Mysql详解Explain索引优化最佳实践
目录
- 1 Explain工具介绍
- 2 explain 两个变种
- 3 explain中的列
- 3.1 id列
- 3.2 select_type列
- 3.3 table列
- 3.4. type列
- 3.5 possible_keys列
- 3.6 key列
- 3.7 key_len列
- 3.8 ref列
- 3.9 rows列
- 3.10 Extra列
- 4 索引最佳实践
- 4.1.全值匹配
- 4.2.最左前缀法则
- 4.3.不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 4.4.存储引擎不能使用索引中范围条件右边的列
- 4.5.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
- 4.6.mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描
- 4.7.is null,is not null 一般情况下也无法使用索引
- 4.8.like以通配符开头('$abc...')mysql索引失效会变成全表扫描操作
- 4.9.字符串不加单引号索引失效
- 4.10.少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化
- 4.11.范围查询优化
1 Explain工具介绍

使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈
在 select 语句之前增加 explain 关键字 ,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL
注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中
Explain分析示例
参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
示例表:
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (`id` int(11) NOT NULL,`name` varchar(45) DEFAULT NULL,`update_time` datetime DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `actor` (`id`, `name`, `update_time`) VALUES (1,'a','2017-12-22 15:27:18'), (2,'b','2017-12-22 15:27:18'), (3,'c','2017-12-22 15:27:18');DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `film` (`id`, `name`) VALUES (3,'film0'),(1,'film1'),(2,'film2');DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (`id` int(11) NOT NULL,`film_id` int(11) NOT NULL,`actor_id` int(11) NOT NULL,`remark` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `film_actor` (`id`, `film_id`, `actor_id`) VALUES (1,1,1),(2,1,2),(3,2,1);mysql> explain select * from actor;
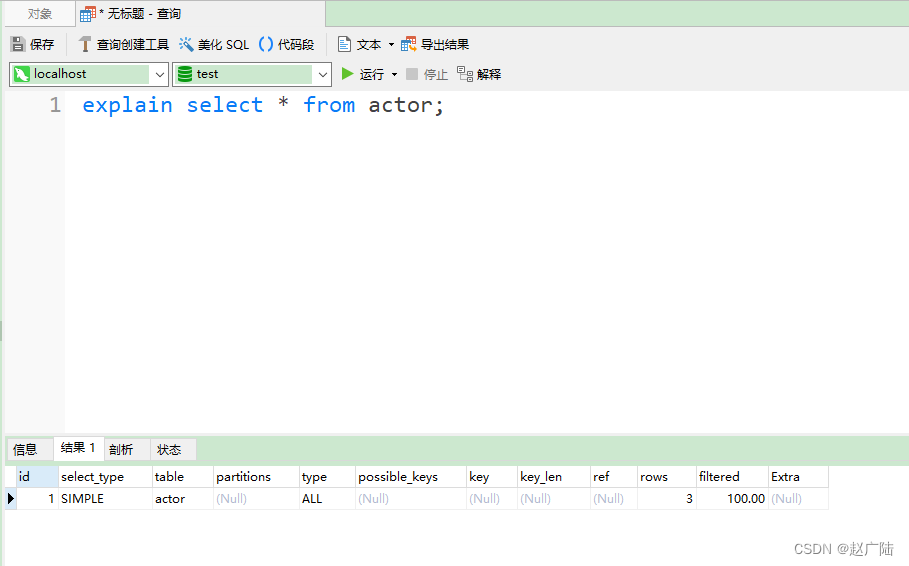
在查询中的每个表会输出一行,如果有两个表通过 join 连接查询,那么会输出两行
2 explain 两个变种
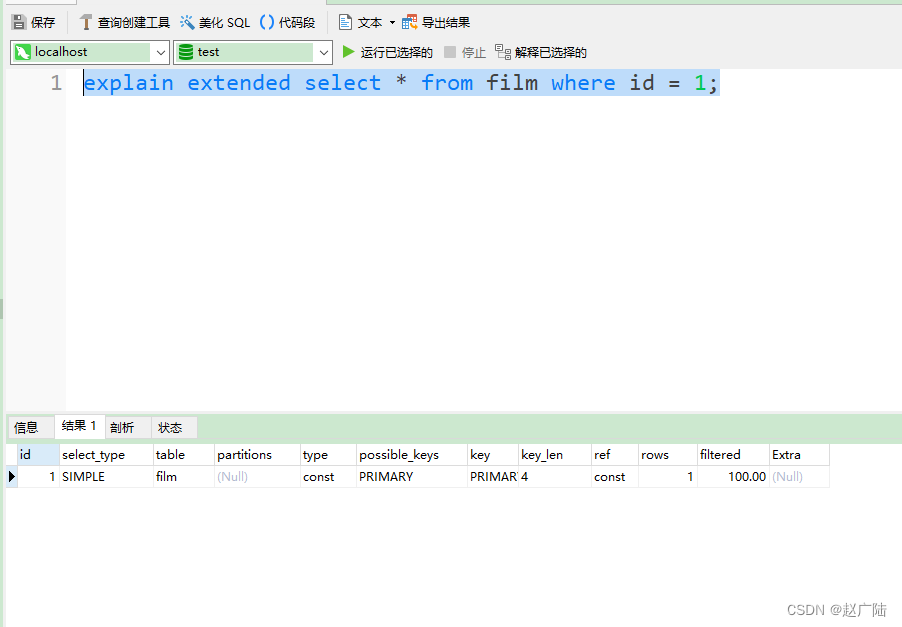
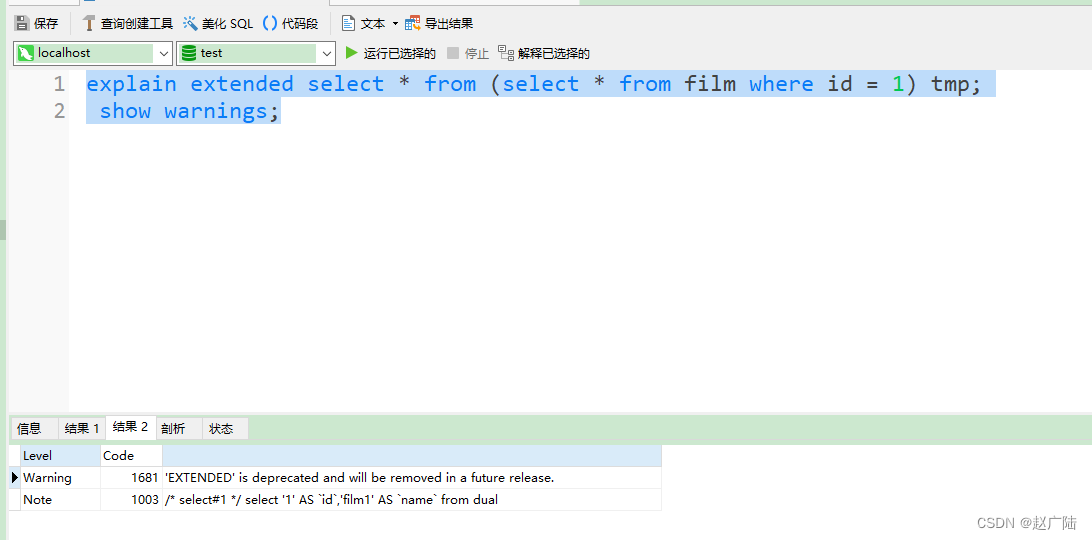
1)explain extended:会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可以得到优化后的查询语句,从而看出优化器优化了什么。额外还有 filtered 列,是一个百分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
mysql> explain extended select * from film where id = 1;
mysql> show warnings;
