美团多场景建模的探索与实践
本文介绍了美团到家/站外投放团队在多场景建模技术方向上的探索与实践。基于外部投放的业务背景,本文提出了一种自适应的场景知识迁移和场景聚合技术,解决了在投放中面临外部海量流量带来的场景数量丰富、场景间差异大的问题,取得了明显的效果提升。希望能给大家带来一些启发或帮助。
-
1 引言
-
2 自适应场景建模
-
2.1 自适应场景知识迁移
-
2.2 自适应场景聚合
-
-
3 总结与展望
1 引言
美团到家Demand-Side Platform(下文简称DSP)平台,主要负责在美团外部媒体上进行商品或者物料的推荐和投放,并不断优化转化效果。随着业务的不断发展与扩大,DSP对接的外部渠道越来越丰富、展示形式越来越多样,物料展示场景的差异性愈发明显(如开屏、插屏、信息流、弹窗等)。
例如,用户在午餐时间更容易点击【某推荐渠道下】【某App】【开屏展示位】的快餐类商家的物料而不是【信息流展示位】的啤酒烧烤类商家物料。场景间差异的背后本质上是用户意图和需求的差异,因此模型需要对越来越多的场景进行定制化建设,以适配不同场景下用户的个性化需求。
业界经典的Mixture-of-Experts架构(MoE,如MMoE、PLE、STAR[1]等)能一定程度上适配不同场景下用户的个性化需求。这种架构将多个Experts的输出结果通过一个门控网络进行权重分配和组合,以得到最终的预测结果。早期,我们基于MoE架构提出了使用物料推荐渠道进行场景划分的多场景建模方案。然而,随着业务的不断壮大,场景间的差异越来越大、场景数量也越来越丰富,这版模型难以适应业务发展,不能很好地解决DSP背景下存在的以下两个问题:
-
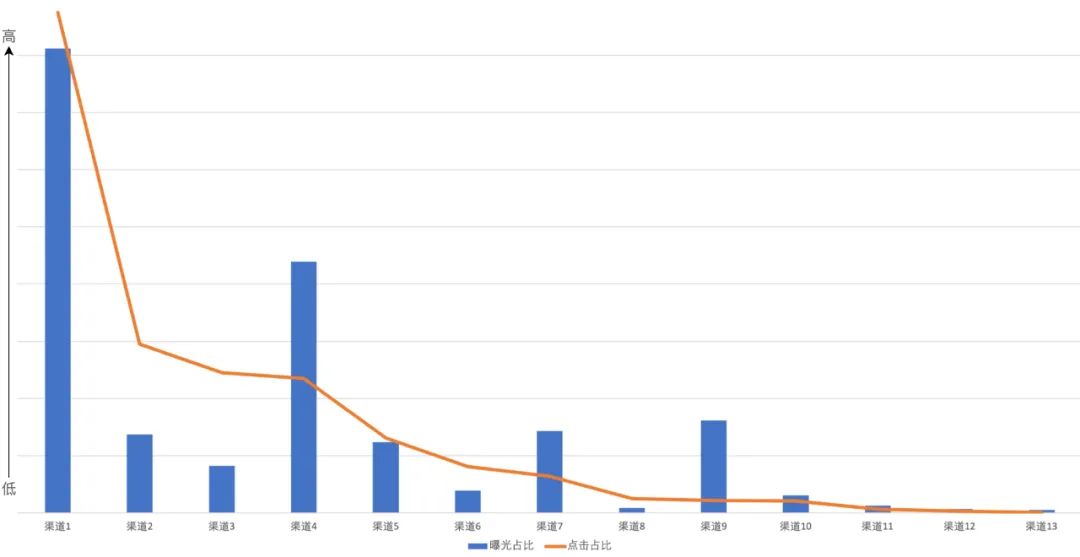
负迁移现象:以推荐渠道为例,由于不同推荐渠道的流量在用户分布、行为习惯、物料展示形式等方面存在差异,其曝光数、点击率也不在同一个数量级(如下图1所示,不同渠道间点击率相差十分显著),数据呈现典型的“长尾”现象。如果使用推荐渠道进行多场景建模的依据,一方面模型会更倾向于学习到头部渠道的信息,对于尾部渠道会存在学习不充分的问题,另一方面尾部渠道的数据也会给头部渠道的学习带来“噪声”,导致出现负迁移。
-
数据稀疏难以收敛:DSP会在外部不同媒体上进行物料展示,而用户在访问外部媒体时,其所处的时空背景、上下文信息、不同App以及物料展示位等信息共同构成了当前的场景,这样的场景在十万的量级,每个场景的数据又十分稀疏,导致模型难以在每个场景上得到充分的训练。
在面对此类建模任务时,业界现有的方法是在不同场景间进行知识迁移。例如,SAML[2]模型采用辅助网络来学习场景的共享知识并迁移至各场景的独有网络;ADIN[3]和SASS[4]模型使用门控单元以一种细粒度的方式来选择和融合全局信息到单场景信息中。然而,在DSP背景中复杂多变的流量背景下,场景差异性导致了场景数量的急剧增长,现有方法无法在巨量稀疏场景下有效。
因此,在本文中我们提出了DSP背景下的自适应场景建模方案(AdaScene, Adaptive Scenario Model),同时从知识迁移和场景聚合两个角度进行建模。AdaScene通过控制知识迁移的程度来最大化不同场景共性信息的利用,并使用稀疏专家聚合的方式利用门控网络自动选择专家组成场景表征,缓解了负迁移现象;同时,我们利用损失函数梯度指导场景聚合,将巨大的推荐场景空间约束到有限范围内,缓解了数据稀疏问题,并实现了自适应场景建模方案。
2 自适应场景建模
在本节开始前,我们先介绍多场景模型的建模方式。多场景模型采用输入层 Embedding + 混合专家(Mixture-of-Experts, MoE)的建模范式,其中输入信息包括了用户侧、商家侧以及场景上下文特征。多场景模型的损失由各场景的损失聚合而成,其损失函数形式如下:

