PostgreSQL执行计划
1. EXPLAIN命令
1)PostgreSQL中EXPLAIN命令的语法格式:
postgres=# \h explain
Command: EXPLAIN
Description: show the execution plan of a statement
Syntax:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statementwhere option can be one of:ANALYZE [ boolean ]VERBOSE [ boolean ]COSTS [ boolean ]SETTINGS [ boolean ]BUFFERS [ boolean ]WAL [ boolean ]TIMING [ boolean ]SUMMARY [ boolean ]FORMAT { TEXT | XML | JSON | YAML }
PS:ANALYZE选项通过实际执行SQL来获得SQL命令的实际执行计划。ANALYZE选项查看到的执行计划因为真正被执行过,所以可以看到执行计划每一步耗费了多长时间,以及它实际返回的行数。2)ANALYZE选项后是真正执行实际的SQL命令,如果SQL语句是一个插入、删除、更新或CREATE TABLE AS语句(这些语句会修改数据库),为了不影响实际数据,可以把EXPLAIN ANALYZE放到一个事务中,执行完后即回滚事务,命令如下:
BEGIN;
EXPLAIN ANALYZE ...;
ROLLBACK;3)计划解释
VERBOSE选项显示计划的附加信息,如计划树中每个节点输出的各个列,如果触发器被触发,还会输出触发器的名称。该选项的值默认为“FALSE”。
COSTS选项显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度。该选项的值默认为“TRUE”。
BUFFERS选项显示缓冲区使用的信息。该参数只能与ANALYZE参数一起使用。显示的缓冲区信息包括共享块读和写的块数、本地块读和写的块数,以及临时块读和写的块数。共享块、本地块和临时块分别包含表和索引、临时表和临时索引,以及在排序和物化计划中使用的磁盘块。上层节点显示出来的块数包括所有其子节点使用的块数。该选项的值默认为“FALSE”。
FORMAT选项指定输出格式,输出格式可以是TEXT、XML、JSON或者YAML。非文本输出包含与文本输出格式相同的信息,但其他程序更易于解析。该参数默认为“TEXT”2 EXPLAIN输出结果解释
osdba=# explain select * from testtab01;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on testtab01 (cost=0.00..184.00 rows=10000 width=36)
(1 row)PS:
数字“0.00”表示启动的成本,也就是说,返回第一行需要多少cost值;
·rows=10000:表示会返回10000行。
·width=36:表示每行平均宽度为36字节。成本“cost”用于描述SQL命令的执行代价,默认情况下,不同操作
的cost值如下:
·顺序扫描一个数据块,cost值定为“1”。
·随机扫描一个数据块,cost值定为“4”。
·处理一个数据行的CPU代价,cost值定为“0.01”。
·处理一个索引行的CPU代价,cost值定为“0.005”。
·每个操作符的CPU代价为“0.0025”。osdba=# explain select a.id,b.note from testtab01 a,testtab02 b where a.id=b.id;
QUERY PLAN
-----------------------------------------------------------------------------
Hash Join (cost=309.00..701.57 rows=9102 width=36)
Hash Cond: (b.id = a.id)
-> Seq Scan on testtab02 b (cost=0.00..165.02 rows=9102 width=36)
-> Hash (cost=184.00..184.00 rows=10000 width=4)
-> Seq Scan on testtab01 a (cost=0.00..184.00 rows=10000 width=4)
3. EXPLAIN使用示例
3.1 以输出JSON格式
osdba=# explain (format json) select * from testtab01;
QUERY PLAN
----------------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Seq Scan", +
"Relation Name": "testtab01",+
"Alias": "testtab01", +
"Startup Cost": 0.00, +
"Total Cost": 184.00, +
"Plan Rows": 10000, +
"Plan Width": 36 +
} +
} +
]
(1 row)3.2 输出XML格式
osdba=# explain (format xml) select * from testtab01;
QUERY PLAN
----------------------------------------------------------
<explain xmlns="http://www.postgresql.org/2009/explain">+
<Query> +
<Plan> +
<Node-Type>Seq Scan</Node-Type> +
<Relation-Name>testtab01</Relation-Name> +
<Alias>testtab01</Alias> +
<Startup-Cost>0.00</Startup-Cost> +
<Total-Cost>184.00</Total-Cost> +
<Plan-Rows>10000</Plan-Rows> +
<Plan-Width>36</Plan-Width> +
</Plan> +
</Query> +
</explain>
(1 row)3.3 analyze”参数
1)添加“analyze”参数,通过实际执行来获得更精确的执行计划
