NLP文本生成全解析:从传统方法到预训练完整介绍
目录
- 1. 引言
- 1.1 文本生成的定义和作用
- 1.2 自然语言处理技术在文本生成领域的使用
- 2 传统方法 - 基于统计的方法
- 2.1.1 N-gram模型
- 2.1.2 平滑技术
- 3. 传统方法 - 基于模板的生成
- 3.1 定义与特点
- 3.2 动态模板
- 4. 神经网络方法 - 长短时记忆网络(LSTM)
- LSTM的核心概念
- PyTorch中的LSTM
- 5. 神经网络方法 - Transformer
- Transformer的核心概念
- PyTorch中的Transformer
- 6. 大型预训练模型 - GPT文本生成机制
- 大型预训练模型的核心概念
本文深入探讨了文本生成的多种方法,从传统的基于统计和模板的技术到现代的神经网络模型,尤其是LSTM和Transformer架构。文章还详细介绍了大型预训练模型如GPT在文本生成中的应用,并提供了Python和PyTorch的实现代码。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. 引言
1.1 文本生成的定义和作用
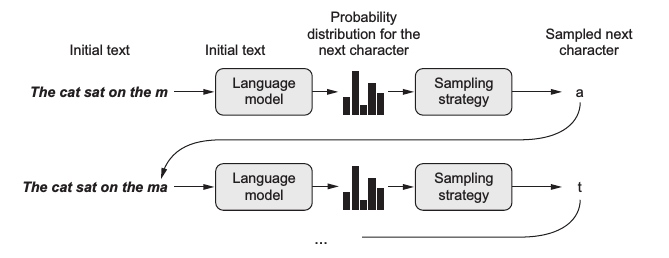
文本生成是自然语言处理的一个核心子领域,它涉及使用模型来自动创建自然语言文本。这种生成可以是基于某些输入的响应,如图像或其他文本,也可以是完全自主的创造。
文本生成的任务可以是简单的,如自动回复邮件,也可以是更复杂的,如编写新闻文章或生成故事。它通常包括以下步骤:
- 确定目标和约束:明确生成文本的目标和约束条件,如风格、语言和长度等。
- 内容的生成:基于预定义的目标和约束条件来生成内容。
- 评价和优化:使用不同的评价指标来测试生成的文本,并进行必要的优化。
例子:
- 自动回复邮件:根据收到的邮件内容,系统可以生成一个简短的、相关的回复。
- 新闻文章生成:利用已有的数据和信息来自动生成新闻文章。
- 故事生成:创建一个可以根据输入的提示来生成故事的系统。
1.2 自然语言处理技术在文本生成领域的使用
自然语言处理技术为文本生成提供了强大的工具和方法。这些技术可以用于解析输入数据、理解语言结构、评估生成文本的质量,以及优化生成过程。
-
序列到序列模型:这是一个广泛应用于文本生成任务的框架,如机器翻译和摘要生成。模型学习将输入序列(如句子)转化为输出序列(如另一种语言的句子)。
-
注意力机制:在处理长序列时,注意力机制可以帮助模型关注输入数据的关键部分,从而产生更准确的输出。
-
预训练语言模型:像BERT和GPT这样的模型通过大量的文本数据进行预训练,之后可以用于各种NLP任务,包括文本生成。
-
优化技术:如束搜索和采样策略,它们可以帮助生成更流畅、准确的文本。
例子:
- 机器翻译:使用序列到序列模型,将英语句子转化为法语句子。
- 生成摘要:利用注意力机制从长篇文章中提取关键信息,生成简短的摘要。
- 文本填充:使用预训练的GPT模型,根据给定的开头生成一个完整的故事。
随着技术的进步,自然语言处理技术在文本生成中的应用也越来越广泛,为我们提供了更多的可能性和机会。
2 传统方法 - 基于统计的方法
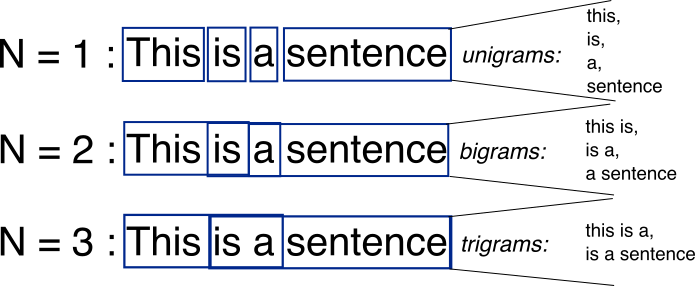
在深度学习技术盛行之前,文本生成主要依赖于基于统计的方法。这些方法通过统计语料库中的词语和短语的频率,预测下一个词或短语的出现概率。
2.1.1 N-gram模型
定义:N-gram模型是基于统计的文本生成方法中的一种经典技术。它基于一个假设,即第N个词的出现只与前面的N-1个词有关。例如,在一个trigram(3-gram)模型中,下一个词的出现只与前两个词有关。
例子:考虑句子 “我爱学习人工智能”,在一个bigram(2-gram)模型中,“人工” 出现后的下一个词可能是 “智能”。
