Read book Netty in action(Chapter VI)--ByteBuf
序言
之前学习了传输,通过前面的学习我们都知道,网络数据的基本单位是字节。JDK中提供了ByteBuffer作为字节的容器,但是过于繁琐复杂,Netty中提供了ByteBuf作为替代品。学习一下。
API
Netty的数据处理API通过两个组件暴露 ------ abstract class byteBuf 和 interface ByteBufHolder。
优点如下:
1.它可以被用户自定义的缓冲区类型拓展。
2.通过内置的复合缓冲区类型实现了透明的零拷贝。
3.容量可以按需增长。
4.切换读写形态不需要调用flip()方法。
5.读和写使用不同的索引。
6.支持方法链式调用。
7.支持引用计数。
8.支持池化。
ByteBuf类 - Netty的数据容器
因为所有的网络通信都设计字节系列的移动,所以高效易用的数据结构是不可少的。Netty的ByteBuf实现满足并超越了这些需求。
HOW TO WORK
ByteBuf维护了两个不同的索引,一个用于读,一个用于写入。当你从ByteBuf中读取的时候。他的readerIndex将会被递增已经被读取的字节数。同样的写入的时候,writerindex也会被递增。read和wirte的索引起始位置都为位置0。
如果打算读取字节直到readerIndex达到和writerIndex同样的值会发送什么。在那是,你将会达到 可以读取的 数据的末尾。类似于数据的索引溢出。
名字以read或者write开头的ByteBuf方法,将会推进器对应的索引,而名称以set或者get开头的操作则不会。后面这些方法只是会以索引为操作来执行想做的操作。
可以指定ByteBuf最大容量。试图移动写索引超过这个值就会触发一个异常!
你完全可以理解为数组,这样更好理解,因为大家对数组比较熟悉,可以借鉴一下其思想
ByteBuf的使用模式
堆缓冲区
最常用的ByteBuf模式是将数据存储在JVM的堆空间中,这种模式被称为 支撑数组,它能在没有使用池化的情况下提供快速的分配和释放。
public static void heapBuffer() {ByteBuf heapBuf = Unpooled.buffer(1024);; //get reference form somewhere// check arrayif (heapBuf.hasArray()) {// get the arraybyte[] array = heapBuf.array();int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();int length = heapBuf.readableBytes();// doSomethingdoSomething(array, offset, length);}}适合有遗留的数据需要处理的请求。
直接缓冲区
直接缓冲区是另外一种ByteBuf模式。我们期望用于对象创建的内存分配永远都来于堆中,但是这并不是必须的-NIO在jdk1.4中引入的ByteBuffer类允许jvm通过本地调用来分配内存。这主要是避免每次在调用本地IO之前将缓冲区里的内容都复制到一个中间缓冲区。
ByteBuf在javadoc中曾指出:直接缓冲区的内容将会被驻留在 会被垃圾回收器回收的堆 之外。说白了,gc干不掉它。如果你的数据包含在一个堆上分配的缓冲区上中,在套接字发送它之前,JVM会将它复制到一个直接缓冲区中。
直接缓冲区的主要缺点是:相对于堆缓冲区,分配和释放比较昂贵,处理遗留代码时如果数据不在堆上,那么还得进行一次复制。
public static void directBuffer() {ByteBuf directBuf = Unpooled.buffer(1024);; //get reference form somewhereif (!directBuf.hasArray()){int length = directBuf.readableBytes();byte[] bytes = new byte[length];directBuf.getBytes(directBuf.readerIndex(),bytes);doSomething(bytes,0,length);}}
复合缓冲区
第三种也是最后一种模式使用的是复合缓冲区,它为多个ByteBuf提供一个聚合视图。在这里可以根据需要添加或者删除ByteBuf实例,JDK中的ByteBuffer完全没有这个东西。Netty是通过一个ByteBuf子类 – CompositeByteBuf 为了实现这个模式,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。
CompositeByteBuf实例可以同时包含直接内存分配和非直接内存分配。
以http为例:一个由两部分 —头部和主体— 组成的将通过HTTP协议传输的消息。这两部分由应用程序不同的模块产生,将会在消息将要发生的时候再行组装。该应用程序可以选择多个重复相同的消息主体。当这种情况发生的时候,对于每个消息都会创建一个新的头部。
因为我们不想为每个消息重新分配这两个缓冲区,所以使用CompositeByteBuf是一个完美的选择。它在消除了没必要复制的同时,暴露了ByteBuf的API。下面看一段代码,如何通过使用JDK的ByteBuffer来实现这个需求,创建了一个包含两个ByteBuffer数组来保存这些消息组件。同时创建了第三个ByteBuffer来保存所有这些数据的副本。
public static void byteBufComposite() {CompositeByteBuf messageBuf = Unpooled.compositeBuffer();ByteBuf headerBuf = Unpooled.buffer(1024); // can be backing or directByteBuf bodyBuf = Unpooled.buffer(1024); // can be backing or directmessageBuf.addComponents(headerBuf, bodyBuf);messageBuf.removeComponent(0); // remove the headerfor (ByteBuf buf : messageBuf) {System.out.println(buf.toString());}}
Netty使用了CompositeByteBuf来优化套接字的IO操作,尽可能消除由JDK缓冲区实现带来的性能问题和内存的问题,这种优化细节不会暴露。存在于netty核心代码中。
字节级操作
随机访问索引
和Java字节数组一样,ByteBuf的索引是从零开始的:第一个字节的索引是0,最后一个总是capacity() - 1.我们可以像遍历数组一样遍历ByteBuf
public static void main(String[] args) {byteBufRelativeAccess();}public static void byteBufRelativeAccess() {CompositeByteBuf messageBuf = Unpooled.compositeBuffer();messageBuf.writeBytes("ok le".getBytes());for (int b = 0; b < messageBuf.capacity(); b++) {byte aByte = messageBuf.getByte(b);System.out.println(aByte);}}
顺序访问索引
虽然ByteBuf同时具有读索引和写索引,但是JDK的ByteBuffer却只有一个索引。所以需要flip()方法在两种模式之间进行来回切换的原因。
ByteBuf被两个索引切成三个部门,第一部分是已经读过的部分,可以被丢弃。第二部分自然是没有被读过的字节,可以读取。那么第三部分肯定就是可以写的空间了,可写字节。
可丢弃字节
已丢弃字节的分段包括了已经被读过的字节。通风调用 discardReadBytes()方法,可以丢弃他们并回收空间。这个分段的初始大小为0,存储在readerIndex中,会随着read的造作执行而增加。调用了这个方法之后,可丢弃的空间现在变成可写的了。这个操作只移动了可读的字节和写索引,而没有对所有可写入的字节进行擦除操作。所以这种操作虽然可以扩充写区域,但是内存的复制不可避免,总得移动读字节到开始位置吧,如果不是内存宝贵,我相信不会这么做的。
可读字节
ByteBuf的可读字节分段存储了实际数据。新分配的,包装的或者复制的缓冲区的默认readerIndex值为0.任何名称以read或者skip开头的操作都将检索或者跳过当前可读索引,并且增加已读索引。
如果被调用的方法需要一个ByteBuf参数作为写入的目标。并且没有指定目标索引参数,那么该缓冲区的写索引也会被增加,例如:readBytes(ByteBuf dest)
