联邦学习-Tensorflow实现联邦模型AlexNet on CIFAR-10
目录
Client端
Server端
扩展
Client.py
Server.py
Dataset.py
Model.py

分享一种实现联邦学习的方法,它具有以下优点:
不需要读写文件来保存、切换Client模型
不需要在每次epoch重新初始化Client变量
内存占用尽可能小(参数量仅翻一倍,即Client端+Server端)
切换Client只增加了一些赋值操作
学习的目标是一个更好的模型,由Server保管,Clients提供更新
数据(Data)由Clients保管、使用文章的代码环境、库依赖:
Python 3.7
Tensorflow v1.14.x
tqdm(一个Python模块)
接下来本文会分成Client端、Server端代码设计与实现进行讲解。懒得看讲解的可以直接拉到最后的完整代码章节,共有四个代码文件,运行python Server.py即可以立马体验原汁原味的(单机模拟)联邦学习。
Client端
明确一下Client端的任务,包含下面三个步骤:
将Server端发来的模型变量加载到模型上
用自己的所有数据更新当前模型
将更新后的模型变量发回给Server
在这些任务下,我们可以设计出Client代码需要具备的一些功能:
创建、训练Tensorflow模型(也就是计算图)
加载Server端发过来的模型变量值
提取当前模型的变量值,发送给Server
维护自己的数据集用于训练
其实,仔细一想也就比平时写的tf模型代码多了个加载、提取模型变量。假设Client类已经构建好了模型,那么sess.run()一下每个变量,即可得到模型变量的值了。下面的代码展示了部分Clients类的定义,get_client_vars函数将返回计算图中所有可训练的变量值:
class Clients:
def __init__(self, input_shape, num_classes, learning_rate, clients_num):
self.graph = tf.Graph()
self.sess = tf.Session(graph=self.graph)
""" 本函数未完待续... """
def get_client_vars(self):
""" Return all of the variables list """
with self.graph.as_default():
client_vars = self.sess.run(tf.trainable_variables())
return client_vars
加载Server端发过来的global_vars到模型变量上,核心在于tf.Variable.load()函数,把一个Tensor的值加载到模型变量中,例如:
variable.load(tensor, sess)
将tensor(类型为tf.Tensor)的值赋值给variable(类型为tf.Varibale),sess是tf.Session。
如果要把整个模型中的变量值都加载,可以用tf.trainable_variables()获取计算图中的所有可训练变量(一个list),保证它和global_vars的顺序对应后,可以这样实现:
def set_global_vars(self, global_vars):
""" Assign all of the variables with global vars """
with self.graph.as_default():
all_vars = tf.trainable_variables()
for variable, value in zip(all_vars, global_vars):
variable.load(value, self.sess)
此外,Clients类还需要进行模型定义和训练。我相信这不是实现联邦的重点,因此在下面的代码中,我将函数体去掉只留下接口定义(完整代码在最后一个章节):
import tensorflow as tf
import numpy as np
from collections import namedtuple
import math
# 自定义的模型定义函数
from Model import AlexNet
# 自定义的数据集类
from Dataset import Dataset
# The definition of fed model
# 用namedtuple来储存一个模型,依次为:
# X: 输入
# Y: 输出
# DROP_RATE: 顾名思义
# train_op: tf计算图中的训练节点(一般是optimizer.minimize(xxx))
# loss_op: 顾名思义
# loss_op: 顾名思义
FedModel = namedtuple('FedModel', 'X Y DROP_RATE train_op loss_op acc_op')
class Clients:
def __init__(self, input_shape, num_classes, learning_rate, clients_num):
self.graph = tf.Graph()
self.sess = tf.Session(graph=self.graph)
# Call the create function to build the computational graph of AlexNet
# `net` 是一个list,依次包含模型中FedModel需要的计算节点(看上面)
net = AlexNet(input_shape, num_classes, learning_rate, self.graph)
self.model = FedModel(*net)
# initialize 初始化
with self.graph.as_default():
self.sess.run(tf.global_variables_initializer())
# Load Cifar-10 dataset
# NOTE: len(self.dataset.train) == clients_num
# 加载数据集。对于训练集:`self.dataset.train[56]`可以获取56号client的数据集
# `self.dataset.train[56].next_batch(32)`可以获取56号client的一个batch,大小为32
# 对于测试集,所有client共用一个测试集,因此:
# `self.dataset.test.next_batch(1000)`将获取大小为1000的数据集(无随机)
self.dataset = Dataset(tf.keras.datasets.cifar10.load_data,
split=clients_num)
def run_test(self, num):
"""
Predict the testing set, and report the acc and loss
预测测试集,返回准确率和loss
num: number of testing instances
"""
pass
def train_epoch(self, cid, batch_size=32, dropout_rate=0.5):
"""
