机器学习——贝叶斯(三种分布)/鸢尾花分类分界图/文本分类应用
0、前言:
- 机器学习中的贝叶斯的理论基础是数学当中的贝叶斯公式。
- 这篇博客强调使用方法,至于理论未作深究。
- 机器学习中三种类型的贝叶斯公式:高斯分布(多分类)、多项式分布(文本分类)、伯努利分布(二分类任务)
- 贝叶斯算法优点:对小规模数据表现好,能处理多分类任务,常用于文本分类。缺点:只能用于分类问题。
1、高斯分布的贝叶斯算法:
- 应用:鸢尾花分类任务分界图
# 导入基础库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris# 导入贝叶斯(高斯分布、多项式分布、伯努利分布)
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
data,target = load_iris(return_X_y=True)
display(data.shape, target.shape)data2 = data[:,2:].copy()
# 训练模型
GS_nb = GaussianNB()
GS_nb.fit(data2,target)# 画分界图
# 先生成x坐标和y坐标
X = np.linspace(data2[:,0].min(),data2[:,0].max(),1000)
Y = np.linspace(data2[:,1].min(),data2[:,1].max(),1000)# 然后将x坐标和y坐标对应的网格坐标对应出来
nx,ny = np.meshgrid(X,Y)# 扁平化
nx = nx.ravel()
ny = ny.ravel()# 组合堆积成新的数据集
disdata = np.c_[nx,ny]
pd.DataFrame(disdata).head(3)# 预测
disdata_pred = GS_nb.predict(disdata)# 绘制分界图(这种速度比较慢)
plt.scatter(disdata[:,0],disdata[:,1],c=disdata_pred)
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')# 绘制分界图(这种速度快)
plt.pcolormesh(X,Y,disdata_pred.reshape(1000,-1)) # 将'disdata_pred'的值以伪彩色图(plt.pcolormesh)的形式在二维网格上显示出来。
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow') # cmap='rainbow'是matplotlib库中plt.scatter函数的一个参数。这个参数用于指定色彩映射(colormap)。在这种情况下,'rainbow'是一种色彩映射,它会从红色开始,逐渐过渡到橙色、黄色、绿色、青色、蓝色和紫色。

