程序员必须掌握哪些算法?
目录
- 简介
- 1. 冒泡排序(Bubble Sort)
- 思想
- 2. 快速排序(Quick Sort)
- 思想
- 3. 二分查找(Binary Search)
- 思想
- 4. 归并排序(Merge Sort)
- 思想
- 5. 插入排序(Insertion Sort)
- 思想
- 6. 堆排序(Heap Sort)
- 思想
- 7. 哈希表(Hash Table)
- 思想
- 8. 图的深度优先搜索(Depth First Search,DFS)
- 思想
- 9. 图的广度优先搜索(Breadth First Search,BFS)
- 思想
- 10. Dijkstra最短路径算法
- 思想
- 总结
简介
作为一个程序员,掌握一些常用的算法对于解决各种问题和提升编程能力非常重要。以下是十个程序员必须掌握的算法,附带有C++代码示例。这篇文章有万字,支持支持作者吧!
1. 冒泡排序(Bubble Sort)
void bubbleSort(int arr[], int n) {for (int i = 0; i < n-1; i++) {for (int j = 0; j < n-i-1; j++) {if (arr[j] > arr[j+1]) {int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}
}
思想
冒泡排序是一种基本的排序算法,它的思想是通过比较相邻元素的大小,将较大(或者较小)的元素交换到数组的末尾,这样每次比较都会让最大(或者最小)的元素"冒泡"到正确的位置,最终实现排序。
具体的实现步骤如下:
- 从数组的第一个元素开始,依次比较相邻的两个元素。
- 如果前一个元素大于后一个元素,就将它们交换位置。
- 继续比较下一对相邻的元素,重复步骤 2 2 2 。
- 重复执行步骤 2 2 2 和步骤 3 3 3,直到没有需要交换的元素。
- 完成一次完整的遍历后,最大(或者最小)的元素将会"冒泡"到最后,因此每次遍历可以确定一个位置。
冒泡排序的时间复杂度是 O ( n 2 ) O(n^2) O(n2) ,其中 n n n 表示数组的长度。它的思想简单,实现也相对容易理解,但对于大规模的数据排序效率较低。
2. 快速排序(Quick Sort)
int partition(int arr[], int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j <= high-1; j++) {if (arr[j] <= pivot) {i++;swap(arr[i], arr[j]);}}swap(arr[i+1], arr[high]);return i+1;
}void quickSort(int arr[], int low, int high) {if (low < high) {int pivotIndex = partition(arr, low, high);quickSort(arr, low, pivotIndex-1);quickSort(arr, pivotIndex+1, high);}
}
思想
快速排序是一种常用的排序算法,它的思想是通过选取一个基准元素,将数组分为两部分,一部分小于基准元素,一部分大于基准元素,然后分别对两部分进行递归排序,最终实现整个数组的排序。
具体的实现步骤如下:
- 选择一个基准元素,可以是数组的第一个元素。
- 将数组分成两部分,小于基准元素的部分和大于基准元素的部分。
- 对两个子数组分别进行递归排序。递归排序的过程是重复步骤1和步骤2,直到子数组的长度为 1 1 1 或者 0 0 0 。
- 递归排序后,将各个子数组按序合并起来,得到完整的排序数组。
快速排序的关键在于分区操作,它通过一趟扫描确定基准元素的最终位置。
具体的分区操作如下:
- 选择基准元素后,设置两个指针,分别指向数组的最左端和最右端。
- 从数组的最右端开始,找到第一个小于基准元素的元素,将其与左指针所指的元素交换位置。
- 从数组的最左端开始,找到第一个大于基准元素的元素,将其与右指针所指的元素交换位置。
- 重复步骤 2 2 2 和步骤 3 3 3 ,直到左指针和右指针相遇。
- 最后将基准元素与左指针所指的元素交换位置,这样基准元素就位于最终的正确位置上。
快速排序的时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn) ,其中 n n n 表示数组的长度。它的思想较为高效,特别适用于大规模的数据排序。
3. 二分查找(Binary Search)
int binarySearch(int arr[], int target, int low, int high) {while (low <= high) {int mid = low + (high - low) / 2;if (arr[mid] == target) {return mid;}else if (arr[mid] < target) {low = mid + 1;}else {high = mid - 1;}}return -1; // 如果没有找到目标元素,返回-1
}
思想
二分查找,也称为折半查找,是一种常用的查找算法,它的思想是在有序数组中通过比较中间元素与目标元素的大小,逐步缩小查找范围,最终找到目标元素的位置。
具体的实现步骤如下:
- 确定有序数组的起始位置left和结束位置right。
- 计算中间位置 m i d mid mid ,即 m i d = ( l e f t + r i g h t ) ÷ 2 mid = (left + right) \div 2 mid=(left+right)÷2 。
- 将目标元素与中间位置的元素进行比较。
- 如果目标元素等于中间位置的元素,则返回该位置。
- 如果目标元素小于中间位置的元素,则在数组的左半部分继续进行二分查找,即更新 r i g h t = m i d − 1 right = mid - 1 right=mid−1 ,然后重复步骤2。
- 如果目标元素大于中间位置的元素,则在数组的右半部分继续进行二分查找,即更新 l e f t = m i d + 1 left = mid + 1 left=mid+1 ,然后重复步骤2。
- 重复执行步骤 2 2 2 和步骤 3 3 3 ,直到找到目标元素或者查找范围为空。
二分查找的时间复杂度是 O ( l o g n ) O(log n) O(logn) ,其中n表示有序数组的长度。由于每次查找都将查找范围减半,所以它的查找效率非常高。但是要求查找的数组必须是有序的,否则需要先进行排序操作。
4. 归并排序(Merge Sort)
