深度学习——线性神经网络一
深度学习——线性神经网络一
文章目录
- 前言
- 一、线性回归
- 1.1. 线性回归的基本元素
- 1.1.1. 线性模型
- 1.1.2. 损失函数
- 1.1.3. 解析解
- 1.1.4. 随机梯度下降
- 1.1.5. 用模型进行预测
- 1.2. 向量化加速
- 1.3. 正态分布与平方损失
- 1.4. 从线性回归到深度网络
- 二、线性回归的从零开始实现
- 2.1. 生成数据集
- 2.2. 读取数据集
- 2.3. 初始化模型参数
- 2.4. 定义模型
- 2.5. 定义损失函数
- 2.6. 定义优化算法
- 2.7. 训练
- 三、线性回归的简洁实现
- 3.1. 生成数据集
- 3.2. 读取数据集
- 3.3. 定义模型
- 3.4. 初始化模型参数
- 3.5. 定义损失函数
- 3.6. 定义优化算法
- 3.7. 训练
- 总结
前言
书接上章,当预备知识有一定了解后,接下来将进入神经网络的学习,而本章主要介绍一下最简单的人工神经网络——线性神经网络。
参考书:
《动手学深度学习》
一、线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。在机器学习领域中的大多数任务通常都与预测有关。 当我们想预测一个数值时,就会涉及到回归问题。
我们把试图预测的目标称为标签(label)或目标(target)。 预测所依据的自变量称为特征(feature)或协变量。
1.1. 线性回归的基本元素
1.1.1. 线性模型
在机器学习领域,我们通常使用的是高维数据集,建模时采用线性代数表示法会比较方便。 当我们的输入包含d个特征时,我们将预测结果 y ^ \hat{y} y^(通常使用“尖角”符号表示y的估计值)表示为:
y ^ = w 1 x 1 + . . . + w d x d + b . \hat{y} = w_1 x_1 + ... + w_d x_d + b. y^=w1x1+...+wdxd+b.
将所有特征放到向量 x \mathbf{x} x中,并将所有权重放到向量 w \mathbf{w} w中,我们可以用点积形式来简洁地表达模型:
y ^ = w ⊤ x + b . \hat{y} = \mathbf{w}^\top \mathbf{x} + b. y^=w⊤x+b.
上式向量 x \mathbf{x} x对应于单个数据样本的特征。
用符号表示的矩阵 X \mathbf{X} X ,可以很方便地引用我们整个数据集的 n n n个样本。其中, X \mathbf{X} X的每一行是一个样本,每一列是一种特征。
对于特征集合 X \mathbf{X} X,预测值 y ^ \hat{\mathbf{y}} y^,可以通过矩阵-向量乘法表示为:
y ^ = X w + b {\hat{\mathbf{y}}} = \mathbf{X} \mathbf{w} + b y^=Xw+b
线性回归的目标是找到一组权重向量 w \mathbf{w} w和偏置 b b b:
这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
1.1.2. 损失函数
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
回归问题中最常用的损失函数是平方误差函数。当样本 i i i的预测值为 y ^ ( i ) \hat{y}^{(i)} y^(i),其相应的真实标签为 y ( i ) y^{(i)} y(i)时,
平方误差可以定义为以下公式:
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 . l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2. l(i)(w,b)=21(y^(i)−y(i))2.
为了度量模型在整个数据集上的质量,我们需计算在训练集 n n n个样本上的损失均值(也等价于求和)。
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w ⊤ x ( i ) + b − y ( i ) ) 2 . L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(w⊤x(i)+b−y(i))2.
在训练模型时,我们希望寻找一组参数( w ∗ , b ∗ \mathbf{w}^*, b^* w∗,b∗),
这组参数能最小化在所有训练样本上的总损失。如下式:
w ∗ , b ∗ = argmin w , b L ( w , b ) . \mathbf{w}^*, b^* = \operatorname*{argmin}_{\mathbf{w}, b}\ L(\mathbf{w}, b). w∗,b∗=w,bargmin L(w,b).
1.1.3. 解析解
线性回归的解可以用一个公式简单地表达出来, 这类解叫作解析解(analytical solution)。但并不是所有的问题都存在解析解。
首先,我们将偏置 b b b合并到参数 w \mathbf{w} w中,合并方法是在包含所有参数的矩阵中附加一列。
我们的预测问题是最小化 ∥ y − X w ∥ 2 \|\mathbf{y} - \mathbf{X}\mathbf{w}\|^2 ∥y−Xw∥2。
这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小值点。
将损失关于 w \mathbf{w} w的导数设为0,得到解析解:
w ∗ = ( X ⊤ X ) − 1 X ⊤ y . \mathbf{w}^* = (\mathbf X^\top \mathbf X)^{-1}\mathbf X^\top \mathbf{y}. w∗=(X⊤X)−1X⊤y.