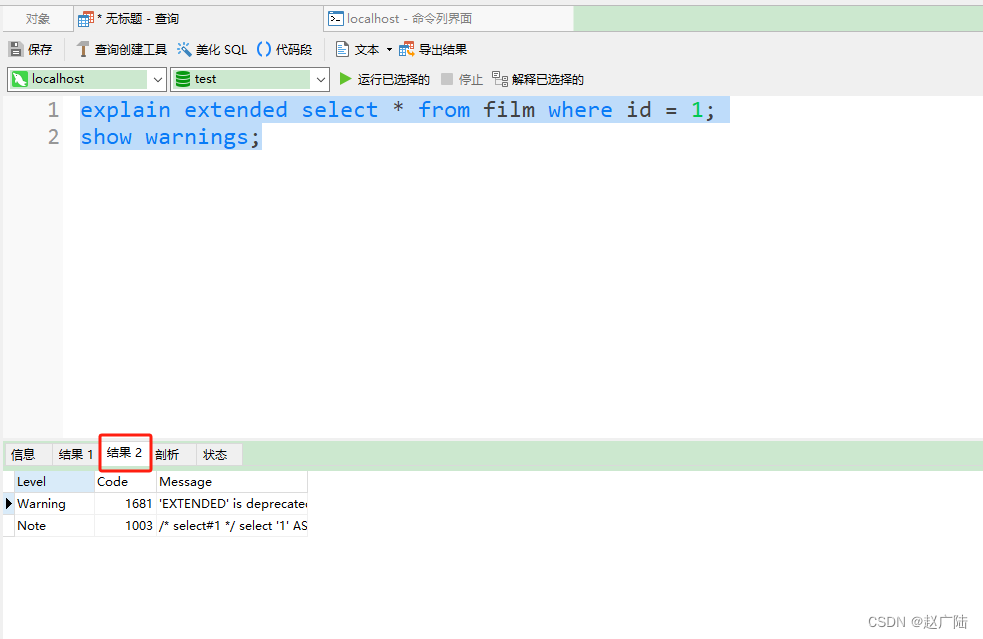
/* select#1 */ select '1' AS `id`,'film1' AS `name` from `test`.`film` where 1
2)explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
3 explain中的列
接下来我们将展示 explain 中每个列的信息。
3.1 id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
3.2 select_type列
select_type 表示对应行是简单还是复杂的查询。
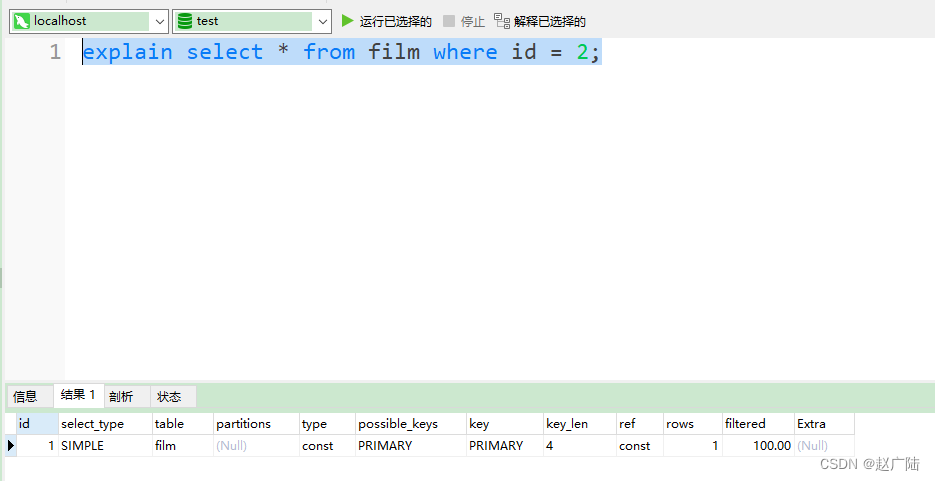
1)simple:简单查询。查询不包含子查询和union
mysql> explain select * from film where id = 2;
2)primary:复杂查询中最外层的 select
3)subquery:包含在 select 中的子查询(不在 from 子句中)
4)derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
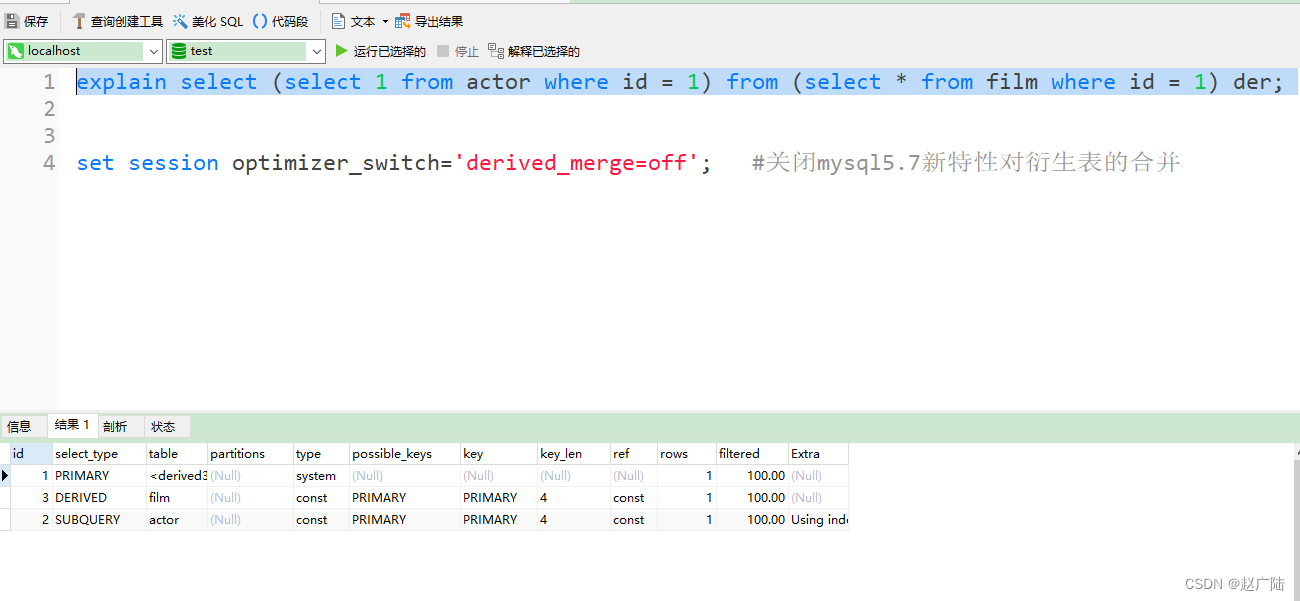
用这个例子来了解 primary、subquery 和 derived 类型
mysql> set session optimizer_switch='derived_merge=off'; #关闭mysql5.7新特性对衍生表的合并
优化
mysql> explain select (select 1 from actor where id = 1) from (select * from film where id = 1) der;
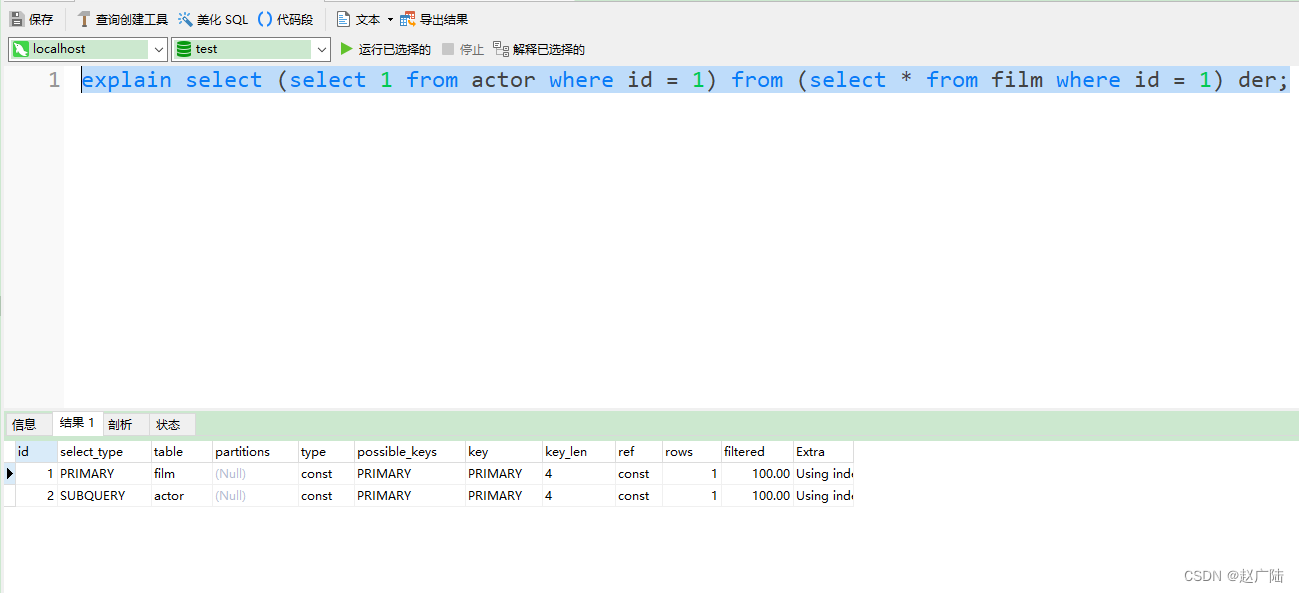
mysql> set session optimizer_switch='derived_merge=on'; #还原默认配置
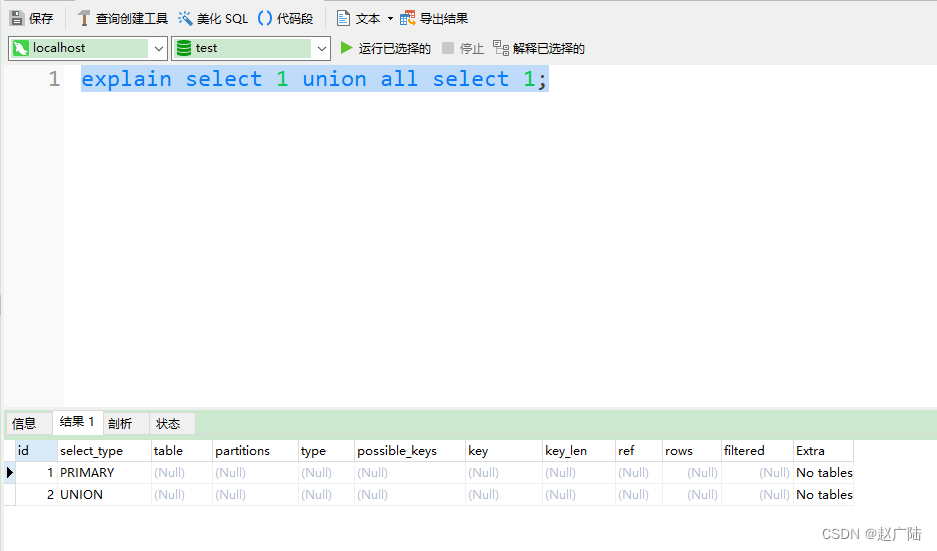
5)union:在 union 中的第二个和随后的 select
mysql> explain select 1 union all select 1;
3.3 table列
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。
当有 union 时,UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 select 行id。
3.4. type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
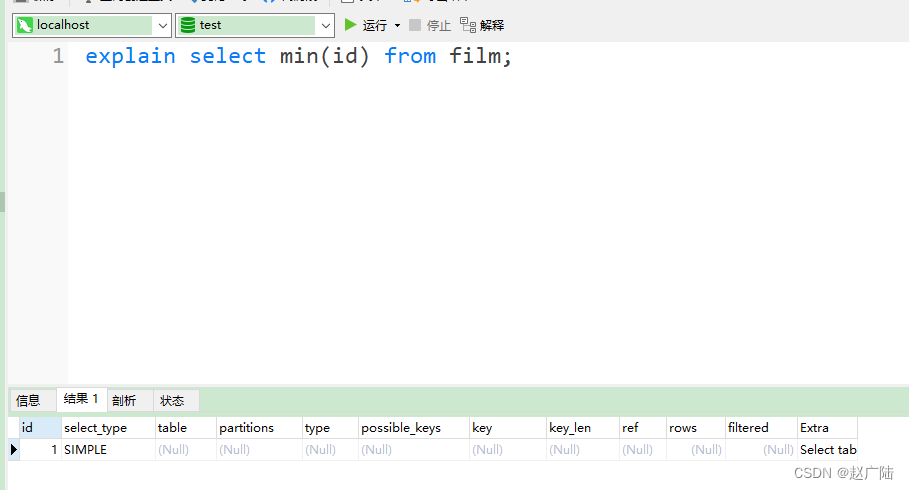
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表
mysql> explain select min(id) from film;
const, system:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。system是const的特例,表里只有一条元组匹配时为system
mysql> explain extended select * from (select * from film where id = 1) tmp;
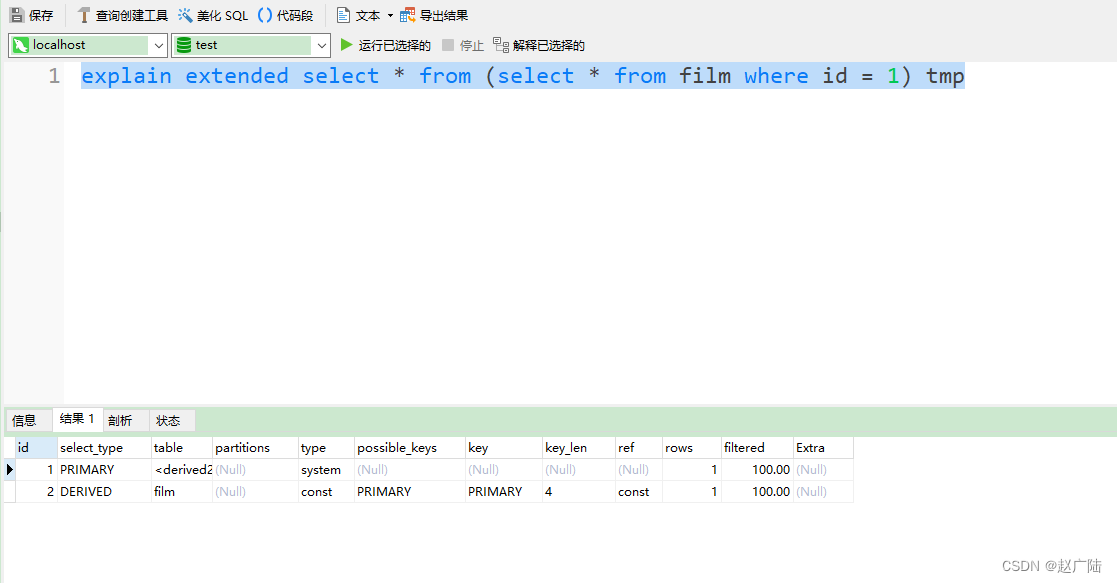
mysql> show warnings;
eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在 const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
mysql> explain select * from film_actor left join film on film_actor.film_id = film.id;
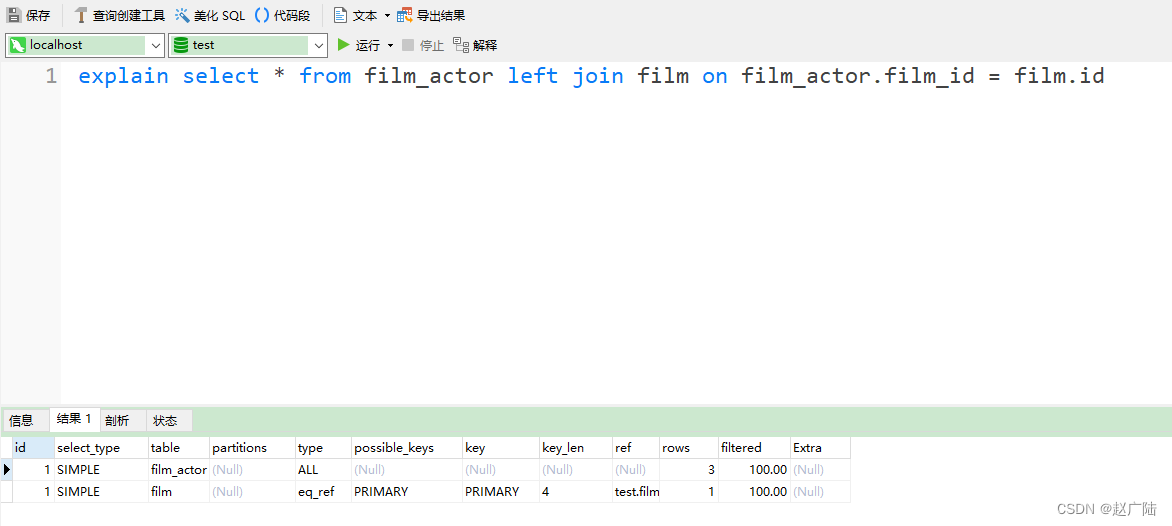
虽然都是1但是是从上到下执行
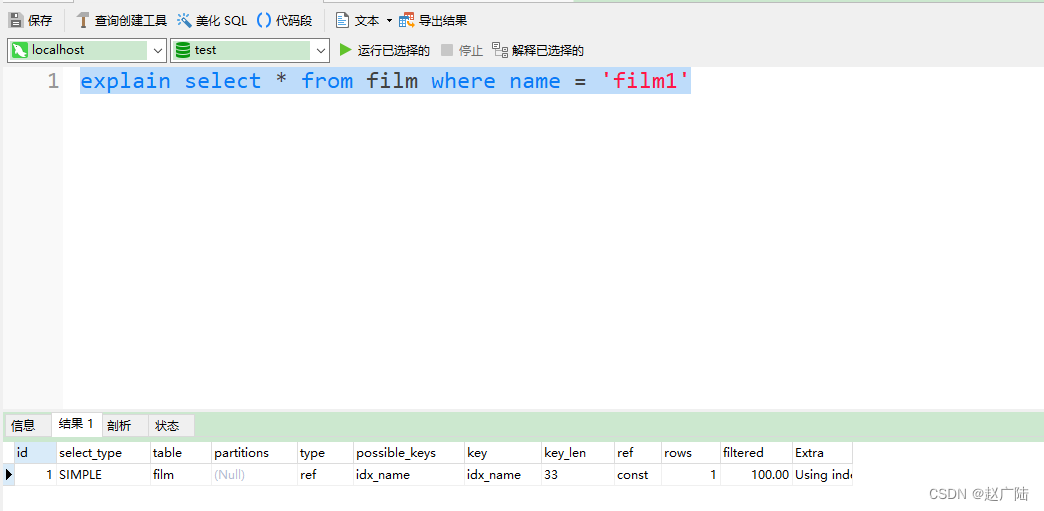
ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
- 简单 select 查询,name是普通索引(非唯一索引)
mysql> explain select * from film where name = ‘film1’;

