207.Flink(二):架构及核心概念,flink从各种数据源读取数据,各种算子转化数据,将数据推送到各数据源
一、Flink架构及核心概念
1.系统架构
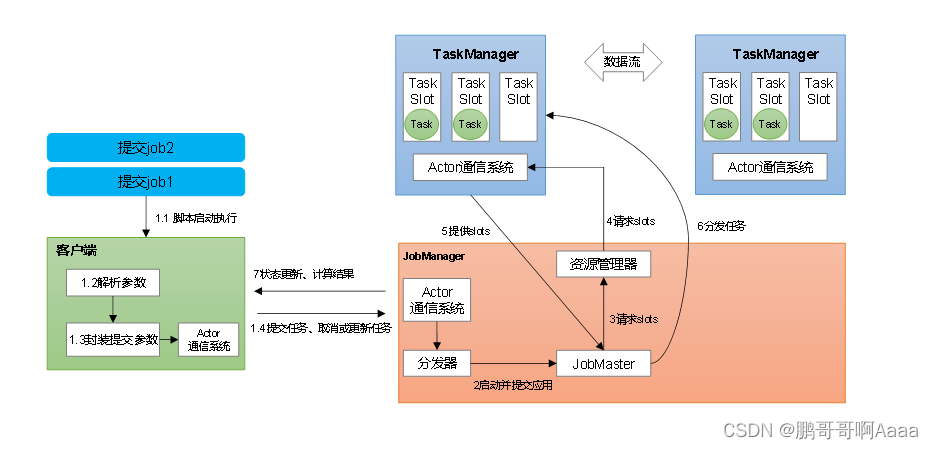
- JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。
- 一个job对应一个jobManager
2.并行度
(1)并行度(Parallelism)概念
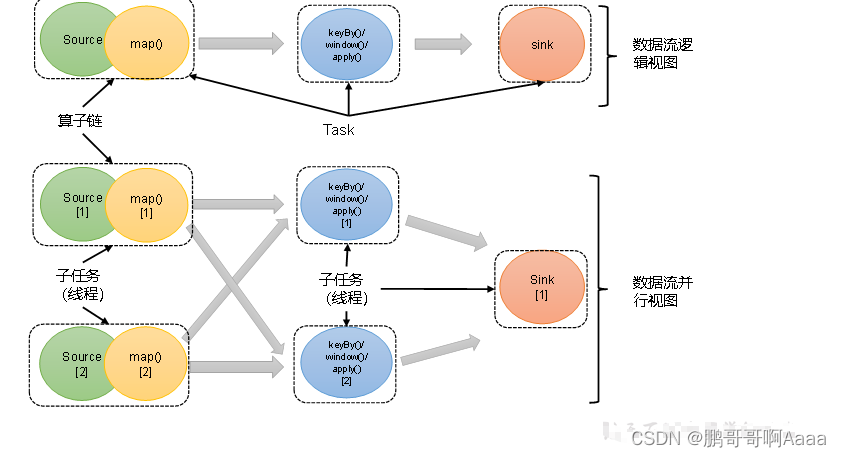
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。
流程序的并行度 = 其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
(2)设置并行度
对某个具体算子设置并行度:
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);全局设置并行度:
env.setParallelism(2);提交任务时指定:
- 通过页面上传jar的时候可以指定
- 可以在命令行启动的时候通过 -p 3指定
flink-conf.yaml中配置:
parallelism.default: 2优先级:
代码中具体算子 > 代码中全局 > 提交任务指定 > 配置文件中指定
3.算子链