- 在这个应用中,用多项式分布的贝叶斯分类效果没有高斯分布好,而伯努利分布的贝叶斯只能用于二分类任务。
2、三种贝叶斯算法的文本分类应用效果:
- 代码:
# 老三件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入三种贝叶斯算法
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
# 导入数据(5571条数据,有两列,其中第一列为标签,第二列为短信内容)
data = pd.read_table('./data2/SMSSpamCollection',header=None)
pd.DataFrame(data).head(2)
# 从数据中分词,并且统计每个短信中分词的出现频率,最终呈现一个稀疏矩阵作为贝叶斯算法的输入
a_data = data[1].copy()
target = data[0].copy()
a_data.shape # 一维
from sklearn.feature_extraction.text import TfidfVectorizer # 特征提取库中的Tfid~是用于文本数据的特征提取
'''
1、TfidfVectorizer将文本数据转换为特征向量形式,每个词表示一个特征维度,每个维度的值是这个词在文本中的权重(出现的次数)
2、这个库是文本数据用于机器学习模型的关键步骤
3、导入后使用方法和机器学习算法非常类似,要先创建对象,然后fit()
'''
# 创建特征词向量的对象
tf = TfidfVectorizer()
tf.fit(a_data) # 输入一维的源文本数据即可,这一步会统计分词信息
X = tf.transform(a_data).toarray() # 这一步会根据上面统计的分词信息构建稀疏矩阵# tf.transform(a_data):
# <5572x8713 sparse(稀疏) matrix of type '<class 'numpy.float64'>'
# with 74169 stored elements in Compressed Sparse Row format>
# .toarray(),就是将结果转换为array数组
# 高斯分布贝叶斯
GS = GaussianNB()
GS.fit(X,target)
GS.score(X,target) # 0.9414931801866475
# 多项式分布贝叶斯
MT = MultinomialNB()
MT.fit(X,target)
MT.score(X,target) # 0.9761306532663316
# 伯努利分布贝叶斯
BE = BernoulliNB()
BE.fit(X,target)
BE.score(X,target) # 0.9881550610193827
# 预测数据处理,要按照之前特征词向量对象模型转换(不能重新设置特征词向量对象后fit,会导致测试数据维度和训练模型的输入数据维度不匹配)
m = ['hello, nice to meet you','Free lunch, please call 09999912313','Free lunch, please call 080900031 9am - 11pm as a $1000 or $5000 price'
]
m = tf.transform(m).toarray()
# 测试预测
GS.predict(m) # array(['ham', 'ham', 'ham'], dtype='<U4')
MT.predict(m) # array(['ham', 'ham', 'spam'], dtype='<U4')
BE.predict(m) # array(['ham', 'ham', 'spam'], dtype='<U4')- 总结:
1、在进行文本分类时调用贝叶斯算法的方式还是中规中矩,其中一个难点是读数据时要先知道数据的格式,然后才能通过pandas来读取
2、非常重要的一个工具就是sklearn库提供的分词工具from sklearn.feature_extraction.text import TfidfVectorizer,它可以把一个一维的文本数据(每个元素是一个句子文本的列表或者其他一维数据)通过fit方法将其特征词提取出来,进行分词,之后通过transform方法再次输入数据就可以把数据变成稀疏矩阵,然后再次通过toarray方法将数据变成真真的numpy二维数组。
3、从文本分类结果看,多项式分布更适合做文本分类,但是对于二分类文本分类任务伯努利效果更佳。
相关文章:
机器学习——贝叶斯(三种分布)/鸢尾花分类分界图/文本分类应用
0、前言: 机器学习中的贝叶斯的理论基础是数学当中的贝叶斯公式。这篇博客强调使用方法,至于理论未作深究。机器学习中三种类型的贝叶斯公式:高斯分布(多分类)、多项式分布(文本分类)、伯努利分…...
SOLIDWORKS Composer位置关键帧的使用
SOLIDWORKS Composer是专业的SOLIDWORKS及3D文件处理的动画制作软件,作为SOLIDWORKS 产品线下的一个明星存在。 SOLIDWORKS Composer几乎可以处理任何SOLIDWORKS的模型文件并将之转化成可以动作的机械动画,可以引用在企业的网站、产品说明书以及工作指导…...

PostgreSQL 流复制搭建与维护
文章目录 前言1. 配置环境1.1 环境介绍1.2 主库白名单1.3 主库参数配置 2. 流复制搭建2.1 备份恢复2.2 创建复制用户2.3 参数修改2.4 启动并检查2.5 同步流复制2.6 同步复制级别 3. 流复制监控3.1 角色判断3.2 主库查看流复制3.3 延迟监控3.4 备库查询复制信息 前言 PostgreSQ…...

【Redis】关于过期数据清除的一些策略
这里要讨论的为过期的数据是如何被清除的,也就是网上常常讨论的过期清除策略。 需要注意的是,redis除了会对过期的数据进行淘汰,也可以通过对内存大小进行限制,并对超出内存限制后进行数据淘汰。此时淘汰的数据未必是过期的&…...

动态SQL
Mybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问题。 1、if if标签可通过test属性的表达式进行判断,若表达式的结果为true,则标签中的内容会执行;反之标签…...

uniapp:OCR识别身份证上传原图失败,问题解决
1、上传普通图片成功 2、上传>4M | >5M图片失败检查:1、uni.uploadFile自身没有文件大小限制。然而,这仍然取决于你的应用程序所在的平台和存储空间容量。 2、上传照片后不在fail,在sucess 提交照片-3 {"data": "<h…...

shell循环和函数
目录 1.for循环2.while循环3.until循环4.函数 1.for循环 for循环是固定循环,也就是在循环时就已经知道需要进行几次的循环,有事也把for循环成为计数循环。for的语法如下两种: 语法一 for 变量 in 值1 值2 值3 …(可以是一个文件等)do程序do…...

