Python 入门之文件和异常处理
文件和异常
至此,已经掌握了编写组织有序而易于使用的程序所需的基本技能,该考虑让程序目标更明确、用途更大了。
本章,将学习文件处理,它能让程序快速分析大量的数据,也将学习错误处理,避免程序在面对意外时崩溃,将学习异常,它们时python创建的特殊对象,用于管理程序运行时出现的错误,还将学习json 模块,它让你能够保存用户数据,以免在程序停止运行后丢失。
1、从文件中读取数据
文本文件可以存储很多数据,要使用文本文件中的信息,首先需要将信息读取到内存中,为此,你可以一次性读取文件的全部内容,也可以每一次一行的方式逐步读取。
1.1、读取整个文件
要读取整个文件,只需将整个文件名读取到内存即可
首先,在程序所在文件目录,创建一个名为pi_diigits.txt 的文本文件,里面可以输入任何内容,我们输入了圆周率,并每隔10 个数字分行书写,再创建一个名为file_reader.py 的文件,下面我们将在这个程序中读取pi_digits.txt 中的信息,并显示到屏幕上:
# pi_digits.txt
3.14159263589793238462643383279
# file_reader.py
with open('pi_digits.txt') as file_object:contents = file_object.read()print(contents.rstrip()) # 打印出来的信息比原文本信息多了一个空行,为此使用rstrip()方法将其去掉
-----------
3.14159263589793238462643383279
在这个程序中,我们使用open()函数来打开文件,open()函数有很多参数,这里我们只需知道前两个即可,第一个为要传入的文件名,第二个为文件的打开模式,python会在程序所在的目录去寻找pi_digits.txt 文件,所以首先需要将指定文件放入到程序所在目录。
打开文件后,返回一个文件对象,在这里我们将返回的文件对象命名为file_object,第二行使用read()方法这个文件全部内容,并将其作为一个长字符串存储到变量contents 中,再打印。
事实上,文件打开就需要关闭,为此我们可以调用close()函数关闭文件,但有时如果程序存在bug,导致clos()语句未执行,文件将不会关闭,有可能导致数据丢失或受损,所以在这里我们使用了关键字with,它能在适当时机自动关闭文件,让python自己去判断处理,你只管打开文件,并在需要时使用它。
1.2、文件路径
在给open()函数传入参数时,有时文件并不在程序文件所在目录,比如程序所在的文件夹为python_work ,而在文件夹python_work 中,有一个名为text_files 的文件夹,我们要打开text_files 目录下的filename.txt 文件,如果我们只传入python_work\filename.txt 并不能找到,因为python之会在python_work 中与程序文件同一个目录的文件中找,为此,我们需要提供文件路径,让python到系统特定位置自己查找:
- 相对路径
相对路径指的是该位置相对于当前运行的程序所在的目录下的某个文件夹中
# 这是windows 系统中的方式,OS X中使用斜杠(/)
with open('text_files\filename.txt') as file_object:
- 绝对路径
绝对路径指的是文件的精确位置,无论文件在电脑哪个磁盘的哪个文件夹中
# 这是windows 系统中的方式,书上使用的是一个反斜杠,经测试为两个
file_path = 'C:\\Users\\hj\Desktop\\Deskto Folder\\new words.txt'
with open(file_path) as file_object:# 这是OS X 系统方式(为测试)
file_path = '/home/ehmatthes/other_files/text_files/fillname.txt'
1.3、逐行读取
读取文件时,常需要检查其中的每一行,可能要在文件中查找特定信息,或者要以某种方式修改文件中的文本,要以每次一行的方式检查文件,可以对文件对象使用for循环:
filename = 'pi_digits.txt'
with open(filename) as file_object:for line in file_object: # 对文本对象执行循环遍历文件中的每一行print(line.rstrip()) # 打印每一行,会对出空白行,因此需要去掉
-----------
3.14159263589793238462643383279
1.4、创建一个包含文件各行内容的列表
使用with 关键字,open()返回的文件对象只能在with 代码块内使用,要在代码块外使用,可以将文件各行存储到一个列表中,你可以立即处理也可以推迟处理。
下面将with 代码块中的pi_digits.txt 文件各行内容存储到一个列表中,再在外面使用:
filename = 'pi_digits.txt'with open(filename) as file_object:lines = file_object.readlines() # readlines() 方法可以从文件中读取每一行,并将其存储到一个列表中(lines)for line in lines: # 遍历列表linesprint(line.rstrip())
1.5、使用文件的内容
将文件读取到内存后,就可以以任何方式使用这些数据了,下面以简单的方式使用圆周率,创建一个字符串,它包含文件中存储的所有数字,且没有空格:
filename = 'pi_digits.txt'
with open(filename) as file_object:lines = file_object.readlines()pi_string = '' # 创建一个变量,用于存储文件中的内容
for line in lines:pi_string += lines.strip() # 将读取的内容添加到pi_string 中print(pi_string)
print(len(pi_string)) # 打印其长度
-------------
3.14159263589793238462643383279
31
读取文本文件时,python将所有的文本都解读为字符串,如果读取的是数字,并要将其作为数值使用,必须使用函数 int()将其转换为整数,或float()将其转换为浮点数。
1.6、读取一个包含百万位的大型文件
前面我们都是读取一个只有三行的文本文件,但这些代码示例也可以处理大得多的文件,python没有任何限制,只要有足够内存。
如果有个文本文件,包含了精确到小数点后1000000位的圆周率,也可以使用前面的方式读取,这里只打印小数点后50位:
filename = 'pi_million_digits.txt'
with open(filename) as file_object:lines = file_object.readlines()pi_string = ''
for line in lines:pi_string += line.strip()
print(pi_string[:52] + '....') # 打印小数点后50位
print(len(pi_string))
-------------
3.14159265358979323846264338327950288419716939937510....