2.关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
mysql> explain select film_id from film left join film_actor on film.id = film_actor.film_id;
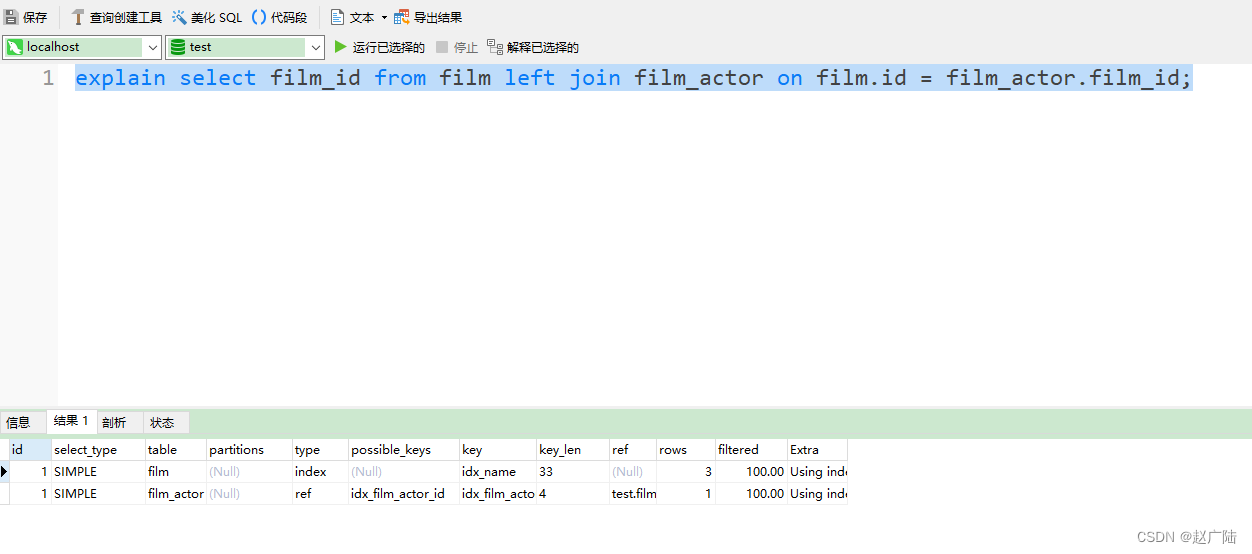
range:范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
mysql> explain select * from actor where id > 1;
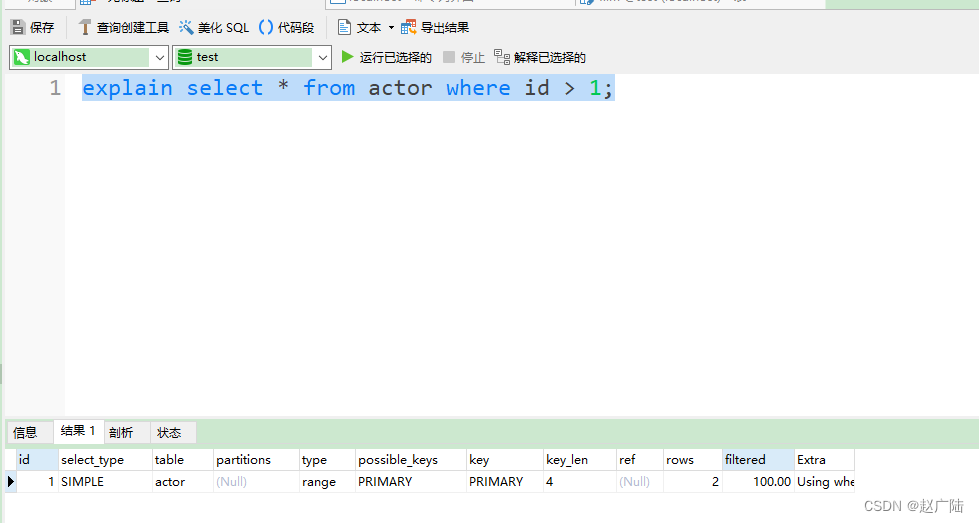
index:扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
mysql> explain select * from film;
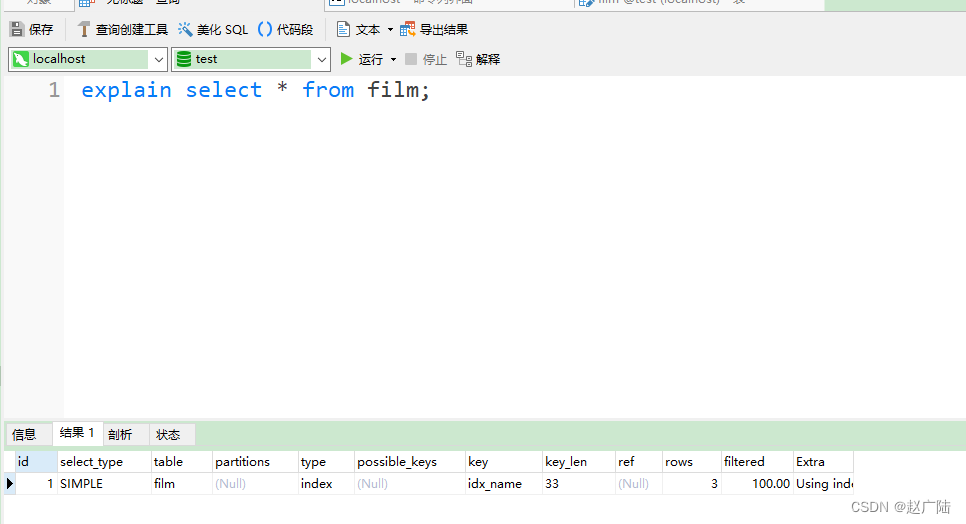
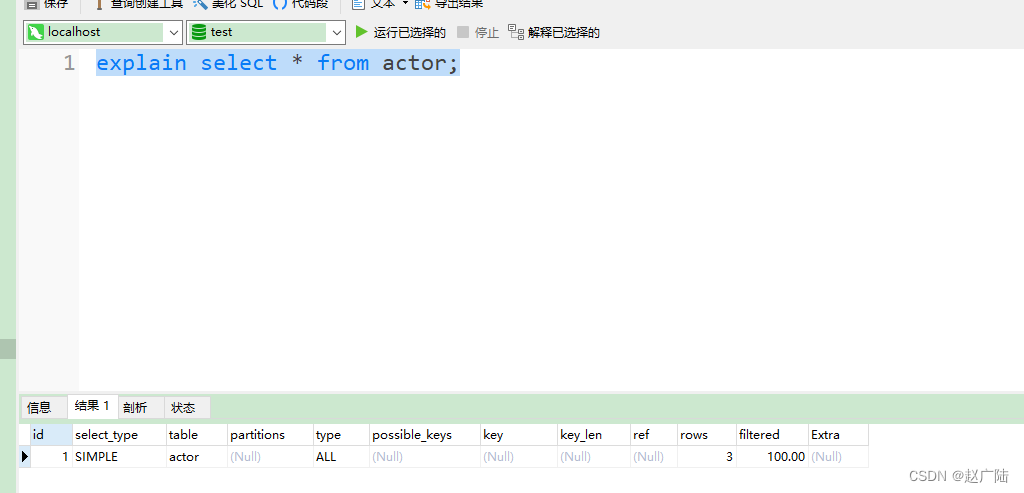
ALL:即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
mysql> explain select * from actor;
3.5 possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
3.6 key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
3.7 key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
mysql> explain select * from film_actor where film_id = 2;
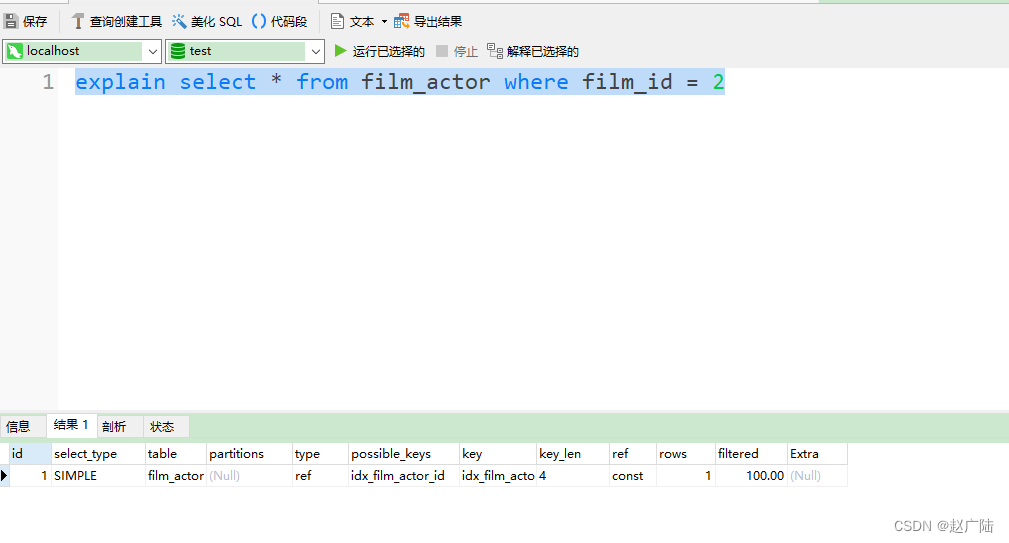
key_len计算规则如下:
字符串,char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,如果是utf-8,一个数字或字母占1个字节,一个汉字占3个字节
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为varchar是变长字符串
数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
3.8 ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
3.9 rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
3.10 Extra列
这一列展示的是额外信息。常见的重要值如下:
1)Using index:使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值
mysql> explain select film_id from film_actor where film_id = 1;
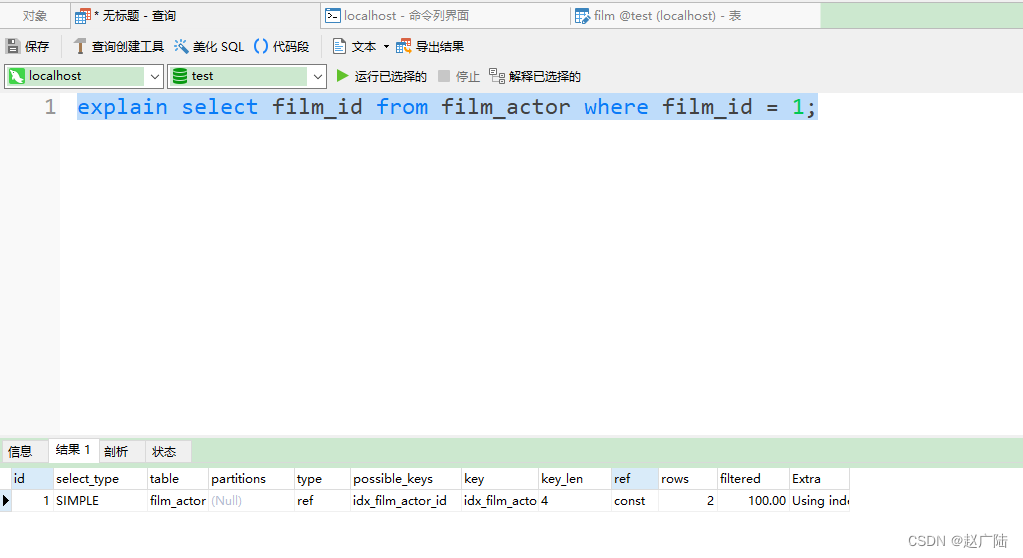
2)Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
mysql> explain select * from actor where name = ‘a’;
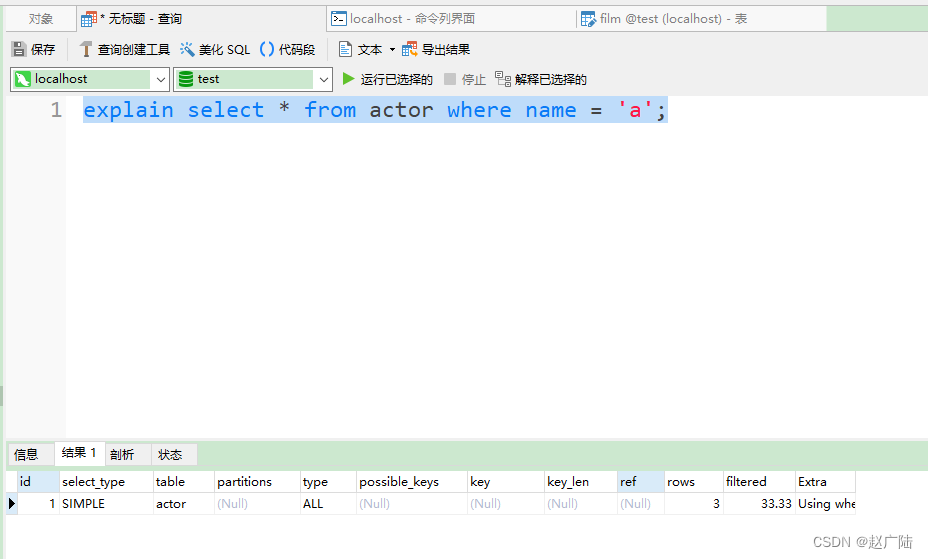
3)Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
mysql> explain select * from film_actor where film_id > 1;
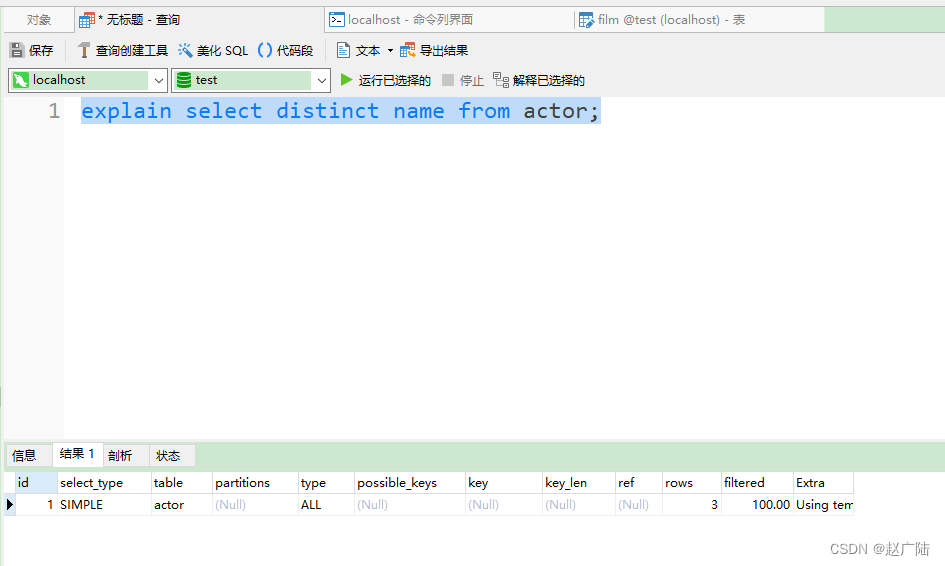
4)Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
- actor.name没有索引,此时创建了张临时表来distinct
mysql> explain select distinct name from actor;
- film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表
mysql> explain select distinct name from film;