京东详情api
简要描述 根据商品id获取详情数据 请求URL http://xxx.xxx.xxx.xxx:xxxx/jd.get.item 请求方式 get 请求Query参数 参数名示例值必选类型说明itemid100016034386是string商品idtokenadmin.api是string权限token 成功返回示例 部分数据展示: {"data&qu…...

MySQL最新版8.1.0安装配置教程
目录 目录 前言 安装流程图 1,MySQL数据库是什么? 2,下载zip压缩包 3,解压到要安装的目录 4,添加环境变量 4.1,找到环境变量 4.2,进行环境变量的添加 5.新建mysql 配置文件 6、安装mysql服务 7、初始化数据文件 8、启动mysql …...

5G试题_1
1、 全息技术属于对5G三大类应用场景网络需求中的哪一种?(A) A. 增强移动宽带 B. 海量大连接 C. 低时延高可靠 D. 低时延大带宽 2、 在5G时代,不同领域的不同设备大量接入网络,其实引用传统的组网方式和服务提供形式也…...

正规股票配资网站的三个明显特点分析
随着股票市场的快速发展,越来越多的投资者开始考虑使用股票配资来增加自己的资金流动性和收益率。然而,在选择股票配资网站时,投资者往往难以辨别哪些网站是正规的,哪些网站存在风险。因此,以下将分析正规股票配资网站…...

质疑苹果5G信号造假成为闹剧,反而将运营商置于尴尬境地
在iPhone15发布会处于热点之际,一位号称通信专家的人士指责iPhone的5G信号造假,一度闹得沸沸扬扬,导致舆论一开始都是质疑苹果造假,然而在知乎却有更多专业人士指出这位专家不了解5G技术,这个问题或许反而出在运营商身…...

vue 预览zip
ZIP的数据从接口传递数据流过来。解析数据流,并将zip的目录绑定到tree中。 1.引入插件jszip: yarn add jszip 2.在需要引用的页面引用: import JSZip from jszip 3. 实现代码 api(option).then((res)>{ // 接口获取zip的数据流 l…...

人先自辱,而后人辱之
语出《孟 子.离娄上》“夫人必自街,而后人懈之;家必自毁,而后人毁之"。 自己不把自己当人看,别人肯定也不会。善待自己,接纳自己。 过去的不再留恋。 心平气和,气定神闲。 政治论述题,每一个题目&a…...

web端三维重建算法-colmap++
vismap vismap 是colmap 版本 (1) 支持superpoint superglue (2) 支持netvlad 图像检索 (3)支持特征点尺度定权 (4)支持二维码定位 (5)支持融合gps &#x…...
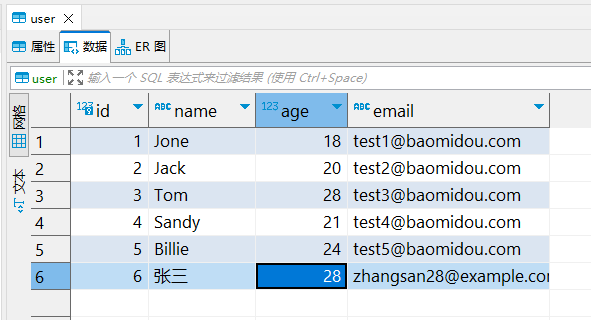
MyBatisPlus(二)基础Mapperr接口:增删改查
MyBatisPlus:基础Mapper接口:增删改查 插入一条数据 代码 Testpublic void insert() {User user new User();user.setId(6L);user.setName("张三");user.setAge(25);user.setEmail("zhangsanexample.com");userMapper.insert(use…...