void merge(int arr[], int low, int mid, int high) {int n1 = mid - low + 1;int n2 = high - mid;int L[n1], R[n2];for (int i = 0; i < n1; i++) {L[i] = arr[low + i];}for (int j = 0; j < n2; j++) {R[j] = arr[mid + 1 + j];}int i = 0, j = 0, k = low;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;}else {arr[k] = R[j];j++;}k++;}while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}
}void mergeSort(int arr[], int low, int high) {if (low < high) {int mid = low + (high - low) / 2;mergeSort(arr, low, mid);mergeSort(arr, mid+1, high);merge(arr, low, mid, high);}
}
思想
归并排序是一种经典的排序算法,它采用分治的思想来实现排序。该算法的基本思想是将一个待排序的数组分成两个大小大致相等的子数组,然后对这两个子数组分别进行递归排序,最后将两个排序好的子数组合并成一个有序的数组。
具体而言,归并排序的步骤如下:
- 将待排序数组不断地分成两半,直到每个子数组只有一个元素。
- 然后将相邻的两个单元素子数组合并成一个有序的两个元素子数组。
- 依次类推,重复进行将相邻的两个有序子数组合并的操作,直到整个数组排序完成。
归并排序的关键在于合并两个有序的子数组。合并时,维护两个指针分别指向两个子数组的起始位置,比较两个指针所指元素的大小,将较小的元素放入新数组中,并将指针向后移动一位。若其中一个子数组已经遍历完,则直接将另一个子数组中的元素依次放入新数组的末尾。
归并排序的时间复杂度是 O ( n l o g n ) O(nlogn) O(nlogn),其中 n n n 是待排序数组的长度。它是一种稳定的排序算法,适用于各种规模的数据集。
5. 插入排序(Insertion Sort)
void insertionSort(int arr[], int n) {for (int i = 1; i < n; i++) {int key = arr[i];int j = i - 1;while (j >= 0 && arr[j] > key) {arr[j+1] = arr[j];j--;}arr[j+1] = key;}
}
思想
插入排序是一种简单直观且常用的排序算法。它的基本思想是将待排序的数组分成已排序和未排序两部分,每次从未排序的部分选择一个元素插入到已排序的部分的合适位置,直到所有元素都被插入到合适的位置为止。
具体而言,插入排序的步骤如下:
- 假定第一个元素是已排序的部分,将第二个元素开始至最后一个元素视为未排序的部分。
- 遍历未排序的部分,依次将当前元素插入已排序的部分,并确保插入后已排序的部分仍然有序。
- 在已排序的部分,从当前元素出发,依次向前比较,找到合适的位置将当前元素插入。
- 重复步骤2和步骤3,直到所有元素都被插入到合适的位置。
插入排序的核心思想是将元素插入到已排序部分时,通过不断比较和移动元素的位置,找到合适的插入位置。这个过程类似于打扑克牌时,将一张新的牌插入到已经有序的牌组中的适当位置。
插入排序的时间复杂度是 O ( n 2 ) O(n^2) O(n2) ,其中 n n n 是待排序数组的长度。对于小规模的数据集,插入排序是一个不错的选择,因为它具有编写简单、空间复杂度低、对于有序部分效率高等特点。但对于大规模数据集,插入排序的效率相对较低,通常不如归并排序、快速排序等排序算法。
6. 堆排序(Heap Sort)
void heapify(int arr[], int n, int i) {int largest = i;int leftChild = 2 * i + 1;int rightChild = 2 * i + 2;if (leftChild < n && arr[leftChild] > arr[largest]) {largest = leftChild;}if (rightChild < n && arr[rightChild] > arr[largest]) {largest = rightChild;}if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}void heapSort(int arr[], int n) {for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}for (int i = n - 1; i >= 0; i--) {swap(arr[0], arr[i]);heapify(arr, i, 0);}
}
思想
堆排序( H e a p Heap Heap S o r t Sort Sort )是一种基于二叉堆数据结构实现的排序算法,它的思想是通过构建最大堆或最小堆来完成排序过程。
具体的实现步骤如下:
- 构建初始堆:将待排序的数组看作一个完全二叉树,从最后一个非叶子节点开始,从右到左依次进行下沉操作,使得每个节点满足堆的性质(对于最大堆来说,父节点的值大于等于子节点的值;对于最小堆来说,父节点的值小于等于子节点的值)。
- 排序过程:从堆的根节点开始,每次将堆顶元素与堆中的最后一个元素交换,然后对剩余元素进行下沉操作,不断缩小堆的范围。
- 重复步骤2,直到堆中的元素只剩下一个,排序完成。
堆排序的特点:
- 不稳定性:堆排序是一种不稳定的排序算法,因为在下沉操作中元素的位置可能发生交换。
- 原地排序:堆排序是一种原地排序算法,不需要额外的存储空间。
- 时间复杂度:堆排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn) ,其中 n n n 表示待排序的元素个数。
堆排序具有较好的平均性能和稳定的时间复杂度,适用于大规模数据的排序。然而,堆排序的实现相对复杂,且在小规模数据上可能不如其他简单的排序算法效率高。
7. 哈希表(Hash Table)
const int TABLE_SIZE = 128;class HashNode {
public:int key;int value;HashNode* next;HashNode(int key, int value) : key(key), value(value), next(nullptr) {}
};class HashMap {
private:HashNode** table;
