Endless lseek导致的SQL异常
最近碰到同事咨询的一个问题,在执行一个函数时,发现会一直卡在那里。
strace抓了下发现会话一直在执行lseek,大致情况如下:
16:13:55.451832 lseek(33, 0, SEEK_END) = 1368064 <0.000037> 16:13:55.477216 lseek(33, 0, SEEK_END) = 1368064 <0.000026> 16:13:55.502579 lseek(33, 0, SEEK_END) = 1368064 <0.000026> 16:13:55.528162 lseek(33, 0, SEEK_END) = 1368064 <0.000024> 16:13:55.553714 lseek(33, 0, SEEK_END) = 1368064 <0.000025> 16:13:55.579242 lseek(33, 0, SEEK_END) = 1368064 <0.000022> ......% time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 0.00 0.000000 0 124 lseek ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 124 total
而当手动去取消掉会话时也能发现,是卡在了其中一个insert语句:
[postgres@xxx/(rasesql)himsdpsods][02-22.16:13:24]M=# select pgawr_snap('cron based snapshot',59451);
^CCancel request sent
ERROR: 57014: canceling statement due to user request
CONTEXT: SQL statement "INSERT INTO pgawr_indexes
( snapid, idx_scan, idx_tup_read, idx_tup_fetch, idx_blks_read,
idx_blks_hit, index_name_id, table_name_id)
SELECT
spid as snapid,
i.idx_scan as idx_scan,
i.idx_tup_read as idx_tup_read,
i.idx_tup_fetch as idx_tup_fetch,
ii.idx_blks_read as idx_blks_read,
ii.idx_blks_hit as idx_blks_hit,
n1.nameid,
n2.nameid
FROM
pg_stat_all_indexes i
join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name
join pgawr_names n2 on i.schemaname ||'.'|| i.relname=n2.name"
PL/pgSQL function pgawr_snap(character varying,bigint) line 104 at SQL statement
LOCATION: ProcessInterrupts, postgres.c:3203
Time: 203994.651 ms (03:23.995)
当然分析这种函数执行慢的,最常用的还是auto_explain,可以在会话中设置来打印函数中具体执行的情况:
load 'auto_explain';set client_min_messages='log'; set auto_explain.log_min_duration = 0; set auto_explain.log_analyze = true; set auto_explain.log_verbose = true; set auto_explain.log_buffers = true; set auto_explain.log_nested_statements = true;
根据上面得到的信息发现文件句柄33对应的恰好也是该SQL中的一张表,而lseek(33, 0, SEEK_END) = 1368064的返回值也的确是和该数据文件的大小一致,说明的确是扫描完该表了。
那就有点奇怪了,这个SQL也很简单,而且单独拿出来执行也都没问题,为什么会一直卡在lseek这个数据文件这里呢?
