【Spatial-Temporal Action Localization(二)】论文阅读2017年
文章目录
- 1. ActionVLAD: Learning spatio-temporal aggregation for action classification [code](https://github.com/rohitgirdhar/ActionVLAD/)[](https://github.com/rohitgirdhar/ActionVLAD/)
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- 思考不足之处
- 2. Action Tubelet Detector for Spatio-Temporal Action Localization [code](https://github.com/qinzhi-0110/pytorch-act-detector)
- 术语前置
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- 思考不足之处
- 3. Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
- 4. Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos [code](https://github.com/kirilllzaitsev/Action_detection/blob/master/action_detection/model.py)
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- Tube of interest pooling
- Tube Proposal Network
- Linking Tube Proposals
1. ActionVLAD: Learning spatio-temporal aggregation for action classification code
摘要和结论
- 动作分类、在整个entire视频时空范围内 聚合局部卷积特征
- 结合双流网络和可学习的时空特征聚合、端到端
- 跨空间和时间汇集并组合来自不同流的信号。 pooling across space and time and combining signals from the different streams.
- (i)跨空间和时间联合池化很重要,但是(ii)外观和运动流最好聚合成它们自己单独的表示。 (i) it is important to pool jointly across space and time, but (ii) appearance and motion streams are best aggregated into their own separate representations.
引言:针对痛点和贡献
痛点:
- 对3D卷积和双流网络都进行了剖析: 视频建模合适的时空表示是什么? 3D 时空卷积,它可能学习复杂的时空依赖性,但迄今为止在识别性能方面很难扩展; 双流架构,将视频分解为运动流和外观流,并为每个流训练单独的 CNN,最终融合输出。虽然这两种方法都取得了快速进展,但双流架构通常优于时空卷积,因为它们可以轻松利用新的超深架构和针对静态图像分类进行预训练的模型。然而,双流架构在很大程度上忽视了视频的长期时间结构,本质上是学习一个对单个帧或少数(最多 10)帧的短块进行操作的分类器 ,可能会强制不同的分类分数达成共识。
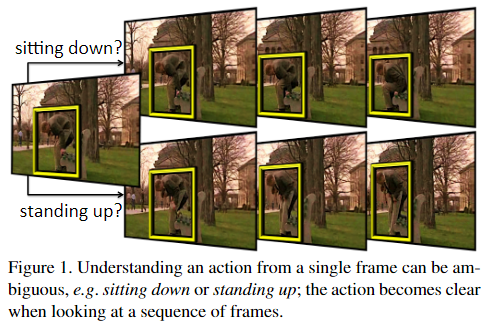
- 帧的独立分类再融合不能准确的对动作进行建模:时间平均是否能够模拟人类行为的复杂时空结构。当相同的子动作在多个动作类之间共享时,这个问题会更加严重。例如,考虑图 1 中所示的“篮球投篮”的复杂复合动作。仅给出几个连续的视频帧,它很容易与其他动作混淆,例如“跑步”、“运球”、“跳跃”和‘扔’。
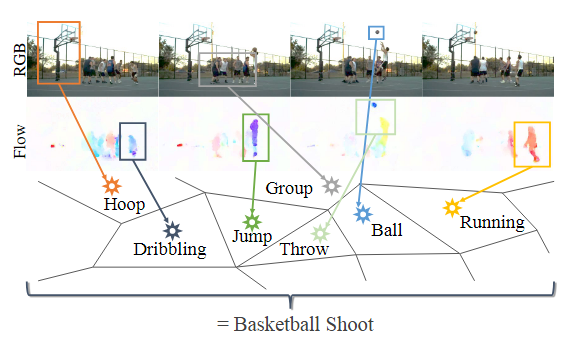
贡献:
- ActionVLAD CNN 层,这可能有助于相关任务,例如长视频中人类行为的(时空)时间定位
- (1)我们通过将可训练的时空聚合与最先进的双流网络集成来开发强大的视频级表示。 (2) 我们研究了跨空间和时间汇集以及组合来自不同流的信号的不同策略,为不同的设计选择提供了见解和实验证据。
- 优于基线:
相关工作
Trainable Spatio-Temporal Aggregation:
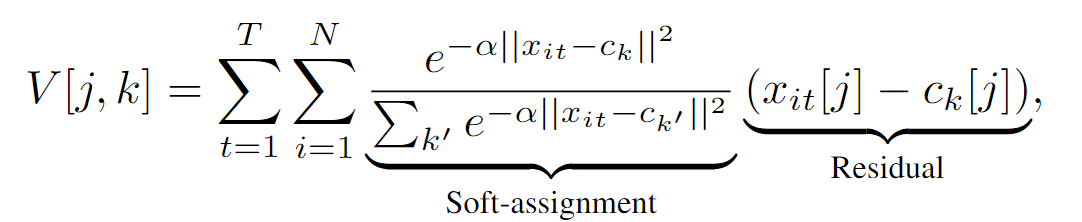
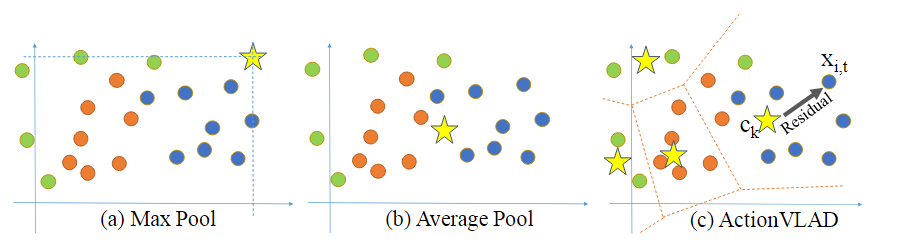
 使用由锚点{ck}表示的K个“动作词”的词汇表将描述符空间RD划分为K个单元来实现的(图3 ©)。
使用由锚点{ck}表示的K个“动作词”的词汇表将描述符空间RD划分为K个单元来实现的(图3 ©)。
模型框架
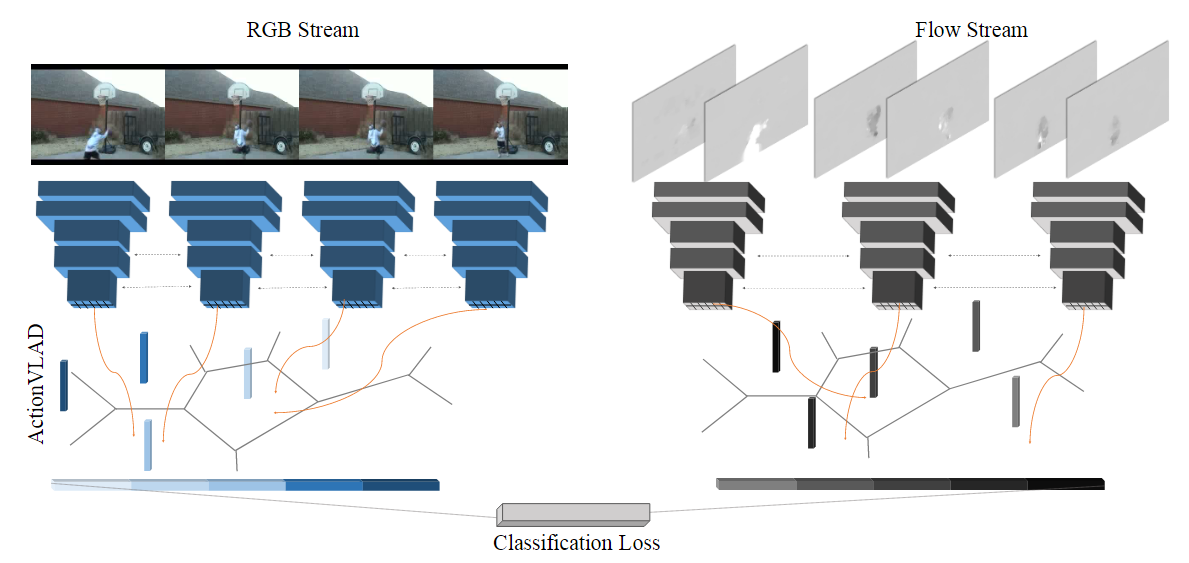
使用标准的CNN架构(VGG-16)从视频的采样外观和运动帧中提取特征。然后使用ActionVLAD池化层跨空间和时间池化这些特征,这是可训练的端到端与分类损失。
Which layer to aggregate?
Evaluation of (a) ActionVLAD at different positions in a VGG-16 network;
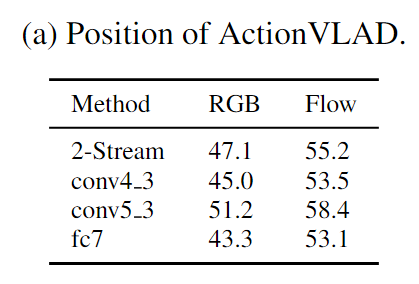
使用双流网络(在帧级上预训练)作为特征生成器,为我们可训练的ActionVLAD池化层提供来自不同帧的输入。但是,我们要汇集哪一层的激活呢?我们通过在最高卷积层(VGG-16的conv5.3)池化特征来获得最佳性能。
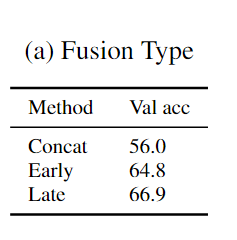
How to combine Flow and RGB streams?
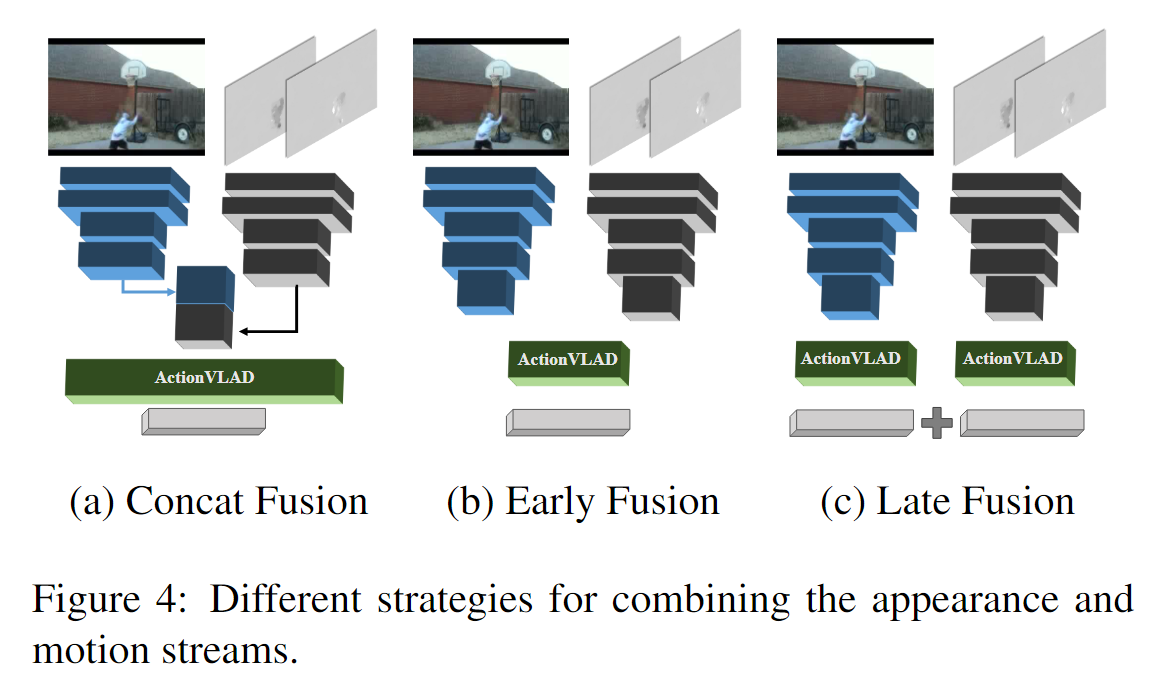
Single ActionVLAD layer over concatenated appearance and motion features (Concat Fusion).
Single ActionVLAD layer over all appearance and motion features (Early Fusion).
Late Fusion.
思考不足之处
- 出发点是好的:单一的动作分类,但是可能有多个不同的子类特征,所以找方法去整合多个子类特征到一整段视频特征的表示中。但多个子类的判断再整合无疑增加了最终精度的下降。
2. Action Tubelet Detector for Spatio-Temporal Action Localization code
术语前置
anchor cuboids : Anchor cuboids与二维目标检测中的bounding boxes类似,都是一种密集采样的方法,用于生成候选框。不同之处在于,anchor cuboids是一种三维形状的候选框,它可以处理视频中的运动物体,并利用了时间维度的信息,而anchor boxes仅适用于二维图像。
tubelets : 本文中的tubelet是指一个由多个连续帧中的bounding box序列组成的时空检测单元,其中每个bounding box都有一个关联的得分,用于表示该检测单元内是否存在某个动作类别。可以理解为在视频中对某个动作的时空位置进行检测和定位的一种方式。 a sequence of bounding boxes, with one confidence score per action class

