【自然语言处理】主题建模:BERTopic(实战篇)
主题建模:BERTopic(实战篇)
BERTopic 是基于深度学习的一种主题建模方法。201820182018 年底,Devlinetal.Devlin\ et\ al.Devlin et al. 提出了 Bidirectional Encoder Representations from Transformers (BERT)[1]^{[1]}[1]。BERT 是一种用于 NLP 的预训练策略,它成功地利用了句子的深层语义信息[2]^{[2]}[2]。
1.加载数据
本次实验数据使用的是 fetch_20newsgroups 数据集。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))['data']
print(len(dataset)) # the length of the data
print(type(dataset)) # the type of variable the data is stored in
print(dataset[:2]) # the first instance of the content within the data

import pandas as pd
import numpy as np
# Creating a dataframe from the data imported
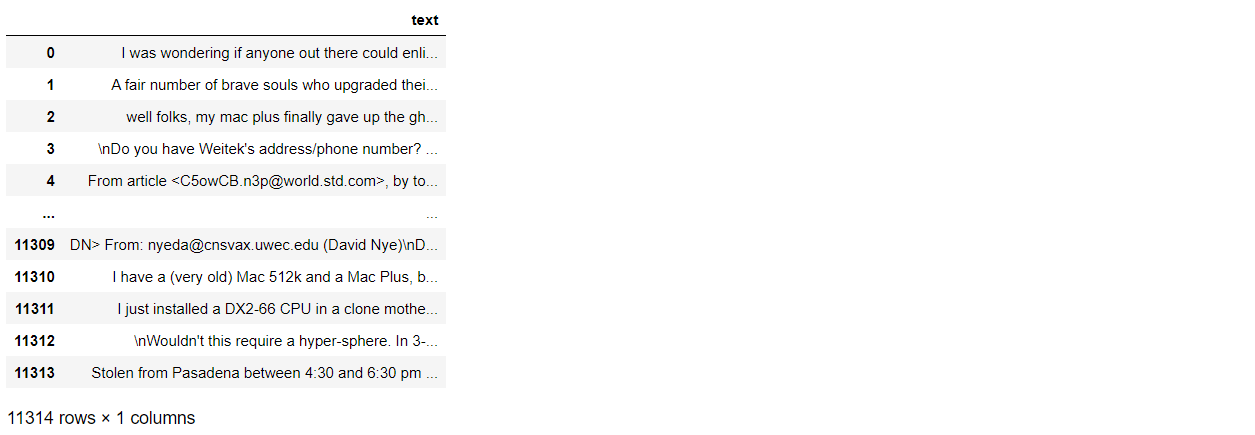
full_train = pd.DataFrame()
full_train['text'] = dataset
full_train['text'] = full_train['text'].fillna('').astype(str) # removing any nan type objects
full_train
2.数据预处理
对于英文文本来说,一般是经过 分词、词形还原、去除停用词 等步骤,但也不是必须的。
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
# If the following packages are not already downloaded, the following lines are needed
# nltk.download('wordnet')
# nltk.download('omw-1.4')
# nltk.download('punkt')filtered_text = []lemmatizer = WordNetLemmatizer()for i in range(len(full_train)):text = lemmatizer.lemmatize(full_train.loc[i,'text'])text = text.replace('\n',' ')filtered_text.append(text)filtered_text[:1]

3.BERTopic 建模
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
from umap import UMAP
from hdbscan import HDBSCAN
from bertopic.vectorizers import ClassTfidfTransformer

