C++之unordered_map,unordered_set模拟实现
unordered_map,unordered_set模拟实现
- 哈希表源代码
- 哈希表模板参数的控制
- 仿函数增加
- 正向迭代器实现
- *运算符重载
- ->运算符重载
- ++运算符重载
- != 和 == 运算符重载
- begin()与end()实现
- unordered_set实现
- unordered_map实现
- map/set 与 unordered_map/unordered_set对比
- 哈希表调整后代码
哈希表源代码
template<class K>
struct HashFunc
{size_t operator()(const K& key){//所有类型都强转为size_t类型return (size_t)key;}
};//模板特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t val = 0;for (auto ch : key){val *= 131;val += ch;}return val;}
};
namespace HashBucket
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;//构造函数HashNode(const pair<K, V>& kv):_kv(kv),_next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}inline size_t __stl_next_prime(size_t n){static const size_t __stl_num_primes = 28;static const size_t __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (size_t i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return -1;}bool Insert(const pair<K, V>& kv){//如果该键值对存在,就返回falseif (Find(kv.first)){return false;}Hash hash;//如果负载因子为1就扩容if (_size == _tables.size()){//创建一个新的哈希表vector<Node*> newTables;size_t newSizes = _size == 0 ? 10 : 2 * _tables.size();//将每个元素初始化为空newTables.resize(__stl_next_prime(_tables.size()), nullptr);//将旧表结点插入到新表当中for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){//记录cur的下一个结点Node* next = cur->_next;//计算相应的哈希桶编号size_t hashi = hash(cur->_kv.first) % newTables.size();//将旧表结点移动值新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}//计算哈希桶编号size_t hashi = hash(kv.first) % _tables.size();//插入结点Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;//元素个数++_size++;return true;}//查找Node* Find(const K& key){//哈希表为空就返回空if (_tables.size() == 0){return nullptr;}Hash hash;//计算哈希地址size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];//遍历哈希桶while (cur){if ((cur->_kv.first) == key){return cur;}cur = cur->_next;}return nullptr;}//删除bool Erase(const K& key){//哈希表大小为0,删除失败if (_tables.size() == 0){return false;}Hash hash;//计算哈希地址size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];//遍历哈希桶,寻找删除结点是否存在while (cur){if (hash(hash(cur->_kv.first)) == key){if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}//删除该结点delete cur;_size--;return true;}prev = cur;cur = cur->_next;}//删除结点不存在,返回falsereturn false;}size_t Size(){return _size;}size_t TableSize(){return _tables.size();}size_t BucketNum(){size_t num = 0;for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){num++;}}return num;}private:vector<Node*> _tables;size_t _size = 0;};
}
哈希表模板参数的控制
unordered_set属于K模型,unordered_map属于KV模型,但是在底层上我们都是用一个哈希表来实现的,所以我们需要将哈希表的第二个参数设置为T。
template<class K, class T>struct HashNode{T _data;HashNode<T>* _next;//构造函数HashNode(const T& data):_data(data),_next(nullptr){}};template<class K, class T, class Hash = HashFunc<K>>class HashTable{typedef HashNode<T> Node;public://......private:vector<Node*> _tables;size_t _size = 0;
};
T模板参数可能只是键值Key,也可能是由Key和Value共同构成的键值对。如果是unordered_set容器,那么它传入底层红黑树的模板参数就是Key和Key:
template<class K, class Hash = HashFunc<K>>
class unorder_set
{
public://...
private:HashBucket::HashTable<K, K, Hash> _ht;
};
如果是unordered_map容器,那么它传入底层红黑树的模板参数就是Key和Value:
template<class K, class V, class Hash = HashFunc<K>>
class unorder_map
{
public://...
private:HashBucket::HashTable<K, pair<K, V>, Hash> _ht;
};
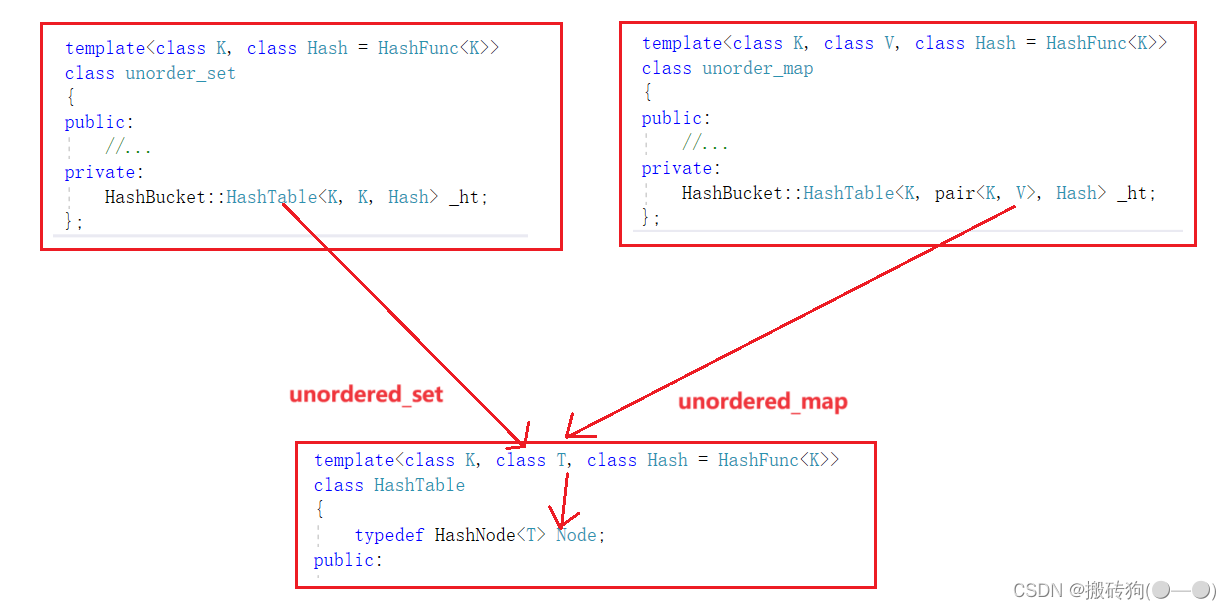
仿函数增加
对于unordered_set容器,我们需要进行键值比较就是对key值进行比较,也就是直接比较T就可以了,但是对于unordered_map容器来说,我们需要比较的是键值对<key,value>中的key,我们需要先将key提取出来,在进行比较。
所以,我们需要在上层unordered_set和unordered_map中各提供一个仿函数,根据传入的T类型分开进行比较操作:
map仿函数:
template<class K, class V, class Hash = HashFunc<K>>
class unorder_map
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public://...
private:HashBucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT> _ht;
};
set仿函数:
template<class K, class Hash = HashFunc<K>>
class unorder_set
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public://...
private:HashBucket::HashTable<K, K, Hash, SetKeyOfT> _ht;
};