摘要和结论
- 提出了ACtion Tubelet detector (ACT-detector)【动作管状探测器(ACT-探测器)】
- 将每一帧的特征进行时间的堆叠,形成时间序列信息sequences of frames
- 建立在SSD的基础上,并引入了锚定立方体anchor cuboids,这些锚定长方体在帧序列上sequences of frames进行评分和回归。
引言:针对痛点和贡献
痛点:
- 仅从单帧无法准确识别动作类别。
贡献:
- 提出一个Action Tubelet detector (ACT-detector),输入多帧连续视频帧,输出预测行为在多帧上的多个bbox构成的anchor cuboids,然后对每个bbox进行回归得到预测行为的tubelets。由于ACT-detector考虑到多个视频帧的连续性特征,从而能够减少行为预测的模糊性,同时提高定位准确度。
相关工作
- 目标检测:Faster-RCNN(RoI 锚框)–>YOLO和SSD。本文将它们扩展到锚长方体anchor cuboids,从而显著提高动作定位。
- 动作定位:(1)滑动窗口的拓展(需要诸如:长方体cuboid shape的假设,动作中涉及的物体或行为的空间范围保持不变,)(2)将候选框(提案)应用到视频领域,即对视频提出若干个proposals,并作分类。
模型框架
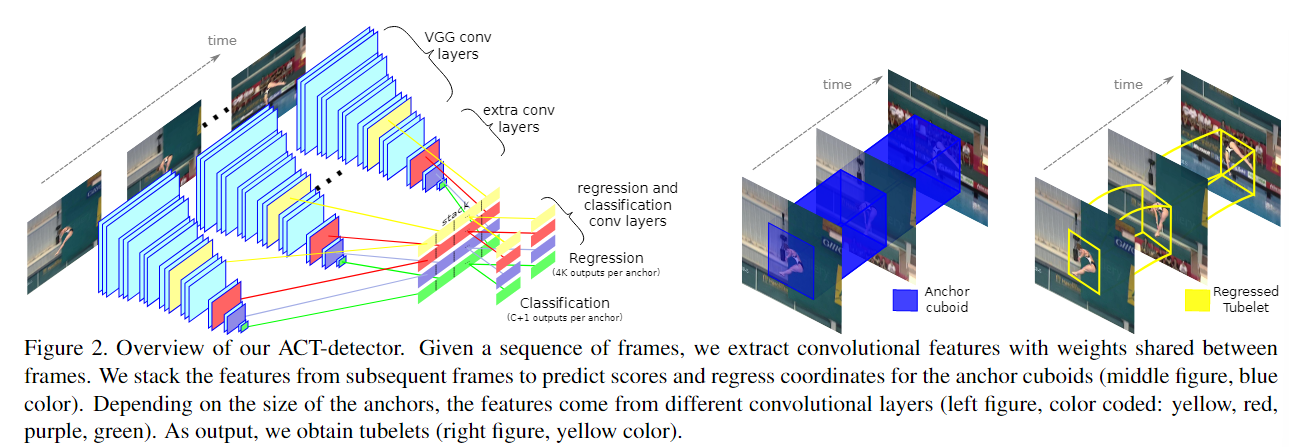