1000002
1.7、检查文件中是否包含你所需的信息
如检查520这个数字是否包含在百万级的圆周率中:
filename = 'pi_million_digits.txt'
with open(filename) as file_object:lines = file_object.readlines()pi_string = ''
for line in lines:pi_string += line.strip()nums = input('Enter a num: ')
if nums in pi_string:print('This num in pi_string.')
else:print('This num not in pi_string.')
----------
Enter a num: 520
This num in pi_string.
练习
- 创建一个文本文件名为learning_python.txt,并将其存储到程序所在目录,内容随意,将各行存储到一个列表中,再在with 代码块外打印它们:
with open('learning_python.txt') as file_object:lines = file_object.readlines()for line in lines:print(line.rstrip())
-------
In Python you can learned:数据类型(字符串、整型、浮点型、布尔型)
In Python you can learned:列表、元组、字典
In Python you can learned:if语句、while循环
In Python you can learned:函数
In Python you can learned:类、模块
In Python you can learned:文件和错误异常
In Python you can learned:用户输入
- 将文件中的Python 替换成C,(可使用replcae(‘old’, ‘new’)方法):
with open('learning_python.txt') as file_object:lines = file_object.readlines()for line in lines:line = line.rstrip()print(line.replace('Python', 'C')) # replace()方法有2个参数,第1个为要替换的元素,第2个为替换的元素
-------------
In C you can learned:数据类型(字符串、整型、浮点型、布尔型)
In C you can learned:列表、元组、字典
In C you can learned:if语句、while循环
In C you can learned:函数
In C you can learned:类、模块
In C you can learned:文件和错误异常
In C you can learned:用户输入
2、写入文件
要想写入文件,可以对文件对象使用write()方法
文件打开模式(open()函数),它有2个实参,第一个为要打开的文件名称,第二个为打开模式(如果不传入第二个实参,python默认只读打开文件),第二个实参可选以下模式:
| 打开模式 | 执行操作 |
|---|---|
| ‘r’ | 以只读方式打开文件(默认) |
| ‘w’ | 以写入方式打开,会覆盖原有文件 |
| ‘x’ | 如果文件存在,打开引发异常 |
| ‘a’ | 以写入方式打开,若文件存在,则在末尾追加写入 |
| ‘b’ | 以二进制模式打开 |
| ‘t’ | 以文本模式打开(默认) |
| ‘+’ | 可读写模式(可添加到其他模式中使用) |
| ‘U’ | 通用换行符支持 |
2.1、写入空文件
要将文本写入文件,在调用open()函数时传入第二个实参,告诉python你要写入打开的文件模式,再利用文件对象的一些方法对文件进行修改:
| 文件对象方法 | 执行操作 |
|---|---|
| close() | 关闭文件 |
| read(size) | 读取size个字符,若未指定size或为负,则读取所有字符 |
| readline(size) | 读取整行,定义size则返回一行的size个字节 |
| readlines(size) | 读取文件的每一行,并将其存储到一个列表中 |
| write(str) | 将字符串str写入文件 |
| writelines(seq) | 写入字符串序列(列表、元组等) |
| tell() | 返回文件当前位置 |
| seek(offset[, whence]) | 设置文件当前位置,f.seek(0, 0/1/2),0代表起始位置,1代表当前位置,2代表文件末尾 |
filename = 'C:\\Users\\hj\\Desktop\\test\\hello.txt' # 在这个路径创建一个hello.txt的文本文件with open(filename, 'w') as f: # 以写入模式打开文件,如果文件不存在,open()函数自动创建它f.write('hello word!') # 如果要写入的是数值,应先用str()将其转换2.2、写入多行
write()方法不会在你写入的文本末尾添加换行符,因此需要在末尾添加换行符:
filename = 'C:\\Users\\hj\\Desktop\\test\\hello.txt'
with open(filename, 'w') as f:f.write('hello word!\n') # 在末尾添加换行符f.write('Life is short, you need Python!\n')
2.3、附加到文件
如果要给文件添加内容,又不想覆盖原因内容,可以使用附加模式打开文件,它不会清空原因内容,只会在末尾添加,如果指定的文件不存在,python将创建一个空文件。
filename = 'C:\\Users\\hj\\Desktop\\test\\hello.txt'
with open(filename, 'a') as f:#f.write('hello word!\n') # 在末尾添加换行符#f.write('Life is short, you need Python!\n')f.write('我喜欢Python。\n')
--------------------
hello word!
