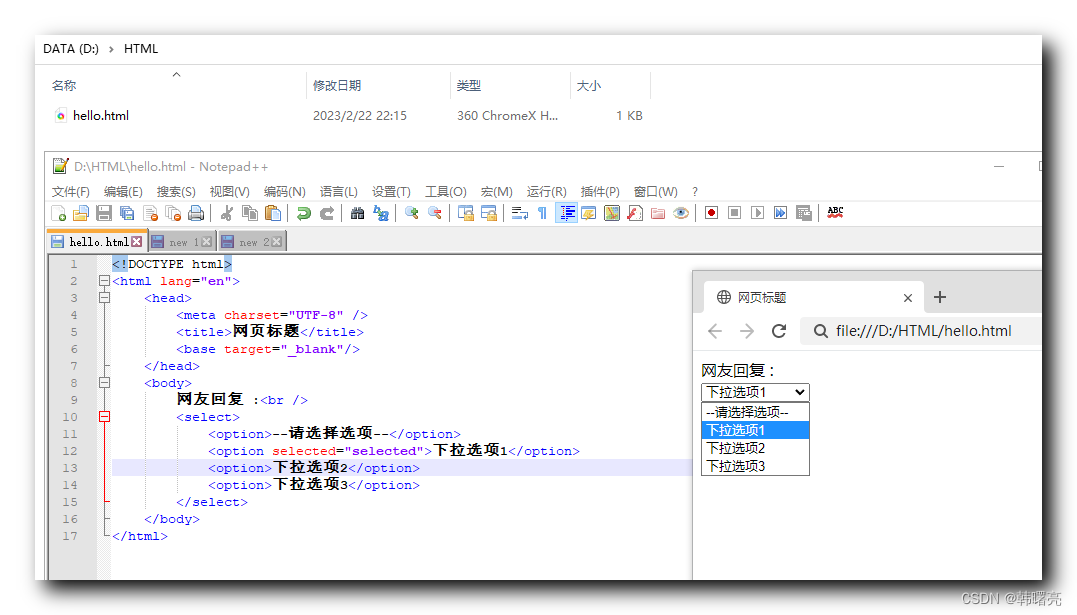
【HTML】HTML 表单 ④ ( textarea 文本域控件 | select 下拉列表控件 )
文章目录一、textarea 文本域控件二、select 下拉列表控件一、textarea 文本域控件 textarea 文本域 控件 是 多行文本输入框 , 标签语法格式如下 : <textarea cols"每行文字字符数" rows"文本行数">多行文本内容 </textarea>实际开发中 并不…...

MySQL 操作 JSON 数据类型
MySQL 从 v5.7.8 开始支持 JSON 数据类型。 JSON 数据类型和传统数据类型的操作还是有很大的差别,需要单独学习掌握。好在 JSON 数据类型的学习成本不算太高,只是在 SQL 语句中扩展了 JSON 函数,操作 JSON 数据类型主要是对函数的学习。 新…...

关于vue3生命周期的使用、了解以及用途(详细版)
生命周期目录前言组合式写法没有 beforeCreate / created 生命周期,并且组合式写生命周期用哪个先引哪个beforeCreatecreatedbeforeMount/onBeforeMountmounted/onMountedbeforeUpdate/onBeforeUpdateupdated/onUpdatedbeforeUnmount/onBeforeUnmountunmounted/onUn…...

2月,真的不要跳槽。
新年已经过去,马上就到金三银四跳槽季了,一些不满现状,被外界的“高薪”“好福利”吸引的人,一般就在这时候毅然决然地跳槽了。 在此展示一套学习笔记 / 面试手册,年后跳槽的朋友可以好好刷一刷,还是挺有必…...

Vulnhub靶场----4、DC-4
文章目录一、环境搭建二、渗透流程三、思路总结一、环境搭建 DC-4下载地址:https://download.vulnhub.com/dc/DC-4.zip kali:192.168.144.148 DC-4:192.168.144.152 二、渗透流程 端口扫描:nmap -T5 -p- -sV -sT -A 192.168.144.1…...
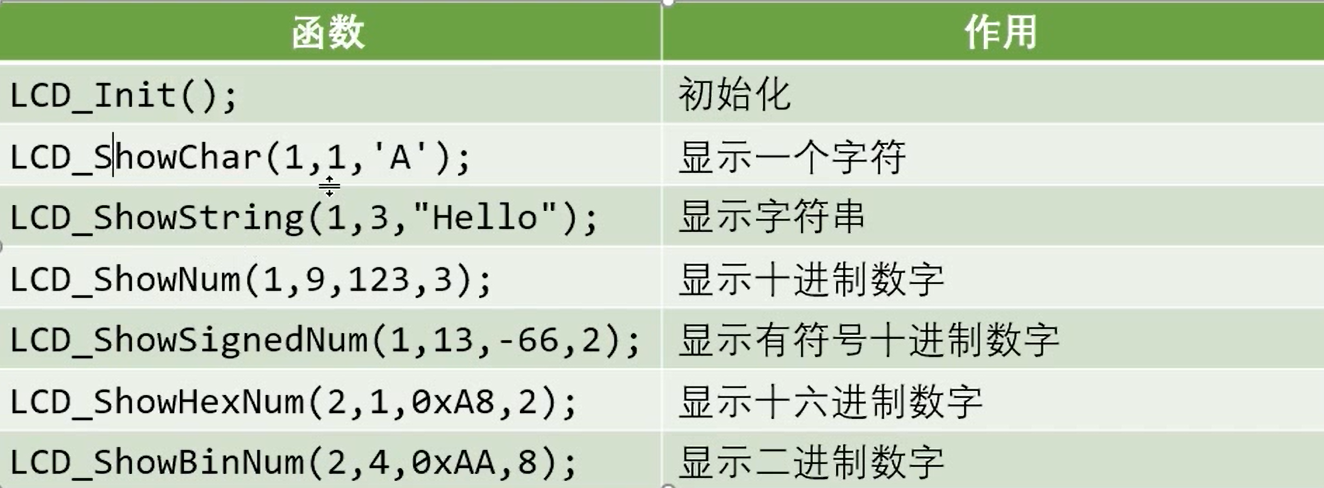
51单片机学习笔记_12 LCD1602 原理及其模块化代码
LCD1602 liquid crystal display 液晶显示屏,一种字符型液晶显示模块,可以显示 16*2 个字符,每个字符是 5*7 点阵。 P0 P2 会和数码管、LED 一定程度上冲突。 地。 Vcc。 调对比度的。 RS:数据指令端。1代表 DB 是数据&#x…...
科技 “新贵”ChatGPT 缘何 “昙花一现” ,仅低代码风靡至今
恍惚之间,ChatGPT红遍全网,元宇宙沉入深海…… 在科技圈,见证了太多“昙花一现”,“新贵” ChatGPT 的爆火几乎复制了元宇宙的路径,它会步元宇宙的后尘,成为下一个沉入深海的工具吗? 不可否认的…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...