输入: K个连续帧
中间: 经过SSD网络,会有 K 个 * 不同层的特征,把K个不同特征堆叠在一起,不同层特征占不同行。
这些特征经过一个卷积会输出类别分数(class+1个),经过另一个卷积输出回归坐标(4*K )。不同层特征会输出不同分数和坐标,不同层对应不同anchors,因此不同图片位置和不同层会不同的anchor,同一位置也会有多个初始化的anchor,但K帧对应同一个anchor,相当于把SSD按时间维度扩展。
每个anchor最终会对应一个anchor cuboid,并最终NMS后输出一个tubelet或者被忽略.
初始化的anchor cuboid沿帧的维度有固定的位置,同时比人的区域要大,回归后每帧的位置不同,组成tubeltes。
输出: tubletes: a sequence of bounding boxes, with one confidence score per action class.
来源
在给定K帧序列的情况下,ACT检测器计算每个帧的卷积特征。这些卷积特征的权重在所有输入帧之间共享。
具体来说,当处理这个图像序列时,ACTdetector会使用卷积操作来提取每一帧图像的特征。不同的帧之间使用相同的卷积权重来进行特征提取,这意味着卷积核的参数在整个序列中是相同的。这种共享权重的方法有助于模型更好地理解和捕捉动作或物体在不同帧之间的相关性,因为它使用了来自所有帧的信息来提取特征,而不是独立处理每一帧。这有助于提高动作定位或检测的准确性。
堆叠来自K帧的每帧的卷积特征。(经过SSD网络,会有 K 个 * 不同层的特征,把K个不同特征堆叠在一起,不同层特征占不同行。) 堆叠的特征是两个卷积层的输入,一个用于为动作类评分,另一个用于回归锚定长方体。
分类层为每个锚定长方体C+1分数输出:每个动作类一个分数加上一个背景分数。这意味着管状分类是基于帧序列进行的。回归将为每个锚定长方体输出4×K个坐标(每个K帧4个)。请注意,尽管管束中的所有长方体都是联合回归的,但它们会为每个帧产生不同的回归。
(不同层特征会输出不同分数和坐标,不同层对应不同anchors,因此不同图片位置和不同层会不同的anchor,同一位置也会有多个初始化的anchor,但K帧对应同一个anchor,相当于把SSD按时间维度扩展。)
用于评分和回归锚定长方体的神经元的感受野大于其空间范围。这允许我们还基于长方体周围的上下文进行预测,即了解可能移动到长方体之外的参与者。