上网搜了下,发现有个类似的bug:BUG #15455: Endless lseek,其中的情况和我这个有些类似:

但是往后看了malilist里面的讨论也是不了了之,最终也没有个结论。。。
哎,没有办法,只能自己接着分析了。
为了方便查看,我这里把SQL简写了,insert也换成select。
[postgres@xxx/(rasesql)himsdpsods][02-22.16:40:10]M=# EXPLAIN ANALYZE SELECT
-> i.idx_scan as idx_scan,
-> i.idx_tup_read as idx_tup_read,
-> i.idx_tup_fetch as idx_tup_fetch,
-> ii.idx_blks_read as idx_blks_read,
-> ii.idx_blks_hit as idx_blks_hit,
-> n1.nameid
-> FROM
-> pg_stat_all_indexes i
-> join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
-> join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name;QUERY PLAN
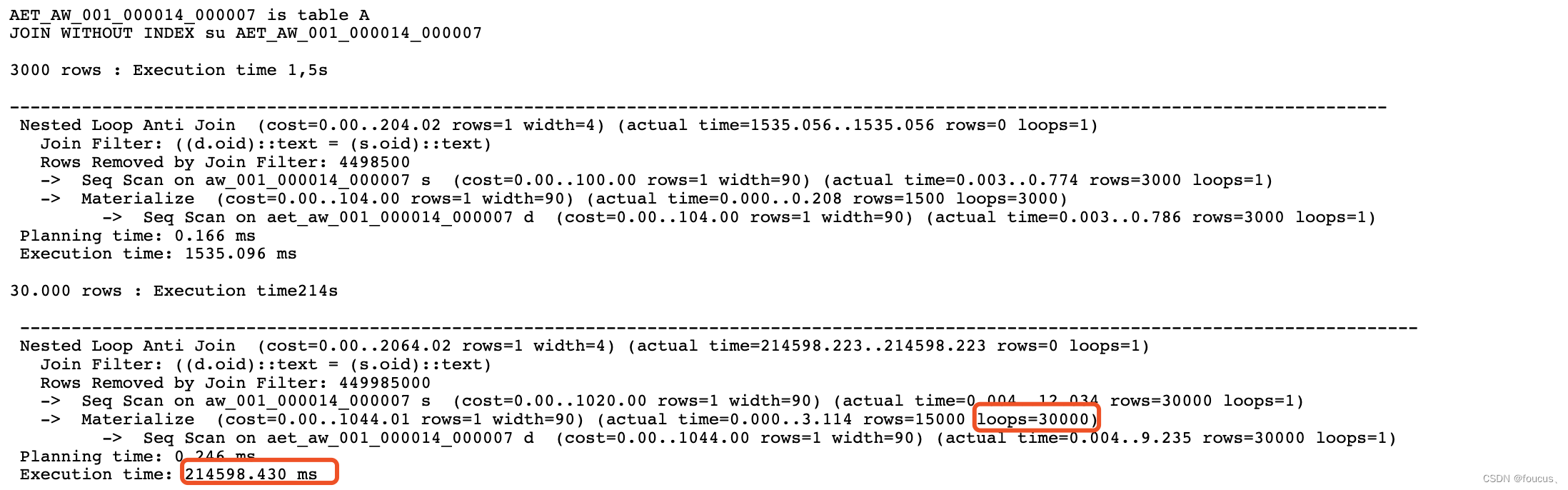
----------------------------------------------------------------------------------------------------------------------------------Nested Loop (cost=1805.21..3055.18 rows=3 width=44) (actual time=0.381..0.384 rows=0 loops=1)Join Filter: ((((n.nspname)::text || '.'::text) || (i.relname)::text) = (n1.name)::text)-> Seq Scan on pgawr_names n1 (cost=0.00..228.00 rows=1 width=44) (actual time=0.380..0.381 rows=0 loops=1)-> Nested Loop (cost=1805.21..2815.83 rows=502 width=136) (never executed)-> Hash Join (cost=1804.92..2585.91 rows=502 width=140) (never executed)Hash Cond: (c.relnamespace = n.oid)-> Nested Loop (cost=1801.01..2580.62 rows=502 width=80) (never executed)-> Hash Join (cost=1800.73..2057.32 rows=900 width=12) (never executed)Hash Cond: (x.indexrelid = x_1.indexrelid)-> Hash Join (cost=766.65..1005.74 rows=2267 width=8) (never executed)Hash Cond: (x.indrelid = c.oid)-> Seq Scan on pg_index x (cost=0.00..224.09 rows=5709 width=8) (never executed)-> Hash (cost=715.81..715.81 rows=4067 width=8) (never executed)-> Seq Scan on pg_class c (cost=0.00..715.81 rows=4067 width=8) (never executed)Filter: (relkind = ANY ('{r,t,m}'::"char"[]))-> Hash (cost=1005.74..1005.74 rows=2267 width=4) (never executed)-> Hash Join (cost=766.65..1005.74 rows=2267 width=4) (never executed)Hash Cond: (x_1.indrelid = c_1.oid)-> Seq Scan on pg_index x_1 (cost=0.00..224.09 rows=5709 width=8) (never executed)-> Hash (cost=715.81..715.81 rows=4067 width=8) (never executed)-> Seq Scan on pg_class c_1 (cost=0.00..715.81 rows=4067 width=8) (never executed)Filter: (relkind = ANY ('{r,t,m}'::"char"[]))-> Index Scan using pg_class_oid_index on pg_class i (cost=0.29..0.58 rows=1 width=68) (never executed)Index Cond: (oid = x.indexrelid)-> Hash (cost=2.85..2.85 rows=85 width=68) (never executed)-> Seq Scan on pg_namespace n (cost=0.00..2.85 rows=85 width=68) (never executed)-> Index Only Scan using pg_class_oid_index on pg_class i_1 (cost=0.29..0.46 rows=1 width=4) (never executed)Index Cond: (oid = i.oid)Heap Fetches: 0
可以看到卡住的SQL拿出来单独执行是没有问题的,但是仔细观察可以发现,该执行计划中很多never executed的节点,说明下面的这些部分实际都没有执行,那是因为pgawr_names这张表是空的,因此对于这个嵌套循环来说,被驱动的部分其实就没有必要执行了。