public:HashMap() {table = new HashNode*[TABLE_SIZE];for (int i = 0; i < TABLE_SIZE; i++) {table[i] = nullptr;}}~HashMap() {for (int i = 0; i < TABLE_SIZE; i++) {HashNode* current = table[i];while (current) {HashNode* temp = current;current = current->next;delete temp;}}delete[] table;}int get(int key) {int hashValue = (key % TABLE_SIZE);if (table[hashValue]) {HashNode* current = table[hashValue];while (current) {if (current->key == key) {return current->value;}current = current->next;}}return -1; // 如果没有找到键对应的值,返回-1}void insert(int key, int value) {int hashValue = (key % TABLE_SIZE);if (!table[hashValue]) {table[hashValue] = new HashNode(key, value);}else {HashNode* current = table[hashValue];while (current->next) {current = current->next;}current->next = new HashNode(key, value);}}void remove(int key) {int hashValue = (key % TABLE_SIZE);if (table[hashValue]) {HashNode* current = table[hashValue];HashNode* previous = nullptr;while (current) {if (current->key == key) {if (previous) {previous->next = current->next;}else {table[hashValue] = current->next;}delete current;break;}previous = current;current = current->next;}}}
};
思想
哈希表( H a s h Hash Hash T a b l e Table Table )是一种常用的数据结构,它通过哈希函数将键映射到特定的存储位置,以实现高效的数据访问和搜索。
哈希表的思想如下:
- 使用哈希函数将键转换为一个整数,这个整数可以作为数组的索引。
- 将键值对存储在哈希表中,以键的哈希值作为数组索引,在数组中存储对应的值。
- 当需要查找或插入一个键值对时,使用哈希函数计算键的哈希值,得到数组索引,然后在哈希表中对应的位置进行操作。
哈希表的特点:
- 快速访问:哈希表通过哈希函数直接计算出存储位置,因此可以在平均情况下以常数时间复杂度进行插入、删除和查找操作。
- 空间效率:哈希表使用数组和链表(或其他解决冲突的方法)来存储键值对,相比于数组或链表,可以更高效地利用存储空间。
- 冲突处理:由于哈希函数的输出可能相同,不同键的哈希值可能相同,这就产生了冲突。哈希表使用冲突处理机制来处理具有相同哈希值的键,常见的方法包括链地址法、开放地址法等。
哈希表在很多应用中被广泛使用,例如字典、缓存、数据库索引等。通过优化哈希函数的设计和解决冲突的方法,可以提高哈希表的效率和性能。
8. 图的深度优先搜索(Depth First Search,DFS)
class Graph {
private:int numVertices;list<int>* adjList;public:Graph(int numVertices) {this->numVertices = numVertices;adjList = new list<int>[numVertices];}~Graph() {delete[] adjList;}void addEdge(int src, int dest) {adjList[src].push_back(dest);}void DFSUtil(int v, bool visited[]) {visited[v] = true;cout << v << " ";list<int>::iterator it;for (it = adjList[v].begin(); it != adjList[v].end(); ++it) {if (!visited[*it]) {DFSUtil(*it, visited);}}}void DFS(int startVertex) {bool* visited = new bool[numVertices];for (int i = 0; i < numVertices; i++) {visited[i] = false;}DFSUtil(startVertex, visited);delete[] visited;}
};
思想
深度优先搜索( D F S DFS DFS )是一种经典的图搜索算法,它的思想是从图中的某个起始节点开始,沿着一条路径一直往下搜索直到不能再继续为止,然后返回到前一个节点继续搜索其他未被访问的路径,直到找到目标节点或遍历完所有可达节点。
具体的实现步骤如下:
- 创建一个栈,用于存储待遍历的节点。
- 将起始节点推入栈中,并标记其为已访问。
- 进入循环,直到栈为空:
- 弹出栈顶的节点,作为当前节点。
- 遍历当前节点的所有邻接节点:
- 如果邻接节点没有被访问过,将其推入栈中,并标记为已访问。
- 标记当前节点的遍历状态(根据需求,可以记录父节点或做其他处理)。
- 当栈为空时,遍历结束。
深度优先搜索的特点是沿着一条路径尽可能深入搜索,直到无法继续为止,然后回溯到前一个节点,继续搜索其他未被访问的路径。这样可以保证在搜索时能够完整地探索一个路径直到底部,然后再回溯到上一层继续搜索其他路径。
在有向图或无向图中,为了避免陷入循环,需要使用一个标记数组或哈希表来记录节点的访问状态。
D F S DFS DFS 常用于图的遍历、连通性判断、拓扑排序等问题。时间复杂度通常为 O ( V + E ) O(V+E) O(V+E) ,其中 V V V 表示图的节点数,E表示图的边数。
9. 图的广度优先搜索(Breadth First Search,BFS)
class Graph {