Life is short, you need Python!
我喜欢Python。
练习一
编写一个程序,提示用户输入其名字,用户做出响应后,将其名字写入到文件 guest.txt 中:
name = input('Enter your name: ')
filename = 'C:\\Users\\hj\\Desktop\\test\\guest.txt'
with open(filename, 'w') as f:f.write(name)
练习二
编写一个while 循环,提示用户输入其名字,并打印一句问候语,再将访问记录添加到文件guest_book.txt 中,确保每条记录独占一行:
filename = 'C:\\Users\\hj\\Desktop\\test\\guest_book.txt'
print("Enter 'quit' when you are finished.")while True:name = input('Enter your name: ')if name == 'quit':breakelse:with open(filename, 'a') as f:f.write(name + '\n')print('Hi ' + name + ", you're been added to the guest book.")练习三
关于编程的调查,编写一个while 循环,询问用户为何喜欢编程,每当用户输入一个原因后,都将其添加到一个存储所有原因的文件中:
filename = 'C:\\Users\\hj\\Desktop\\test\\reason.txt'
responses = []while True:response = input('Enter why do you like programming? ')responses.append(response)continue_poll = input('would you like to let someone else respond?(y/n)')if continue_poll != 'y':breakwith open(filename, 'a') as f:for response in responses:f.write(response + '\n')
3、异常
当发生让python 不知所措的错误时,它会创建一个异常对象,如果你编写了处理该异常的代码,程序将继续执行,否则会引发一个错误,显示 traceback,其中包含异常报告。
处理异常,通常使用(try–except 代码块),它让python执行指定操作,同时报告python发生异常该怎么办,即使出现了异常,程序也能继续执行,而不会出现让用户困惑的traceback。
3.1、处理 ZeroDivisionError 异常
这个异常意为(除数(分母)为0的异常),以下为一个简单的计算题,要用户输入2个数字,然后求其商,如果没有(try–except 代码块),当用户输入second name 为0 时,程序将奔溃:
print("Give me a two numbers, and I'll divide them.")
print("Enter 'q' to quit.")while True:first_name = input('\nFirst name: ')if first_name == 'q':breaksecond_name = input('\nSecond name: ')if second_name == 'q':breakanswer = int(first_name) / int(second_name)print(answer)
---------------------------------------------
Give me a two numbers, and I'll divide them.
Enter 'q' to quit.First name: 5Second name: 0
Traceback (most recent call last):File "C:/Users/hj/PycharmProjects/package/file_reader.py", line 102, in <module>answer = int(first_name) / int(second_name)
ZeroDivisionError: division by zero3.2、使用异常避免崩溃
发生错误时,如果程序还有工作没有完成,那么能妥善处理错误就显得尤其重要,因此要求在用户输入无效程序发生错误时,程序能提示用户提供有效输入。
**将容易出错的代码放在 try 代码块后,except 代码块告诉python,如果它尝试运行 try 代码块中的代码时发生了异常该怎么办,else 代码块则是在 try 代码块中的代码能成功执行才需要执行的代码。 **
print("Give me a two numbers, and I'll divide them.")
print("Enter 'q' to quit.")while True:first_name = input('\nFirst name: ')if first_name == 'q':breaksecond_name = input('\nSecond name: ')if second_name == 'q':breaktry: # 添加try-except代码块answer = int(first_name) / int(second_name)except ZeroDivisionError: # 若用户输入second name 为0,则执行这条语句,提示用户print('You can not divide by zero')else: # 若try 代码块中的代码没有发生异常,则继续执行这段代码块print(answer)---------------------------------
Give me a two numbers, and I'll divide them.
Enter 'q' to quit.First name: 6Second name: 2
3.0
3.3、处理 FileNotFoundError 异常
处理文件时,一种常见的问题是找不到文件,有可能是你找到文件不存在或者在别的目录,从而引发 FileNotFoundError 错误:
filename = 'alice.txt'try:with open(filename) as f:contents = f.readline()except FileNotFoundError:msg = 'sorry, ' + filename + ' does not exist.'print(msg)
----------------------------
sorry, alice.txtdoes not exist.
3.4、分析文本
你可以分析包含整本书的文本文件,比如计算文件中包含多少个单词,我们将使用split()方法,它可以将一串字符串分隔成若干元素,并存储在一个列表中,以空格为分隔符:
# programming.py
filename = 'programming.txt'try:with open(filename) as f:contents = f.read() # 将文件对象读取出来并存储到变量 contents 中
except FileNotFoundError:msg = 'Sorry, the file ' + filename + ' does not exist.'print(msg)
else:# 计算文件大致包含了多少个单词words = contents.spilt() # 将变量 contents 分隔,并存储到列表 words 中num_words = len(words) # 获取列表的长度print('This file ' + filename + ' has about ' + str(num_words) + 'words.') # 打印文件中有多少个单词#print(words)
----------------------The fileprogramming.txt has about 4 words.