Train one client with its own data for one epoch
用`cid`号的client的数据对模型进行训练
cid: Client id
"""
pass
def choose_clients(self, ratio=1.0):
"""
randomly choose some clients
随机选择`ratio`比例的clients,返回编号(也就是下标)
"""
client_num = self.get_clients_num()
choose_num = math.floor(client_num * ratio)
return np.random.permutation(client_num)[:choose_num]
def get_clients_num(self):
""" 返回clients的数量 """
return len(self.dataset.train)
细心的同学可能已经发现了,类名是Clients是复数,表示一堆Clients的集合。但模型self.model只有一个,原因是:不同Clients的模型实际上是一样的,只是数据不同;类成员self.dataset已经对数据进行了划分,需要不同client参与训练时,只需要用Server给的变量值把模型变量覆盖掉,再用下标cid找到该Client的数据进行训练就得了。
当然,这样实现的最重要原因,是避免构建那么多个Client的计算图。咱没那么多显存TAT
概括一下:联邦学习的Clients,只是普通TF训练模型代码上,加上模型变量的值提取、赋值功能。
Server端
按照套路,明确一下Server端代码的主要任务:
使用Clients:给一组模型变量给某个Client进行更新,把更新后的变量值拿回来
管理全局模型:每一轮更新,收集多个Clients更新后的模型进行归总,成为新一轮的模型
简单起见,我们Server端的代码不再抽象成一个类,而是以脚本的形式编写。首先,实例化咱们上面定义的Clients:
from Client import Clients
def buildClients(num):
learning_rate = 0.0001
num_input = 32 # image shape: 32*32
num_input_channel = 3 # image channel: 3
num_classes = 10 # Cifar-10 total classes (0-9 digits)
#create Client and model
return Clients(input_shape=[None, num_input, num_input, num_input_channel],
num_classes=num_classes,
learning_rate=learning_rate,
clients_num=num)
CLIENT_NUMBER = 100
client = buildClients(CLIENT_NUMBER)
global_vars = client.get_client_vars()
client变量储存着CLIENT_NUMBER个Clients的模型(实际上只有一个计算图)和数据。global_vars储存着Server端的模型变量值,也就是我们大名鼎鼎的训练目标,目前它只是Client端模型初始化的值。
接下来,对于Server的一个epoch,Server会随机挑选一定比例的Clients参与这轮训练,分别把当前的Server端模型global_vars交给它们进行更新,并分别收集它们更新后的变量。本轮参与训练的Clients都收集后,平均一下这些更新后的变量值,就得到新一轮的Server端模型,然后进行下一个epoch。下面是循环epoch更新的代码,仔细看注释哦:
def run_global_test(client, global_vars, test_num):
""" 跑一下测试集,输出ACC和Loss """
client.set_global_vars(global_vars)
acc, loss = client.run_test(test_num)
print("[epoch {}, {} inst] Testing ACC: {:.4f}, Loss: {:.4f}".format(
ep + 1, test_num, acc, loss))
CLIENT_RATIO_PER_ROUND = 0.12 # 每轮挑选clients跑跑看的比例
epoch = 360 # epoch上限
for ep in range(epoch):
# We are going to sum up active clients' vars at each epoch
# 用来收集Clients端的参数,全部叠加起来(节约内存)
client_vars_sum = None
# Choose some clients that will train on this epoch
# 随机挑选一些Clients进行训练
random_clients = client.choose_clients(CLIENT_RATIO_PER_ROUND)
# Train with these clients
# 用这些Clients进行训练,收集它们更新后的模型
for client_id in tqdm(random_clients, ascii=True):
# Restore global vars to client's model
# 将Server端的模型加载到Client模型上
client.set_global_vars(global_vars)
# train one client
# 训练这个下标的Client
client.train_epoch(cid=client_id)
# obtain current client's vars
# 获取当前Client的模型变量值
current_client_vars = client.get_client_vars()
# sum it up
# 把各个层的参数叠加起来
if client_vars_sum is None:
client_vars_sum = current_client_vars
else:
for cv, ccv in zip(client_vars_sum, current_client_vars):
cv += ccv
# obtain the avg vars as global vars
# 把叠加后的Client端模型变量 除以 本轮参与训练的Clients数量
# 得到平均模型、作为新一轮的Server端模型参数
global_vars = []
for var in client_vars_sum:
global_vars.append(var / len(random_clients))
# run test on 1000 instances
# 跑一下测试集、输出一下
run_global_test(client, global_vars, test_num=600)
经过那么一些轮的迭代,我们就可以得到Server端的训练好的模型参数global_vars了。虽然它逻辑很简单,但我希望观众老爷们能注意到其中的两个联邦点:Server端代码没有接触到数据;每次参与训练的Clients数量相对于整体来说是很少的。
