使用 YCSB 和 PE 进行 HBase 性能压力测试
HBase主要性能压力测试有两个,一个是 HBase 自带的 PE,另一个是 YCSB,先简单说一个两者的区别。PE 是 HBase 自带的工具,开箱即用,使用起来非常简单,但是 PE 只能按单个线程统计压测结果,不能汇总整体压测数据,更重要的是,PE 没有 YCSB 的 预设模板(Workload) 功能,测试场景单一,相较而言,YCSB 要强大的多,它的 Workload 功能非常实用,可以模拟更贴近实际使用场景的压力状况。下面分解介绍一下两款工具的使用方法。
1. YCSB
官方文档: https://github.com/brianfrankcooper/YCSB/blob/master/asynchbase/README.md
1.1 全局配置
hbaseYcsbUrl="https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-hbase20-binding-0.17.0.tar.gz"
hbaseYcsbPkg=$(basename $hbaseYcsbUrl)
hbaseYcsbDir=$(basename $hbaseYcsbUrl ".tar.gz")
export YCSB_HOME="/opt/$hbaseYcsbDir"
1.2. 下载
下载地址: https://github.com/brianfrankcooper/YCSB/releases
wget $hbaseYcsbUrl -P /tmp/
sudo tar -xzf /tmp/$hbaseYcsbPkg -C /opt
$YCSB_HOME/bin/ycsb -h
1.3. 建表
cat << EOF | hbase shell
disable 'usertable'
drop 'usertable'
n_splits = 30 # HBase recommends (10 * number of regionservers)
create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}}
describe 'usertable'
EOF
1.4. 加载数据
$YCSB_HOME/bin/ycsb load hbase20 -cp /etc/hbase/conf/ -p columnfamily=cf -P $YCSB_HOME/workloads/workloada
上述数据加载使用的是方案/模板:workloada(就是一个properties文件),该方案默认写入1000条记录,并执行1000次操作(read,update,scan等),用户可以自定插入的数据量和操作次数,例如:-p recordcount=10000 -p operationcount=10000。这里再详细说明 一下recordcount和operationcount两个属性:
recordcount:总的插入数据量,写入数据的操作不会算到operationcount里面operationcount:总的操作次数,操作被分成了read、update、scan、insert四种类型,可以在配置中设定它们之间的比例,但总的操作次数是由operationcount控制的
1.5. 确认数据是否加载成功