private:int numVertices;list<int>* adjList;public:Graph(int numVertices) {this->numVertices = numVertices;adjList = new list<int>[numVertices];}~Graph() {delete[] adjList;}void addEdge(int src, int dest) {adjList[src].push_back(dest);}void BFS(int startVertex) {bool* visited = new bool[numVertices];for (int i = 0; i < numVertices; i++) {visited[i] = false;}list<int> queue;visited[startVertex] = true;queue.push_back(startVertex);while (!queue.empty()) {int currVertex = queue.front();cout << currVertex << " ";queue.pop_front();list<int>::iterator it;for (it = adjList[currVertex].begin(); it != adjList[currVertex].end(); ++it) {if (!visited[*it]) {visited[*it] = true;queue.push_back(*it);}}}delete[] visited;}
};
思想
广度优先搜索( B F S BFS BFS )是一种经典的图搜索算法,它的思想是从图中的某个起始节点开始,逐层遍历其邻接节点,直到找到目标节点或遍历完所有可达节点。
具体的实现步骤如下:
- 创建一个队列,用于存储待遍历的节点。
- 将起始节点加入队列,并标记其为已访问。
- 进入循环,直到队列为空:
- 从队列中取出一个节点作为当前节点。
- 遍历当前节点的所有邻接节点:
- 如果邻接节点没有被访问过,将其加入队列,并标记为已访问。
- 标记当前节点的遍历状态(根据需求,可以记录父节点或距离等信息)。
- 当队列为空时,遍历结束。
广度优先搜索的特点是先遍历离起始节点近的层级,再逐渐扩展到离起始节点更远的层级。这样可以保证在搜索时找到的路径是离起始节点最短的路径。因此, B F S BFS BFS 常被用于求解最短路径或层级遍历等问题。
值得注意的是,在有向图或无向图中,为了避免重复访问节点,需要使用一个标记数组或哈希表来记录节点的访问状态。
B F S BFS BFS 的时间复杂度为 O ( V + E ) O(V+E) O(V+E) ,其中 V V V 表示图的节点数, E E E 表示图的边数。
10. Dijkstra最短路径算法
#include <limits.h>
#define V 9int minDistance(int dist[], bool sptSet[]) {int min = INT_MAX, min_index;for (int v = 0; v < V; v++)if (sptSet[v] == false && dist[v] <= min)min = dist[v], min_index = v;return min_index;
}void printPath(int parent[], int j, int idx) {if (parent[j]==-1)return;printPath(parent, parent[j], idx);printf("%d ", j+1);
}int printSolution(int *dist, int n, int *parent, int src) {int idx = 0;printf("Vertex\t\t Distance\tPath");for (int i = 0; i < V; i++) {if (i != src) {printf("\n%d -> %d \t\t %d\t\t%d ", src+1, i+1, dist[i], src+1);printPath(parent, i, idx);}}
}void dijkstra(int graph[V][V], int src) {int dist[V];bool sptSet[V];int parent[V];for (int i = 0; i < V; i++)dist[i] = INT_MAX, sptSet[i] = false;parent[src] = -1;dist[src] = 0;for (int count = 0; count < V - 1; count++) {int u = minDistance(dist, sptSet);sptSet[u] = true;for (int v = 0; v < V; v++)if (!sptSet[v] && graph[u][v] && dist[u] != INT_MAX && dist[u] + graph[u][v] < dist[v]) {parent[v] = u;dist[v] = dist[u] + graph[u][v];} }printSolution(dist, V, parent, src);
}
思想
Dijkstra最短路径算法是一种用于计算图中单源最短路径的经典算法,它的思想是通过不断更新当前已知的从源节点到各个节点的最短距离来逐步求解最短路径。
具体的实现步骤如下:
- 创建一个距离表,用于存储从源节点到各个节点的最短距离。初始时,源节点的最短距离设为 0 0 0 ,其他节点的最短距离设为无穷大。
- 创建一个集合,用于存储已经确定最短路径的节点。初始时集合为空。
- 选择最短距离最小的节点作为当前节点,并将其加入到已确定最短路径的集合中。
- 遍历当前节点的邻居节点:
- 如果经过当前节点到达邻居节点的距离小于邻居节点当前已知的最短距离,更新邻居节点的最短距离为经过当前节点到达邻居节点的距离。
- 重复步骤 3 3 3 和步骤 4 4 4 ,直到所有节点都被加入到已确定最短路径的集合中,或者目标节点的最短路径已经确定。
- 最终得到的距离表就是从源节点到各个节点的最短距离。
D i j k s t r a Dijkstra Dijkstra 算法基于广度优先搜索的思想,在每一次迭代选择最短距离的节点进行扩展,从而逐渐确定最短路径。它适用于没有负权边的有向图或无向图。时间复杂度通常为 O ( ∣ V ∣ 2 ) O(|V|^2) O(∣V∣2) ,其中 ∣ V ∣ |V| ∣V∣ 表示图的节点数,但使用堆等数据结构可以将时间复杂度优化至 O ( ( ∣ E ∣ + ∣ V ∣ ) l o g ∣ V ∣ ) O((|E|+|V|)log|V|) O((∣E∣+∣V∣)log∣V∣) ,其中 ∣ E ∣ |E| ∣E∣ 表示图的边数。
总结
以上是十个常用的算法示例,涵盖了排序、查找、图算法等多个领域。掌握这些算法能够提高程序员的算法思维和解决问题的能力。希望这些示例对您有所帮助!