3.1 嵌入(Embeddings)
在 BERTopic 中,all-MiniLM-L6-v2 作为处理英文文本的默认嵌入模型,paraphrase-multilingual-MiniLM-L12-v2 提供对另外 505050 多种语言的嵌入支持。当然,Sentence-Transformers 还提供了很多其他的嵌入模型。
我们甚至可以不选择 Sentence-Transformers 提供的任何一种嵌入方法,而改用 Flair、Spacy、Gensim 等提供的嵌入方法,那么安装时候则需要选择:
pip install bertopic[flair]
pip install bertopic[gensim]
pip install bertopic[spacy]
注意:如果这些模型比较难下载,可以先从官网手动下载,再加载对应的路径即可。比如下面用到的 all-MiniLM-L6-v2 就是博主先手动下载到文件夹下的。
# Step 1 - Extract embeddings
embedding_model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
3.2 降维(Dimensionality Reduction)
除了利用默认的 UMAP 降维,我们还可以使用 PCA、Truncated SVD、cuML UMAP 等降维技术。
# Step 2 - Reduce dimensionality
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')
n_neighbors:此参数控制 UMAP 如何平衡数据中的局部结构与全局结构。值越小 UMAP 越专注于局部结构;值越大 UMAP 越专注于全局结构。n_components:该参数允许用户确定将嵌入数据的降维空间的维数。与其他一些可视化算法(例如t-SNE)不同,UMAP 在嵌入维度上具有很好的扩展性,不仅仅只能用于 222 维或 333 维的可视化。min_dist:该参数控制允许 UMAP 将点打包在一起的紧密程度。从字面上看,它提供了允许点在低维表示中的最小距离。值越小嵌入越密集。metric:该参数控制了如何在输入数据的环境空间中计算距离。
详情参见:https://umap-learn.readthedocs.io/en/latest/parameters.html
3.3 聚类(Clustering)
除了默认的 HDBSCAN,K-Means 聚类算法在原作者的实验上表现也非常好,当然也可以选择其他的聚类算法。
# Step 3 - Cluster reduced embeddings
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
min_cluster_size:影响生成的聚类的主要参数。理想情况下,这是一个相对直观的参数来选择:将其设置为你希望考虑集群的最小大小的分组。cluster_selection_method:该参数确定 HDBSCAN 如何从簇树层次结构中选择平面簇。默认方法是eom,表示 Excess of Mass。prediction_data:确保 HDBSCAN 在拟合模型时进行一些额外的计算,从而显著加快以后的预测查询速度。
详情参见:https://hdbscan.readthedocs.io/en/latest/parameter_selection.html
3.4 序列化(Tokenizer)
from sklearn.feature_extraction.text import CountVectorizer
# Step 4 - Tokenize topics
vectorizer_model = CountVectorizer(stop_words="english")
3.5 加权(Weighting scheme)
此处的加权是利用了基于 TF-IDF 改进的 c-TF-IDF,也可以使用基于类 BM25 的加权方案,或者对 TF 进行开方处理。
- Wx,c=∣∣tfx,c∣∣×log(1+Afx)W_{x,c}=||tf_{x,c}||×log(1+\frac{A}{f_x})Wx,c=∣∣tfx,c∣∣×log(1+fxA)
- 基于类
BM25的加权方案:log(1+A−fx+0.5fx+0.5)log(1+\frac{A-f_x+0.5}{f_x+0.5})log(1+fx+0.5A−fx+0.5) - 减少词频:∣∣tfx,c∣∣||\sqrt{tf_{x,c}}||∣∣tfx,c∣∣
注:我在《文本相似度算法:TF-IDF与BM25》这篇博客中详细介绍了 BM25 算法。
# Step 5 - Create topic representation
ctfidf_model = ClassTfidfTransformer()
4.训练模型
topic_model = BERTopic(embedding_model=embedding_model, # Step 1 - Extract embeddingsumap_model=umap_model, # Step 2 - Reduce dimensionalityhdbscan_model=hdbscan_model, # Step 3 - Cluster reduced embeddingsvectorizer_model=vectorizer_model, # Step 4 - Tokenize topicsctfidf_model=ctfidf_model, # Step 5 - Extract topic wordsdiversity=0.5, # Step 6 - Diversify topic wordsnr_topics=10
)
几个常用的参数:
diversity:是否使用MMR(Maximal Marginal Relevance,最大边际相关性)来多样化生成的主题表示。如果设置为None,则不会使用MMR。可接受的值介于 000 和 111 之间,000 表示完全不多样化,111 表示最多样化。nr_topics:指定主题数会将初始主题数减少到指定的值。这种减少可能需要一段时间,因为每次减少主题 (−1-1−1) 都会激活c-TF-IDF计算。如果将其设置为None,则不会应用任何减少。将其设置为‘auto’,则HDBSCAN自动减少主题。calculate_probabilities:默认为False。是否计算每篇文档所有主题的概率,而不是计算每篇文档指定主题的概率。如果文档较多(>100000> 100000>100000),这可能会减慢主题的提取速度。如果为False,则不能使用相应的可视化方法visualize_probabilities。
博主测试的训练时间大概是 101010 分钟。
topics, probabilities = topic_model.fit_transform(filtered_text)
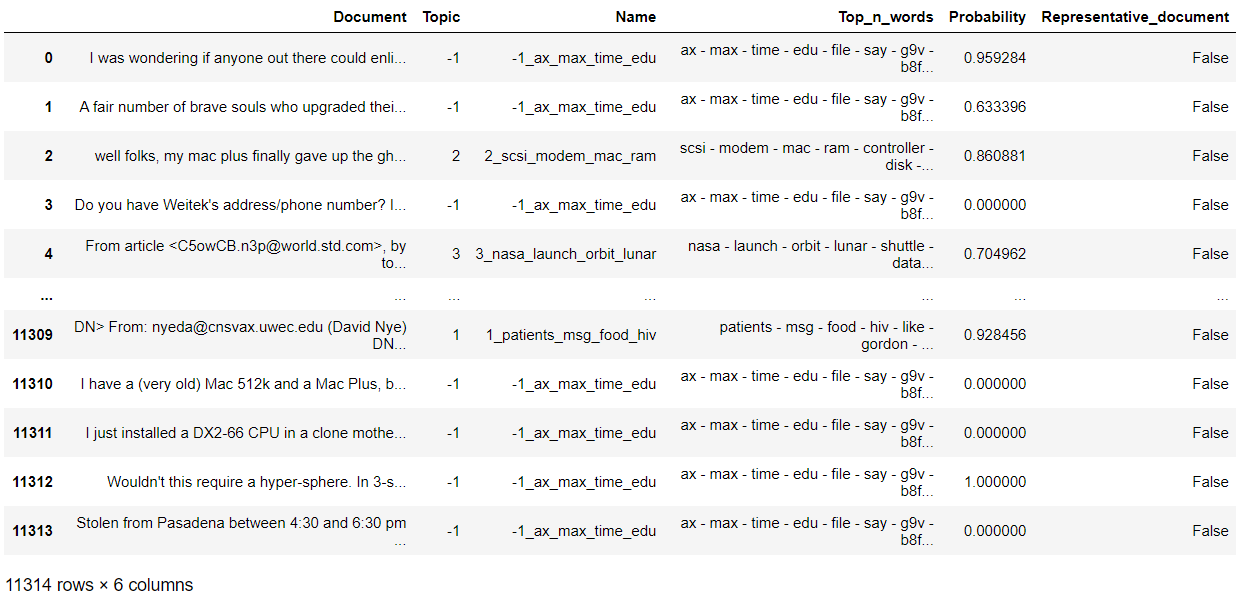
topic_model.get_document_info(filtered_text)
topic_model.get_topic_freq()

topic_model.get_topic(0)

5.可视化结果
BERTopic 提供了多种类型的可视化方法,以帮助我们从不同的方面评估模型。后续我会专门出一篇博客针对 BERTopic 中的可视化进行详细介绍,此处仅对一些常用的可视化方法进行总结。
5.1 Barchart
可视化所选主题的条形图。
topic_model.visualize_barchart()