5)Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
- actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录
mysql> explain select * from actor order by name;
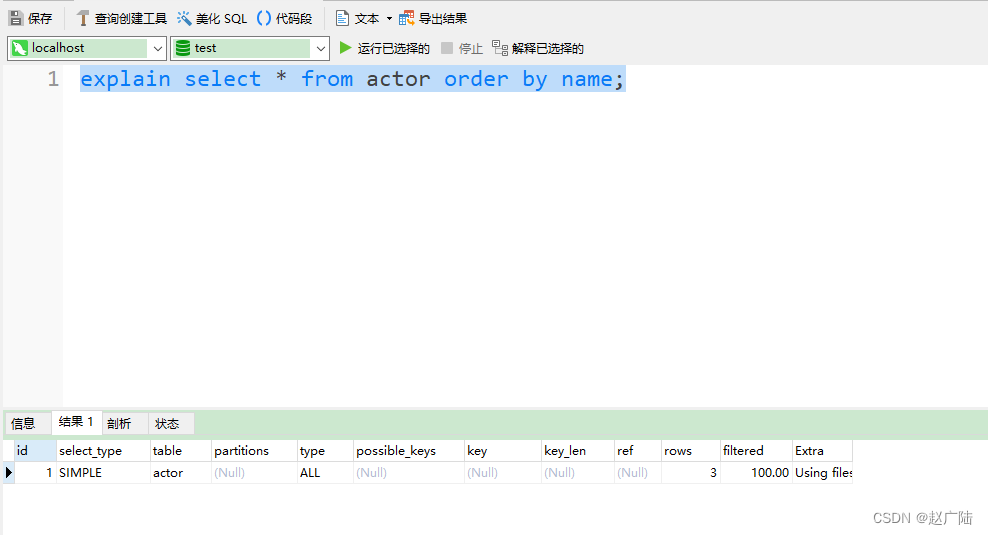
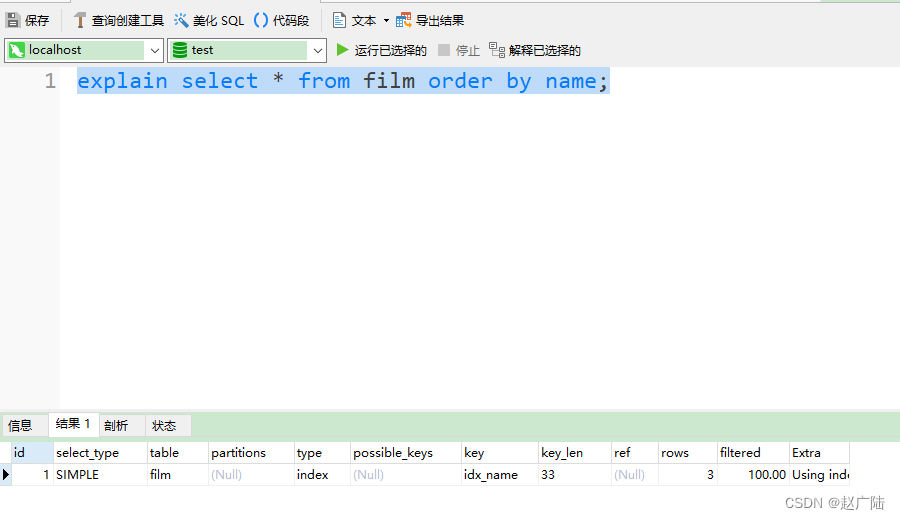
- film.name建立了idx_name索引,此时查询时extra是using index
mysql> explain select * from film order by name;
6)Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段是
mysql> explain select min(id) from film;