其中,K为场景数量,α为各场景的损失权重值。
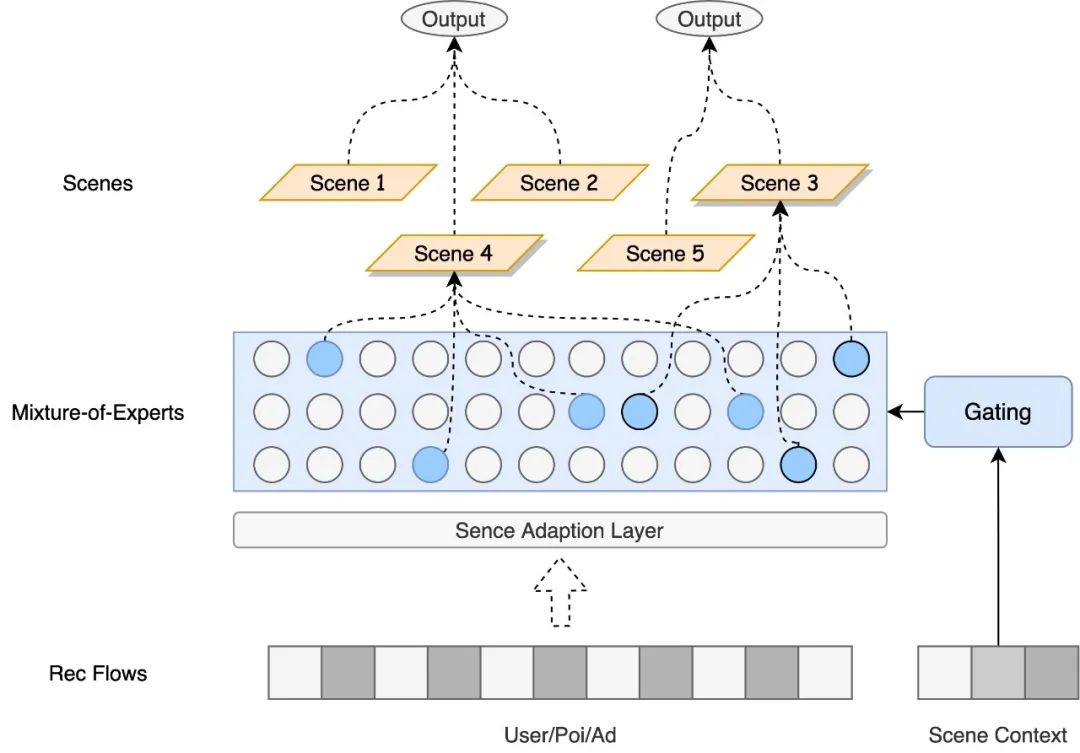
我们提出的AdaScene自适应场景模型主要包含以下2个部分:场景知识迁移(Knowledge Transfer)模块以及场景聚合(Scene Aggregation)模块,其模型结构如下图2所示。场景知识迁移模块自适应地控制不同场景间的知识共享程度,并通过稀疏专家网络自动选择K个专家构成自适应场景表征。场景聚合模块通过离线预先自动化衡量所有场景间损失函数梯度的相似度,继而通过最大化场景相似度来指导场景的聚合。
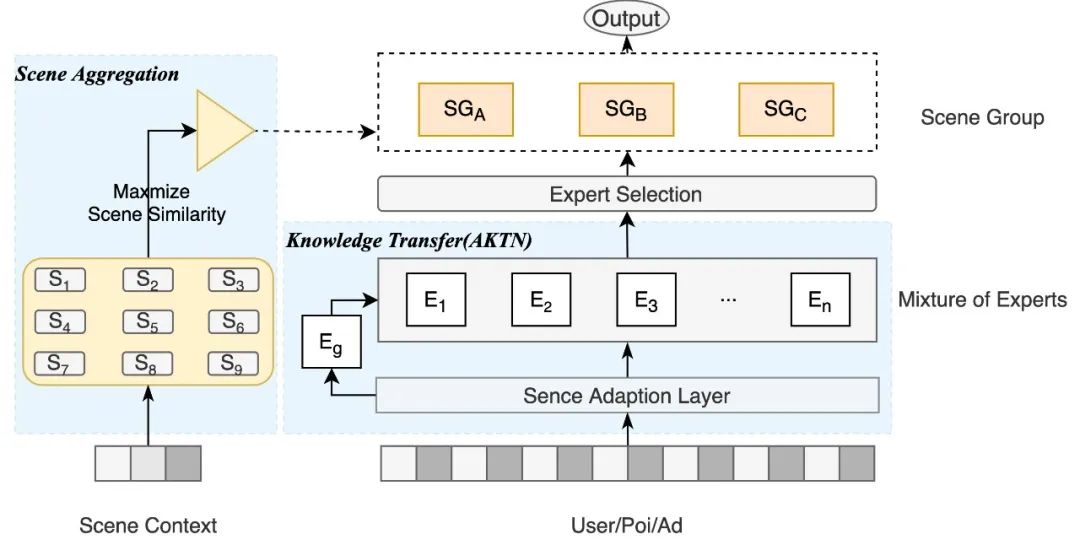
图2 自适应场景建模AdaScene示意图

