【办公自动化】用Python批量从上市公司年报中获取主要业务信息

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python处理PDF
二、用Python将PDF文件转存为图片
三、往期推荐
四、文末推荐与福利
一、Python处理PDF
-
Python处理PDF的好处
-
自动化和批量处理:使用Python,你可以自动处理大量的PDF文件,例如从扫描仪生成的文档、报告、合同等。这可以节省大量时间和努力,尤其是在需要重复性任务时。
-
文本提取:Python可以轻松地从PDF中提取文本内容,使其可搜索、可编辑和可分析。这对于文本分析、数据挖掘和文档检索等任务非常有用。
-
报告生成:你可以使用Python创建自定义的PDF报告,将数据、图表和图像等信息以专业的方式呈现。这对于生成自动化的业务报告、数据可视化和数据分析很有帮助。
-
PDF编辑:Python库和工具使你能够合并、拆分、旋转、裁剪和编辑PDF文件的页面。这对于在不使用专业PDF编辑软件的情况下进行简单的文档编辑很有用。
-
图像提取:Python允许你从PDF文件中提取图像,这对于处理包含图形、图表和图片的文档非常有帮助。
-
数据提取:当PDF文件包含表格或结构化数据时,Python可以用于提取和转换这些数据,以便进一步分析或导入到数据库中。
-
自定义处理:Python提供了多种用于PDF处理的库,允许你根据项目的需求进行自定义处理。你可以选择适合你需求的库,以满足具体要求。
-
跨平台:Python是跨平台的,因此你可以在不同操作系统上运行相同的代码,而无需担心兼容性问题。
Python处理PDF文件的主要第三方库包括:
-
PyPDF2:PyPDF2是一个用于处理PDF文件的库,可以用于提取文本、合并、拆分和旋转PDF文件的页面。它还支持添加页面、水印和书签等功能。
-
ReportLab:ReportLab是一个用于创建PDF文件的库,允许你以编程方式构建PDF文档,包括添加文本、图像、表格等。
-
PDFMiner:PDFMiner是一个用于提取文本和元数据的PDF处理库。它可以解析PDF文件并提取文本、布局信息和链接等。
-
pdf2image:pdf2image是一个用于将PDF文件转换为图像的库,这对于处理包含图形的PDF文件非常有用。
-
fpdf2:fpdf2是一个用于创建PDF文件的库,支持自定义字体、图像和表格等。
-
PyMuPDF:PyMuPDF是一个用于处理PDF文件的库,可以用于提取文本、图像和元数据。它还支持PDF文件的渲染和转换为图像。
-
Camelot:Camelot是一个用于提取表格数据的库,特别适用于从PDF文件中提取表格数据。
-
Tabula-py:Tabula-py是一个用于提取表格数据的库,可将PDF中的表格转换为DataFrame对象。
-
开发环境
操作系统:使用windows, mac都可以
Python版本:系统中需要安装Python3.6以上的版本,Python2已经过期不建议使用,Python3.6以前的版本功能相对弱,最好就是采用Python3.6以上的版本
开发工具:有两个可以选择,jupyter notebook,是个网页编辑器,可以运行Python,常常用于交互性、探索性的开发;pycharm,用于成熟脚本,或者web服务的一些开发;这两个工具可以随意选择。
二、用Python将PDF文件转存为图片
技术工具:
Python版本:3.9
代码编辑器:jupyter notebook
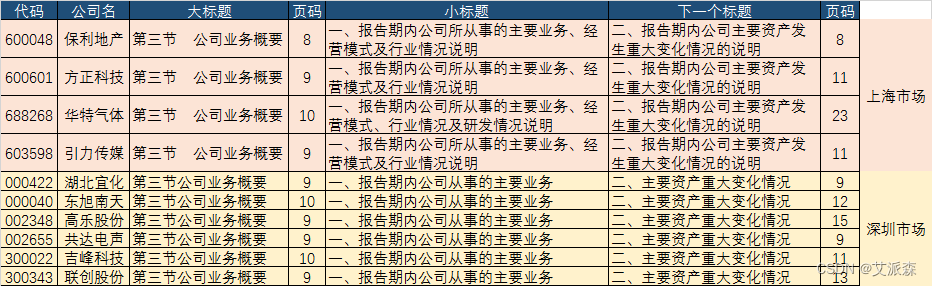
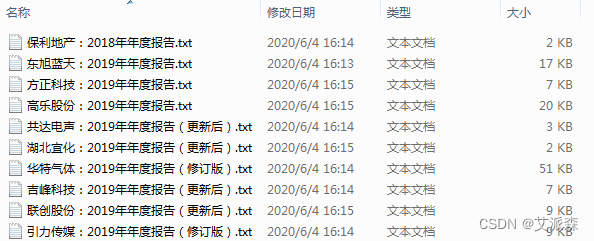
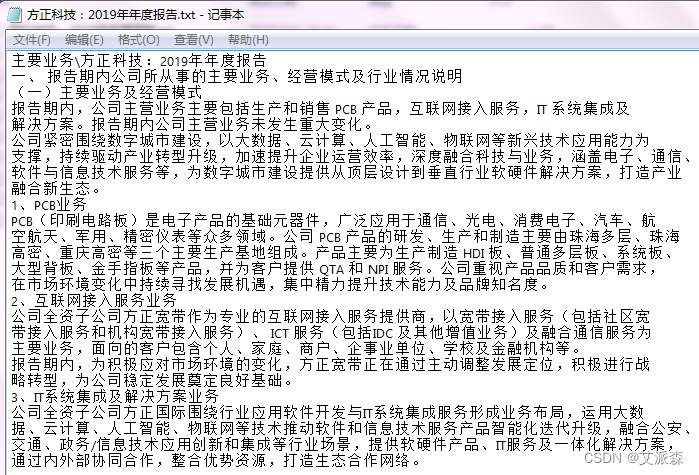
要求批量从上市公司年报中截取公司从事的主要业务信息,以便进行后续的分析。首先我们要分析一下上市公司年报的结构,及目标信息所在位置。一般上市公司的年报都是公开的,可随意下载。其格式一般是PDF。年报内容包含的板块几乎相同,只是深圳市场与上海市场略有区别。随机挑选了10家上市公司的年报(如下图)。可见,公司业务都位于“第三节公司业务概要”,只是上海市场的年报,“第三节”后有空格。其所在页基本在8,9,10页。“第三节”里的第一个小标题,两个市场也有点不同。主要业务介绍完后,接下来都是介绍“主要资产重大变化情况”,这部分及以后的内容都不是我们想要的。因此,打算确定关键词“公司业务概要”及“重大变化情况”,作为文字截取的起始关键词。当然,如果年报中还有其它内容也涉及到这两个词,就会造成干扰。保险起见,在PDF文档内搜索一下,运气不错,这两个关键词在文档中是唯一的,也就是只在这两个地方出现。那就可以放心干了。