5.2 Documents
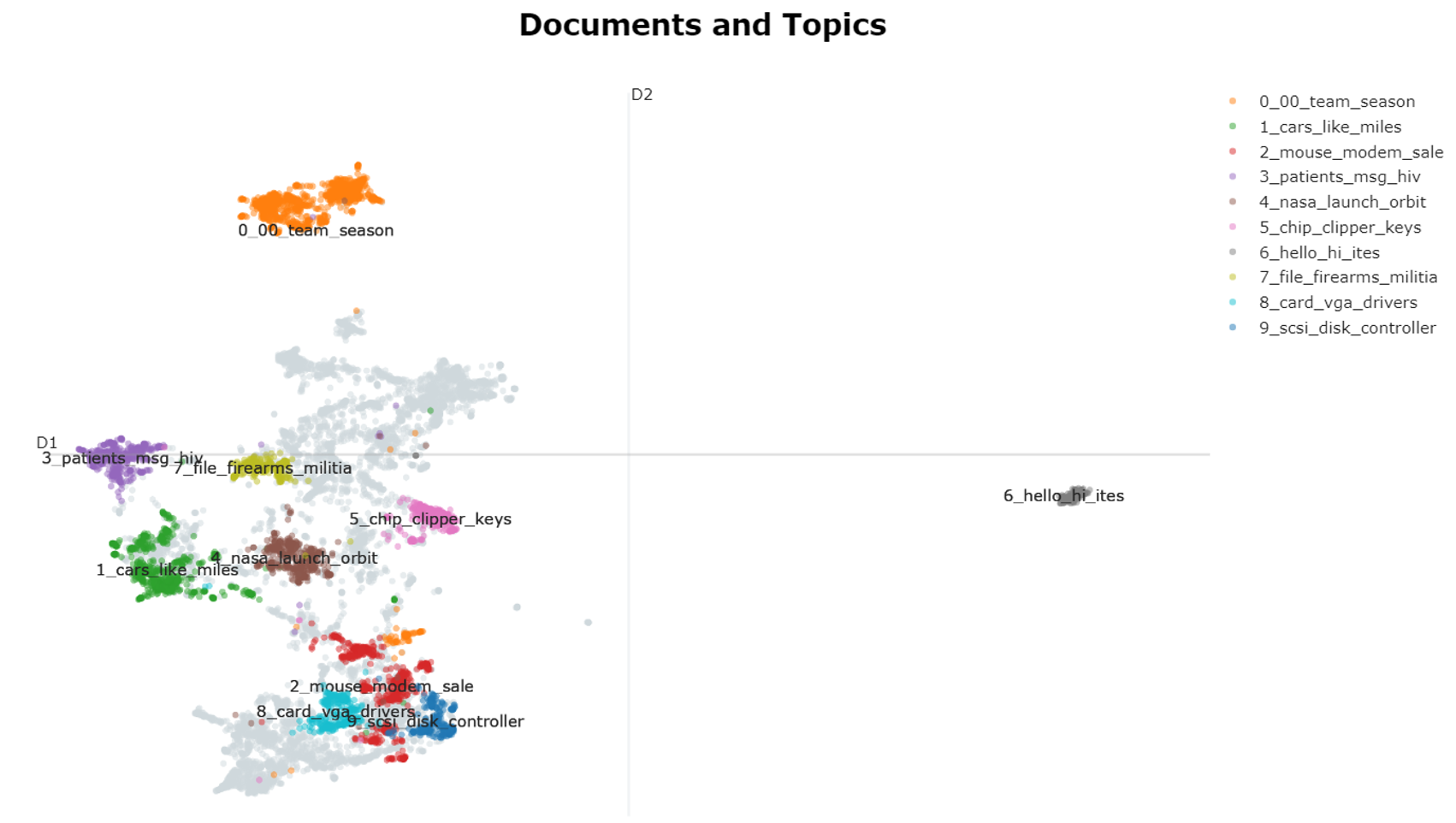
在 2D 中可视化文档及其主题。
embeddings = embedding_model.encode(filtered_text, show_progress_bar=False)# Run the visualization with the original embeddings
topic_model.visualize_documents(filtered_text, embeddings=embeddings)
5.3 Hierarchy Topics
基于主题嵌入之间的余弦距离矩阵执行层次聚类。
topic_model.visualize_hierarchy()
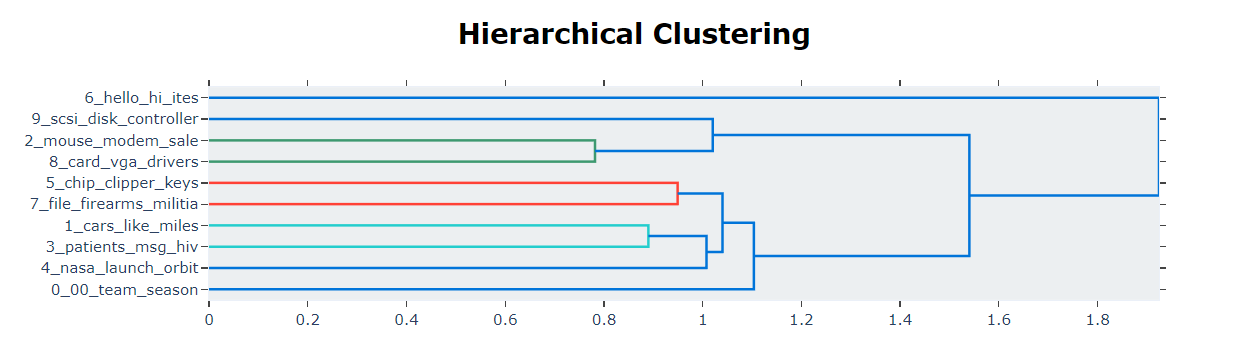
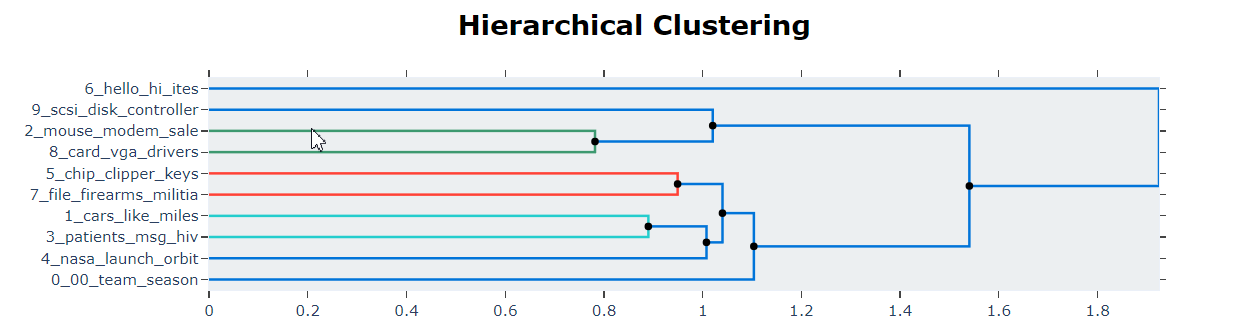
# Extract hierarchical topics and their representations
hierarchical_topics = topic_model.hierarchical_topics(filtered_text)# Visualize these representations
topic_model.visualize_hierarchy(hierarchical_topics=hierarchical_topics)
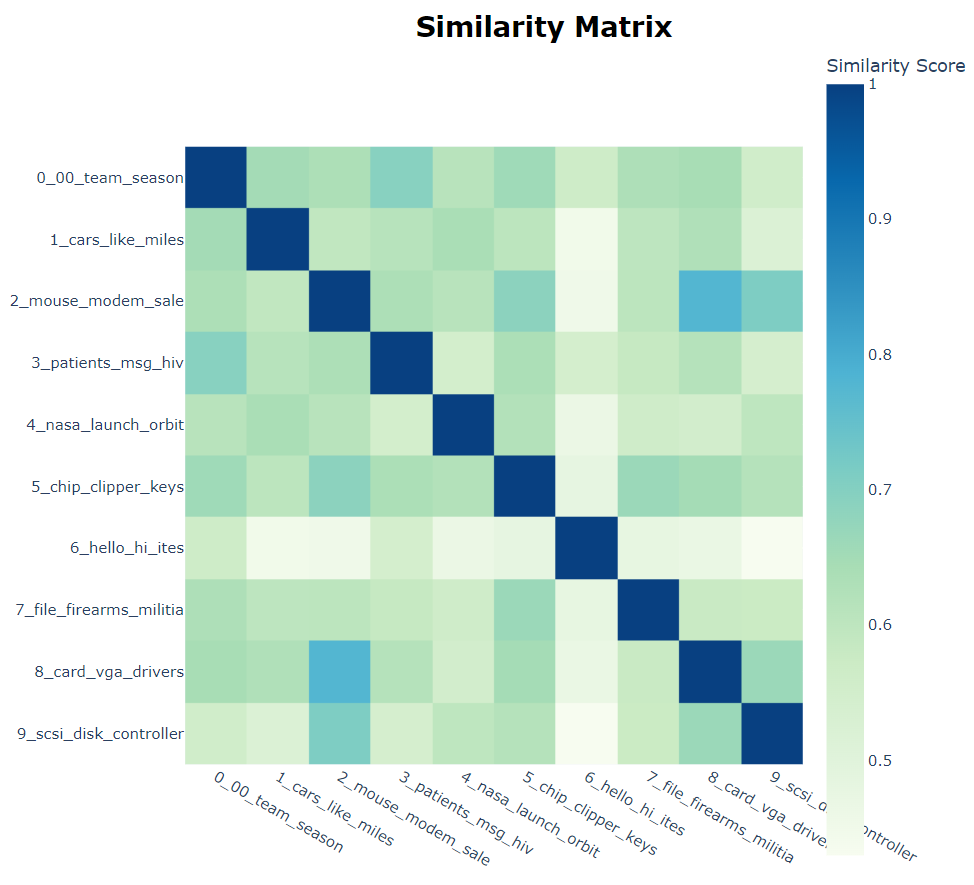
5.4 Heatmap
基于主题嵌入之间的余弦相似度矩阵,创建了一个热图来显示主题之间的相似度。
topic_model.visualize_heatmap()
5.5 Term Score Decline
每个主题都由一组单词表示。然而,这些词以不同的权重来代表主题。本可视化方法显示了需要多少单词来表示一个主题,以及随着单词的添加,增益在什么时候开始下降。
topic_model.visualize_term_rank()