(1)算子间的数据传输
*1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。它们之间不需要重新分区,也不需要调整数据的顺序。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于Spark中的窄依赖。
*2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
(2)合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分
// 禁用算子链,该算子不会和前面和后面串在一起
.map(word -> Tuple2.of(word, 1L)).disableChaining();// 全局禁用算子链
env.disableChaining();// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()- 当一对一的时候,每个运算量都很大,这个时候不适合串在一起。
- 当需要定位具体问题的时候,不串在一起更容易排查问题
4.任务槽
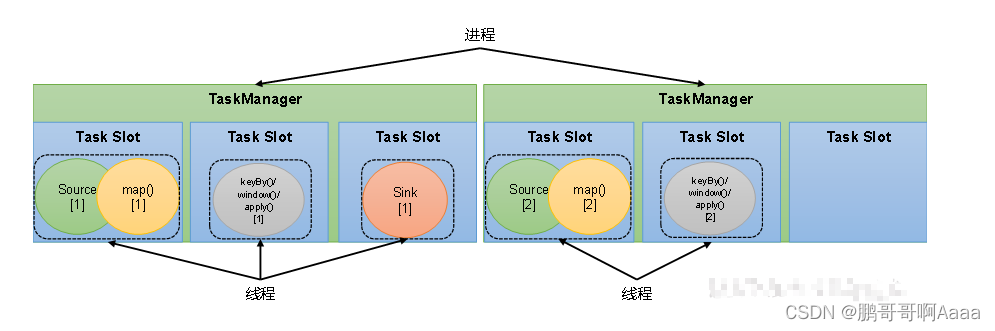
(1)任务槽(Task Slots)概念
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
TaskManager的计算资源是有限的,为了控制并发量,TaskManager对每个任务运行所占用的内存资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽的大小是均等的,且任务槽之间的资源不可以互相借用。
如图,每个TaskManager有三个任务槽,每个槽运行自己的任务。槽的大小均等。
(2)任务槽数量的设置
在Flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中,可以设置TaskManager的slot数量,默认是1个slot。
taskmanager.numberOfTaskSlots: 8slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,建议将slot数量配置为机器的CPU核心数。
(3)任务对任务槽的共享
在同一个作业中,不同任务节点的并行子任务可以放在同一个slot上执行

可以共享:
- 同一个job中,不同算子的子任务才可以共享同一个slot。这些子任务是同时运行
- 前提是:属于同一个slot共享组,默认都是“default”
手动指定共享组:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");共享的好处:允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行
(4)任务槽和并行度的关系
- 任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置
- 并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置
如果是yarn模式,申请的TaskManager的数量 = job并行度 / 每个TM的slot数量,向上取整
即:假设10个并行度的job,每个TM的slot是3个,那么需要10/3,向上取整,即需要最少4个TaskManager
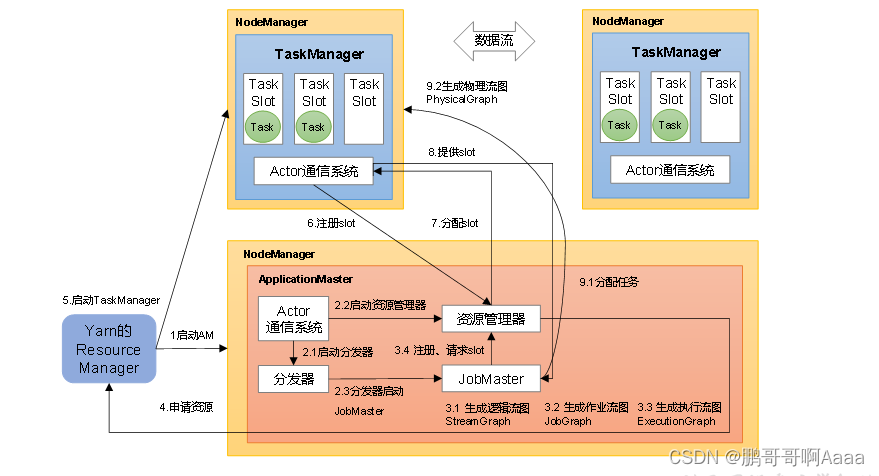
二、作业提交流程
1.Standalone会话模式作业提交流程
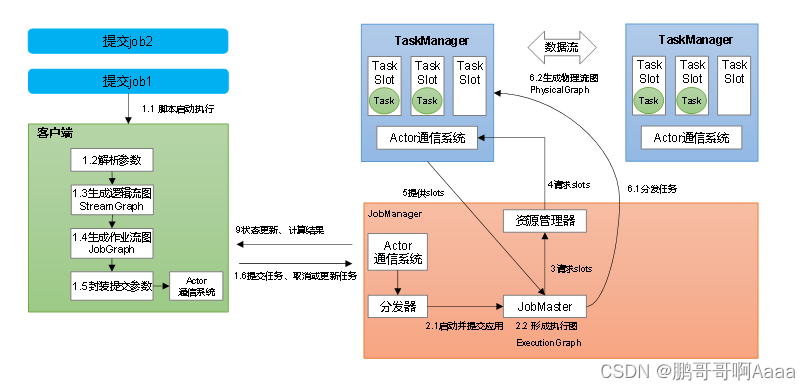
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。