下面,我们分别介绍自适应场景知识迁移和场景聚合的建模方案。
| 2.1 自适应场景知识迁移
在多场景建模中,场景定义方式决定了场景专家的学习样本,很大程度上影响着模型对场景的拟合能力,但无论采用哪种场景定义方式,不同场景间用户分布都存在重叠,用户行为模式也会有相似性。
为提升不同场景间共性的捕捉能力,我们从场景特征和场景专家两个维度探索场景知识迁移的方法,在以物料推荐渠道×App×展示形态作为多场景建模Base模型的基础上,构建了如下图3所示的自适应场景知识迁移模型(Adaptive Knowledge Transfer Network, AKTN)。该模型建立了场景共享参数与私有参数的知识迁移桥梁,能够自适应地控制知识迁移的程度、缓解负迁移现象。
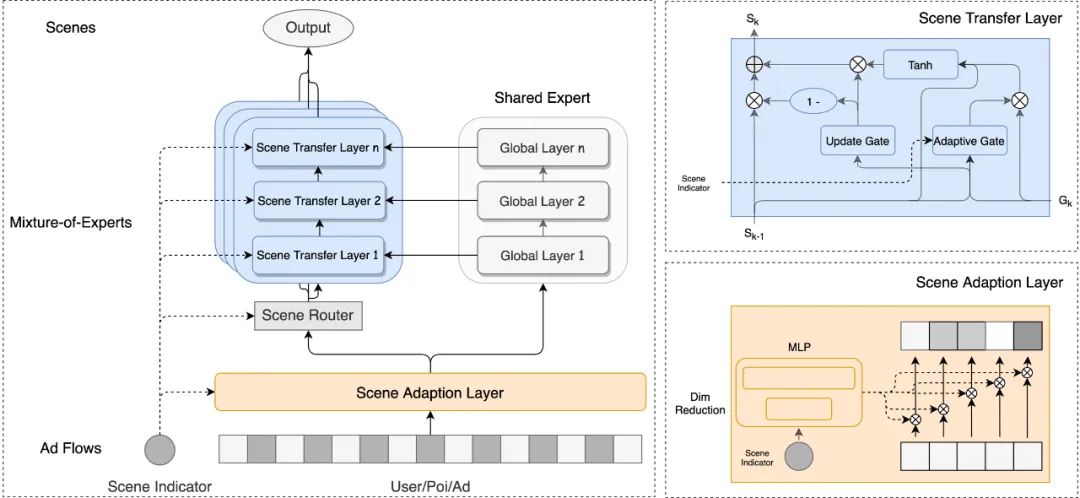
图3 AKTN(Adaptive Knowledge Transfer Network)