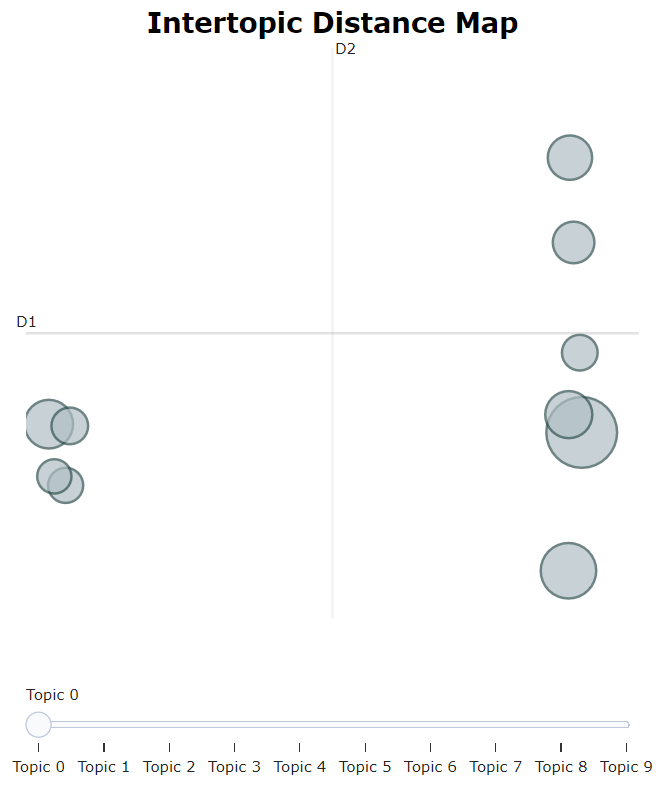
5.6 Topics
本可视化方法是受到了 LDAvis 的启发。LDAvis 是一种服务于 LDA 的可视化技术。
topic_model.visualize_topics()
6.评估
在 BERTopic 官网上并没有对评估这一块内容的介绍。但如果你想定量比较 LDA 和 BERTopic 的结果,则需要对评估方法加以掌握。
关于主题建模的评估方法,在我之前写的博客中也多次提到。可视化是一种良好的评估方法,但我们也希望以定量的方式对建模结果进行评估。主题连贯度(Topic Coherence)是最常用的评估指标之一。我们可以使用 Gensim 提供的 CoherenceModel 对结果进行进行评估。计算主题连贯度的方法很多,我们此处仅以 C_v 为例。
import gensim
import gensim.corpora as corpora
from gensim.models.coherencemodel import CoherenceModel
documents = pd.DataFrame({"Document": filtered_text,"ID": range(len(filtered_text)),"Topic": topics})
documents.head()