#['I', 'love', 'Python!', 'hello']
3.5、使用多个文件
下面举例分析计算多个文件,看每个文件包含多少个单词,特意将new words.txt 没放入程序所在目录,测试程序是否能检测出来并正常运行:
def count_words(filename):"""计算一个文件包含多少个单词"""try:with open(filename) as f:contents = f.read()except FileNotFoundError:msg = 'Sorry, the file ' + filename + ' does not exist.'print(msg)else:words = contents.split()num_words = len(words)print('The file ' + filename + ' has about ' + str(num_words) + ' words.')filenames = ['programming.txt', 'learning_python.txt', 'pi_million_digits.txt', 'new words.txt']
# 将文件名存放到列表 filenames 中
for filename in filenames: # 遍历列表 filenamescount_words(filename) # 传入参数filename-----------------------------------
The file programming.txt has about 4 words.
The file learning_python.txt has about 35 words.
The file pi_million_digits.txt has about 10000 words.
Sorry, the file new words.txt does not exist.
3.6、pass 语句
在之前的实例中,我们在except 代码块中告诉用户原因,但有时并不是每次都需要告知用户原因的,我们可以 用 pass 语句使程序在程序发生异常“一声不吭”,明确告诉python 什么都不用做:
def count_words(filename):try:with open(filename) as f:contents = f.read()except FileNotFoundError:pass # 使用 pass 语句,直接跳过else:words = contents.split()num_words = len(words)print('The file ' + filename + ' has about ' + str(num_words) + ' words.')filenames = ['programming.txt', 'learning_python.txt', 'pi_million_digits.txt', 'new words.txt']
for filename in filenames:count_words(filename)
-------------------------The file programming.txt has about 4 words.
The file learning_python.txt has about 35 words.
The file pi_million_digits.txt has about 10000 words.
pass 语句还充当了占位符,它提醒你在程序的某个地方什么都没有做,并且以后也许要在这里做些什么。例如,在这个程序中,我们可能觉得将找不到的文件名称写入到文件 missing_files.txt 中,用户看不到这个文件,但我们可以读取这个文件,进而处理所有文件找不到的问题。
3.7、决定报告哪些错误
什么情况下该向用户报告错误?又在什么情况下异常时一声不吭?
若用户知道要分析哪些文件,他们可能希望在有文件没有分析时出现一条消息,就将原因告诉他们,若用户只想看到结果,而不关心要分析哪些文件,那么就一声不吭,向用户显示他不想看到的信息会降低程序的可用性。
编写好的程序,经过测试不易出现内部错误,但只要程序依赖于外部因素,如输入、存在指定文件、网络连接等就有可能出现异常,凭借经验可判断该在何时添加异常处理块,以及是否该向用户提供多少相关信息。
4、存储数据
很多程序都要求用户输入某种信息,如存储游戏首选项或提供可视化的数据,不管是什么,程序都把信息存储在列表和字典等数据结构中,用户关闭程序时,保存信息,一种简单的方式就是使用json 模块来存储数据。
json 模块能将简单的python数据转存到文件中,并在程序再次运行时加载该文件,json 是跨平台的,并非只有python能用,其他语言也可以使用,因此可以分享给别人。
4.1、使用 json.dump()和 json.load()
- json.dump()函数:用来将文件存储到文件,它接受两个实参(要存储的数据、用于存储数据的文件对象)
- json.load()函数,用于程序再次运行加载文件到内存
# 将一个列表存储到文件中,使用json模块
import json # 导入 json 模块numbers = [2, 3, 4, 5, 6] # 定义一个列表
file_name = 'json_file.json'with open(file_name, 'w') as f: # 使用写入模式json.dump(numbers, f) # 将numbers 转存到file_name中运行程序,没有输出,但打开 json_file.json 文件,numbers 数据已经存储到其中。
再编写一个程序,使用 json.load()函数将这个列表读取到内存中
import jsonfile_name = 'json_file.json'
with open(file_name) as f:numbers = json.load(f) # 使用json.load()将数据加载到内存print(numbers)
-------------------------------------------------
[2, 3, 4, 5, 6]
4.2、保存和读取用户生成的数据
使用 json 模块保存数据有个好处,它能在你下次运行程序时,记住你的信息,比如下面例子,用户首次运行程序被要求输入其名字,待再次运行程序时,程序就已经记住他了:
# remember_me.py
import jsonfile_name = 'username.json'try:with open(file_name) as f: # 使用异常代码块,判断用户是否是首次输入,若是首次(文件不存在),则执行except 代码块,要求用户输入名字username = json.load(f)
except FileNotFoundError: username = input("What's your name? ")with open(file_name, 'w') as f:json.dump(username, f) # 将用户名写入文件中,此时程序已经记住用户名print("We'll remember you when you come back, " + username + '!')
else:print('Welcome back, ' + username + '!')
