Kafka 面试题
Kafka 面试题
Q:讲一下Kafka。
Kafka 入门一篇文章就够了
Kafka的简单理解
Q:消息队列,有哪些使用场景及用途?
解耦,削峰,限流。
Q:Kafka相对其他消息队列,有什么特点?
持久化:Kafka的持久化能力比较好,通过磁盘持久化。而RabbitMQ是通过内存持久化的。
吞吐量:Rocket的吞吐量非常高。Kafka的吞吐量也特别高。基本都是单机十万级别。
消息处理:RabbitMQ的消息不支持批量处理,而RocketMQ和Kafka支持批量处理。
高可用:RabbitMQ采用主从模式。Rocket支持多主多从。Kafka基于Replication多副本,ISR,选举Leader。
低延时:Kafka生产和消费的延时都很低,是毫秒级别的。
事务:RocketMQ支持事务消息,而Kafka和RabbitMQ不支持。
详情见: https://www.cnblogs.com/expiator/p/10023649.html
Q:Kafka有哪些缺点?
- 无法弹性扩容:对partition的读写都在partition leader所在的broker,如果该broker压力过大,也无法通过新增broker来解决问题;
- 扩容成本高:集群中新增的broker只会处理新topic,如果要分担老topic-partition的压力,需要手动迁移partition,这时会占用大量集群带宽;
- partition过多会使得性能显著下降。broker上partition过多让磁盘顺序写几乎退化成随机写。
- kafka不支持事务消息。
参考资料: https://blog.csdn.net/zjjcchina/article/details/122359951
Q:Kafka有哪些模式?
如果一个生产者或者多个生产者产生的消息能够被多个消费者同时消费的情况,这样的消息队列称为"发布订阅模式"的消息队列
Q:Kafka作为消息队列,有哪些优势?
分布式的消息系统。
高吞吐量。即使存储了许多TB的消息,它也保持稳定的性能。
数据保留在磁盘上,因此它是持久的。
Q:kafka的吞吐量为什么高?Kafka为什么处理速度会很快?
零拷贝:Kafka 实现了"零拷贝"原理来快速移动数据,避免了内核之间的切换。
消息压缩、分批发送:Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。
批处理能够进行更有效的数据压缩并减少 I/O 延迟。
页缓存:页缓存是操作系统实现的一种主要磁盘缓存,用来减少对磁盘I/O的操作。
顺序读写:Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费。顺序写入磁盘,比随机写入快很多倍。
详情见: https://mp.weixin.qq.com/s/iJJvgmwob9Ci6zqYGwpKtw
Q:讲一下页缓存
页缓存是操作系统实现的一种主要磁盘缓存,用来减少对磁盘I/O的操作。
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页(page)是否在页缓存(page cache)中,如果存在(命中)则直接返回数据,从而避免了对物理磁盘的I/O操作。
如果没有命中,则操作系统会向磁盘发起读取请求并将读取到的数据页存入页缓存,之后再将数据返回给进程。
同样的,如果一个进程需要将数据写入到磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
参考资料:《深入理解kafka:核心设计与实践原理》
Q:讲一下Kafka中的零拷贝。
传统的IO流程包括read以及write的过程
read:将数据从磁盘读取到内核缓存区中,在拷贝到用户缓冲区
write:先将数据写入到socket缓冲区中,最后写入网卡设备
数据的拷贝整个过程耗费的时间比较高。
而零拷背利用了Linux的sendFile技术。
sendfile表示在两个文件描述符之间传输数据,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作,从内核缓冲区就发到socket缓冲区,省去了进程切换和一次数据拷贝,性能变得更好。
Q:讲下kafka的三种语义
「消息传递语义」就是 Kafka 提供的 Producer 和 Consumer 之间的消息传递过程中消息传递的保证性。
-
至少一次:at-least-once
这种语义有可能会对数据重复处理。
(1): 设置enable.auto.commit为false,禁用自动提交offset
(2): 消息处理完之后手动调用consumer.commitSync()提交offset
这种方式是在消费数据之后,手动调用函数consumer.commitSync()异步提交offset,有可能处理多次的场景是消费者的消息处理完并输出到结果库,但是offset还没提交,这个时候消费者挂掉了,再重启的时候会重新消费并处理消息,所以至少会处理一次 -
至多一次:at-most-once
这种语义有可能会丢失数据。
至多一次消费语义是kafka消费者的默认实现。
(1): enable.auto.commit设置为true。
(2): auto.commit.interval.ms设置为一个较低的时间范围。
由于上面的配置,此时kafka会有一个独立的线程负责按照指定间隔提交offset。
消费者的offset已经提交,但是消息还在处理中(还没有处理完),这个时候程序挂了,导致数据没有被成 功处理,再重启的时候会从上次提交的offset处消费,导致上次没有被成功处理的消息就丢失了。 -
仅一次:exactly-once
这种语义可以保证数据只被消费处理一次。
(1): 将enable.auto.commit设置为false,禁用自动提交offset
(2): 使用consumer.seek(topicPartition,offset)来指定offset
(3): 在处理消息的时候,要同时保存住每个消息的offset。
以原子事务的方式保存offset和处理的消息结 果,这个时候相当于自己保存offset信息了,把offset和具体的数据绑定到一块,数据真正处理成功的时 候才会保存offset信息。
这样就可以保证数据仅被处理一次了。
参考资料:https://blog.csdn.net/lt326030434/article/details/119881907
kafka生产者
Q:Kafka的生产者,是如何发送消息的?