而查看完该函数的内容之后发现,在执行这个SQL之前是有往pgawr_names这张表里面插入数据的。
这样一下子就有思路了:因为在同一个会话中,前一条SQL往pgawr_names表里面插入了大量数据,而表的统计信息在会话提交前是不会更新的。
[postgres@xxx/(rasesql)himsdpsods][02-22.16:54:40]M=# begin; BEGIN Time: 0.128 ms[postgres@xxx/(rasesql)himsdpsods][02-22.16:55:11]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names'; n_live_tup | last_analyze ------------+------------------------------- 0 | 2023-02-22 15:09:43.348236+08 (1 row)Time: 11.319 ms [postgres@xxx/(rasesql)himsdpsods][02-22.16:55:27]M=# insert into pgawr_names (name) -> select distinct i.schemaname ||'.'|| i.indexrelname -> from pg_stat_all_indexes i -> left join pgawr_names on i.schemaname ||'.'|| i.indexrelname=name -> where -> name is null; INSERT 0 5709 Time: 207.526 ms[postgres@xxx/(rasesql)himsdpsods][02-22.16:55:41]M=# ANALYZE pgawr_names ; ANALYZE Time: 73.666 ms[postgres@xxx/(rasesql)himsdpsods][02-22.16:55:46]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names'; n_live_tup | last_analyze ------------+------------------------------- 0 | 2023-02-22 15:09:43.348236+08 (1 row)Time: 0.876 ms
既然如此,看来前面看到的会话一直卡在lseek其实是执行计划后面的嵌套循环太多导致的,我们可以把pgawr_names表中手动插入较少的数据来验证下:
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:00]M=# begin;
BEGIN
Time: 0.141 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:02]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names';n_live_tup | last_analyze
------------+-------------------------------0 | 2023-02-22 17:01:53.272047+08
(1 row)Time: 11.615 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:03]M=# insert into pgawr_names(name) select md5(random()::text) from generate_series(1,200);
INSERT 0 200
Time: 52.083 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:28]M=# EXPLAIN ANALYZE SELECT
-> i.idx_scan as idx_scan,
-> i.idx_tup_read as idx_tup_read,
-> i.idx_tup_fetch as idx_tup_fetch,
-> ii.idx_blks_read as idx_blks_read,
-> ii.idx_blks_hit as idx_blks_hit,
-> n1.nameid
-> FROM
-> pg_stat_all_indexes i
-> join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
-> join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name;QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------Nested Loop (cost=1805.21..3055.18 rows=3 width=44) (actual time=5618.220..5618.229 rows=0 loops=1)Join Filter: ((((n.nspname)::text || '.'::text) || (i.relname)::text) = (n1.name)::text)Rows Removed by Join Filter: 1141800-> Seq Scan on pgawr_names n1 (cost=0.00..228.00 rows=1 width=44) (actual time=0.014..0.417 rows=200 loops=1)-> Nested Loop (cost=1805.21..2815.83 rows=502 width=136) (actual time=0.071..26.143 rows=5709 loops=200)-> Hash Join (cost=1804.92..2585.91 rows=502 width=140) (actual time=0.069..16.342 rows=5709 loops=200)Hash Cond: (c.relnamespace = n.oid)-> Nested