相关文章:

程序员必须掌握哪些算法?
目录 简介1. 冒泡排序(Bubble Sort)思想 2. 快速排序(Quick Sort)思想 3. 二分查找(Binary Search)思想 4. 归并排序(Merge Sort)思想 5. 插入排序(Insertion Sort&#…...

Java高级之File类、节点流、缓冲流、转换流、标准I/O流、打印流、数据流
第13章 IO流 文章目录 一、File类的使用1.1、如何创建File类的实例1.2、常用方法1.2.1、File类的获取功能1.2.2、File类的重命名功能1.2.3、File类的判断功能1.2.4、File类的创建功能1.2.5、File类的删除功能 二、IO流原理及流的分类2.1、Java IO原理2.2、流的分类/体系结构 三…...
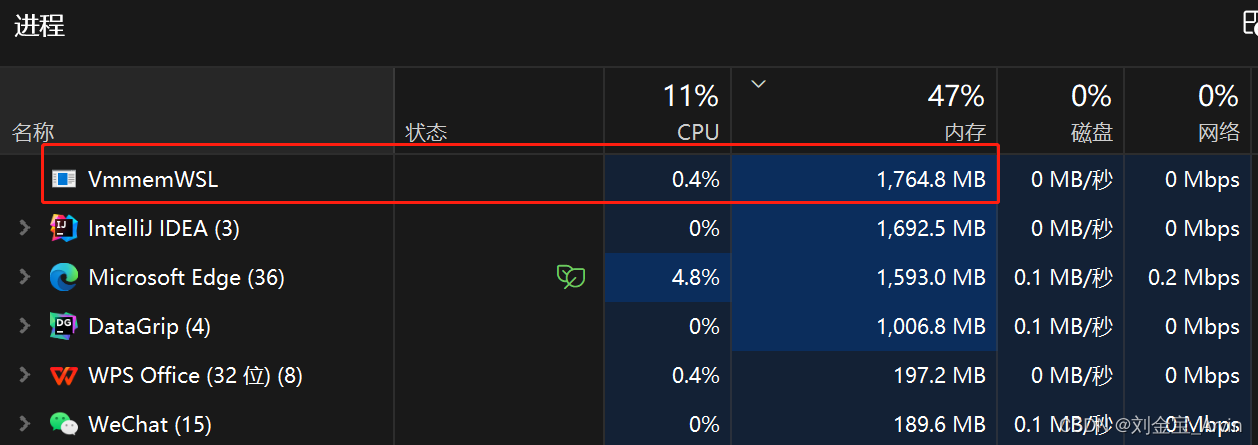
解决WSL2占用内存过多问题(Docker on WSL2: VmmemWSL)
解决WSL2占用内存过多问题(Docker on WSL2: VmmemWSL) 一、问题描述二、问题解决2.1 创建.wslconfig文件2.2 重启wsl2 一、问题描述 安装完WSL2后,又安装了Docker,使用了一段时间,发现电脑变卡,进一步查看…...
