Python--文件和异常
目录
1、读取文件
1.1 读取文件的全部内容
1.2 相对路径和绝对路径
1.3 访问文件中的各行
1.4 使用文件中的内容
1.5 包含100万位的大型文件
1.6 圆周率中的生日
2、写入文件
2.1 写入一行
2.2 写入多行
3、异常
3.1 处理ZeroDivisionError 异常
3.2 使用try-except代码块
3.3 使用异常避免崩溃
3.4 else代码块
3.5 处理FileNotFoundError异常
3.6 分析文本
3.7 使用多个文件
3.8 静默失败
3.9 决定报告哪些错误
3.10 count()求特定单词
4、存储系统
4.1 使用json.dumps() 和 json.loads()
4.2 保存和读取用户生成的数据
4.3 重构
1、读取文件
要使⽤⽂本⽂件中的信息,⾸先需要将信息读取到内存中。既可以⼀次性 读取⽂件的全部内容,也可以逐⾏读取。
1.1 读取文件的全部内容
要读取⽂件,需要⼀个包含若⼲⾏⽂本的⽂件。下⾯来创建⼀个⽂件,它 包含精确到⼩数点后 30 位的圆周率值,且在⼩数点后每 10 位处换⾏:
3.1415926535 8979323846 2643383279下⾯的程序打开并读取这个⽂件,再将其内容显⽰到屏幕上:
from pathlib import Path
❶ path = Path('pi_digits.txt')
❷ contents = path.read_text()print(contents)要使⽤⽂件的内容,需要将其路径告知 Python。路径(path)指的是⽂件或
⽂件夹在系统中的准确位置。Python 提供了 pathlib 模块,让你能够更轻
松地在各种操作系统中处理⽂件和⽬录。提供特定功能的模块通常称为库 (library)。这就是这个模块被命名为 pathlib 的原因所在。
这⾥⾸先从 pathlib 模块导⼊ Path 类。Path 对象指向⼀个⽂件,可⽤ 来做很多事情。例如,让你在使⽤⽂件前核实它是否存在,读取⽂件的内 容,以及将新数据写⼊⽂件。这⾥创建了⼀个表⽰⽂件 pi_digits.txt 的 Path 对象,并将其赋给了变量 path(⻅❶)。由于这个⽂件与当前编写 的 .py ⽂件位于同⼀个⽬录中,因此 Path 只需要知道其⽂件名就能访问 它。
创建表⽰⽂件 pi_digits.txt 的 Path 对象后,使⽤ read_text() ⽅法来读 取这个⽂件的全部内容(⻅❷)。read_text() 将该⽂件的全部内容作为 ⼀个字符串返回,⽽我们将这个字符串赋给了变量 contents。在打印 contents 的值时,将显⽰这个⽂本⽂件的全部内容:
3.1415926535 8979323846 2643383279 相⽐于原始⽂件,该输出唯⼀不同的地⽅是末尾多了⼀个空⾏。为何会多 出这个空⾏呢?因为 read_text() 在到达⽂件末尾时会返回⼀个空字符 串,⽽这个空字符串会被显⽰为⼀个空⾏。 要删除这个多出来的空⾏,可对字符串变量 contents 调⽤ rstrip():
from pathlib import Path
path = Path('pi_digits.txt')
contents = path.read_text()
contents = contents.rstrip()
print(contents)Python ⽅法 rstrip() 能删除字符串末尾的空⽩。现在,
输出与原始⽂件的内容完全⼀致了:
3.1415926535 8979323846 2643383279要在读取⽂件内容时删除末尾的换⾏符,可在调⽤ read_text() 后直接
调⽤⽅法 rstrip():
contents = path.read_text().rstrip()1.2 相对路径和绝对路径
当将类似于 pi_digits.txt 这样的简单⽂件名传递给 Path 时,Python 将在当 前执⾏的⽂件(即 .py 程序⽂件)所在的⽬录中查找。
根据你组织⽂件的⽅式,有时可能要打开不在程序⽂件所属⽬录中的⽂ 件。例如,你可能将程序⽂件存储在了⽂件夹 python_work 中,并且在⽂件 夹 python_work 中创建了⼀个名为 text_files 的⽂件夹,⽤于存储程序⽂件 要操作的⽂本⽂件。虽然⽂件夹 text_files 在⽂件夹 python_work 中,但仅 向 Path 传递⽂件夹 text_files 中的⽂件的名称也是不可⾏的,因为 Python 只在⽂件夹 python_work 中查找,⽽不会在其⼦⽂件夹 text_files 中查找。 要让 Python 打开不与程序⽂件位于同⼀个⽬录中的⽂件,需要提供正确的 路径。
在编程中,指定路径的⽅式有两种。⾸先,相对⽂件路径让 Python 到相对 于当前运⾏的程序所在⽬录的指定位置去查找。由于⽂件夹 text_files 位于 ⽂件夹 python_work 中,因此需要创建⼀个以 text_files 打头并以⽂件名结 尾的路径,如下所⽰:
path = Path('text_files/filename.txt')其次,可以将⽂件在计算机中的准确位置告诉 Python,这样就不⽤管当前 运⾏的程序存储在什么地⽅了。这称为绝对⽂件路径。在相对路径⾏不通 时,可使⽤绝对路径。假如 text_files 并不在⽂件夹 python_work 中,则仅 向 Path 传递路径 'text_files/filename.txt' 是⾏不通的,因为 Python 只在⽂件夹 python_work 中查找该位置。为了明确地指出希望 Python 到哪⾥去查找,需要提供绝对路径。
绝对路径通常⽐相对路径⻓,因为它们以系统的根⽂件夹为起点:
path = Path('/home/eric/data_files/text_files/filename.txt')使⽤绝对路径,可读取系统中任何地⽅的⽂件。就⽬前⽽⾔,最简单的做 法是,要么将数据⽂件存储在程序⽂件所在的⽬录中,要么将其存储在程 序⽂件所在⽬录下的⼀个⽂件夹(如 text_files)中。
注意:在显⽰⽂件路径时,Windows 系统使⽤反斜杠(\)⽽不是斜杠 (/)。但是你在代码中应该始终使⽤斜杠,即便在 Windows 系统中
也是如此。在与你或其他⽤户的系统交互时,pathlib 库会⾃动使⽤
正确的路径表⽰⽅法。
1.3 访问文件中的各行
你可以使⽤ splitlines() ⽅法将冗⻓的字符串转换为⼀系列⾏,再使⽤ for 循环以每次⼀⾏的⽅式检查⽂件中的各⾏:
from pathlib import Pathpath = Path('pi_digits.txt')
❶ contents = path.read_text()
❷ lines = contents.splitlines()for line in lines:print(line)1.4 使用文件中的内容
将⽂件的内容读取到内存中后,就能以任意⽅式使⽤这些数据了。
from pathlib import Pathpath = Path('pi_digits.txt')contents = path.read_text()lines = contents.splitlines()pi_string = ''
❶ for line in lines:pi_string += lineprint(pi_string)print(len(pi_string))变量 pi_string 存储的字符串包含原来位于每⾏左端的空格。要删除这 些空格,可对每⾏调⽤ lstrip():