Loop (cost=1801.01..2580.62 rows=502 width=80) (actual time=0.068..14.519 rows=5709 loops=200)-> Hash Join (cost=1800.73..2057.32 rows=900 width=12) (actual time=0.066..4.280 rows=5709 loops=200)Hash Cond: (x.indexrelid = x_1.indexrelid)-> Hash Join (cost=766.65..1005.74 rows=2267 width=8) (actual time=0.028..2.815 rows=5709 loops=200)Hash Cond: (x.indrelid = c.oid)-> Seq Scan on pg_index x (cost=0.00..224.09 rows=5709 width=8) (actual time=0.002..0.833 rows=5709 loops=200)-> Hash (cost=715.81..715.81 rows=4067 width=8) (actual time=5.083..5.085 rows=4070 loops=1)Buckets: 4096 Batches: 1 Memory Usage: 191kB-> Seq Scan on pg_class c (cost=0.00..715.81 rows=4067 width=8) (actual time=0.010..4.506 rows=4070 loops=1)Filter: (relkind = ANY ('{r,t,m}'::"char"[]))Rows Removed by Filter: 6170-> Hash (cost=1005.74..1005.74 rows=2267 width=4) (actual time=7.443..7.445 rows=5709 loops=1)Buckets: 8192 (originally 4096) Batches: 1 (originally 1) Memory Usage: 265kB-> Hash Join (cost=766.65..1005.74 rows=2267 width=4) (actual time=4.328..6.637 rows=5709 loops=1)Hash Cond: (x_1.indrelid = c_1.oid)-> Seq Scan on pg_index x_1 (cost=0.00..224.09 rows=5709 width=8) (actual time=0.005..1.006 rows=5709 loops=1)-> Hash (cost=715.81..715.81 rows=4067 width=8) (actual time=4.312..4.313 rows=4070 loops=1)Buckets: 4096 Batches: 1 Memory Usage: 191kB-> Seq Scan on pg_class c_1 (cost=0.00..715.81 rows=4067 width=8) (actual time=0.009..3.746 rows=4070 loops=1)Filter: (relkind = ANY ('{r,t,m}'::"char"[]))Rows Removed by Filter: 6170-> Index Scan using pg_class_oid_index on pg_class i (cost=0.29..0.58 rows=1 width=68) (actual time=0.001..0.001 rows=1 loops=1141800)Index Cond: (oid = x.indexrelid)-> Hash (cost=2.85..2.85 rows=85 width=68) (actual time=0.038..0.039 rows=85 loops=1)Buckets: 1024 Batches: 1 Memory Usage: 17kB-> Seq Scan on pg_namespace n (cost=0.00..2.85 rows=85 width=68) (actual time=0.010..0.023 rows=85 loops=1)-> Index Only Scan using pg_class_oid_index on pg_class i_1 (cost=0.29..0.46 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=1141800)Index Cond: (oid = i.oid)Heap Fetches: 1141800Planning Time: 3.383 msExecution Time: 5618.715 ms
(38 rows)Time: 5623.090 ms (00:05.623)
发现果然如此,仅仅插入了200条数据而已,循环次数就达到了1141800次(5709*200)。而在原先的函数中往pgawr_names表中插入了有5000多条数据,这意味着至少要循环1千万次,这也是为什么会觉得SQL一直卡住在执行lseek的原因了。
回头再去看BUG #15455: Endless lseek,其实也是类似的原因,由于在会话中表数据量变化较多,而统计信息无法更新,同时SQL中有嵌套循环,导致性能异常,陷入了endless lseek中。
对此我们需要注意了,如果在同一个事务中先对某张表进行大量的增删操作,又由于其统计信息在事务结束前是不会更新的,而恰好该事务后面又有相关查询使用了该表,可能会对性能产生巨大影响,而如果该SQL中又包含较多嵌套循环,那么你也可能陷入看上去无休无止的lseek中了~
相关文章:
Endless lseek导致的SQL异常
最近碰到同事咨询的一个问题,在执行一个函数时,发现会一直卡在那里。 strace抓了下发现会话一直在执行lseek,大致情况如下: 16:13:55.451832 lseek(33, 0, SEEK_END) 1368064 <0.000037> 16:13:55.477216 lseek(33, 0, SE…...
