【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
- Abstract
- 1 Introduction
- 2 Method
- 2.1 Scene Representation
- 2.3 Towards Realistic Rendering
- 2.4 Optimization
- 3.1 Photorealistic Rendering
- 3.2 Instance-wise Editing
- 3.3 The blessing of moduler design
- 3.4 Ablation Results
- 4 Conclusion

paper code
Abstract
如今,自动驾驶汽车可以在普通情况下平稳行驶,人们普遍认识到,真实的传感器模拟将在通过模拟解决剩余的极端情况方面发挥关键作用。为此,我们提出了一种基于神经辐射场(NeRF)的自动驾驶模拟器。与现有作品相比,我们的作品具有三个显着特点:
(1)实例感知。我们的模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以单独控制实例的静态(例如大小和外观)和动态(例如轨迹)属性。
(2)模块化。我们的模拟器允许在不同的现代 NeRF 相关主干、采样策略、输入模式等之间灵活切换。我们期望这种模块化设计能够促进基于 NeRF 的自动驾驶模拟的学术进步和工业部署。
(3)真实性。考虑到最佳的模块选择,我们的模拟器设置了新的最先进的照片级真实感结果。我们的模拟器将开源,而大多数同类模拟器都不开源。项目页面:https://open-air-sun.github.io/mars/。
1 Introduction
自动驾驶 [11,13,33,16,24,14] 可以说是现代 3D 场景理解 [5,25] 技术最重要的应用。如今,Robotaxis可以在拥有最新高清地图的大城市中运行,顺利应对日常驾驶场景。然而,一旦道路上意外发生自动驾驶算法分布之外的极端情况,乘客的生命就会受到威胁。困境在于,虽然我们需要更多关于极端情况的训练数据,但在现实世界中收集它们通常意味着危险和高昂的费用。为此,社区认为真实感模拟[17,6,29,10]是一条极具潜力的技术路径。如果算法能够在模拟器中经历大量的极端情况,并且模拟与真实的差距很小,那么当前自动驾驶算法的性能瓶颈就有可能得到解决。
现有的自动驾驶仿真方法有其自身的局限性。 CARLA [8] 是一种广泛使用的基于传统图形引擎的传感器模拟器,其真实性受到资产建模和渲染质量的限制。 AADS [17] 也利用传统的图形引擎,但使用精心策划的资源展示了令人印象深刻的照片级真实感。另一方面,GeoSim [6] 引入了一种通过学习图像增强网络来进行真实模拟的数据驱动方案。灵活的资产生成和渲染可以通过具有良好几何形状和逼真外观的图像合成来实现。
在本文中,我们利用 NeRF 的真实渲染能力进行自动驾驶仿真。从现实环境中捕获的训练数据保证了模拟与真实之间的微小差距。一些作品还利用 NeRF 来模拟室外环境中的汽车 [20] 和静态背景 [10]。然而,无法对由移动物体和静态环境组成的复杂动态场景进行建模,限制了它们在现实世界传感器模拟中的实际应用。最近,神经场景图(NSG)[21]将动态场景分解为学习场景图,并学习类别级对象的潜在表示。然而,其基于多平面的背景建模表示无法在大视点变化下合成图像。
具体来说,我们的核心贡献是第一个基于 NeRF 的开源模块化框架,用于逼真的自动驾驶模拟。所提出的管道以分解的方式对前景实例和后景环境进行建模。不同的 NeRF 主干架构和采样方法以统一的方式合并,并支持多模态输入。所提出的框架的最佳模块组合在公共基准上实现了最先进的渲染性能,并具有较大的裕度,表明了逼真的模拟结果。
2 Method

图 1. 管道。左:我们首先计算所查询的射线 r 和所有可见实例边界框 { B i j } \{\mathcal{B}_{ij}\} {Bij}的射线-盒交集。对于背景节点,我们直接使用选定的场景表示模型和选定的采样器来推断逐点属性,就像传统 NeRF 中一样。对于前景节点,光线首先被转换为实例框架 r o r_o ro,然后通过前景节点表示进行处理(第 2.1 节)。右:所有样本都被组合并渲染为 RGB 图像、深度图和语义(第 2.2 节)。
Overview.
如图1所示,我们的目标是提供一个用于构建组合神经辐射场的模块化框架,其中可以针对户外驾驶场景进行真实的传感器模拟。考虑到具有大量动态对象的大型无界室外环境。
系统的输入包括一组 RGB 图像 { L i } N \{\mathcal{L}_i\}^N {Li}N (由车辆端或路边传感器捕获)、传感器姿态 { T i } N \{\mathcal{T}_i\}^N {Ti}N (使用 IMU/GPS 信号计算)和对象轨迹(包括 3D 边界)框 { B i j } N × M \{\mathcal{B}_{ij}\}^{N \times M} {Bij}N×M 、类别 { t y p e i j } N × M \{type_{ij}\}^{N \times M} {typeij}N×M 和实例 ID { i d x i j } N × M \{idx_{ij}\}^{N \times M} {idxij}N×M)。 N 是输入帧的数量,M 是整个序列中跟踪实例 { O i } M \{\mathcal{O}_i\}^M {Oi}M的数量。训练期间还可以采用一组可选的深度图 { D i } N \{\mathcal{D}_i\}^N {Di}N 和语义分割掩模 { S i } N \{\mathcal{S}_i\}^N {Si}N 作为额外的监督信号。通过构建组合神经场,所提出的框架可以在给定的传感器姿势下模拟真实的传感器感知信号(包括 RGB 图像、深度图、语义分割掩模等)。还支持对对象轨迹和外观进行实例编辑。
Pipeline.
我们的框架对每个前景实例和后景节点进行组合建模。如图 1 所示,当查询给定射线 r 的属性(RGB、深度、语义等)时,我们首先计算其与所有可见对象的 3D 边界框的交集,以获得进入和离开的距离 [ t i n , t o u t ] [t_{in}, t_{out}] [tin,tout]。然后,查询背景节点(图 1 左上)和前景对象节点(图 1 左下),其中每个节点对一组 3D 点进行采样,并使用其特定的神经表示网络来获取点属性(RGB、密度、语义等)。具体来说,为了查询前景节点,我们根据对象轨迹将光线原点和方向从世界空间转换为实例帧。最后,来自背景和前景节点的所有光线样本被组合并进行体积渲染,以产生逐像素渲染结果(图 1 右侧,第 2.2 节)。
我们观察到背景节点(通常是无界的大规模场景)的性质与以对象为中心的前景节点不同,而传感器模拟中的当前工作[15,21]使用统一的 NeRF 模型。我们的框架提供了一个灵活的开源框架,支持背景和前景节点场景表示的不同设计选择,并且可以轻松地结合静态场景重建和以对象为中心的重建的新的最先进的方法。
2.1 Scene Representation
我们将场景分解为一个大规模的无界 NeRF(作为背景节点)和多个以对象为中心的 NeRF(作为独立的前景节点)。传统上,神经辐射场将给定的 3D 点坐标 x = (x, y, z) 和 2D 观察方向 d 映射到其辐射率 c 和体积密度 σ,如方程式 1 所示。 1. 基于这种开创性的表示,针对不同目的提出了许多变体,因此我们采用模块化设计。