- 逻辑流图:列出并行度,算子,各算子之间关系(一对一还是需要重分区)
- 作业图:将一对一的算子做算子链的优化,作业中间会有中间结果集
- 执行图:将并行度展开,并标注每个并行处理的算子
- 物理图:基本同执行图,是执行图的落地
2.Yarn应用模式作业提交流程
三、 DataStream API
DataStream API是Flink的核心层API。一个Flink程序,其实就是对DataStream的各种转换。
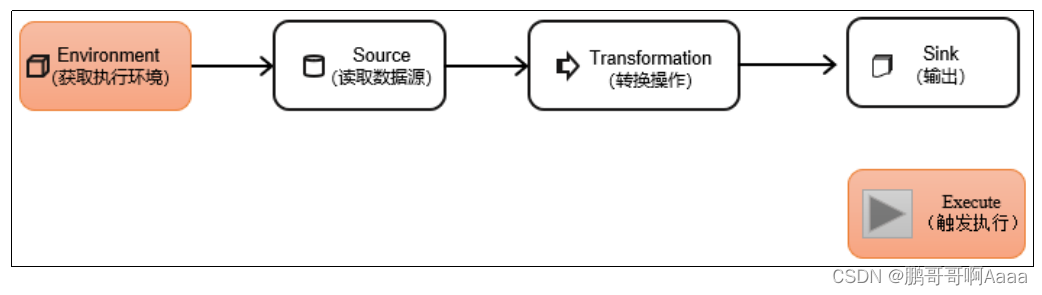
1.执行环境(Execution Environment)
(1)创建执行环境
*1)StreamExecutionEnvironment.getExecutionEnvironment();
它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境
*2)StreamExecutionEnvironment.createLocalEnvironment();
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU核心数
*3)StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager主机名
1234, // JobManager进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
);
这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
(2)执行模式(Execution Mode)
流批一体:代码api是同一套,可以指定为 批,也可以指定为 流。
通话代码配置:
env.setRuntimeMode(RuntimeExecutionMode.BATCH);通过命令行配置:
bin/flink run -Dexecution.runtime-mode=BATCH(3)触发程序执行
当main()方法被调用时,并没有真正处理数据。只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
如果在一段代码里面执行多个任务,可以使用env.executeAsync();
package com.atguigu.env;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** TODO** @author cjp* @version 1.0*/
public class EnvDemo {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment
// .getExecutionEnvironment(); // 自动识别是 远程集群 ,还是idea本地环境.getExecutionEnvironment(conf); // conf对象可以去修改一些参数// .createLocalEnvironment()
// .createRemoteEnvironment("hadoop102", 8081,"/xxx")// 流批一体:代码api是同一套,可以指定为 批,也可以指定为 流// 默认 STREAMING// 一般不在代码写死,提交时 参数指定:-Dexecution.runtime-mode=BATCHenv.setRuntimeMode(RuntimeExecutionMode.BATCH);env
// .socketTextStream("hadoop102", 7777).readTextFile("input/word.txt").flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1).print();env.execute();/** TODO 关于execute总结(了解)* 1、默认 env.execute()触发一个flink job:* 一个main方法可以调用多个execute,但是没意义,指定到第一个就会阻塞住* 2、env.executeAsync(),异步触发,不阻塞* => 一个main方法里 executeAsync()个数 = 生成的flink job数* 3、思考:* yarn-application 集群,提交一次,集群里会有几个flink job?* =》 取决于 调用了n个 executeAsync()* =》 对应 application集群里,会有n个job* =》 对应 Jobmanager当中,会有 n个 JobMaster*/