JUC-day01
JUC-day01 什么是JUC线程的状态: wait sleep关键字:同步锁 原理(重点)Lock接口: ReentrantLock(可重入锁)—>AQS CAS线程之间的通讯 1 什么是JUC 1.1 JUC简介 在Java中,线程部分是一个重点,本篇文章说的JUC也是关于线程的。JUC就是java.util .con…...
Mind+Python+Mediapipe项目——AI健身之跳绳
原文:MindPythonMediapipe项目——AI健身之跳绳 - DF创客社区 - 分享创造的喜悦 【项目背景】跳绳是一个很好的健身项目,为了获知所跳个数,有的跳绳上会有计数器。但这也只能跳完这后看到,能不能在跳的过程中就能看到,…...

数据库概述
20世纪60年代后期,就出现了数据库技术。取得成就如下:造就了四位图灵奖得主发展成为以数据建模和DBMS核心技术为主,内容丰富的一门学科。带动了一个巨大的软件产业-DBMS产品及其相关工具和解决方案。四个基本概念数据数据是数据库中存储的基本…...
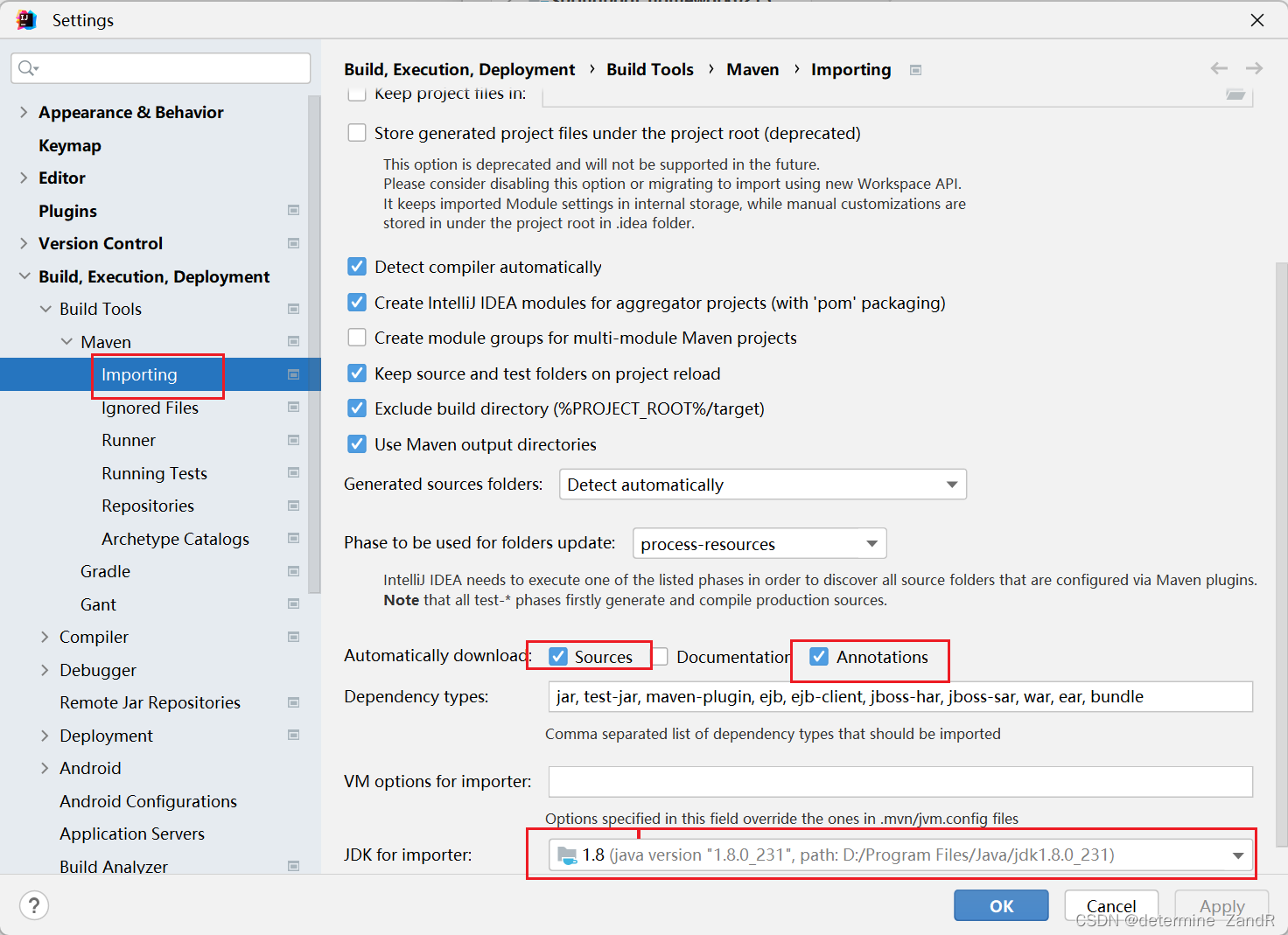
【已解决】解决IDEA的maven刷新依赖时出现Connot reconnect错误
前言 小编我将用CSDN记录软件开发求学之路上亲身所得与所学的心得与知识,有兴趣的小伙伴可以关注一下!也许一个人独行,可以走的很快,但是一群人结伴而行,才能走的更远!让我们在成长的道路上互相学习&#…...