如果在缓冲区的可读字节数已经耗尽时次中读取数据,那么会引发一个IndexOutOfBoundsException。
如何从读取所有可以读取的字节:
public static void readAllData() {ByteBuf buffer = Unpooled.compositeBuffer();while (buffer.isReadable()) {System.out.println(buffer.readByte());}}
可写字节
可写字节分段是指一个拥有未定义内容的、写入就绪的内存区域。新分配的缓冲区的写索引默认值为0。任何名称以write开头的操作都是从当前写操作中开始写数据,并将它增加以及写入的字节数。如果写操作的目标也是ByteBuf,并且没有指定源索引的值,则源缓冲区的readerIndex也同样会被增加相同的大小。调用如下:
writeBytes(ByteBuf dest)。如果我那个目标中写入超过目标容量的数据,将会已发一个索引越界异常。
public static void write() {// Fills the writable bytes of a buffer with random integers.ByteBuf buffer =Unpooled.compositeBuffer(); //get reference form somewherewhile (buffer.writableBytes() >= 4) {buffer.writeInt(1024);}}索引管理
JDK的InputStream定义了mark(int readlimit)和reset()方法,这些方法分别被用来将流中的当前位置指定,以及将流重置到该位置。同样,可以通过调用markReaderIndex()、markWriterIndex()、和resetReaderIndex()来标记和重置ByteBuf的readerIndex和writeIndex。这些和InputStream中的调用别无二致,只是没有什么readlimit来指定标记何时失效。
和数组一样,我们可以通过调用readerIndex(int)或者writerIndex(int)来讲索引移动到指定位置。试图将任何一个索引设置到无效的位置将会导致索引越界异常。可以通过clear()方法将readerIndex和writerIndex都设置为0,但是并不会清理内存。clear()比discardReadBytes()清的多,他只会重置索引而非复制处理内存。
查找操作
在ByteBuf中有多种可以用来确定索引的方法。最简单的是使用IndexOf方法。较复杂的查找可以通过哪些需要一个ByteProcessor作为参数的方法达成。这个接口只定义了一个方法:
boolean process(byte value)
他将检查输入值是否是正在查找的值。
例子:
public static void byteProcessor() {ByteBuf buffer = Unpooled.compositeBuffer(); //get reference form somewherebuffer.writeBytes("测测测测测测测测,\r".getBytes());int index = buffer.forEachByte(ByteProcessor.FIND_CR);System.out.println(index);}
查找回车符。
派生缓冲区
派生缓冲区为ByteBuf提供了专门的方式来呈现其内容的视图。这些类视图是通过以下方法被创建的:
duplicate();
slice();
slice(int,int);
Unpooled.unmodifiableBuffer(xxx)
order(ByteOrder)
readSlice(int)
这个方法都会返回一个新的实例,它具有自己的读索引,写索引和标记索引。其存储内部和JDK的ByteBuffer一样,都是共享的。这使得创建一个派生缓存区的代价低廉,但是这也意味着,如果你修改了它的内容,同时也修改了对应的实例。这个类似于 浅拷贝,从某种意义上来说,他们是差不多的从设计层面上和使用层面。但是又可以切片,反正有这个概念就可以。
public static void byteBufSlice() {Charset utf8 = Charset.forName("UTF-8");ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);ByteBuf sliced = buf.slice(0, 15);System.out.println(sliced.toString(utf8));buf.setByte(0, (byte)'J');System.out.println(buf.toString(utf8));System.out.println(sliced.toString(utf8));assert buf.getByte(0) == sliced.getByte(0);}
你会发现改了sliced,原来的buf也会改变,不妨debuf跑一下。
再对比一下copy,我刚刚以浅拷贝为例,这个就像深拷贝。
public static void byteBufCopy() {Charset utf8 = Charset.forName("UTF-8");ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);ByteBuf copy = buf.copy(0, 15);System.out.println(copy.toString(utf8));buf.setByte(0, (byte)'J');System.out.println(buf.toString(utf8));System.out.println(copy.toString(utf8));assert buf.getByte(0) != copy.getByte(0);}
可以自行debug看结果不同,我举深浅拷贝的例子,就可以很好理解了。
深拷贝: User id User1 id1 id改 id1不变
浅拷贝: User id User1 id1 id改 id1变
读/写操作
前面曾经提到,有两种类别的读写操作:
set / get 索引不变,从给定的索引开始
read / write 从给定的索引开始,索引变化。
API就不放出来了。直接放个书上的案例:
get 和 set
public static void byteBufSetGet() {Charset utf8 = StandardCharsets.UTF_8;ByteBuf byteBuf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);char char1 = (char) byteBuf.getByte(0);System.out.println(char1);int readerIndex = byteBuf.readerIndex();int writerIndex = byteBuf.writerIndex();System.out.println(readerIndex);System.out.println(writerIndex);byteBuf.setByte(0, (byte) 'W');System.out.println((char) byteBuf.getByte(0));readerIndex = byteBuf.readerIndex();writerIndex = byteBuf.writerIndex();System.out.println(readerIndex);System.out.println(writerIndex);}
read 和 write
public static void byteBufWriteRead() {Charset utf8 = StandardCharsets.UTF_8;ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);System.out.println((char)buf.readByte());int readerIndex = buf.readerIndex();System.out.println(readerIndex);int writerIndex = buf.writerIndex();System.out.println(writerIndex);buf.writeByte((byte)'?');System.out.println((char)buf.readByte());readerIndex = buf.readerIndex();writerIndex = buf.writerIndex();System.out.println(readerIndex);System.out.println(writerIndex);System.out.println(buf.toString(utf8));}
每次read之后,索引后移,前面数据就是废物数据了。自行debuf,一看便知。还有很多方法,使用方法自行查看API