// env.executeAsync();// ……
// env.executeAsync();}
}
2.源算子(Source)
从Flink1.12开始,主要使用流批统一的新Source架构:
DataStreamSource<String> stream = env.fromSource(…)(1)创建pojo对象
需要空参构造器,所有属性的类型都是可以序列化的
package com.atguigu.bean;import java.util.Objects;/*** TODO** @author cjp* @version 1.0*/
public class WaterSensor {public String id;//水位传感器类型public Long ts;//传感器记录时间戳public Integer vc;//水位记录// 一定要提供一个 空参 的构造器public WaterSensor() {}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}
}
(2)从集合中读取数据
package com.atguigu.source;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author cjp* @version 1.0*/
public class CollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO 从集合读取数据DataStreamSource<Integer> source = env.fromElements(1,2,33); // 从元素读
// .fromCollection(Arrays.asList(1, 22, 3)); // 从集合读source.print();env.execute();}
}
(3)从文件读取数据
先添加配置:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>1.17.0</version></dependency>package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author cjp* @version 1.0*/
public class FileSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从文件读: 新Source架构FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "filesource").print();env.execute();}
}
/**** 新的Source写法:* env.fromSource(Source的实现类,Watermark,名字)**/(4)从Socket读取数据
DataStream<String> stream = env.socketTextStream("localhost", 7777);(5)从Kafka读取数据
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version>
</dependency>package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;/*** TODO** @author cjp* @version 1.0*/
public cl相关文章:
207.Flink(二):架构及核心概念,flink从各种数据源读取数据,各种算子转化数据,将数据推送到各数据源
一、Flink架构及核心概念 1.系统架构 JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。一个job对应一个jobManager 2.并行度 (1)并行度(Parallelism)概念 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任…...
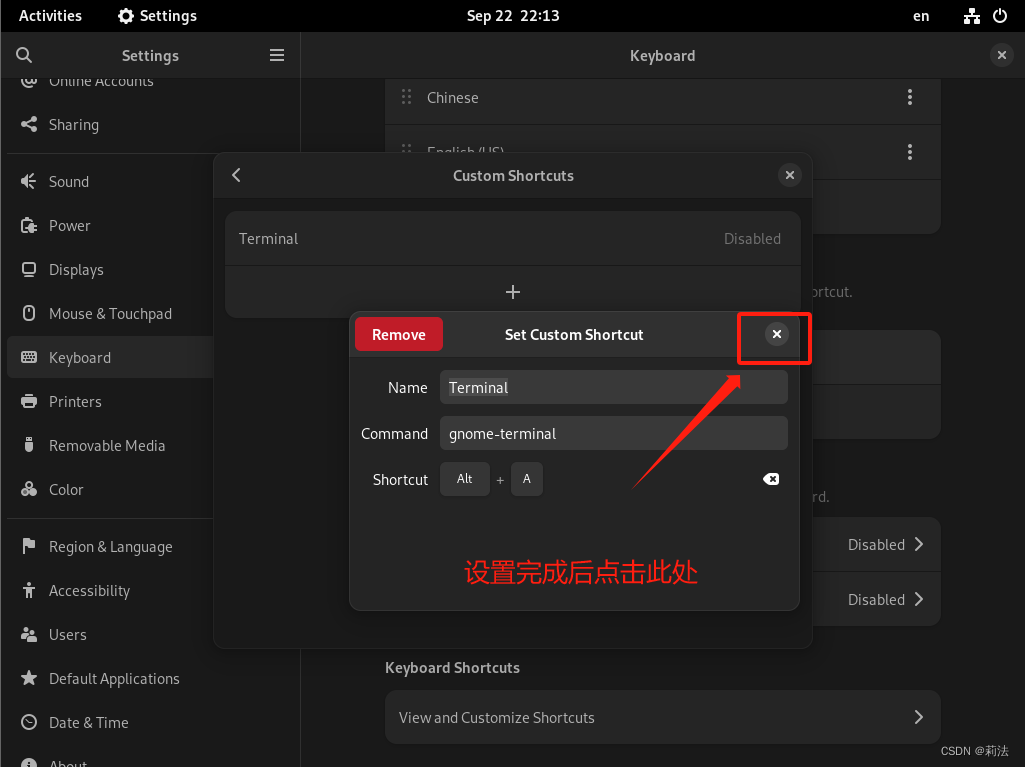
debian终端快捷键设置
为了方便使用图形化debian,快捷调出shell终端是提升工作学习效率的最重要的一步。 1.首先点击右上角,选择设置 2.点击键盘,选择快捷键,并创建自定义快捷键 3.点击添加快捷键 4.根据图中提示创建快捷键 Name: Terminal Command…...