4 索引最佳实践
示例表:
CREATE TABLE `employees` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',PRIMARY KEY (`id`),KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
4.1.全值匹配
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei';
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22;
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
4.2.最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';
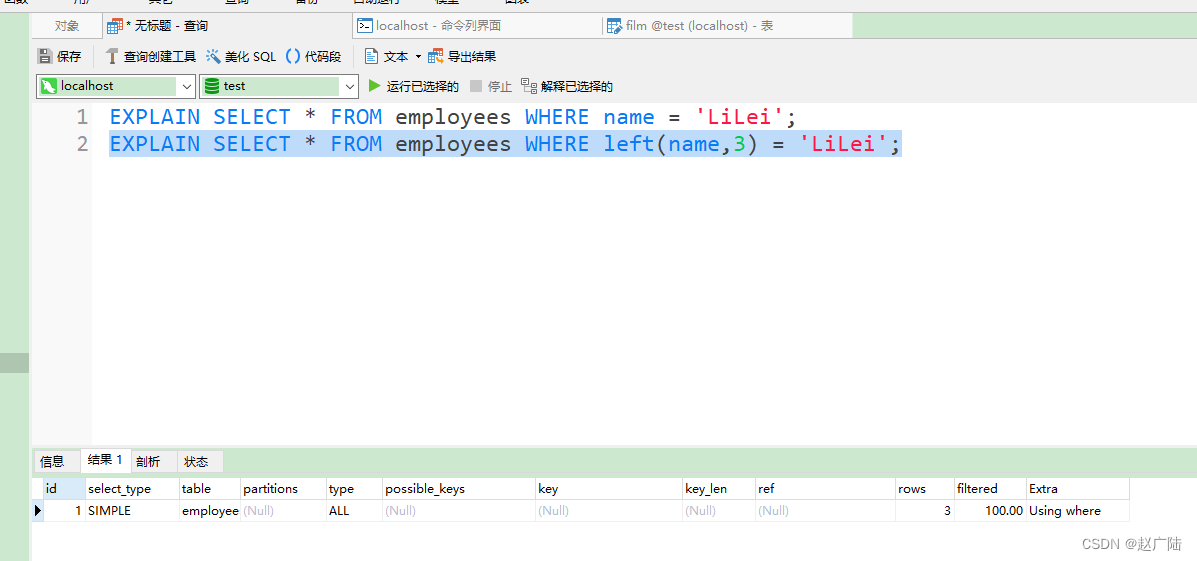
4.3.不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';
EXPLAIN SELECT * FROM employees WHERE left(name,3) = 'LiLei';
给hire_time增加一个普通索引:
ALTER TABLE `employees` ADD INDEX `idx_hire_time` (`hire_time`) USING BTREE ;
EXPLAIN select * from employees where date(hire_time) ='2018-09-30';

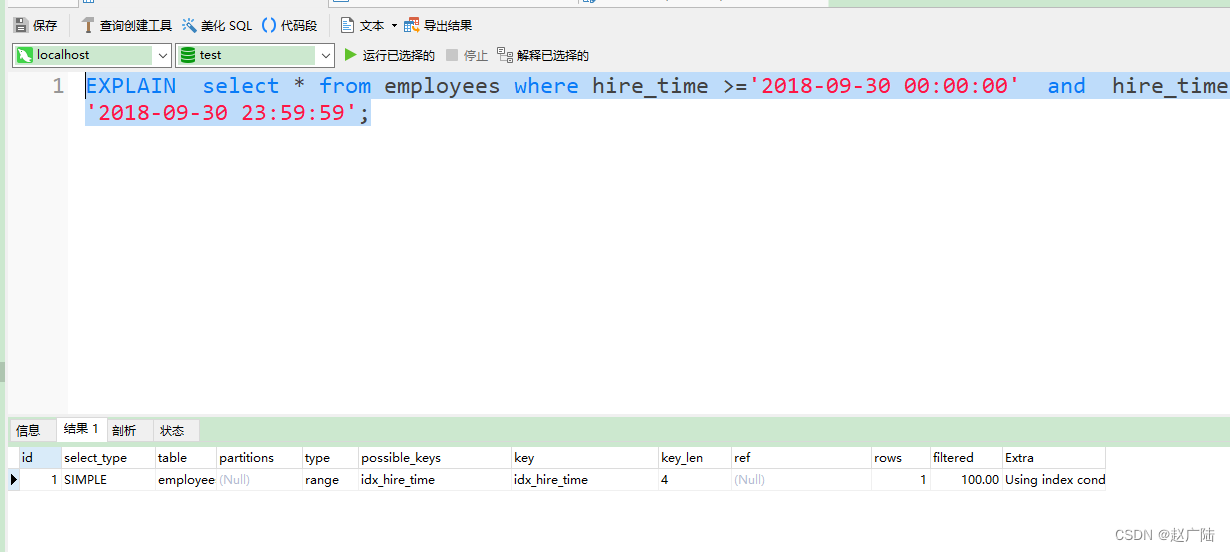
转化为日期范围查询,有可能会走索引:
EXPLAIN select * from employees where hire_time >=‘2018-09-30 00:00:00’ and hire_time <=‘2018-09-30 23:59:59’;
还原最初索引状态
ALTER TABLE employees DROP INDEX idx_hire_time;
4.4.存储引擎不能使用索引中范围条件右边的列
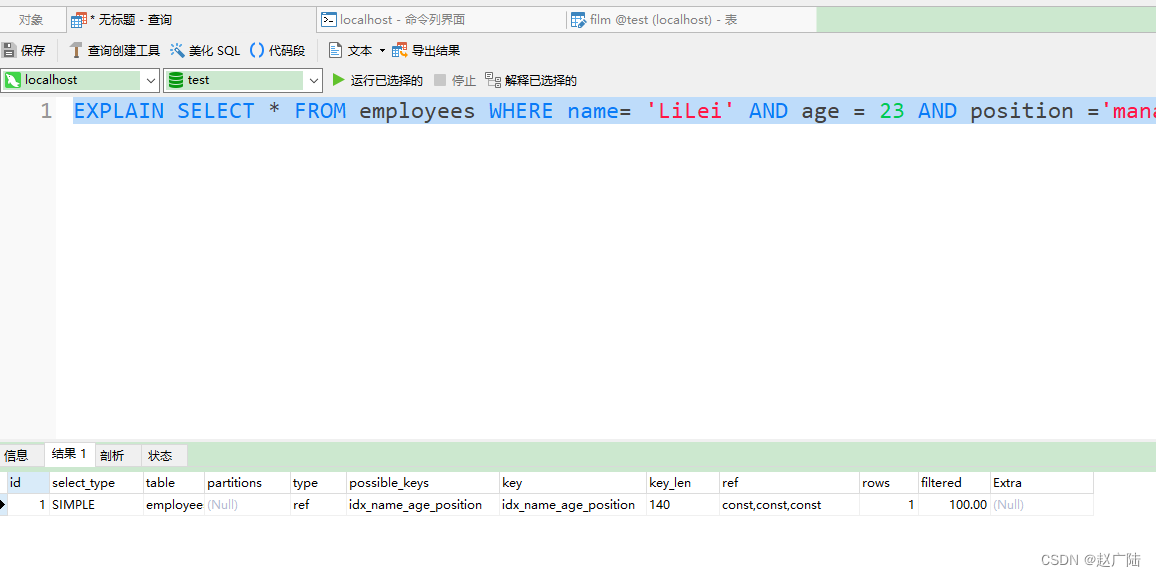
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';
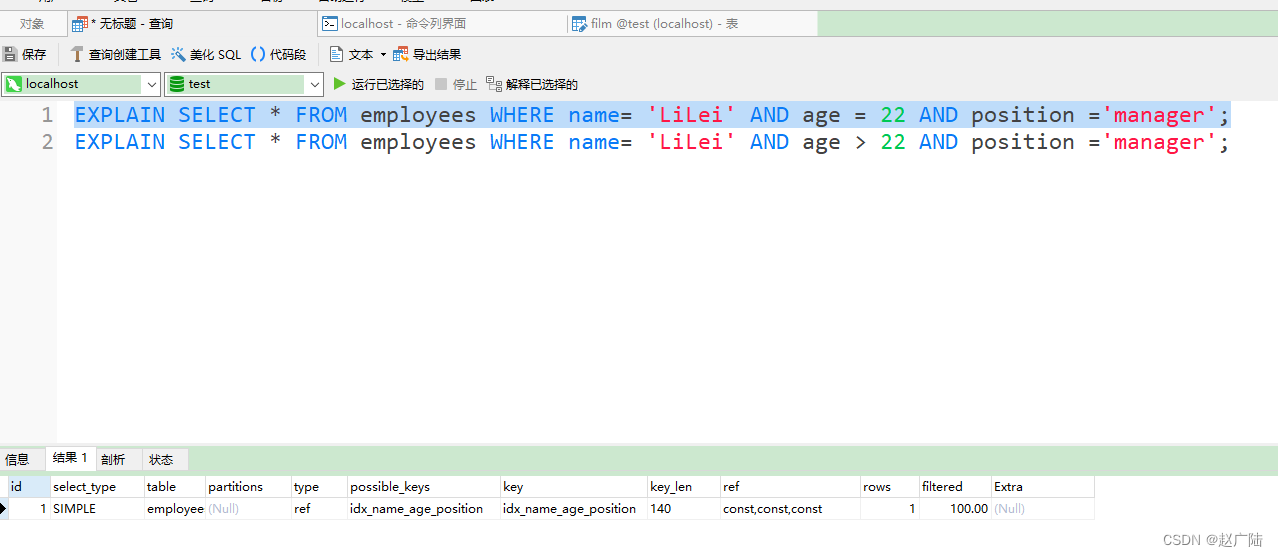