1.1.4. 随机梯度下降
即使在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。
在许多任务上,那些难以优化的模型效果要更好。
因此,弄清楚如何训练这些难以优化的模型是非常重要的。
梯度下降(gradient descent)的方法,几乎可以优化所有深度学习模型。(它通过不断地在损失函数递减的方向上更新参数来降低误差)
因为梯度下降在每次更新参数之前,我们必须遍历整个数据集。执行极慢。所以通常采用小批量随机梯度下降
-
在每次迭代中,我们首先随机抽样一个固定数量样本的小批量 B \mathcal{B} B,
-
然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。
-
最后,我们将梯度乘以一个预先确定的正数 η \eta η,并从当前参数的值中减掉。
我们用下面的数学公式来表示这一更新过程( ∂ \partial ∂表示偏导数):
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) . (\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b). (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b).
对于平方损失和仿射变换,我们可以明确地写成如下形式:
w ← w − η ∣ B ∣ ∑ i ∈ B ∂ w l ( i ) ( w , b ) = w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w ⊤ x ( i ) + b − y ( i ) ) , b ← b − η ∣ B ∣ ∑ i ∈ B ∂ b l ( i ) ( w , b ) = b − η ∣ B ∣ ∑ i ∈ B ( w ⊤ x ( i ) + b − y ( i ) ) . \begin{aligned} \mathbf{w} &\leftarrow \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{\mathbf{w}} l^{(i)}(\mathbf{w}, b) = \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \mathbf{x}^{(i)} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right),\\ b &\leftarrow b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_b l^{(i)}(\mathbf{w}, b) = b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right). \end{aligned} wb←w−∣B∣ηi∈B∑∂wl(i)(w,b)=w−∣B∣ηi∈B∑x(i)(w⊤x(i)+b−y(i)),←b−∣B∣ηi∈B∑∂bl(i)(w,b)=b−∣B∣ηi∈B∑(w⊤x(i)+b−y(i)).
∣ B ∣ |\mathcal{B}| ∣B∣表示每个小批量中的样本数, η \eta η表示学习率
批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。
这些可以调整但不在训练过程中更新的参数称为超参数,调参是选择超参数的过程
1.1.5. 用模型进行预测
给定“已学习”的线性回归模型 w ^ ⊤ x + b ^ \hat{\mathbf{w}}^\top \mathbf{x} + \hat{b} w^⊤x+b^,现在我们可以通过给定特征来估计目标(这个过程通常称为预测)
1.2. 向量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。
为了实现这一点,需要我们对计算进行向量化,从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
import time
import numpy as np
import torch
from d2l import torch as d2l
n = 10000
a = torch.ones([n])
b = torch.ones([n])
# print(a.numel())#我们定义一个计时器
class Timer: #@save"""记录多次运行时间"""def __init__(self):self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()c = torch.zeros(n)
timer = Timer()
#我们使用for循环,每次执行一位的加法
for i in range(n):c[i] = a[i] + b[i]
print(f'{timer.stop():.5f} sec')#使用重载的+运算符来计算按元素的和
timer.start()
d = a + b
print(f"{timer.stop():.5f} sec")#结果:
0.10190 sec
0.00000 sec结果很明显,第二种方法比第一种方法快得多。向量化代码通常会带来数量级的加速。
1.3. 正态分布与平方损失
接下来,我们通过对噪声分布的假设来解读平方损失目标函数。正态分布和线性回归之间的关系很密切。
简单的说,若随机变量 x x x具有均值 μ \mu μ和方差 σ 2 \sigma^2 σ2(标准差 σ \sigma σ),其正态分布概率密度函数如下:
p ( x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( x − μ ) 2 ) . p(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2 \sigma^2} (x - \mu)^2\right). p(x)=2πσ21exp(−2σ21(x−μ)2).