cat << EOF | hbase shell
scan 'usertable'
EOF
1.6. 选择压测模板(Workload)
上述加载数据的测试仅仅是一个“冒烟”测试,实际进行压测前,要根据目标场景选择一个相匹配的 Workload,当然,也可以完全自定义 Workload,以下是存放在$YCSB_HOME/workloads下的6种预定义的 Workload:
| Workload预制方案 | 说明 |
|---|---|
| workloada | 50% 读 50% 更新,读写均衡 |
| workloadb | 95% 读 5% 更新,读多写少,多数系统比较符合这种场景 |
| workloadc | 100% 读 |
| workloadd | 95% 读 5% 插入,读最近更新,越新的纪录读取概率越大(requestdistribution=latest) |
| workloade | 95% 扫描 5% 插入,小范围查询(重Scan),不是点查 |
| workloadf | 50% 读,50% 读取-修改-写入,即:读取一个纪录,然后修改这个纪录,最后写回 |
1.7. 正式压测
了解了上述不同类型的 Workload 后,选择一个符合自身集群使用场景的 Workload,然后就可以正式压测了,以下以workloadb为例:
nohup $YCSB_HOME/bin/ycsb run hbase20 \-cp /etc/hbase/conf/ \-p columnfamily=cf \-p recordcount=10000000 \-p operationcount=10000000 \-P $YCSB_HOME/workloads/workloadb \-threads 3 \-s &> nohup.out &
tail -f nohup.out
压测执行完毕后会给出类似下图的压测报告:
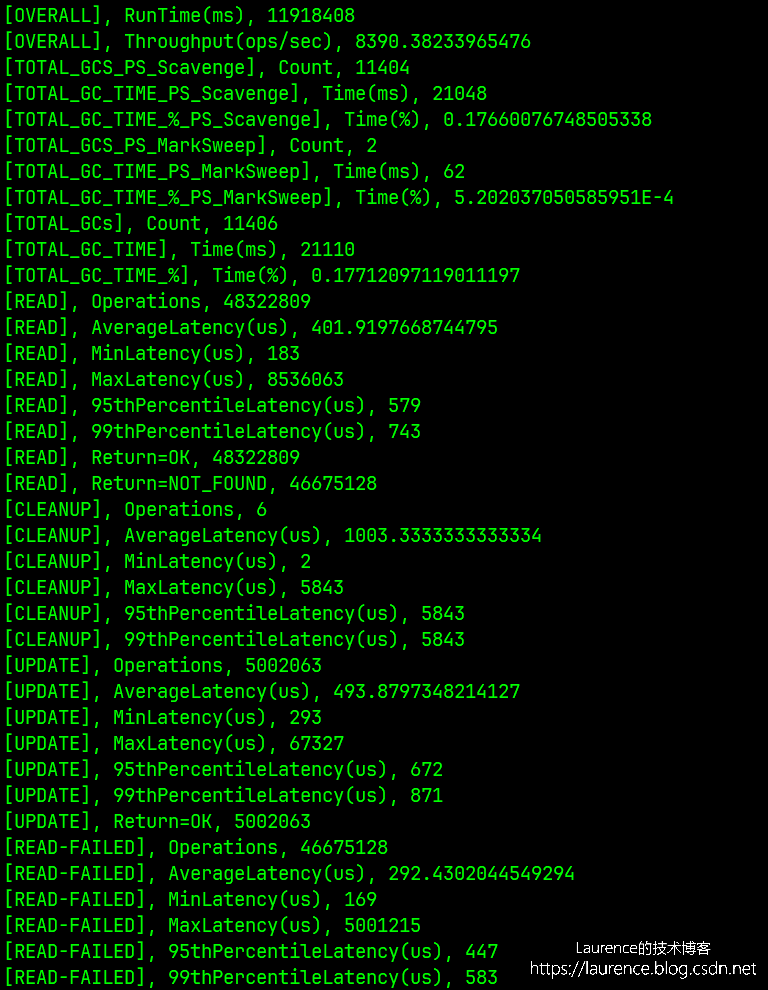
2. PE
PE只能统计每个线程执行的情况,不能统计整体的状态,所以还是推荐使用YCSB。
2.1 建表并执行测试
cat << EOF | hbase shell
create 'test-table', {NAME => 'f', REPLICATION_SCOPE=>'1'}
EOFhbase pe --nomapred --oneCon=true --table=test-table --rows=1000000 --valueSize=100 --compress=SNAPPY --presplit=16 --autoFlush=true randomWrite 16
PE的测试报告并不在控制台直接输出(这一点不太好),而是写入到了HBase的LOG文件,如果是EMR,会写到/var/log/hbase/hbase.log中,PE会分别打出每个线程的延迟状况,类似下面这样:
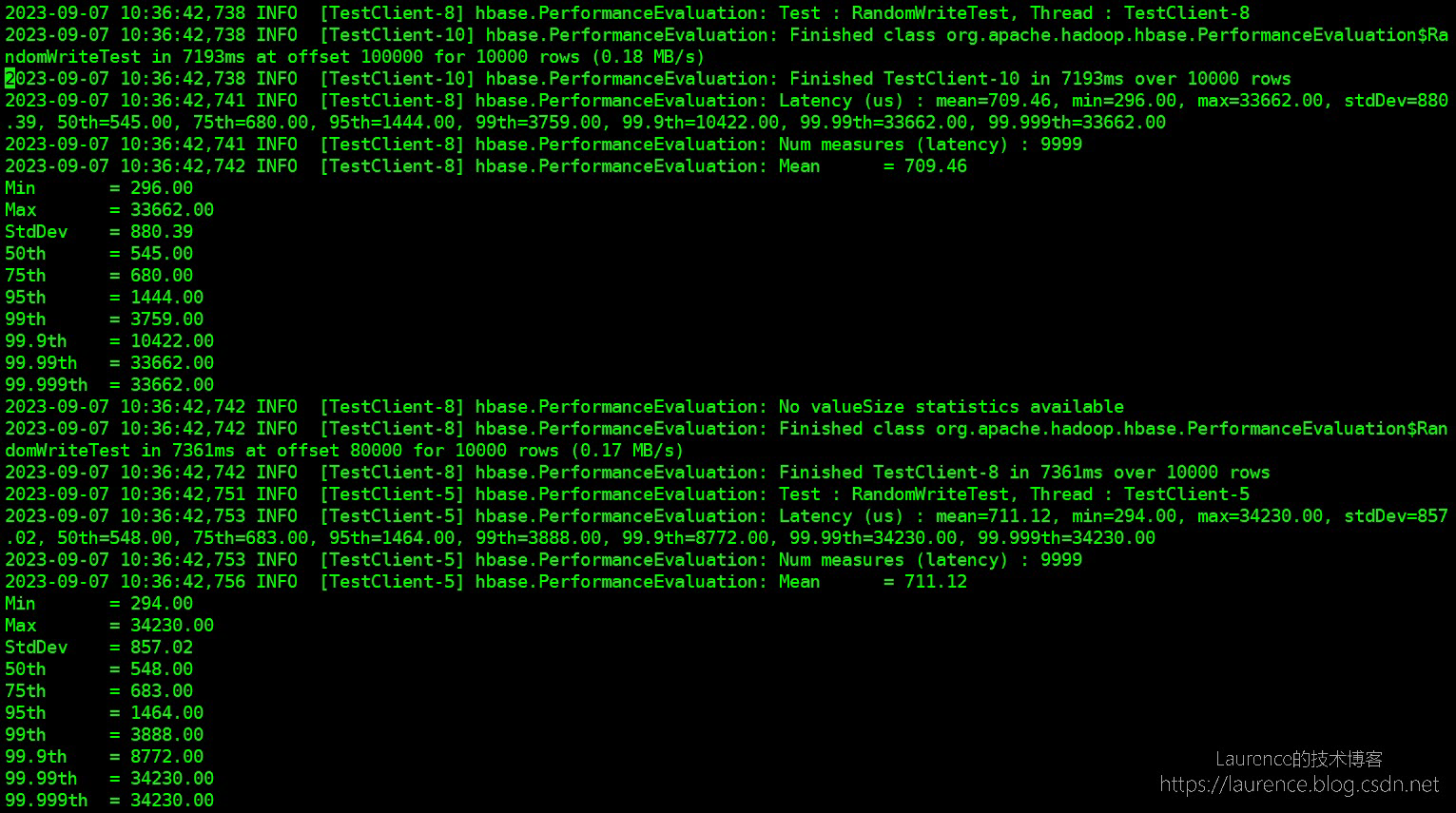
3. 附录
3.1. PE 命令行参数