正向迭代器实现
哈希表只存在正向迭代器,哈希表的正向迭代器实际上是对整个哈希表进行了封装:
//前置声明
template<class K, class T, class Hash, class KeyOfT>
class HashTable;template<class K, class T, class Hash, class KeyOfT>
struct __HashIterator
{typedef HashNode<T> Node;typedef HashTable <K, T, Hash, KeyOfT> HT;typedef __HashIterator <K, T, Hash, KeyOfT> Self;Node* _node;HT* _pht;
}
*运算符重载
解引用操作就是返回单链表某个结点的数据:
T& operator*()
{return _node->_data;
}
->运算符重载
->操作就是返回数据的地址:
T* operator->()
{return &_node->_data;
}
++运算符重载
哈希表中++其实就是寻找当前哈希桶中的该结点下一个结点,如果一个哈希桶中已经寻找完,就去下一个哈希桶中进行寻找,直到找到为止;
代码如下:
Self& operator++()
{//寻找该结点下一个结点点if (_node->_next){//下一个结点不为空,就指向下一个结点_node = _node->_next;}else{Hash hash;KeyOfT kot;//为空就计算该哈希桶所处位置的哈希地址size_t i = hash(kot(_node->_data)) % _pht->_tables.size();//地址++就计算出下一个桶的位置i++;//继续循环寻找for (; i < _pht->_tables.size(); i++){if (_pht->_tables[i]){_node = _pht->_tables[i];break;}}//找完整个哈希表,就指向nullptrif (i == _pht->_tables.size()){_node = nullptr;}}return *this;
}
!= 和 == 运算符重载
!= 和 ==就是判断是不是同一个结点:
//!=
bool operator!=(const Self& s)
{return _node != s._node;
}
//==
bool operator==(const Self& s)
{return _node == s._node;
}
begin()与end()实现
- begin函数返回哈希表当中第一个不为nullptr位置的正向迭代器。
- end函数返回哈希表当中最后一个位置下一个位置的正向迭代器,这里直接用空指针构造一个正向迭代器。
class HashTable
{typedef HashNode<T> Node;template<class K, class T, class Hash, class KeyOfT>friend struct __HashIterator;
public:typedef __HashIterator <K, T, Hash, KeyOfT> iterator;iterator begin(){//从前往后遍历整个数组for (size_t i = 0; i < _tables.size(); i++){//找到不为空的位置并返回该位置迭代器if (_tables[i]){return iterator(_tables[i], this);}}//最后返回end();return end();}iterator end(){//返回一个为空的位置的迭代器return iterator(nullptr, this);}
}
unordered_set实现
template<class K, class Hash = HashFunc<K>>
class unordered_set
{struct SetKeyOfT{const K& operator()(const K& key){return key;}};
public:typedef typename HashBucket::HashTable <K, K, Hash, SetKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}
private:HashBucket::HashTable<K, K, Hash, SetKeyOfT> _ht;
};
unordered_map实现
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public:typedef typename HashBucket::HashTable <K, pair<K, V>, Hash, MapKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){_ht.Insert(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}
private:HashBucket::HashTable<K, pair<K, V>, Hash, MapKeyOfT> _ht;
};
map/set 与 unordered_map/unordered_set对比
map/set 底层是使用红黑树实现的,unordered_map/unordered_set底层是用哈希表进行实现的,两者的底层实现是不同的,对于少量的数据,他们的增删查改没有区别,但是对于大量的数据unordered系列是要更胜一筹的,特别是对于查找来说,unordered系列基本可以一直保持高效率;
哈希表调整后代码
#pragma oncetemplate<class K>
struct HashFunc
{size_t operator()(const K& key){//所有类型都强转为size_t类型return (size_t)key;}
};//模板特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t val = 0;for (auto ch : key){val *= 131;val += ch;}return val;}
};namespace HashBucket