对无界背景场景进行逼真建模的挑战在于准确表示远区,因此我们利用无界场景扭曲 [2] 来收缩远区。对于前景节点,我们支持代码条件表示 f (x, d, z) = (c, σ) (z 表示实例级潜在代码)和传统的表示,解释如下。
Architectures.
在我们的模块化框架中,我们支持各种 NeRF 主干,这些主干可以大致分为两个超类:基于 MLP 的方法 [18,1,2],或基于网格的方法,在其哈希网格体素中存储空间变化的特征顶点[19,23]。尽管这些架构在细节上彼此不同,但它们遵循相同的高级公式1 并封装在 MARS 中统一接口下的模块中。
虽然基于 MLP 的表示在数学形式上很简单,但我们给出了基于网格的方法的正式阐述。多分辨率特征网格 { G θ l } l = 1 L \{\mathcal{G}_{\theta}^{l}\}^{L}_{l=1} {Gθl}l=1L 的具体实现具有逐层分辨率 R l : = ⌊ R m i n ⋅ b l ⌋ , b = e x p ( l n R m a x − l n R m i n L − 1 ) R_l := ⌊R_{min} · b^l⌋, b = exp(\frac{ln R_{max} − ln R_{min}}{ L−1}) Rl:=⌊Rmin⋅bl⌋,b=exp(L−1lnRmax−lnRmin) ,其中 R m i n 、 R m a x R_{min}、R_{max} Rmin、Rmax 是最粗和最细的分辨率[31,19]。坐标 x 首先缩放到每个分辨率,然后通过向上和向下操作处理为 ⌈ x ⋅ R l ⌉ 、 ⌊ x ⋅ R l ⌋ ⌈x · R_l⌉、⌊x · R_l⌋ ⌈x⋅Rl⌉、⌊x⋅Rl⌋ 并进行散列以获得表索引 [19]。然后对提取的特征向量进行三线性插值并通过浅 MLP 进行解码。

Sampling.
我们支持各种采样策略,包括最近提出的提案网络 [2],它从无辐射 NeRF 模型中提取密度场以生成射线样本以及其他采样方案,例如从粗到细采样 [18] 或均匀采样 [9]。
Foreground Nodes.
为了渲染前景实例,我们首先将投影光线转换到每个实例的坐标空间,然后推断每个实例规范空间中的以对象为中心的 NeRF。我们框架的默认设置使用代码条件模型,该模型利用潜在代码对实例特征进行编码,并使用共享类别级解码器对类先验进行编码,从而允许对许多具有紧凑内存使用的长轨迹进行建模。同时,我们的框架也支持传统的无代码条件的。我们在补充材料中详细介绍了修改后的前景表示(在第 3 节中表示为“Ours")。

图 2. 构图渲染图。远处区域中的一些静态车辆被视为背景物体。
2.2 Compositional Rendering
图 2 展示了合成渲染结果。为了以给定的相机姿态 T i \mathcal{T}_{i} Ti 渲染图像,我们在每个渲染像素处投射一条光线 r = o + t d r = o + td r=o+td 。对于每条射线 r,我们首先计算与所有可见前景节点 O i j \mathcal{O}_{ij} Oij 的交集间隔 [ t i n , t o u t ] [t_{in}, t_{out}] [tin,tout](图 3),并将样本 { P k o b j − j } \{\mathcal{P}_{k}^{obj-j}\} {Pkobj−j}沿射线从世界空间变换到每个前景规范空间。我们还沿光线采样一组 3D 点 { P k g b } \{\mathcal{P}_{k}^{gb}\} {Pkgb}作为背景样本。所有节点中的样本首先通过其相应的网络来获取逐点颜色 { c k b g , o b j } \{c_{k}^{bg,obj}\} {ckbg,obj}、密度 { σ k b g , o b j } \{σ_{k}^{bg,obj}\} {σkbg,obj} 和前景语义逻辑 { s k b g } \{s_{k}^{bg}\} {skbg}。考虑到前景样本的语义属性实际上是它们的类别标签,我们创建一个 one-hot 向量:

为了聚合逐点属性,我们按世界空间中的光线距离对所有样本进行排序,并使用标准体积渲染过程来渲染逐像素属性:

2.3 Towards Realistic Rendering
Sky Modeling.
在我们的框架中,我们支持使用天空模型来处理无限距离处的外观,其中利用基于 MLP 的球形环境贴图 [22] 来对永远不会与不透明表面相交的无限远区域进行建模:

然而,天真地将天空颜色 c s k y c_{sky} csky 与背景和前景渲染(等式 4)混合会导致潜在的不一致。因此,我们引入 BCE 语义正则化来缓解这个问题:

Resolving Conflict Samples.