#正态分布与平方损失
def normal(x,mu,sigma):p = 1/np.sqrt(2*math.pi*sigma**2)return p * np.exp(-0.5 /sigma**2 * (x-mu)**2)
# 再次使用numpy进行可视化
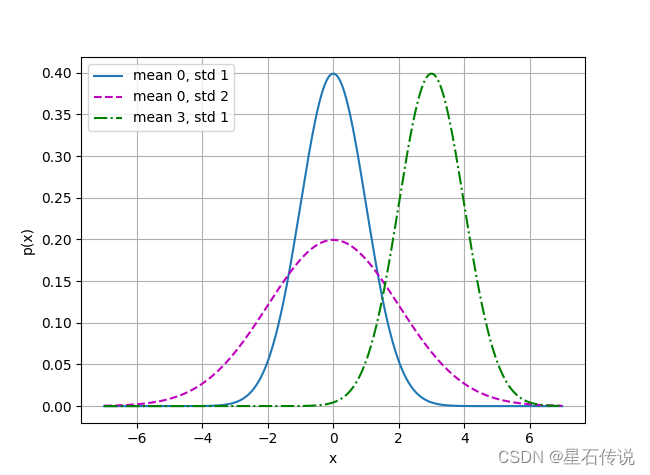
x = np.arange(-7, 7, 0.01)# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',ylabel='p(x)', figsize=(6.5, 4.5),legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])
d2l.plt.show()如图,改变均值会产生沿 x x x轴的偏移,增加方差将会分散分布、降低其峰值。
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:
我们假设了观测中包含噪声,其中噪声服从正态分布。
噪声正态分布如下式:
y = w ⊤ x + b + ϵ , y = \mathbf{w}^\top \mathbf{x} + b + \epsilon, y=w⊤x+b+ϵ,
其中, ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim \mathcal{N}(0, \sigma^2) ϵ∼N(0,σ2)。
因此,我们现在可以写出通过给定的 x \mathbf{x} x观测到特定 y y y的似然:
P ( y ∣ x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( y − w ⊤ x − b ) 2 ) . P(y \mid \mathbf{x}) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2 \sigma^2} (y - \mathbf{w}^\top \mathbf{x} - b)^2\right). P(y∣x)=2πσ21exp(−2σ21(y−w⊤x−b)2).
现在,根据极大似然估计法,参数 w \mathbf{w} w和 b b b的最优值是使整个数据集的似然最大的值:
P ( y ∣ X ) = ∏ i = 1 n p ( y ( i ) ∣ x ( i ) ) . P(\mathbf y \mid \mathbf X) = \prod_{i=1}^{n} p(y^{(i)}|\mathbf{x}^{(i)}). P(y∣X)=i=1∏np(y(i)∣x(i)).
根据极大似然估计法选择的估计量称为极大似然估计量。
由于历史原因,优化通常是说最小化而不是最大化。我们可以改为最小化负对数似然 − log P ( y ∣ X ) -\log P(\mathbf y \mid \mathbf X) −logP(y∣X)。
− log P ( y ∣ X ) = ∑ i = 1 n 1 2 log ( 2 π σ 2 ) + 1 2 σ 2 ( y ( i ) − w ⊤ x ( i ) − b ) 2 . -\log P(\mathbf y \mid \mathbf X) = \sum_{i=1}^n \frac{1}{2} \log(2 \pi \sigma^2) + \frac{1}{2 \sigma^2} \left(y^{(i)} - \mathbf{w}^\top \mathbf{x}^{(i)} - b\right)^2. −logP(y∣X)=i=1∑n21log(2πσ2)+2σ21(y(i)−w⊤x(i)−b)2.
现在我们只需要假设 σ \sigma σ是某个固定常数就可以忽略第一项,
因为第一项不依赖于 w \mathbf{w} w和 b b b。
现在第二项除了常数 1 σ 2 \frac{1}{\sigma^2} σ21外,其余部分和前面介绍的均方误差是一样的。
幸运的是,上面式子的解并不依赖于 σ \sigma σ。
因此,在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。
1.4. 从线性回归到深度网络
尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型,从而把线性模型看作一个神经网络。
二、线性回归的从零开始实现
2.1. 生成数据集
我们使用线性模型参数w=[2,−3.4]⊤、b=4.2 和噪声项ϵ生成数据集及其标签: y=Xw+b+ϵ.