osdba=# explain analyze select * from testtab01;
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on testtab01 (cost=0.00..184.00 rows=10000 width=36) (actual time=0.493..4.320 rows=10000 loops=1)
Total runtime: 5.653 ms
(2 rows)PS:从上面的运行结果中可以看出,加了“analyze”参数后,可以看到实际的启动时间(第一行返回的时间)、执行时间、实际的扫描行数
(actual time=0.493..4.320 rows=10000 loops=1),其中启动时间为0.493毫秒,返回所有行的时间为4.320毫秒,返回的行数是100002)analyze选项还有另一种语法,即放在小括号内,得到的结果与上面的结果完全一致
osdba=# explain (analyze true) select * from testtab01;
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on testtab01 (cost=0.00..184.00 rows=10000 width=36) (actual time=0.019..2.650 rows=10000 loops=1)
Total runtime: 4.004 ms
(2 rows)3)如果只查看执行的路径情况而不看cost值,则可以加“(costsfalse)”选项
osdba=# explain (costs false) select * from testtab01;
QUERY PLAN
-----------------------
Seq Scan on testtab01
(1 row)4)联合使用analyze选项和buffers选项,通过实际执行来查看实际的代价和缓冲区命中的情况
osdba=# explain (analyze true,buffers true ) select * from testtab03;
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on testtab03 (cost=0.00..474468.18 rows=26170218 width=36) (actual time=0.498..8543.701 rows=10000000 loops=1)
Buffers: shared hit=16284 read=196482 written=196450
Total runtime: 9444.707 ms
(3 rows)
PS:因为加了buffers选项,执行计划的结果中就会出现一行“Buffers:shared hit=16284 read=196482 written=196450”,其中“shared
hit=16284”表示在共享内存中直接读到16284个块,从磁盘中读到196482块,写磁盘196450块。有人可能会问,SELECT为什么会写?这是因为共享内存中有脏块,从磁盘中读出的块必须把内存中的脏块挤出内存,所以产生了很多的写。5)“create table as”的执行计划
osdba=# explain create table testtab04 as select * from testtab03 limit 100000;
QUERY PLAN
-----------------------------------------------------------------------------
Limit (cost=0.00..3127.66 rows=100000 width=142)
-> Seq Scan on testtab03 (cost=0.00..312766.02 rows=10000002 width=142)
(2 rows)6)下insert语句的执行计划:
osdba=# explain insert into testtab04 select * from testtab03 limit 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Insert on testtab04 (cost=0.00..4127.66 rows=100000 width=142)
-> Limit (cost=0.00..3127.66 rows=100000 width=142)
-> Seq Scan on testtab03 (cost=0.00..312766.02 rows=10000002 width=142)
(3 rows)7)删除语句的执行计划
osdba=# explain delete from testtab04;
QUERY PLAN
-------------------------------------------------------------------
Delete on testtab04 (cost=0.00..22.30 rows=1230 width=6)
-> Seq Scan on testtab04 (cost=0.00..22.30 rows=1230 width=6)
(2 rows)8)更新语句的执行计划
osdba=# explain update testtab04 set note='bbbbbbbbbbbbbbbb';
QUERY PLAN
--------------------------------------------------------------------
Update on testtab04 (cost=0.00..22.30 rows=1230 width=10)
-> Seq Scan on testtab04 (cost=0.00..22.30 rows=1230 width=10)
(2 rows)
4. 全表扫描
全表扫描在PostgreSQL中也称顺序扫描(Seq Scan),全表扫描就是把表中的所有数据块从头到尾读一遍,然后从中找到符合条件的数据块。
1)全表扫描在EXPLAIN命令的输出结果中用“Seq Scan”表示
osdba=# EXPLAIN SELECT * FROM testtab01;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on testtab01 (cost=0.00..2754.05 rows=151905 width=36)