from collections import defaultdict, Counter
import randomdef build_ngram_model(text, n=2):model = defaultdict(Counter)for i in range(len(text) - n):context, word = tuple(text[i:i+n-1]), text[i+n-1]model[context][word] += 1return modeldef generate_with_ngram(model, max_len=20):context = random.choice(list(model.keys()))output = list(context)for i in range(max_len):if context not in model:breaknext_word = random.choices(list(model[context].keys()), weights=model[context].values())[0]output.append(next_word)context = tuple(output[-len(context):])return ' '.join(output)text = "我 爱 学习 人工 智能".split()
model = build_ngram_model(text, n=2)
generated_text = generate_with_ngram(model)
print(generated_text)
2.1.2 平滑技术
定义:在统计模型中,我们经常会遇到一个问题,即语料库中可能有一些N-grams从未出现过,导致其概率为0。为了解决这个问题,我们使用平滑技术来为这些未出现的N-grams分配一个非零概率。
例子:使用Add-1平滑(Laplace平滑),我们将每个词的计数加1,来保证没有词的概率为0。
def laplace_smoothed_probability(word, context, model, V):return (model[context][word] + 1) / (sum(model[context].values()) + V)V = len(set(text))
context = ('我', '爱')
probability = laplace_smoothed_probability('学习', context, model, V)
print(f"P('学习'|'我 爱') = {probability}")
通过使用基于统计的方法,虽然我们可以生成文本,但这些方法有其局限性,尤其是在处理长文本时。随着深度学习技术的发展,更先进的模型逐渐取代了传统方法,为文本生成带来了更多的可能性。
3. 传统方法 - 基于模板的生成
基于模板的文本生成是一种早期的文本生成方法,依赖于预定义的句子结构和词汇来创建文本。这种方法虽然简单直观,但其生成的文本通常缺乏变化和多样性。
3.1 定义与特点
定义:模板生成方法涉及到使用预先定义的文本模板和固定的结构,根据不同的数据或上下文填充这些模板,从而生成文本。
特点:
- 确定性:输出是可预测的,因为它直接基于模板。
- 快速生成:不需要复杂的计算,只需简单地填充模板。
- 局限性:输出可能缺乏多样性和自然感,因为它完全基于固定模板。
例子:在天气预报中,可以有一个模板:“今天在{城市}的最高温度为{温度}度。”。根据不同的数据,我们可以填充该模板,生成如“今天在北京的最高温度为25度。”的句子。
def template_generation(template, **kwargs):return template.format(**kwargs)template = "今天在{city}的最高温度为{temperature}度。"