--snip--
for line in lines:
pi_string += line.lstrip()
print(pi_string)
print(len(pi_string))注意:在读取⽂本⽂件时,Python 将其中的所有⽂本都解释为字符 串。如果读取的是数,并且要将其作为数值使⽤,就必须使⽤ int() 函数将其转换为整数,或者使⽤ float() 函数将其转换为浮点数。
1.5 包含100万位的大型文件
如果⼀个⽂本⽂件包含精确到⼩数点后 1 000 000 位⽽不是 30 位的圆周率值,也可以创建⼀个包含所有这些数字的字符串。⽆须对前⾯的程序做任何修改,只需将这个⽂件传递给它即可。在这⾥, 只打印到⼩数点后 50 位,以免终端花太多时间滚动显⽰全部的 1 000 000 位数字:
from pathlib import Path
path = Path('pi_million_digits.txt')
contents = path.read_text()
lines = contents.splitlines()
pi_string = ''
for line in lines:pi_string += line.lstrip()
print(f"{pi_string[:52]}...")
print(len(pi_string))输出表明,创建的字符串确实包含精确到⼩数点后 1 000 000 位的圆周率
值:
3.14159265358979323846264338327950288419716939937510...
1000002 在可处理的数据量⽅⾯,Python 没有任何限制。只要系统的内存⾜够⼤, 你想处理多少数据就可以处理多少数据。
1.6 圆周率中的生日
我⼀直想知道⾃⼰的⽣⽇是否包含在圆周率值中。下⾯来扩展刚才编写的 程序,以确定某个⼈的⽣⽇是否包含在圆周率值的前 1 000 000 位中。。为此,可先将⽣⽇表⽰为⼀个由数字组成的字符串,再检查这个字符串是否 在 pi_string 中:
--snip--
for line in lines: pi_string += line.strip()
birthday = input("Enter your birthday, in the form mmddyy: ")
if birthday in pi_string:
print("Your birthday appears in the first million digits of pi!")
else:
print("Your birthday does not appear in the first million digits of
pi.") ⾸先提⽰⽤户输⼊其⽣⽇,再检查这个字符串是否在 pi_string 中。运 ⾏这个程序:
Enter your birthdate, in the form mmddyy: 120372
Your birthday appears in the first million digits of pi! 我的⽣⽇确实出现在了圆周率值中!读取⽂件的内 容后,就能以任意⽅式
对其进⾏分析了
2、写入文件
保存数据的最简单的⽅式之⼀是将其写⼊⽂件。
2.1 写入一行
定义⼀个⽂件的路径后,就可使⽤ write_text() 将数据写⼊该⽂件了。
from pathlib import Path
path = Path('programming.txt')
path.write_text("I love programming.")write_text() ⽅法接受单个实参,即要写⼊⽂件的字符串。
注意:Python 只能将字符串写⼊⽂本⽂件。如果要将数值数据存储到
⽂本⽂件中,必须先使⽤函数 str() 将其转换为字符串格式。
2.2 写入多行
write_text() ⽅法会在幕后完成⼏项⼯作。⾸先,如果 path 变量对应 的路径指向的⽂件不存在,就创建它。其次,将字符串写⼊⽂件后,它会 确保⽂件得以妥善地关闭。
要将多⾏写⼊⽂件,需要先创建⼀个字符串(其中包含要写⼊⽂件的全部 内容),再调⽤ write_text() 并将这个字符串传递给它。
下⾯将多⾏内 容写⼊⽂件 programming.txt:
from pathlib import Path
contents = "I love programming.\n"
contents += "I love creating new games.\n"
contents += "I also love working with data.\n"
path = Path('programming.txt')
path.write_text(contents)⾸先定义变量 contents,⽤于存储要写⼊⽂件的所有内容。
注意:在对 path 对象调⽤ write_text() ⽅法时,务必谨慎。如果 指定的⽂件已存在, write_text() 将删除其内容,并将指定的内容写⼊其中。
3、异常
Python 使⽤称为异常(exception)的特殊对象来管理程序执⾏期间发⽣的 错误。每当发⽣让 Python 不知所措的错误时,它都会创建⼀个异常对象。
- 如果你编写了处理该异常的代码,程序将继续运⾏;
- 如果你未对异常进⾏ 理,程序将停⽌,并显⽰⼀个 traceback,其中包含有关异常的报告。
异常是使⽤ try-except 代码块处理的。
3.1 处理ZeroDivisionError 异常
下⾯来看⼀种导致 Python 引发异常的简单错误。
print(5/0)Python ⽆法这样做,因此你将看到⼀个 traceback:
Traceback (most recent call last):File "division_calculator.py", line 1, in <module>print(5/0)~^~
❶ ZeroDivisionError: division by zero在上述 traceback 中,错误 ZeroDivisionError 是个异常对象(⻅ ❶)。Python 在⽆法按你的要求做时,就会创建这种对象。在这种情况 下,Python 将停⽌运⾏程序,并指出引发了哪种异常,⽽我们可根据这些 信息对程序进⾏修改。
3.2 使用try-except代码块
当你认为可能发⽣错误时,可编写⼀个 try-except 代码块来处理可能引 发的异常。
try:print(5/0)
except ZeroDivisionError:print("You can't divide by zero!")3.3 使用异常避免崩溃
如果在错误发⽣时,程序还有⼯作没有完成,妥善地处理错误就显得尤其 重要。
print("Give me two numbers, and I'll divide them.")print("Enter 'q' to quit.")while True:first_number = input("\nFirst number: ")if first_number == 'q':breaksecond_number = input("Second number: ")if second_number == 'q':breakanswer = int(first_number) / int(second_number)print(answer)这个 程序没有采取任何处理错误的措施,因此在执⾏除数为 0 的除法运算时,
它将崩溃:
Give me two numbers, and I'll divide them.