以下,先随便找一家上市公司的年报来测试一下。先导入`pdfplumber`模块,用于提取Pdf文件中的文字(也可以用PyPDF2模块,但读取中文容易出错,因此放弃)。然后设定关键词“重大变化情况”,作为停止搜索标志(这个词后面的内容不是我们想要的)。再打开PDF文件,从第7页开始提取文字,26页终止(因为绝大部分年报的“主要业务”内容在8~15页,有个别到23页了)。将每页的文字信息存入`data`字典。再用`if`语句设定一个终止程序,即当关键词“重大变化情况”出现在当页的内容中时,就停止后续的读取了,因为后续读取到的内容已经不是我们想要的了。这样可以节省时间。打个比方,如果我们要的内容在8~9页,程序只会提取7~9页的内容,后面就不会再提取了。
#获取年报中的“主要业务”信息
import pdfplumber
file = r"年报\东旭蓝天:2019年年度报告.PDF"
data = []
key_words = "重大变化情况"
with pdfplumber.open(file) as p:for i in range(6,26): #公司主要业务主要年报的在8~23页范围内page = p.pages[i] #选页page_text = page.extract_text() #提取文字data.append(page_text) #将提取的文字加入列表if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间break # 终止for循环得到的结果如下:
data
然后,我们就用开始关键词“公司业务概要”和结束关键词“重大变化情况”来截取二者之间的文字。先定义一个文字截取函数,传入起始关键词,及待处理的字符串。通过`find()`方法确定起始关键词对应的位置索引,然后截取二者之间的字符。
#从字符串中提取指定首尾的文字
def Get_text(start_str, end_str, source_str):start = source_str.find(start_str) #找到开始关键词对应的位置索引if start >= 0:start += len(start_str)end = source_str.find(end_str, start)#找到结束关键词对应的位置索引if end >= 0:return source_str[start:end].strip() #截取起始位置之间的字符#将数据列表`data`转换成一个大字符串
source_str = "".join(data)
#截取文字
start_str = "公司业务概要"
end_str = "重大变化情况"
text_wanted = Get_text(start_str, end_str, source_str)
text_wanted
以上,就把想要的内容基本提取出来了。但最后那个几个字“二、主要资产”不是我们要的,因此需要将其去除。先将以上字符串`text_wanted`按照换行符“\n”进行分割,在砍掉最后一个元素,即可得到最终想要的字符串。
final_text = text_wanted.split("\n")[:-1]
final_text
将以上字符串写入txt文件,并按公司名称命名保存。写入的txt文件结果如下:
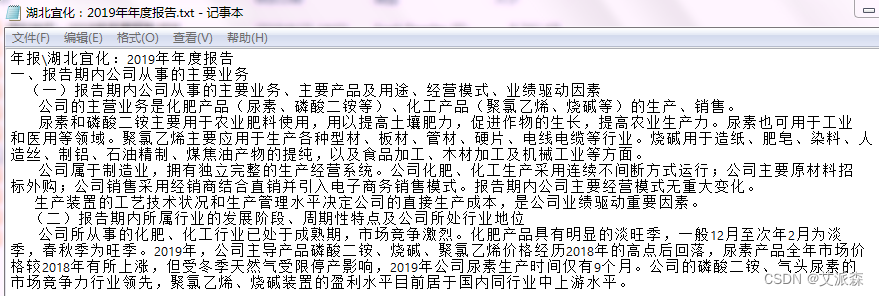
#定义写入txt的函数
def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表.file = open(filename + '.txt','w',encoding="utf-8")file.write(filename + "\n")for i in range(len(final_text)):text = final_text[i]if i != len(final_text)-1: #判断是否最后一个元素text = text+'\n' #若不是最后一个元素才换行file.write(text)file.close()To_txt(r"年报\东旭蓝天:2019年年度报告",final_text)成功搞定一个之后,我们就可以批量处理了。将待处理的年报放入指定路径,然后获取其路径,存入列表`files`。稍微整合一下程序,运行。10份年报,用时144秒,平均1份年报14秒。