ByteBufHolder接口
在平时开发中不难发现,处理实际的数据负载以外,我们还需要存储各种属性值。HTTP响应便是一个很好的例子,有什么Cookie,状态码之类的额外的东西。
为了处理这种常用的用例,Netty提供了ByteBufHolder接口。ByteBufHolder也为Netty的高级特性提供了支持,如缓冲区池化,和所有的池一样,从池中拿,自行释放。ByteBufHolder只有几种用于访问底层数据和引用技术的方法。
content() 返回这个ByteBufHolder所持的ByteBuf
copy() 返回ByteBufHolder的一个深拷贝,其中带一个copy副本
duplicate() 返回ByteBufHolder的一个浅拷贝,其中带一个共享副本
如果要实现一个将其有效负载储存在ByteBuf中的消息对象。可以使用ByteBufHolder。
ByteBuf分配
按需分配:ByteBufAllocator接口
为了降低分配和释放内存的开销。通过ByteBufAllocator实现了(ByteBuf)的池化。它可以用来分配我们所描述过得任何类型的ByteBuf。使用池化特定于应用程序的决定,它不会改变ByteBuf的API。
ByteBufAllocator的方法有
buffer()返回一个基于堆或者直接内存的ByteBuf
heapBuffer()返回一个基于堆内存存储的ByteBuf
directBuffer()返回一个基于直接内存的ByteByf
compostiteBuffer()返回一个可以通过添加最大到指定数目的基于堆或者直接内存存储的缓冲区来拓展的compostiteByteBuf
toBuffer()返回一个用于套接字的IO操作的ByteBuf
可以通过Channel或者绑定到ChannelHandler的ChannelHandlerContext获取到一个到ByteBufAllocator的引用。
public static void obtainingByteBufAllocatorReference(){Channel channel = ...; //get reference form somewhereByteBufAllocator allocator = channel.alloc();ChannelHandlerContext ctx = ...; //get reference form somewhereByteBufAllocator allocator2 = ctx.alloc();}差不多就这样。Netty实现了两种ByteBufAllocator的实现,PooledByteBufAllocator和UnpooledByteBufAllocator。前者池化了ByteBuf的实例以提升性能并最大限度的减少内存碎片。而后者不池化,每次都会返回一个新的实例,和连接池还有线程池别无二例,池化就进池,不池化自己管理。当然了,Netty的实现是默认池化的。
Unpooled缓冲区
有时候,你无法获得一个ByteBufAllocator的引用,那么,Netty给我们提供了一个小工具类叫做:Unpooled,它提供了静态的辅助方法,来获取没有池化的ByteByf实例。方法有如下几个:
buffer() 返回一个没有池化的基于堆内存存储的ByteBuf
directBuffer() 返回一个未池化的基于直接内存存储的ByteBuf
wrappedBuffer() 返回一个包装了给定数据的ByteBuf
copiedBuffer() 返回了一个复制了给定数据的ByteBuf
我们案例中经常使用的代码你一定非常熟悉。
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
Unpooled类还能使得ByteBuf同样可以用于哪些并不需要netty介入的非网络项目,使得其能得益于高性能可扩展的缓冲区API。(后续考虑将其引入naruku)。
ByteBufUtil类
看名字就知道是个缓冲区的工具类。这个API是同样的,并且和池化无关。
这些方法中有个叫做 hexdump()的方法,它以十六进制的表现形式打印ByteBuf里的内容。这很有用,他可以轻易地转换回来实际的字节表示。
还有equals方法,可以比较两个ByteBuf实例的相等性。如果需要实现自己的ByteBuf子类,可能会发现其他用途。
引用计数
引用计数是通过正某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术,在netty 第四版中引入到了ByteBuf和ByteBufHolder中,他们均实现了ReferenceCounted接口
public abstract class ByteBuf implements ReferenceCounted, Comparable<ByteBuf> {
// ...
}
public interface ReferenceCounted {/*** Returns the reference count of this object. If {@code 0}, it means this object has been deallocated.*/int refCnt();/*** Increases the reference count by {@code 1}.*/ReferenceCounted retain();/*** Increases the reference count by the specified {@code increment}.*/ReferenceCounted retain(int increment);/*** Records the current access location of this object for debugging purposes.* If this object is determined to be leaked, the information recorded by this operation will be provided to you* via {@link ResourceLeakDetector}. This method is a shortcut to {@link #touch(Object) touch(null)}.*/ReferenceCounted touch();/*** Records the current access location of this object with an additional arbitrary information for debugging* purposes. If this object is determined to be leaked, the information recorded by this operation will be* provided to you via {@link ResourceLeakDetector}.*/ReferenceCounted touch(Object hint);/*** Decreases the reference count by {@code 1} and deallocates this object if the reference count reaches at* {@code 0}.** @return {@code true} if and only if the reference count became {@code 0} and this object has been deallocated*/boolean release();/*** Decreases the reference count by the specified {@code decrement} and deallocates this object if the reference* count reaches at {@code 0}.** @return {@code true} if and only if the reference count became {@code 0} and this object has been deallocated*/boolean release(int decrement);
}
其实通过名字计数就知道这个东西不会太复杂,它主要涉及跟踪某发哥特定对象活动引用的数量。一个ReferenceCounted 实现的实例将会通常以活动的引用计数1作为开始,只要引用数大于0。就能保证对象不会被释放。减少到0的时候,就会释放,释放的对象就没有办法使用了。这个小玩意对于池化技术来说,至关重要。
我也很好奇这东西是怎么实现的,我曾经自诩为JAVA性能开发工程师,自吹自擂说任何JAVA技术,我都能追其源码,这个东西不知道的话,我面子挂不住,我决定探险,去看看他的源码。顺便看看 Unpooled.copiedBuffer的实现,我决定用断点去一探究竟。前方高能!!!