ϵ可以视为模型预测和标签时的潜在观测误差。 在这里我们认为标准假设成立,即ϵ服从均值为0的正态分布。 为了简化问题,我们将标准差设为0.01。 下面的代码生成合成数据集:
import random
import torch
from d2l import torch as d2l#生成数据集:
def synthetic_data(w, b, num_examples): #@save"""生成y=Xw+b+噪声"""X = torch.normal(0, 1, (num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
#features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)
print('features:', features[0],'\nlabel:', labels[0])
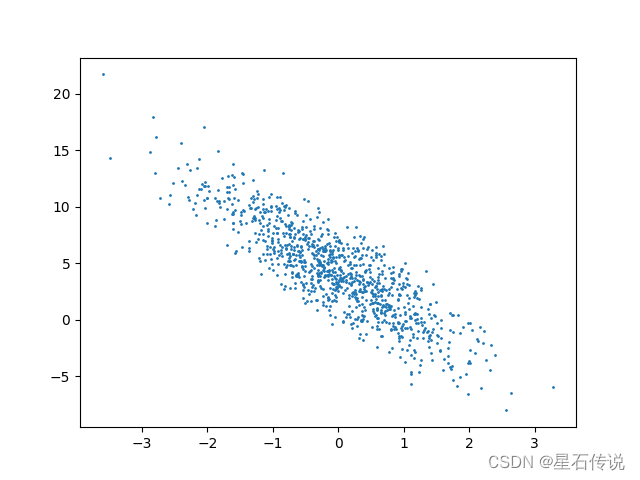
#可视化线性关系(第二个特征和标签值的散点图)
# d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
d2l.plt.show()#结果:
features: tensor([-0.5307, 1.2137])
label: tensor([-0.9951])
2.2. 读取数据集
定义一个data_iter函数, 该函数随机接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签
#读取数据集:
def data_iter(bath_size,features,labels):num_examples = len(features) #获取数据集的总样本数量indices = list(range(num_examples))random.shuffle(indices) #将样本索引列表打乱#这些样本是随机读取的,没有特定的顺序for i in range(0,num_examples,bath_size):bath_indices = torch.tensor(indices[i:min(i+bath_size,num_examples)])yield features[bath_indices],labels[bath_indices]#查看
bath_size = 10
for X ,y in data_iter(bath_size,features,labels):print(X,"\n",y)break
2.3. 初始化模型参数
在我们开始用小批量随机梯度下降优化我们的模型参数之前,我们需要先有一些参数
#初始化参数
w = torch.normal(0,0.01,size=(2,1),requires_grad= True)
b =torch.zeros(1,requires_grad=True)2.4. 定义模型
#定义模型
def linreg(X,w,b):#线性回归模型return torch.matmul(X,w) +b #或用torch.mv()2.5. 定义损失函数
#定义损失函数
def squared_loss(y_hat,y):#均方损失return (y_hat - y.reshape(y_hat.shape))**2 / 22.6. 定义优化算法
#定义优化算法:
def sgd(params,lr,bath_size):#小批量随机梯度下降with torch.no_grad():for param in params:param -= lr *param.grad /bath_size #梯度反方向传播param.grad.zero_()2.7. 训练
#训练
"""
执行以下循环:
初始化参数
重复以下训练,直到完成
计算梯度
更新参数
"""lr = 0.03 #学习率
num_epochs = 3 #迭代轮数
net = linreg #线性模型
loss = squared_loss #损失函数for epoch in range(num_epochs):for X,y in data_iter(bath_size,features,labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量,l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward()sgd([w,b],lr,bath_size) # 使用参数的梯度更新参数with torch.no_grad():train_l = loss(net(features,w,b),labels)print(f"epoch{epoch+ 1},loss {float(train_l.mean()):f}")#比较真实参数和通过训练学到的参数来评估训练的成功程度
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')#结果:
epoch1,loss 0.033319
epoch2,loss 0.000119
epoch3,loss 0.000048
w的估计误差: tensor([ 0.0004, -0.0006], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0005], grad_fn=<RsubBackward1>)三、线性回归的简洁实现
3.1. 生成数据集
与前面类似
import torch
from torch.utils import data
from d2l import torch as d2l#生成数据集
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
3.2. 读取数据集
features和labels作为API的参数传递,并通过数据迭代器指定batch_size。 此外,布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
取数据集
def load_array(data_arrays,batch_size,is_train = True): #@save#构造一个pytorch数据迭代器dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset,batch_size,shuffle=is_train)batch_size = 10
data_iter = load_array((features, labels), batch_size)#print(next(iter(data_iter))) #从迭代器中获取第一项。3.3. 定义模型
定义一个模型变量
net,它是一个Sequential类的实例。
Sequential类将多个层串联在一起。
当给定输入数据时,Sequential实例将数据传入到第一层,
然后将第一层的输出作为第二层的输入,以此类推。
在下面的例子中,我们的模型只包含一个层,因此实际上不需要Sequential。
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1)) #2表示输入特征的维度,1表示输出特征的维度3.4. 初始化模型参数
我们通过
net[0]选择网络中的第一个图层,
然后使用weight.data和bias.data方法访问参数。
我们还可以使用替换方法normal_和fill_来重写参数值。
print(net[0].weight.data.normal_(0,0.01))
print(net[0].bias.data.fill_(0))
print(net[0])
print(net)#结果:
tensor([[-8.8769e-03, -2.7674e-05]])
tensor([0.])