生产者的消息是先被写入分区中的缓冲区中,然后分批次发送给 Kafka Broker。
异步发送消息的同时能够对异常情况进行处理,生产者提供了Callback 回调。
Q:Kafka生产者发送消息,有哪些分区策略?
Kafka 的分区策略指的就是将生产者发送到哪个分区的算法。
有顺序轮询、随机轮询、key-ordering 策略。
编写一个类实现org.apache.kafka.clients.Partitioner接口。实现内部两个方法:partition()和close()。然后显式地配置生产者端的参数partitioner.class
常见的策略:
轮询策略(默认)。保证消息最大限度地被平均分配到所有分区上。
随机策略。随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
按key分区策略(key-ordering 策略)。key可能是uid或者订单id,将同一标志位的所有消息都发送到同一分区,这样可以保证一个分区内的消息有序。
Kafka 中每条消息都会有自己的key,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
其他分区策略。如:基于地理位置的分区策略。
Kafka broker
Q:Kafka为什么要分区?
实现负载均衡和水平扩展。
Kafka可以将主题(Topic)划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。
Q:Kafka,是如何在Broker间分配分区的?
- 在broker间平均分布分区副本;
假设有6个broker,打算创建一个包含10个分区的Topic,复制系数为3,那么Kafka就会有30个分区副本,它可以被分配给这6个broker,这样的话,每个broker可以有5个副本。 - 要确保每个分区的每个副本分布在不同的broker上面;
假设Leader分区0会在broker1上面,Leader分区1会在broker2上面,Leder分区2会在broker3上面。
接下来会分配跟随者副本。如果分区0的第一个Follower在broker2上面,第二个Follower在broker3上面。
分区1的第一个Follower在broker3上面,第二个Follower在broker4上面。。
顺序性
Q:Kafka如何保证消息的顺序性?
Kafka 可以保证同一个分区里的消息是有序的。也就是说消息发送到一个Partition 是有顺序的。
Q:Kafka多个分区,如何保证消息的顺序性?
生产者在发消息的时候指定partition key,kafka对其进行hash计算,根据计算结果决定放入哪个partition。这样partition key计算结果相同的消息会放在同一个partition。此时,partition数量仍然可以设置多个,提升topic的整体吞吐量。
kafka消费者
Q:你们的kafka有多少个分区?有多少个消费者?有多少个服务实例?
有5个分区,5个消费者。
分区和消费者的数量相等最好。不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置。
Q:kafka 消费者的消费策略有哪些?
Kafka 有四种主流的分区分配策略: Range 、 RoundRobin 、 Sticky 、 CooperativeSticky 。
可以通过配置参数 partition.assignment.strategy ,修改分区的分配策略。默认策略是 Range + CooperativeSticky 。 Kafka 可以同时使用 多个分区分配策略。
- Range 按顺序。
分区有0-6,消费者有0-2,那么每个消费者分7/3=2个分区,剩下的按序分配。
消费者0:P0,P1,P2
消费者1:P3,P4
消费者2:P5,P6
如果消费者0挂了,
那么
消费者1:0,1,2,3
消费者2:4,5,6
缺点:大数据环境容易产生数据倾斜。
- RoundRobin: 轮询排序
- Sticky:粘性分区。
再分区的尽量少的去改变旧的分配方案。
举个例子,现在的分区方案:
C0:P0,P1,P2
C1:P3,P4
C2:P5,P6
消费者C0挂了之后,
C1:P0,P1,P3,P4
C2:P5,P6,P2
range是按序分配,而sticky是随机的。不一定就是012,34,56
尽量均匀可以减少再分区的开销。 - CooperativeSticky多种配合使用
参考资料: https://blog.csdn.net/u011066470/article/details/124090278
Q:Kafka的偏移量是什么?
消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置。等到下次消费时,他会接着上次位置继续消费
Q:Kafka的消费者群组Consumer Group订阅了某个Topic,假如这个Topic接收到消息并推送,那整个消费者群组能收到消息吗?
http://kafka.apache.org/intro
Kafka官网中有这样一句"Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. "
表示推送到topic上的record,会被传递到已订阅的消费者群组里面的一个消费者实例。
Q:kafka出现消息积压,有哪些原因??怎么解决?如何提高Kafka的消费速度?
出现消息积压,可能是因为消费的速度太慢。
扩容消费者。之所以消费延迟大,就是消费者处理能力有限,可以增加消费者的数量。
扩大分区。一个分区只能被消费者群组中的一个消费者消费。消费者扩大,分区最好多随之扩大。
消费者重平衡
Q:讲一下kafka的 Rebalance(重平衡).重平衡有什么用?哪些场景下会发生重平衡?