原生ajax
什么是Ajax Asynchronous JavaScript and xml 异步的 js 和 xml(数据承载方式) ,本质:使用js提供的异步对象XMLHttpRequest 异步的向服务器提交请求,并且接受服务器响应回来的数据。 使用ajax 1.创建异步对象 var xhrnew XMLHttp…...
:并发编程)
面试题库(五):并发编程
多线程类的使用 java线程同步有哪些方法、各自的优缺点synchronized 和ReentrantLock区别,可重入锁是什么?threadlocal有什么用Java中创建线程有几种方式?分别是? 当主线程执行结束后,子线程还会继续执行下去吗?JUC中有哪些常用的集合?(项目中用到的)CopyOnWriteArray…...

Android FileProvider笔记
一、FileProvider是什么 通过FileProvider.getUriForFile(NonNull Context context, NonNull String authority, NonNull File file)方法获得一个有临时权限的Uri给客户端用来访问本APP文件。 当然看FileProvider类的注释更加详细 二、代码示例 <providerandroid:name&q…...
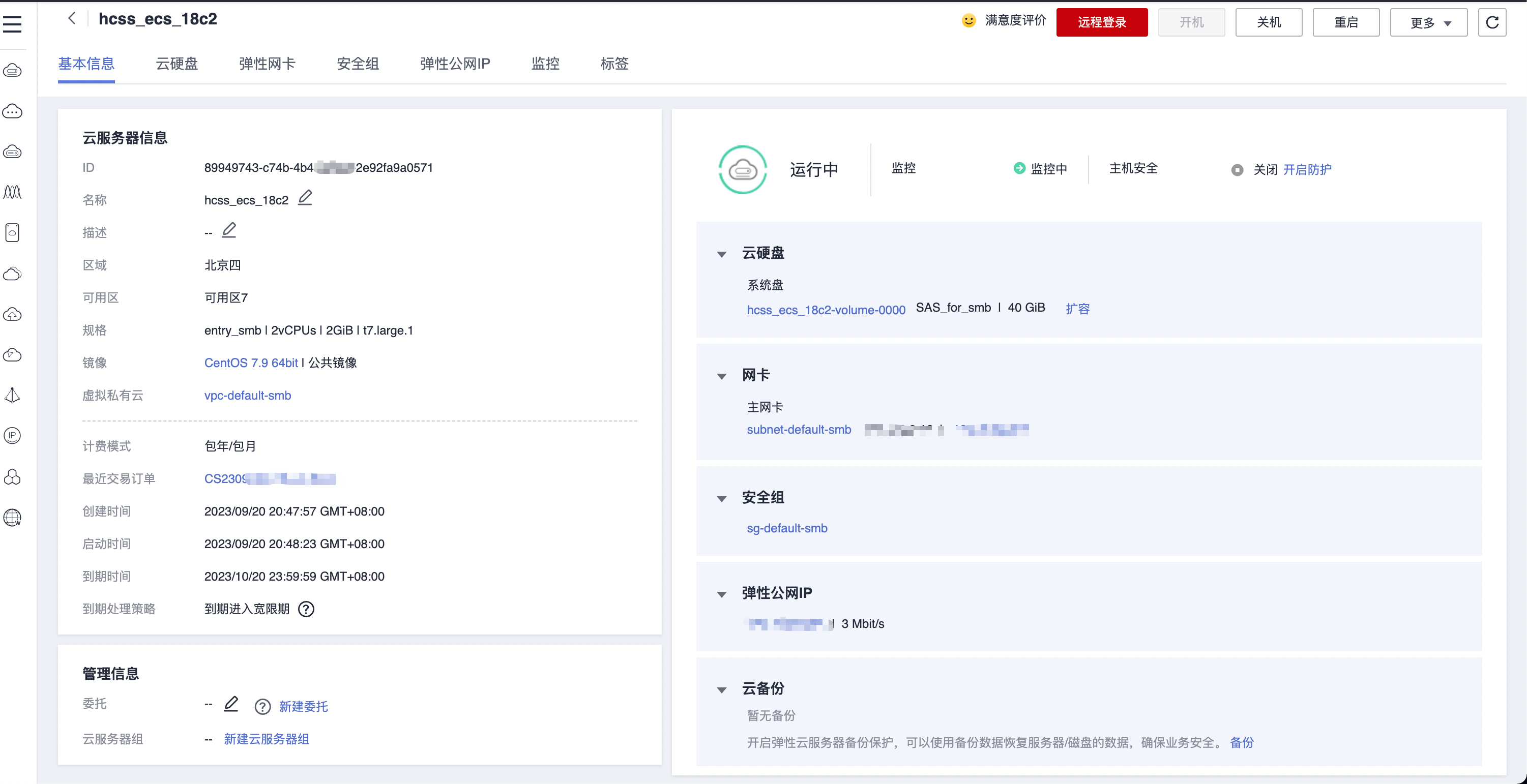
华为云云耀云服务器L实例评测 |云服务器选购
华为云耀云服务器 L 实例是一款轻量级云服务器,开通选择实例即可立刻使用,不需要用户再对服务器进行基础配置。新用户还有专享优惠,2 核心 2G 内存 3M 带宽的服务器只要 89 元/年,可以点击华为云云耀云服务器 L 实例购买地址去购买…...