General Options:nomapred 采用MapReduce的方式启动多线程测试还是通过多线程的方式,如果没有安装MapReduce,或者不想用MapReduce,通常我们采用多线程的方式,因此一般在命令中加上--nomapred来表示不使用MapReduce。 rows 每个客户端(线程)运行的行。默认值:一百万。注意这里的行数是指单线程的行数,如果rows=100, 线程数为10,那么在写测试中,写入HBase的将是 100 x 10 行 size 总大小,单位GiB。与--rows互斥。默认值:1.0。 sampleRate 样本比例:对总行数的一部分样本执行测试。只有randomRead支持。默认值:1.0 traceRate 启用HTrace跨度。每N行启动一次跟踪。默认值:0 table 测试表的名字,如果不设,默认为TestTable。 multiGet 如果> 0,则在执行RandomRead时,执行多次获取而不是单次获取。默认值:0 compress 要使用的压缩类型(GZ,LZO,...)。默认值:'无' flushCommits 该参数用于确定测试是否应该刷新表。默认值:false writeToWAL 在puts上设置writeToWAL。默认值:True autoFlush 默认为false,即PE默认用的是BufferedMutator,BufferedMutator会把数据攒在内存里,达到一定的大小再向服务器发送,如果想明确测单行Put的写入性能,建议设置为true。个人觉得PE中引入autoFlush会影响统计的准确性,因为在没有攒够足够的数据时,put操作会立马返回,根本没产生RPC,但是相应的时间和次数也会被统计在最终结果里。 oneCon 多线程运行测试时,底层使用一个还是多个链接。这个参数默认值为false,每个thread都会启一个Connection,建议把这个参数设为True presplit 表的预分裂region个数,在做性能测试时一定要设置region个数,不然所有的读写会落在一个region上,严重影响性能 inmemory 试图尽可能保持CF内存的HFile。不保证始终从内存中提供读取。默认值:false usetags 与KV一起写标签。与HFile V3配合使用。默认值:false numoftags 指定所需的标签号。仅当usetags为true时才有效。 filterAll 通过不将任何内容返回给客户端,帮助过滤掉服务器端的所有行。通过在内部使用FilterAllFilter,帮助检查服务器端性能。 latency 设置为报告操作延迟。默认值:False bloomFilter Bloom 过滤器类型,[NONE,ROW,ROWCOL]之一 valueSize 写入HBase的value的size,单位是Byte,大家可以根据自己实际的场景设置这个Value的大小。默认值:1024 valueRandom 设置是否应该在0和'valueSize'之间改变值大小;设置读取大小的统计信息:默认值: Not set. valueZipf 设置是否应该以zipf格式改变0和'valueSize'之间的值大小, 默认值: Not set. period 报告每个'period'行:默认值:opts.perClientRunRows / 10 multiGet 批处理组合成N组。只有randomRead支持。默认值: disabled replicas 启用区域副本测试。默认值:1。 splitPolicy 为表指定自定义RegionSplitPolicy。 randomSleep 在每次获得0和输入值之前进行随机睡眠。