文件的变编译和引用、执行)
动态链接库(.so)文件的变编译和引用、执行
动态链接库(.so)文件的变编译和引用 动态链接库:SO(Shared Object)是一种动态链接库,也被称为共享库。它是一种可被多个程序共享使用的二进制代码库,其中包含已编译的函数和代码。与静态链接库不同,动态链接…...
文件解压命令)
linux(centos8)文件解压命令
linux解压命令tar 解压命令常用解压命令1 [.tar] 文件 解压到当前文件夹2 [.tar.gz] 文件 解压到当前文件夹3 [.tar] 解压到指定文件夹 -C 必须是大写unzip 解压命令常用解压命令1 [.zip]解压到当前文件夹2 [.zip] 解压到指定文件夹2 [.zip] 解压到指定文件夹(强行覆…...

阅读笔记6——通道混洗
一、逐点卷积 当前先进的轻量化网络大都使用深度可分离卷积或组卷积,以降低网络的计算量,但这两种操作都无法改变特征图的通道数,因此需要使用11的卷积。总体来说,逐点的11卷积有如下两点特性: 可以促进通道之间的信息…...
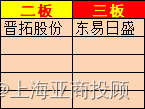
上海亚商投顾:沪指失守3300点 卫星导航概念全天强势
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。市场情绪指数早间低开后震荡回升,沪指盘中一度翻红,随后又再度走低,创业板指午后跌近1%。…...