分区的所有权从一个消费者转到其他消费者的行为称为重平衡。
新加入群组的消费者实例分摊了之前的消费者的部分分区消息。
或者消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区。
Rebalance 是 Kafka 消费者端实现高可用性、伸缩性的重要手段。
消费者通过向Kafka Broker发送心跳来维护自己是消费者组的一员并确认其拥有的分区。对于不同的消费群体来说,其组织协调者可以是不同的。只要消费者定期发送心跳,就会认为消费者是存活的并处理其分区中的消息。当消费者检索记录或者提交它所消费的记录时就会发送心跳。
如果过了一段时间 Kafka 停止发送心跳了,会话(Session)就会过期,组织协调者就会认为这个 Consumer 已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间里,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽量降低处理停顿。
消费失败
Q:kafka消费时,如果处理失败,怎么办?
先重试几次。如果重试还是不成功,可以根据业务选择:
- 处理失败的,放到死信队列(其他topic即可),不断重试。
- 处理失败的,记录到一张表里面,同时发送告警信息给开发人员。
- 处理失败的,如果是不重要的数据,直接跳过。(谨慎选择)
消息丢失
Q:讲一下Kafka的ack机制。
acks 参数指定了要有多少个分区副本接收消息,生产者才认为消息是写入成功的。此参数对消息丢失的影响较大。
如果 acks = 0,就表示生产者也不知道自己产生的消息是否被服务器接收了,它才知道它写成功了。如果发送的途中产生了错误,生产者也不知道,它也比较懵逼,因为没有返回任何消息。这就类似于 UDP 的运输层协议,只管发,服务器接受不接受它也不关心。
如果 acks = 1,只要集群的 Leader 接收到消息,就会给生产者返回一条消息,告诉它写入成功。如果发送途中造成了网络异常或者 Leader 还没选举出来等其他情况导致消息写入失败,生产者会受到错误消息,这时候生产者往往会再次重发数据。因为消息的发送也分为 同步 和 异步,Kafka 为了保证消息的高效传输会决定是同步发送还是异步发送。如果让客户端等待服务器的响应(通过调用 Future 中的 get() 方法),显然会增加延迟,如果客户端使用回调,就会解决这个问题。
如果 acks = all,这种情况下是只有当所有参与复制的节点都收到消息时,生产者才会接收到一个来自服务器的消息。不过,它的延迟比 acks =1 时更高,因为我们要等待不只一个服务器节点接收消息。
参考资料: https://juejin.im/post/5ddf5659518825782d599641
Q:Kafka如何避免消息丢失?如何保证消息的可靠性传输?
1.生产者丢失消息的情况:
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。
可以采用为其添加回调函数的形式,获取回调结果。
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
可以设置 Producer 的retries(重试次数)为一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。
设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。
2.消费者丢失消息的情况:
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,
试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
手动关闭闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset 。
3.Kafka丢失消息:
a.假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被
follower 副本的同步的话,就会造成消息丢失。
因此可以设置ack=all。
b.设置 replication.factor >= 3
为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 replication.factor >= 3。这样就可以保证每个
分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
c.设置min.insync.replicas >=2。最小同步副本数。对于一个包含3个副本的主题,如果min.insync.replicas设置为2,那么至少要存在两个同步副本才能向分区写入数据。
如果2个副本不可用,那么broker就会停止接受生产者的请求,尝试发送数据的生产者会收到异常。
详情参考:《kafka权威指南》第六章。可靠的数据传递。
https://blog.csdn.net/qq_34337272/article/details/104903388?fps=1&locationNum=2
Q:Kafka写入的数据如何保证不丢失?kafka的数据写到主节点后,还没来得及复制,就挂掉了,那数据会丢失么?
所以如果要让写入Kafka的数据不丢失,你需要要求几点:
(1)每个Partition都至少得有1个Follower在ISR列表里,跟上了Leader的数据同步。
最小同步副本数 min.insync.replicas
最小同步副本数, 表示的是 ISR 列表里面最小的同步副本个数,默认是=1。
这个配置再加上 acks=-1/all 可以设置高可靠性了。
特别需要注意:这个配置是用来设置同步副本个数的下限的, 并不是只有 min.insync.replicas 个副本同步成功就返回ack。
只要你acks=-1/all 就意味着你ISR里面的副本必须都要同步成功。
(2)每次写入数据的时候,都要求至少写入Partition Leader成功,同时还有至少一个ISR里的Follower也写入成功,才算这个写入是成功了。
(3)如果不满足上述两个条件,那就一直写入失败,让生产系统不停的尝试重试,直到满足上述两个条件,然后才能认为写入成功
按照上述思路去配置相应的参数,才能保证写入Kafka的数据不会丢失。
需要保证,每次写数据,必须是leader和follower都写成功了,才能算是写成功,保证一条数据必须有两个以上的副本。
这个时候万一leader宕机,就可以切换到那个follower上去,那么Follower上是有刚写入的数据的,此时数据就不会丢失了。
详情见: https://juejin.cn/post/6844903790789787655
https://mp.weixin.qq.com/s/CXrvy7Moj2ElPm_CJ-gH2A
可靠性、副本
Q:Kafka怎么保证可靠性?高可用?