默认值:0 Note: -D properties will be applied to the conf used. For example: -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.task.timeout=60000 Command: filterScan 使用过滤器运行扫描测试,根据它的值查找特定行(确保使用--rows = 20) randomRead 运行随机读取测试 randomSeekScan 运行随机搜索和扫描100测试 randomWrite 运行随机写测试 scan 运行扫描测试(每行读取) scanRange10 使用开始和停止行(最多10行)运行随机搜索扫描 scanRange100 使用开始和停止行运行随机搜索扫描(最多100行) scanRange1000 使用开始和停止行(最多1000行)运行随机搜索扫描 scanRange10000 使用开始和停止行运行随机搜索扫描(最多10000行) sequentialRead 运行顺序读取测试 sequentialWrite 运行顺序写入测试 Args: nclients 整数。必须要有该参数。客户端总数(和HRegionServers)
running: 1 <= value <= 500
Examples: 运行一个单独的客户端: $ bin/hbase org.apache.hadoop.hbase.PerformanceEvaluation sequentialWrite 1
3.2. 百分位数值(Percentile):P99,P999
百分位数值是一个统计学中的术语,通俗一点解释是:把所有的请求响应时间按从小到大的顺序排列起来,排在某个百分比位置上的请求响应时间就是这个百分比对应的百分位数值。举个例子就是明白了:
P99:响应耗时从小到大排列,处在99%位置上的耗时即为P99值。假设该值为200ms,就意味着:99%的用户的响应耗时在200ms之内,只有1%的用户的响应耗时大于200ms
P99.9 ( P999 ):许多互联网公司会采用P99.9值,也就是99.9%的用户耗时作为指标,通过测量与优化该值,就可保证绝大多数用户的使用体验。 至于P99.99值,优化成本过高,而且服务响应由于网络波动、系统抖动等不能解决之情况,因此大多数时候都不考虑该指标。
参考资料:
https://hbase.apache.org/book.html#hbase_metrics
https://hbase.apache.org/book.html#offheap_read_write
https://help.aliyun.com/zh/emr/emr-on-ecs/user-guide/hbase-metrics
https://www.cnblogs.com/felixzh/p/10246335.html
https://cloud.tencent.com/developer/article/1596748
相关文章:
使用 YCSB 和 PE 进行 HBase 性能压力测试
HBase主要性能压力测试有两个,一个是 HBase 自带的 PE,另一个是 YCSB,先简单说一个两者的区别。PE 是 HBase 自带的工具,开箱即用,使用起来非常简单,但是 PE 只能按单个线程统计压测结果,不能汇…...