------------------------------------------------------
# 用户首次运行时结果
What's your name? alice
We'll remember you when you come back, alice!# 用户再次运行程序时结果
Welcome back, alice!
4.3、重构
有时会遇到这样的情况,程序能够正确运行,但是可以进一步改进—将代码划分为一系列的具体工作函数,这种过程称为重构,它可以使代码更清晰、更易于理解、更易拓展。
要重构 remember_me.py ,我们可以将其大部分逻辑放到一个或多个函数中,它的重点是问候,因此我们将其放入到一个名为 great_user ()的函数中:
# remember_me.py
import jsondef great_user():"""问候用户,并指出其名"""file_name = 'username.json'try:with open(file_name) as f:username = json.load(f)except FileNotFoundError:username = input("What's your name? ")with open(file_name, 'w') as f:json.dump(username, f)print("We'll remember you when you come back, " + username + '!')else:print('Welcome back, ' + username + '!')
great_user()
考虑到使用一个函数,它不仅问候用户,还在存储用户名时获取它,而在没有存储用户名时提示用户输入,所有的任务都在一个函数中,我们觉得再重构它,将其获取用户名的代码转移到另外一个函数(get_stored_username())中,提示用户输入的放入另外一个函数(get_new_username())中:
import jsondef get_stored_name(): # 判断文件是否存在,要是不存在就返回一个空,否则返回用户名"""如果存储了用户名就获取它"""file_name = 'user_name.json'try:with open(file_name) as f:username = json.load(f)except FileNotFoundError:return Noneelse:return usernamedef get_new_username(): # 如果文件存在(即用户名存在),因为返回的也是用户名,故不执行,否则提示用户用户输入用户名"""提示用户输入用户名"""username = input("What's your name? ")file_name = 'user_name.json'with open(file_name, 'w') as f:json.dump(username, f)return usernamedef great_user():"""问候用户,并指出其名"""username = get_stored_name() # 若文件存在,返回值为用户名(即为真),否则返回值为空(假)if username: # 返回值为真时执行print('Welcome back, ' + username + '!')else: # 返回值为假时执行username = get_new_username()print("We'll remember you when you come back, " + username + '!')great_user()
----------------------------------
# 首次运行
What's your name? alice
We'll remember you when you come back, alice!# 第二次运行
Welcome back, alice!
我们调用great_user(),它打印一条合适的消息:要么欢迎老用户回来,要么问候新用户,为此它首先调用get_stored_name(),这个函数只负责获取存储的用户名(若存储了的话),再在必要时调用get_new_username(),这个函数只负责获取并存储新用户的用户名,每个函数分工合作。
练习
验证用户,remember_me.py 中,当前和最后一次运行该程序的用户并非同一人,为此我们可以在great_user()中打印用户回来的消息前,首先询问他用户名是否正确,如果不对,就调用get_new_username()让用户输入正确的用户名:
# remember_me.py
import jsondef get_stored_name():--snip--def get_new_username():--snip--def great_user():"""问候用户,并指出其名"""username = get_stored_name()if username:correct = input('Are you ' + username + '? (y/n) ')if correct == 'y':print('Welcome back, ' + username + '!')else:username = get_new_username()print("We'll remember you when you come back, " + username + '!')else:username = get_new_username()print("We'll remember you when you come back, " + username + '!')great_user()
---------------------------------------------
Are you alice? (y/n) n
What's your name? lila
We'll remember you when you come back.
附录
常见的Python 异常:
- AssertionError:断言语句失败
当assert 关键字后的条件为假时,程序停止抛出AssertionError异常。
>>> a = [2, 3, 4]
>>> assert len(a) < 0
Traceback (most recent call last):File "<pyshell#1>", line 1, in <module>assert len(a) < 0
AssertionError
- AttributeError:当访问的对象属性不存在时抛出异常
>>> my_fish = [2, 3, 4]
>>> my_fish.goldfish
Traceback (most recent call last):File "<pyshell#3>", line 1, in <module>my_fish.goldfish
AttributeError: 'list' object has no attribute 'goldfish'
- IndexError:索引超出序列范围
>>> a = [2, 3, 4]
>>> a[3]
Traceback (most recent call last):File "<pyshell#6>", line 1, in <module>a[3]
IndexError: list index out of range
- KeyError:字典中查找一个不存在的关键字
当在字典中查找一个不存在的关键字时,引发KeyError 异常
>>> my_dict = {'one': 1, 'two': 2}
>>> my_dict['three']
Traceback (most recent call last):File "<pyshell#9>", line 1, in <module>my_dict['three']
KeyError: 'three'
- NameError:尝试访问一个不存在的变量
>>> name
Traceback (most recent call last):File "<pyshell#10>", line 1, in <module>name
NameError: name 'name' is not defined
- OSError:操作系统产生的异常
这是操作系统引发的异常,因素有很多,网络、系统或其他,与FileNotFoundError 找不到文件差不多,FileNotFoundError 是 OSError 的子类。
- SyntaxError:语法错误
一般会提示你哪里语法错误,找出修改即可
>>> print 'heelo'
SyntaxError: Missing parentheses in call to 'print'
- TypeError:不同类型间的无效操作
>>> 1 + '1'
Traceback (most recent call last):File "<pyshell#12>", line 1, in <module>1 + '1'
TypeError: unsupported operand type(s) for +: 'int' and 'str'
- IndentationError:缩进错误
a = 3
if a > 1:
a += 1
-----------------------------------------------File "C:/Users/hj/PycharmProjects/package/file_reader.py", line 272a += 1^
IndentationError: expected an indented block
- ValueError:传入无效的参数
import mathx1 = math.sqrt(-1) # math 模块中的sqrt()函数是用来计算非负实数的平方根(即参数为非负实数)
print(x1)
-----------------------
Traceback (most recent call last):File "C:/Users/hj/PycharmProjects/package/file_reader.py", line 273, in <module>x1 = math.sqrt(-1)
ValueError: math domain error
- ZeroDivisionError :除数为零
- FileNotFoundError:文件不存在或者不在索引目录
相关文章:

Python 入门之文件和异常处理
文件和异常 至此,已经掌握了编写组织有序而易于使用的程序所需的基本技能,该考虑让程序目标更明确、用途更大了。 本章,将学习文件处理,它能让程序快速分析大量的数据,也将学习错误处理,避免程序在面对意…...