{template<class T>struct HashNode{T _data;HashNode<T>* _next;//构造函数HashNode(const T& data):_data(data),_next(nullptr){}};//前置声明template<class K, class T, class Hash, class KeyOfT>class HashTable;template<class K, class T, class Hash, class KeyOfT>struct __HashIterator{typedef HashNode<T> Node;typedef HashTable <K, T, Hash, KeyOfT> HT;typedef __HashIterator <K, T, Hash, KeyOfT> Self;Node* _node;HT* _pht;//构造函数__HashIterator(Node* node, HT* pht):_node(node),_pht(pht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}Self& operator++(){//寻找该结点下一个结点点if (_node->_next){//下一个结点不为空,就指向下一个结点_node = _node->_next;}else{Hash hash;KeyOfT kot;//为空就计算该哈希桶所处位置的哈希地址size_t i = hash(kot(_node->_data)) % _pht->_tables.size();//地址++就计算出下一个桶的位置i++;//继续循环寻找for (; i < _pht->_tables.size(); i++){if (_pht->_tables[i]){_node = _pht->_tables[i];break;}}//找完整个哈希表,就指向nullptrif (i == _pht->_tables.size()){_node = nullptr;}}return *this;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};template<class K, class T, class Hash, class KeyOfT>class HashTable{typedef HashNode<T> Node;template<class K, class T, class Hash, class KeyOfT>friend struct __HashIterator;public:typedef __HashIterator <K, T, Hash, KeyOfT> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(_tables[i], this);}}return end();}iterator end(){return iterator(nullptr, this);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}inline size_t __stl_next_prime(size_t n){static const size_t __stl_num_primes = 28;static const size_t __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (size_t i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return -1;}pair<iterator, bool> Insert(const T& data){Hash hash;KeyOfT kot;//如果该键值对存在,就返回falseiterator ret = Find((kot(data)));if (ret != end()){return make_pair(ret, false);}//如果负载因子为1就扩容if (_size == _tables.size()){//创建一个新的哈希表vector<Node*> newTables;size_t newSizes = _size == 0 ? 10 : 2 * _tables.size();//将每个元素初始化为空newTables.resize(__stl_next_prime(_tables.size()), nullptr);//将旧表结点插入到新表当中for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){//记录cur的下一个结点Node* next = cur->_next;//计算相应的哈希桶编号size_t hashi = hash(kot(cur->_data)) % newTables.size();//将旧表结点移动值新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}//计算哈希桶编号size_t hashi = hash(kot(data)) % _tables.size();//插入结点Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;//元素个数++_size++;return make_pair(iterator(newnode, this), true);}//查找iterator Find(const K& key){//哈希表为空就返回空if (_tables.size() == 0){return end();}Hash hash;KeyOfT kot;//计算哈希地址size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];//遍历哈希桶while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return end();}//删除bool Erase(const K& key){//哈希表大小为0,删除失败if (_tables.size() == 0){return false;}Hash hash;//计算哈希地址size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];//遍历哈希桶,寻找删除结点是否存在while (cur){if (hash(kot(cur->_data)) == key){if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}//删除该结点delete cur;_size--;return true;}prev = cur;cur = cur->_next;}//删除结点不存在,返回falsereturn false;}private:vector<Node*> _tables;size_t _size = 0;};
}相关文章:
C++之unordered_map,unordered_set模拟实现
unordered_map,unordered_set模拟实现 哈希表源代码哈希表模板参数的控制仿函数增加正向迭代器实现*运算符重载->运算符重载运算符重载! 和 运算符重载begin()与end()实现 unordered_set实现unordered_map实现map/set 与 unordered_map/unordered_set对比哈希表…...