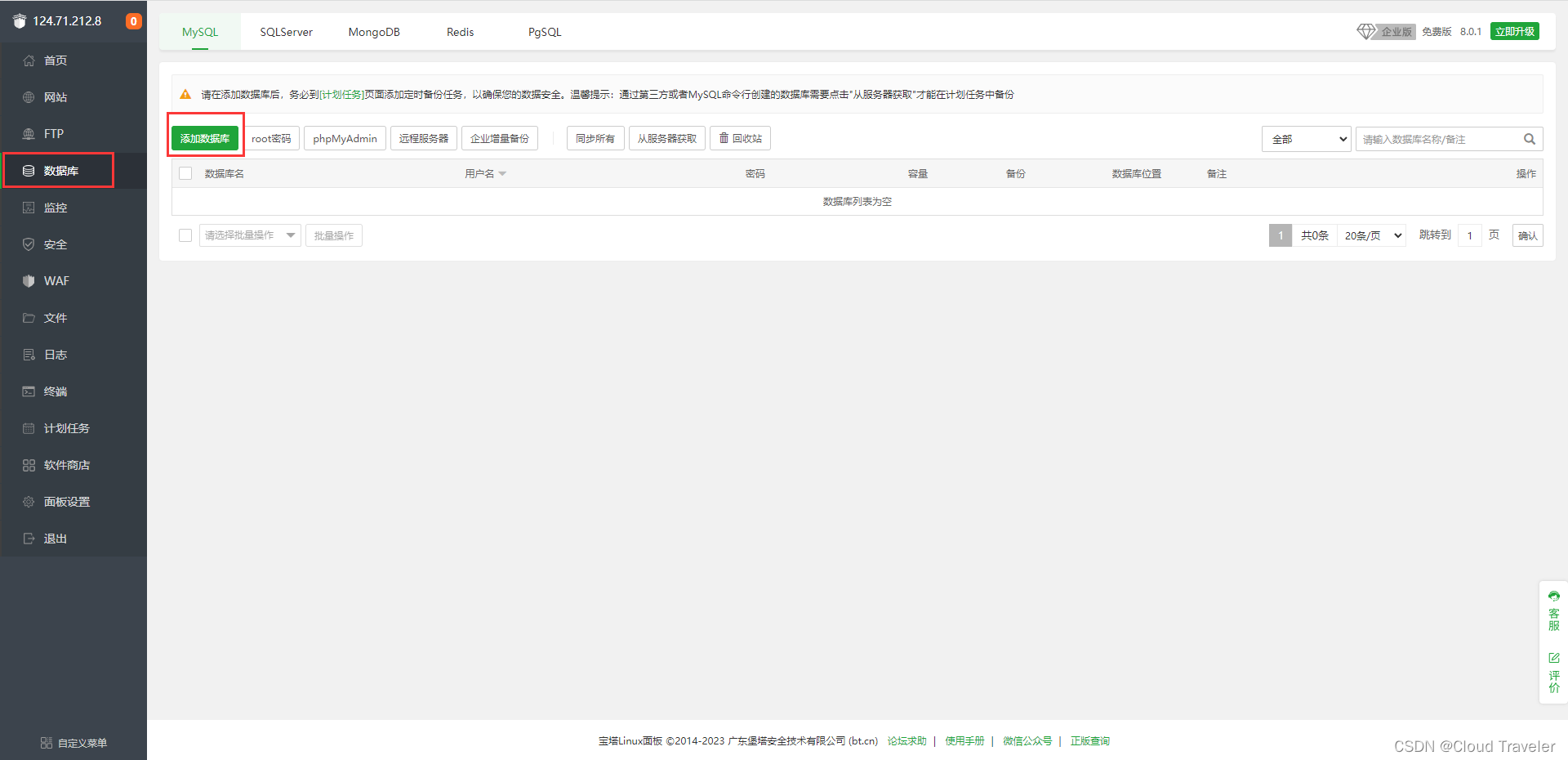
华为云云耀云服务器L实例评测|了解配置和管理L型云服务器
华为云云耀云服务器L实例配置和管理教程 华为云云耀云服务器L实例的介绍概述特点优势与弹性云服务器(ECS)的对比 注册和创建L型云服务器注册华为云账号创建L型云服务器实例配置实例参数配置其他参数尝试登录 远程登录 L实例查看公网ip通过本地shell远程连…...
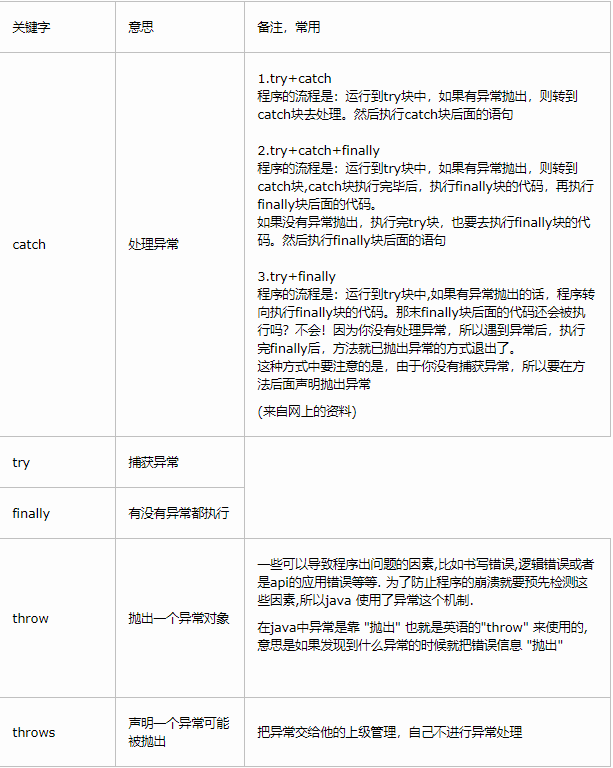
【面试题】——Java基础篇(33题)
文章目录 1. 八大基本数据类型分类2. 重写和重载的区别3. int和integer区别4. Java的关键字5. 什么是自动装箱和拆箱?6. 什么是Java的多态性?7. 接口和抽象类的区别?8. Java中如何处理异常?9. Java中的final关键字有什么作用&…...