开始
Charset utf8 = StandardCharsets.UTF_8;
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);

刚进来,就看到了想看到的,我们追过去看看。release应该表示是一个是否释放的状态。 ByteBuf buffer = ALLOC.heapBuffer(ByteBufUtil.utf8Bytes(string));应该表示是一个基于堆的一个缓冲区。里面的逻辑我不看,我目的是看释放。是怎么释放的
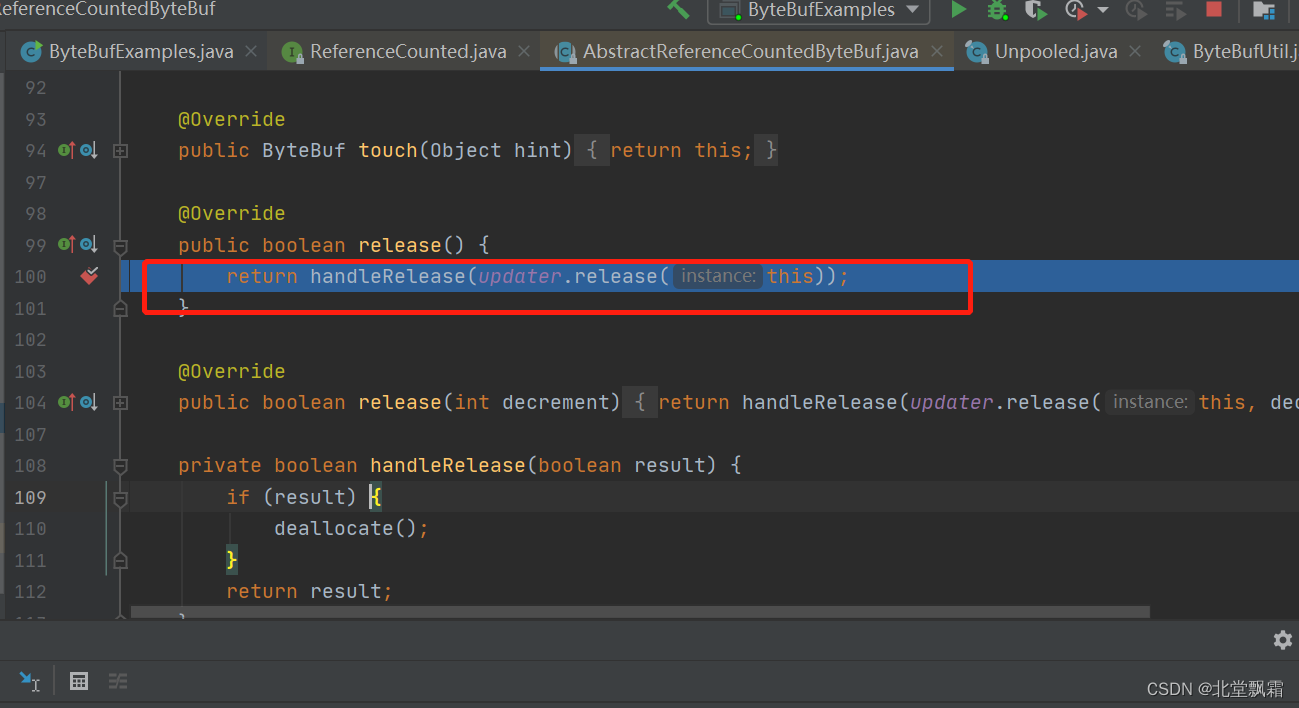
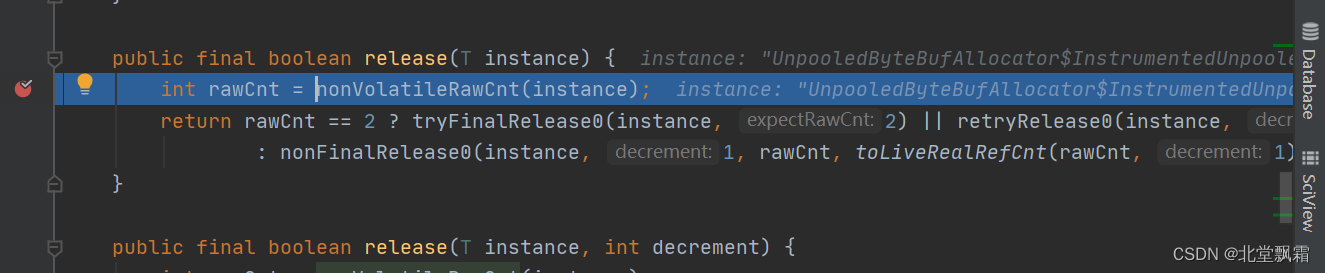

说实话这个方法具体干嘛我不知道,但是他肯定是在获取引用次数,如果这个数是2的话,那么就会尝试这个方法。

这个看懂了,cas操作嘛,把这个2换成1。如果这个失败了,就执行这个方法
private boolean retryRelease0(T instance, int decrement) {for (;;) {int rawCnt = updater().get(instance), realCnt = toLiveRealRefCnt(rawCnt, decrement);if (decrement == realCnt) {if (tryFinalRelease0(instance, rawCnt)) {return true;}} else if (decrement < realCnt) {// all changes to the raw count are 2x the "real" changeif (updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) {return false;}} else {throw new IllegalReferenceCountException(realCnt, -decrement);}Thread.yield(); // this benefits throughput under high contention}}
这段代码的意思是:如果真实计数是1,回到tryFinalRelease0,返回true,如果真实计数大于1,那么减1,就不能释放,如果小于1,就报错。如果不是2。进入nonFinalRelease0方法。
private boolean nonFinalRelease0(T instance, int decrement, int rawCnt, int realCnt) {if (decrement < realCnt// all changes to the raw count are 2x the "real" change - overflow is OK&& updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) {return false;}return retryRelease0(instance, decrement);}
意思是更新引用计数,失败调用retryRelease0方法。