多副本,以及ISR机制。
在Kafka中主要通过ISR机制来保证消息的可靠性。
ISR(in sync replica):是Kafka动态维护的一组同步副本,在ISR中有成员存活时,只有这个组的成员才可以成为leader,内部保存的为每次提交信息时必须同步的副本(acks = all时),每当leader挂掉时,在ISR集合中选举出一个follower作为leader提供服务,当ISR中的副本被认为坏掉的时候,会被踢出ISR,当重新跟上leader的消息数据时,重新进入ISR。
详情见: https://www.jianshu.com/p/ebeaa7593d83
Q:讲一下kafka的副本机制,AR、ISR、OSR
(1)AR副本集合 (Assigned Replicas):分区Partition中的所有Replica组成AR副本集合。
(2)ISR副本集合(In Sync Replica):所有与Leader副本能保持一定程度同步的Replica组成ISR副本集合,其中也包括 Leader副本。
(3)OSR副本集合 (Out-of-Sync Replied) :与Leader副本同步滞后过多的Replica组成OSR副本集合。
Q:Kafka是读写分离的么?
不是的。
在Kafka中,一个Topic的每个Partition都有若干个副本,副本分成两类:领导者副本「Leader Replica」和追随者副本「Follower Replica」。每个分区在创建时都要选举一个副本作为领导者副本,其余的 副本作为追随者副本。
在Kafka中,Follower副本是不对外提供服务的。也就是说,任何一个Follower副本都不能响应客户端的 读写请求。
所有的读写请求都必须先发往Leader副本所在的Broker,由该Broker负责处理。Follower副本 不处理客户端请求,它唯一的任务就是从Leader副本异步拉取消息,并写入到自己的提交日志中,从而实现 与Leader副本的同步。
Q:什么是HW?
HW(high watermark):副本的高水印值,replica中leader副本和follower副本都会有这个值,通过它可以得知副本中已提交或已备份消息的范围,leader副本中的HW,决定了消费者能消费的最新消息能到哪个offset。
HW: 即高水位,它标识了一个特定的消息偏移量offset,消费者只 能拉取到这个水位offset之前的消息。
Q:什么是LEO?
LEO(log end offset):日志末端位移,代表日志文件中下一条待写入消息的offset,这个offset上实际是没有消息的。不管是leader副本还是follower副本,都有这个值。
LEO:它标识当前日志文件中下一条待写入的消息的offset,在ISR 副本集合中的每个副本都会维护自身的LEO。
参考资料:https://www.cnblogs.com/youngchaolin/p/12641463.html
Q:Kafka怎么保证一致性?(存疑)
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到。
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
详情见:https://www.jianshu.com/p/f0449509fb11
重复消费
Q:Kafka怎么处理重复消息?怎么避免重复消费?
偏移量offset:消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置。等到下次消费时,他会接着上次位置继续消费。
一般情况下,kafka重复消费都是由于未正常提交offset造成的,比如网络异常,消费者宕机之类的。
把Kafka消费者的配置enable.auto.commit设为false,禁止Kafka自动提交offset,从而避免了提交失败而导致永远重复消费的问题。
怎么避免重复消费:将消息的唯一标识保存起来,每次消费时判断是否处理过即可。
Q:如何保证消息不被重复消费?(如何保证消息消费的幂等性)
怎么保证消息队列消费的幂等性?其实还是得结合业务来思考,有几个思路:
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下好吧。
比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
如果是复杂一点的业务,那么每条消息加一个全局唯一的 id,类似订单 id 之类的东西,然后消费到了之后,先根据这个 id 去比如 Redis 里查一下,之前消费过吗?
如果没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
参考资料:https://www.jianshu.com/p/8d1c242872a4
消息pull、push
Q:Kafka消息是采用pull模式,还是push模式?
生产者是push,而消费者是pull模式。
Q:pull模式和push模式,各有哪些特点?
push模式,即时性?可以在broker获取消息后马上送达消费者。
而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
消费者可以自行决定消费的速率、是否批量处理模式处理消息.
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会一直轮询,一直返回空数据。
针对这一点, Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费, consumer 会等待一段时间之后再返回。
低延时、高吞吐量
Q:针对 Kafka 线上系统, 你是如何进⾏调优的?
「吞吐量」和「延时」是⾮常重要的优化指标。
吞吐量 TPS:是指 Broker 端或 Client 端每秒能处理的消息数,越⼤越好。
延时:表示从 Producer 端发送消息到 Broker 端持久化完成到 Consumer 端成功消费之间的时间间隔。与吞吐量 TPS 相反,延时越短越好。
总之,⾼吞吐量、低延时是我们调优 Kafka 集群的主要⽬标。
Q:针对 Kafka 线上系统, 如何降低延时?
降低延时的⽬的就是尽量减少端到端的延时。
调整 Producer 端和 Consumer 端的参数配置。
对于 Producer 端,此时我们希望可以快速的将消息发送出去,必须设置 linger.ms=0,同时关闭压缩,另外设置 acks = 1,减少副本同步时间。
⽽对于 Consumer 端我们只保持 fetch.min.bytes=1 ,即 Broker 端只要有能返回的数据,就⽴即返回给 Consumer,减少延时。
linger.ms:表示批次缓存时间,如果数据迟迟未达到batch.size,sender 等待 linger.ms 之后就会发送数据。单位 ms,默认值是 0,意思就是消息必须立即被发送。
如果设置的太短,会导致频繁网络请求,吞吐量下降;
如果设置的太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
所以适当增加会提高吞吐量,建议10~100毫秒。
fetch.min.bytes:表示只要 Broker 端积攒了多少数据,就可以返回给 Consumer 端。默认值1字节,适当增加该值为1kb或者更多。
存储
Q:Kafka是如何存储消息的?