疯狂的SOVA:Android银行木马“新标杆”
2021年8月初,一款针对Android银行APP的恶意软件出现在人们的视野中,ThreatFabric 安全研究人员首次发现了这一木马,在其C2服务器的登录面板,研究人员发现,攻击者将其称之为SOVA。 ** SO** ** V** ** A简介** 在俄语中…...

汽车零部件企业数字工厂管理系统建设方案
在汽车零部件制造领域,伴随工业信息化与机器人化,制造模式逐渐从 CAD/CAE/CAM 数字化设计及加工走向全产品周期虚拟现实的数字化工厂管理系统平台,实现虚拟现实设计制造,防范产品缺陷并预防设备故障,大幅提高生产效率。…...

【线程同步工具】Semaphore源码解析
控制对资源的一个或多个副本的并发访问 Java API 提供了一种信号量机制 Semaphore。 一个信号量就是一个计数器, 可用于保护对一个或多个共享资源的访问。 当一个线程要访问多个共享资源中的一个时,它首先需要获得一个信号量。如果信号量内部的计数器的…...

获取实时天气
一、用天气API(需要付费) 网址:https://www.tianqiapi.com/请求方式及url:请求方式:GET接口地址:https://tianqiapi.com/free/day请求示例https://www.tianqiapi.com/free/day?appid_____&appsecret__…...

【数据库】redis数据持久化
目录 数据持久化 一, RDB 1, 什么是RDB 2,持久化流程 3, 相关配置 案例演示: 4, 备份和恢复 1、备份 2、恢复 3,优势 4, 劣势 二,AOF 1,什么是A…...
前端编译、JIT编译、AOT编译
一、前端编译:java设计之初就是强调跨平台,通过javac将源文件编译成于平台无关的class文件, 它定义了执行 Java 程序所需的所有信息(许多Java"语法糖",是在这个阶段完成的,不依赖虚拟机ÿ…...

父子组件中,子组件调用父组件的方法