扩展
如果要更换模型,只需要实现新的模型计算图构造函数,替换Client端的AlexNet函数,保证它能返回那一系列的计算节点即可。
如果要实现Non-I.I.D.的数据分布,只需要修改Dataset.py中的数据划分方式。但是,我稍微试验了一下,目前这个模型+训练方式,不能应对极度Non-I.I.D.的情况。也反面证明了,Non-I.I.D.确实是联邦学习的一个难题。
如果要Clients和Server之间传模型梯度,需要把Client端的计算梯度和更新变量分开,中间插入和Server端的交互,交互内容就是梯度。这样说有点抽象,很多同学可能经常用Optimizer.minimize(文档在这),但并不知道它是另外两个函数的组合,分别为:compute_gradients()和apply_gradients()。前者是计算梯度,后者是把梯度按照学习率更新到变量上。把梯度拿到后,交给Server,Server返回一个全局平均后的梯度再更新模型。尝试过是可行的,但是并不能减少传输量,而且单机模拟实现难度大了许多。
如果要分布式部署,那就把Clients端代码放在flask等web后端服务下进行部署,Server端通过网络传输与Clients进行通信。需要注意,Server端发起请求的时候,可能因为参数量太大导致一些问题,考虑换个非HTTP协议。
完整代码
一共有四个代码文件,他们应当放在同一个文件目录下:
Client.py:Client端代码,管理模型、数据
Server.py:Server端代码,管理Clients、全局模型
Dataset.py:定义数据的组织形式
Model.py:定义TF模型的计算图
我也将它们传到了Github上,仓库链接:https://github.com/Zing22/tf-fed-demo。
下面开始分别贴出它们的完整代码,其中的注释只有我边打码边写的一点点,上文的介绍中补充了更多中文注释。运行方法非常简单:
python Server.py
Client.py
import tensorflow as tf
import numpy as np
from collections import namedtuple
import math
from Model import AlexNet
from Dataset import Dataset
# The definition of fed model
FedModel = namedtuple('FedModel', 'X Y DROP_RATE train_op loss_op acc_op')
class Clients:
def __init__(self, input_shape, num_classes, learning_rate, clients_num):
self.graph = tf.Graph()
self.sess = tf.Session(graph=self.graph)
# Call the create function to build the computational graph of AlexNet
net = AlexNet(input_shape, num_classes, learning_rate, self.graph)
self.model = FedModel(*net)
# initialize
with self.graph.as_default():
self.sess.run(tf.global_variables_initializer())
# Load Cifar-10 dataset
# NOTE: len(self.dataset.train) == clients_num
self.dataset = Dataset(tf.keras.datasets.cifar10.load_data,
split=clients_num)
def run_test(self, num):
with self.graph.as_default():
batch_x, batch_y = self.dataset.test.next_batch(num)
feed_dict = {
self.model.X: batch_x,
self.model.Y: batch_y,
self.model.DROP_RATE: 0
}
return self.sess.run([self.model.acc_op, self.model.loss_op],
feed_dict=feed_dict)
def train_epoch(self, cid, batch_size=32, dropout_rate=0.5):
"""
Train one client with its own data for one epoch
cid: Client id
"""
dataset = self.dataset.train[cid]
with self.graph.as_default():
for _ in range(math.ceil(dataset.size / batch_size)):
batch_x, batch_y = dataset.next_batch(batch_size)
feed_dict = {
self.model.X: batch_x,
self.model.Y: batch_y,
self.model.DROP_RATE: dropout_rate
}
self.sess.run(self.model.train_op, feed_dict=feed_dict)
def get_client_vars(self):
""" Return all of the variables list """
with self.graph.as_default():
client_vars = self.sess.run(tf.trainable_variables())
return client_vars
def set_global_vars(self, global_vars):
""" Assign all of the variables with global vars """
with self.graph.as_default():
all_vars = tf.trainable_variables()
for variable, value in zip(all_vars, global_vars):
variable.load(value, self.sess)
def choose_clients(self, ratio=1.0):
""" randomly choose some clients """
client_num = self.get_clients_num()
choose_num = math.ceil(client_num * ratio)
return np.random.permutation(client_num)[:choose_num]
def get_clients_num(self):
return len(self.dataset.train)
Server.py
import tensorflow as tf
from tqdm import tqdm