图 3. 我们的无冲突采样过程的视觉演示。我们在所有节点中使用均匀采样来进行说明。
Resolving Conflict Samples.
由于我们的背景和前景采样是独立完成的,因此背景样本有可能落入前景边界框内(图 3 背景截断样本)。合成渲染可能会错误地将前景样本分类为背景(稍后称为背景-前景模糊性)。因此,在移除前景实例后,背景区域将出现伪影(图 4)。理想情况下,有了足够的多视图监督信号,系统可以在训练过程中自动学习区分前景和背景。然而,对于数据驱动的模拟器来说,随着车辆在道路上快速移动,获取丰富且高质量的多视图图像对用户来说是一个挑战。 NSG [21] 中没有观察到这种模糊性,因为 NSG 仅对光线平面交叉点上的几个点进行采样,并且不太可能有太多背景截断样本。

图 4。我们表明,在没有进行正则化的情况下,背景截断样本会导致背景-前景模糊。
为了解决这个问题,我们设计了一个正则化项,可以最小化背景截断样本的密度和,以最小化它们在渲染过程中的影响:

其中 { P i ( t r ) } \{P^{(tr)}_ i \} {Pi(tr)} 表示背景截断样本。
2.4 Optimization
为了优化我们的系统,我们最小化以下目标函数:

其中 λ 1 − 5 λ_{1−5} λ1−5 是加权参数。 L s k y L_{sky} Lsky 和 L a c c u m L_{accum} Laccum 在方程式中进行了解释。 7和8。
Color Loss:
我们采用标准 MSE 损失来最小化光度测量误差:

Depth Loss:
我们引入深度损失来解决无纹理区域和从稀疏视点观察到的区域。我们设计了两种监督几何形状的策略。给定深度数据,我们利用从[7]导出的光线分布损失。另一方面,如果深度数据不可用,我们利用单深度网络并应用以下[31]的单深度损失。

Semantic Losses:
我们遵循 SemanticNeRF [34] 并使用交叉熵语义损失 
3 Experiments
在本节中,我们提供了大量的实验结果来演示所提出的用于自动驾驶的实例感知、模块化和真实的模拟器。我们在 KITTI [11] 数据集和虚拟 KITTI-2 (V-KITTI) [3] 数据集的场景上评估我们的方法。在下文中,我们使用“我们的默认设置”来表示带有提案采样器的基于网格的 NeRF 用于背景节点,以及我们修改后的类别级表示以及用于前景节点的从粗到细的采样器。

表 1. 图像重建任务的定量结果以及与基线方法的设置比较。用于评估的数据集是KITTI。
3.1 Photorealistic Rendering
我们通过评估图像重建和新视图合成(NVS)来验证模拟器的真实感渲染性能[21,26]。

表 2. 新视图合成的定量结果
Baselines.
我们与其他最先进的方法进行定性和定量比较:NeRF [18]、带时间戳输入的 NeRF(表示为 NeRF+Time)、NSG [21]、PNF [15] 和 SUDS [26]。请注意,它们都没有同时满足表1 中提到的所有三个标准。
Implementation Details.
我们的模型使用 RAdam 作为优化器,经过 200,000 次迭代训练,每批 4096 条光线。背景节点的学习率被指定为 1 ∗ 1 0 − 3 1 * 10^{−3} 1∗10−3,衰减到 1 ∗ 1 0 − 5 1 * 10^{−5} 1∗10−5,而对象节点的学习率被分配为 5 ∗ 1 0 − 3 5 * 10^{−3} 5∗10−3,衰减到 1 ∗ 1 0 − 5 1 * 10^{−5} 1∗10−5。

图 5. KITTI 数据集上的定性图像重建结果。
Experiment Settings.
图像重建设置中的训练和测试图像集是相同的,而在 NVS 任务中,我们渲染不包含在训练数据中的帧。具体来说,我们每隔 4 帧、每 2 帧和 4 帧进行一次训练,并且每 4 帧中只有 1 帧进行训练,即 25%、50% 和 75%。
我们遵循图像合成中的标准评估协议,并报告定量评估默认设置的峰值信噪比(PSNR)、结构相似性(SSIM)和学习感知图像块相似性(LPIPS)[32]。图像重建的结果如表 1 所示,NVS 的结果如表 2 所示,这表明我们的方法在两种设置下都优于基线方法。我们使用 75% 的训练数据在 V-KITTI 上可以达到 29.79 PSNR,而之前发布的最佳结果是 23.87。
 图 6. 不同渲染通道的图库。
图 6. 不同渲染通道的图库。
3.2 Instance-wise Editing
我们的框架分别对背景和前景节点进行建模,这使我们能够以实例感知的方式编辑场景。我们定性地展示了删除实例、添加新实例和编辑车辆轨迹的能力。在图 7 中,我们展示了一些旋转和平移车辆的编辑示例,但可以在我们的视频剪辑中找到更多结果。

3.3 The blessing of moduler design
我们使用后景和前景节点、采样器和监督信号的不同组合进行评估,这归功于我们的模块化设计。
请注意,文献中的一些基线方法实际上对应于该表中的消融条目。例如,PNF [15] 使用 NeRF 作为背景节点表示,使用实例化 NeRF 作为具有语义损失的前景节点表示。 NSG [21] 使用 NeRF 作为背景节点表示,使用类别级 NeRF 作为前景表示,但采用多平面采样策略。我们的默认设置使用基于网格的背景节点表示,以及我们提出的前景节点表示的类别级方法。
3.4 Ablation Results
在本节中,我们分析不同的实验设置,验证我们设计的必要性。我们揭示了不同设计选择对背景节点表示、前景节点表示等的影响。具体来说,我们展示了 50,000 次迭代的所有实验。与之前的工作 [26,15,21] 在 90 张图像的短序列上评估他们的方法不同,我们使用数据集中的完整序列进行所有评估。由于它们不是开源的,并且不知道它们的确切评估序列,我们希望我们的新基准测试能够标准化这个重要领域。定量评价见表3。
对于背景和前景节点,我们用基于 MLP 和基于网格的模型替换默认模型(表 3 中的 ID 1),并在第 2 行、第 7-12 行列出它们的指标。在第 3-6 行中,我们展示了模型组件的有效性。对于模型和采样器,背景和前景节点的选定模块分别在斜杠之前和之后注明。