记一次 .NET 某电力系统 内存暴涨分析
一:背景 1. 讲故事 前些天有位朋友找到我,说他生产上的程序有内存暴涨情况,让我帮忙看下怎么回事,最简单粗暴的方法就是让朋友在内存暴涨的时候抓一个dump下来,看一看大概就知道咋回事了。 二:Windbg 分…...

1.SpringEL初始
SpringEL初始 文章目录 SpringEL初始什么是SpringELSpring BeansSpring EL以XML形式Spring EL以注解形式启用自动组件扫描 执行输出 什么是SpringEL Spring EL与OGNL和JSF EL相似,计算评估或在bean创建时执行。此外,所有的Spring表达式都可以通过XML或注…...

HTTP 状态码
状态码状态码英文名称中文描述100Continue继续。客户端应继续其请求101Switching Protocols切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议200OK请求成功。一般用于GET与POST请求201Created已创建。成功…...
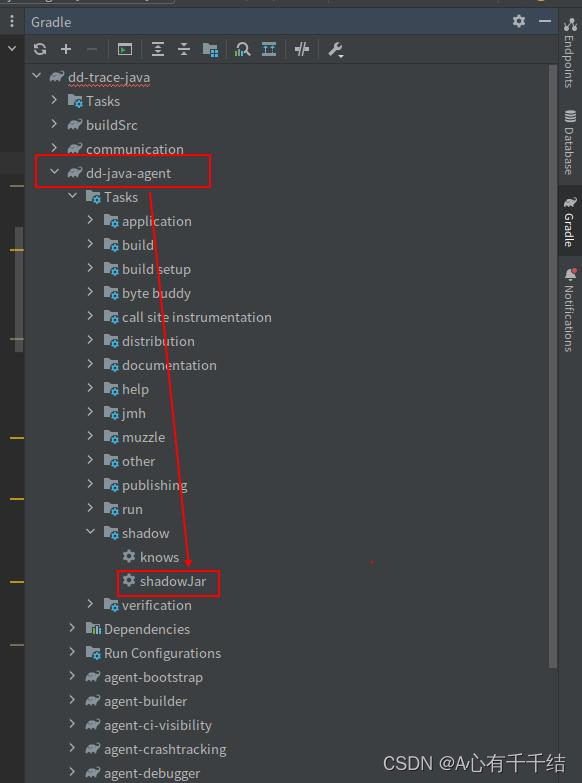
ddtrace 系列篇之 dd-trace-java 项目编译
dd-trace-java 是 Datadog 开源的 java APM 框架,本文主要讲解如何编译 dd-trace-java 项目。 环境准备 JDK 编译环境(三个都要:jdk8\jdk11\jdk17) Gradle 8 Maven 3.9 (需要 15G 以上的存储空间存放依赖) Git >2 (低于会出现一想不到的异常…...
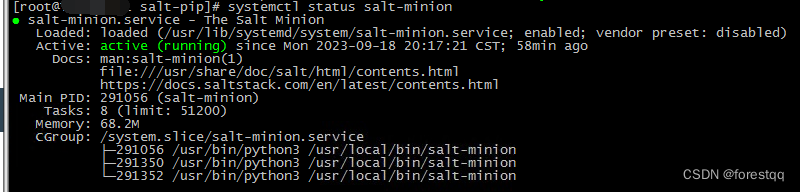
华为aarch64架构的泰山服务器EulerOS 2.0 (SP8)系统离线安装saltstack3003.1实践
华为泰山服务器的CPU芯片架构为aarch64,所装系统为EulerOS 2.0 (SP8)aarch64系统,安装saltstack比较困难。本文讲解通过pip安装方式离线安装saltstack3003.1以进行集中化管理和维护。 一、系统环境 1、操作系统版本 [rootlocalhost ~]# cat /etc/os-r…...
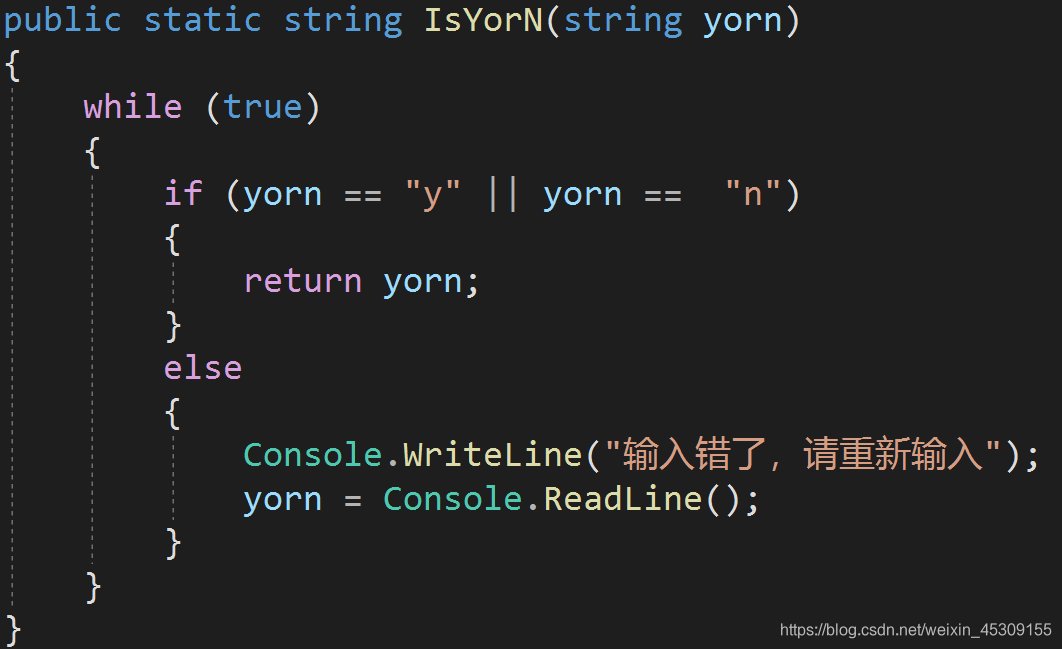
C#中的方法
引言 在C#编程语言中,方法是一种封装了一系列可执行代码的重要构建块。通过方法,我们可以将代码逻辑进行模块化和复用,提高代码的可读性和可维护性。本文将深入探讨C#中的方法的定义、参数传递、返回值、重载、递归等方面的知识,…...