场景特征适配在输入层根据场景信息对不同特征进行权重适配,筛选出当前场景下模型最关注的特征;场景知识迁移在隐层专家网络中进行知识迁移,控制共享专家中共性信息向场景独有信息的流动,使得场景共性信息得以传递。
这两种知识迁移方式互为补充、相辅相成,共同提升多场景模型的预估能力。我们对比了不同模块的实验效果,具体结果如下表1所示。可以看出,引入场景知识迁移和特征权重优化在头部、尾部渠道都能带来一定提升,其中尾部小流量场景上(见下表1子场景2、3)有更为明显的提升,可见场景知识迁移缓解了场景之间的负迁移现象。
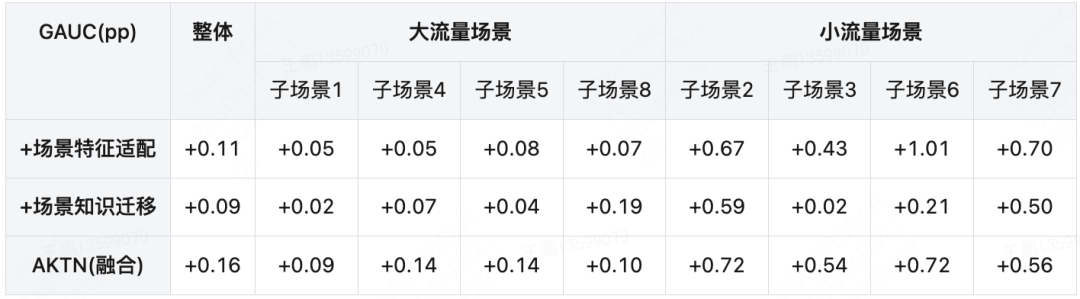
表1 AKTN实验效果
相关研究和实践表明[6][7][8],稀疏专家网络对于提高计算效率和增强模型效果非常有用。因此,我们在AKTN模型的基础上,在专家层进一步优化多场景模型。具体的,我们将场景知识迁移层替换为自动化稀疏专家选择方法,通过门控网络从大规模专家中选取与当前场景最相关的个构成自适应场景表征,其选择过程如下图4所示:
在实践中,我们通过使用可微门控网络对专家进行有效组合,以避免不相关任务之间的负迁移现象。同时大规模专家网络的引入扩大了多场景模型的选择空间,更好地支持了门控网络的选择。考虑到多场景下的海量流量和复杂场景特征,在业界调研的基础上对稀疏专家门控网络进行了探索。
具体而言,我们对以下稀疏门控方法进行了实践:
-
方法一:通过KL散度衡量子场景与各专家之间的相似度,以此选择与当前场景最匹配的k个专家。在实现方式上,使用场景*专家的二维矩阵计算相似性,并通过KL散度选择出最适合的k个专家。
-
方法二:每个子场景配备一个专家选择门控网络,m个场景则有m个门控网络。对于每个场景的门控网络,配备个k个单专家选择器[9],每个单专家选择器负责从n个专家中选择一个作为当前场景的专家(n为Experts个数)。在实践中,为提高训练效率,我们对单专家选择器中权重较小的值进行截断,保证每个单专家选择器仅选择一个专家。
在离线实验中,我们以物料推荐渠道 * 展示形态作为场景定义,对上述稀疏门控方法进行了尝试,离线效果如下表2所示:
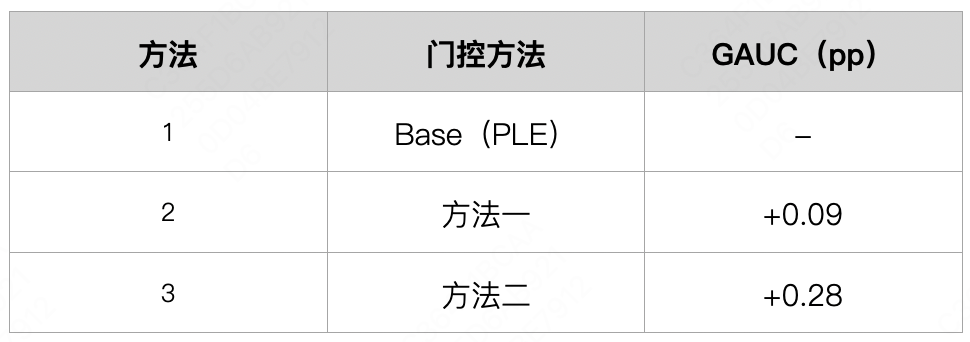
表2 稀疏门控方法效果
可以看出,基于软共享机制的专家聚合方法能够更好地通过所激活的相同专家网络对各场景之间的知识进行共享。相较于常见的以截断方式为主的门控网络,使用二进制编码的方式使得其在不损失其他专家网络信息的同时,能够更好地收敛到目标专家数量,同时其可微性使得其在以梯度为基础的优化算法中训练更加稳定。
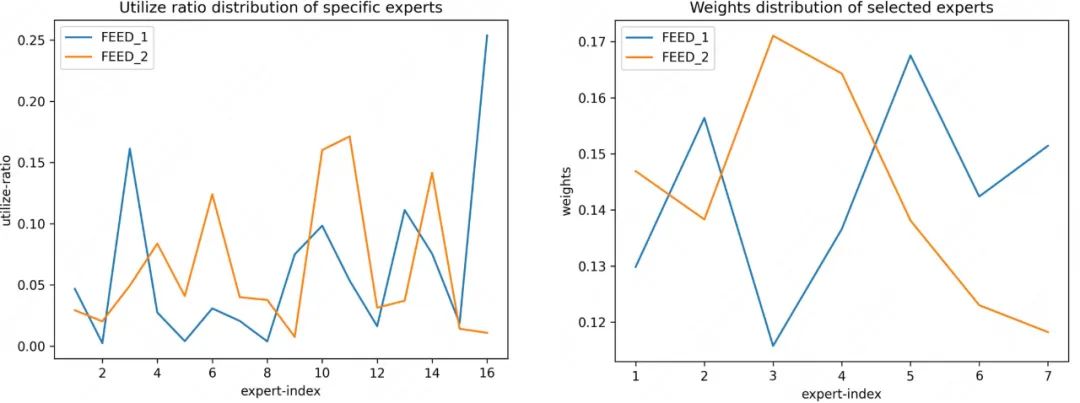
同时,为了验证稀疏门控网络能否有效区分不同场景并捕捉到场景间差异性,我们使用n=16个专家中选择K=7个的例子,对验证集中不同场景下各专家的利用率、选择专家的平均权重进行了可视化分析(如图5-图7所示),实验结果表明该方法能够有效地选择出不同的专家对场景进行表达。
例如,图6中KP_1更多地选择第5个专家,而KP_2更倾向于选择第15个专家。并且,不同场景对各专家的使用率以及选择专家的平均权重也有着明显的差异性,表明该方法能够捕捉到细分场景下流量的差异性并进行差异化的表达。
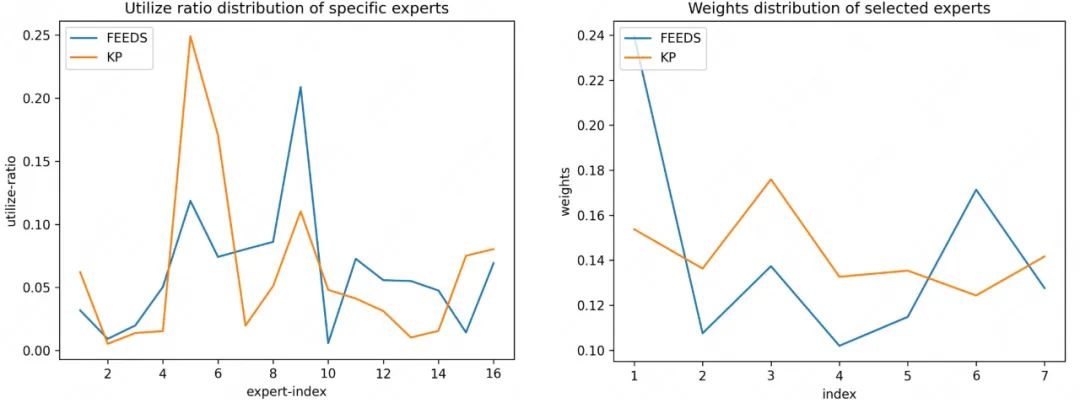
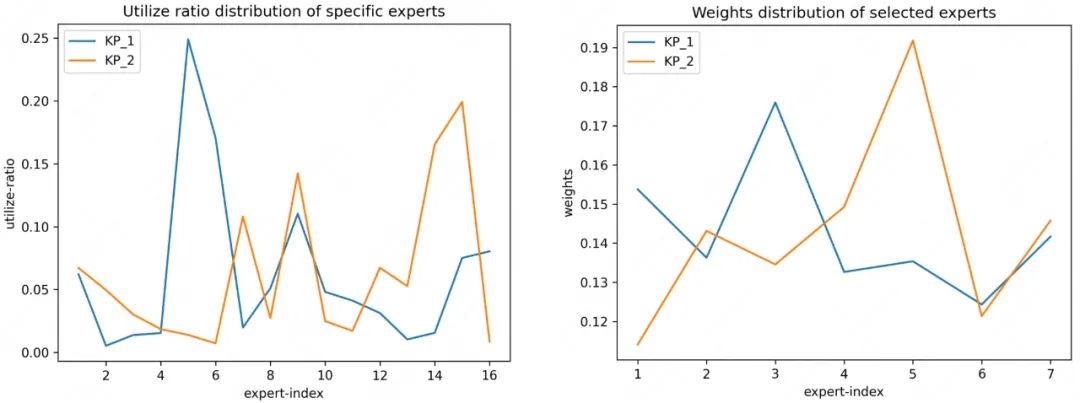
实验证明,在通过大规模专家网络对每个场景进行建模的同时,基于软共享机制的专家聚合方法能够更好地通过所激活的相同专家网络对各场景之间的知识进行共享。同时,为了进一步探索Experts个数对模型性能的影响,我们在方法二的基础上通过调整专家个数和topK比例设计了多组对比实验,实验结果如下表3所示:
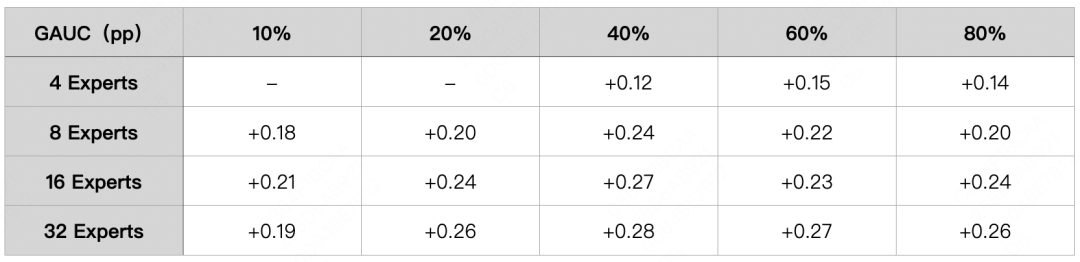
从实验数据可以看出,大规模的Experts结构会带来正向的离线收益;并且随着选取专家个数比例的增加(表3横轴),模型整体的表现效果也有上升的趋势。
| 2.2 自适应场景聚合
理想情况下,一条请求(流量)可以看作一个独立的场景。但如引言所述,随着DSP业务持续发展,不同的物料展示渠道、形式、位置等持续增加,每个场景的数据十分稀疏,我们无法对每个细分场景进行有效训练。
因此,我们需要对各个推荐场景进行聚类、合并。我们使用场景聚合的方法对此问题进行求解,通过衡量所有场景间的相似度,并最大化该相似度来指导场景的聚合,解决了数据稀疏导致难以收敛的问题。具体的,我们将该问题表示为:


因此,我们在2.1节场景知识迁移模型的基础上,增加了场景聚合部分,提出了基于 Two-Stage 策略进行训练的场景聚合模型:
-
Stage 1:基于相似度衡量方法对各场景的相似度进行归纳,并以最大化分组场景的相似度为目标找到各场景的最优聚合方式(如Scene1与Scene 4可聚合为场景组合Scene Group SGA);
-
Stage 2:基于Stage 1得到的场景聚合方式,以交叉熵损失为目标函数最小化各场景下的交叉熵损失。
其中,Stage 2与2.1节中所述一致,本节主要针对Stage 1进行阐述。我们认为,一个有效的场景聚合方法应该能自适应地应对流量变化的趋势,能够发现场景之间的内在联系并依据当前流量特点自动适配聚合方法。我们首先想到的是从规则出发,将人工先验知识作为场景聚合的依据,按照推荐渠道、展示形式以及两者叉乘的方式进行了相应迭代。然而这类场景聚合方式需要可靠的人工经验来支撑,且在应对海量流量时不能迅速捕捉到其中的变化。
因此,我们对场景之间关系的建模方法进行了相关的探索。首先,我们通过离线训练时场景之间的表征迁移和组合训练来评估场景之间的影响,但这种方式存在组合空间巨大、训练耗时较长的问题,效率较低。
在多任务的相关研究中[10][11][12][13],使用梯度信息对任务之间的关系进行建模是一种有效的方法。类似的在多场景模型中,能够根据各场景损失函数的梯度信息对场景间的相似度进行建模,因此我们采用多专家网络并基于梯度信息自动化地对场景之间的相似度进行求解,模型示意如下图8所示:
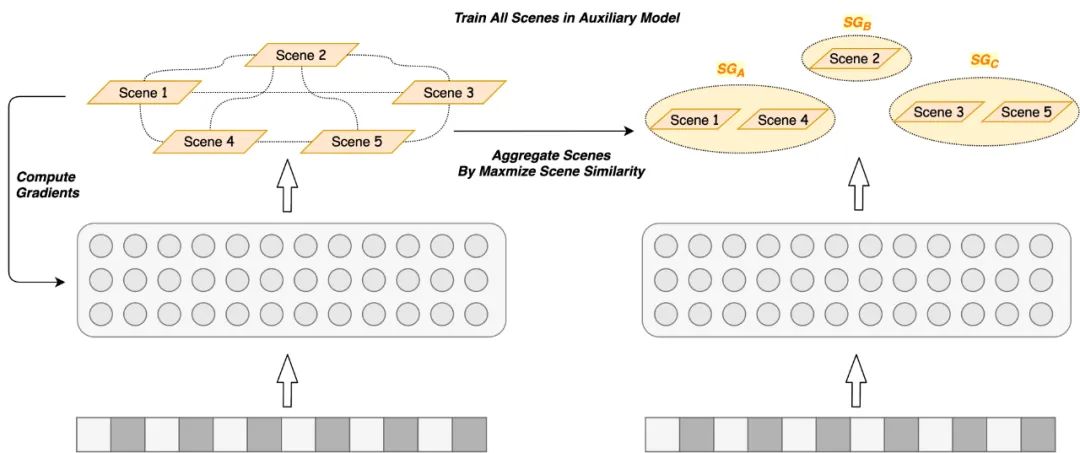
基于上述思路,我们对场景之间的关系建模方法进行了以下尝试。
1. Gradient Regulation
基于梯度信息能够对场景信息进行潜在表示这一认知,我们在损失函数中加入各场景损失函数关于专家层梯度距离的正则项,整体的损失函数如下所示,该正则项的系数表示场景之间的相似度,为常见的评估梯度之间距离的方法,比如,距离。
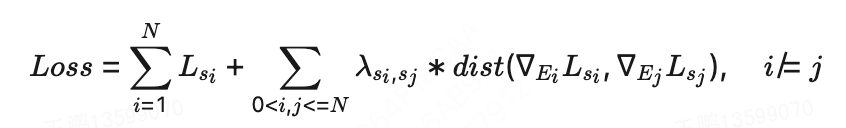
2. Lookahead Strategy

3. Meta Weights
Lookahead Strategy该方法对场景间的关系进行了显式建模,但是这种根据损失函数的变化计算场景相关系数的策略存在着训练不稳定、波动较大的现象,无法像Gradient Regulation这一方法对场景相似度进行求解。
 我们以推荐渠道和展示形式(是否开屏)的多场景模型作为Base,对上述3种方法做了探索。为了提高训练效率,我们在设计 Stage 1 模型时做了以下优化:
我们以推荐渠道和展示形式(是否开屏)的多场景模型作为Base,对上述3种方法做了探索。为了提高训练效率,我们在设计 Stage 1 模型时做了以下优化:

我们对每个方法的GAUC进行了比较,实验效果如下表4所示。相较于人工规则,基于梯度的场景聚合方法都能带来效果的明显提升,表明损失函数梯度能在一定程度上表示场景之间的相似性,并指导多场景进行聚合。
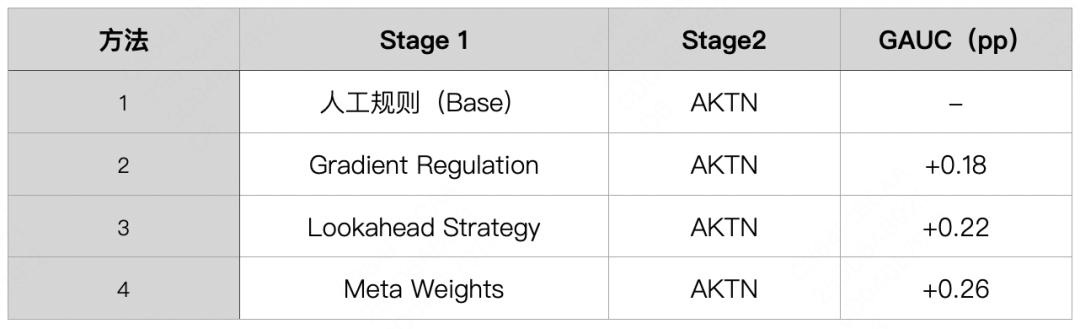
为了更全面的展现场景聚合对于模型预估效果的影响,我们选取Meta Weights进行分组数量的调优实验,具体的实验结果如下表5所示。可以发现:随着分组数的增大,GAUC提升也越大,此时各场景间的负迁移效应减弱;但分组超过一定数量时,场景间总体的相似度减小,GAUC呈下降趋势。

此外,我们对Meta Weigts方法中部分场景间的关系进行了可视化分析,分析结果如下图9所示。以场景作为坐标轴,图中的每个方格表示各场景间的相似度,颜色的深浅表示渠道间的相似程度大小。
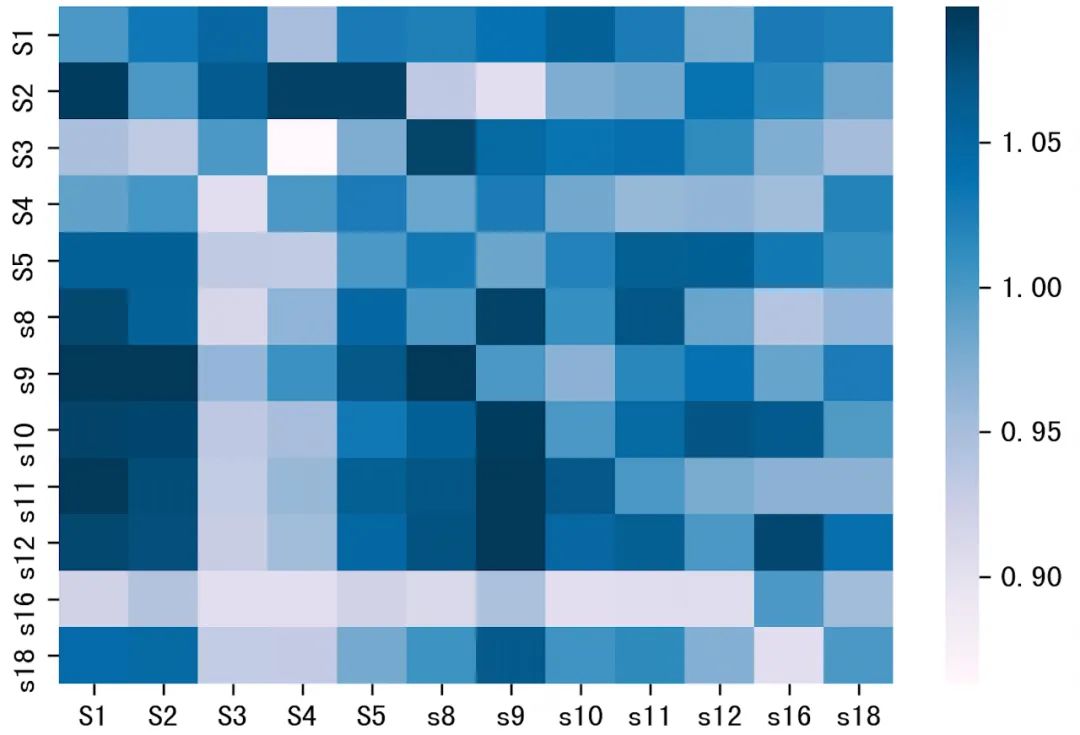
图9 部分细分场景下的相似度示例
从图中可以发现,以渠道和展示形式为粒度的细分场景下,该方法能够学习到不同场景间的相关性,例如A渠道下的信息流(s16)与其他场景的相关性较低,会将其作为独立的场景进行预估,而B渠道下的开屏展示(s9)与C渠道开屏展示(s8)相关性较高,会将其聚合为一个场景进行预估,同时该相似度矩阵不是对称的,这也说明各场景间相互的影响存在着差异。
3 总结与展望
通过多场景学习的探索和实践,我们深入挖掘了推荐模型在不同场景下的建模能力,并分别从场景知识迁移、场景聚合方向进行了尝试和优化,这些尝试提供了更好的理解和解释推荐模型对不同类型流量和场景的应对能力。然而,这只是多场景学习研究的开始,后续我们会探索并迭代以下方向:
-
更好的场景划分方式:当前多场景的划分主要还是依据渠道(渠道*展示形态)作为流量的划分方式,未来会在媒体、展示位、媒体*时间等维度上进行更详细地探索;
-
端到端的流量聚合方式:在进行流量聚合时,使用了Two-Stage的策略进行聚合。然而,这种方式不能充分地利用流量数据中相关的信息。因此,需要探索端到端的流量场景聚合方案将更直接和有效地提高推荐模型的能力。
结合多场景学习,在未来的研究中将不断探索新的方法和技术,以提高推荐模型对不同场景和流量类型的建模能力,创造更好的用户体验以及商业价值。
4 作者简介
王驰、森杰、树立、文帅、尹华、肖雄等,均来自美团到家事业群/到家研发平台/成都研发中心。
5 参考文献
[1] STAR:Sheng, Xiang-Rong, et al. "One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction." Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
[2] SAML:Chen, Yuting, et al. "Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce." 2020 International Conference on Data Mining Workshops (ICDMW). IEEE, 2020.
[3] ADIN:Jiang, Yuchen, et al. "Adaptive Domain Interest Network for Multi-domain Recommendation." Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
[4]SASS:Zhang, Yuanliang, et al. "Scenario-Adaptive and Self-Supervised Model for Multi-Scenario Personalized Recommendation." Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
[5] Squeeze-and-Excitation:Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[6] 美团外卖推荐情境化智能流量分发的实践与探索
[7] PaLM:https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
[8] GLaM:https://proceedings.mlr.press/v162/du22c.html
[9] 单专家选择器:https://arxiv.org/abs/2106.03760
[10] HOA:https://proceedings.mlr.press/v119/standley20a.html
[11] Gradient Affinity:https://proceedings.neurips.cc/paper/2021/hash/e77910ebb93b511588557806310f78f1-Abstract.html
[12] SRDML:https://dl.acm.org/doi/abs/10.1145/3534678.3539442
[13] Auto-Lambda:https://arxiv.org/abs/2202.03091
[14] MAML:https://arxiv.org/abs/1703.03400
---------- END ----------
美团科研合作
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com。
推荐阅读
| KDD Cup 2020多模态召回比赛季军方案与广告业务应用
| KDD Cup 2020多模态召回比赛亚军方案与搜索业务应用
| 多业务建模在美团搜索排序中的实践
相关文章:
美团多场景建模的探索与实践
本文介绍了美团到家/站外投放团队在多场景建模技术方向上的探索与实践。基于外部投放的业务背景,本文提出了一种自适应的场景知识迁移和场景聚合技术,解决了在投放中面临外部海量流量带来的场景数量丰富、场景间差异大的问题,取得了明显的效果…...
第11篇:ESP32vscode_platformio_idf框架helloworld点亮LED
第1篇:Arduino与ESP32开发板的安装方法 第2篇:ESP32 helloword第一个程序示范点亮板载LED 第3篇:vscode搭建esp32 arduino开发环境 第4篇:vscodeplatformio搭建esp32 arduino开发环境 第5篇:doit_esp32_devkit_v1使用pmw呼吸灯实验 第6篇:ESP32连接无源喇叭播…...