4 Conclusion
在本文中,我们提出了一个基于 NeRF 的逼真自动驾驶模拟模块化框架。我们的开源框架由一个后景节点和多个前景节点组成,可以对复杂的动态场景进行建模。我们通过大量的实验证明了我们框架的有效性。所提出的管道在公共基准上实现了最先进的渲染性能。我们还支持场景表示和采样策略的不同设计选择,从而在模拟过程中提供灵活性和多功能性。
Limitations.
我们的方法需要数小时的训练,并且无法实时渲染。此外,我们的方法未能考虑玻璃或其他反射材料上的动态镜面反射效应,这可能会导致渲染图像中的伪影。提高模拟效率和视图相关效果将是我们未来的工作。
抛砖:
- NeRF在自动驾驶领域的有效应用,效果很棒。
- 这个模块化挺好,可以自由组合各个小模块,可以针对不同场景较方便地切换模块与优化。
- 这份工作结合的NeRF在渲染方向的优势,似乎在NeRF重建方向由于效率等原因,很少看到相关应用,目前来看,可能NeRF重建还是后处理方面比较有优势(比如重建街景?)。
相关文章:
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器 Abstract1 Introduction2 Method2.1 Scene Representation2.3 Towards Realistic Rendering2.4 Optimization3.1 Photorealistic Rendering3.2 Instance-wise Editing3.3 The blessing of moduler des…...

Leetcode 2856. Minimum Array Length After Pair Removals
Leetcode 2856. Minimum Array Length After Pair Removals 1. 解题思路2. 代码实现 题目链接:2856. Minimum Array Length After Pair Removals 1. 解题思路 这一题思路而言个人觉得还是挺有意思的,因为显然这道题没法直接用greedy的方法进行处理&am…...

深入了解Vue.js框架:构建现代化的用户界面
目录 一.Vue前言介绍 二.Vue.js框架的核心功能与特性 三.MVVM的介绍 四.Vue的生命周期 五.库与框架的区别 1.库(Library): 2.框架(Framework): 六.Vue常用指令演示 1.v-model 2.v-on:click&…...

力扣 -- 673. 最长递增子序列的个数
小算法: 通过一次遍历找到数组中最大值出现的次数: 利用这个小算法求解这道题就会非常简单了。 参考代码: class Solution { public:int findNumberOfLIS(vector<int>& nums) {int nnums.size();vector<int> len(n,1);auto…...

43.248.189.X网站提示风险,存在黑客攻击页面被篡改,改如何解决呢?
当用户百度搜索我们的网站,准备打开该网站时,访问页面提示风险,告知被黑客攻击并有被篡改的情况,有哪些方案可以查看解决问题? 当遇到网站提示风险到时候,可以考虑采用下面几个步骤来解决问题:…...

Java8中判断一个对象不为空存在一个类对象是哪个
Java8中判断一个对象不为空存在一个类对象是哪个? 在Java 8中,你可以使用java.util.Optional类来处理可能为空的对象。Optional类可以帮助你优雅地处理空值情况,而不需要显式地进行空值检查。 这是一个简单的Optional示例: imp…...