Kafka使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。
Kafka中存储的一般都是海量的消息数据,为了避免日志文件过大,
一个分片并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录。
数据存储设计的特点在于以下几点:
(1)Kafka把主题中一个分区划分成多个分段的小文件段,通过多个小文件段,就容易根据偏移量查找消息、定期清除和删除已经消费完成的数据文件,减少磁盘容量的占用;
(2)采用稀疏索引存储的方式构建日志的偏移量索引文件,并将其映射至内存中,提高查找消息的效率,同时减少磁盘IO操作;
(3)Kafka将消息追加的操作逻辑变成为日志数据文件的顺序写入,极大的提高了磁盘IO的性能;
参考:https://www.jianshu.com/p/3e54a5a39683
参考资料:https://blog.csdn.net/zhangxm_qz/article/details/87636094
Q:讲一下Kafka集群的Leader选举机制。
Kafka在Zookeeper上针对每个Topic都维护了一个ISR(in-sync replica—已同步的副本)的集合,集合的增减Kafka都会更新该记录。如果某分区的Leader不可用,Kafka就从ISR集合中选择一个副本作为新的Leader。
Q:在 Kafka 中 Zookeeper 作⽤是什么?
ZooKeeper,主要⽤来「负责 Kafka集群元数据管理,集群协调⼯作」,在每个 Kafka 服务器启动的时候去连接并将⾃⼰注册到 Zookeeper,类似注册中⼼
Kafka 使⽤ Zookeeper 存放「集群元数据」、「集群成员管理」、 「Controller 选举」、「其他管理类任务」等。
1)集群元数据:Topic 对应 Partition 的所有数据都存放在 Zookeeper 中,且以 Zookeeper 保存的数据为准。
2)集群成员管理:Broker 节点的注册、删除以及属性变更操作等。主要包括两个⽅⾯:成员数量的管理,主要体现在新增成员和移除现有成员;单个成员的管理,如变更单个 Broker 的数据等。
3)Controller 选举:即选举 Broker 集群的控制器 Controller。其实它除了具有⼀般 Broker 的功能之外,还具有选举主题分区 Leader 节点的功能。在启动 Kafka系统时,其中⼀个 Broker 会被选举为控制器,负责管理主题分区和副本状态,还会执⾏分区重新分配的管理任务。如果在 Kafka 系统运⾏过程中,当前的控制器出现故障导致不可⽤,那么 Kafka 系统会从其他正常运⾏的 Broker 中重新选举出新的控制器。
4)其他管理类任务:包括但不限于 Topic 的管理、参数配置等等。
Q:Kafka 3.X 「2.8版本开始」为什么移除 Zookeeper 的依赖?
1)集群运维层⾯:Kafka 本身就是⼀个分布式系统,如果还需要重度依赖 Zookeeper,集群运维成本和系统复杂度都很⾼。
2)集群性能层⾯:Zookeeper 架构设计并不适合这种⾼频的读写更新操作, 由于之前的提交位移的操作都是保存在 Zookeeper ⾥⾯的,这样的话会严重影响 Zookeeper 集群的性能。
参考资料:
https://juejin.cn/post/6844903790789787655
《kafka面试连环炮》
《kafka权威指南》
《深入理解kafka:核心设计与实践原理》
相关文章:

Kafka 面试题
Kafka 面试题 Q:讲一下Kafka。 Kafka 入门一篇文章就够了 Kafka的简单理解 Q:消息队列,有哪些使用场景及用途? 解耦,削峰,限流。 Q:Kafka相对其他消息队列,有什么特点? 持久化:Kafka的持久化…...
离线部署 python 3.x 版本
文章目录 离线部署 python 3.x 版本1. 下载版本2. 上传到服务器3. 解压并安装4. 新建软连信息5. 注意事项 离线部署 python 3.x 版本 1. 下载版本 python 各版本下载地址 本次使用版本 Python-3.7.0a2.tgz # linux 可使用 wget 下载之后上传到所需服务器 wget https://www.py…...

Java 获取豆瓣电影TOP250
对于爬虫,Java并不是最擅长的,但是也可以实现,此次主要用到的包有hutool和jsoup。 hutool是一个Java工具包,它简化了Java的各种API操作,包括文件操作、类型转换、HTTP、日期处理、JSON处理、加密解密等。它的目标是使…...
)
笔试面试相关记录(5)
(1)不包含重复字符的最长子串的长度 #include <iostream> #include <string> #include <map>using namespace std;int getMaxLength(string& s) {int len s.size();map<char, int> mp;int max_len 0;int left 0;int i …...
四、C#—变量,表达式,运算符(2)
🌻🌻 目录 一、表达式1.1 什么是表达式1.2 表达式的基本组成 二、运算符2.1 算术运算符2.1.1 使用 / 运算符时的注意事项2.1.2 使用%运算符时的注意事项 2.2 赋值运算符2.2.1 简单赋值运算符2.2.2 复合赋值运算符 2.3 关系运算符2.4 逻辑运算符2.4.1 逻辑…...