基础项目实用案例
文章目录 倒计时动态生成表格发布留言密码框验证模态框拖拽 倒计时 function countDown(time) {var nowTime new Date();var inputTime new Date(time);var times (inputTime - nowTime) / 1000;var d parseInt(times / 60 / 60 / 24);d d < 10 ? 0 d : d;var h par…...

sprngboot整合kabana
Spring Boot是一个开源框架,可以基于Spring框架快速开发和构建生产级别的应用程序。Kibana是一个可视化和交互式分析平台,用于检索和分析Elasticsearch集群中存储的数据。 下面是Spring Boot整合Kibana的基本步骤: 添加Maven依赖 在pom.xm…...
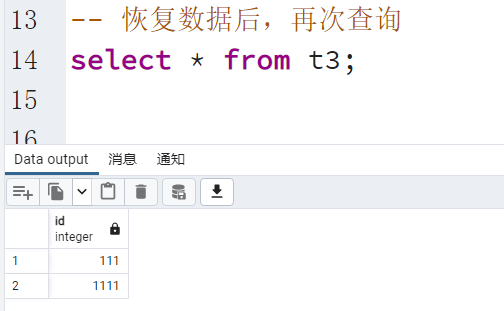
PostgreSQL 数据备份恢复
文章目录 PostgreSQL 备份方式SQL备份(逻辑备份)文件系统备份(物理备份)归档备份(物理备份) 逻辑备份&恢复物理备份&恢复(全量)备份恢复 物理备份&恢复(某个…...
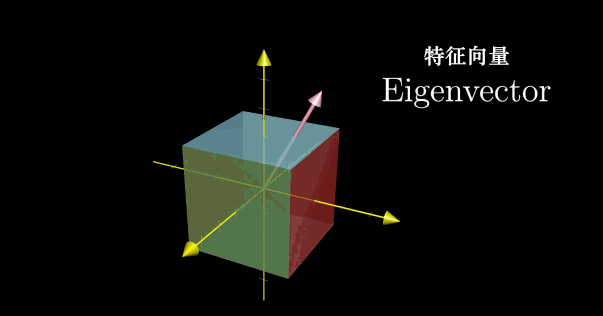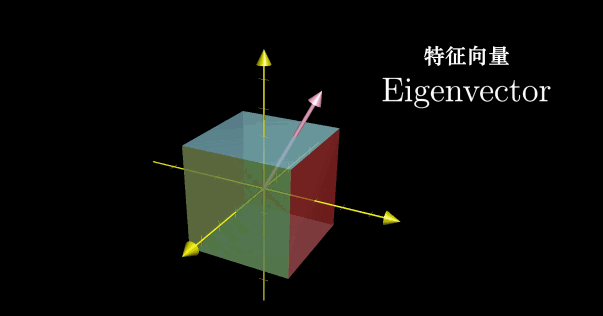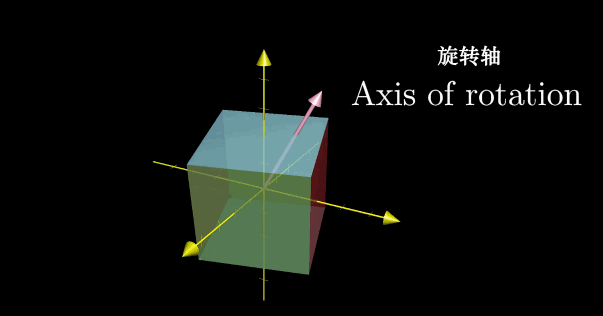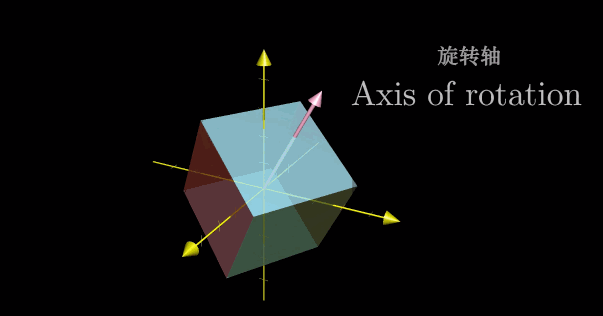
线性代数的本质(七)——特征值和特征向量
特征值和特征向量 本章特征值和特征向量的概念只在方阵的范畴内探讨。 相似矩阵 Grant:线性变换对应的矩阵依赖于所选择的基。 一般情况下,同一个线性变换在不同基下的矩阵不同。仍然以平面线性变换为例,Grant 选用标准坐标系下的基向量 i…...