项目:点餐系统
项目扩展: 1.订单操作 2.用户管理(临时用户生成用户注册与登录) 项目有可能涉及到的面试: 说说你的项目 为什么要做这个项目 服务器怎么搭建的 最初我自己写了一个简单的服务器,但是不太稳定,比较粗…...
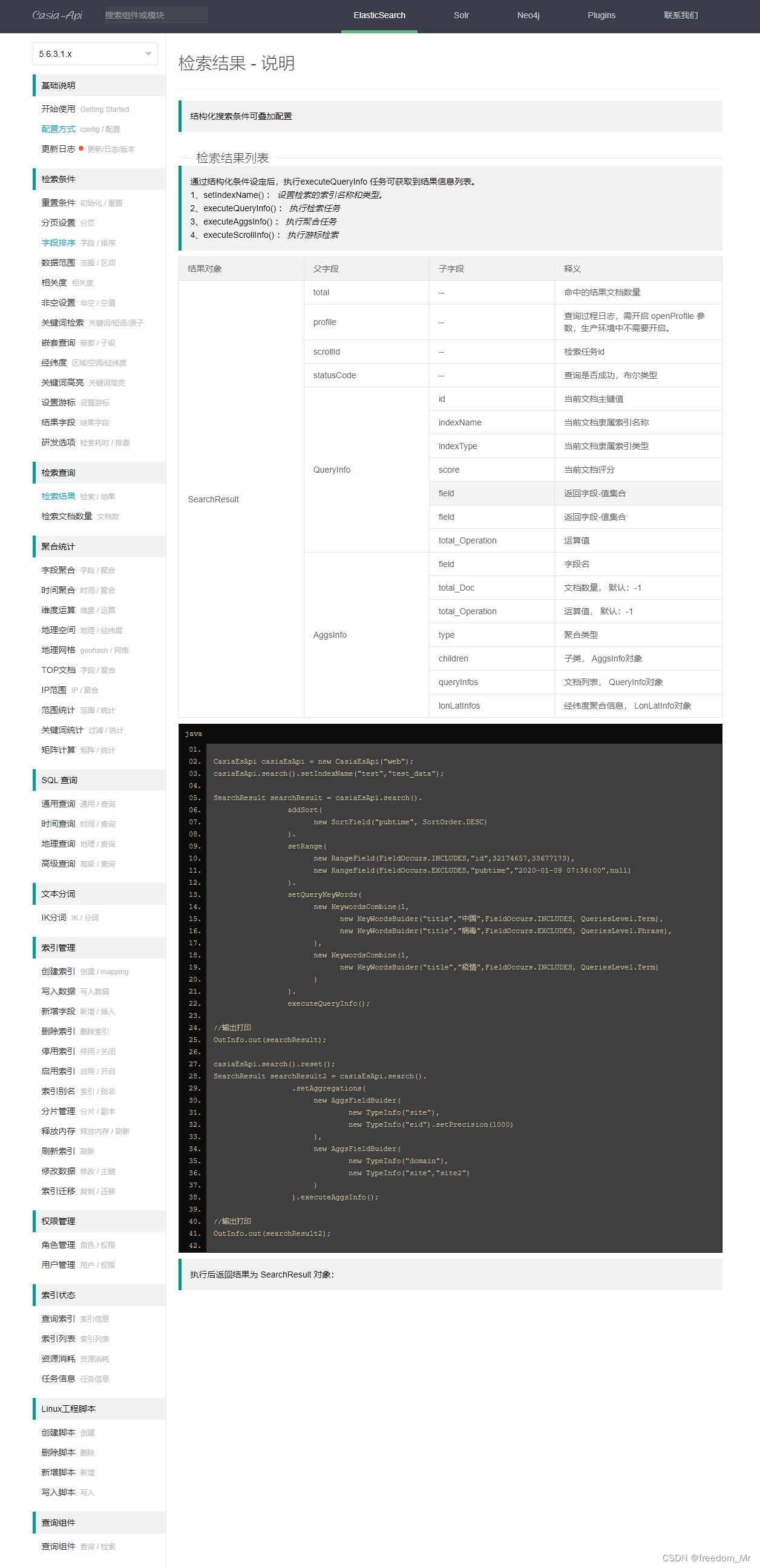
ElasticSearch 5.6.3 自定义封装API接口
在实际业务中,查询 elasticsearch 时会遇到很多特殊查询,官方接口包有时不便利,特殊情况需要自定义接口,所以为了灵活使用、维护更新 编写了一套API接口,仅供学习使用 当前自定义API接口依赖 elasticsearch 5.6.3 版本…...
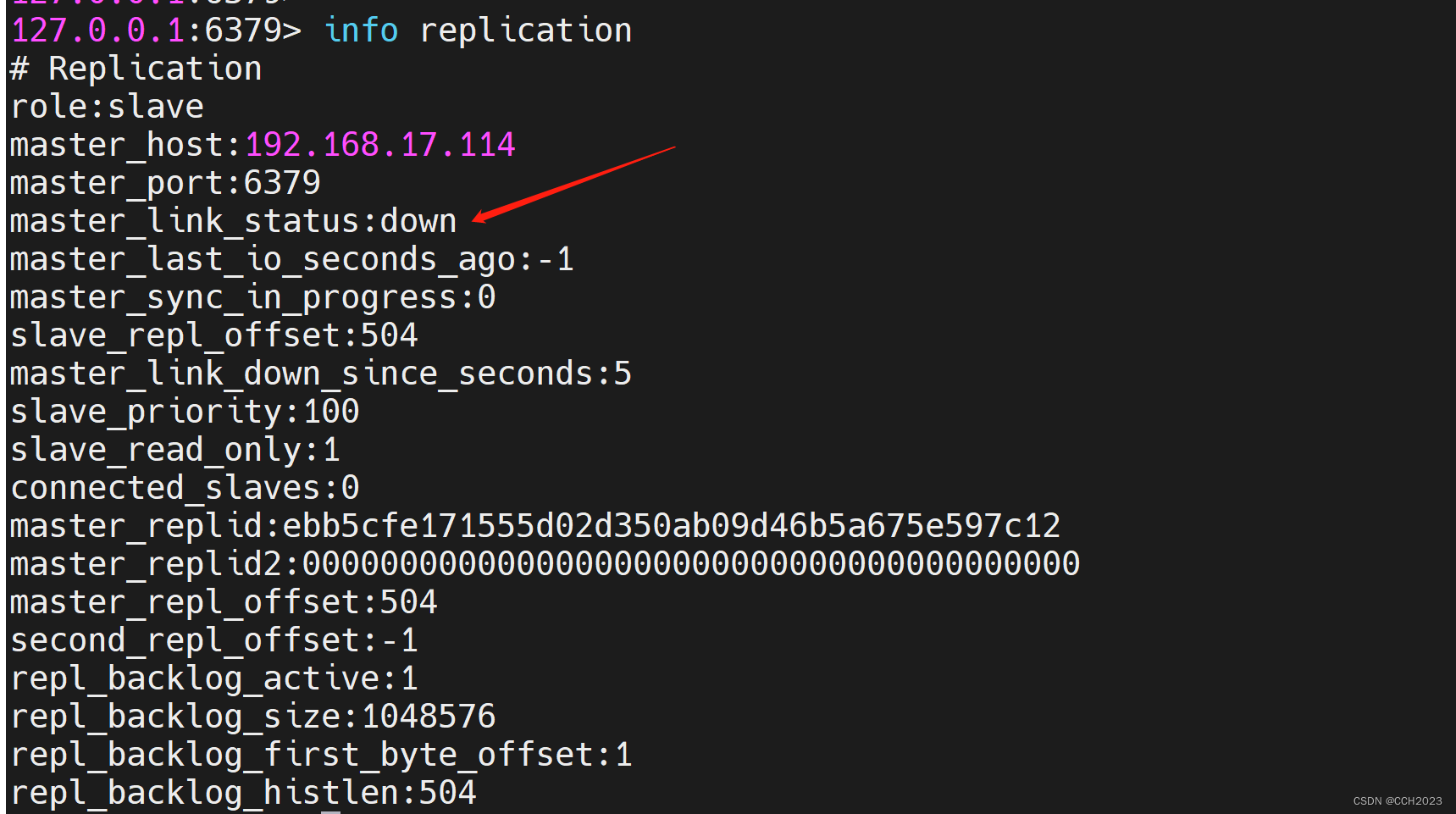
企业架构LNMP学习笔记51
企业案例使用: 主从模式: 缓存集群结构示意图: 去实现Redis的业务分离: 读的请求分配到从服务器上,写的请求分配到主服务器上。 Redis是没有中间件来进行分离的。 是通过业务代码直接来进行读写分离。 准备两台虚…...
rom修改----安卓系列机型如何内置app 如何选择so文件内置
系统内置app的需求 在与各工作室对接中操作单中,很多需要内置客户特定的有些app到系统里,这样方便客户刷入固件后直接调用。例如内置apk 去开机引导 去usb调试 默认开启usb安全设置等等。那么很多app内置有不同的反应。有的可以直接内置。有的需要加so…...