父子组件中,子组件调用父组件的方法 方法一:直接在子组件中通过this.$parent.event来调用父组件的方法 父组件 <template><p><child>父组件</child></p> </template> <script>import child from ~/compone…...
第七章.深度学习
第七章.深度学习 7.1 深度学习 深度学习是加深了层的深度神经网络。 1.加深层的好处 1).可以减少网络的参数数量 5*5的卷积运算示例: 重复两次3*3的卷积层示例: 图像说明: ①.一次5 * 5的卷积运算的区域可以由两次3 * 3的卷积运算抵消&a…...
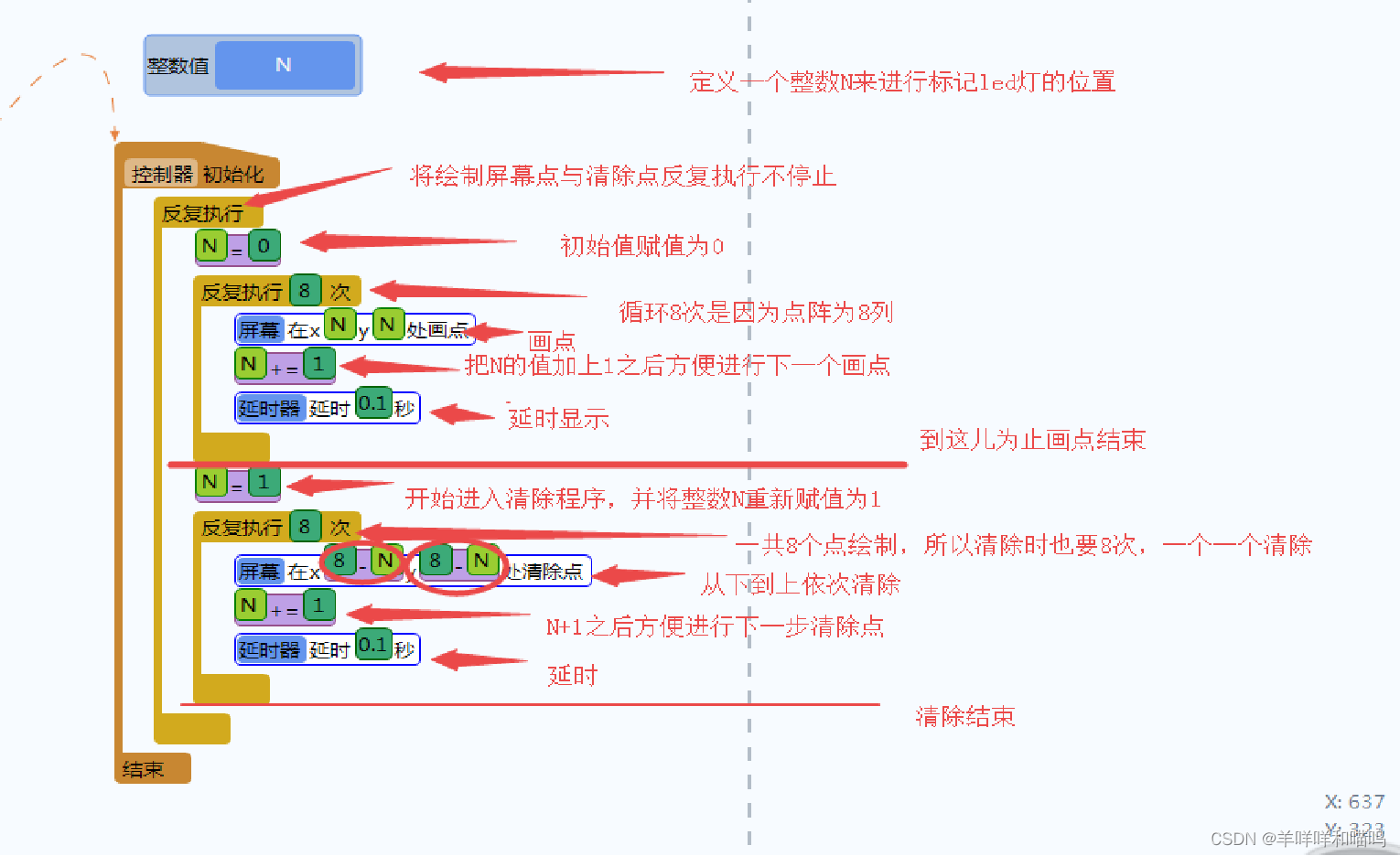
小学生学Arduino---------点阵(三)动态的显示与清除
学习目标: 1、理解“整数值”的概念与使用 2、理解“N1”指令的意义 3、掌握“反复执行多次”指令的使用 4、掌握屏幕模块的清除功能指令 5、理解“反复执行”指令与“反复执行多次”指令的嵌套使用 6、搭建电路图 7、编写程序 效果: 整数包括…...

opencv图片处理
目录1 图片处理1.1 显示图片1.2 旋转图片1.3 合并图片1.4、Mat类1.4.1、像素的储存结构1.4.2、访问像素数据1.6、rgb转灰度图1.7、二值化1.8、对比度和亮度1.9、图片缩放1.9.1、resize临近点算法双线性内插值1.9.2、金字塔缩放1.10、图片叠加1 图片处理 1.1 显示图片 #includ…...
—— 复合类型)
C++ Primer Plus 学习笔记(二)—— 复合类型
数组 当我们只是定义了数组,而没有对数组进行初始化时,那数组的值将是未定义的。 在对数组进行初始化时,如果只对数组的一部分进行初始化,编译器会将把其他元素自动设置为0。 #include <iostream>using namespace std;in…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...