Enter 'q' to quit.
First number: 5
Second number: 0
Traceback (most recent call last): File "division_calculator.py", line 11, in <module> answer = int(first_number) / int(second_number) ~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~
ZeroDivisionError: division by zero程序崩溃可不好,让⽤户看到 traceback 也不是个好主意。不懂技术的⽤户 会感到糊涂,怀有恶意的⽤户还能通过 traceback 获悉你不想让他们知道的 信息。
3.4 else代码块
通过将可能引发错误的代码放在 try-except 代码块中,可提⾼程序抵御 错误的能⼒。这个⽰例还包含⼀个 else 代码块,只有 try 代码块成功执⾏才需要继续执⾏的代码,都应放到 else 代码块中:
--snip-- while True:
--snip-- if second_number == 'q': break
❶try: answer = int(first_number) / int(second_number)
❷except ZeroDivisionError:
print("You can't divide by 0!")
❸else: print(answer)3.5 处理FileNotFoundError异常
在使⽤⽂件时,⼀种常⻅的问题是找不到⽂件:要查找的⽂件可能在其他 地⽅,⽂件名可能不正确,或者这个⽂件根本就不存在。
我们来尝试读取⼀个不存在的⽂件。下⾯的程序尝试读取⽂件 alice.txt 的内
容,但这个⽂件并没有被存储在 alice.py 所在的⽬录中:
from pathlib import Path
path = Path('alice.txt')
contents = path.read_text(encoding='utf-8')请注意,这⾥使⽤ read_text() 的⽅式与前⾯稍有不同。如果系统的默 认编码与要读取的⽂件的编码不⼀致,参数 encoding 必不可少。如果要 读取的⽂件不是在你的系统中创建的,这种情况更容易发⽣。
Python ⽆法读取不存在的⽂件,因此引发了⼀个异常:
Traceback (most recent call last):
❶ File "alice.py", line 4, in <module>
❷ contents = path.read_text(encoding='utf-8') ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/.../pathlib.py", line 1056, in read_text with self.open(mode='r', encoding=encoding, errors=errors) as f: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/.../pathlib.py", line 1042, in open return io.open(self, mode, buffering, encoding, errors, newline) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ❸ FileNotFoundError: [Errno 2] No such file or directory: 'alice.txt'
这⾥的 traceback ⽐前⾯的那些都⻓,因此下⾯介绍如何看懂复杂的 traceback。
通常最好从 traceback 的末尾着⼿。
从最后⼀⾏可知,引发了异 常 FileNotFoundError(⻅❸)。这⼀点很重要,它让我们知道应该在 要编写的 except 代码块中使⽤哪种异常。
回头看看 traceback 开头附近(⻅❶),从这⾥可知,错误发⽣在⽂件 alice.py 的第四⾏。接下来的⼀⾏列出了导致错误的代码⾏(⻅❷)。 traceback 的其余部分列出了⼀些代码,它们来⾃打开和读取⽂件涉及的 库。通常,不需要详细阅读和理解 traceback 中的这些内容。
为了处理这个异常,应将 traceback 指出的存在问题的代码⾏放到 try 代码
块中。这⾥,存在问题的是包含 read_text() 的代码⾏:
from pathlib import Pathpath = Path('alice.txt')try:contents = path.read_text(encoding='utf-8')
❶ except FileNotFoundError:print(f"Sorry, the file {path} does not exist.")这样,当找不 到⽂件时,Python 将运⾏ except 代码块中的代码,从⽽显⽰⼀条友好的
错误消息,⽽不是 traceback:
Sorry, the file alice.txt does not exist.3.6 分析文本
你可以分析包含整本书的⽂本⽂件。
下⾯来提取童话 Alice in Wonderland(《爱丽丝漫游奇境记》)的⽂本,并 尝试计算它包含多少个单词。我们将使⽤ split() ⽅法,它默认以空⽩为 分隔符将字符串分拆成多个部分:
from pathlib import Path
path = Path('alice.txt')
try:contents = path.read_text(encoding='utf-8')
except FileNotFoundError:print(f"Sorry, the file {path} does not exist.")