React中的页面跳转方式详解
在React中,页面跳转通常通过路由来实现。React有多种路由库可供选择,其中最常用的是React Router。React Router提供了几种不同的跳转方式,包括使用组件进行页面跳转、使用组件进行重定向,以及使用编程式导航进行跳转。 使用组件进…...
Golang代码漏洞扫描工具介绍——govulncheck
Golang Golang作为一款近年来最火热的服务端语言之一,深受广大程序员的喜爱,笔者最近也在用,特别是高并发的场景下,golang易用性的优势十分明显,但笔者这次想要介绍的并不是golang本身,而且golang代码的漏洞…...
第31章_瑞萨MCU零基础入门系列教程之WIFI蓝牙模块驱动实验
本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id728461040949 配套资料获取:https://renesas-docs.100ask.net 瑞萨MCU零基础入门系列教程汇总: ht…...

arkworks工具栈概览
1. 引言 arkworks定位为zkSNARK编程的Rust生态。其开源代码见: https://github.com/arkworks-rs/ arkworks目前已广泛用于大量项目中,如:Aleo、anoma、celo、Espresso、Findora、Manta、Mina、Nimiq、penumbra等等。 参与arkworks开源实现…...
华为云云服务器云耀L实例评测 | 在华为云耀L实例上搭建电商店铺管理系统:一次场景体验
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
sqlserver存储过程报错:当前事务无法提交,而且无法支持写入日志文件的操作。请回滚该事务。
现象: 系统出现异常,手动执行过程提示如上。 问题排查: 1.直接执行的过程事务挂起(排除) 2.重启数据库实例(重启后无效) 3.过程中套用过程,套用的过程中使用事务,因为…...

二刷力扣--字符串
字符串 摘自Python文档-标准库: 在Python中, 字符串是由 Unicode 码位构成的不可变序列。 由于不存在单独的“字符”类型,对字符串做索引操作将产生一个长度为 1 的字符串。 也就是说,对于一个非空字符串 s, s[0] s[0:1]。 不存…...
如何将 OBJ 模型转换和压缩为 GLTF 以与 AWS IoT TwinMaker 配合使用
推荐:使用NSDT场景编辑器快速搭建3D应用场景 概述 在这篇博文中,引用了几种文件扩展名和模型格式。在开始之前,最好了解以下内容: OBJ – 对象文件,一种标准的 3D 图像格式,可以通过各种 3D 图像编辑程序…...

零基础学前端(四)重点讲解 CSS
1. 该篇适用于从零基础学习前端的小白 2. 初学者不懂代码得含义也要坚持模仿逐行敲代码,以身体感悟带动头脑去理解新知识 3. 初学者切忌,不要眼花缭乱,不要四处找其它文档,要坚定一个教授者的方式,将其学通透ÿ…...

类和对象【初始化列表与友元】
全文目录 初始化列表特性 explicit关键字static成员特性 友元友元函数友元类内部类特性 初始化列表 构造函数体中的语句只能将其称为赋初值,而不能称作初始化。因为初始化只能初始化一次,而构造函数体内可以多次赋值。 对象的初始化是在初始化列表进行…...

ActiveRecord::Migration.maintain_test_schema!
测试gem: rspec-rails 问题描述 在使用 rspec-rails 进行测试时,出现了以下错误 ActiveRecord::StatementInvalid: UndefinedFunction: ERROR: function init_id() does not exist这个错误与数据库架构有关。 schema.rb中 create_table "users…...

逆向-beginners之helloworld
#include <stdio.h> int _main() { printf("hello world.\n"); return 0; } // 上面的代码等效于: char *SG3830[] {"hello, world\n"}; int main() { printf("%s", *SG3830); return 0; } #if 0 /* * i…...