4.5.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
EXPLAIN SELECT name,age FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
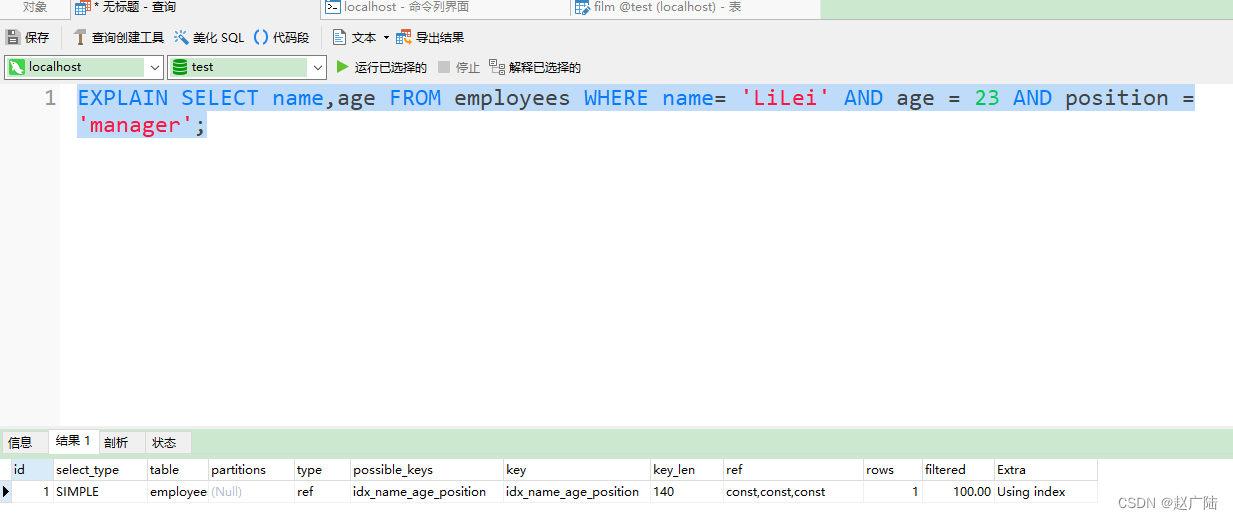
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
查询全部字段会进行一个回表增加磁盘IO
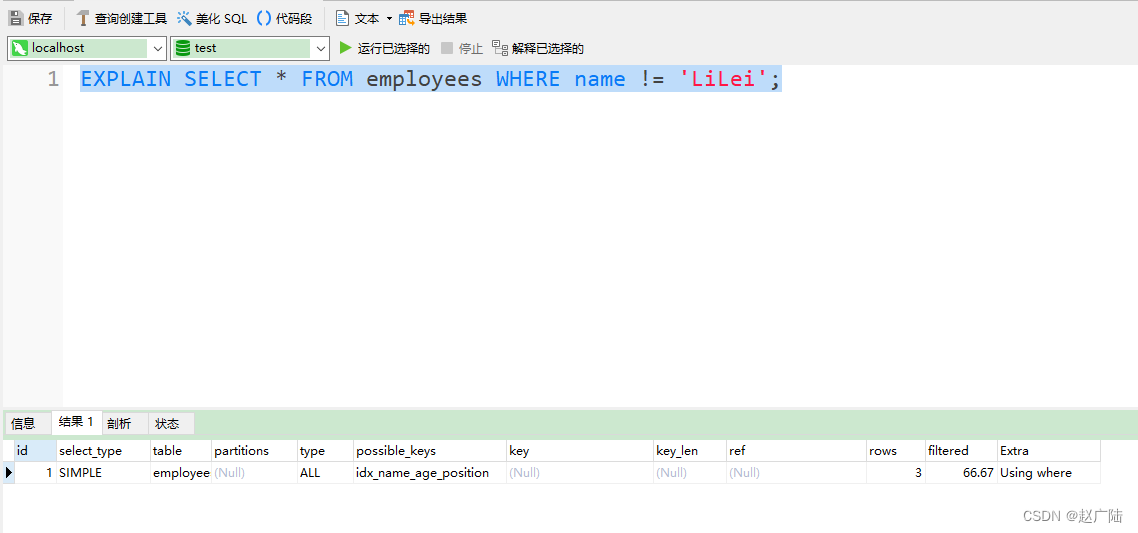
4.6.mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描
< 小于、 > 大于、 <=、>= 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
EXPLAIN SELECT * FROM employees WHERE name != 'LiLei';
4.7.is null,is not null 一般情况下也无法使用索引
EXPLAIN SELECT * FROM employees WHERE name is null
4.8.like以通配符开头(‘$abc…’)mysql索引失效会变成全表扫描操作
EXPLAIN SELECT * FROM employees WHERE name like '%Lei'
EXPLAIN SELECT * FROM employees WHERE name like 'Lei%'
问题:解决like’%字符串%'索引不被使用的方法?
a)使用覆盖索引,查询字段必须是建立覆盖索引字段
EXPLAIN SELECT name,age,position FROM employees WHERE name like ‘%Lei%’;
b)如果不能使用覆盖索引则可能需要借助搜索引擎
4.9.字符串不加单引号索引失效
EXPLAIN SELECT * FROM employees WHERE name = '1000';
EXPLAIN SELECT * FROM employees WHERE name = 1000;
4.10.少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引,详见范围查询优化
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' or name = 'HanMeimei';
4.11.范围查询优化
给年龄添加单值索引
ALTER TABLE `employees` ADD INDEX `idx_age` (`age`) USING BTREE ;
explain select * from employees where age >=1 and age <=2000;
没走索引原因:mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。比如这个例子,可能是由于单次数据量查询过大导致优化器最终选择不走索引
优化方法:可以将大的范围拆分成多个小范围
explain select * from employees where age >=1 and age <=1000;
explain select * from employees where age >=1001 and age <=2000;
还原最初索引状态
ALTER TABLE `employees` DROP INDEX `idx_age`;
索引使用总结:
like KK%相当于=常量,%KK和%KK% 相当于范围
相关文章:
Mysql详解Explain索引优化最佳实践
目录 1 Explain工具介绍2 explain 两个变种3 explain中的列3.1 id列3.2 select_type列3.3 table列3.4. type列3.5 possible_keys列3.6 key列3.7 key_len列3.8 ref列3.9 rows列3.10 Extra列 4 索引最佳实践4.1.全值匹配4.2.最左前缀法则4.3.不在索引列上做任何操作(计…...

STM32H7 Azure RTOS
STM32H7 是意法半导体(STMicroelectronics)推出的一款高性能微控制器系列,基于 Arm Cortex-M7 内核。它具有丰富的外设和高性能计算能力,适用于各种应用领域。 Azure RTOS(原名 ThreadX)是一款实时操作系统…...

基于LUT查找表方法的图像gamma校正算法FPGA实现,包括tb测试文件和MATLAB辅助验证
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 将gamma2.2和gamma1/2.2的数据分别导入到matlab进行对比: 2.算法运行软件版本 matlab2022a 3.部分核心程序 timescale 1ns / 1ps //…...

Function模块
0 Preface/Foreword 1 数据结构 1.1 func_cb_t //task control block typedef struct {u8 sta; //cur working task numberu8 last; //lask task number #if BT_BACKSTAGE_ENu8 sta_break…...