操作系统作业
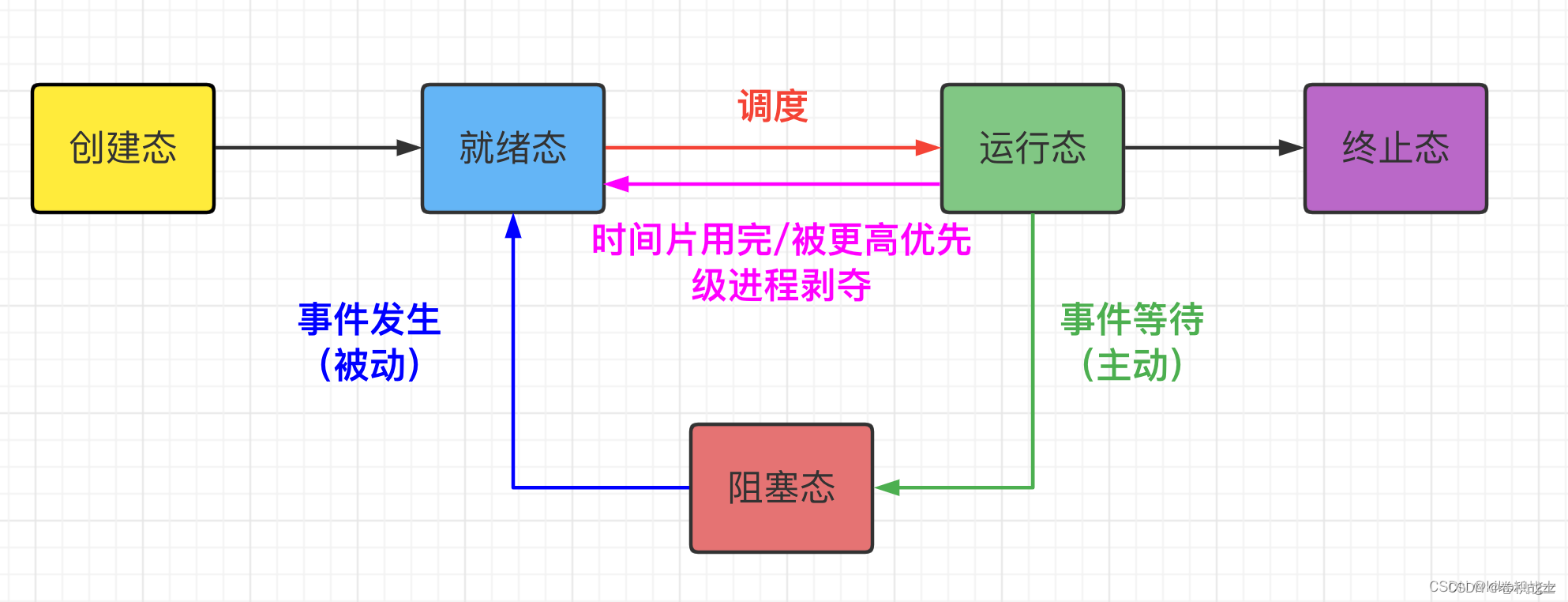
1、下列关于线程的描述中,错误的是A.内核级线程的调度由操作系统完成B.操作系统为每个用户级线程建立一个线程控制块C.用户级线程间的切换比内核级线程间的切换效率高D.用户级线程可以在不支持内核级线程的操作系统上实…...