output = template_generation(template, city="北京", temperature=25)
print(output)
3.2 动态模板
定义:为了增加文本的多样性,我们可以设计多个模板,并根据上下文或随机性选择不同的模板进行填充。
例子:针对天气预报,我们可以有以下模板:
- “{city}今天的温度达到了{temperature}度。”
- “在{city},今天的最高气温是{temperature}度。”
import randomdef dynamic_template_generation(templates, **kwargs):chosen_template = random.choice(templates)return chosen_template.format(**kwargs)templates = ["{city}今天的温度达到了{temperature}度。","在{city},今天的最高气温是{temperature}度。"
]output = dynamic_template_generation(templates, city="上海", temperature=28)
print(output)
尽管基于模板的方法为文本生成提供了一种简单和直接的方式,但它在处理复杂和多样化的文本生成任务时可能会显得力不从心。现代深度学习方法提供了更强大、灵活和多样化的文本生成能力,逐渐成为主流方法。
4. 神经网络方法 - 长短时记忆网络(LSTM)
长短时记忆网络(LSTM)是一种特殊的递归神经网络(RNN),专为解决长期依赖问题而设计。在传统的RNN中,随着时间步的增加,信息的传递会逐渐变得困难。LSTM通过其特殊的结构来解决这个问题,允许信息在时间步之间更容易地流动。
LSTM的核心概念
定义:LSTM的核心是其细胞状态,通常表示为(C_t)。与此同时,LSTM包含三个重要的门:遗忘门、输入门和输出门,这三个门共同决定信息如何被更新、存储和检索。
- 遗忘门:决定哪些信息从细胞状态中被遗忘或丢弃。
- 输入门:更新细胞状态,决定哪些新信息被存储。
- 输出门:基于细胞状态,决定输出什么信息。
例子:假设我们正在处理一个文本序列,并想要记住某个词汇的性别标记(如“他”或“她”)。当我们遇到一个新的代词时,遗忘门可能会帮助模型忘记旧的性别标记,输入门会帮助模型存储新的标记,而输出门则会在下一个时间步输出这个标记,以保持序列的一致性。
PyTorch中的LSTM
使用PyTorch,我们可以轻松地定义和训练一个LSTM模型。
import torch.nn as nn
import torch# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)self.linear = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()c0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))out = self.linear(out[:, -1, :])return outinput_dim = 10
hidden_dim = 20
output_dim = 1
num_layers = 1
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers)# 一个简单的例子,输入形状为 (batch_size, time_steps, input_dim)
input_seq = torch.randn(5, 10, 10)
output = model(input_seq)
print(output.shape) # 输出形状为 (batch_size, output_dim)