documents_per_topic = documents.groupby(['Topic'], as_index=False).agg({'Document': ' '.join})
documents_per_topic
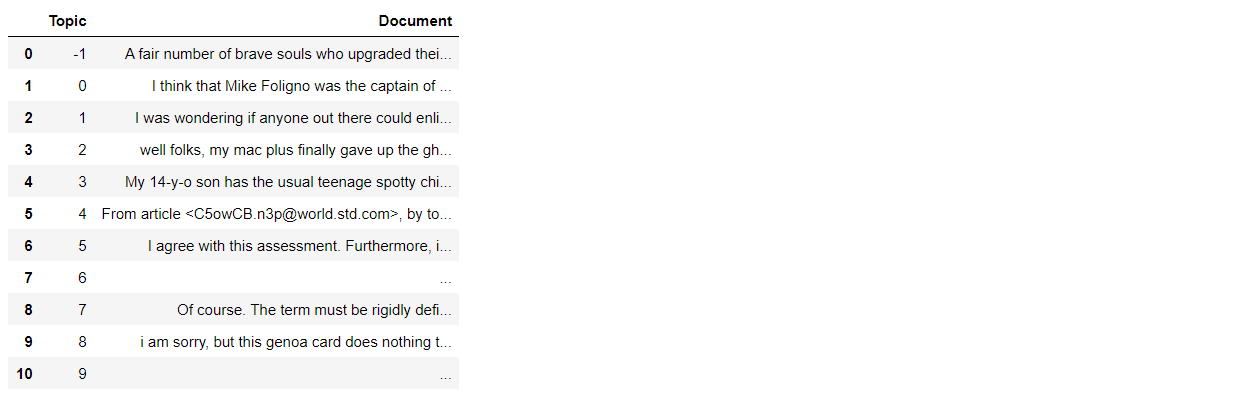
cleaned_docs = topic_model._preprocess_text(documents_per_topic.Document.values)
# Extract vectorizer and analyzer from BERTopic
vectorizer = topic_model.vectorizer_model
analyzer = vectorizer.build_analyzer()
下面的内容主要涉及到 Gensim 中模型的使用,在我之前的博客中也有详细介绍,此处不再赘述。
# Extract features for Topic Coherence evaluation
words = vectorizer.get_feature_names()tokens = [analyzer(doc) for doc in cleaned_docs]dictionary = corpora.Dictionary(tokens)corpus = [dictionary.doc2bow(token) for token in tokens]topic_words = [[words for words, _ in topic_model.get_topic(topic)] for topic in range(len(set(topics))-1)]
不过,我们稍微看一下 topic_words 中的内容。
topic_words
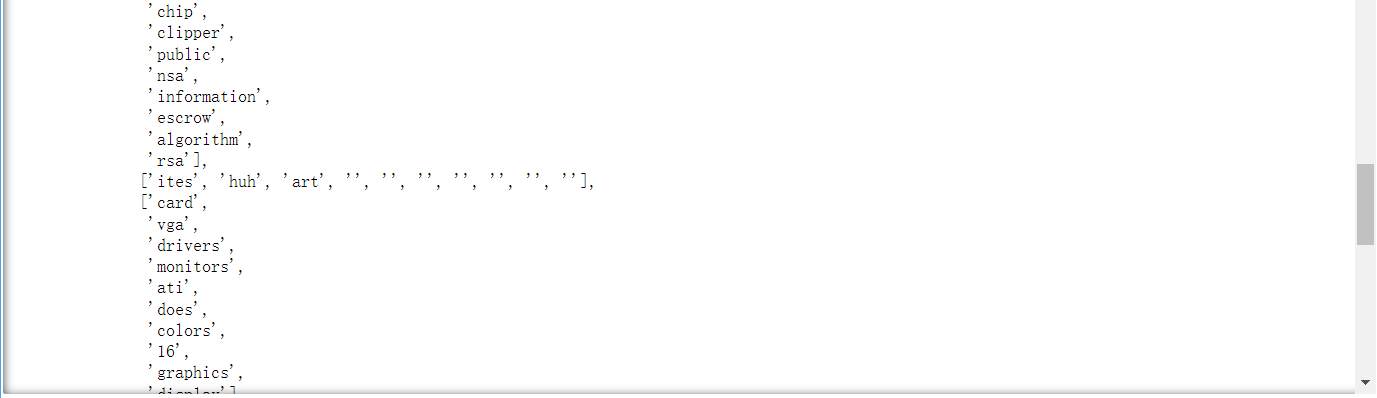
topic_words 的结果是一个双重列表,含义是每一个主题所对应的代表词组。从上图中可以看到,有一个列表的结果中包含空字符串,必须把这个空字符串去掉,不然后面的连贯度计算会报错。(注意:博主在这个地方一开始出现了错误,经排查才发现)
a = []
for i in range(len(topic_words)):b = []for word in topic_words[i]:if word != '':b.append(word)a.append(b)topic_words = a
topic_words

# Evaluate
coherence_model = CoherenceModel(topics=topic_words, texts=tokens, corpus=corpus,dictionary=dictionary, coherence='c_v')coherence = coherence_model.get_coherence()print(coherence)

如果在一开始导入数据时,没有去除掉头尾的内容,按照下面这种方式导入,主题连贯度得分也会低不少。所以文本内容和有效的数据清理会对最后的结果会产生一定影响。
dataset = fetch_20newsgroups(subset='train')['data']

最后,对于本文中用到的几个包的版本特别说明一下。先安装 bertopic,再安装 gensim。
| 名称 | 版本 | 名称 | 版本 |
|---|---|---|---|
| pandas | 1.4.1 | numpy | 1.20.0 |
| bertopic | 0.13.0 | gensim | 3.8.3 |
| nltk | 3.8.1 | scikit-learn | 1.2.1 |
| scipy | 1.10.0 | sentence-transformers | 2.2.2 |
参考文献
-
[1] Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv, abs/1810.04805.
-
[2] Soodeh Hosseini and Zahra Asghari Varzaneh. 2022. Deep text clustering using stacked AutoEncoder. Multimedia Tools Appl. 81, 8 (Mar 2022), 10861–10881. https://doi.org/10.1007/s11042-022-12155-0
相关文章:
【自然语言处理】主题建模:BERTopic(实战篇)
主题建模:BERTopic(实战篇)BERTopic 是基于深度学习的一种主题建模方法。201820182018 年底,Devlinetal.Devlin\ et\ al.Devlin et al. 提出了 Bidirectional Encoder Representations from Transformers (BERT)[1]^{[1]}[1]。BER…...

k8s学习笔记
目录 一、安装前准备 二、安装 1、安装kubelet、kubeadm、kubectl 2、使用kubeadm引导集群 1、下载各个机器需要的镜像 2、初始化主节点 3、加入node节点 3、部署dashboard 1、主节点安装 2、设置访问端口 3、创建访问账号 4、令牌访问获取token 三、实战 1、资源创…...

web自动化测试入门篇05——元素定位的配置管理
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:【Austin_zhai】 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能,分享行业相关最新信息。…...
C语言预处理
文章目录 目录 文章目录 前言 一、程序编译的过程 二、编译阶段 1.预处理(*.i) 2.编译(*.s) 3.汇编(*.o) 4.链接 总结 前言 提示:使用vs code(gcc编译器)与vs2022来演示c语言的预处理 提示:以下是本篇文章正文内容,下面…...
git报错大全,你将要踩的坑我都帮你踩了系列
使用git push -u origin master报下面的错: 使用git push -u origin master报下面的错: Updates were rejected because the remote contains work that you do not have locally,This is usually caused by another repository pushing to …...
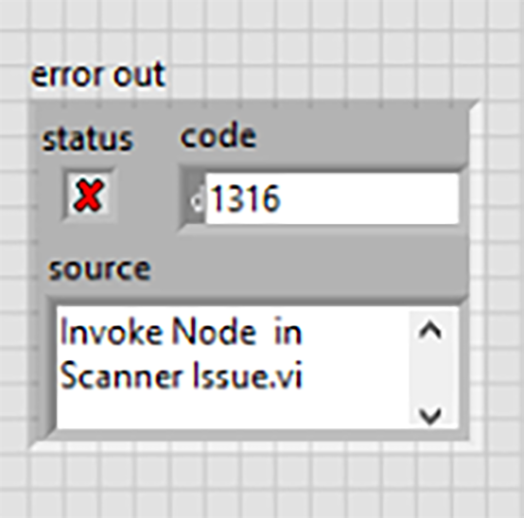
LabVIEW中使用.NET方法时出现错误1316
LabVIEW中使用.NET方法时出现错误1316为什么不能调用带有泛型参数的方法?LabVIEW不支持哪些.NET功能?为什么会收到以下错误:发生此错误的原因是正在调用LabVIEW中不支持的.NET功能。有关解决方法,请参阅“其他信息”部分。可以在下…...