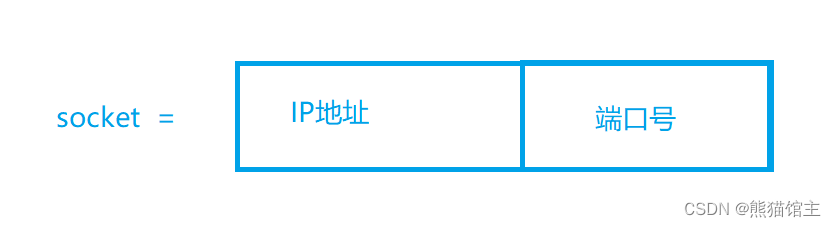
【计算机网络 -- 期末复习】
例题讲解 IP地址(必考知识点) 子网掩码 子网划分 第一栗: 子网划分题目的答案一般不唯一,我们主要采用下方的写法: 第二栗: 路由跳转 数据传输 CSMA/CD数据传输 2、比特率与波特率转换 四相位表示&am…...
接口是对类的一部分行为的抽象)
三、(补充)接口是对类的一部分行为的抽象
接口是对类的一部分行为的抽象 类类型 实现接口 为什么不是描述类呢?而是类一部分行为的抽象? 类中分为:静态部分(构造器)、实例部分(类成员)。 类成员:实例的属性、原型上的方…...

CIMCAI intellgent ship product applied by world top3 shipcompany
CIMCAI智慧船公司集装箱管理产品ceaspectusS™全球规模应用全球前三大船公司认可验箱标准应用落地全球港航人工智能AI独角兽 CIMCAI中集飞瞳CIMCAI Intellgent shipping product ceaspectusS ™which applied by the worlds top three shipping companiesGlobal port and shipp…...

媒体见面会怎么做?
传媒如春雨,润物细无声,大家好媒体见面会是企业与媒体沟通的一种常见形式,以下是一些媒体见面会的建议:1,确定目标和主题:在媒体见面会前,企业应该确定目标和主题。这包括确定想要传达的信息、受…...

Nginx面试题一步到位
1.什么是Nginx? Nginx是一个 轻量级/高性能的反向代理Web服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发。 2.Nginx 有哪些优点&…...

华为OD机试真题 用 C++ 实现 - 括号检查
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...
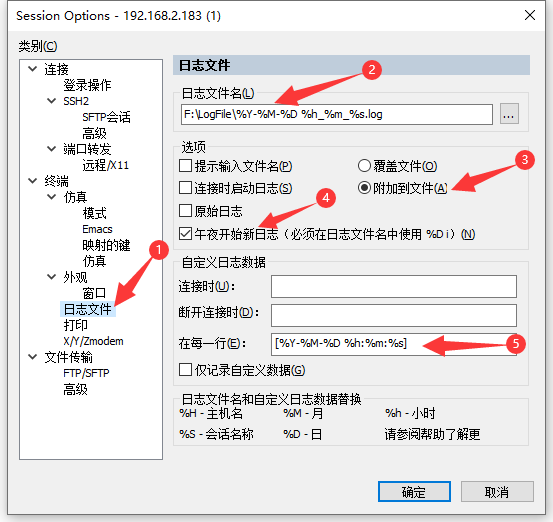
Windows下SecureCRT的下载、安装、使用、配置【Telnet/ssh/Serial】
目录 一、概述 二、SecureCRT的下载、安装 三、SecureCRT的使用 👉3.1 使用SSH协议连接Linux开发主机 👉3.2 使用Serial(串口)协议连接嵌入式开发板 👉3.3 使用Telnet协议连接嵌入式开发板 四、SecureCRT配置会话选项 🎨4…...
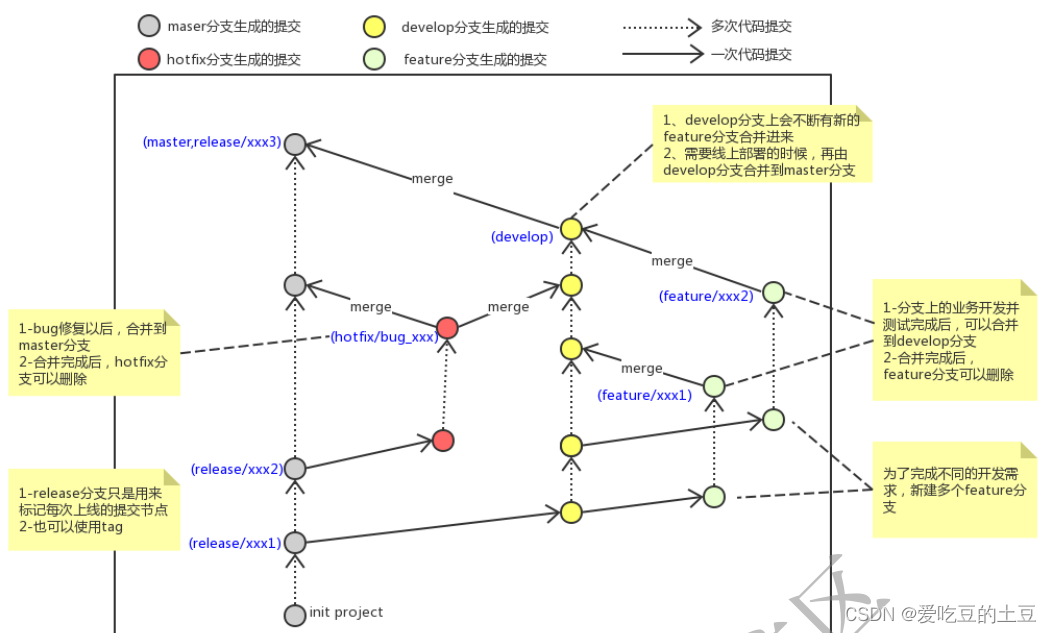
Git 分支操作
1:什么是分支几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离 开来进行重大的Bug修改、开发新的功能,以免影响开发主线。 几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作…...