LSTM由于其在处理时间序列数据,尤其是在长序列中保留关键信息的能力,已经在多种自然语言处理任务中取得了显著的成功,例如文本生成、机器翻译和情感分析等。
5. 神经网络方法 - Transformer
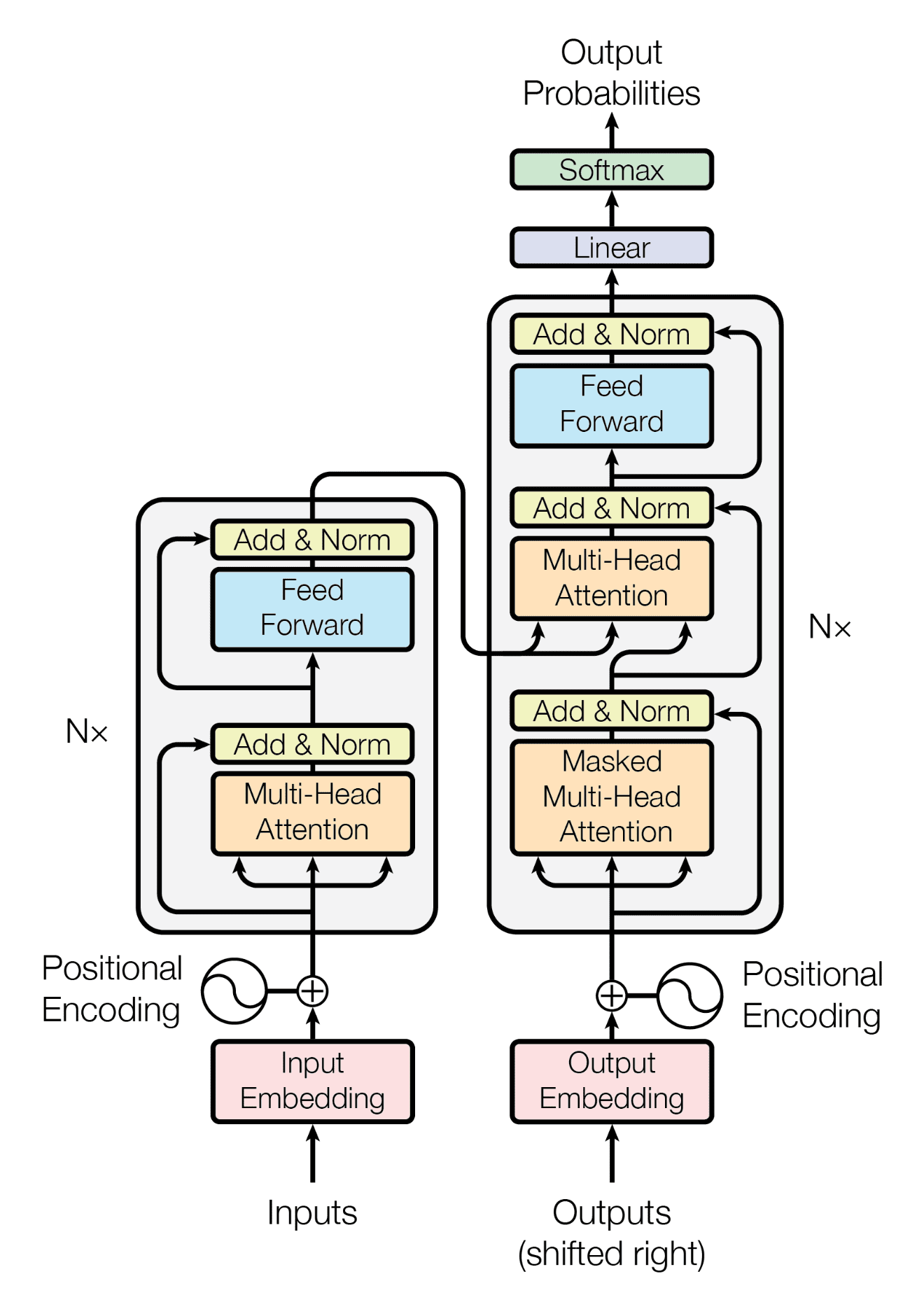
Transformer 是近年来自然语言处理领域的重要进展,它摒弃了传统的递归和卷积结构,完全依赖自注意力机制来处理序列数据。
Transformer的核心概念
定义:Transformer 是一个基于自注意力机制的深度学习模型,旨在处理序列数据,如文本。其核心是多头自注意力机制,可以捕捉序列中不同位置间的依赖关系,无论它们之间有多远。
多头自注意力:这是 Transformer 的关键部分。每个“头”都学习序列中的不同位置的表示,然后将这些表示组合起来。
位置编码:由于 Transformer 不使用递归或卷积,因此需要额外的位置信息来了解序列中词的位置。位置编码将这种信息添加到序列的每个位置。
例子:考虑句子 “The cat sat on the mat.” 如果我们想强调 “cat” 和 “mat” 之间的关系,多头自注意力机制使 Transformer 可以同时关注 “cat” 和距离较远的 “mat”。
PyTorch中的Transformer
使用 PyTorch,我们可以使用现成的 Transformer 模块来定义一个简单的 Transformer 模型。
import torch.nn as nn
import torchclass TransformerModel(nn.Module):def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers):super(TransformerModel, self).__init__()self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers)self.fc = nn.Linear(d_model, d_model) # 示例中的一个简单的线性层def forward(self, src, tgt):output = self.transformer(src, tgt)return self.fc(output)d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6model = TransformerModel(d_model, nhead, num_encoder_layers, num_decoder_layers)# 示例输入,形状为 (sequence_length, batch_size, d_model)
src = torch.randn(10, 32, d_model)
tgt = torch.randn(20, 32, d_model)output = model(src, tgt)
print(output.shape) # 输出形状为 (tgt_sequence_length, batch_size, d_model)
Transformer 由于其强大的自注意力机制和并行处理能力,已经在多种自然语言处理任务中取得了突破性的成果,如 BERT、GPT 和 T5 等模型都是基于 Transformer 架构构建的。
6. 大型预训练模型 - GPT文本生成机制
近年来,大型预训练模型如 GPT、BERT 和 T5 等已成为自然语言处理领域的标准模型。它们在多种任务上都展现出了卓越的性能,尤其在文本生成任务上。
大型预训练模型的核心概念
定义:大型预训练模型是通过在大量无标签数据上进行预训练的模型,然后在具体任务上进行微调。这种“预训练-微调”范式使得模型能够捕捉到自然语言的丰富表示,并为各种下游任务提供一个强大的起点。
预训练:模型在大规模文本数据上进行无监督学习,如书籍、网页等。此时,模型学习到了词汇、语法和一些常识信息。