如何微调甜甜圈模型——使用示例
Python 中的 Donut 模型可用于从给定图像中提取文本。这在各种场景中都很有用,例如扫描收据。 您可以轻松地。但与人工智能模型一样,您应该根据您的特定需求微调模型。 我编写本教程是因为我没有找到任何资源来准确展示如何使用我的数据集微调 Donut 模型。因此,我必须从其…...
小程序中如何查看指定会员的付款记录
在小程序中,我们可以通过一些简单的步骤来查看指定会员的付款记录。下面是具体的操作流程: 1. 找到指定的会员卡。在管理员后台->会员管理处,找到需要查看付款记录的会员卡。也支持对会员卡按卡号、手机号和等级进行搜索。 2. 查看会员卡…...

LeetCode_贪心算法_困难_630.课程表 III
目录 1.题目2.思路3.代码实现(Java) 1.题目 这里有 n 门不同的在线课程,按从 1 到 n 编号。给你一个数组 courses ,其中 courses[i] [durationi, lastDayi] 表示第 i 门课将会持续上 durationi 天课,并且必须在不晚于…...

Drozer安装
Drozer安装包下载 https://labs.withsecure.com/tools/drozer Drozer需要的python包下载 pip install "pip<21.0" pyOpenSSL pip install "pip<21.0" service_identity pip install "pip<21.0" twisted pip install "pip<…...

752. 打开转盘锁
链接: 752. 打开转盘锁 题解: class Solution { public:int openLock(vector<string>& deadends, string target) {std::unordered_set<std::string> table(deadends.begin(), deadends.end());if (table.find("0000") ! t…...
Bearly:基于人工智能的AI写作文章生成工具
【产品介绍】 名称 Bearly 具体描述 Bearly是一个AI人工智能内容创作工具。你可以用Bearly来阅读、写作、创作,提高你的效率。包括使用Bearly来生成网页的摘要、标题、关键点,也可以用Bearly来生成创意内容、艺术图片、文案编辑等。帮助你克…...
)
28GHz毫米波滤波器设计实战:用SynMatrix快速搞定SIW带通滤波器(附完整参数)
28GHz毫米波滤波器设计实战:SynMatrix工具链的高效应用指南 在毫米波频段,滤波器设计一直是射频工程师面临的重大挑战之一。尤其是当工作频率上升到28GHz甚至更高时,传统设计方法往往陷入反复迭代的泥潭,耗费大量时间在仿真优化与…...

ClickHouse可视化工具大比拼:Tabix vs DBeaver,哪个更适合你?
ClickHouse可视化工具深度评测:Tabix与DBeaver的实战对比 当你面对ClickHouse海量数据时,一个得心应手的可视化工具能让你事半功倍。作为目前最流行的两款ClickHouse客户端,Tabix和DBeaver各有拥趸,但究竟哪款更适合你的工作场景…...
)
不花一分钱!用闲置电脑搭建永久Mac远程控制台(VNC+cpolar固定TCP教程)
零成本打造24小时在线的Mac远程开发环境 你是否有一台闲置的Mac电脑放在角落积灰?或者需要随时随地访问家里的开发环境?将旧Mac改造成全天候在线的远程工作站,不仅能充分利用闲置资源,还能为移动办公提供极大便利。本文将手把手教…...

告别单调闪烁!用GD32F303的TIMER高级功能玩转PWM:实现S形曲线呼吸灯与多灯同步效果
解锁GD32F303定时器高阶玩法:S形曲线PWM与多灯协同控制艺术 呼吸灯效果在嵌入式设备中早已司空见惯,但大多数实现仍停留在简单的线性渐变阶段。当LED亮度以恒定速率变化时,人眼会感知到明显的"机械感"——就像早期数字音乐缺少模拟…...

ARMv8-A架构革命——超越64位寻址的三大范式转移
该文章同步至公众号OneChan 开篇:回答上篇进阶思考 在上一篇的结尾,我们留下了三个问题,现在让我们逐一探讨: 1. 从A53到A55再到A510,ARM的小核设计哲学如何演变? Cortex-A53 (2014):定义了“…...

ViPER4Windows终极修复指南:让Windows音效神器重获新生
ViPER4Windows终极修复指南:让Windows音效神器重获新生 【免费下载链接】ViPER4Windows-Patcher Patches for fix ViPER4Windows issues on Windows-10/11. 项目地址: https://gitcode.com/gh_mirrors/vi/ViPER4Windows-Patcher 你是否曾为ViPER4Windows在Wi…...

深度学习框架YOLOV8模型如何训练水下生物检测数据集 构建基于YOLOv8➕pyqt5的水下生物检测系统 海胆‘, ‘海参‘, ‘扇贝‘, ‘海星‘, ‘水草
享基于YOLOv8➕pyqt5的水下生物检测系统内含7600张水下生物数据集 包括[‘海胆’, ‘海参’, ‘扇贝’, ‘海星’, ‘水草’],5类也可自行替换模型,使用该界面做其他检测 这是一个非常经典的计算机视觉应用项目,结合了深度学习的目标检测&…...

提升Python编码效率:ptpython语法高亮与自动补全的终极指南
提升Python编码效率:ptpython语法高亮与自动补全的终极指南 【免费下载链接】ptpython A better Python REPL 项目地址: https://gitcode.com/gh_mirrors/pt/ptpython ptpython是一款功能强大的Python REPL工具,它通过语法高亮、智能自动补全和丰…...

113. 强制使用 Letsencrypt ECDSA 和 DNS-01 续期挑战的默认 HTTPS Rancher 证书
Environment 环境 2.9 Situation 地理位置A self-signed default Rancher certificate is currently used and will be migrated to a stronger Let’s Encrypt ECDSA-386 certificate using the DNS-01 renewal challenge. 目前使用自签名默认的牧场证书,并将通过…...
Retinexformer Unleashed: A Deep Dive into Transformer-Based Low-Light Image Enhancement
1. Retinexformer:当Transformer遇见低光图像增强 深夜拍的照片总是又暗又糊?Retinexformer可能是目前最聪明的AI解决方案。这个将Transformer架构与Retinex理论结合的创新模型,在ICCV 2023上以6dB的性能优势碾压传统方法。我实测过它的增强效…...