React Router,常用API有哪些?
react-router React Router是一个用于构建单页面应用程序(SPA)的库,它是用于管理React应用中页面导航和路由的工具。SPA是一种Web应用程序类型,它在加载初始页面后,通过JavaScript来动态加载并更新页面内容࿰…...

JVM类加载和双亲委派机制
当我们用java命令运行某个类的main函数启动程序时,首先需要通过类加载器把类加载到JVM,本文主要说明类加载机制和其具体实现双亲委派模式。 一、类加载机制 类加载过程: 类加载的过程是将类的字节码加载到内存中的过程,主要包括…...

P-MVSNet ICCV-2019 学习笔记总结 译文 深度学习三维重建
文章目录 5 P-MVSNet ICCV-20195.0 主要特点5.1 文章概述5.2 研究方法5.2.1 特征提取5.2.2 学习局域匹配置信5.2.3 深度图预测5.2.4 Loss方程MVSNet系列最新顶刊 对比总结5 P-MVSNet ICCV-2019 深度学习三维重建 P-MVSNet-ICCV-2019(原文、译文、批注) 下载 5.0 主要特点 …...
vueshowpdf 移动端pdf文件预览
1、安装 npm install vueshowpdf -S2、参数 属性说明类型默认值v-model是否显示pdf--pdfurlpdf的文件地址String- scale 默认放大倍数 Number1.2 minscale 最小放大倍数 Number0.8 maxscale 最大放大倍数 Number2 3、事件 名称说明回调参数closepdf pdf关闭事件-pdferr文…...