Linear(in_features=2, out_features=1, bias=True)
Sequential((0): Linear(in_features=2, out_features=1, bias=True)
)
3.5. 定义损失函数
计算均方误差使用的是MSELoss类,也称为平方L2范数。 默认情况下,它返回所有样本损失的平均值。
loss = nn.MSELoss()
3.6. 定义优化算法
小批量随机梯度下降算法是一种优化神经网络的标准工具,
PyTorch在optim模块中实现了该算法的许多变种。
当我们(实例化一个SGD实例)时,我们要指定优化的参数
(可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。
#定义优化算法:
trainer = torch.optim.SGD(net.parameters(),lr= 0.03)
3.7. 训练
在每个迭代周期里,我们将完整遍历一次数据集(
train_data),
不停地从中获取一个小批量的输入和相应的标签。
对于每一个小批量,我们会进行以下步骤:
- 通过调用
net(X)生成预测并计算损失l(前向传播)。 - 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
#训练:
num_epochs = 3
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X) ,y)trainer.zero_grad() #将模型参数的梯度清零,以便进行反向传播。l.backward() #根据损失值进行反向传播,计算模型参数的梯度。trainer.step() #根据梯度更新模型参数l = loss(net(features), labels) #计算整个训练集的损失值print(f'epoch {epoch + 1}, loss {l:f}')w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)#结果:
epoch 1, loss 0.000213
epoch 2, loss 0.000100
epoch 3, loss 0.000099
w的估计误差: tensor([3.5274e-04, 3.2663e-05])
b的估计误差: tensor([9.5367e-07])
总结
本章根据书本知识,详细介绍了线性神经网络中的线性回归原理,并从零开始展示了线性回归的代码实现,以及在pytorch深度学习框架下更简洁的线性回归代码实现。接下来将进入softmax回归的讲解。
靖康耻,犹未雪;臣子恨,何时灭?驾长车,踏破贺兰山缺…
–2023-9-18 进阶篇
相关文章:
深度学习——线性神经网络一
深度学习——线性神经网络一 文章目录 前言一、线性回归1.1. 线性回归的基本元素1.1.1. 线性模型1.1.2. 损失函数1.1.3. 解析解1.1.4. 随机梯度下降1.1.5. 用模型进行预测 1.2. 向量化加速1.3. 正态分布与平方损失1.4. 从线性回归到深度网络 二、线性回归的从零开始实现2.1. 生…...
利用大模型知识图谱技术,告别繁重文案,实现非结构化数据高效管理
我,作为一名产品经理,对文案工作可以说是又爱又恨,爱的是文档作为嘴替,可以事事展开揉碎讲清道明;恨的是只有一个脑子一双手,想一边澄清需求一边推广宣传一边发布版本一边申报认证实在是分身乏术࿰…...

Java抽象类和普通类区别、 数组跟List的区别
抽象类 Java中的抽象类是一种特殊的类,它不能被实例化,只能被继承。抽象类通常用于定义一些通用的属性和方法,但是这些方法的具体实现需要在子类中完成。抽象类中可以包含抽象方法和非抽象方法。 抽象方法是一种没有实现的方法,…...

Leetcode.2522 将字符串分割成值不超过 K 的子字符串
题目链接 Leetcode.2522 将字符串分割成值不超过 K 的子字符串 rating : 1605 题目描述 给你一个字符串 s s s ,它每一位都是 1 1 1 到 9 9 9 之间的数字组成,同时给你一个整数 k k k 。 如果一个字符串 s s s 的分割满足以下条件,我们…...
)
成绩分析(蓝桥杯)
成绩分析 题目描述 小蓝给学生们组织了一场考试,卷面总分为 100 分,每个学生的得分都是一个 0 到 100 的整数。 请计算这次考试的最高分、最低分和平均分。 输入描述 输入的第一行包含一个整数 n (1≤n≤104 ),表示考试人数。 接下来 n 行…...
【多思路附源码持续更新】2023年华为杯(中国研究生数学建模)竞赛C题
赛题 若官网拥挤,数据集和赛题下载地址如下: https://download.csdn.net/download/weixin_47723732/88364777 历届优秀论文下载地址,可以做参考文章 https://download.csdn.net/download/weixin_47723732/88365222 论文万能模板下载地址 htt…...