这释放连起来就是用nonVolatileRawCnt获得引用计数,然后判断引用计数是否是2或者减的值就是真实引用计数值,是的话就可以尝试直接设置的方法tryFinalRelease0,如果失败会去尝试释放方法retryRelease0,这个是自旋,直到成功为止。如果不是的话就普通的引用计数器值的修改即可nonFinalRelease0。
再往下跑就是
private boolean handleRelease(boolean result) {if (result) {deallocate();}return result;}如果可以释放调用deallocate方法,进去看看
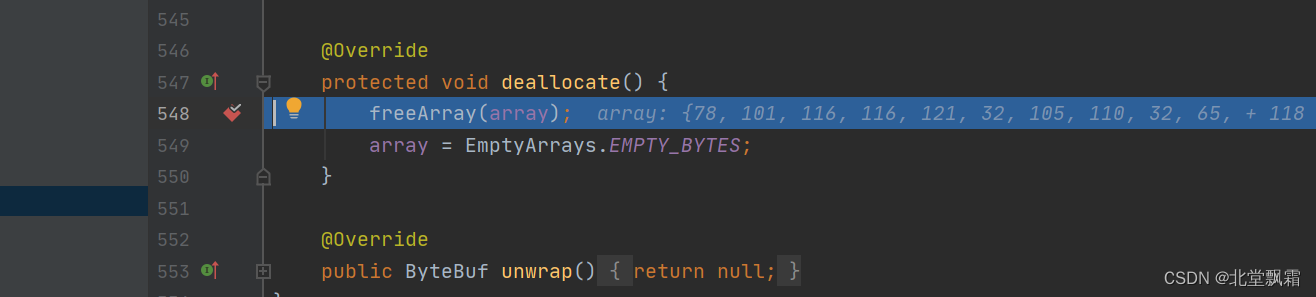
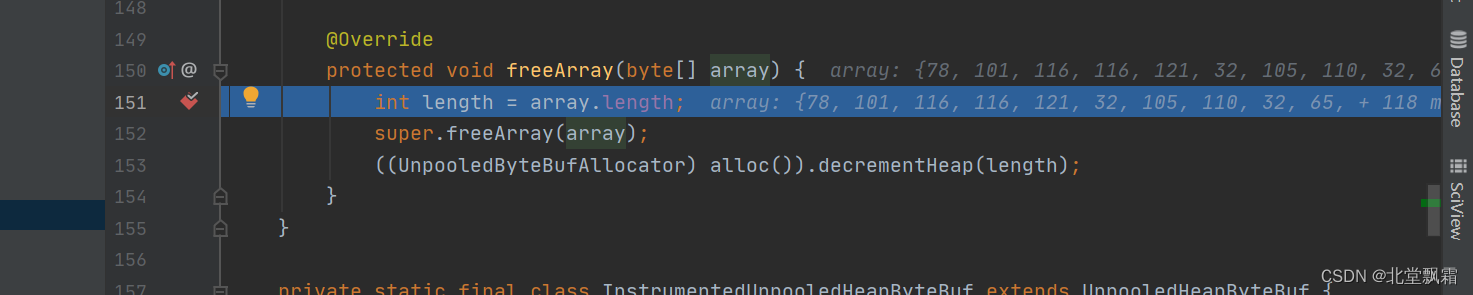
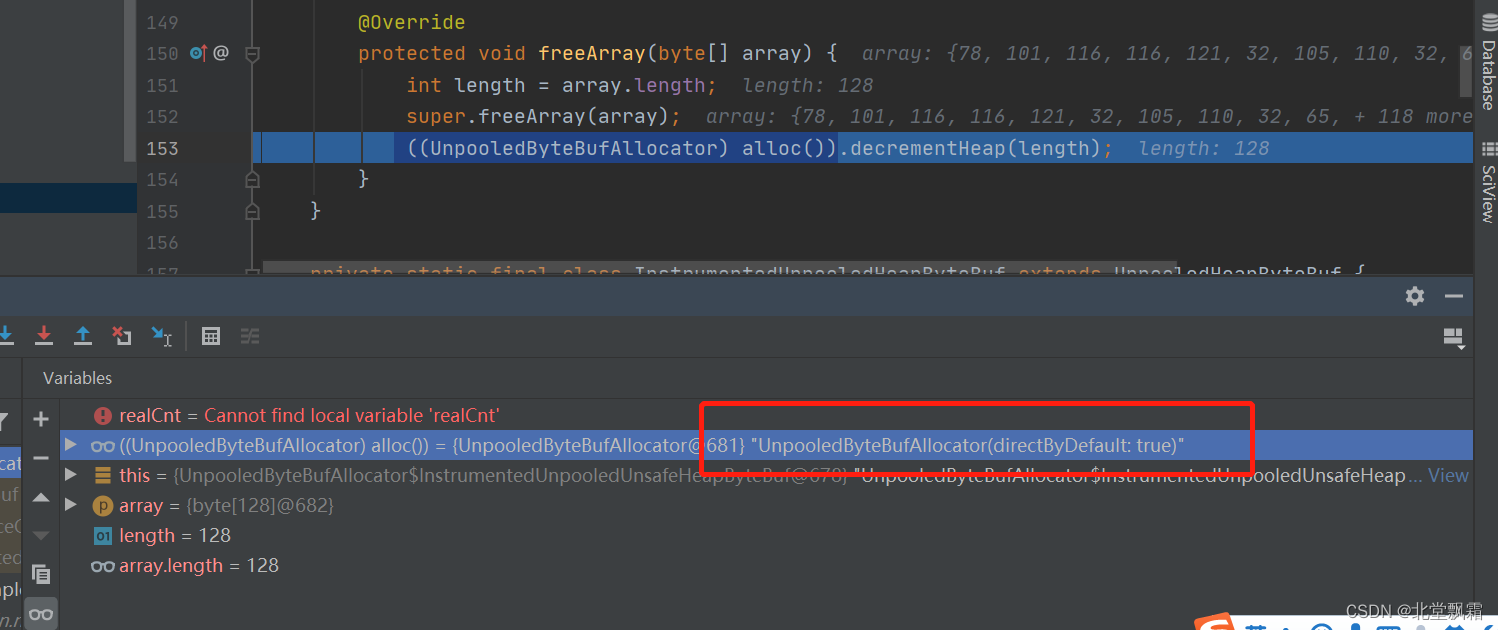
将Long(Heap)置为负数之后,直接释放内存。
这就是释放,那么增加引用,还有什么其他的逻辑应该都差不多,每次看到一些有趣的或者设计到工作内容的代码,我都忍不住进去看看源码。看大神是怎么实现的。以后我们遇到了,能不能用一样的手法,这就是阅读源码的附赠品,获得power是主产品。这个power是非常重要的,是关乎职业进阶的命脉,power够了,则早晚引发质变的。
回来,一个ReferenceCounted 我们不用关心当前引用值,只需在我们想释放的时候,让所有活动都失效就足够了。
结束语
这一把学习了ByteBuf容器,知道了优于JDK的地方,还搞了一些变体,并且何时去使用的例子,我们知道了
使用不同的读索引和写索引控制数据访问,
使用内存的不同方式 基于 heap 和 direct
通过CompositeByteBuf生成多个ByteBuf的聚合视图
数据访问方法,切片,搜索和复制
读写和设置API
ByteBufAllocate池化和引用计数
从源码上走了一下释放,满足了一下求知欲。
相关文章:
Read book Netty in action(Chapter VI)--ByteBuf
序言 之前学习了传输,通过前面的学习我们都知道,网络数据的基本单位是字节。JDK中提供了ByteBuffer作为字节的容器,但是过于繁琐复杂,Netty中提供了ByteBuf作为替代品。学习一下。 API Netty的数据处理API通过两个组件暴露 ---…...
VsCode开发工具的入门及基本使用
VsCode开发工具的入门及基本使用一、VsCode介绍1.VsCode简介2.VsCode特点二、安装VsCode1.下载VsCode2.安装VsCode3.打开VsCode三、设置VsCode中文1.搜索中文语言插件2.安装中文语言插件四、初识VsCode1.VsCode左侧栏模块2.系统设置功能五、VsCode初始配置1.禁用自动更新2.开启…...

python标准库——OS模块接口详解
OS系统操作模块 os模块提供各种Python 程序与操作系统进行交互的接口 os模块是整理文件和目录最常用的模块 函数作用补充os.sep()取代操作系统特定的路径分隔符os.name()指示你正在使用的工作平台。比如对于Windows,它是nt,而对于Linux/Unix用户&…...