正则表达式相关概念及不可见高度页面的获取
12.正则 概念:匹配有规律的字符串,匹配上则正确 1.正则的创建方式 构造函数创建 // 修饰符 igm// i 忽视 ignore// g global 全球 全局// m 换行 var regnew RegExp("匹配的内容","修饰符")var str "this is a Box";var reg new RegExp(&qu…...

深入学习 Redis - 分布式锁底层实现原理,以及实际应用
目录 一、Redis 分布式锁 1.1、什么是分布式锁 1.2、分布式锁的基础实现 1.2.1、引入场景 1.2.2、基础实现思想 1.2.3、引入 setnx 1.3、引入过期时间 1.4、引入校验 id 1.5、引入 lua 脚本 1.5.1、引入 lua 脚本的原因 1.5.2、lua 脚本介绍 1.6、过期时间续约问题&…...
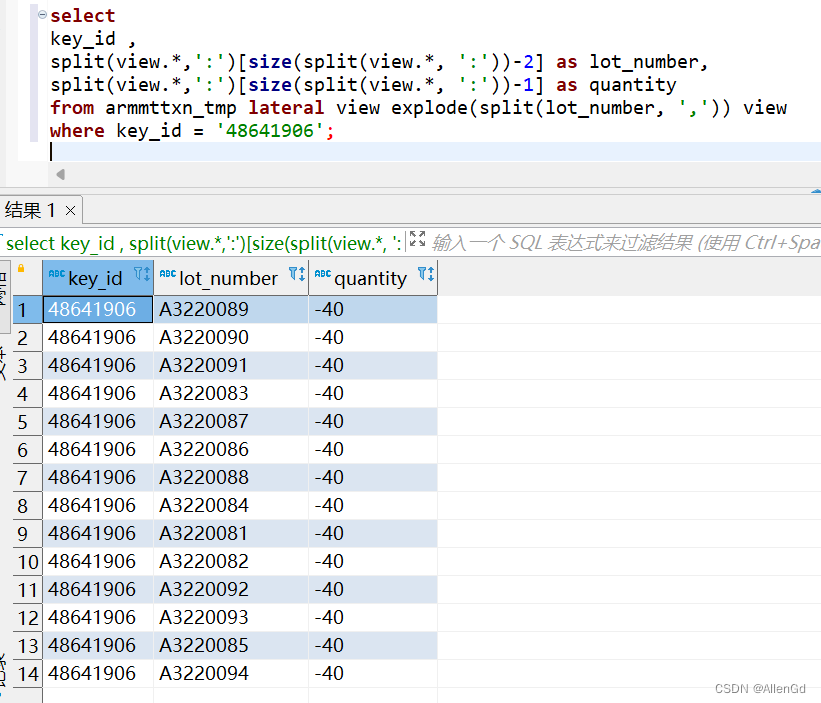
Hive行转列[一行拆分成多行/一列拆分成多列]
场景: hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…...

TypeScript系列之类型 string
文章の目录 背景写在最后 背景 与JavaScript不同的是,TypeScript使用的是静态类型,比如说它指定了变量可以保存的数据类型。如下面代码所示,如果在JavaScript中,指定变量可以保存的数据类型,会报错:类型注…...