(1 row)
5. 索引扫描
索引通常是为了加快查询数据的速度而增加的。索引扫描,就是在索引中找出需要的数据行的物理位置,然后再到表的数据块中把相应的数据读出来的过程
1)索引扫描在EXPLAIN命令的输出结果中用“Index Scan”表示
osdba=# EXPLAIN SELECT * FROM testtab01 where id=1000;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using idx_testtab01_id on testtab01 (cost=0.29..8.31 rows=1 width=70)
Index Cond: (id = 1000)
(2 rows)6. 位图扫描
位图扫描也是走索引的一种方式。方法是扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以把两个索引形成的位图通过AND或OR计算合并成一个,再到表的数据文件中把数据读出来。
1)当执行计划的结果行数很多时会走这种扫描,如非等值查询、IN子句或有多个条件都可以走不同的索引时
osdba=# explain select * from testtab02 where id2 >10000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on testtab02 (cost=18708.13..36596.06 rows=998155 width=16)
Recheck Cond: (id2 > 10000)
-> Bitmap Index Scan on idx_testtab02_id2 (cost=0.00..18458.59 rows=998155 width=0)
Index Cond: (id2 > 10000)
(4 rows)
PS:在位图扫描中可以看到,“Bitmap Index Scan”先在索引中找到符合条件的行,然后在内存中创建位图,再到表中扫描,也就是我们看到的“Bitmap Heap Scan”。大家还会看到“Recheck Cond:(id2>10000)”,这是因为多版本的原因,从索引中找出的行从表中读出后还需要再检查一下条件2)因为IN子句走位图索引的示例
osdba=# explain select * from testtab02 where id1 in (2,4,6,8);
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on testtab02 (cost=17.73..33.47 rows=4 width=16)
Recheck Cond: (id1 = ANY ('{2,4,6,8}'::integer[]))
-> Bitmap Index Scan on idx_testtab02_id1 (cost=0.00..17.73 rows=4 width=0)
Index Cond: (id1 = ANY ('{2,4,6,8}'::integer[]))
(4 rows)3)下面是走两个索引后将位图进行BitmapOr运算的示例
osdba=# explain select * from testtab02 where id2 >10000 or id1 <200000;
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on testtab02 (cost=20854.46..41280.46 rows=998446 width=16)
Recheck Cond: ((id2 > 10000) OR (id1 < 200000))
-> BitmapOr (cost=20854.46..20854.46 rows=1001000 width=0)
-> Bitmap Index Scan on idx_testtab02_id2 (cost=0.00..18458.59 rows=998155 width=0)
Index Cond: (id2 > 10000)
-> Bitmap Index Scan on idx_testtab02_id1 (cost=0.00..1896.65 rows=102430 width=0)
Index Cond: (id1 < 200000)
(7 rows)7 条件过滤
条件过滤,一般就是在WHERE子句上加过滤条件,当扫描数据行时会找出满足过滤条件的行。条件过滤在执行计划中显示为“Filter”
1)
osdba=# EXPLAIN SELECT * FROM testtab01 where id<1000 and note like 'asdk%';
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using idx_testtab01_id on testtab01 (cost=0.29..48.11 rows=1 width=70)
Index Cond: (id < 1000)
Filter: (note ~~ 'asdk%'::text)2)如果条件的列上有索引,可能会走索引而不走过滤
osdba=# EXPLAIN SELECT * FROM testtab01 where id<1000;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using idx_testtab01_id on testtab01 (cost=0.29..45.63 rows=991 width=70)
Index Cond: (id < 1000)
(2 rows)
osdba=# EXPLAIN SELECT * FROM testtab01 where id>1000;
QUERY PLAN
-----------------------------------------------------------------
Seq Scan on testtab01 (cost=0.00..2485.00 rows=99009 width=70)
Filter: (id > 1000)
(2 rows8. 嵌套循环连接
嵌套循环连接(NestLoop Join)是在两个表做连接时最朴素的一种连接方式。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1万不适合),要把返回子集较小的表作为外表,而且在内表的