训练损失:
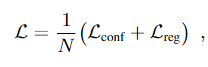 N表示anchor cuboids和真值匹配的个数,
N表示anchor cuboids和真值匹配的个数,
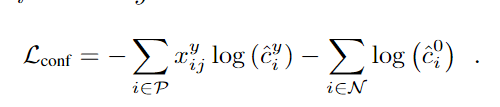 使用softmax损失定义置信度损失
使用softmax损失定义置信度损失
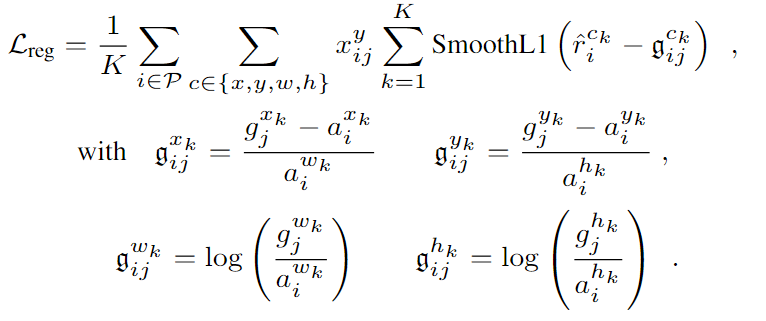
思考不足之处
- 锚点或短管的尺寸和形状的限制:方法中使用的锚点或短管的尺寸和形状通常是事先定义的,这可能导致在处理各种不同尺寸和形状的动作或物体时效果不佳。如果视频中的动作或物体与定义的锚点不匹配,可能会导致错过或误检测。
3. Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos
局部最大池特征时空向量(ST-VLMPF)
摘要和结论
- 局部最大池特征时空向量(ST-VLMPF),这是一种专门为局部深度特征编码而设计的基于超向量的编码方法。a super vector-based encoding method specifically designed for encoding local deep features.
- Feature assignment is carried out at two levels, by using the similarity and spatio-temporal information。利用相似性和时空信息在两个层次上进行特征分配。
引言:针对痛点和贡献
痛点:
- 当前标准编码的缺点之一是缺乏考虑时空信息
- 手工制作的特征是手工设计的,通常包含低水平的信息,如边缘。
- 当前预训练神经网络的可用性很高,许多研究人员将它们仅用作特征提取工具,因为在许多方面重新训练或微调神经网络都更加困难。因此,需要一种高效的深度特征编码方法来处理这个问题。
贡献:
- 解决了视频理解的一个重要问题:如何在整个视频上构建一个包含CNN特征的视频表示。
模型框架
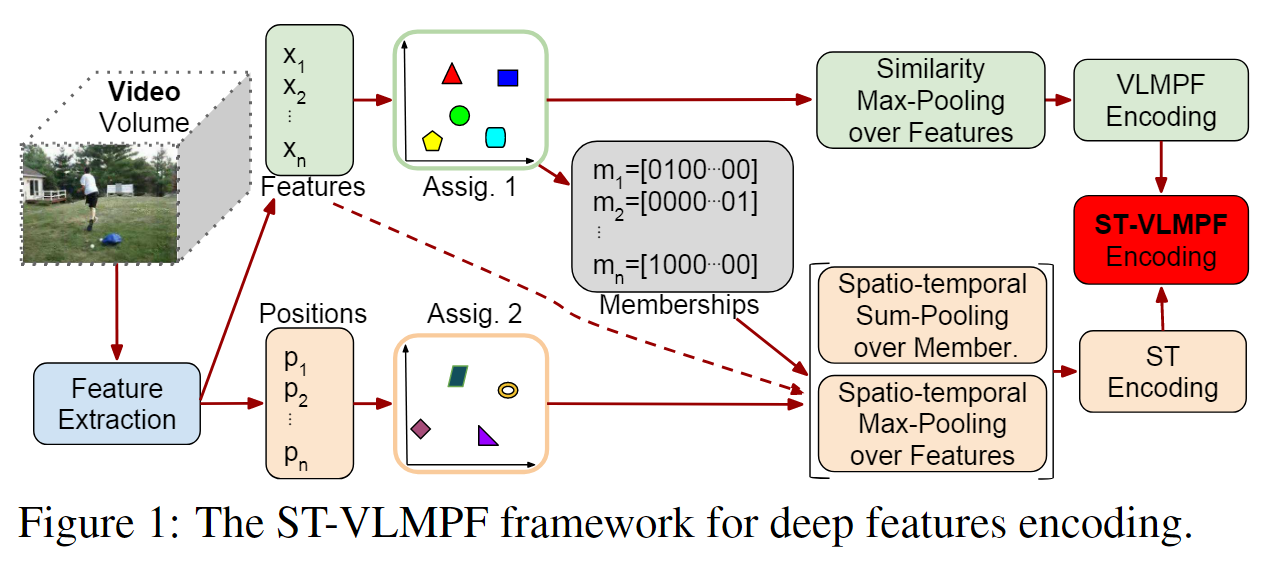
使用k-均值从从数据集中的视频子集提取的随机选择特征的大子集学习码本C。结果表示K1个视觉单词,C={c1,c2,…,ck 1},它们基本上是用k-Means学习的每个特征簇的平均值。
- 首先从视频中提取局部特征。视频用提取的局部特征X={x1, x2,…, xn}∈Rn×d,其中d为特征维数,n为视频的局部特征总数。与局部特征一起,我们保留了它们的位置P ={p1, p2,…, pn}∈Rn×3。
- 我们提出的编码方法使用获得的码本执行两个硬分配,第一个是基于特征相似性,第二个是基于它们的位置。对于第一次分配,每个本地视频特征 xj(j=1, …, n) 被分配给来自码本 C 的最接近的视觉单词。然后,在分配给集群 ci (i=1, …, n) 的特征组上。 …, k1)
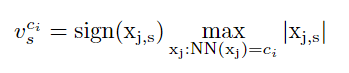
NN(xj) 表示特征 xj 的码本 C 的最近邻质心,基本上它保证我们对分配给视觉词的每组特征分别执行池化; Sign 函数返回数字和 |.| 的符号代表绝对值。基本上,公式 2 获得最大绝对值,同时保留返回的最终结果的初始符号。在图 1 中,我们将这种相似性称为特征最大池化,因为特征根据其相似性进行分组,然后对每个结果组执行最大池化。所有向量 [vc1 , vc2 , …, vck1 ] 的串联表示 VLMPF(局部最大池化特征向量)编码,最终向量大小为 (k1×d)。 - 第一次分配后,我们还保留每个特征的质心成员资格,目的是保留相关的基于相似性的聚类信息。第一次分配后,我们还保留每个特征的质心成员资格,目的是保留相关的基于相似性的聚类信息。对于每个特征,我们用一个向量 m 来表示隶属信息,例如,m=[0100…00] 将成员特征信息映射到码本 C 的第二个视觉词。