else:
#计算⽂件⼤致包含多少个单词
❶ words = contents.split()
❷ num_words = len(words)
print(f"The file {path} has about {num_words} words.")我将⽂件 alice.txt 移到了正确的⽬录中,让 try 代码块能够成功地执⾏。 对变量 contents(它现在是⼀个⻓⻓的字符串,包含童话 Alice in Wonderland 的全部⽂本)调⽤ split() ⽅法,⽣成⼀个列表,其中包含这 部童话中的所有单词(⻅❶)。
3.7 使用多个文件
下⾯多分析⼏本书。先将这个程序的⼤部分代码移到⼀个名为 count_words() 的函数中,这样对多本书进⾏分析会更容易:
from pathlib import Pathdef count_words(path):
❶ """计算⼀个⽂件⼤致包含多少个单词"""try:contents = path.read_text(encoding='utf-8')except FileNotFoundError:print(f"Sorry, the file {path} does not exist.")else:# 计算⽂件⼤致包含多少个单词words = contents.split()num_words = len(words)print(f"The file {path} has about {num_words} words.")path = Path('alice.txt')count_words(path)这些代码⼤多与原来⼀样,只是被移到了函数 count_words() 中,并且 增加了缩进量。
为此,我们把要分析的⽂件的名称存储在⼀个列表中,然后对列表中 的每个⽂件都调⽤ count_words()。
from pathlib import Pathdef count_words(filename):--snip--filenames = ['alice.txt', 'siddhartha.txt', 'moby_dick.txt', 'little_women.txt']for filename in filenames:
❶ path = Path(filename)count_words(path)3.8 静默失败
我们告诉⽤户有⼀个⽂件找不到。但并⾮每次捕获异常 都需要告诉⽤户,你有时候希望程序在发⽣异常时保持静默,就像什么都 没有发⽣⼀样继续运⾏。要让程序静默失败,可像通常那样编写 try 代码 块,但在 except 代码块中明确地告诉 Python 什么都不要做。Python 有⼀ 个 pass 语句,可在代码块中使⽤它来让 Python 什么都不做:
def count_words(path):"""计算⼀个⽂件⼤致包含多少个单词"""try:--snip--except FileNotFoundError:passelse:--snip--现在,当出现 FileNotFoundError 异常时,虽然仍将执⾏except 代码块中的代码,但什么都不会发⽣。
3.9 决定报告哪些错误
如果⽤ 户知道要分析哪些⽂件,他们可能希望在有⽂件未被分析时出现⼀条消息
来告知原因。
如果⽤户只想看到结果,并不知道要分析哪些⽂件,可能就 ⽆须在有些⽂件不存在时告知他们。
3.10 count()求特定单词
可以使⽤⽅法 count() 来确定特定的单词或短语在字符串中出现了多
少次。例如,下⾯的代码计算 'row' 在⼀个字符串中出现了多少次:
>>> line = "Row, row, row your boat"
>>> line.count('row')
2
>>> line.lower().count('row')
3 请注意,通过使⽤ lower() 将字符串转换为全⼩写的,可捕捉要查找 的单词的各种格式,⽽不管其⼤⼩写如何。
4、存储系统
很多程序要求⽤户输⼊某种信息,⽐如让⽤户存储游戏⾸选项或提供要可 视化的数据。当⽤户关闭程序时,⼏乎总是要保存他们提供的信 息。⼀种简单的⽅式是使⽤模块 json 来存储数据。
模块 json 让你能够将简单的 Python 数据结构转换为 JSON 格式的字符 串,并在程序再次运⾏时从⽂件中加载数据。你还可以使⽤ json 在 Python 程序之间共享数据。
注意:JSON(JavaScript Object Notation)格式最初是为 JavaScript 开发 的,但随后成了⼀种通⽤的格式,被包括 Python 在内的众多语⾔采 ⽤。
4.1 使用json.dumps() 和 json.loads()
下⾯先编写⼀个存储⼀组数的简短程序,再编写⼀个将这些数读取到内存 中的程序。第⼀个程序将使⽤ json.dumps() 来存储这组数,⽽第⼆个程 序将使⽤ json.loads() 来读取它们。
json.dumps() 函数接受⼀个实参,即要转换为 JSON 格式的数据。这个 函数返回⼀个字符串,这样你就可将其写⼊数据⽂件了:
from pathlib import Pathimport jsonnumbers = [2, 3, 5, 7, 11, 13]
❶ path = Path('numbers.json')
❷ contents = json.dumps(numbers)path.write_text(contents)下⾯再编写⼀个程序,使⽤ json.loads() 将这个列表读取到内存中:
from pathlib import Pathimport json
❶ path = Path('numbers.json')
❷ contents = path.read_text()
❸ numbers = json.loads(contents)print(numbers)在❶处,确保读取的是前⾯写⼊的⽂件。这个数据⽂件是使⽤特殊格式的 ⽂本⽂件,因此可使⽤ read_text() ⽅法来读取它(⻅❷)。然后将这 个⽂件的内容传递给 json.loads()(⻅❸)。这个函数将⼀个 JSON 格 式的字符串作为参数,并返回⼀个 Python 对象(这⾥是⼀个列表),⽽我 们将这个对象赋给了变量 numbers。最后,打印恢复的数值列表,看看是 否与 number_writer.py 中创建的数值列表相同:
[2, 3, 5, 7, 11, 13] 这是⼀种在程序之间共享数据的简单⽅式。
4.2 保存和读取用户生成的数据
使⽤ json 保存⽤户⽣成的数据很有必要,因为如果不以某种⽅式进⾏存 储,⽤户的信息就会在程序停⽌运⾏时丢失。
下⾯来看⼀个这样的例⼦:
提⽰⽤户在⾸次运⾏程序时输⼊⾃⼰的名字,并且在他再次运⾏程序时仍
然记得他。
先来存储⽤户的名字:
from pathlib import Path import json
❶ username = input("What is your name? ")
❷ path = Path('username.json') contents = json.dumps(username) path.write_text(contents)
❸ print(f"We'll remember you when you come back, {username}!")⾸先,提⽰⽤户输⼊名字(⻅❶)。接下来,将收集到的数据写⼊⽂件 username.json(⻅❷)。然后,打印⼀条消息,指出存储了⽤户输⼊的信息 (⻅❸):
What is your name? Eric
We'll remember you when you come back, Eric! 现在再编写⼀个程序,向名字已被存储的⽤户发出问候:
greet_user.py
from pathlib import Path import json
❶ path = Path('username.json') contents = path.read_text()
❷ username = json.loads(contents)
print(f"Welcome back, {username}!")我们读取数据⽂件的内容(⻅❶),并使⽤json.loads() 将恢复的数据 赋给变量 username(⻅❷)。有了已恢复的⽤户名,就可以使⽤个性化 的问候语欢迎⽤户回来了:
Welcome back, Eric!需要将这两个程序合并到⼀个程序(remember_me.py)中。在这个程序运 ⾏时,将尝试从内存中获取⽤户的⽤户名。如果没有找到,就提⽰⽤户输 ⼊⽤户名,并将其存储到⽂件 username.json 中,以供下次使⽤。
from pathlib import Pathimport jsonpath = Path('username.json')
❶ if path.exists():contents = path.read_text()username = json.loads(contents)print(f"Welcome back, {username}!")