SpringMvc中的请求转发和重定向
之前的案例,我们发现request域中的值可以传到jsp页面中,也就是通过视图解析器跳转到视图的底层是请求转发。 如果我们跳转时不想使用视图解析器,可以使用原生HttpServletRequest进行请求转发或HttpServletResponse进行重定向: Req…...
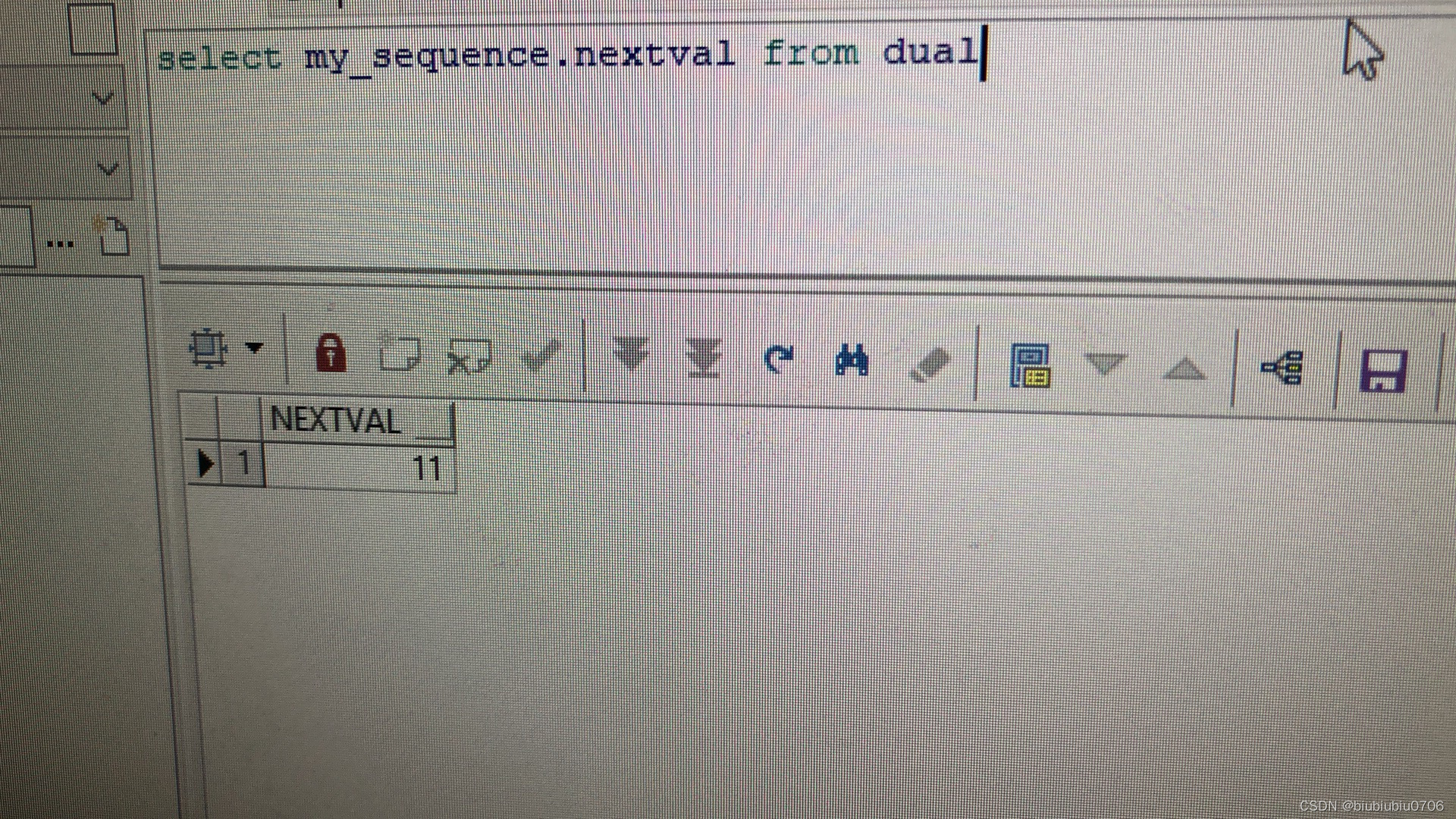
Oracle,高斯创建自增序列
某些时候,需要获取到一个自增值 然后点击左下 Apply 也可以通过SQL语句执行 dual在Oracle中是张虚拟表,通常用于执行这样的查询 Oracle中查询语句: select 序列名.nextval from dual 在高斯数据库中:查询是 select my_sequence.nextval 不需要加form xxx …...
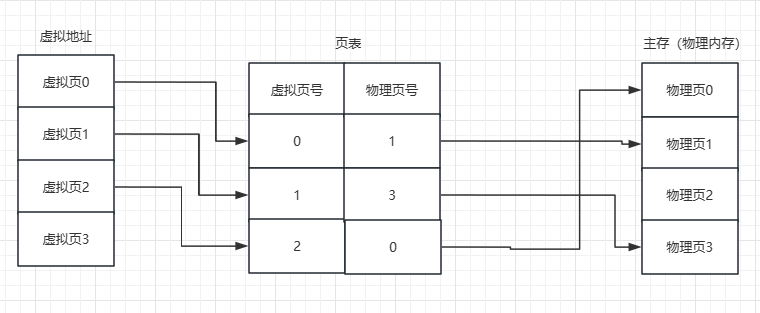
操作系统学习笔记-精简复习版
文章目录 操作系统概述1、操作系统2、主要功能3、用户态和内核态4、系统调用 进程管理1、进程和线程2、引入线程的好处3、线程间同步4、进程控制块 PCB5、进程的状态6、进程的通信方式7、进程的调度算法8、僵尸进程&孤儿进程9、死锁 内存管理1、内存碎片2、内存管理3、虚拟…...
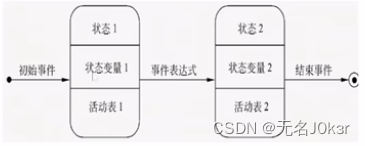
系统架构:软件工程速成
文章目录 参考概述软件工程概述软件过程 可行性分析可行性分析概述数据流图数据字典 需求分析需求分析概述ER图状态转换图 参考 软件工程速成(期末考研复试软考)均适用. 支持4K 概述 软件工程概述 定义:采用工程的概念、原理、技术和方法来开发与维护软件。 三…...