HTTP2.0 相比 HTTP1.0、HTTP1.1 有哪些重大改进?值得升级更换吗?
目录 HTTP1.0 HTTP1.1 HTTP2.0 主要特性对比 HTTP发展历史 HTTP2解决的问题 HTTP1.0 HTTP1.1 HTTP2.0...
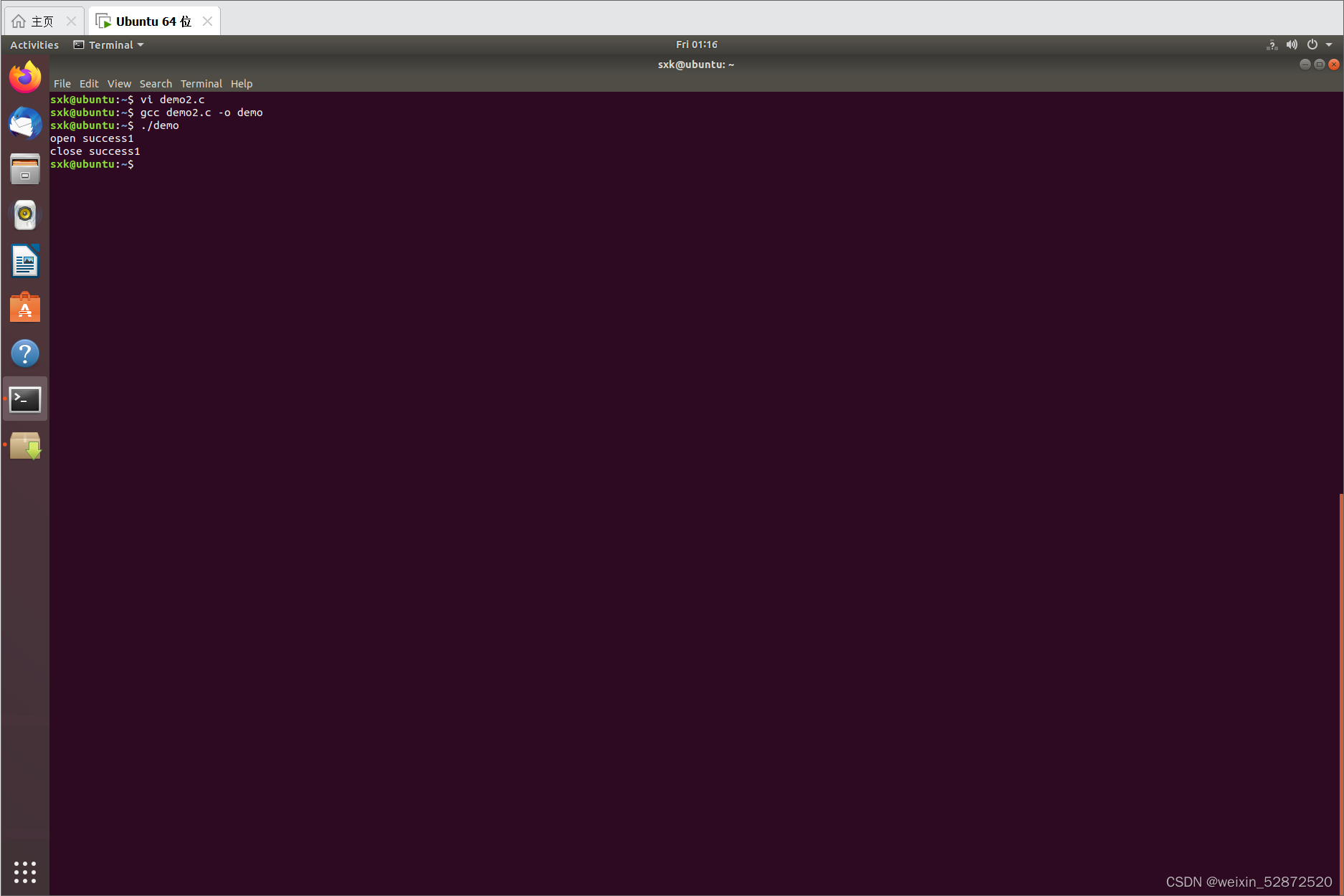
九、Linux文件 - fopen函数和fclose函数讲解
目录 1.fopen函数 2.fclose函数 3.fopen函数和fclose实战 1.fopen函数 fopen fwrite fread fclose ...属于标准C库 include <stdio.h> standard io lib open close write read 属于Linux系统调用 可移植型:fopen > open(open函数只在嵌入…...

轨迹预测算法vectorNet调研报告
前言 传统的行为预测方法是规则的,基于道路结构的约束生成多个行为假设。最近,很多基于学习的预测方法被提出。他们提出了对于不同行为假设的进行概率解释的好处,但是需要重构一个新的表示来编码地图和轨迹信息。有趣的是,虽然高精…...
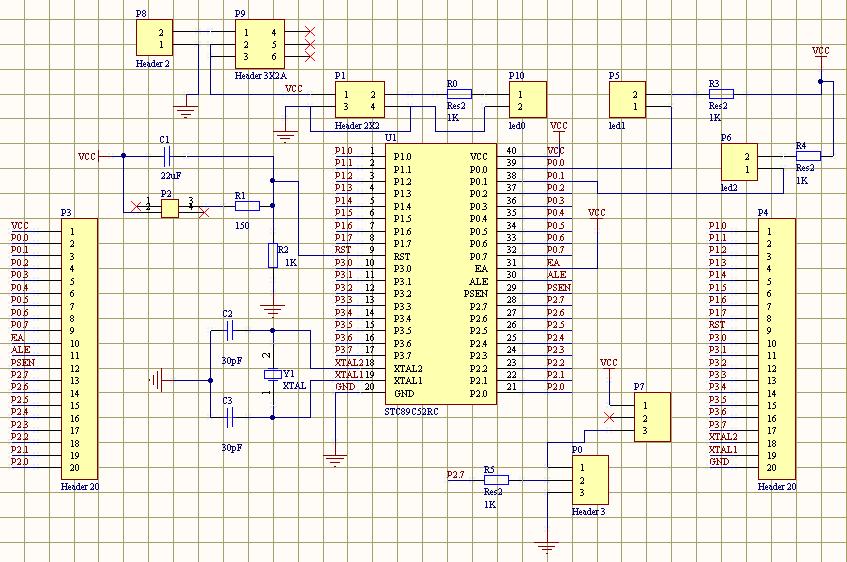
基于STM32设计的避障寻迹小车
一、前言 1.1 项目背景 根据美国玩具协会在一项研究中,过去几年全球玩具销售增长与GDP的世界平均水平大致相同。但全球玩具市场的内部结构已经占据了巨大的位置变化:传统玩具的市场份额正在下降,高科技电子玩具正在蓬勃发展。全球玩具市场的…...