QMK Toolbox:解锁机械键盘自定义潜能的终极工具
QMK Toolbox:解锁机械键盘自定义潜能的终极工具 【免费下载链接】qmk_toolbox A Toolbox companion for QMK Firmware 项目地址: https://gitcode.com/gh_mirrors/qm/qmk_toolbox 想让你心爱的机械键盘拥有超乎想象的功能吗?厌倦了千篇一律的按键…...

多维度拆透渲染引擎 第三篇【维度:内部结构】渲染引擎之内 —— 核心模块全景拆解
第三篇【维度:内部结构】渲染引擎之内 —— 核心模块全景拆解读完此篇你将理解:渲染前端/后端的分野、七大核心模块各自的职责、灰色地带的归属判断逻辑、渲染引擎与外部子系统的接口设计原则。 本篇与第四篇、第八篇的关系:本篇回答"渲…...
)
别怕!用Python的NumPy库,5分钟搞懂机器学习里的线性代数(附代码示例)
用NumPy玩转机器学习中的线性代数:5分钟实战指南 当你第一次接触机器学习时,那些复杂的数学公式可能会让你望而却步。但别担心!作为编程爱好者,我们完全可以用熟悉的Python工具来理解这些概念。本文将带你用NumPy库快速掌握机器学…...

Linux设备驱动之V4L2框架与Camera子系统
1. V4L2框架与Camera子系统概述 第一次接触Linux Camera驱动开发时,我被V4L2这个缩写搞得很困惑。后来才知道这是Video for Linux 2的简称,是Linux内核中处理视频设备的通用框架。简单来说,它就像是一个大管家,负责协调摄像头硬件…...

如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定!
如何轻松运行Flash游戏和网页?这款免费浏览器让你一键搞定! 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否曾经想重温经典的Flash游戏,却发现现…...

树莓派4B实时内核编译踩坑实录:从Ubuntu 20.04到RT-PREEMPT补丁的完整流程
树莓派4B实时内核编译实战:RT-PREEMPT补丁全流程与深度调优指南 第一次尝试给树莓派4B编译实时内核时,我盯着屏幕上那一串串报错信息足足发呆了半小时。作为一款广泛应用于工业控制、机器人开发等实时性要求较高场景的单板计算机,树莓派默认内…...

免费获取3000+材料折射率数据:光学设计者的终极资源库
免费获取3000材料折射率数据:光学设计者的终极资源库 【免费下载链接】refractiveindex.info-database Database of optical constants 项目地址: https://gitcode.com/gh_mirrors/re/refractiveindex.info-database 你是否在为寻找准确的光学材料数据而烦恼…...

Android Studio依赖下载总报SSL错?可能是你的阿里云Maven仓库配置‘捣鬼’
Android Studio依赖下载SSL报错全解析:从阿里云镜像到证书信任链的深度修复指南 每次点击"Sync Project with Gradle Files"时看到那个刺眼的红色错误提示,相信不少Android开发者都会血压升高。特别是当错误信息里出现"unable to find va…...

3步掌握百度网盘解析工具:告别限速困扰的终极指南
3步掌握百度网盘解析工具:告别限速困扰的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾因百度网盘的蜗牛下载速度而抓狂?面对宝贵的…...

当同行已经用 AI 实现精益管理,你的企业还在靠粗放式经营? [2026实战指南:基于实在Agent的企业级自动化闭环方案]
在2026年的商业语境下,企业间的竞争已不再是单纯的资源规模比拼,而是“管理颗粒度”的较量。 随着生成式AI从Demo演示步入核心生产环境,FinOps(云财务管理)的重心已全面转向AI支出管理。 根据最新行业数据显示…...