- 我们根据特征位置执行第二次分配。图 1 的底部显示了该路径。 P 中的每个特征位置 pj 被分配到码本 PC 中最近的质心。
- 根据时空信息对特征进行分组,然后计算最大绝对值,同时保持特征的原始符号。我们还在等式 3 中连接关于从第一次分配获得的特征相似性的成员信息,其目标是将时空分组特征的相似性成员与时空信息封装在一起。我们连接所有这些向量 [vpc1 , vpc2 , …, vpck2 ] 以创建 ST(时空)编码,从而得到 (k2×d + k2×k1) 向量大小。最后,我们连接 ST 和 VLMPF 编码以创建最终的 ST-VLMPF 表示,用作分类器的输入。因此,ST-VLMPF 表示的向量的最终大小为 (k1×d) + (k2×d + k2×k1)。
Local deep features extraction
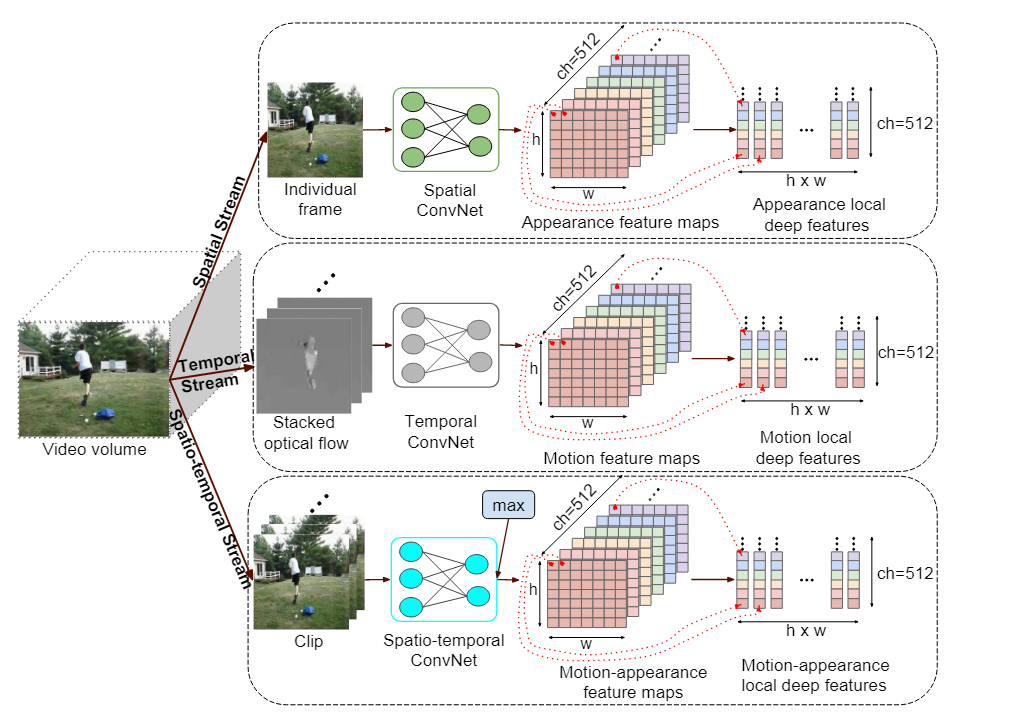
用于捕获外观的空间流、用于捕获运动的时间流和用于同时捕获外观和运动信息的时空流。
4. Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos code
摘要和结论
- propose an endto-end deep network called Tube Convolutional Neural Network (T-CNN) for action detection in videos.提出了一种用于视频中动作检测的端到端管卷积神经网络(T-CNN)。它利用 3D 卷积网络提取有效的时空特征,并在统一的框架中执行动作定位和识别。粗略提议框基于 3D 卷积特征立方体进行密集采样,并链接起来以进行动作识别和定位。
引言:针对痛点和贡献
痛点:
- 以前基于卷积神经网络(CNN)的视频动作检测方法通常包含两个主要步骤:帧级动作提案生成和跨帧提案关联。此外,这些方法大多数采用双流 CNN 框架来分别分别(separately)处理空间和时间特征。
贡献:
- 提出了一种基于端到端深度学习的视频动作检测方法。它直接对原始视频进行操作,使用单个3D网络捕获时空信息,基于3D卷积特征进行动作定位和识别。这是第一个利用 3D ConvNet 进行动作检测的工作。
- 引入了 Tube Proposal Network,它利用时域中的skip pooling来保留 3D 体积中动作定位的时间信息。
- 在 T-CNN 中提出了一个新的池化层——Tube-of-Interesr(ToI)池化层。 ToI 池化层是 R-CNN 感兴趣区域 (RoI) 池化层的 3D 推广。它有效地缓解了管道提案的空间和时间大小可变的问题。
相关工作
- R-CNN:对于图像中的目标检测,Region-CNN(R-CNN),区域提案region proposal是使用选择性搜索selective search来提取的。然后将候选区candidate region扭曲warped为固定大小fixed size并输入 ConvNet 以提取 CNN 特征。最后,训练SVM模型用于对象分类。
- Fast R-CNN。与 R-CNN 的多级管道multi-stage pipline相比,Fast R-CNN 在网络中加入了对象分类器,同时训练对象分类器object classifiter和边界框回归器bounding box regressor。引入Region-of-Interest(RoI)池化层来提取不同大小的边界框的固定长度特征向量。
- Faster R-CNN。它引入了 RPN(Region Proposal Network)来代替选择性搜索来生成提案。 RPN 与检测网络共享完整的图像卷积特征,因此提案生成几乎是免费的。 Faster R-CNN 实现了最先进的目标检测性能,同时在测试过程中保持高效。受其高性能的推动,在本文中,我们探索将更快的 R-CNN 从 2D 图像区域推广到 3D 视频量以进行动作检测。