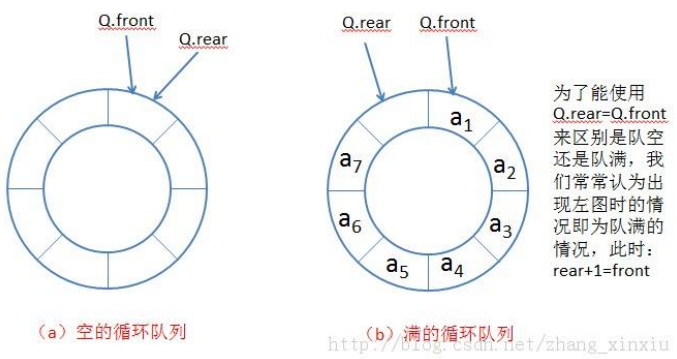
LeetCode 622.设计循环队列
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里&a…...
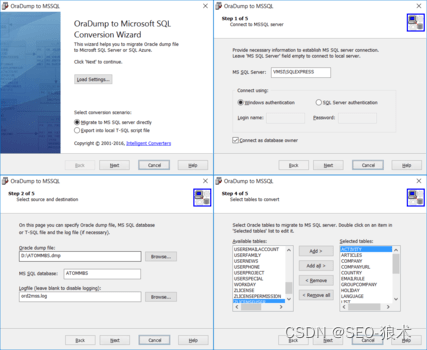
OraDump导出套件
OraDump导出套件 只需单击几下即可将数据从Oracle转储文件导出到流行的数据库和格式。 OraDump Export Kit是一个将数据从Oracle转储文件导出到流行数据库和格式的软件包。该产品具有高性能,因为它直接读取转储文件。命令行支持允许编写脚本、自动化和安排转换过程。…...

CVE-2022-22947 SpringCloud GateWay SPEL RCE 漏洞分析
漏洞概要 Spring Cloud Gateway 是Spring Cloud 生态中的API网关,包含限流、过滤等API治理功能。 Spring官方在2022年3月1日发布新版本修复了Spring Cloud Gateway中的一处代码注入漏洞。当actuator端点开启或暴露时,可以通过http请求修改路由ÿ…...
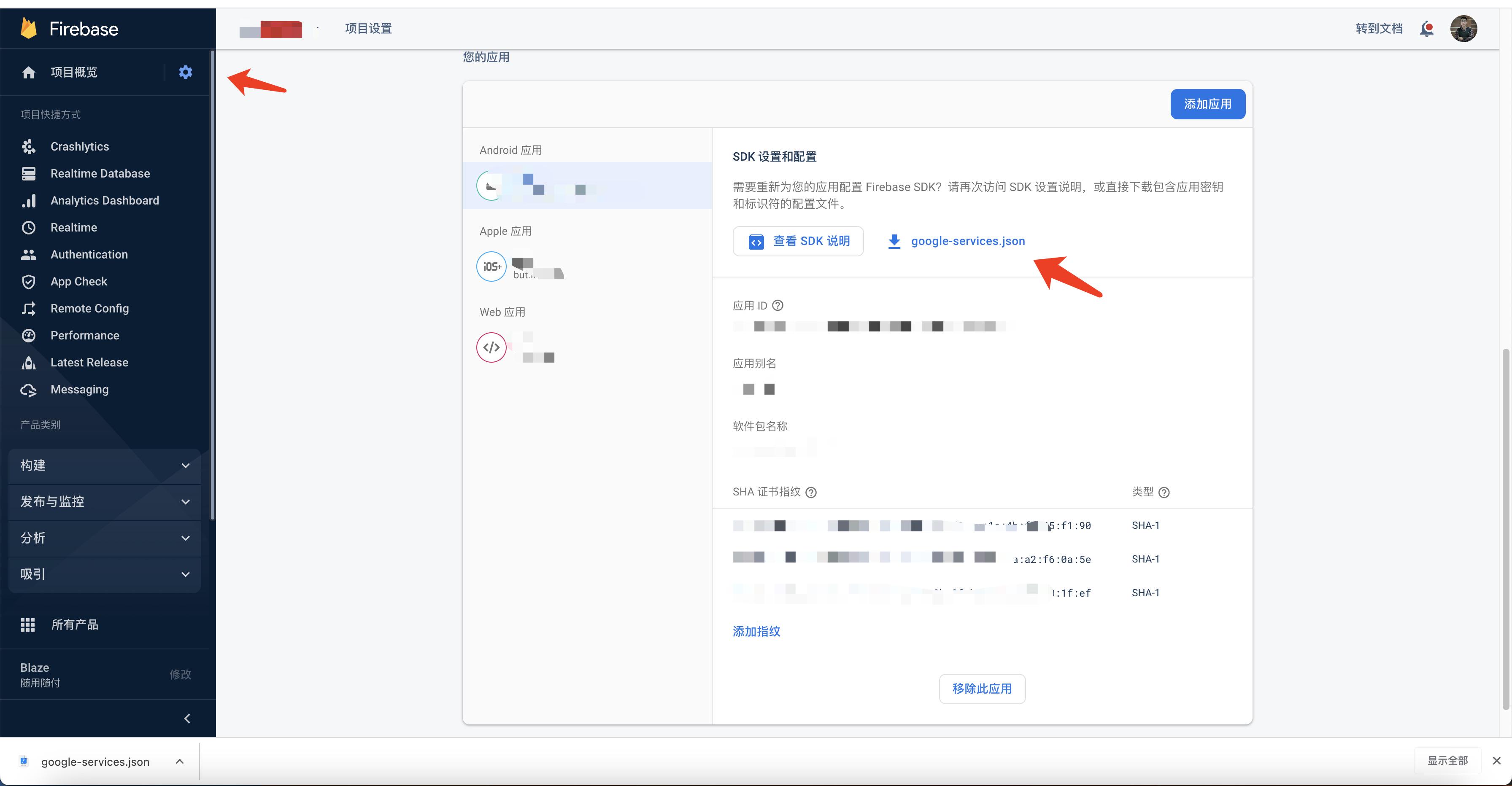
Firebase常用功能和官方Demo简介
一、Firebase简介Firebase刚开始是一家实时后端数据库创业公司,它能帮助开发者很快的写出Web端和移动端的应用。自2014年10月Google收购Firebase以来,用户可以在更方便地使用Firebase的同时,结合Google的云服务。现在的Firebase算是谷歌旗下的…...