【WSN】基于蚁群算法的WSN路由协议(最短路径)消耗节点能量研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
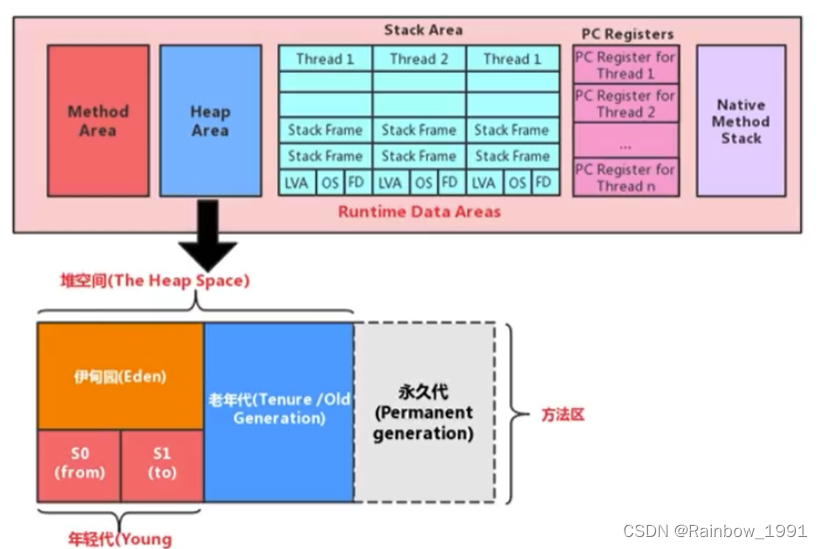
JVM的内存分配及垃圾回收
内存分配 在了解Java的内存管理前,需要知道JVM中的内存分配。 栈 存储局部变量。在方法的定义中或在方法中声明的变量为局部变量;栈内存中的数据在该方法结束(返回或抛出异常或方法体运行到最后)时自动释放栈中存放的数据结构为…...

Python实现查询一个文件中的pdf文件中的关键字
要求,查询一个文件中的pdf文件中的关键字,输出关键字所在PDF文件的文件名及对应的页数。 import os import PyPDF2def search_pdf_files(folder_path, keywords):# 初始化结果字典,以关键字为键,值为包含关键字的页面和文件名列表…...
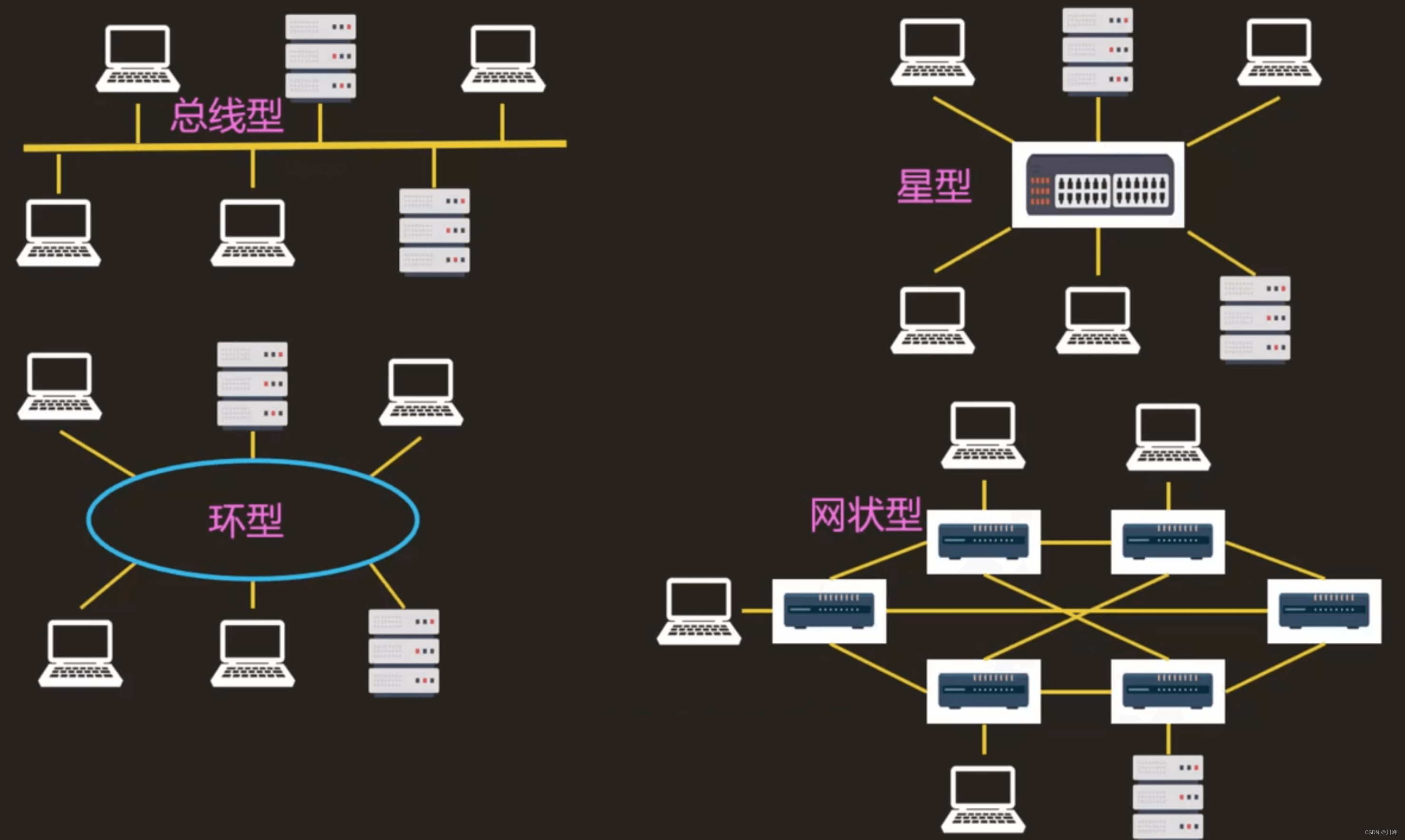
【计算机网络笔记一】网络体系结构
IP和路由器概念 两台主机如何通信呢? 首先,主机的每个网卡都有一个全球唯一地址,MAC 地址,如 00:10:5A:70:33:61 查看 MAC 地址: windows: ipconfig / alllinux:ifconfig 或者 ip addr 同一个网络的多…...