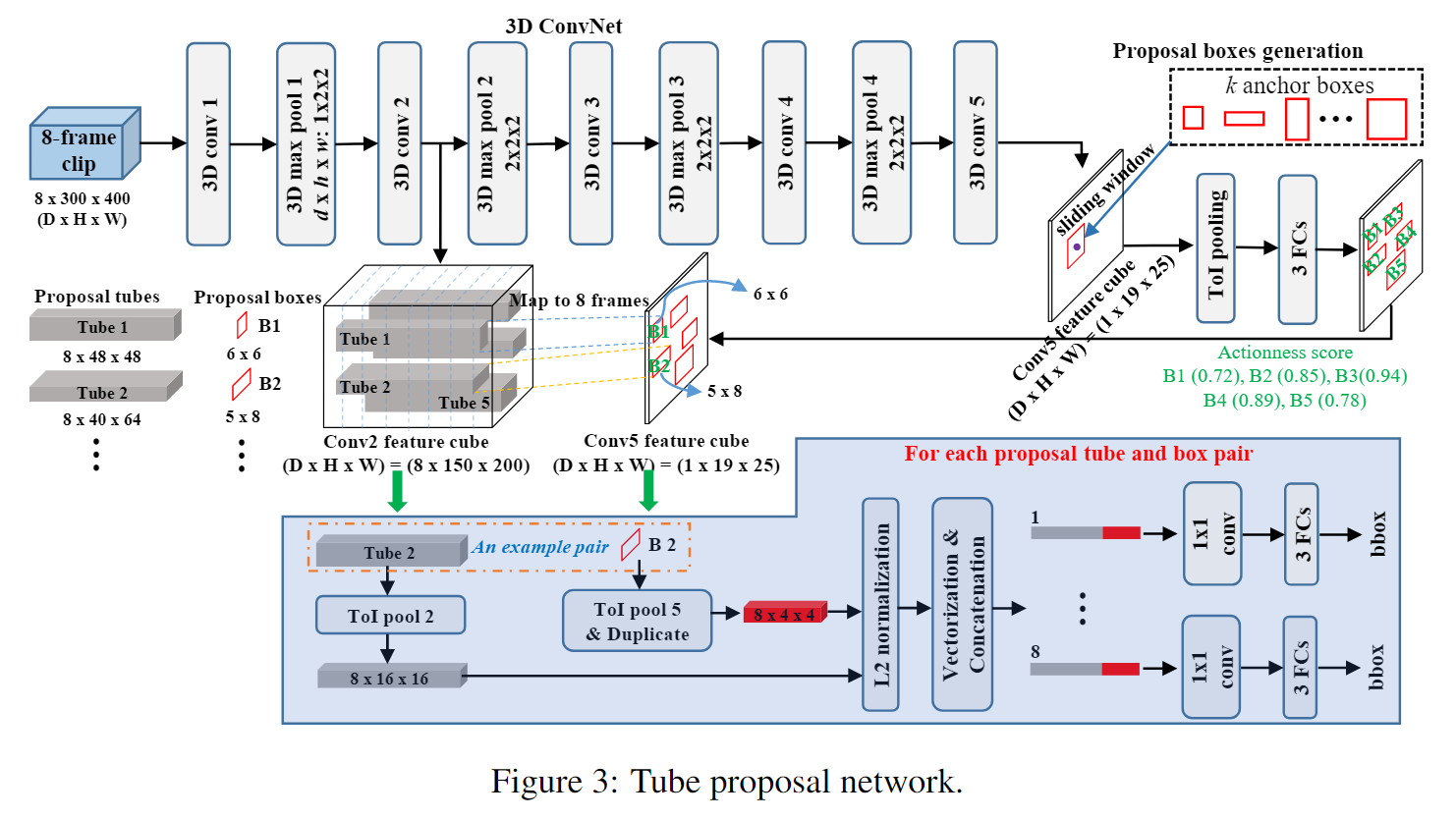
模型框架
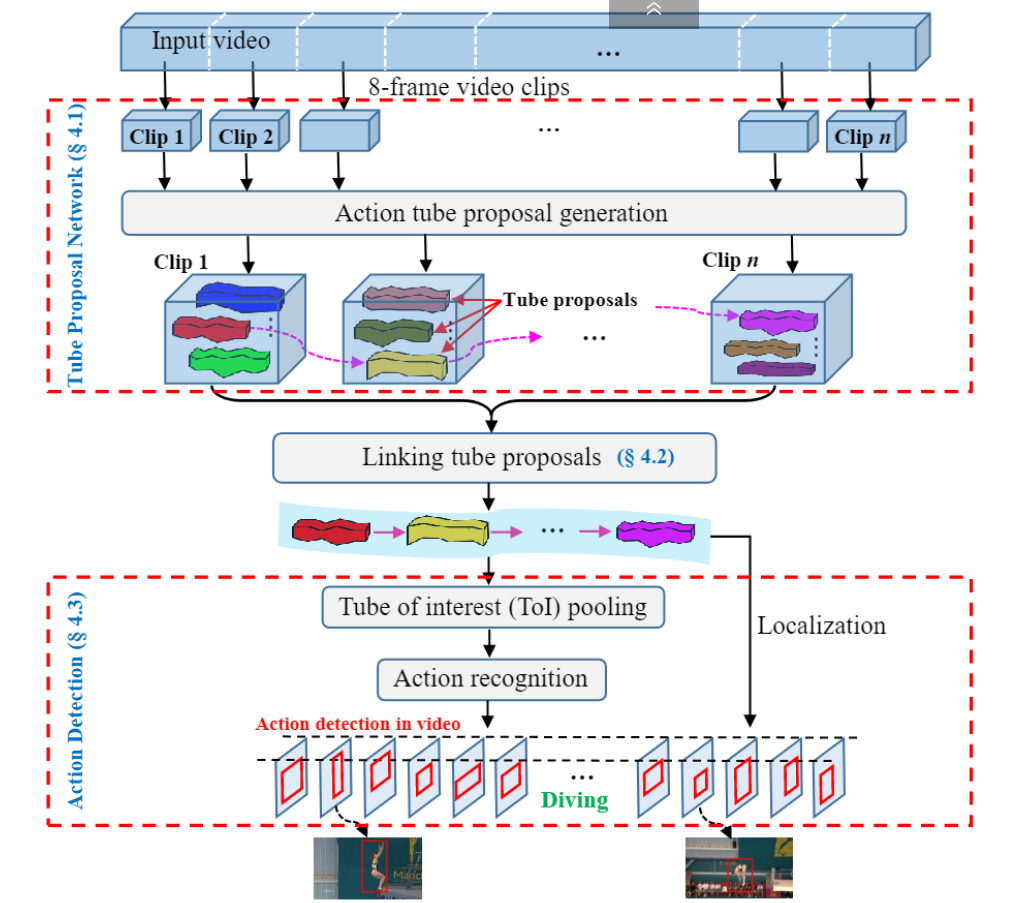
- 输入视频首先被分成相等长度的剪辑 clip。
- 然后,将剪辑clip输入到管建议网络(TPN)并获得一组管建议tube proposals。
- 接下来,每个视频剪辑的管建议根据其动作分数actioness score和相邻建议之间的重叠overlap进行链接,以形成视频中时空动作定位的完整管建议。
- 最后,将Tube-of-Interest(ToI)池化pooling应用于链接link的动作管提议,以生成用于动作标签预测的固定长度特征向量a fixed length feature vector。
Tube of interest pooling
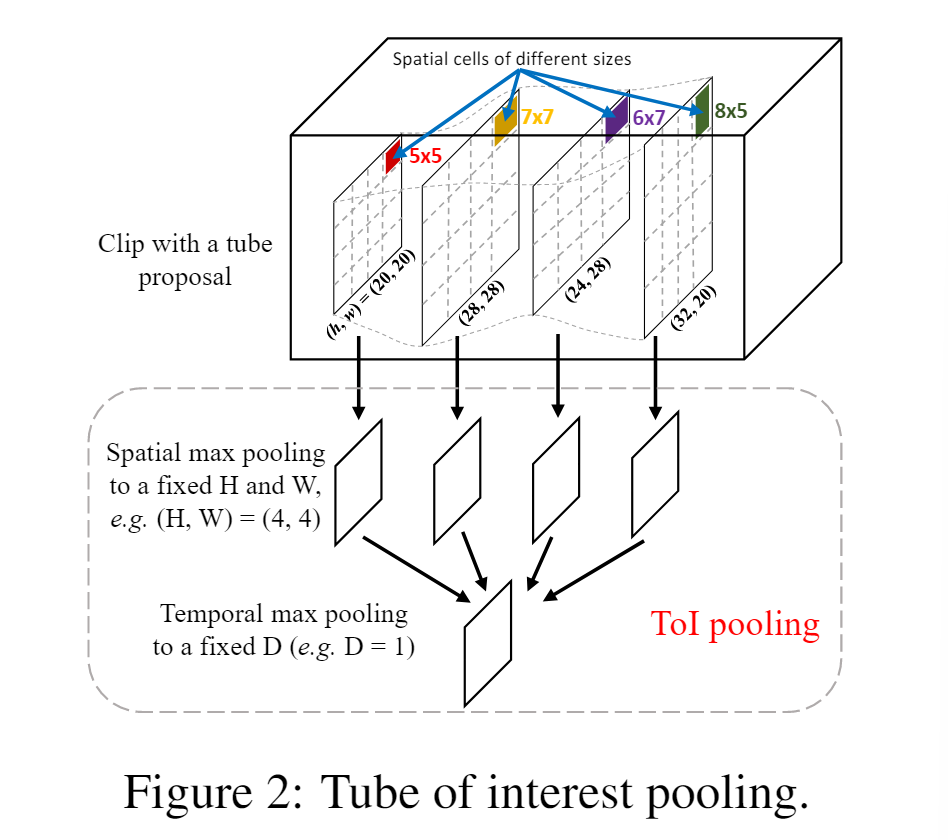
- 空间最大池化: 首先,将 h × w 特征图分为 H × W 个 bin,其中每个 bin 对应于大小约为 h/H × w/W 的单元。在每个单元格中,应用最大池化来选择最大值。
- 时间最大池化: 其次,空间池化的 d 个特征图在时间上被划分为 D个bin。与第一步类似,d/D 相邻特征图被分组在一起以执行标准时间最大池化。因此,ToI 池化层的固定输出大小为 D × H × W 。图 2 展示了 ToI 池化的图示。
- 如上图,红色区域卷积对20*20的特征图分了4个bins,
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
Tube Proposal Network
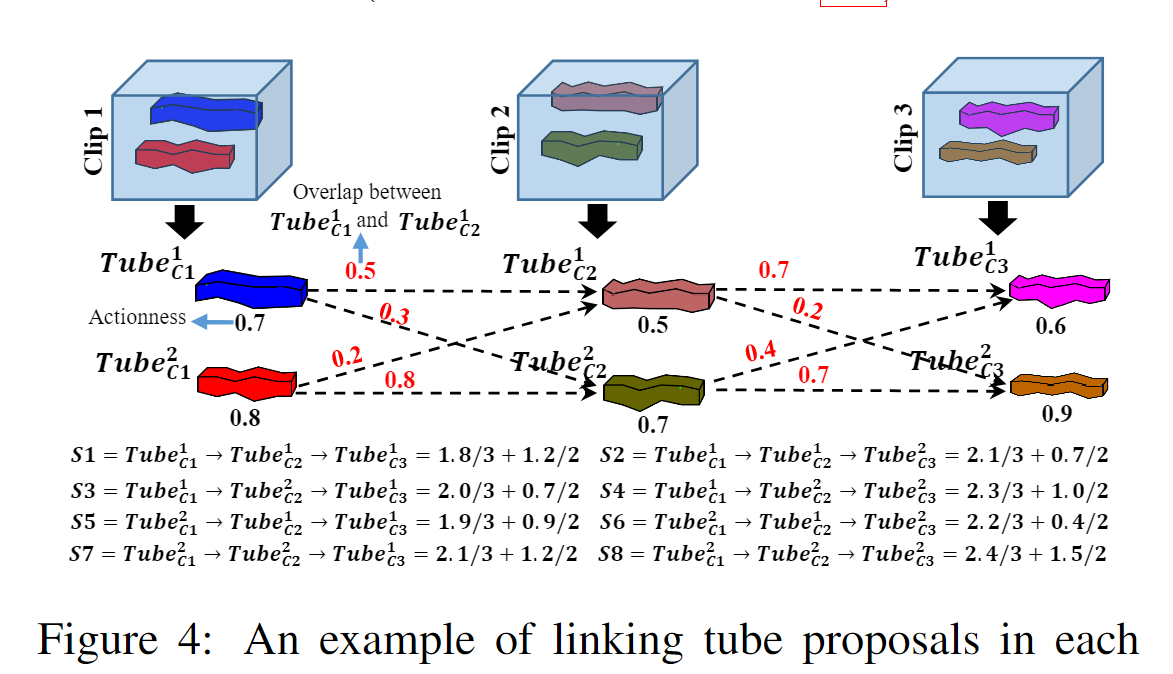
Linking Tube Proposals
来自不同clip的每个tube proposal可以link在管提案序列tube proposal sequence ((即视频管提案)中以进行动作检测。然而,并非所有管建议的组合都能正确捕获完整的动作。例如,一个clip中的tube proposal可能包含动作,而下一clip中的tube proposal可能仅捕获背景。直观上,所选tube proposal中的内容应捕获动作,并且任何两个连续剪辑中连接的管建议应具有较大的时间重叠。 因此,在链接管提案时要考虑两个标准:行动性和重叠分数。然后为每个视频提案分配一个分数,定义如下:
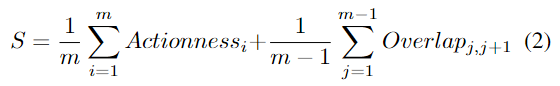
其中 Actionness_i 表示来自第 i 个clip的管提案的行动得分,Overlap_j,_j+1 测量分别来自第 j 和第 (j + 1) 个clip的链接的两个提案之间的重叠,m 是视频剪辑总数。如图 3 所示,来自 conv5 特征管的每个边界框提案都与一个动作分数相关联。行动分数由相应的管提案继承。
两个管提案之间的重叠是根据第 j 个管提案的最后一帧和第 (j+1) 个管提案的第一帧的 IoU(并交交集)来计算的。 S 的第一项计算视频提案中所有管提案的平均动作得分,第二项计算每两个连续视频剪辑中管提案之间的平均重叠度。因此,我们确保链接的管提案可以封装操作,同时具有时间一致性。图 4 展示了连接管提案和计算分数的示例。我们选择视频中分数最高的多个链接提案序列。
相关文章:
【Spatial-Temporal Action Localization(二)】论文阅读2017年
文章目录 1. ActionVLAD: Learning spatio-temporal aggregation for action classification [code](https://github.com/rohitgirdhar/ActionVLAD/)[](https://github.com/rohitgirdhar/ActionVLAD/)摘要和结论引言:针对痛点和贡献相关工作模型框架思考不足之处 2.…...