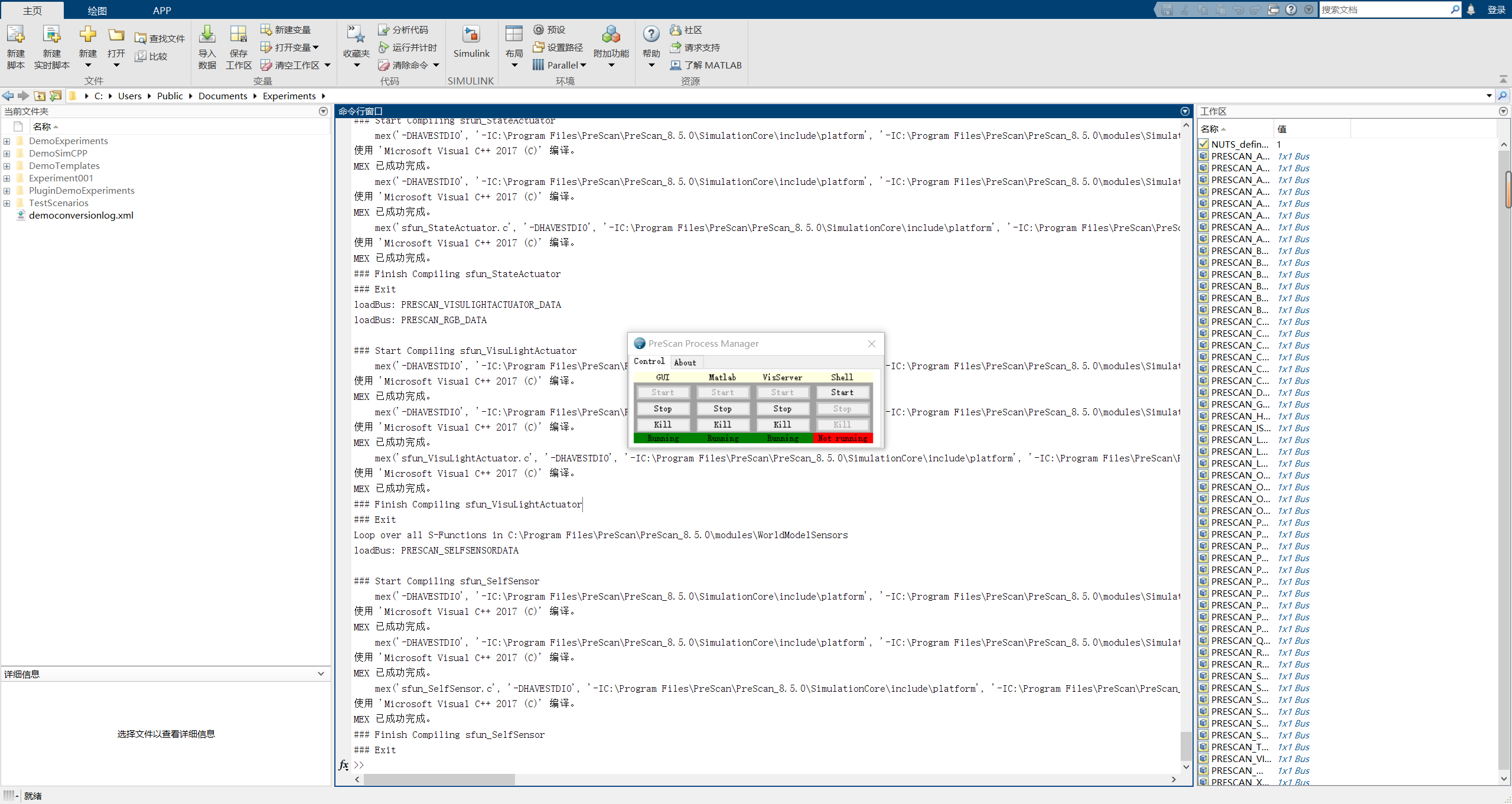
MATLAB R2020a 与PreScan8.5.0 详细安装教程(图文版)
目录MATLAB安装PreScan安装每文一语MATLAB安装 MATLAB是一款数学软件,用于科学计算、数据分析和可视化等任务。以下是MATLAB的几个优势: 丰富的工具箱:MATLAB拥有多种工具箱,包括信号处理、图像处理、优化、控制系统等࿰…...

CNI 网络流量 4.3 Calico felix
文章目录felix 太重要了,单独一文搞懂它Felix是一个守护程序,在每个 endpoints 的节点上运行。Felix 负责编制路由和 ACL 规则等,以便为该主机上的 endpoints 资源正常运行提供所需的网络连接 主要实现一下工作 管理网络接口,Feli…...

超声波风速风向传感器的通讯协议
接线定义 1 电源正 棕色线 4 风向信号 2 电源负 黑色线 5 485A 蓝色线 3 风速信号 6 485B 灰色线 ⊙寄存器参数表 地址 访问权限 参数名称 数据解析方法 0x0000 R 风速 瞬时 *100 上报 0x0001 R 风向 原数上报 0x0002 R 最大风速 *100 上报 0x0003 R 平均风速 *100 上报 0x000…...
—— 直接内存)
JVM笔记(8)—— 直接内存
一、什么是直接内存 直接内存不是虚拟机运行时数据区的一部分,是在运行时数据区外、直接向系统申请的内存空间。 通常,访问直接内存的速度会优于堆,读写性能更好。因此,出于性能考虑,读写频繁的场合可能会考虑使用直…...

Unity性能优化:如何优化Drawcall
前言 降低游戏的Drawcall,是渲染优化很重要的手段,接下来从以下4个方面来分析如何降低DrawCall: 对惹,这里有一个游戏开发交流小组,希望大家可以点击进来一起交流一下开发经验呀 降低Drawcall的意义是什么?如何查看游戏的Drawca…...

类与对象(this 关键字、构造器)
目录一、面向对象二、类与对象三、对象内存图四、成员变量和局部变量区别五、this关键字六、构造器/构造方法一、面向对象 一种编程思想:也就是说我们要以何种思路,解决问题,以何种形式组织代码 当解决一个问题的时候,面向对象会把事物抽象成…...