from Client import Clients
def buildClients(num):
learning_rate = 0.0001
num_input = 32 # image shape: 32*32
num_input_channel = 3 # image channel: 3
num_classes = 10 # Cifar-10 total classes (0-9 digits)
#create Client and model
return Clients(input_shape=[None, num_input, num_input, num_input_channel],
num_classes=num_classes,
learning_rate=learning_rate,
clients_num=num)
def run_global_test(client, global_vars, test_num):
client.set_global_vars(global_vars)
acc, loss = client.run_test(test_num)
print("[epoch {}, {} inst] Testing ACC: {:.4f}, Loss: {:.4f}".format(
ep + 1, test_num, acc, loss))
#### SOME TRAINING PARAMS ####
CLIENT_NUMBER = 100
CLIENT_RATIO_PER_ROUND = 0.12
epoch = 360
#### CREATE CLIENT AND LOAD DATASET ####
client = buildClients(CLIENT_NUMBER)
#### BEGIN TRAINING ####
global_vars = client.get_client_vars()
for ep in range(epoch):
# We are going to sum up active clients' vars at each epoch
client_vars_sum = None
# Choose some clients that will train on this epoch
random_clients = client.choose_clients(CLIENT_RATIO_PER_ROUND)
# Train with these clients
for client_id in tqdm(random_clients, ascii=True):
# Restore global vars to client's model
client.set_global_vars(global_vars)
# train one client
client.train_epoch(cid=client_id)
# obtain current client's vars
current_client_vars = client.get_client_vars()
# sum it up
if client_vars_sum is None:
client_vars_sum = current_client_vars
else:
for cv, ccv in zip(client_vars_sum, current_client_vars):
cv += ccv
# obtain the avg vars as global vars
global_vars = []
for var in client_vars_sum:
global_vars.append(var / len(random_clients))
# run test on 600 instances
run_global_test(client, global_vars, test_num=600)
#### FINAL TEST ####
run_global_test(client, global_vars, test_num=10000)
Dataset.py
import numpy as np
from tensorflow.keras.utils import to_categorical
class BatchGenerator:
def __init__(self, x, yy):
self.x = x
self.y = yy
self.size = len(x)
self.random_order = list(range(len(x)))
np.random.shuffle(self.random_order)
self.start = 0
return
def next_batch(self, batch_size):
perm = self.random_order[self.start:self.start + batch_size]
self.start += batch_size
if self.start > self.size:
self.start = 0
return self.x[perm], self.y[perm]
# support slice
def __getitem__(self, val):
return self.x[val], self.y[val]
class Dataset(object):
def __init__(self, load_data_func, one_hot=True, split=0):
(x_train, y_train), (x_test, y_test) = load_data_func()
print("Dataset: train-%d, test-%d" % (len(x_train), len(x_test)))
if one_hot:
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
if split == 0:
self.train = BatchGenerator(x_train, y_train)
else:
self.train = self.splited_batch(x_train, y_train, split)
self.test = BatchGenerator(x_test, y_test)
def splited_batch(self, x_data, y_data, split):
res = []
for x, y in zip(np.split(x_data, split), np.split(y_data, split)):
assert len(x) == len(y)
res.append(BatchGenerator(x, y))
return res
Model.py
import tensorflow as tf
import numpy as np
from tensorflow.compat.v1.train import AdamOptimizer
#### Create tf model for Client ####
def AlexNet(input_shape, num_classes, learning_rate, graph):
"""
Construct the AlexNet model.