VUE之proxy配置实现跨域
什么是跨域 要了解跨域,首先得知道浏览器的同源策略。 同源策略:是由Netscape提出的一个安全策略,能够阻挡恶意文档,保护本地数据。它能限制一个源的文档或脚本对另一个源的交互,使得其它源的文档或脚本,…...

AI与医疗保健:革命性技术如何拯救生命
文章目录 引言AI的应用领域1. 影像识别2. 疾病诊断3. 药物研发4. 个性化治疗 AI技术1. 机器学习2. 深度学习3. 自然语言处理4. 基因组学 实际案例1. Google Health的深度学习模型2. IBM Watson for Oncology3. PathAI的病理学分析 道德和隐私考虑结论 🎉欢迎来到AIG…...

Spring Boot + Vue3前后端分离实战wiki知识库系统<十三>--单点登录开发二
接着Spring Boot Vue3前后端分离实战wiki知识库系统<十二>--用户管理&单点登录开发一继续往下。 登录功能开发: 接下来则来开发用户的登录功能,先准备后端的接口。 后端增加登录接口: 1、UserLoginReq: 先来准备…...
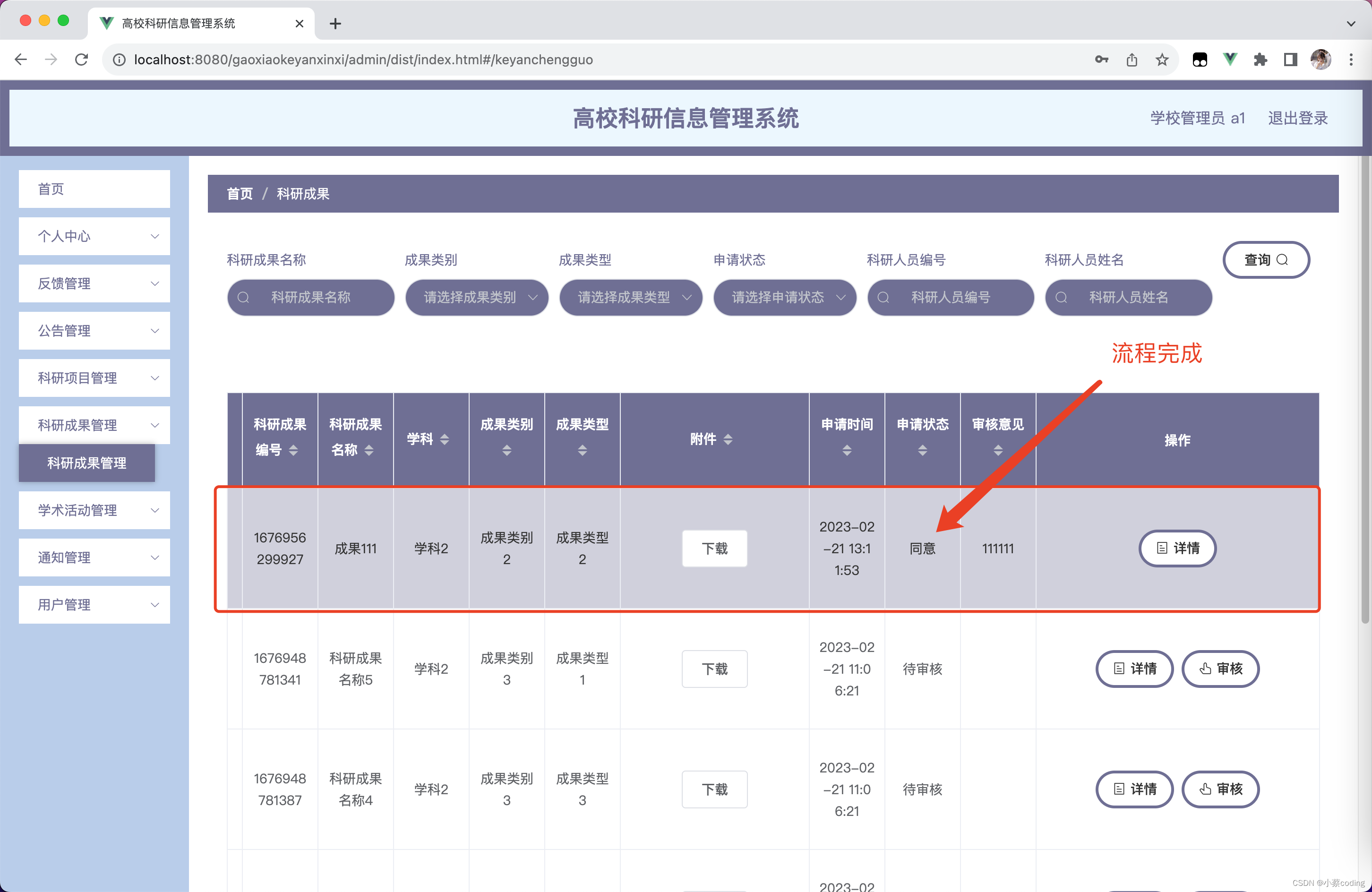
基于Java的高校科研信息管理系统设计与实现(亮点:完整严谨的科研项目审批流程、多文件上传、多角色)
高校科研信息管理系统 一、前言二、我的优势2.1 自己的网站2.2 自己的小程序(小蔡coding)2.3 有保障的售后2.4 福利 三、开发环境与技术3.1 MySQL数据库3.2 Vue前端技术3.3 Spring Boot框架3.4 微信小程序 四、功能设计4.1 主要功能描述 五、系统实现5.1…...
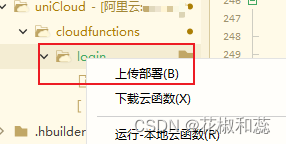
【uniapp】Dcloud的uni手机号一键登录,具体实现及踩过的坑,调用uniCloud.getPhoneNumber(),uni.login()等
一键登录Dcloud官网请戳这里,感兴趣的可以看看官网,有很详细的示例,选择App一键登录,可以看到一些常用的概述 比如: 1、调用uni.login就能弹出一键登录的页面 2、一键登录的流程,可以选择先预登录uni.prelo…...