连接字段上要有索引,否则速度会很慢。执行的过程如下:确定一个驱动表(Outer Table),另一个表为Inner Table,驱动表中的每一行与Inner Table表中的相应记录Join类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且InnerTable表有有效的访问(Index)。需要注意的是,Join的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间才是最快的。
9. 散列连接
优化器使用两个表中较小的表,利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。这种方式适用于较小的表可以完全放于内存中的情况,这样总成本就是访问两个表的成本之和。但是如果表很大,不能完全放入内存,优化器会将它分割成若干不同的分区,把不能放入内存的部分写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O的性能。
1)个散列连接
osdba=# explain select a.id,b.id,a.note from testtab01 a, testtab02 b where a.id=b.id and b.id<=1000000;
QUERY PLAN
--------------------------------------------------------------------------------
Hash Join (cost=20000041250.75..20000676975.71 rows=999900 width=93)
Hash Cond: (a.id = b.id)
-> Seq Scan on testtab01 a (cost=10000000000.00..10000253847.55 rows=10000055 width=89)
-> Hash (cost=10000024846.00..10000024846.00 rows=999900 width=4)
-> Seq Scan on testtab02 b (cost=10000000000.00..10000024846.00 rows=999900 width=4)
Filter: (id <= 1000000)
(6 rows)2)先看表大小,命令如下
osdba=# select pg_relation_size('testtab01');
pg_relation_size
------------------
1260314624
(1 row)
osdba=# select pg_relation_size('testtab02');
pg_relation_size
------------------
101138432
(1 row)
PS:因为表“'testtab01”大于“'testtab02”,所以Hash Join是先在较小的表“testtab02”上建立散列表,然后扫描较大的表“testtab01”并探测散列表,找出与散列表匹配的行10. 合并连接
通常情况下,散列连接的效果比合并连接要好,然而如果源数据上有索引,或者结果已经被排过序,此时执行排序合并连接不需要再进行排序,合并连接的性能会优于散列连接。
1)表“testtab01”的“id”字段上有索引,表“testtab02”的“id”字段上也有索引,这时从索引扫描的数据已经排好序了,就可以直接进行合并连接(Merge Join)
osdba=# explain select a.id,b.id,a.note from testtab01 a, testtab02 b where a.id=b.id and b.id<=100000;
QUERY PLAN
--------------------------------------------------------------------------------
Merge Join (cost=1.47..47922.57 rows=99040 width=93)
Merge Cond: (a.id = b.id)
-> Index Scan using idx_testtab01_id on testtab01 a (cost=0.43..413538.43 rows=10000000 width=89)
-> Index Only Scan using idx_testtab02_id on testtab02 b (cost=0.42..4047.63 rows=99040 width=4)
Index Cond: (id <= 100000)
(5 rows)2)把表“testtab02”上的索引删除,下面的示例中的执行计划是把testtab02排序后再走Merge Join
osdba=# drop index idx_testtab02_id;
DROP INDEX
osdba=# explain select a.id,b.id,a.note from testtab01 a, testtab02 b where a.id=b.id and b.id<=100000;
QUERY PLAN
--------------------------------------------------------------------------------
Merge Join (cost=34419.21..78788.84 rows=99040 width=93)
Merge Cond: (a.id = b.id)
-> Index Scan using idx_testtab01_id on testtab01 a (cost=0.43..413538.43 rows=10000000 width=89)
-> Materialize (cost=34418.70..34913.90 rows=99040 width=4)
-> Sort (cost=34418.70..34666.30 rows=99040 width=4)
Sort Key: b.id
-> Seq Scan on testtab02 b (cost=0.00..24846.00 rows=99040 width=4)
Filter: (id <= 100000)
(8 rows)PS:从上面的执行计划中可以看到“Sort Key:b.id”,就是对表“testtab02”的“id”字段进行排序相关文章:

PostgreSQL执行计划
1. EXPLAIN命令 1)PostgreSQL中EXPLAIN命令的语法格式: postgres# \h explain Command: EXPLAIN Description: show the execution plan of a statement Syntax: EXPLAIN [ ( option [, ...] ) ] statement EXPLAIN [ ANALYZE ] [ VERBOSE ] statementwhere option can be…...

【2023 睿思芯科 笔试题】~ 题目及参考答案
文章目录 1. 题目 & 答案单选题编程题问题1:解析1:问题2:解析2: 声明 名称如标题所示,希望大家正确食用(点赞转发评论) 本次笔试题以两种形式考察的,分别是:选择题&a…...

Java手写AVL树
Java手写AVL树 1. AVL树实现思路原理 为了解释AVL树的实现思路原理,下面使用Mermanid代码表示该算法的思维导图: #mermaid-svg-ycH8kKpzVk2HWEby {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid…...

运维自动化:提高效率的秘诀
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
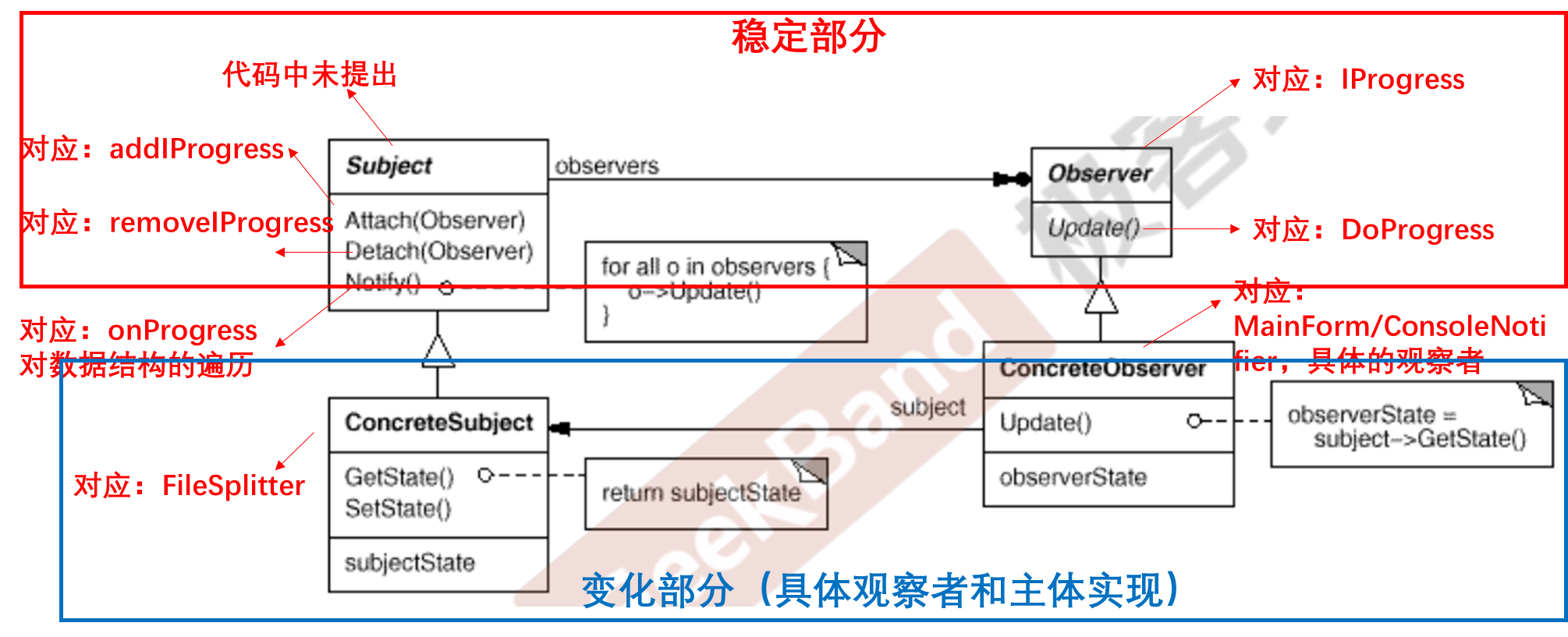
C++设计模式_05_Observer 观察者模式
接上篇,本篇将会介绍C设计模式中的Observer 观察者模式,和前2篇模板方法Template Method及Strategy 策略模式一样,仍属于“组件协作”模式。Observer 在某些领域也叫做 Event 。 文章目录 1. 动机( Motivation)2. 代码…...

github网站打不开,hosts文件配置
首先获取github官网的ip地址, 打开cmd,输入ping github.com 配置: #github 140.82.114.4 github.com 199.232.69.194 github.global.ssl.fastly.net 185.199.108.153 assets-cdn.github.com 185.199.110.153 assets-cdn.github.com 185.199…...