input_shape: The shape of input (`list` like)
num_classes: The number of output classes (`int`)
learning_rate: learning rate for optimizer (`float`)
graph: The tf computation graph (`tf.Graph`)
"""
with graph.as_default():
X = tf.placeholder(tf.float32, input_shape, name='X')
Y = tf.placeholder(tf.float32, [None, num_classes], name='Y')
DROP_RATE = tf.placeholder(tf.float32, name='drop_rate')
# 1st Layer: Conv (w ReLu) -> Lrn -> Pool
# conv1 = conv(X, 11, 11, 96, 4, 4, padding='VALID', name='conv1')
conv1 = conv(X, 11, 11, 96, 2, 2, name='conv1')
norm1 = lrn(conv1, 2, 2e-05, 0.75, name='norm1')
pool1 = max_pool(norm1, 3, 3, 2, 2, padding='VALID', name='pool1')
# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups
conv2 = conv(pool1, 5, 5, 256, 1, 1, groups=2, name='conv2')
norm2 = lrn(conv2, 2, 2e-05, 0.75, name='norm2')
pool2 = max_pool(norm2, 3, 3, 2, 2, padding='VALID', name='pool2')
# 3rd Layer: Conv (w ReLu)
conv3 = conv(pool2, 3, 3, 384, 1, 1, name='conv3')
# 4th Layer: Conv (w ReLu) splitted into two groups
conv4 = conv(conv3, 3, 3, 384, 1, 1, groups=2, name='conv4')
# 5th Layer: Conv (w ReLu) -> Pool splitted into two groups
conv5 = conv(conv4, 3, 3, 256, 1, 1, groups=2, name='conv5')
pool5 = max_pool(conv5, 3, 3, 2, 2, padding='VALID', name='pool5')
# 6th Layer: Flatten -> FC (w ReLu) -> Dropout
# flattened = tf.reshape(pool5, [-1, 6*6*256])
# fc6 = fc(flattened, 6*6*256, 4096, name='fc6')
flattened = tf.reshape(pool5, [-1, 1 * 1 * 256])
fc6 = fc_layer(flattened, 1 * 1 * 256, 1024, name='fc6')
dropout6 = dropout(fc6, DROP_RATE)
# 7th Layer: FC (w ReLu) -> Dropout
# fc7 = fc(dropout6, 4096, 4096, name='fc7')
fc7 = fc_layer(dropout6, 1024, 2048, name='fc7')
dropout7 = dropout(fc7, DROP_RATE)
# 8th Layer: FC and return unscaled activations
logits = fc_layer(dropout7, 2048, num_classes, relu=False, name='fc8')
# loss and optimizer
loss_op = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,
labels=Y))
optimizer = AdamOptimizer(
learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model
prediction = tf.nn.softmax(logits)
pred = tf.argmax(prediction, 1)
# accuracy
correct_pred = tf.equal(pred, tf.argmax(Y, 1))
accuracy = tf.reduce_mean(
tf.cast(correct_pred, tf.float32))
return X, Y, DROP_RATE, train_op, loss_op, accuracy
def conv(x, filter_height, filter_width, num_filters,
stride_y, stride_x, name, padding='SAME', groups=1):
"""Create a convolution layer.
Adapted from: https://github.com/ethereon/caffe-tensorflow
"""
# Get number of input channels
input_channels = int(x.get_shape()[-1])
# Create lambda function for the convolution
convolve = lambda i, k: tf.nn.conv2d(
i, k, strides=[1, stride_y, stride_x, 1], padding=padding)
with tf.variable_scope(name) as scope:
# Create tf variables for the weights and biases of the conv layer
weights = tf.get_variable('weights',
shape=[
filter_height, filter_width,
input_channels / groups, num_filters
])
biases = tf.get_variable('biases', shape=[num_filters])
if groups == 1:
conv = convolve(x, weights)
# In the cases of multiple groups, split inputs & weights and
else:
# Split input and weights and convolve them separately
input_groups = tf.split(axis=3, num_or_size_splits=groups, value=x)
weight_groups = tf.split(axis=3,
num_or_size_splits=groups,
value=weights)
output_groups = [
convolve(i, k) for i, k in zip(input_groups, weight_groups)
]
# Concat the convolved output together again
conv = tf.concat(axis=3, values=output_groups)
# Add biases
bias = tf.reshape(tf.nn.bias_add(conv, biases), tf.shape(conv))
# Apply relu function
relu = tf.nn.relu(bias, name=scope.name)
return relu
def fc_layer(x, input_size, output_size, name, relu=True, k=20):
"""Create a fully connected layer."""