二维码智慧门牌管理系统:数据现势性,满足应用需求的根本保证
文章目录 前言一、项目背景二、数据的现势性三、系统的优势四、应用前景 前言 在当今信息化社会,数据的重要性日益凸显,尤其是数据的现势性,它决定着服务的质量和满足应用需求的能力。近日,一个创新的二维码智慧门牌管理系统项目…...

BF算法(C++)简单讲解
BF算法匹配过程易理解,若匹配,子串和主串都往下移一位。不匹配时,主串回溯至本次匹配开始下标的下一位。例:图中第三趟匹配时,主串到第七位时与子串不匹配,这次匹配主串是从第三位开始的,所以下…...

JVM 虚拟机 ----> Java 类加载机制
文章目录 JVM 虚拟机 ----> Java 类加载机制一、概述二、类的生命周期1、类加载过程(Loading)(1)加载(2)验证(3)准备(4)解析(5)初始…...
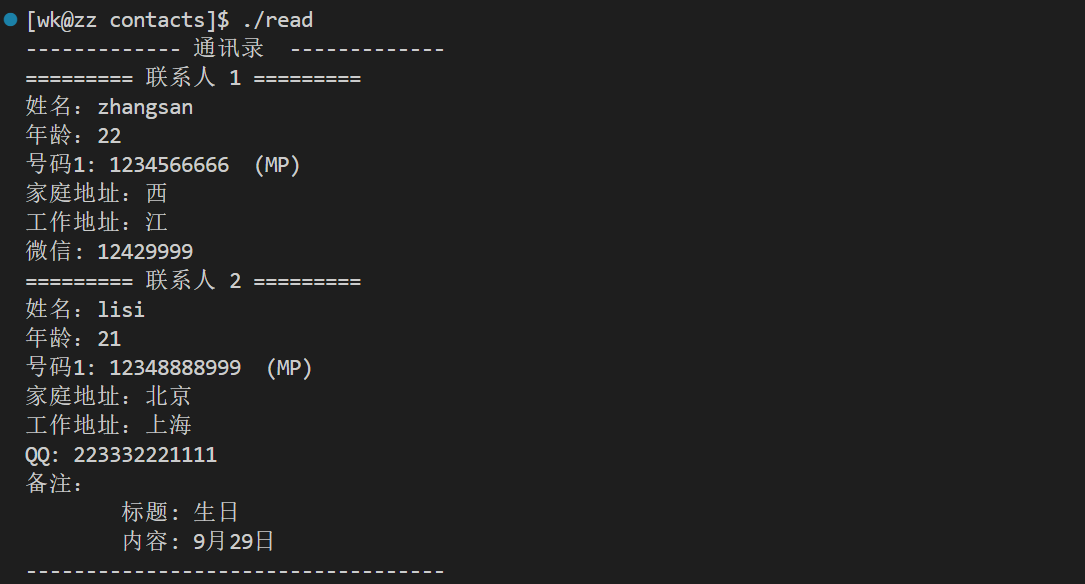
《protobuf》基础语法2
文章目录 枚举类型ANY 类型oneof 类型map 类型改进通讯录实例 枚举类型 protobuf里有枚举类型,定义如下 enum PhoneType {string home_addr 0;string work_addr 1; }同message一样,可分为 嵌套定义,文件内定义,文件外定义。不…...

利用 SOAR 加快事件响应并加强网络安全
随着攻击面的扩大和攻击变得越来越复杂,与网络攻击者的斗争重担落在了安全运营中心 (SOC) 身上。SOC 可以通过利用安全编排、自动化和响应 (SOAR) 平台来加强组织的安全态势。这一系列兼容的以安全为中心的软件可加快事…...
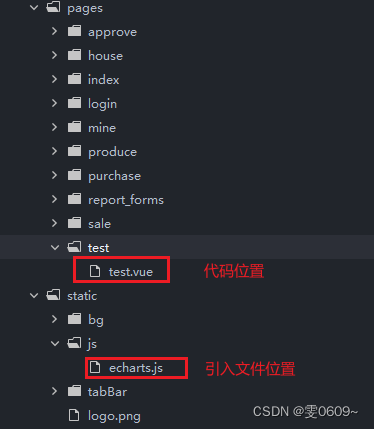
uni-app:通过ECharts实现数据可视化-如何引入项目
效果 引入文件位置 代码 <template><view id"myChart"></view> </template> <script> import echarts from /static/js/echarts.js // 引入文件 export default {mounted() {// 初始化EChartsconst myChart echarts.init(document…...

string 模拟与用法
string 用法 string string 模拟 #pragma once #include <assert.h> #include <string.h> #include <iostream>namespace sjy {class string{public://迭代器相关typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _st…...

[NLP] LLM---<训练中文LLama2(一)>训练一个中文LLama2的步骤
一 数据集 【Awesome-Chinese-LLM中文数据集】 【awesome-instruction-dataset】【awesome-instruction-datasets】【LLaMA-Efficient-Tuning-数据集】Wiki中文百科(25w词条)wikipedia-cn-20230720-filteredBaiduBaiKe(563w词条) …...
华为云云耀云服务器L实例使用教学 | 利用华为云服务器搭建--> 基于Spring Boot+WebSocket+WebRtc实现的多人自习室
文章目录 1. 购买华为云服务器L2. 在华为云服务器上搭建项目前期准备工作1. 更换登录密码2. 安全组配置 3. 在服务器上运行自己的项目 1. 购买华为云服务器L 在有优惠券的情况下,来到华为云这个网址下面,链接为:https://www.huaweicloud.com…...
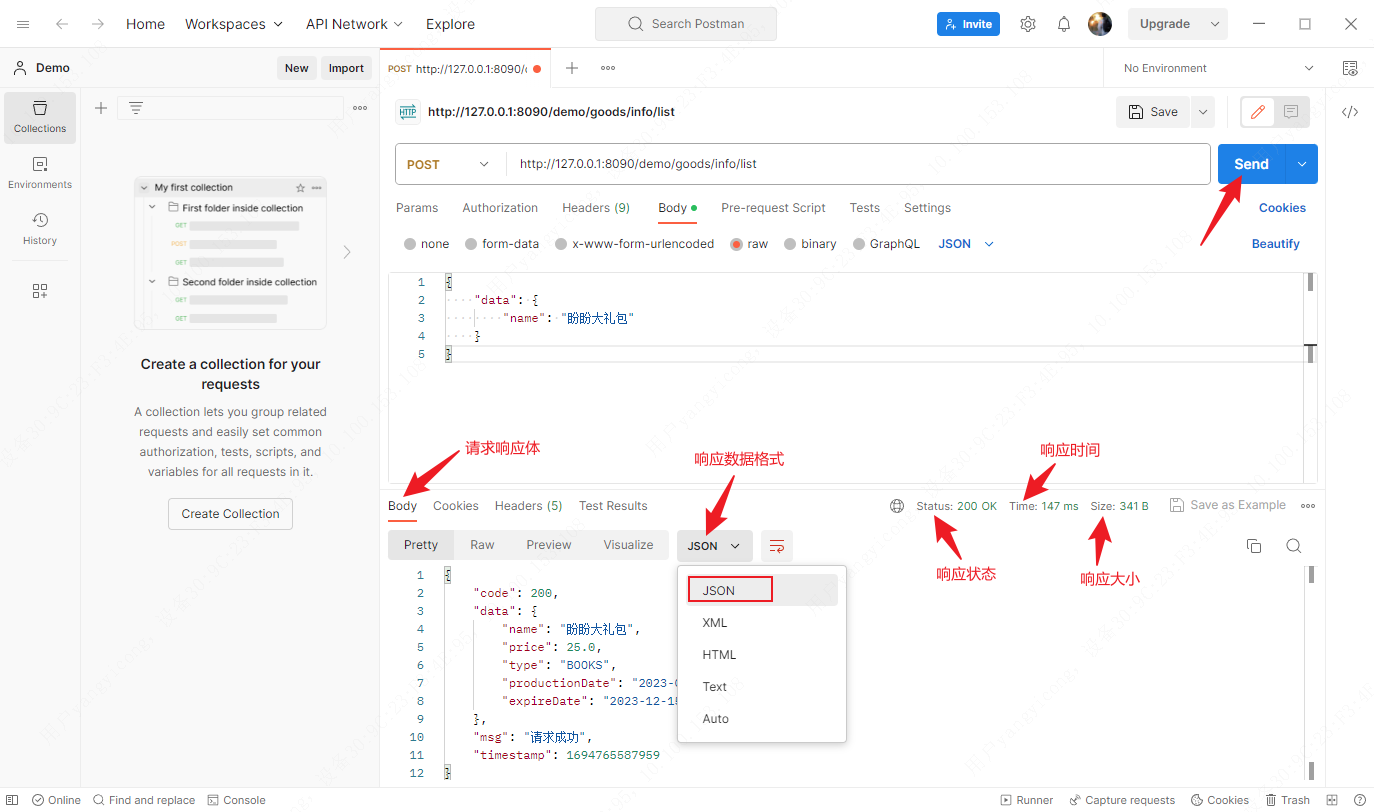
Postman应用——接口请求(Get和Post请求)
文章目录 新增请求接口请求Get接口请求Post 这里只讲用的比较多的Get和Post请求方式,也可以遵循restful api接口规范,使用其他请求方式。 GET(SELECT):从服务器取出资源(一项或多项)POST&#…...
k8s pod概念、分类及策略
目录 一.pod相关概念 2.Kubrenetes集群中Pod两种使用方式 3.pause容器的Pod中的所有容器共享的资源 4.kubernetes中的pause容器主要为每个容器提供功能: 6.Pod分为两类: 二.Pod容器的分类 1.基础容器…...