❷ else:username = input("What is your name? ")contents = json.dumps(username)path.write_text(contents)print(f"We'll remember you when you come back, {username}!")4.3 重构
你经常会遇到这样的情况:虽然代码能够正确地运⾏,但还可以将其划分 为⼀系列完成具体⼯作的函数来进⾏改进。这样的过程称为重构。
要重构 remember_me.py,可将其⼤部分逻辑放到⼀个或多个函数中。
remember_me.py 的重点是问候⽤户,因此将其所有代码都放到⼀个名为
greet_user() 的函数中:
from pathlib import Path import json
def greet_user():
❶"""问候⽤户,并指出其名字""" path = Path('username.json') if path.exists(): contents = path.read_text() username = json.loads(contents) print(f"Welcome back, {username}!") else: username = input("What is your name? ") contents = json.dumps(username) path.write_text(contents) print(f"We'll remember you when you come back, {username}!")
greet_user()下⾯重构 greet_user(),不让它执⾏这么多任务。⾸先将获取已存储⽤
户名的代码移到另⼀个函数中:
from pathlib import Path
import jsondef get_stored_username(path):
❶"""如果存储了⽤户名,就获取它""" if path.exists(): contents = path.read_text() username = json.loads(contents)
return username
else:
❷return None def greet_user(): """问候⽤户,并指出其名字""" path = Path('username.json')
username = get_stored_username(path)
❸if username: print(f"Welcome back, {username}!") else: username = input("What is your name? ") contents = json.dumps(username) path.write_text(contents) print(f"We'll remember you when you come back, {username}!") greet_user() 新增的 get_stored_username() 函数⽬标明确,⽂档字符串(⻅❶) 指出了这⼀点。
还需要将 greet_user() 中的另⼀个代码块提取出来,将在没有存储⽤户名时提⽰⽤户输⼊的代码放在⼀个独⽴的函数中:
from pathlib import Pathimport jsondef get_stored_username(path):"""如果存储了⽤户名,就获取它"""--snip--def get_new_username(path):"""提⽰⽤户输⼊⽤户名"""username = input("What is your name? ")contents = json.dumps(username)path.write_text(contents)return usernamedef greet_user():"""问候⽤户,并指出其名字"""path = Path('username.json')
❶ username = get_stored_username(path)if username:print(f"Welcome back, {username}!")else:
❷ username = get_new_username(path)print(f"We'll remember you when you come back, {username}!")greet_user()在 remember_me.py 的这个最终版本中,每个函数都执⾏单⼀⽽清晰的任 务。我们调⽤ greet_user(),它打印⼀条合适的消息:要么欢迎⽼⽤户 回来,要么问候新⽤户。
相关文章:

Python--文件和异常
目录 1、读取文件 1.1 读取文件的全部内容 1.2 相对路径和绝对路径 1.3 访问文件中的各行 1.4 使用文件中的内容 1.5 包含100万位的大型文件 1.6 圆周率中的生日 2、写入文件 2.1 写入一行 2.2 写入多行 3、异常 3.1 处理ZeroDivisionError 异常 3.2 使用try-exce…...

IDEFICS 简介: 最先进视觉语言模型的开源复现
我们很高兴发布 IDEFICS ( Image-aware Decoder Enhanced la Flamingo with Ininterleaved Cross-attention S ) 这一开放视觉语言模型。IDEFICS 基于 Flamingo,Flamingo 作为最先进的视觉语言模型,最初由 DeepMind 开发,但目前尚未公开发布…...

玩转Mysql系列 - 第20篇:异常捕获及处理详解
这是Mysql系列第20篇。 环境:mysql5.7.25,cmd命令中进行演示。 代码中被[]包含的表示可选,|符号分开的表示可选其一。 需求背景 我们在写存储过程的时候,可能会出现下列一些情况: 插入的数据违反唯一约束ÿ…...

一些工具类
1、字符串处理工具类 1.1、StrUtils package com.study.java8.util;/*** Classname:StrUtils* Description:字符串工具类* Date:2023/9/9 9:37* Author:jsz15*/import org.apache.commons.lang.text.StrBuilder; import org.apa…...

20230916后台面经整理
1.面对抢优惠券这样的高负载场景,你从架构、负载均衡等方面说一下你的设计? 答了参考Nginx进行负载均衡,然后在每台服务器怎么怎么弄(架构每一层怎么设计) 参考https://toutiao.io/posts/6z3uu2m/preview,h…...
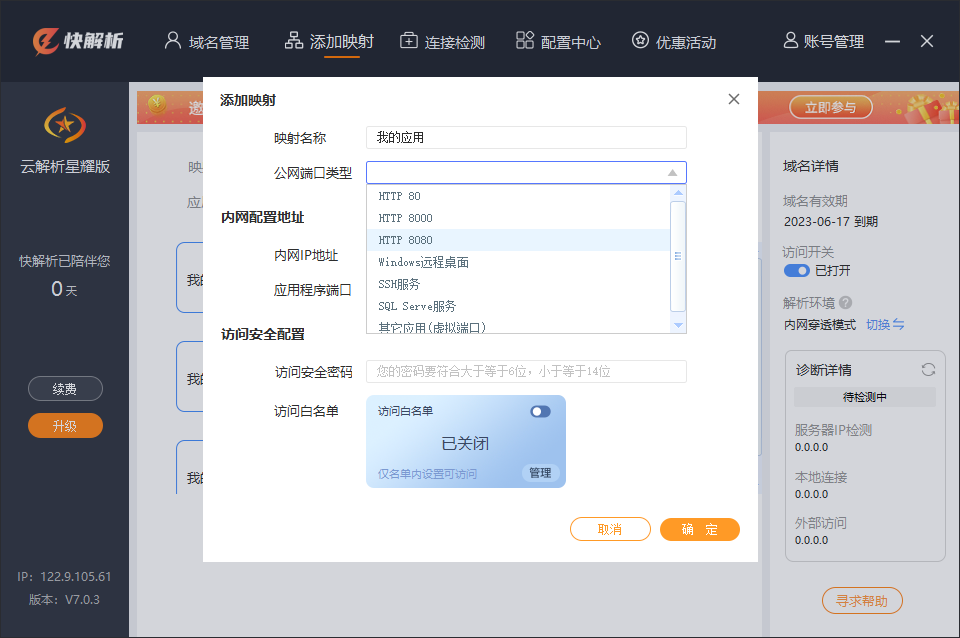
如何通过快解析测试接口内外网?本地内网ip让外网访问连接
接口调试测试是网络技术员经常工作内容之一。如在公司内部api项目webserver测试,在公司内办公室个人电脑是正常用内网IP访问连接测试的,但在外网电脑需要远程测试时需要怎么测试呢?这里提供一种内网地址让外网访问的通用方法:快解…...