总结PCB设计的经验
一般PCB基本设计流程如下:前期准备->PCB结构设计->PCB布局->布线->布线优化和丝印->网络和DRC检查和结构检查->制版。: : 第一:前期准备。这包括准备元件库和原理图。“工欲善其事,必先利其器”,要做出一…...
HCIE-HCS规划设计搭建
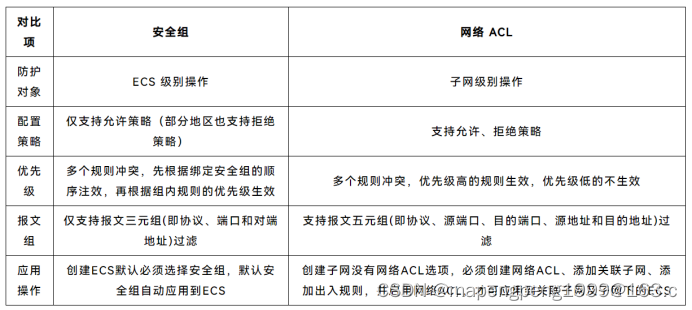
1、相关术语 1、等价路由 等价路由(Equal-cost routing)是一种网络路由策略,用于在网络中选择多个具有相同路由度量(路由距离或成本)的最佳路径之一来转发数据流量。 当存在多个路径具有相同的路由度量时,…...

c语言输出杨辉三角
#include<stdio.h> int main() {int x 0; //表示杨辉三角的的大小int y 1;printf("请输入x的值: ");scanf("%d", &x);for (int i 0; i < x; i) {for (int j 0; j < i; j) {if (j 0 || i 0) {y 1;}else {y y * (i - j 1) / j;}pri…...
)
性能测试-持续测试及性能测试建设(22)
什么是持续测试? 持续测试定义为:在软件交付流水线中执行自动化测试的过程,目的是获得关于预发布软件业务风险的即时反馈。 完成持续测试,我们还是需要回到定义中,它有3个关键词:软件交付流水线、自动化测试、即时反馈。 首先,持续测试需要具备一条完整的流水线,其代表…...

嵌入式C 语言中的三块技术难点
C 语言在嵌入式学习中是必备的知识,甚至大部分操作系统都要围绕 C 语言进行,而其中有三块技术难点,几乎是公认级别的“难啃的硬骨头”。 今天就来带你将这三块硬骨头细细拆解开来,一定让你看明白了。 0x01 指针 指针是公认…...

【斗破年番】紫研新形象,萧炎终成翻海印,救援月媚,三宗决战
Hello,小伙伴们,我是小郑继续为大家深度解析斗破年番。 斗破苍穹年番动画更新了,小医仙帅气回归,萧炎紫妍成功进入山谷闭关苦修,美杜莎女王守护没多久,就因蛇人族求救离开。从官方公布的最新预告来看,萧炎紫…...
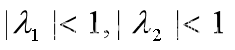
差分方程模型:国民总收入(GDP)的乘数-加速数模型
【背景知识-凯恩斯经济增长模型】 凯恩斯(John M.Keynes)建立了著名的国民经济增长模型。令Y表示国民总收入,C表示总消费,E为总支出,I表示投资,G为政府的投入(如基建等)。那么有 【6.1】 其中࿰…...

【C语言】指针和数组笔试题解析(1)
指针是C语言的灵魂,他的玩法多种多样,这篇文章带来指针的笔试题详解,可以帮助我们更好的理解与巩固指针的知识 目录 预备知识:题目:一维数组:二维数组: 题目比较多,但切记戒骄戒躁&a…...