C++系列-左移运算符重载
左移运算符重载 左移运算符的应用左移运算符的重载 左移运算符的应用 左移运算符,左移第一个操作数的位,第二个操作数决定要移动的位置左移运算符还可以用于输出调试,cout << “Hello” << endl; 左移运算符的重载 左移运算符…...

【Vue】vue中v-if的用法
v-if是Vue.js中常用的条件渲染指令,根据表达式的值来动态控制元素的显示或隐藏。具体的使用方法如下: 1.基本语法 <div v-if"condition"><!-- content --> </div>其中,v-if后面跟着一个表达式condition&#x…...
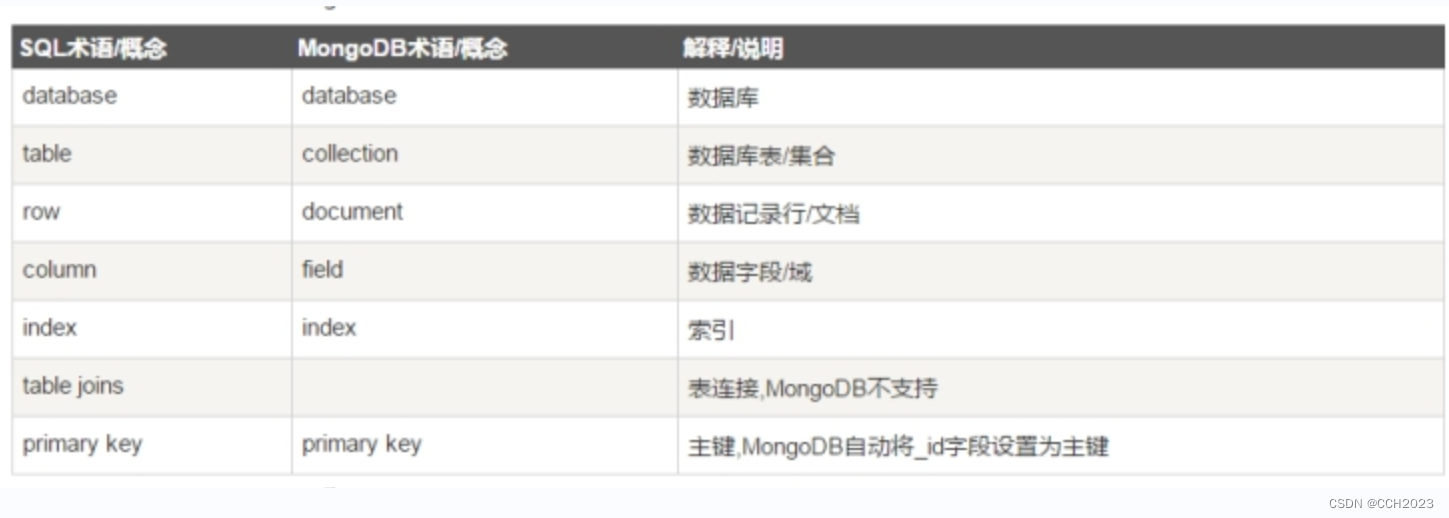
企业架构LNMP学习笔记54
企业架构NoSQL数据库之MongoDB。 学习目标和内容: 1)能够简单描述mongoDB的使用特点: 2)能够安装配置启动MongoDB; 3)能够使用命令行客户端简单操作MongoDB; 4)能够实现基本的数…...
C【函数】
1.常用API 1.strcpy:#include<string.h> char * strcpy ( char * destination, const char * source );int main(){char arr1[] "bit";char arr2[20] "###########";// bit\0########strcpy(arr2, arr1);printf("…...
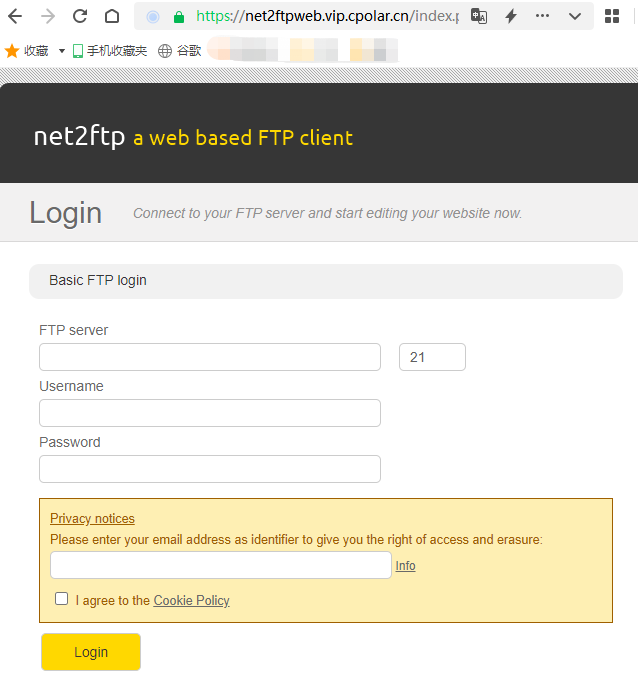
【简单教程】利用Net2FTP构建免费个人网盘,实现便捷的文件管理
文章目录 1.前言2. Net2FTP网站搭建2.1. Net2FTP下载和安装2.2. Net2FTP网页测试 3. cpolar内网穿透3.1.Cpolar云端设置3.2.Cpolar本地设置 4.公网访问测试5.结语 1.前言 文件传输可以说是互联网最主要的应用之一,特别是智能设备的大面积使用,无论是个人…...

05-Flask-Flask查询路由方式
Flask查询路由方式 前言命令行方式代码实现返回所有路由 前言 本篇来学习下Flask中查询路由的方式 命令行方式 # window 用set linux 用 export set FLASK_APPtest_6_flask运行发方式# 打印所有路由 flask routes代码实现返回所有路由 # -*- coding: utf-8 -*- # Time …...

lua环境搭建数据类型
lua作为一门计算机语言,从语法角度个人感觉还是挺简洁的接下来我们从0开始学习lua语言。 1.首先我们需要下载lua开发工具包 在这里我们使用的工具是luadist 下载链接为:https://luadist.org/repository/下载后的压缩包解压后就能用。 2.接下来就是老生…...

c++11的一些新特性
c11 1. {}初始化2. 范围for循环3. final与override4. 右值引用4.1 左值引用和右值引用4.2 左值引用与右值引用比较 5. lambda表达式6. 声明6.1 auto6.2 decltype6.3 nullptr 7. 可变参数模版 1. {}初始化 在C中,使用花括号初始化的方式被称为列表初始化。列表初始化…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...

数据结构:泰勒展开式:霍纳法则(Horner‘s Rule)
目录 🔍 若用递归计算每一项,会发生什么? Horners Rule(霍纳法则) 第一步:我们从最原始的泰勒公式出发 第二步:从形式上重新观察展开式 🌟 第三步:引出霍纳法则&…...