)
基于STM32设计的校园一卡通(设计配套的手机APP)
一、功能介绍 【1】项目介绍 随着信息技术的不断发展,校园一卡通作为一种高效便捷的管理方式,已经得到了广泛的应用。而其核心部件——智能卡也被越来越多的使用者所熟知。 本文介绍的项目是基于STM32设计的校园一卡通消费系统,通过RC522模块实现对IC卡的读写操作,利用2…...
有了Spring为什么还需要SpringBoot呢
目录 一、Spring缺点分析 二、什么是Spring Boot 三、Spring Boot的核心功能 3.1 起步依赖 3.2 自动装配 一、Spring缺点分析 1. 配置文件和依赖太多了!!! spring是一个非常优秀的轻量级框架,以IOC(控制反转&…...

【记录】Python 之于 C/C++ 区别
记录本人在 Python 上经常写错的一些地方(C/C 写多了,再写 Python 有点切换不过来) 逻辑判断符号用 and、or、!可以直接 10 < num < 30 比较大小分支语句:if、elif、else使用 、-,Python 中不支持 、- - 这两个…...

【Vue-Element-Admin】dialog关闭回调事件
背景 点击导入按钮,调出导入弹窗,解析excel数据后,不点击【确认并导入】按钮,直接关闭弹窗,数据违背清理 实现 使用dialog的close回调函数,在el-dialog添加close,在methods中定义closeDialog…...

Ansible自动化:简化你的运维任务
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
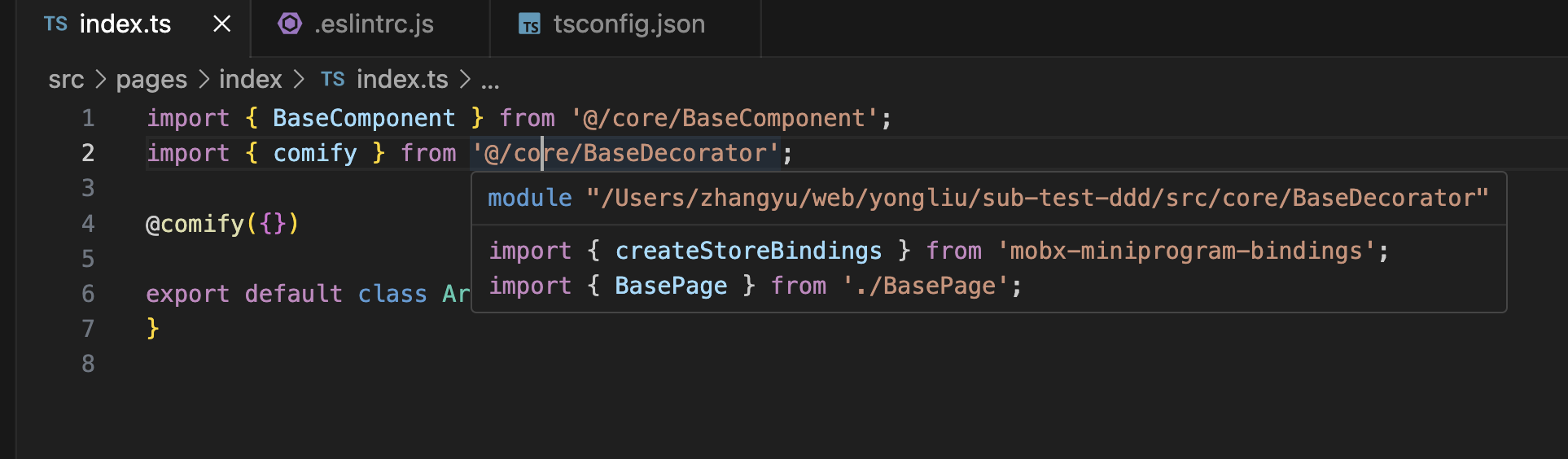
webpack配置alias后eslint和ts无法识别
背景 我们在 webpack 配置 alias 后,发现项目中引入的时候,还是会报错,如下: 可以看到,有一个是 ts报错,还有一个是 eslint 报错。 解决 ts 报错 tsconfig.json {"compilerOptions": {...&q…...