微调:在预训练后,模型在特定任务的标记数据上进行有监督学习,如机器翻译、文本生成或情感分析。
例子:考虑 GPT-3,它首先在大量的文本上进行预训练,学习到语言的基本结构和信息。然后,可以用很少的样本或无需任何额外的训练,直接在特定任务上生成文本。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
NLP文本生成全解析:从传统方法到预训练完整介绍
目录 1. 引言1.1 文本生成的定义和作用1.2 自然语言处理技术在文本生成领域的使用 2 传统方法 - 基于统计的方法2.1.1 N-gram模型2.1.2 平滑技术 3. 传统方法 - 基于模板的生成3.1 定义与特点3.2 动态模板 4. 神经网络方法 - 长短时记忆网络(LSTM)LSTM的核心概念PyTorch中的LST…...

OpenBA:开源模型家族再添一员!从头训练的15B中英非对称Encoder-Decoder结构双语模型...
苏州大学从头训练的双语非对称Encoder-Decoder模型OpenBA已正式开源! 主要亮点包括: 亮点一:此模型为中文开源社区贡献了一个有代表性的编码器解码器大语言模型,其训练过程(包括数据收集与清洗、模型构建与训练&#x…...
安防视频监控平台EasyNVR无法控制云台,该如何解决?
TSINGSEE青犀视频安防监控平台EasyNVR可支持设备通过RTSP/Onvif协议接入,并能对接入的视频流进行处理与多端分发,包括RTSP、RTMP、HTTP-FLV、WS-FLV、HLS、WebRTC等多种格式。在智慧安防等视频监控场景中,EasyNVR可提供视频实时监控直播、云端…...

基座向量施密特正交化
最近再次细细的阅读了向量施密特正交化,重新系统梳理一下 一、正交基地与向量的正交分解 二、基化成标准正交基,是什么意思 将一个向量空间中的基向量通过某种方式转化为一组标准正交基,是指将原有的基向量进行调整,使得它们满足…...
OpenCV图像金字塔
什么是图像金字塔? 向上采样 :cv.pyrUp(img) 向下采样 : cv.pyrDown(img) 代码实现 import numpy as np import cv2 as cv import matplotlib.pyplot as plt#图像的读取 img cv.imread("lena.png")#进行图像采样 up_img cv.pyrUp(img) #上…...

Arduino驱动MMA7361/MMA7360三轴加速度传感器(惯性测量传感器篇)
目录 1、传感器特性 2、控制器和传感器连线图 3、驱动程序 MMA7361三轴加速度传感器是替代停产的MMA7260三轴加速度传感器,三轴加速度传感器是一种可以对物体运动过程中的加速度进行测量的电子设备,典型互动应用中的加速度传感器可以用来对物体的姿态或者运动方向进行检测…...

ceph分布式存储
目录 一、概述 1、特点 2、组件 3、架构图 二、分布式部署 1、环境拓扑 2、实验准备 3、ceph安装 安装 初始化monitor 同步管理信息 安装mgr(管理守护进程) 安装rgw 创建mds服务 OSD安装 4、dashboard安装 开启dashboard模块 生成签名 …...

DA1--用pandas查看网站用户数据
目录 1.题目描述 2.输入描述 3.输出描述 4.题目分析 5.通过代码 1.题目描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID …...

JWT令牌
一、JWT(Json Web Token)能干什么 1、安全认证(权限认证) 比如登录系统的时候,服务器会检查前端请求数据中携带的token信息,符合标准则允许访问,不符合则拒绝你的访问请求。 2、信息传递 比…...