2023-09-22 LeetCode每日一题(将钱分给最多的儿童)
2023-09-22每日一题 一、题目编号 2591. 将钱分给最多的儿童二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数 money ,表示你总共有的钱数(单位为美元)和另一个整数 children ,表示你要将钱分配给多少个儿童。 你…...

功能测试的重要性
前言 在软件开发领域,功能测试是确保软件质量的关键步骤之一。正如其名称所示,功能测试是验证软件产品是否具有其描述的功能和符合预期结果的过程。这种类型的测试非常重要,因为它不仅可以帮助团队检测潜在的缺陷并提高软件品质,…...

《Linux高性能服务器编程》--高级I/O函数
目录 1--Pipe() 2--dup() 和 dup2() 3--readv() 和 writev() 4--sendfile() 5--mmap() 和 munmap() 6--spice() 7--tea() 8--fcntl() 1--Pipe() #include <unistd.h> int pipe(int fd[2]); // 成功返回0,失败返回-1 pipe() 函数可用于创建一个管道&a…...
算法通关村 | 透彻理解动态规划
1. 斐波那契数列 1,1,2,3,5,8,13,..... f(n) f(n-1) f(n-2) 代码实现 public static int count_2 0;public int fibonacci(int n){if (n < 2){count_2;return n;}int f1 1;int f2 2;i…...
)
数据结构(持续更新)
嗯,怎么说数据结构果然很玄妙。按照能不能存储多行元素大致分为两类。 不能存好几行的数据包括pair,int,float,double,char,struct; 能存好几行的:map,unordered_map,list,vector,set,string,array。 1. pair “pair” 是 C++ 标准库中的一个模板类,它用于存储…...
nginx部署vue后显示500 Internal Server Error解决方案
前言 描述:当我配置好全部之后,通过 服务器 ip 地址访问,遇到报错信息:500 Internal Server Error。 今天部署vue前端项目一直报错500,无法显示出主页面。 一个以为是自己的dist位置没有访问正确或者nginx.conf的位…...

微调大型语言模型(一):为什么要微调(Why finetune)?
今天我们来学习Deeplearning.ai的在线课程 微调大型语言模型(一)的第一课:为什么要微调(Why finetune)。 我们知道像GPT-3.5这样的大型语言模型(LLM)它所学到的知识截止到2021年9月,那么如果我们向ChatGPT询问2022年以后发生的事情,它可能会…...

【GO】网络请求例子
post请求;multipart/form-data类型 // 构建请求参数requestData : map[string]interface{}{"gb": "","code": "","reMemberInfo": map[string]interface{}{"shi": "","…...