【视觉检测】使用opencv编写一个图片缺陷检测流程
1. 导入必要的库,如OpenCV,NumPy等。 2. 使用OpenCV读取图像,并将其转换为灰度图像。 3. 使用OpenCV的Canny边缘检测算法检测图像中的边缘。 4. 使用OpenCV的Hough变换算法检测图像中的线条。 5. 使用OpenCV的模板匹配算法检测图像中的缺…...

3.Dockerfile 定制镜像
3. Dockerfile 定制镜像 从上一节的docker commit的学习中,我们可以了解到,镜像的定制实际上就是定制每一层所添加的配置、文件等信息,但是命令毕竟只是命令,每次定制都得去重复执行这个命令,而且还不够直观ÿ…...

Web基础与HTTP协议
Web基础与HTTP协议一、Web基础与HTTP概述1、域名概念二、域名服务与域名注册1、域名定义2、域名服务三、网页访问(http、https)1、网页概述2、网页的基本标签四、Web1、Web概述2、Web1.0 Web2.0五、HTTP协议概述1、HTTP协议简介2、HTTP协议请求总结一、W…...
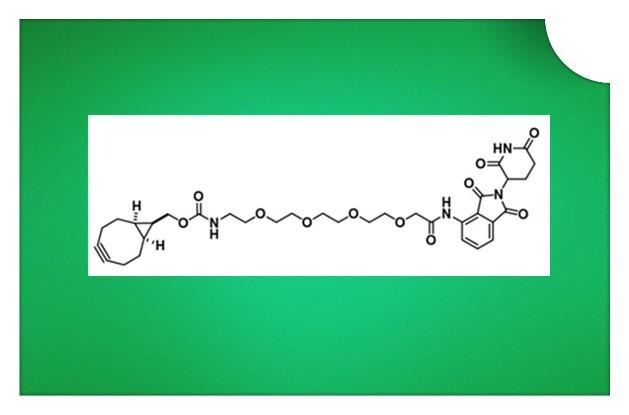
【化学试剂】endo-BCN-PEG4-Pomalidomide,(1R,8S,9S)-双环[6.1.0]壬-四聚乙二醇-泊马度胺纯度95%+
一、基础产品数据(Basic Product Data):CAS号:N/A中文名:(1R,8S,9S)-双环[6.1.0]壬-四聚乙二醇-泊马度胺英文名:endo-BCN-PEG4-Pomalidomide二、详细产品数据(Detailed Product Data)…...
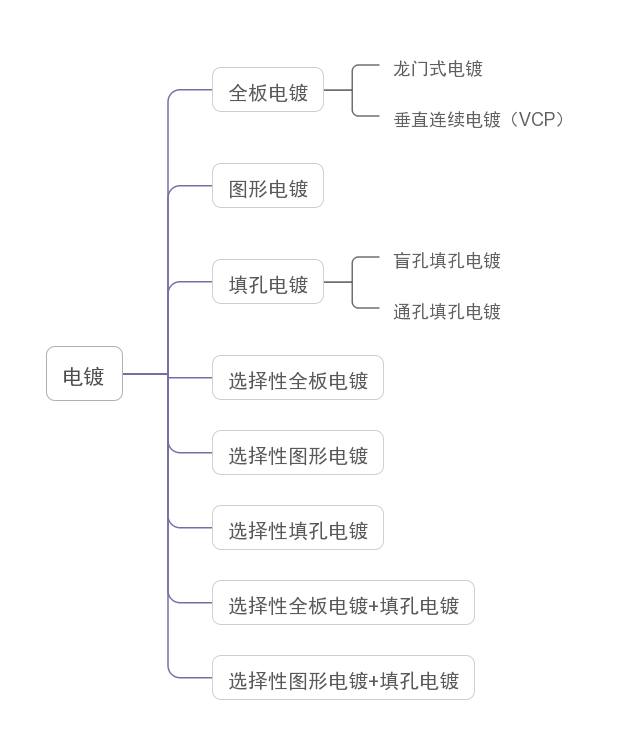
全板电镀与图形电镀,到底有什么区别?
衔接上文,继续为朋友们分享普通单双面板的生产工艺流程。 如图,第四道主流程为电镀。 电镀的目的为: 适当地加厚孔内与板面的铜厚,使孔金属化,从而实现层间互连。 至于其子流程,可以说是非常简单&#x…...
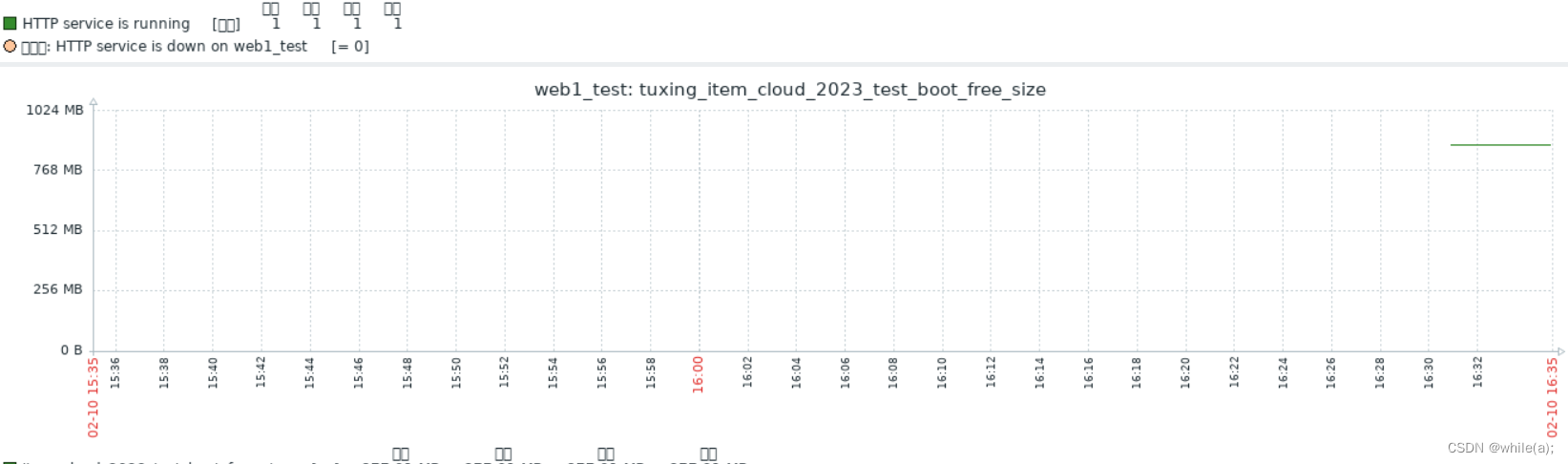
Zabbix 构建监控告警平台(二)--
Apache监控示例(图形监控)模板TemplateZabbix Items 1.Apache监控示例(图形监控) 1.1创建主机组 在“配置”->“主机群组”->“创建主机群组” 填入组名“webserver_test” 创建完成之后可以在“配置”->"主机群组&…...