Vue中组件的三种注册方式
组件的注册 1.全局注册: 在全局注册中,你需要确保在 Vue 根实例之前导入并注册组件。通常,你会在入口文件(例如 main.js)中执行这些操作。 // main.jsimport Vue from vue; import App from ./App.vue;// 导入全局组…...
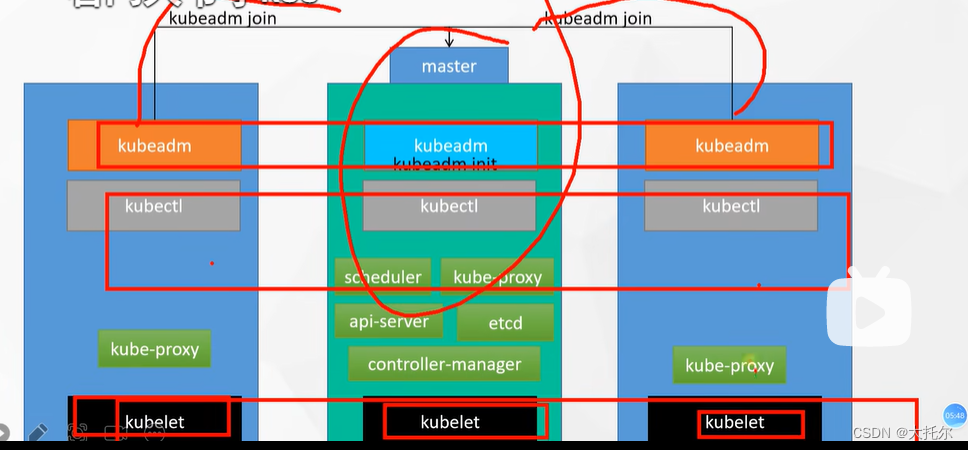
docker 和k8s 入门
docker 和k8s 入门 本文是云原生的学习记录,可以参考以下文档 k8s https://www.yuque.com/leifengyang/oncloud 相关视频教程可参考如下 https://www.bilibili.com/video/BV13Q4y1C7hS?p2&vd_source0882f549dac54045384d4a921596e234 相对于公有云&#x…...

基于Yolov8的交通标志牌(TT100K)识别检测系统
1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上,并引入了新功能和改进,以进一步提升性能和灵活…...

使用Python编写一个多线程的12306抢票程序
国庆长假即将到来,大家纷纷计划着自己的旅行行程。然而,对于很多人来说,抢购火车票人们成了一个令人头疼的问题。12306网站的服务器经常因为流量高而崩溃,导致抢票变得越来越严重异常困难。 首先,让我们来了解一下1230…...

DT Paint Effects工具(三)
管 分支 使用细枝 叶 力 使用湍流 流动画 渲染全局参数 建造盆栽植物...
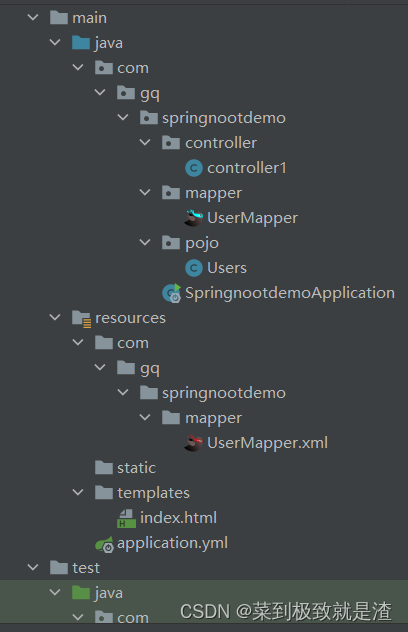
SpringBoot整合Mybatis
目录 (1)引入依赖 (2)编写Mapper接口 (3)编写Mapper映射文件 (4)编写yml配置文件 (5)编写测试类 (1)引入依赖 <dependency>…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...
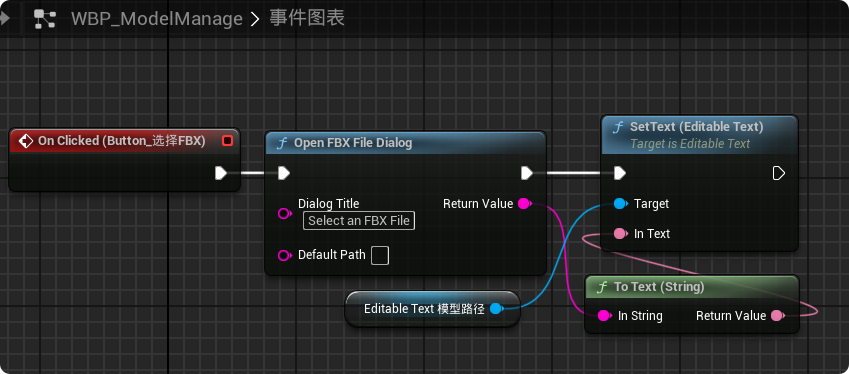
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...