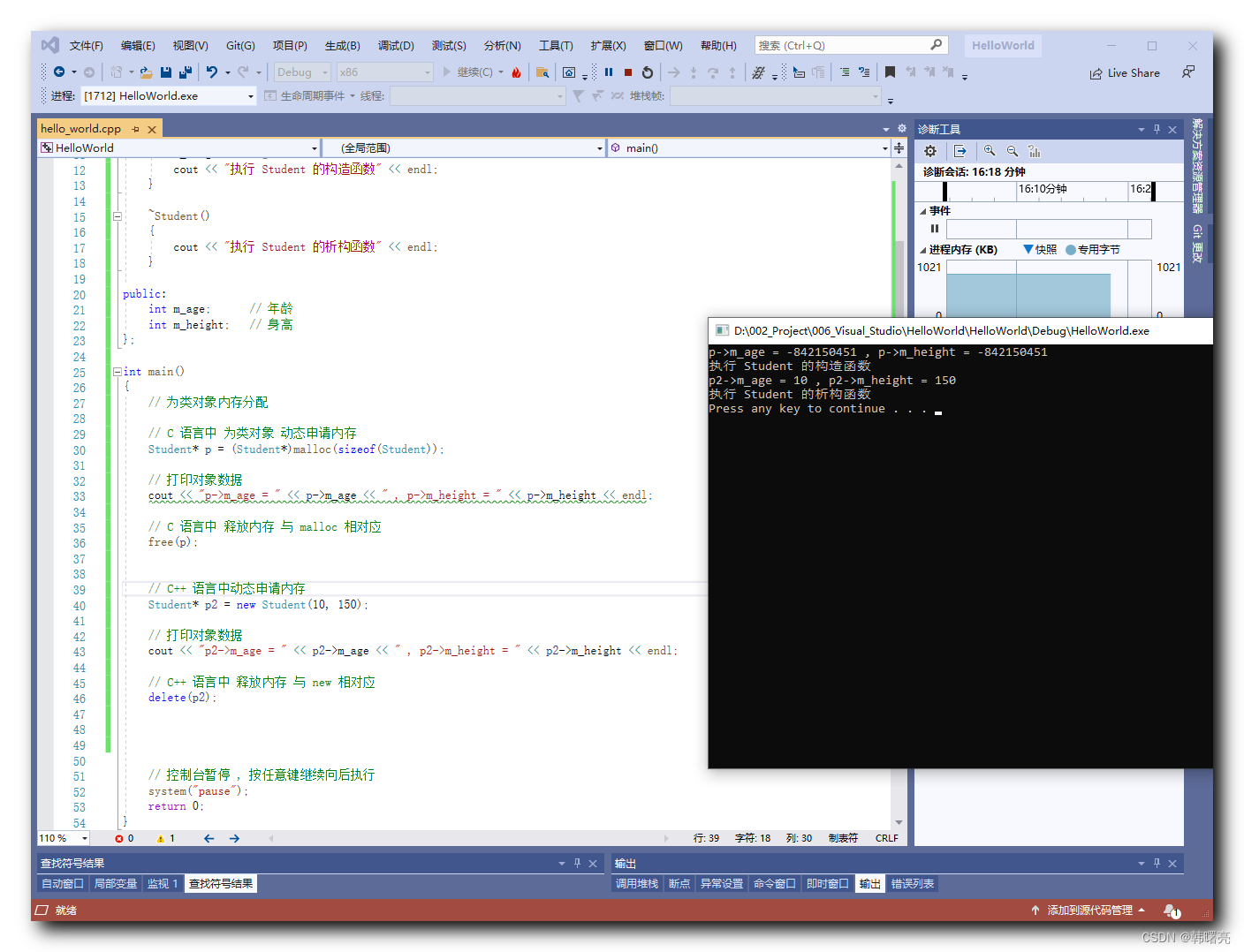
【C++】动态内存管理 ③ ( C++ 对象的动态创建和释放 | new 运算符 为类对象 分配内存 | delete 运算符 释放对象内存 )
文章目录 一、C 对象的动态创建和释放1、C 语言 对象的动态创建和释放 的方式2、C 语言 对象的动态创建和释放 的方式 二、代码示例 - 对象的动态创建和释放 一、C 对象的动态创建和释放 使用 C 语言中的 malloc 函数 可以为 类对象 分配内存 ; 使用 free 函数可以释放上述分配…...