开学季,关于校园防诈骗宣传,如何组织一场微信线上答题考试
开学季,关于校园防诈骗宣传,如何组织一场微信线上答题考试如何组织一场微信线上答题考试在线考试是一种非常节约成本的考试方式,考生通过微信扫码即可参加培训考试,不受时间、空间的限制,近几年越来越受企事业单位以及…...
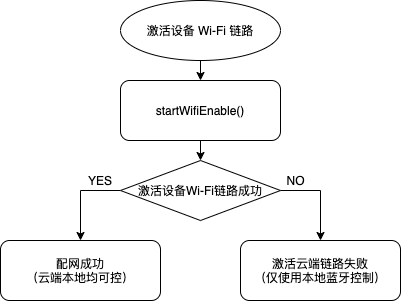
蓝牙单点技术实现路径介绍
本文主要介绍蓝牙设备与手机一对一相连的 蓝牙单点 技术。 准备工作 系统要求:蓝牙使用需要安卓 4.3 以及以上版本,智能生活 App SDK 从安卓 4.4 开始支持。Manifest 权限: <uses-permission android:name"android.permission.ACCE…...

Ubuntu22.04 用 `hwclock` 或 `timedatectl` 来设置RTC硬件时钟为本地时区
Ubuntu22.04用 hwclock 或 timedatectl 来设置硬件时区为本地时区 可以用hwclock命令 sudo hwclock --localtime --systohc👆效果等同👇 , --localtime的简写是-l ; --systohc的简写是-w sudo hwclock -l -w也可以用timedatectl命令 👆效果…...

Node=>Express路由 学习2
1.概念 Express路由指的是客户端的请求与服务器处理函数之间的映射关系 Express路由由三部分组成 请求类型 请求URL地址 处理函数 app.METHOD ( PATH , HANDLER )根据定义的先后顺序进行匹配 请求类型和请求的URl同时匹配成功才会调用相应的处理函数 简单用法 2.模块化路由 为了…...

如何在Windows中快速读取Linux分区?Ext2Read完整教程指南
如何在Windows中快速读取Linux分区?Ext2Read完整教程指南 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否曾经遇到过…...
建议收藏。)
Java面试八股文总结(金三银四版)建议收藏。
今年的行情,让招聘面试变得雪上加霜。已经有不少大厂,如腾讯、字节跳动的招聘名额明显减少,面试门槛却一再拔高,如果不用心准备,很可能就被面试官怼得哑口无言,甚至失去了难得的机会。 现如今,…...

ComfyUI里玩转微软Florence-2:一个模型搞定图片描述、目标检测和抠图
在ComfyUI中解锁Florence-2的全能视觉工具箱 当AI绘画遇上多功能视觉模型,会碰撞出怎样的火花?微软开源的Florence-2正是这样一个"视觉瑞士军刀",它能同时完成图片描述生成、目标检测和图像分割等任务。而对于ComfyUI用户来说&…...

MaaYuan使用指南
MaaYuan使用指南 【免费下载链接】MaaYuan 代号鸢 / 如鸢 一键长草小助手 项目地址: https://gitcode.com/gh_mirrors/ma/MaaYuan MaaYuan是一款基于MaaFramework开发的跨平台游戏自动化工具,专为《代号鸢》和《如鸢》玩家设计。通过图像识别和模拟控制技术&…...

效率提升秘籍:在PyTorch-2.x-Universal-Dev环境里,这样用pyyaml和requests最省事
效率提升秘籍:在PyTorch-2.x-Universal-Dev环境里,这样用pyyaml和requests最省事 1. 引言:为什么这两个库值得关注 在深度学习项目开发中,我们常常把注意力集中在模型架构和训练算法上,却忽略了两个看似简单但极其重…...

)
Python实战:如何用多线程加速破解ZIP/RAR密码(附完整代码)
Python多线程密码破解实战:从原理到性能优化 在数据恢复和渗透测试领域,密码保护的压缩文件处理是常见需求。当我们面对遗忘密码的ZIP/RAR文件时,Python提供了高效的解决方案。本文将深入探讨如何利用多线程技术显著提升密码破解效率…...

如何构建高效可扩展的实时数据处理系统:抖音直播弹幕采集架构深度解析
如何构建高效可扩展的实时数据处理系统:抖音直播弹幕采集架构深度解析 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 抖音…...

别再手动算坐标了!用Python的coord-convert库5分钟搞定高德/百度/WGS84互转
别再手动算坐标了!用Python的coord-convert库5分钟搞定高德/百度/WGS84互转 你是否曾在处理地理数据时,被不同地图平台的坐标系搞得焦头烂额?GPS设备采集的WGS84坐标无法直接在高德地图上显示,百度地图的坐标又和微信小程序不兼容…...

MiniCPM-o-4.5-nvidia-FlagOS学术写作助手:LaTeX公式与论文排版智能辅助
MiniCPM-o-4.5-nvidia-FlagOS学术写作助手:LaTeX公式与论文排版智能辅助 写论文,尤其是理工科的论文,最头疼的是什么?十有八九的科研人员和学生会告诉你:是LaTeX公式和排版。一个复杂的公式,代码敲半天&am…...