C#根据excel文件中的表头创建数据库表
C#根据excel文件中的表头创建数据库表 private void button1_Click(object sender, EventArgs e){string tableName tableNameTextBox.Text;string connectionString "";using (OpenFileDialog openFileDialog new OpenFileDialog()){openFileDialog.Filter &quo…...
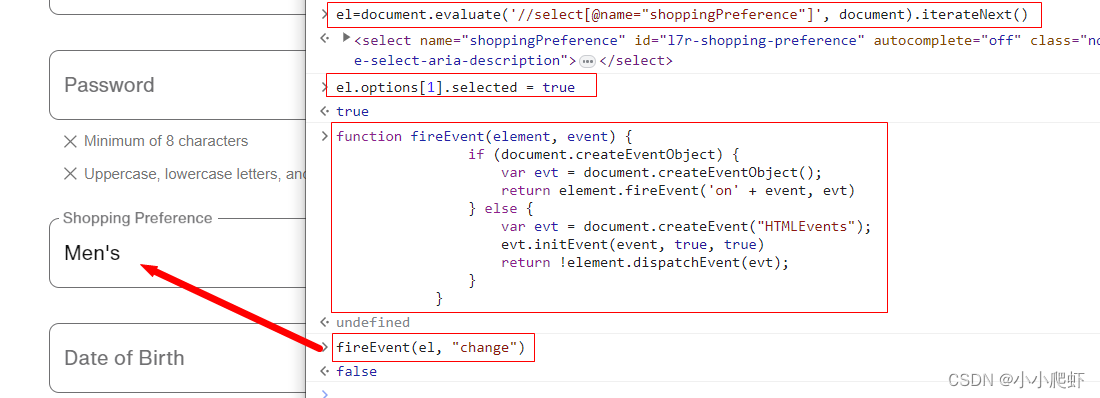
js通过xpath定位元素并且操作元素以下拉框select为例
js也可以使用xpath定位元素,现在实例讲解。 页面上有一个下拉框,里面内容有三个,用F12看一下 一、使用xpath定位这个下拉框select eldocument.evaluate(//select[name"shoppingPreference"], document).iterateNext()二、为下拉框…...
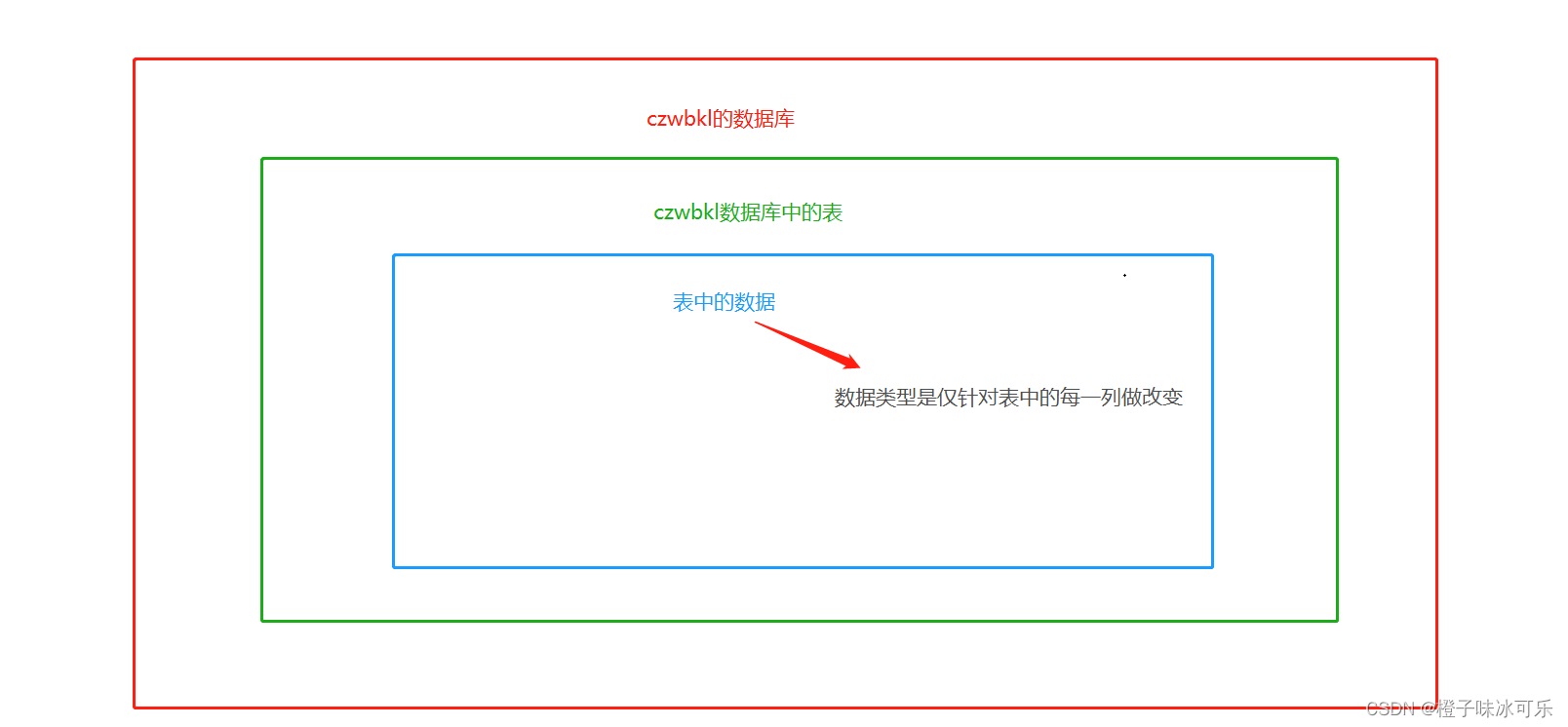
数据类型
目录 1.数值类型 整数类型 int 小数类型 double 2.字符类型 固定长度字符串 char 可变长度字符串 varchar 3.日期时间类型 日期类型:date 日期时间类型:datetime MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article…...