Prometheus PromQL数据查询语言
PromQL 简介 PromQL(Prometheus Query Language)是 Prometheus 内置的数据查询语言。支持用户进行实时的数据查询及聚合操作。 Prometheus 基于指标名称(metrics name)以及附属的标签集(labelset)唯一定义一…...
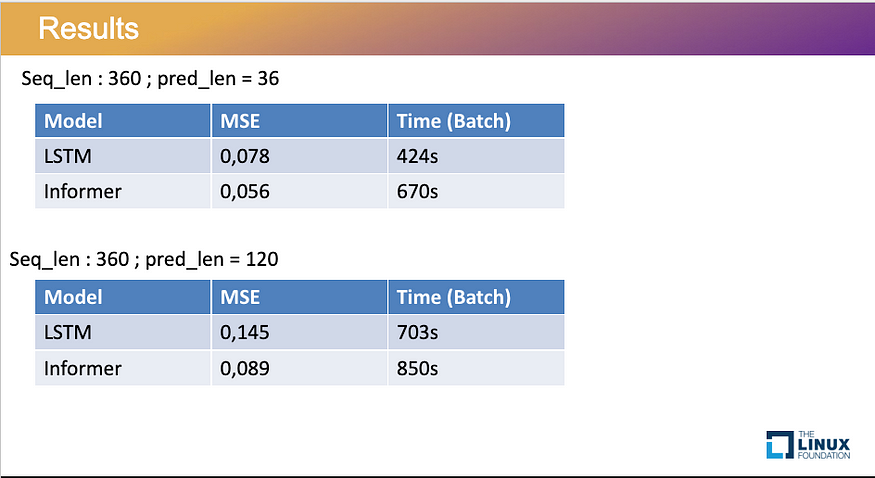
如何将转换器应用于时序模型
一、说明 在机器学习的广阔环境中,变压器作为建筑奇迹屹立不倒,以其复杂的设计和捕获复杂关系的能力重塑了我们处理和理解大量数据的方式。 自 2017 年创建第一台变压器以来,变压器类型呈爆炸式增长,包括强大的生成 AI 模型&#…...

数据结构:队列
文章目录 队列一,概述二,添加数据三,删除数据 队列 一,概述 队列是一种特殊的数据结构,它遵循先进先出(FIFO)的原则。在队列中,元素被添加到末尾,并从头部移除。队列只…...

AUTOSAR汽车电子嵌入式编程精讲300篇-基于AUTOSAR架构的AT控制系统研究与实现
目录 前言 国内外研究现状 国外研究现状 国内研究现状 2 AUTOSAR规范及开发流程...
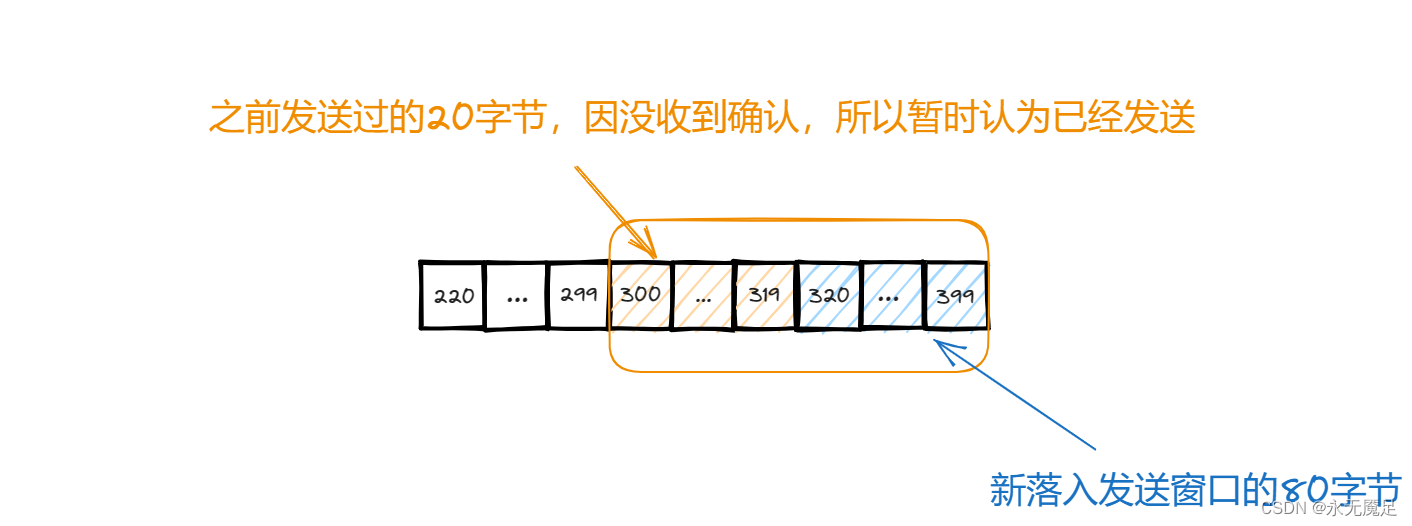
计网第五章(运输层)(四)(TCP的流量控制)
一、基本概念 流量控制就是指让发送方的发送速率不要太快,使得接收方来得及接收。可以使用滑动窗口机制在TCP连接上实现对发送方的流量控制。 注意:之前在讨论可靠传输时,讨论过选择重传协议和回退N帧协议都是基于滑动窗口的机制上进行实现…...

【华为OD机试python】查找众数及中位数【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 众数是指一组数据中出现次数最多的那个数,众数可以是多个。 中位数是指把一组数据从小到大排序后,如果这组数据的总数是奇数, 那最中间的那个数就是中位数; 如果这组数据总数是偶数,那…...
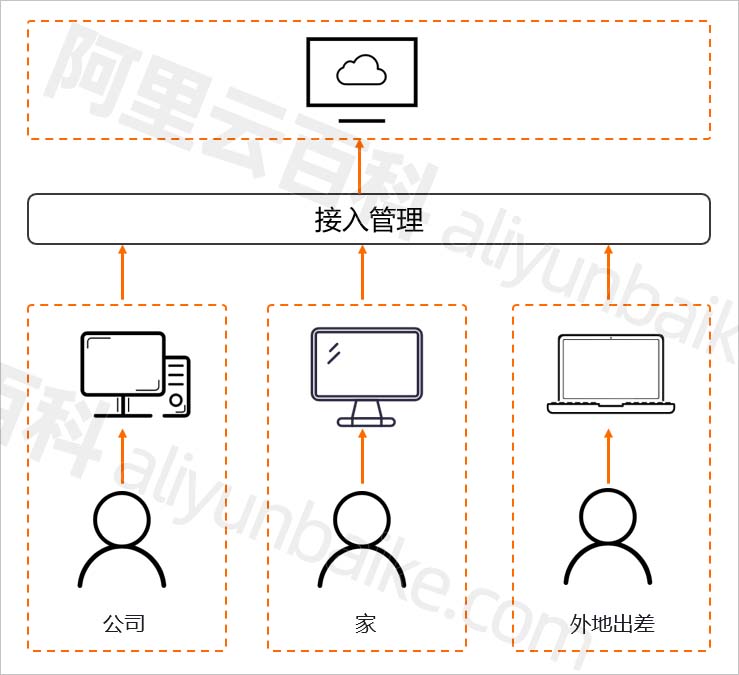
阿里云无影云电脑详细介绍:价格、使用和功能优势说明
什么是阿里云无影云电脑?无影云电脑(原云桌面)是一种快速构建、高效管理桌面办公环境,无影云电脑可用于远程办公、多分支机构、安全OA、短期使用、专业制图等使用场景,阿里云百科分享无影云桌面的详细介绍、租用价格、…...
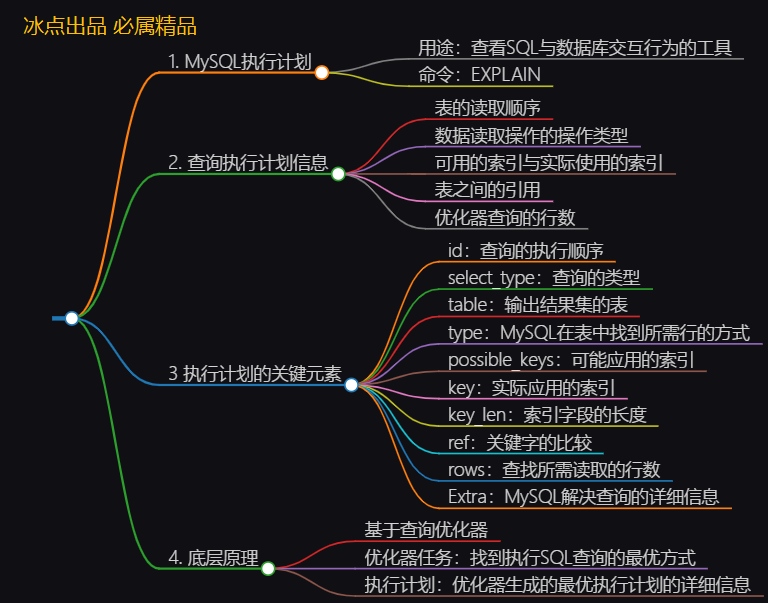
【实践篇】MySQL执行计划详解
文章目录 本文知识大纲速览1. 前言2. 基本介绍1. 什么是执行计划2. 如何查看执行计划3. 执行计划的组成部分 3. 执行计划的关键元素1. id2. select_type3. table:4. type:5. possible_keys:6. key:7. key_len8. ref:9. rows:10. Extra 4. 底层原理5. 执行计划示例解读本文知识图…...
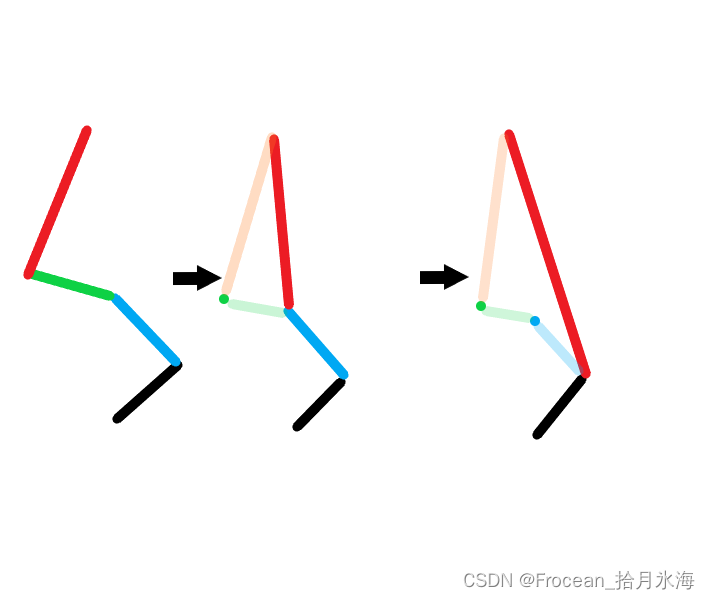
二维凸包(Graham) 模板 + 详解
(闲话) 上了大学后没怎么搞oi,从土木跑路到通信了(提桶开润大成功!),但是一年上两年的课(补的),保研也寄掉了( 说起来自从博客被大学同学发现并…...
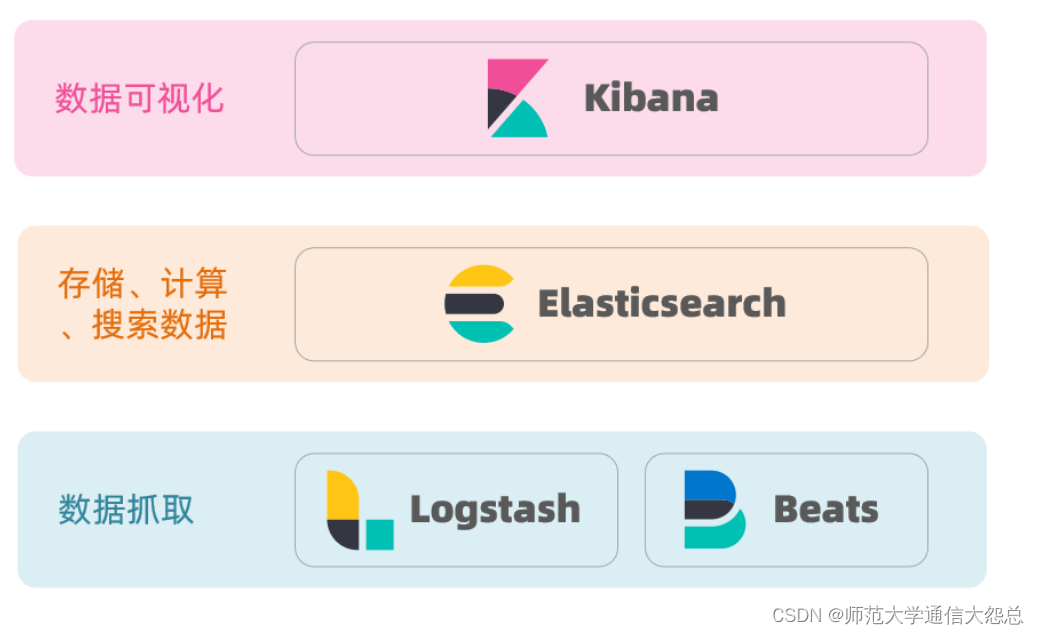
ElasticSearch(ES)简单介绍
ES简介 Elasticsearch(通常简称为ES)是一个开源的分布式搜索和分析引擎,旨在处理各种类型的数据,包括结构化、半结构化和非结构化数据。它最初是为全文搜索而设计的,但随着时间的推移,它已经演变成一个功能…...