Qt Quick Layouts Overview
Qt快速布局概述 #【中秋征文】程序人生,中秋共享# Qt快速布局是用于在用户界面中排列项目的项目。由于Qt快速布局还可以调整其项目的大小,因此它们非常适合可调整大小的用户界面。 开始 可以使用文件中的以下导入语句将 QML 类型导入到应用程序中。.qml…...

DCT-Net新手入门:从镜像部署到生成第一个卡通头像的全流程
DCT-Net新手入门:从镜像部署到生成第一个卡通头像的全流程 1. 准备工作:认识DCT-Net卡通化工具 你有没有想过把自己的照片变成卡通头像?DCT-Net是一个专门用于人像卡通化的AI模型,它能将普通照片转换成风格独特的卡通图像。这个…...

别再只盯着find提权了!盘点Linux下5种更隐蔽的权限维持姿势与排查手册
超越find提权:Linux系统下5种高阶权限维持技术与深度排查指南 当攻击者成功获取Linux系统权限后,权限维持(Persistence)往往成为攻防对抗的核心战场。传统安全培训常聚焦于SUID提权等基础手段,但真实APT攻击中…...

解锁外语游戏新体验:XUnity自动翻译器完全指南 [特殊字符]
解锁外语游戏新体验:XUnity自动翻译器完全指南 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而苦恼吗?XUnity自动翻译器让你轻松打破语…...

情感漏洞经纪:倒卖AI崩溃瞬间年入百万
新兴暴利职业的崛起在人工智能技术高速发展的今天,一种名为“情感漏洞经纪”的灰色产业悄然兴起,从业者通过倒卖AI系统崩溃瞬间的数据年入百万。这些经纪人专门捕捉AI模型在情感交互中的故障时刻——如系统宕机前的“遗言”、未完成的情感回应或异常输出…...

企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践
企业级图片批量处理方案:InstructPix2Pix在电商修图中的落地实践 1. 引言:电商修图的效率困局 想象一下,一家中型电商公司,每天要上新几百个商品。每个商品都需要一组高质量的主图、细节图、场景图。设计师团队忙得焦头烂额&…...
)
InnoDB 事务 undo log 与 MVCC 可视化讲解(画流程图+伪代码)
InnoDB 事务 undo log 与 MVCC 可视化讲解(画流程图+伪代码) 前言 在MySQL的InnoDB存储引擎中,事务的四大特性(ACID)是其核心能力之一。其中,隔离性(Isolation)和一致性(Consistency)的实现离不开undo log与MVCC(多版本并发控制)的精妙设计。 本文将从底层原理出…...
)
从需求到SQL:手把手教你将‘住院管理系统’的ER图转化为可运行的数据表(附建表语句)
从需求到SQL:住院管理系统数据库设计实战指南 在医疗信息化快速发展的今天,一套设计良好的住院管理系统数据库不仅能提高医院运营效率,更能为患者提供更精准的医疗服务。本文将带你从零开始,完整实现一个住院病人信息管理系统的数…...

别再为小Batch Size发愁了!手把手教你用Group Normalization稳定训练你的PyTorch模型
别再为小Batch Size发愁了!手把手教你用Group Normalization稳定训练你的PyTorch模型 当你在训练深度学习模型时,是否遇到过这样的困境:由于GPU显存限制,只能使用较小的batch size,结果模型训练变得极不稳定ÿ…...

VisualVM安全监控指南:敏感数据保护与权限管理
VisualVM安全监控指南:敏感数据保护与权限管理 【免费下载链接】visualvm VisualVM is an All-in-One Java Troubleshooting Tool 项目地址: https://gitcode.com/gh_mirrors/vi/visualvm VisualVM作为一款强大的Java应用性能监控与故障诊断工具,…...

3步实现UMA模型吸附能预测:从数据准备到结果验证完整指南
3步实现UMA模型吸附能预测:从数据准备到结果验证完整指南 【免费下载链接】ocp Open Catalyst Projects library of machine learning methods for catalysis 项目地址: https://gitcode.com/GitHub_Trending/oc/ocp 在催化材料研究中,吸附能是评…...