with tf.variable_scope(name) as scope:
# Create tf variables for the weights and biases.
W = tf.get_variable('weights', shape=[input_size, output_size])
b = tf.get_variable('biases', shape=[output_size])
# Matrix multiply weights and inputs and add biases.
z = tf.nn.bias_add(tf.matmul(x, W), b, name=scope.name)
if relu:
# Apply ReLu non linearity.
a = tf.nn.relu(z)
return a
else:
return z
def max_pool(x,
filter_height, filter_width,
stride_y, stride_x,
name, padding='SAME'):
"""Create a max pooling layer."""
return tf.nn.max_pool2d(x,
ksize=[1, filter_height, filter_width, 1],
strides=[1, stride_y, stride_x, 1],
padding=padding,
name=name)
def lrn(x, radius, alpha, beta, name, bias=1.0):
"""Create a local response normalization layer."""
return tf.nn.local_response_normalization(x,
depth_radius=radius,
alpha=alpha,
beta=beta,
bias=bias,
name=name)
def dropout(x, rate):
"""Create a dropout layer."""
return tf.nn.dropout(x, rate=rate)
相关文章:
联邦学习-Tensorflow实现联邦模型AlexNet on CIFAR-10
目录 Client端 Server端 扩展 Client.py Server.py Dataset.py Model.py 分享一种实现联邦学习的方法,它具有以下优点: 不需要读写文件来保存、切换Client模型 不需要在每次epoch重新初始化Client变量 内存占用尽可能小(参数量仅翻一…...
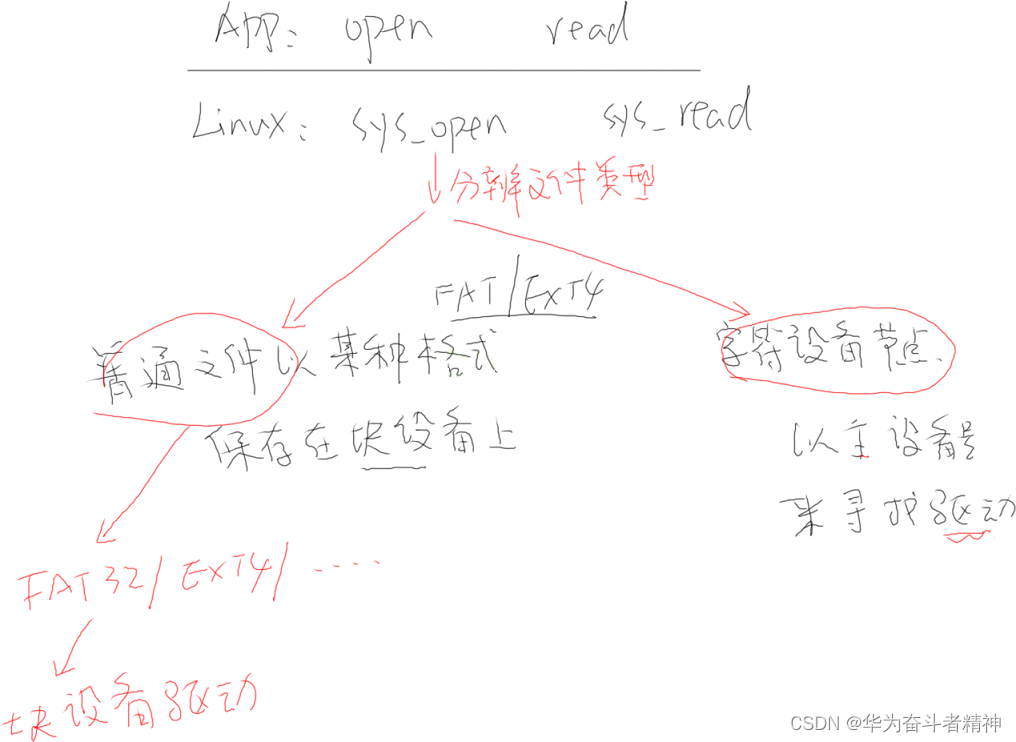
嵌入式Linux应用开发-文件 IO
嵌入式Linux应用开发-文件 IO 第四章 文件 IO4.1 文件从哪来?4.2 怎么访问文件?4.2.1 通用的 IO 模型:open/read/write/lseek/close4.2.2 不是通用的函数:ioctl/mmap 4.3 怎么知道这些函数的用法?4.4 系统调用函数怎么…...