vue 模板应用
一,模板应用也就是对DOM的操作 二,如何使用 通过标签里面添加ref 和vue中使用 this.$refs.ref的名字.操作 进行使用 <template><h3>模板引用</h3><div ref"cont" class"cont">{{ content }}</div>&…...
Golang教程与Gin教程合集,入门到实战
GolangGin框架GormRbac微服务仿小米商城项目实战视频教程Docker Swarm K8s云原生分布式部署 介绍: Go即Golang,是Google公司2009年11月正式对外公开的一门编程语言,它不仅拥有静态编译语言的安全和高性能,而 且又达到了动态语言开…...

国家网络安全周 | 天空卫士荣获“2023网络安全优秀创新成果大赛优胜奖”
9月11日上午,四川省2023年国家网络安全宣传周在泸州开幕。在开幕式上,为2023年网络安全优秀创新成果大赛——成都分站赛暨四川省“熊猫杯”网络安全优秀作品大赛中获奖企业颁奖,天空卫士银行数据安全方案获得优秀解决方案奖。 本次比赛由四川…...
)
Swift学习笔记一(Array篇)
目录 0 绪论 1 数组的创建和初始化 2.数组遍历 2.1通过键值对遍历 2.2 通过forEach遍历 2.3 通过for in遍历 2.3.1 for in 搭配 enumerated 2.3.2 for in的另一种形式 2.3.2 for in 搭配 indices 2.4 通过Iterator遍历器遍历 3 数组的操作 3.1 contains 判断数组包含…...

C++项目实战——基于多设计模式下的同步异步日志系统-②-前置知识补充-不定参函数
文章目录 专栏导读不定参函数C风格不定参函数不定参宏函数 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计划导师,阿里云专家博主,CSDN内容合伙人…致力于 C/C、Linux 学…...