#获取待处理的年报的路径
import os
path='年报' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
files 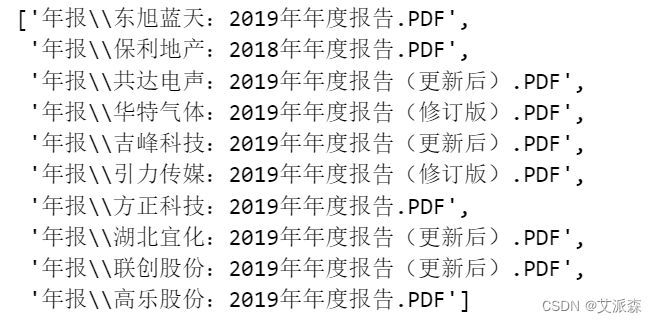
import pdfplumber
import time
time0= time.time()
#从字符串中提取指定首尾的文字
def Get_text(start_str, end_str, source_str):start = source_str.find(start_str) #找到开始关键词对应的位置索引if start >= 0:start += len(start_str)end = source_str.find(end_str, start)#找到结束关键词对应的位置索引if end >= 0:return source_str[start:end].strip() #截取起始位置之间的字符#定义写入txt的函数
def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表.file = open(filename + '.txt','w',encoding="utf-8")file.write(filename + "\n")for i in range(len(final_text)):text = final_text[i]if i != len(final_text)-1: #判断是否最后一个元素text = text+'\n' #若不是最后一个元素才换行file.write(text)time.sleep(0.1) #加入一个延时,避免批量写入出现乱码file.close()#获取年报中的“主要业务”信息
for file in files:data = []key_words = "重大变化情况"with pdfplumber.open(file) as p:for i in range(6,26): #公司主要业务主要年报的在8~23页范围内page = p.pages[i] #选页page_text = page.extract_text() #提取文字data.append(page_text) #将提取的文字加入列表if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间break # 终止for循环 #将数据列表`data`转换成一个大字符串source_str = "".join(data)#截取文字start_str = "公司业务概要"end_str = "重大变化情况"text_wanted = Get_text(start_str, end_str, source_str)#去掉不需要的尾巴final_text = text_wanted.split("\n")[:-1]new_file = "主要业务\\" + file.split("\\")[1][:-4]To_txt(new_file,final_text)print("{} 处理完成!".format(new_file))time1= time.time()
print("处理完成,共用时 {} 秒。".format(time1-time0))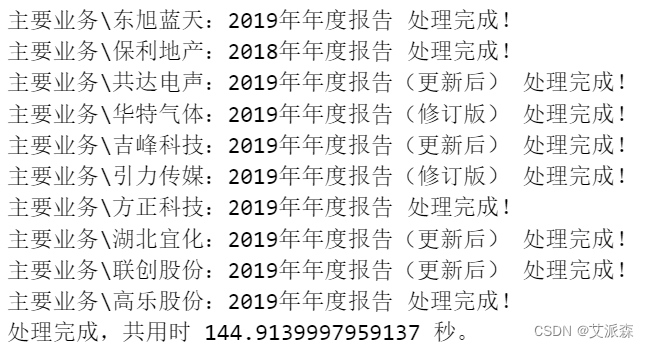
三、往期推荐
Python提取pdf中的表格数据(附实战案例)
使用Python自动发送邮件
Python操作ppt和pdf基础
Python操作word基础
Python操作excel基础
使用Python一键提取PDF中的表格到Excel
使用Python批量生成PPT版荣誉证书
使用Python批量处理Excel文件并转为csv文件
四、文末推荐与福利