【C++】多态,从使用到底层。
文章目录 前言一、多态的概念二、多太的定义和实现2.1 多太的构造条件2.2 虚函数2.3 重写(覆盖)2.4 C11 override 和 final2.5 重载,隐藏,重写 三、多态的原理3. 1虚函数表3.2 虚函数表如何完成多态的功能3.3 虚函数表存储在内存空间的那个区域ÿ…...

uvm白皮书练习_ch2_ch221只有driver的验证平台之*2.2.1 最简单的验证平台
uvm白皮书练习 ch221 dut.sv 这个DUT的功能非常简单,通过rxd接收数据,再通过txd发送出去。其中rx_dv是接收的数据有效指示,tx_en是发送的数据有效指示。 module dut (clk,rst_n,rxd,rx_dv,txd,tx_en );input clk ; input rst_n ; in…...

服务断路器_Resilience4j超时降级
创建模块cloud-consumer-resilience4j-order80 POM引入依赖 <dependencies><!-- 引入Eureka 客户端依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</a…...

【知识点随笔分析】我看看谁还不会用CURL命令
目录 前言: CURL介绍: CURL的基本使用: CURL与PING命令的区别: CURL命令的应用: 总结: 前言: 当今互联网时代,与服务器进行数据交互成为了无法回避的需求。无论是获取Web…...
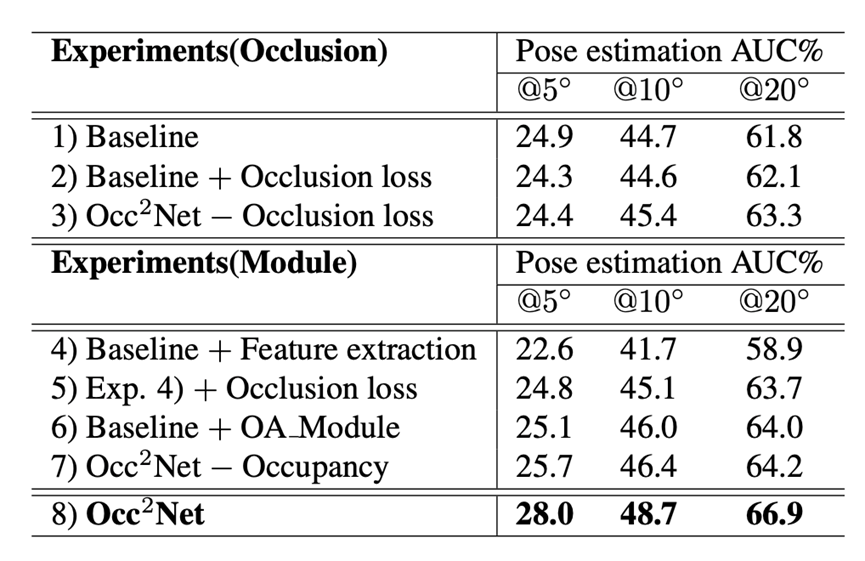
ICCV 2023|Occ2Net,一种基于3D 占据估计的有效且稳健的带有遮挡区域的图像匹配方法...
本文为大家介绍一篇入选ICCV 2023的论文,《Occ2Net: Robust Image Matching Based on 3D Occupancy Estimation for Occluded Regions》, 一种基于3D 占据估计的有效且稳健的带有遮挡区域的图像匹配方法。 论文链接:https://arxiv.org/abs/23…...

leetcode - 14. Longest Common Prefix
Description Write a function to find the longest common prefix string amongst an array of strings. If there is no common prefix, return an empty string “”. Example 1: Input: strs ["flower","flow","flight"] Output: "…...
结构(查询操作 一))
MySQL-查询语句语法(DQL)结构(查询操作 一)
SQL语句 编写顺序 - 执行顺序 1、SELECT 字段列表 4 2、FROM 表名列表 1 3、WHERE 条件列表 2 4、GROUP BY 分组字段列表 …...
SWAT-MODFLOW地表水与地下水耦合
耦合模型被应用到很多科学和工程领域来改善模型的性能、效率和结果,SWAT作为一个地表水模型可以较好的模拟主要的水文过程,包括地表径流、降水、蒸发、风速、温度、渗流、侧向径流等,但是对于地下水部分的模拟相对粗糙,考虑到SWAT…...