C++使用Boost库加入UDP组播时程序崩溃
程序崩溃情况 本程序运行在Oracle VM VirtualBox虚拟的Ubuntu20.04上 terminate called after throwing an instance of ‘boost::wrapexceptboost::system::system_error’ what(): set_option: No such device 已放弃 (核心已转储) ** C使用Boost库加入组播的代码 #inclu…...
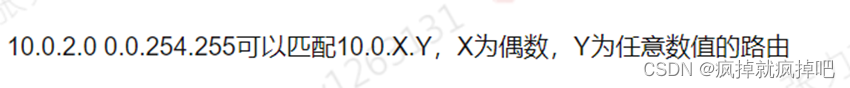
华为HCIA(四)
链路聚合可以负载分担,增加带宽,提高可靠性 Eth-trunk的传输速率和成员端口数量喝带宽有关 路由器分割广播域,交换机分割冲突域 指定端口:DP;根端口:RP;阻塞端口:AP 如果目的MAC不在交换机MAC中&…...
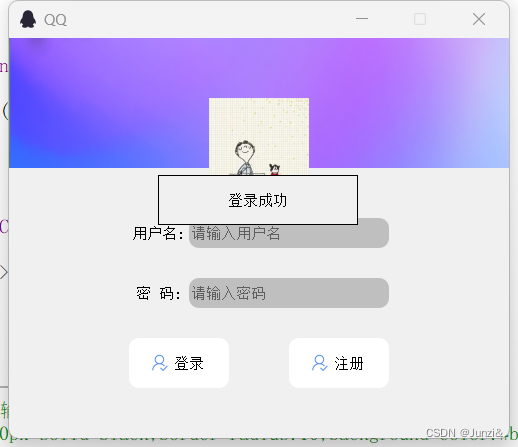
Qt --- Day01
效果图: 头像的圆形未实现 单击登陆,触发信号与槽 enter_widget.h #ifndef ENTER_H #define ENTER_H#include <QDialog> #include<QLabel> #include<QTimer> class enter_widget : public QDialog {Q_OBJECT public:explicit enter_…...

24.98万起,新一代AITO问界M7值得买吗?
监制 | 何玺 排版 | 叶媛 问界汽车新品来袭。 9月12日下午,问界汽车为全新的M7系列车型举行了发布会。华为常务董事余承东,在全网一片“遥遥领先”呼声的烘托下,上台发表演讲,详细介绍了M7的全面升级和各大亮点。 01 新一代AI…...

Java毕业设计 SSM SpringBoot 水果蔬菜商城
Java毕业设计 SSM SpringBoot 水果蔬菜商城 SSM 水果蔬菜商城 功能介绍 首页 图片轮播 关键字搜索商品 分类菜单 折扣大促销商品 热门商品 商品详情 商品评价 收藏 加入购物车 公告 留言 登录 注册 我的购物车 结算 个人中心 我的订单 商品收藏 修改密码 后台管理 登录 商品…...

前端JS中的异步编程与Promise
🎬 岸边的风:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 一、JavaScript的异步编步机制 二、事件循环(Event Loop)和任务队列(Task Queue…...
Pytorch Advanced(二) Variational Auto-Encoder
自编码说白了就是一个特征提取器,也可以看作是一个降维器。下面找了一张很丑的图来说明自编码的过程。 自编码分为压缩和解码两个过程。从图中可以看出来,压缩过程就是将一组数据特征进行提取, 得到更深层次的特征。解码的过程就是利用之前的…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...

简约商务通用宣传年终总结12套PPT模版分享
IOS风格企业宣传PPT模版,年终工作总结PPT模版,简约精致扁平化商务通用动画PPT模版,素雅商务PPT模版 简约商务通用宣传年终总结12套PPT模版分享:商务通用年终总结类PPT模版https://pan.quark.cn/s/ece1e252d7df...