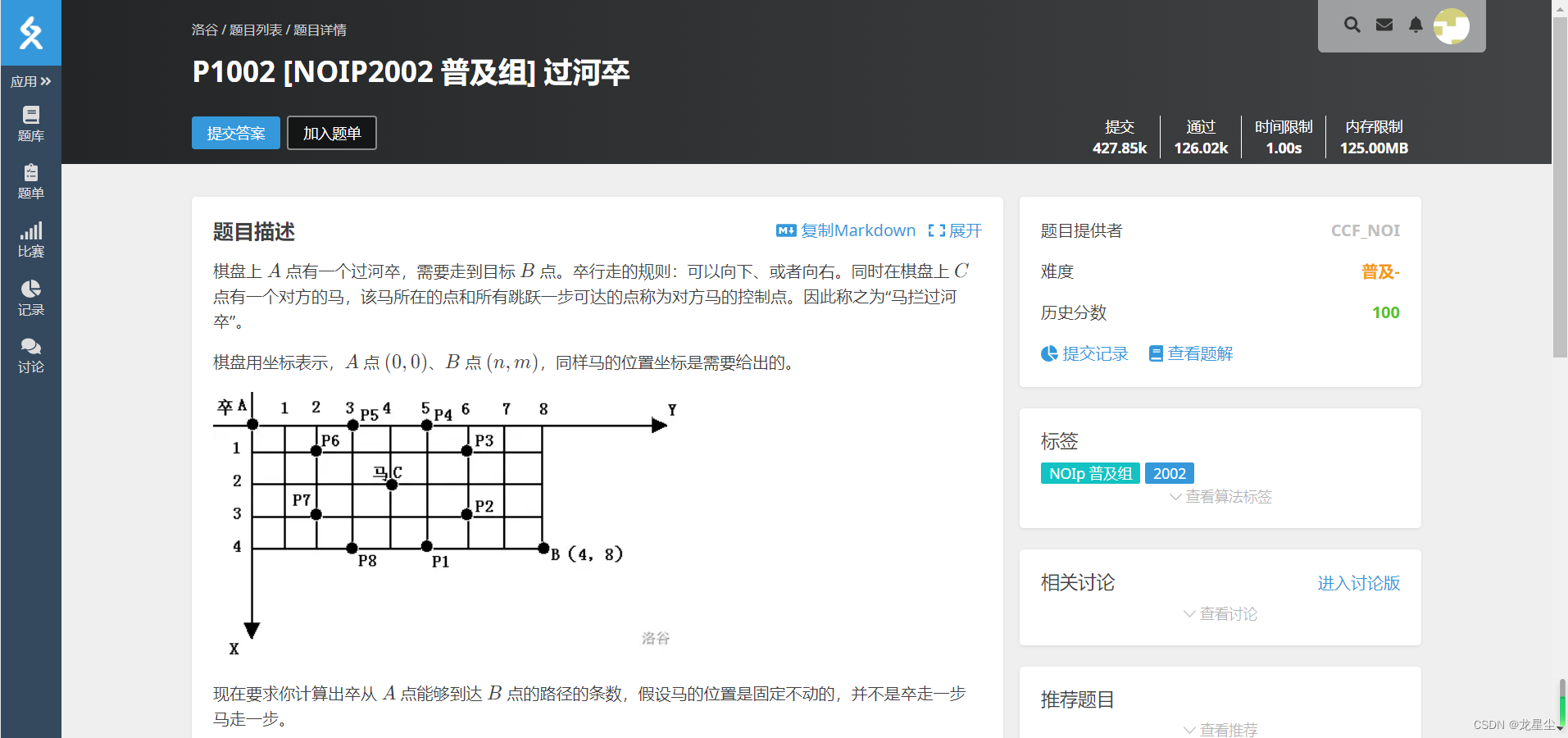
[NOIP2002 普及组] 过河卒
题目描述: 棋盘上 A 点有一个过河卒,需要走到目标 B 点。卒行走的规则:可以向下、或者向右。同时在棋盘上 C 点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点。因此称之为“马拦过河卒”。 棋盘用坐标表…...
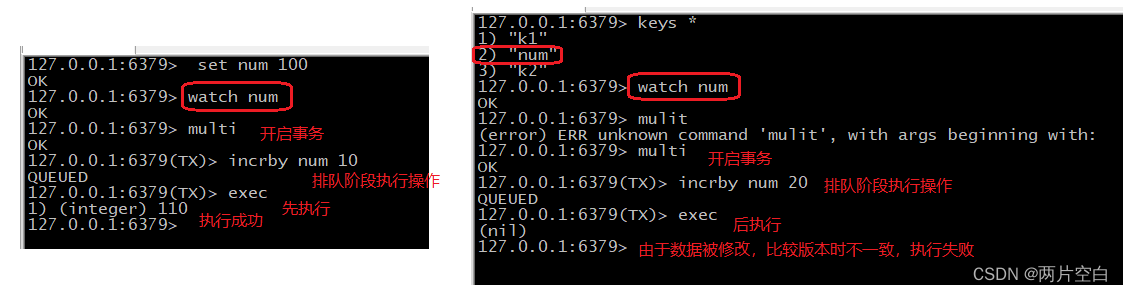
redis事务和锁机制
目录 事务定义 事务操作命令 redis事务的错误处理 redis事务冲突问题 redis解决事务冲突的方法 Redis事务的三个特性 事务定义 redis事务是一个单独的隔离操作:事务中的所有命令都会序列化,按顺序的执行。事务中在执行过程中,不会被其他客户…...

Java实例——线程
1、查看线程存活状态 Thread.isAlive() Thread.getName() public class MyThread extends Thread{Overridepublic void run() {for (int i 0; i < 10; i) {printMsg();}}public static void printMsg(){Thread thread Thread.currentThread();//Thread.getName() 获取线程…...

云计算学习课程——越来越重要的云安全
2023,越来越多的企业和组织正在或即将把核心系统和数据迁移上云端,其中以公有云和服务居多,那么就意味着在数据迁移的过程中会出现安全问题的几率更大。企业也越来越注重云安全体系,对我们云计算运维工程师来说,也是一…...
Android 高性能列表:RecyclerView + DiffUtil
文章目录背景介绍一般刷新 notifyDataSetChanged()局部刷新实现调用代码准备工作创建 MyDiffUtilCallback 类继承 DiffUtil.Callback 抽象类MyAdpter 类代码实现步骤总结通过 log 证实 diffutil 的局部刷新diffutil 优化后台线程参考主线程参考diff 更新优化后写法相关参考背景…...

为什么派生类的构造函数必须在初始化列表中调用基类的构造函数
调用派生类的构造函数时,可能会调用继承自基类的函数,也就可能会用到基类的数据成员,因此,调用派生类的构造函数时,必须确保继承自基类的数据成员已构造完毕,而将基类构造函数的调用写在初始化列表中&#…...

2023年2月初某企业网络工程师面试题【建议收藏】
拓扑图如下,主机A与主机B能互相通信,但是A不能ping通RA的F0接口,这是为什么?RA上f0接口上配置了ACL,禁止源ip为主机A,目的ip为RA f0的数据包的发送; 第一个路由器上只有到主机B网段的路由&#…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...