【面试题】TCP如何保证传输可靠性?TCP流量控制实现、拥塞控制、ARQ协议、停止等待ARQ、连续ARQ
文章目录1. TCP 如何保证传输的可靠性?2.TCP 如何实现流量控制?3.TCP 的拥塞控制是怎么实现的?3.ARQ 协议了解吗?4.停止等待 ARQ 协议5.连续 ARQ 协议1. TCP 如何保证传输的可靠性? 基于数据块传输 :应用数据被分割成…...

MySQL一隐式转换
我相信90%以上的同学们在平时开发时,或多或少都被隐式转换(CONVERT_IMPLICIT)坑过,甚至测出bug前你都浑然不知。你还别不信,“无形之刃,最为致命!” mysql> SELECT * from t_user; ---------…...
风光并网对电网电能质量影响的matlab/simulink仿真建模
之前配电网的一个项目,我把其中一部分分享给大家,电能质量影响这部分,我在模型中主要体现的就是不同容量的光伏、风电接入,对并网点的电压影响情况。(主页还有单独风电并网系统,光伏并网发电系统以及微电网…...
浅谈Spring循环依赖
文章目录1.前言2.什么是循环依赖?3.两种Spring容器循环依赖3.1.构造器循环依赖(无法解决)3.2.setter循环依赖(可以解决)3.3.小结4.循环依赖检查5.循环依赖的处理5.1.单例setter循环依赖5.2.Spring解决循环依赖5.3. 循环…...
| 包含代码编写思路)
华为OD机试题 - 拼接 URL(JavaScript)| 包含代码编写思路
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 华为OD机试题 最近更新的博客使用说明拼接 URL题目…...

【FFMPEG】Filtering Introduction[翻译/举例]
Filtering Introduction Filtering in FFmpeg is enabled through the libavfilter library. FFmpeg中的Filtering可以通过libavfilter library来使用。 In libavfilter, a filter can have multiple inputs and multiple outputs. To illustrate the sorts of things that are…...
什么是IP65?仅仅是防水等级吗?看完本文直呼666!
IP65在硬件设备,准确的来说在电气设备中,这个参数很常见,但是作为网络技术的博主,为啥要介绍IP65? 这个很好解释,因为网络设备,比如路由器、交换机,还有服务器、监控等都是属于电气…...
:数据库连接池)
Flask入门(10):数据库连接池
目录10.数据库连接池模式一模式二示例:使用数据库连接池进行登录验证10.数据库连接池 参考:https://www.cnblogs.com/wangkun122/articles/8992637.html 通过DBUtils实现数据库连接池 安装: pip install DBUtils1.2注意:pytho…...
华为OD机试C++实现 - 最小步骤数
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...

数仓:用户行为类指标一网打尽
前言 用户行为分析是对用户在产品或触点上产生的行为及行为背后的数据进行分析,通过构建用户行为数据分析体系或者用户画像,来改变产品、营销、运营决策,实现精细化运营,指导业务增长。总之,很重要。 先来看下用户类…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...
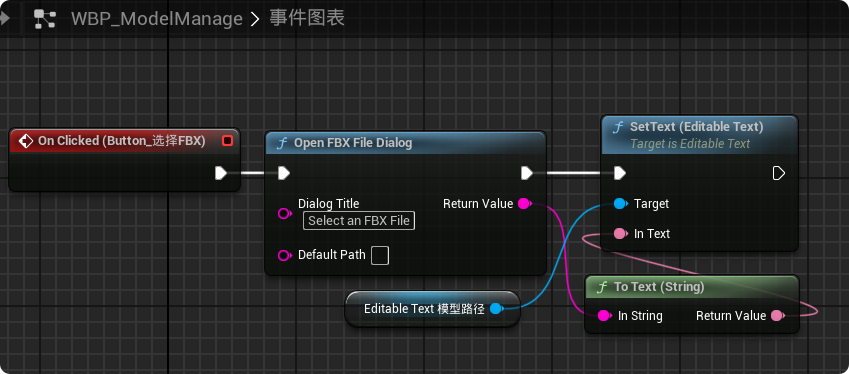
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...