清华社【秋日阅读企划】领券立享优惠
IT好书 5折叠加10元无门槛优惠券:https://u.jd.com/Yqsd9wj
活动时间:9月4日-9月17日,先到先得,快快来抢!








相关文章:
【办公自动化】用Python批量从上市公司年报中获取主要业务信息
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
的使用方式】简洁明了初识C语言)
【sizeof()的使用方式】简洁明了初识C语言
sizeof()介绍 sizeof其实仅仅只是一个操作符,我们要注意它并不是一个函数,他就类似与常见的、、-......的操作符,并且sizeof是一个单目操作符。sizeof实际上是获取了数据在内存中所占用的存储空间,以字节为…...

10. 正则表达式匹配
10. 正则表达式匹配 class IsMatch:"""10. 正则表达式匹配https://leetcode.cn/problems/regular-expression-matching/description/"""def solution(self, s: str, p: str) -> bool:m, n len(s), len(p)memo [[-1] * n for _ in range(m)]…...

[Unity]GPU Instancing 无效的原因
参考: GPU Instancing 深入浅出-基础篇(1) - 知乎 Unity GPU Instance踩坑记录_为什么gpuinstance画不出图像_拯救人类的技术宅的博客-CSDN博客 GPUInstancing在真机上失效问题_安卓手机 unity gpu instancing报错__hiJ的博客-CSDN博客 补…...

2023 年前端编程 NodeJs 包管理工具 npm 安装和使用详细介绍
npm 基本概述 npm is the world’s largest software registry. Open source developers from every continent use npm to share and borrow packages, and many organizations use npm to manage private development as well. npm 官方网站:https://www.npmjs.…...
)
ptmalloc源码分析 - Top chunk的扩容函数sysmalloc实现(09)
目录 一、sysmalloc函数基本分配逻辑 二、强制try_mmap分配方式 三、非主分配区分配的实现 1. 设置老的Top chunk的参数 2. 尝试使用grow_heap函数 3. 尝试使用new_heap函数 4. 尝试使用try_mmap方式 四、主分配区分配的实现 1. 设置Top扩容的size值 2. brk分配成功的…...

[BJDCTF2020]ZJCTF,不过如此 preg_replace /e模式漏洞
目录 preg_replace的/e模式 为什么要变为 {${phpinfo()}} 另一个方法 版本 <?phperror_reporting(0); $text $_GET["text"]; $file $_GET["file"]; if(isset($text)&&(file_get_contents($text,r)"I have a dream")){echo &qu…...
C++day4
1、仿照string类,完成myString 类 #include <iostream> #include <cstring>using namespace std; class myString {private:char *str; //记录c风格的字符串int size; //记录字符串的实际长度public://无参构造myString():size(10…...