uni-app使用CSS实现无限旋转动画
本来想用uni.createAnimation创建一个旋转动画,发现转完一圈后就不动了,没法循环旋转, 后来又用setInterval每隔一个周期就把旋转角度加180度,发现运行一段时间后动画逐渐崩坏,应该是动画的周期和定时器的周期时间没有…...
java面向对象(八)
文章目录 一、abstract关键字的使用1.概念2. abstract修饰类:抽象类3.abstract修饰方法,抽象方法4.abstract使用上的注意点:5.抽象类的匿名子类 二、计算一段代码执行所花费的时间三、接口的使用1.接口的使用2.定义接口中的成员3.代码demo4.Java类可以实…...
【proverif】proverif的下载安装和初使用
文章目录 一、proverif下载1. 下载proverif安装包2. 解压proverif安装包3. 点开其中的README,安装graphciz和gtk4. 查看安装是否成功5. 测试 一、proverif下载 1. 下载proverif安装包 官网:proverif 首先下载全过程无需开外网,而且安装包下…...

浙江大学《乡村振兴战略下传统村落文化旅游设计》许少辉八一著作——2023学生开学季辉少许
浙江大学《乡村振兴战略下传统村落文化旅游设计》许少辉八一著作——2023学生开学季辉少许...
Centos7.9 一键脚本部署 LibreNMS 网络监控系统
前言: LibreNMS 是个以 PHP/MySQL 为基底的自动探索网络监控系统 LibreNMS 官网 版本23.8.2-52-g7bbe0a2 - Thu Sep 14 2023 22:33:23 GMT0700数据库纲要2023_09_01_084057_application_new_defaults (259)Web 服务器nginx/1.20.1PHP8.1.23Python3.6.8DatabaseMa…...
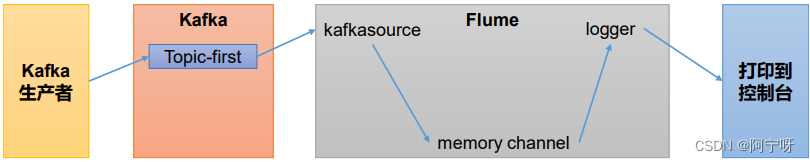
【大数据之Kafka】十六、Kafka集成外部系统之集成Flume
Flume 是一个在大数据开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于 Kafka 的消费者。 Flume安装和部署:https://blog.csdn.net/qq_18625571/article/details/131678589?spm1001.2014.3001.5501 1 Flume生产者 (1)…...
)
java学习--day3 (运算符、if循环、switch-case结构)
文章目录 今天的内容1.运算符1.1关系运算符1.2逻辑运算符1.3逻辑运算符的短路原则 2.分支结构【重点】2.1if分支2.2if-else分支2.3if-else的嵌套写法2.4if-else if 分支结构2.5swicth-case结构 扩展知识点 1.八大基本数据类型整型: byte short int long浮点: float double字…...

ActiveMQ、RabbitMQ、RocketMQ、Kafka区别
一、消息中间件的使用场景 消息中间件的使用场景总结就是六个字:解耦、异步、削峰 1.解耦 如果我方系统A要与三方B系统进行数据对接,推送系统人员信息,通常我们会使用接口开发来进行。但是如果运维期间B系统进行了调整,或者推送…...

csp初赛总结 那些年编程走过的坑 初高中信竞常考语法算法点
😘个人主页:曲终酣兴晚的小书屋💖 😕作者介绍:一个莽莽撞撞的🐻 💖专栏介绍:日常生活&往事回忆 😶🌫️每日金句:祝大家心有山水不造作&…...
验厂需要注意哪些方面?)
DollarTree(美元树)验厂需要注意哪些方面?
【DollarTree(美元树)验厂需要注意哪些方面?】 美元树(Dollar tree),是美国的一元店。每件商品都只卖一美元,吃的、用的和玩的应有尽有。美元树在美国共拥有4900家门店,其中一半的连…...
vector使用和模拟实现
💓博主个人主页:不是笨小孩👀 ⏩专栏分类:数据结构与算法👀 C👀 刷题专栏👀 C语言👀 🚚代码仓库:笨小孩的代码库👀 ⏩社区:不是笨小孩👀 🌹欢迎大…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...