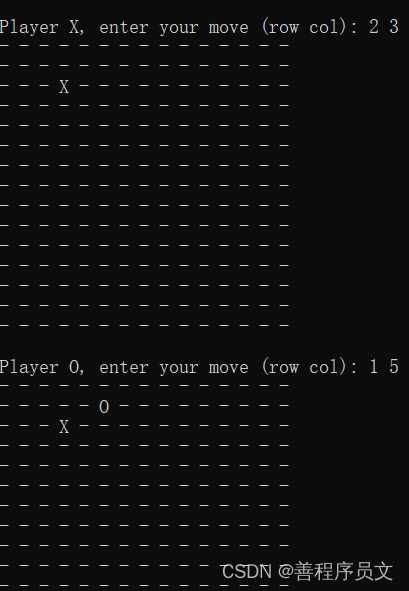
用c++实现五子棋小游戏
五子棋是一款经典小游戏,今天我们就用c实现简单的五子棋小游戏 目录 用到的算法: 思路分析 定义变量 开始写代码 完整代码 结果图: 用到的算法: 合法移动的判断:isValidMove 函数通过检查指定位置是否在棋盘范…...
Android 12.0 SystemUI下拉状态栏定制化之隐藏下拉通知栏布局功能实现(二)
1.前言 在12.0的系统定制化开发中,由于从12.0开始SystemUI下拉状态栏和11.0的变化比较大,所以可以说需要从新分析相关的SystemUI的 布局,然后做分析来实现不同的功能,今天就开始实现关于隐藏SystemUI下拉状态栏中的通知栏布局系列二,去掉下拉状态栏中 通知栏部分 白色的…...
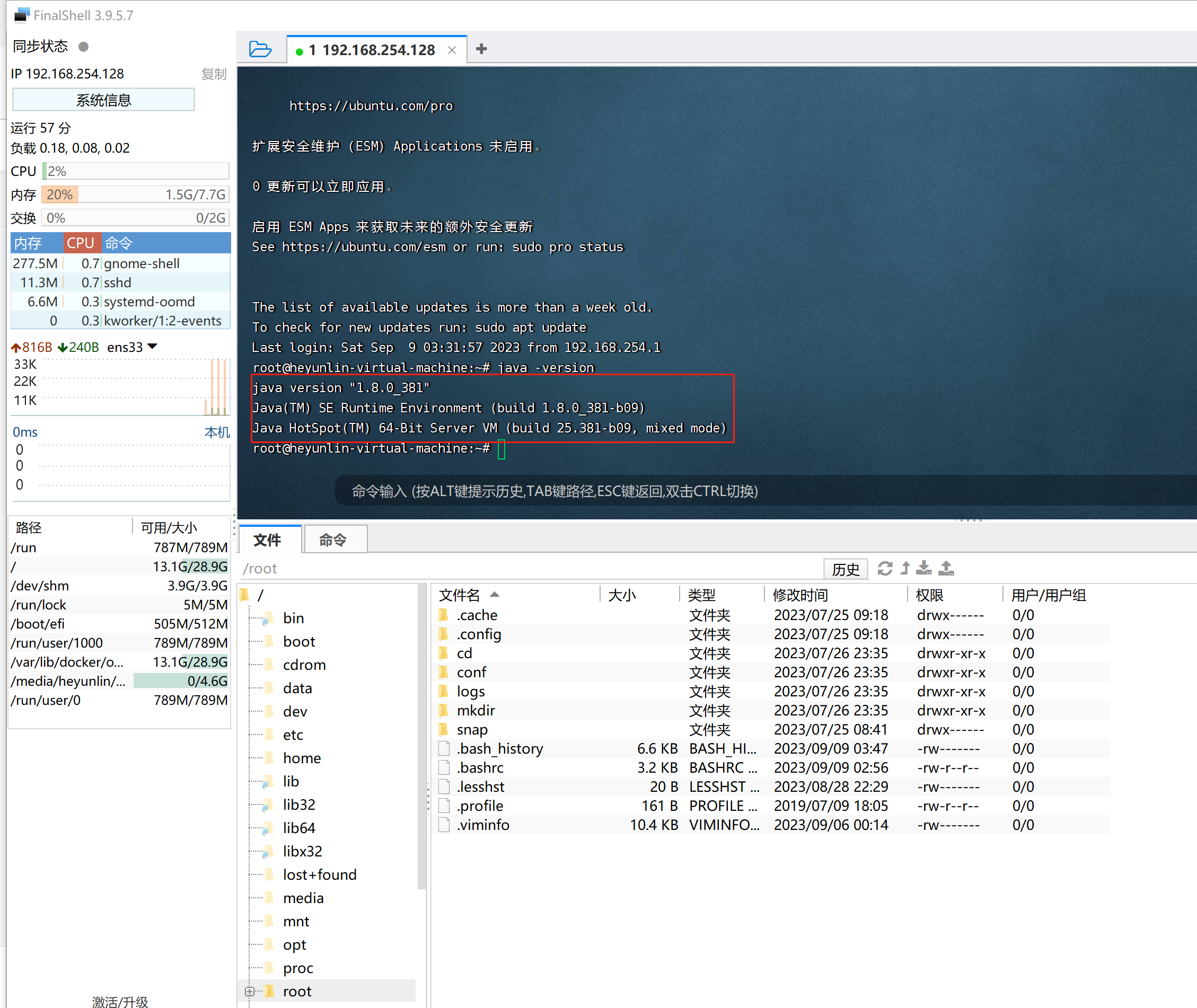
通过finalshell快速在ubuntu上安装jdk1.8
这篇文章主要介绍一下怎么通过finalshell连接ubuntu,然后在ubuntu上安装jdk1.8,让不熟悉linux操作系统的童鞋也能快速地完成安装。 目录 一、准备一台虚拟机 二、安装finalshell远程连接工具 三、获取ubuntu虚拟机的ip地址 四、通过finalshell连接u…...