泡泡玛特海外布局动作不断,开启东南亚潮玩盛会
近日,泡泡玛特海外布局动作不断,9月8日至10日,泡泡玛特2023 PTS潮流玩具展(下简称新加坡PTS)在新加坡滨海湾金沙成功举办,现场人气爆棚,三天吸引了超过2万观众入场,这也是泡泡玛特首…...
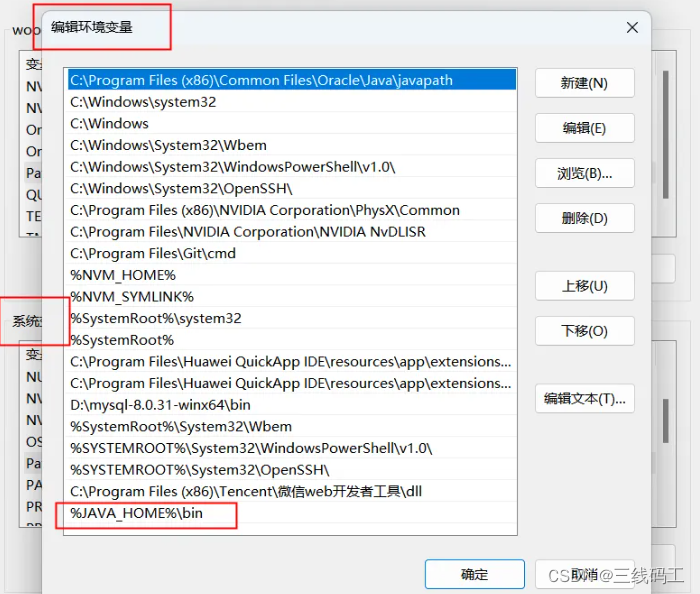
uniappAndroid平台签名证书(.keystore)生成
一、安装JRE环境 https://www.oracle.com/java/technologies/downloads/#java8 记住下载默认安装地址。ps:我都默认安装地址C:\Program Files\Java\jdk-1.8 二、安装成功后配置环境变量 系统变量配置 AVA_HOME 放到环境变量去 %JAVA_HOME%\bin 三、生成签名证书…...
Gateway学习和源码解析
文章目录 什么是网关?搭建实验项目demo-servicegateway-service尝试简单上手 路由(Route)断言(Predicate)和断言工厂(Predicate Factory)gateway自带的断言工厂After(请求必须在某个…...
移动机器人运动规划 --- 基于图搜索的Dijkstra算法
移动机器人运动规划 --- 基于图搜索的Dijkstra算法 Dijkstra 算法Dijkstra 算法 伪代码流程Dijkstra 算法步骤示例Dijkstra算法的优劣分析 Dijkstra 算法 Dijkstra 算法与BFS算法的区别就是 : 从容器中弹出接下来要访问的节点的规则不同 BFS 弹出: 层级最浅的原则,…...

Mybatis SQL构建器
上一篇我们介绍了在Mybatis映射器中使用SelectProvider、InsertProvider、UpdateProvider、DeleteProvider进行对数据的增删改查操作;本篇我们介绍如何使用SQL构建器在Provider中优雅的构建SQL语句。 如果您对在Mybatis映射器中使用SelectProvider、InsertProvider…...
怎么将几张图片做成pdf合在一起
怎么将几张图片做成pdf合在一起?在我们平时的工作中,图片和pdf都是非常重要的电脑文件,使用也非常频繁,图片能够更为直观的展示内容,而pdf则更加的正规,很多重要文件大多会做成pdf格式的。在职场人的日常工…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...
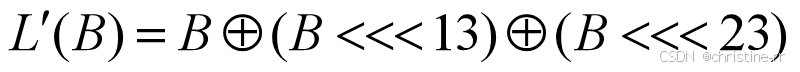
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...

CSS 工具对比:UnoCSS vs Tailwind CSS,谁是你的菜?
在现代前端开发中,Utility-First (功能优先) CSS 框架已经成为主流。其中,Tailwind CSS 无疑是市场的领导者和标杆。然而,一个名为 UnoCSS 的新星正以其惊人的性能和极致的灵活性迅速崛起。 这篇文章将深入探讨这两款工具的核心理念、技术差…...
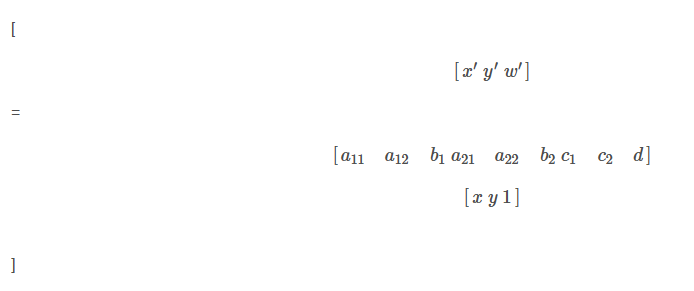
使用python进行图像处理—图像变换(6)
图像变换是指改变图像的几何形状或空间位置的操作。常见的几何变换包括平移、旋转、缩放、剪切(shear)以及更复杂的仿射变换和透视变换。这些变换在图像配准、图像校正、创建特效等场景中非常有用。 6.1仿射变换(Affine Transformation) 仿射变换是一种…...