【Flowable】使用UEL整合Springboot从0到1(四)
前言 在前面我们介绍了Springboot简单使用了foleable以及flowableUI的安装和使用,在之前我们分配任务的处理人的时候都是通过Assignee去指定固定的人的。这在实际业务中是不合适的,我们希望在流程中动态的去解析每个节点的处理人,当前flowab…...

WebGL 计算点光源下的漫反射光颜色
目录 点光源光 逐顶点光照(插值) 示例程序(PointLightedCube.js) 代码详解 示例效果 逐顶点处理点光源光照效果时出现的不自然现象 更逼真:逐片元光照 示例程序(PointLightedCube_perFragment.js…...

Java精品项目源码第61期垃圾分类科普平台(代号V061)
Java精品项目源码第61期垃圾分类科普平台(代号V061) 大家好,小辰今天给大家介绍一个垃圾分类科普平台,演示视频公众号(小辰哥的Java)对号查询观看即可 文章目录 Java精品项目源码第61期垃圾分类科普平台(代号V061)难度指数&…...
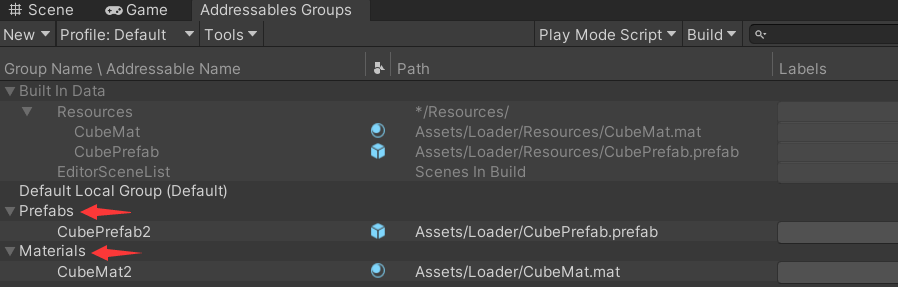
【Unity3D】资源管理
1 前言 Unity 中资源管理方案主要有 Resources、TextAsset、ScriptableObject 、AssetDatabase、PlayerPrefs、Addressables、AssetBundle、SQLite,本文将介绍其中大部分方案。 2 Resources Resources 主要用于加载资源,被加载的资源需要放在 Resources…...

数据结构-----队列
目录 前言 队列 定义 队列的定义和操作方法 队列节点的定义 操作方式 顺序表实现队列(C/C代码) 链表实现队列(C/C代码) Python语言实现队列 前言 排队是我们日常生活中必不可少的一件事,去饭堂打饭的时候排队&a…...

postgresql教程
postgreSQL教程目录 postgreSQL 创建数据库的方式:postgreSQL删除数据库的方式:PostgreSQL 创建表格postgre删除表格:postgreSQL INSERT INTO 语句postgreSQL SELECT 语句:postgresql索引:什么情况下要避免使用索引? p…...

1万6千多最好的背单词SQLITE\ACCESS数据库
本来是实在不想再整英语类的数据了,因为实在是太多了,奈何今天弄到的这份数据库实在很精彩,因此还是希望能够有人喜欢。 搞一个“accept”字段的样例: 【explain】 vi. 承认;同意;承兑; vt. 接受;承认;承担;承兑; 【etyma】 ac…...

springboot aop Aspectj 切面
常用: Aspect、Component、Pointcut、Before、AfterReturning SpringBoot的AOP(aspect注解)的简单使用 - 知乎 springboot项目中引入Aspectj并使用_springboot引入aspectj_山鬼谣me的博客-CSDN博客...

Leetcode 2862. Maximum Element-Sum of a Complete Subset of Indices
Leetcode 2862. Maximum Element-Sum of a Complete Subset of Indices 1. 解题思路2. 代码实现 题目链接:2862. Maximum Element-Sum of a Complete Subset of Indices 1. 解题思路 这一题的核心在于想明白一点: 要使得子序列当中任意两个数之积均为…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...