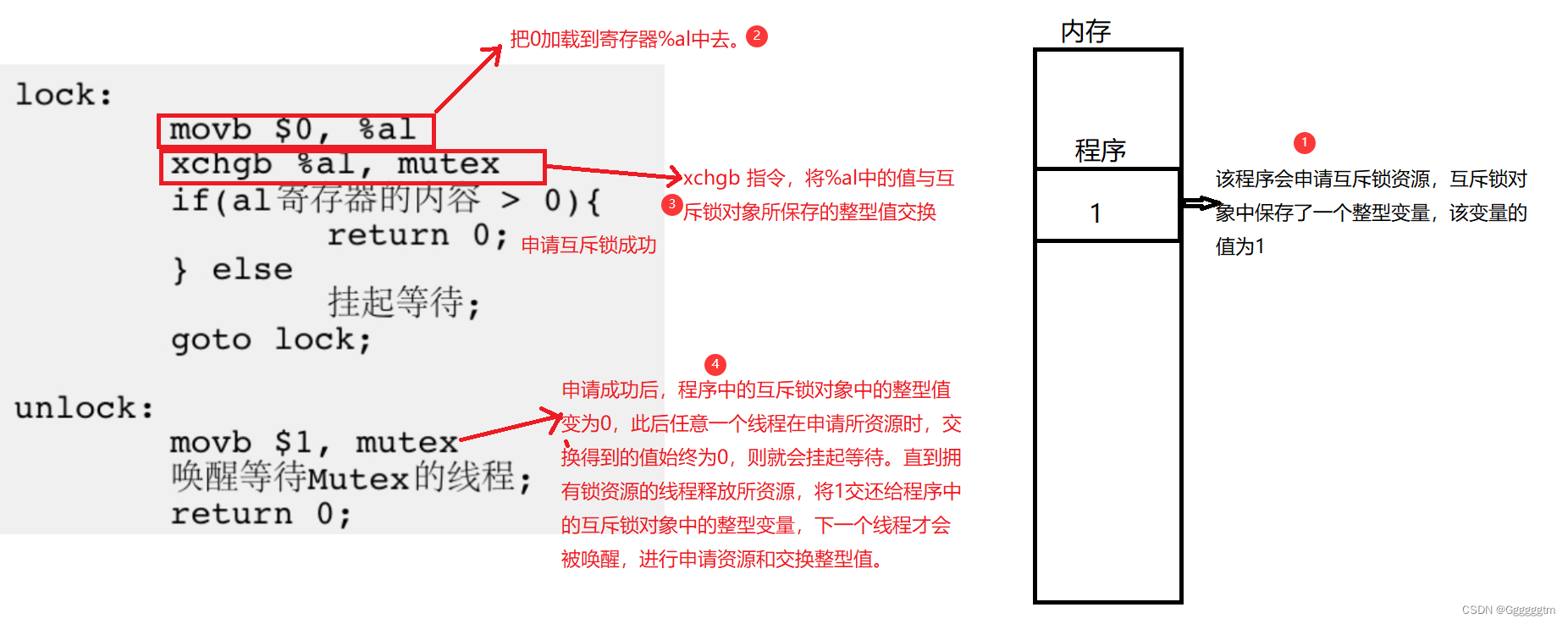
【Linux从入门到精通】多线程 | 线程互斥(互斥锁)
上篇文章我们对线程 | 线程介绍&线程控制介绍后,本篇文章将会对多线程中的线程互斥与互斥锁的概念进行详解。同时结合实际例子解释了可重入与不被重入函数、临界资源与临界区和原子性的概念。希望本篇文章会对你有所帮助。 文章目录 引入 一、重入与临界 1、1 可…...
Echarts 散点图的详细配置过程
文章目录 散点图 简介配置步骤简易示例 散点图 简介 Echarts散点图是一种常用的数据可视化图表类型,用于展示两个或多个维度的数据分布情况。散点图通过在坐标系中绘制数据点的位置来表示数据的关系。 Echarts散点图的特点如下: 二维数据展示ÿ…...
Nginx详解 五:反向代理
文章目录 1. 正向代理和反向代理1.1 正向代理概述1.1.1 什么是正向代理1.1.2 正向代理的作用1.1.3 正向代理的基本格式 1.2 反向代理概述1.2.1 什么是反向代理1.2.2 反向代理可实现的功能1.2.3 反向代理的可用模块 2. 配置反向代理2.1 反向代理配置参数2.1.1 proxy_pass2.1.2 其…...

【PDF密码】PDF文件打开之后不能打印,怎么解决?
正常的PDF文件是可以打印的,如果PDF文件打开之后发现文件不能打印,我们需要先查看一下自己的打印机是否能够正常运行,如果打印机是正常的,我们再查看一下,文件中的打印功能按钮是否是灰色的状态。 如果PDF中的大多数功…...