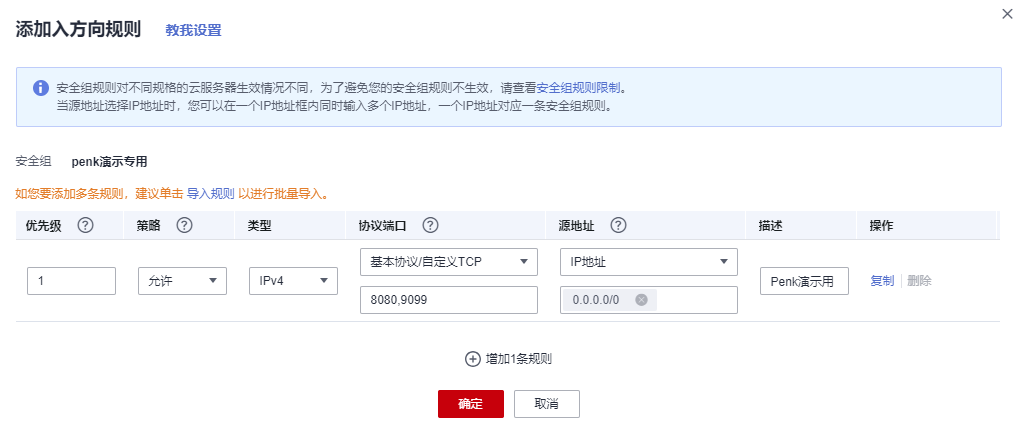
小程序从无到有教学教程-- 01.重置华为云服务器Huawei Cloud EulerOS 2.0版本并且设置安全组
概述 专门拿了专栏来讲解,所以目录结构就比较简单了 文章目录 概述修改华为云操作系统选择Huawei Cloud EulerOS 2.0 镜像顺便配置华为安全组 修改华为云操作系统 这里选择华为最新的系统,不过也就2.0~ 选择Huawei Cloud EulerOS 2.0 镜像 这里记住密…...

js实现短信验证码一键登录
前言 短信验证码一键登录是一种方便快捷的登录方式,用户只需输入手机号码,然后接收到手机短信验证码并自动填入验证码框,即可完成登录操作。本文将介绍短信验证码一键登录的原理,并给出一个简单的示例说明。 短信验证码一键登录…...

vue2的基础知识巩固
一、定义:是一个渐进式的JavaScript框架 二、特点: 减少了大量的DOM操作编写 ,可以更专注于逻辑操作分离数据和界面的呈现,降低了代码耦合度(前端端分离)支持组件化开发,更利于中大型项目的代码组织 vue2核心功能&a…...
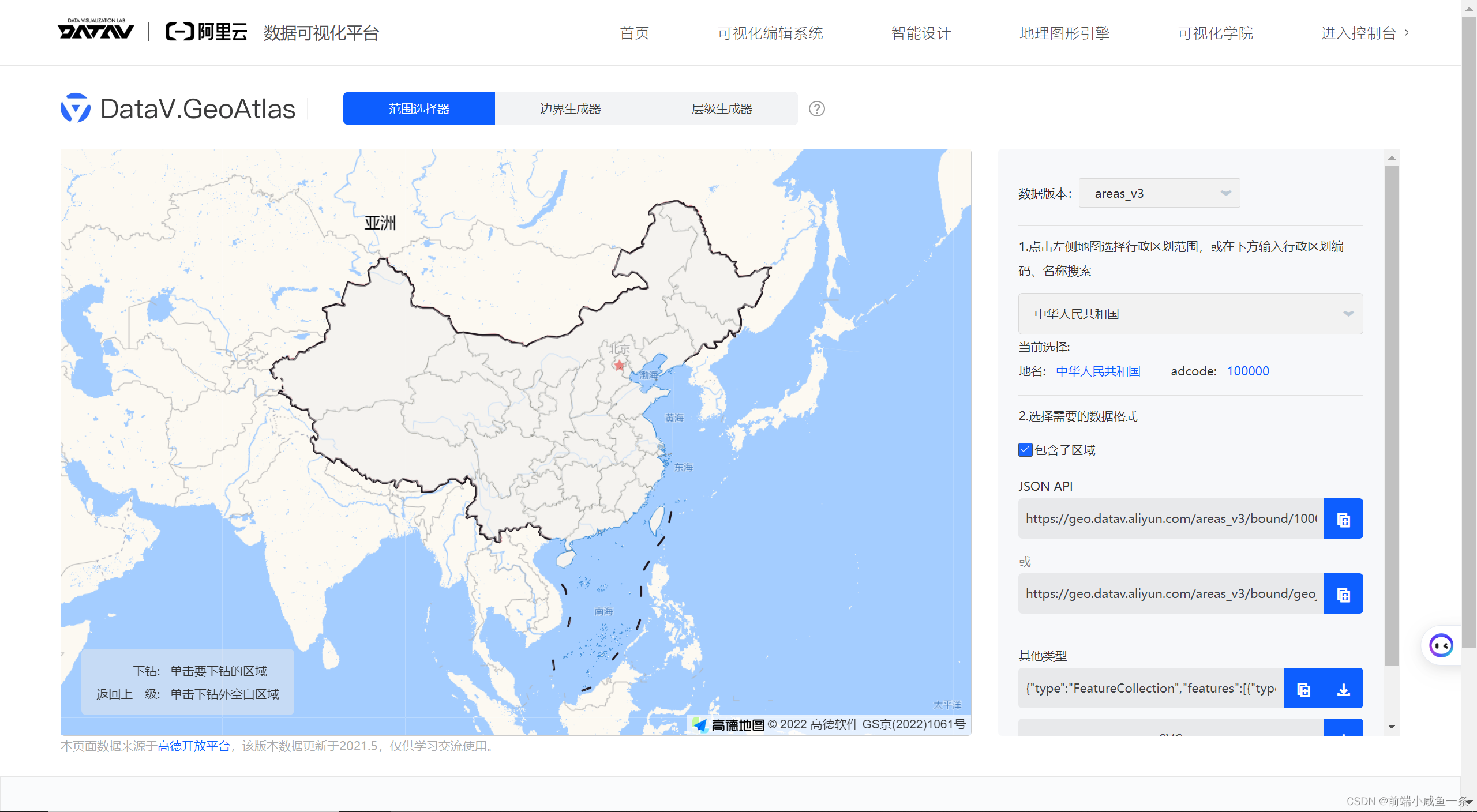
echart离线地图下载地址
链接: 离线地图地址 https://datav.aliyun.com/portal/school/atlas/area_selector...

elk日志某个时间节点突然搜索不到了