硕士应聘大专老师
招聘信息 当地人社局、学校(官方) 公众号(推荐): 辅导员招聘 厦门人才就业信息平台 高校人才网V 公告出完没多久就要考试面试,提前联系当地院校,问是否招人。 校招南方某些学校会直接去招老师。…...

Gram矩阵
Gram矩阵如何计算 Gram 矩阵是由一组向量的内积构成的矩阵。如果你有一组向量 v 1 , v 2 , … , v n v_1, v_2, \ldots, v_n v1,v2,…,vn,Gram 矩阵 G G G 的元素 G i j G_{ij} Gij 就是向量 v i v_i vi 和向量 v j v_j vj 的内积。数学上&#x…...
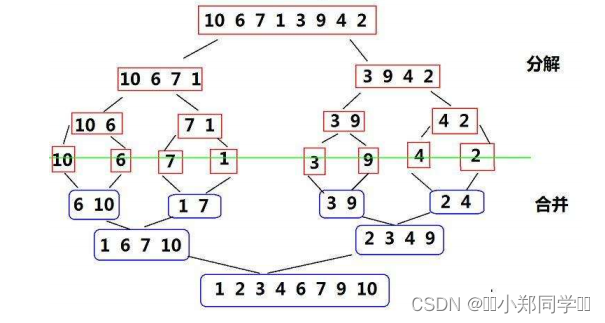
【数据结构】七大排序算法详解
目录 ♫什么是排序 ♪排序的概念 ♪排序的稳定性 ♪排序的分类 ♪常见的排序算法 ♫直接插入排序 ♪基本思想 ♪算法实现 ♪算法稳定性 ♪时间复杂度 ♪空间复杂度 ♫希尔排序 ♪基本思想 ♪算法实现 ♪算法稳定性 ♪时间复杂度 ♪空间复杂度 ♫直接选择排序 ♪基本思想 ♪算法…...

OpenCV之VideoCapture
VideoCaptrue类对视频进行读取操作以及调用摄像头。 头文件: #include <opencv2/video.hpp> 主要函数如下: 构造函数 C: VideoCapture::VideoCapture(); C: VideoCapture::VideoCapture(const string& filename); C: VideoCapture::Video…...

ESP32微控制器与open62541库: 详细指南实现OPC UA通信协议_C语言实例
1. 引言 在现代工业自动化和物联网应用中,通信协议起着至关重要的作用。OPC UA(开放平台通信统一架构)是一个开放的、跨平台的通信协议,被广泛应用于工业4.0和物联网项目中。本文将详细介绍如何在ESP32微控制器上使用C语言和open…...
怎样快速打开github.com
访问这个网站很慢是因为有DNS污染,被一些别有用心的人搞了鬼了, 可以使用火狐浏览器开启火狐浏览器的远程dns解析就可以了.我试了一下好像单独这个办法不一定有用,要结合修改hosts文件方法,双重保障 好像就可以了...

【C#】.Net基础语法二
目录 一、字符串(String) 【1.1】字符串创建和使用 【1.2】字符串其他方法 【1.3】字符串格式化的扩展方法 【1.4】字符串空值和空对象比较 【1.5】字符串中的转移字符 【1.6】大写的String和小写的string 【1.7】StringBuilder类的重要性 二、数组(Array) 【2.1】声…...

C++之this指针总结(二百二十)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

C++——如何正确的使用STL中的vector?
什么是vector? 在STL(标准模板库)中,vector是一种动态数组容器,可根据需要自动增长或缩小。它可以存储任意类型的元素,并且支持快速的随机访问。 vector是表示可变大小数组的序列容器vector采用的是连续的…...

【C语言】模拟实现内存函数
本篇文章目录 相关文章1. 模拟 memcpy 内存拷贝2. 模拟 memmove 内存移动 相关文章 【C语言】数据在内存中是以什么顺序存储的?【C语言】整数在内存中如何存储?又是如何进行计算使用的?【C语言】利用void*进行泛型编程【C语言】4.指针类型部…...