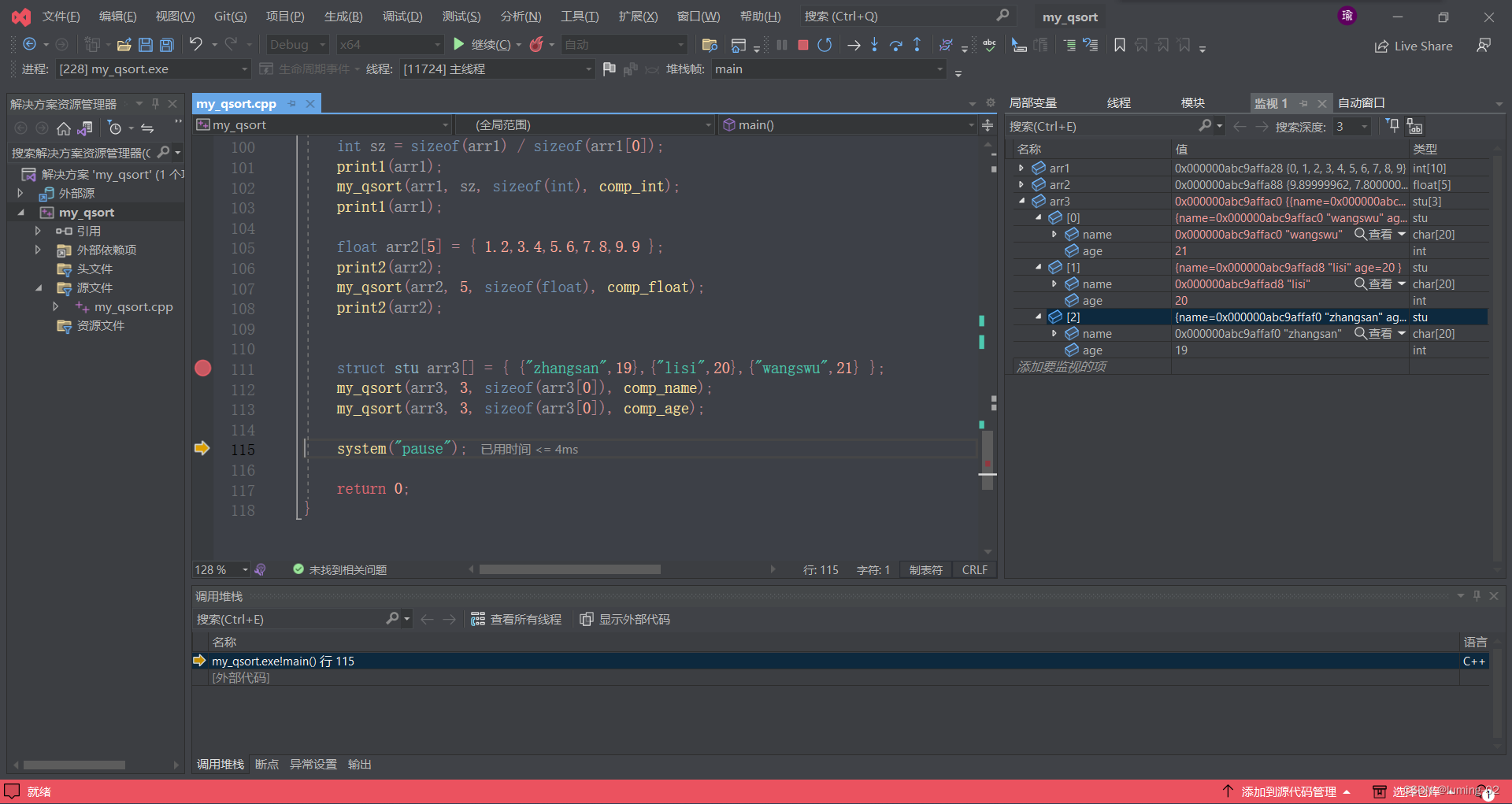
深入解析 qsort 函数(下),用冒泡排序模拟实现 qsort 函数
前言:对于库函数有适当了解的朋友们,对于 qsort 函数想必是有认知的,因为他可以对任意数据类型进行排序的功能属实是有点厉害的,本次分享,笔者就给大家带来 qsort 函数的全面的解读 本次知识的分享笔者分为上下俩卷文章…...

Azure + React + ASP.NET Core 项目笔记一:项目环境搭建(二)
有意义的标题 pnpm 安装umi4 脚手架搭建打包语句变更Visual Studio调试Azure 设置变更发布 pnpm 安装 参考官网,或者直接使用npm安装 npm install -g pnpmumi4 脚手架搭建 我这里用的umi4,官网已附上 这里需要把clientapp清空,之后 cd Cl…...

Vmware通过VMware tools设置共享文件夹
步骤说明: 先安装VMware tools,再设置共享文件夹即可。 写在前面: 刚安装虚拟机时,窗口可能显得太小,这是窗口分辨率没有调整导致的。 点击设置->显示->分辨率调整即可 一、安装VMware tools 1.1 点击虚拟机…...
)
RPA机器人流程自动化专题培训大纲 (针对大学生的版本)
一、课程简介 RPA机器人流程自动化是一种新兴的技术,它通过软件机器人模拟人类操作计算机完成重复性任务,从而实现业务流程的自动化。本课程旨在介绍RPA机器人流程自动化的基本概念、原理和应用,并通过实践案例演示如何应用RPA机器人流程自动…...

数据在内存中的存储——练习4
题目: int main() {char a[1000];int i;for(i0; i<1000; i){a[i] -1-i;}printf("%d",strlen(a));return 0; }思路分析: 已知条件: 通过循环遍历,我们得到的结果是 -1、-2、-3、-4等等。这些是数组内部的存储的元…...

Python 06 之面向对象基础
😀前言 在日常编程和软件开发中,我们通常会遇到各种各样的问题,其中很多问题都可以通过面向对象的程序设计方法来解决。面向对象编程不仅可以使代码更加组织化和系统化,而且还可以提高代码的重用性和可维护性。 . 在本教程中&…...
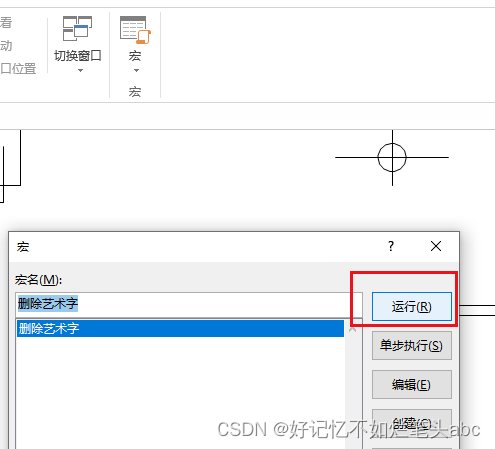
去除pdf/word的水印艺术字
对于pdf中的水印如果无法去除水印,则先另存为word,然后再按下面办法处理即可: 查看宏,创建:删除艺术字 添加内容: Sub 删除艺术字()Dim sh As ShapeFor Each sh In ActiveDocument.ShapesIf sh.Type msoT…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...