elk日志某个时间节点突然搜索不到了,检查filebeat正常 Kibana手动上传数据: 响应: Error: Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [2000]/[2000] maximum shards open 原因:ElasticSearch总分片数量导致的异常,ES…...
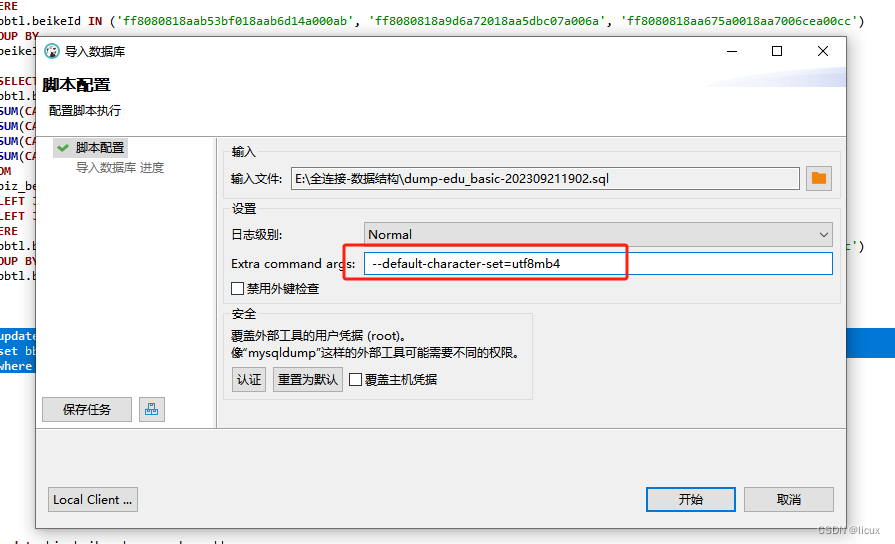
dbeaver 导出的sql文件,恢复数据库报错,Unknown command ‘\‘‘.
这是因为编码格式错误导致的, 加上这个即可 (注意前后不能有空格) --default-character-setutf8mb4...

Android.bp常用语法和预定义属性
介绍 Android.bp是Android构建系统中用于定义模块和构建规则的配置文件,它使用一种简单的声明式语法。以下是Android.bp的一些常见语法规则和约定: 注释: 单行注释使用//符号。 多行注释使用/和/包围。 和go语言相同 // 这是单行注释 /* 这是…...

close和fclose
在Linux系统中,close函数并不会主动调用fsync接口。close函数只是关闭了文件描述符,而不保证数据被写入到磁盘。如果你想确保数据被写入到磁盘,你需要在close函数之前调用fsync函数。这是因为Linux使用了缓存机制来提高磁盘的读写性能&#x…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...