OpenCV(三十五):凸包检测
1.凸包检测介绍 凸包检测是计算凸包的一种技术,凸包就是:给定二维平面上的点集,将最外层的点连接起来构成的凸边形,它是包含点集中所有的点。 2.凸包检测函数convexHull() void cv::convexHull ( InputArray points, OutputArra…...
PS 透视裁剪工具
上文 PS 裁剪工具及工具栏配置讲解 我们讲完了裁剪工具 然后 我们继续来研究 透视裁剪工具 切换到 透视裁剪工具 后 我们先点击左上方的清除 先不要这些多的配置 然后 我们可以先用鼠标在图像上 画出一个局域 然后 我们去拖他四个角中的其中一个 就能拖出一些不同的形状 然…...
)
每日一个C库函数-#1-memset()
每日一个C库函数-#1-memset() 来源 C 标准库 - <string.h> 声明 void *memset(void *str, int c, size_t n);str:要填充的内存块;c:要被设置的值(以何值填充)。该值以 int 形式传递,填充内存块时…...

GraphQL基础知识与Spring for GraphQL使用教程
文章目录 1、数据类型1.1、标量类型1.2. 高级数据类型 基本操作2、Spring for GraphQL实例2.1、项目目录2.2、数据库表2.3、GraphQL的schema.graphql2.4、Java代码 3、运行效果3.1、添加用户3.2、添加日志3.3、查询所有日志3.4、查询指定用户日志3.5、数据订阅 4、总结 GraphQL…...
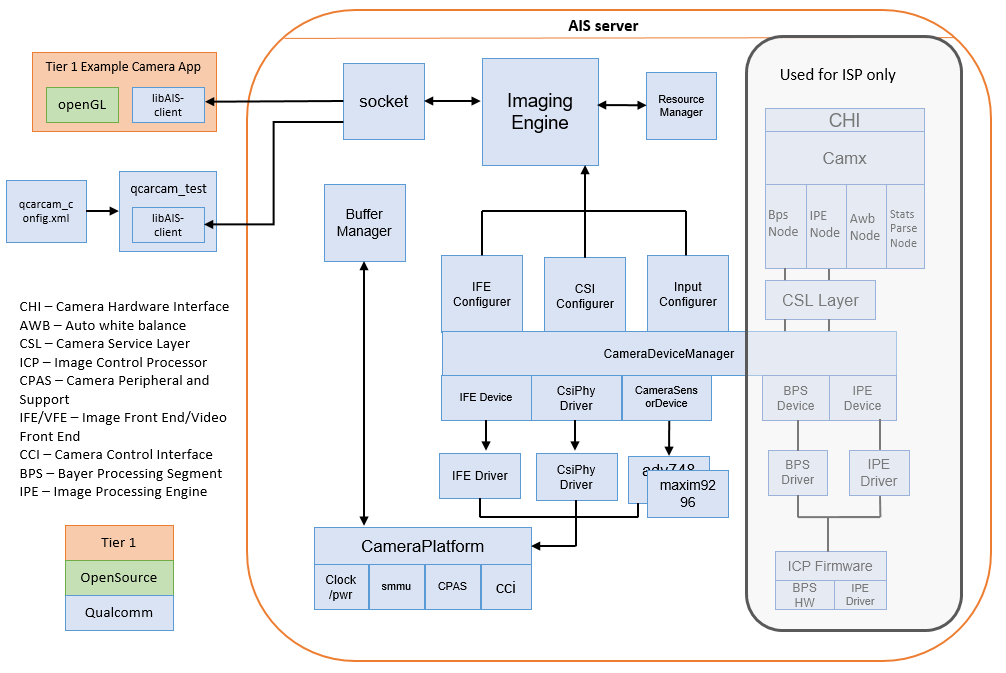
【SA8295P 源码分析】97 - QNX AIS Camera 框架介绍 及 Camera 工作流程分析
【SA8295P 源码分析】97 - QNX AIS Camera 框架介绍 及 Camera 工作流程分析 一、QNX AIS Server 框架分析二、QNX Hypervisor / Android GVM 方案介绍三、Camera APP 调用流程分析四、QCarCam 状态转换过程介绍五、Camera 加串-解串 硬件链路分析六、摄像头初始化检测过程介绍…...

威胁的数量、复杂程度和扩散程度不断上升
Integrity360 宣布了针对所面临的网络安全威胁、数量以及事件响应挑战的独立研究结果。 数据盗窃、网络钓鱼、勒索软件和 APT 是最令人担忧的问题 这项调查于 2023 年 8 月 9 日至 14 日期间对 205 名 IT 安全决策者进行了调查,强调了他们的主要网络安全威胁和担忧…...

Kando测试框架完全指南:Mocha和Chai的终极使用技巧
Kando测试框架完全指南:Mocha和Chai的终极使用技巧 【免费下载链接】kando 🌸 Do things with utmost efficiency. 项目地址: https://gitcode.com/gh_mirrors/ka/kando Kando是一款跨平台的饼状菜单桌面工具,它为用户提供了高效、直观…...

利用快马ai一键生成android studio配置脚本,五分钟搭建安卓开发原型环境
利用快马AI一键生成Android Studio配置脚本,五分钟搭建安卓开发原型环境 最近在尝试学习安卓开发,发现Android Studio的安装和配置过程相当繁琐。从下载安装包到配置SDK、创建模拟器,再到初始化项目,每一步都可能遇到各种问题。作…...

OpenClaw自动化运维助手:Qwen3.5-9B处理服务器告警与执行修复
OpenClaw自动化运维助手:Qwen3.5-9B处理服务器告警与执行修复 1. 从半夜被报警电话吵醒说起 凌晨3点17分,我的手机又一次疯狂震动起来。Zabbix监控系统发来警报:生产环境的Redis集群主节点内存使用率达到95%。强撑着睡意打开电脑࿰…...

MongoDB中大型文本字段怎么存_GridFS切分与外部存储对比
会。MongoDB单文档上限16MB,但超2MB字符串易致客户端OOM或超时;GridFS非自动魔法,需手动管理分块、拼接与清理;大文本应优先存OSS/S3,Mongo仅存元数据。大文本存MongoDB会撑爆内存吗?会。MongoDB单文档上限…...

BEAST 2 终极指南:如何快速掌握贝叶斯分子进化分析工具
BEAST 2 终极指南:如何快速掌握贝叶斯分子进化分析工具 【免费下载链接】beast2 Bayesian Evolutionary Analysis by Sampling Trees 项目地址: https://gitcode.com/gh_mirrors/be/beast2 BEAST 2(Bayesian Evolutionary Analysis by Sampling T…...

数聚智连转战港交所:年营收16亿 净利4340万 蓝标与险峰是股东
雷递网 雷建平 4月2日北京数聚智连科技股份有限公司(简称:“数聚智连”)日前递交招股书,准备在港交所上市。数聚智连曾向深交所创业板递交招股书,计划募资8亿元,最终IPO被终止,此番是数聚智连转…...

Elsevier投稿状态追踪:告别手动刷新,让审稿进度一目了然
Elsevier投稿状态追踪:告别手动刷新,让审稿进度一目了然 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 还在为Elsevier投稿系统的繁琐查询而烦恼吗?每次登录系统查看审稿进度都需…...
鸿蒙系统底层接口快速接入指南 | 鸿蒙开发筑基实战)
1 (带目录)鸿蒙系统底层接口快速接入指南 | 鸿蒙开发筑基实战
鸿蒙系统底层接口快速接入指南 | 鸿蒙开发筑基实战 作者:杨建宾(华夏之光永存) 系列完整目录(鸿蒙生态开发实战进阶全集・轻量进阶版) 第一章:鸿蒙基础适配篇(本文) 1 鸿蒙系统底层接…...

实践证明:用需求四要素描述需求,AI编程返工率大幅下降
实践证明:用需求四要素描述需求,AI编程返工率大幅下降目标 边界 示例 验收 其中,边界 和 验收 最容易被低估,也最值得你花时间写清楚写在前面 你有没有遇到过这样的情况: 让 AI 写一个函数,结果它给你加…...

LiuJuan20260223Zimage实战:如何通过Gradio界面生成高质量人像图片
LiuJuan20260223Zimage实战:如何通过Gradio界面生成高质量人像图片 1. 认识LiuJuan20260223Zimage模型 LiuJuan20260223Zimage是一个基于Z-Image模型并融合LoRA技术的文生图模型,专门用于生成特定风格的人像图片。这个模型最大的特点是: 专…...