AMS爆炸来袭,上线即巅峰
1.关于首发项目Antmons(AMS)空投结果 Gate.io Startup 首发项目Antmons代币AMS于Aug15th,AM 07:00开始下单,24小时内下单同等对待总共有15,950人下单,下单总价值超过1,000万美金分发系数约为0.001640495298341。根据上线规则AMS项目认购成功,…...
是面试官放水,还是公司实在是太缺人?这都没挂,华为原来这么容易进...
华为是大企业,是不是很难进去啊?” “在华为做软件测试,能得到很好的发展吗? 一进去就有9.5K,其实也没有想的那么难” 直到现在,心情都还是无比激动! 本人211非科班,之前在字节和腾…...
怒刷LeetCode的第2天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:滑动窗口 方法二:双指针加哈希表 第二题 题目来源 题目内容 解决方法 方法一:二分查找 方法二:归并排序 方法三:分治法 第三题 题目来源 题目内容 解…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-车载CAN总线网络的异常检测(续)
目录 车载 CAN 总线网络异常检测技术 3.1 车载 CAN 总线网络异常检测技术概述 3.1.1基于统计的异...
mojo安装
docker安装mojo 官网 https://developer.modular.com/login 很奇怪登录页面不显示 类似于网站劫持 docker 安装mojo带jupyterlab的方式 https://hub.docker.com/r/lmq886/mojojupyterlab 拉取镜像 docker pull lmq886/mojojupyterlab docker pull lmq886/mojojupyterlab:1.2 启…...

【探索Linux】—— 强大的命令行工具 P.8(进程地址空间)
阅读导航 前言一、内存空间分布二、什么是进程地址空间1. 概念2. 进程地址空间的组成 三、进程地址空间的设计原理1. 基本原理2. 虚拟地址空间 概念 大小和范围 作用 虚拟地址空间的优点 3. 页表 四、为什么要有地址空间五、总结温馨提示 前言 前面我们讲了C语言的基础知识&am…...
vue3 - Element Plus 切换主题色及el-button hover颜色不生效的解决方法
GitHub Demo 地址 在线预览 Element Plus 自定义主题官方文档 如果您想要通过 js 控制 css 变量,可以这样做: // document.documentElement 是全局变量时 const el document.documentElement // const el document.getElementById(xxx)// 获取 css 变…...

【C++面向对象侯捷】1.C++编程简介
文章目录 视频来源:我的百度网盘...
年龄大了转嵌入式有机会吗?
年龄大了转嵌入式有机会吗? 首先,说下结论:年龄并不是限制转行嵌入式软件开发的因素,只要具备一定的编程和电子基础知识,认真学习和实践,是可以成为优秀的嵌入式软件开发工程师的。最近很多小伙伴找我&…...
)
Mysql高级——索引优化和查询优化(2)
5. 排序优化 5.1 排序优化 问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢? 优化建议: SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中避免全表…...

SpringMVC的拦截器和JSR303的使用
目录 一、JSR303 二、拦截器(interceptor) 一、JSR303 1.1.什么是JSR303 JSR 303,它是Java EE(现在称为Jakarta EE)规范中的一部分。JSR 303定义了一种用于验证Java对象的标准规范,也称为Bean验证。 Bean验…...
servlet中doGet方法无法读取body中的数据
servlet中doGet方法不支持读取body中的数据。...

Ubuntu MongoDB账户密码设置
1.创建用户 在MongoDB中,可以使用db.createUser()方法来创建用户。该方法接受一个包含用户名、密码和角色等信息的文档作为参数。 // 连接到MongoDB数据库 mongo// 切换到admin数据库 use admin// 创建用户 db.createUser({user: "admin",pwd: "adm…...
)
指针进阶(3)
9. 模拟实现排序函数 这里我们使用冒泡排序算法,模拟实现一个排序函数,可以排序任意类型的数据。 这段代码可以排序整型数据,我们需要在这段代码的基础上进行改进,使得它可以排序任意类型的数据。 #define _CRT_SECURE_NO_WARN…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...