Jenkins学习笔记3
gitgithubjenkins: 架构图: 说明:jenkins知道github有更新了,就pull进行构建build,编译、自动化测试。然后部署到应用服务器。 maven java的项目构建工具。 在开发者电脑上创建空密码密钥对。 [rootgit-developer ~…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...
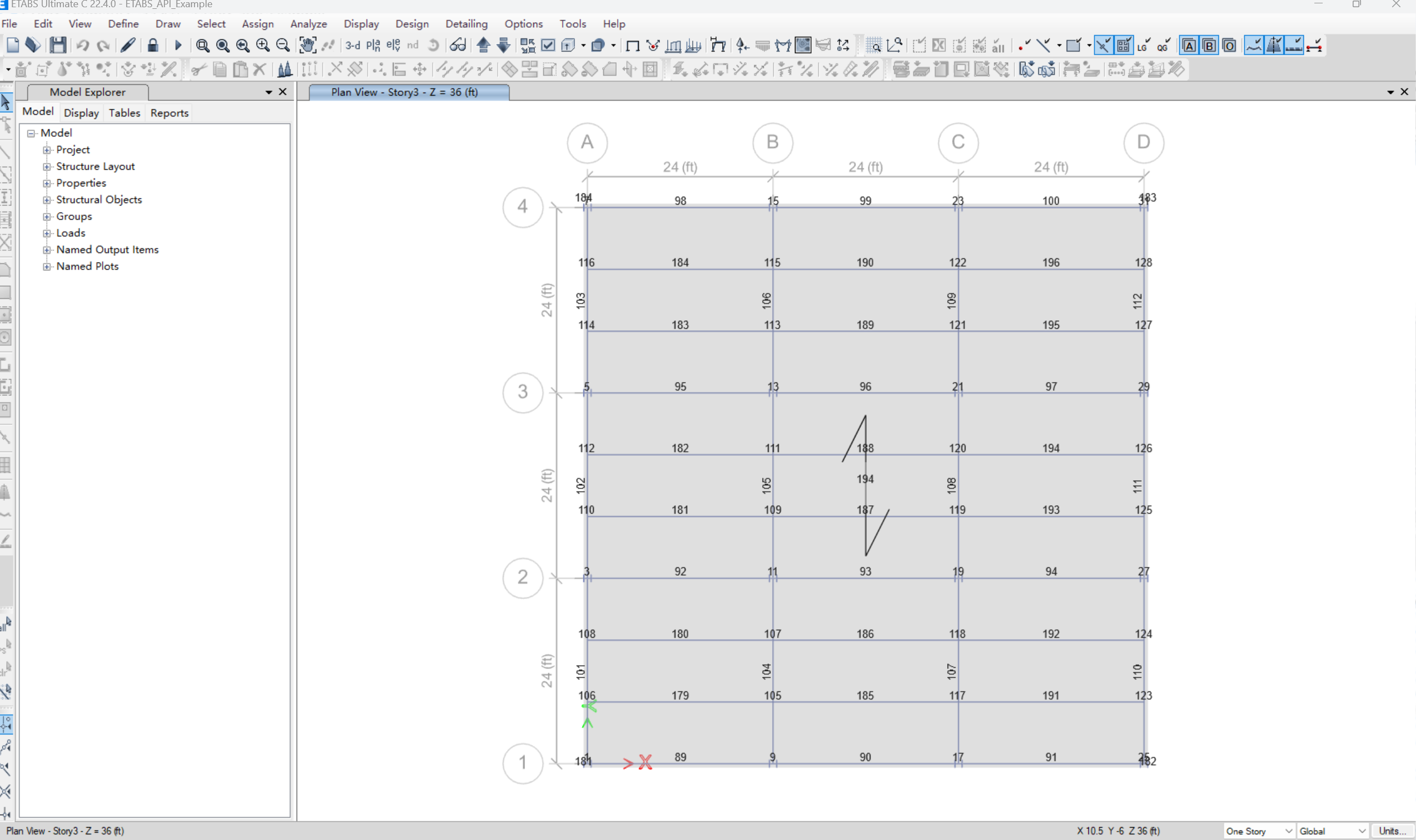
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...
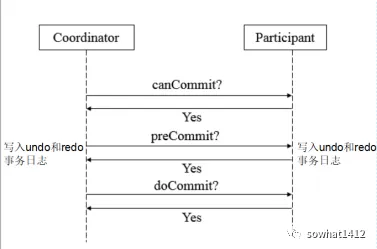
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...

CppCon 2015 学习:REFLECTION TECHNIQUES IN C++
关于 Reflection(反射) 这个概念,总结一下: Reflection(反射)是什么? 反射是对类型的自我检查能力(Introspection) 可以查看类的成员变量、成员函数等信息。反射允许枚…...
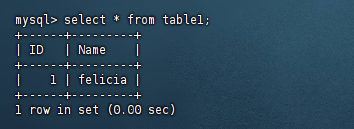
Linux入门(十五)安装java安装tomcat安装dotnet安装mysql
安装java yum install java-17-openjdk-devel查找安装地址 update-alternatives --config java设置环境变量 vi /etc/profile #在文档后面追加 JAVA_HOME"通过查找安装地址命令显示的路径" #注意一定要加$PATH不然路径就只剩下新加的路径了,系统很多命…...