【LeetCode-简单题】541. 反转字符串 II
文章目录 题目方法一:双指针 题目 方法一:双指针 题目的意思: 通俗一点说,每隔k个反转k个,末尾不够k个时全部反转; 需要注意右边界的取值 int r Math.min(l k -1,n-1);//取右边界与n-1的最小值 确定边界…...
Linux服务使用宝塔面板搭建网站,并发布公网访问
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 前言 宝塔面板作为简单好用的服务器运维管理面板,它支持Linux/Windows系统,我们可用它来一键配置LAMP/LNMP环境、网站、数据库、FTP等&…...

代码随想录算法训练营19期第48天
198.打家劫舍 视频讲解:动态规划,偷不偷这个房间呢?| LeetCode:198.打家劫舍_哔哩哔哩_bilibili 代码随想录 初步思路:动态规划。 总结: dp[i]:考虑下标i(包括i)…...

【校招VIP】产品项目分析之竞品分析
考点介绍: 在产品经理的日常工作当中,经常需要针对某个具体问题或特定功能点进行竞品调研;竞品分析是结构化分析方法论,核心思想是通过对比的方法寻找最佳的解决方案。 产品项目分析之竞品分析-相关题目及解析内容可点击文章末尾…...

【JavaScript内置对象】Date对象,从零开始
【JavaScript内置对象】Date对象,从零开始 时间的表示方式 时间表示的基本概念 最初,人们是通过观察太阳的位置来决定时间的,但是这种方式有一个最大的弊端就是不同区域位置大家使用的时间是不一致的。 相互之间没有办法通过一个统一的时间…...
idea启动缓慢解决办法
idea启动缓慢解决办法 文章目录 idea启动缓慢解决办法前言一、修改内存大小二、虚拟机运行大小三、插件禁用1、安卓相关2、构建工具3、Code Coverage 代码覆盖率4、数据库5、部署工具6、html和xml7、ide settings8、JavaScript框架和工具9、jvm框架10、Keymap快捷键映射11、kot…...

App测试中ios和Android有哪些区别呢?
App测试中,大家最常问到的问题就是:ios和 Android有什么区别呢? 在Android端,我们经常会使用 JavaScript、 HTML、 CSS等技术来编写一些简单的 UI界面。而 iOS端,我们经常会使用到 UI设计、界面布局、代码结构、 API等…...

Flink JobManager的高可用配置
背景 在flink执行中,jobManager是一个负责执行流式应用执行和检查点生成的组件,一旦发生故障,那么其负责的所有应用都会被取消,所以我们需要对JobManager配置高可用的模式 JobManager高可用配置 配置JobManager的高可用需要使用…...

为什么Token手动添加到请求的Header中,通常使用“Authorization“字段?
为什么Token手动添加到请求的Header中,通常使用"Authorization"字段? 通常将Token放置在"Authorization"字段中的主要原因如下: 标准化:HTTP协议中定义了一些常见的头部字段,如"Authorizati…...

国际生态数据获取网络
1、https://lternet.edu/ 2、https://www.neonscience.org/ 3、https://www.tern.org.au/ 4、https://www.industry.gov.au/ 5、http://www.cbas.ac.cn/ 6、https://sdg.casearth.cn/datas/casearthData 7、https://data.casearth.cn/ 8、https://omai.casearth.cn/ai-l…...
爬虫逆向实战(34)-某视综数据(MD5、AES)
一、数据接口分析 主页地址:某视综 1、抓包 通过抓包可以发现数据接口是/rank/waiting/fans 2、判断是否有加密参数 请求参数是否加密? 通过查看“载荷”模块可以发现有一个sign参数 请求头是否加密? 无响应是否加密? 通过查…...
数据分析三剑客之Matplotlib
0.Matplotlib绘图和可视化 1.简介 我的前面两篇文章介绍了 Nimpy ,Pandas 。今天来介绍一下Matplotlib。 简单来说,Matplotlib 是 Python 的一个绘图库。它包含了大量的工具,你可以使用这些工具创建各种图形,包括简单的散点图&…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...