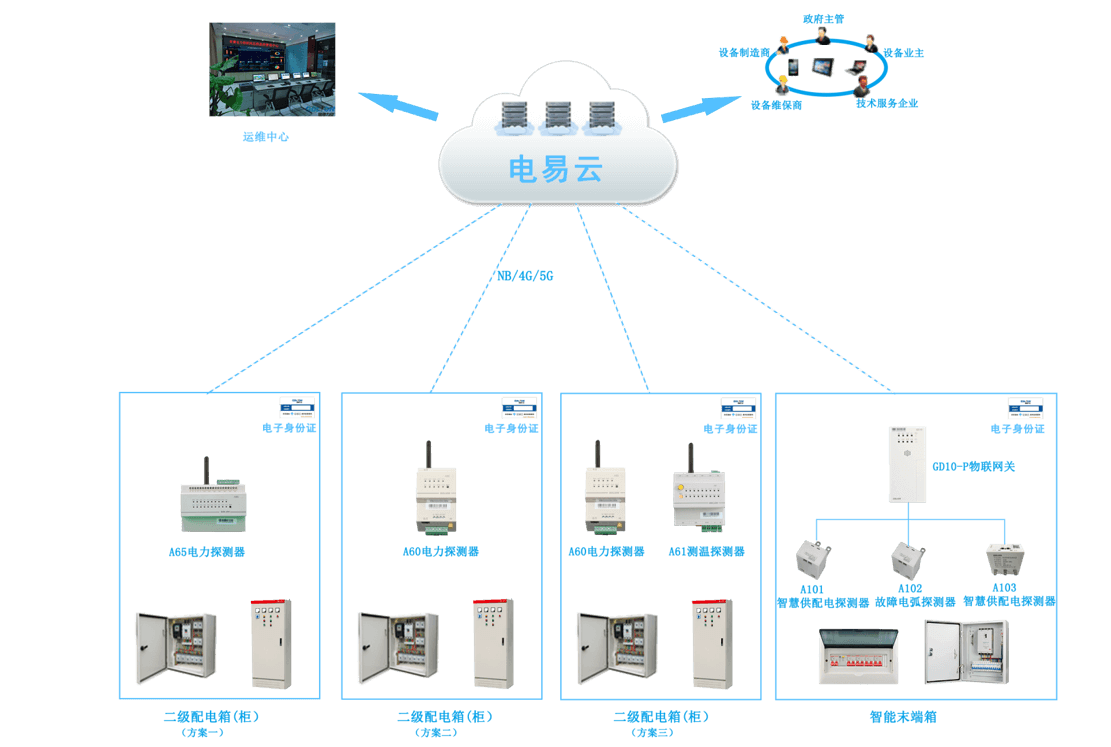
工地临时用电之智慧用电:全方位保障用电安全
随着科技进步和智能化的发展,工地用电管理也迎来了智慧化的革新。智慧用电,作为智慧工地的重要组成部分,通过集中式管理和创新的技术手段,为工地提供了全方位的用电安全保障。 针对工地临时用 的现状及系统结构,力安科…...

JumpServer开源堡垒机与爱可生云树数据库完成兼容性认证
近日,中国领先的开源软件提供商FIT2CLOUD飞致云宣布,JumpServer开源堡垒机已经完成与爱可生云树数据库软件的兼容性认证。经过双方联合测试,云树数据库软件(简称:ActionDB)V1.0与杭州飞致云信息科技有限公司…...

信息化发展64
信息化体系 信息化代表了一种信息技术被高度应用,信息资源被高度共享,从而使得人的智能潜力以及社会物质资源潜力被充分发挥,个人行为、组织决策和社会运行趋于合理化的理想状态。 1997年召开的首届全国信息化工作会议,对信息化和…...

什么是全媒体整合营销?如何做好全媒体整合营销呢?
互联网发展进入深水区,目前营销大部分工作都与网络有关,网络营销形成各种分支,媒体平台的类型越来越多,如今的互联网发展背景下企业如何做好网络营销呢?小马识途营销顾问团队普遍认为企业当今应该开展的全媒体整合营销…...
系统集成|第十六章(笔记)
目录 第十六章 信息(文档)和配置管理16.1 文档管理16.2 配置管理 上篇:第十五章、采购管理 下篇:第十七章、变更管理 第十六章 信息(文档)和配置管理 16.1 文档管理 信息系统项目相关信息(文档…...
hive数据库操作,hive函数,FineBI可视化操作
1、数据库操作 1.1、创建数据库 create database if not exists myhive;use myhive;1.2、查看数据库详细信息 desc database myhive;数据库本质上就是在HDFS之上的文件夹。 默认数据库的存放路径是HDFS的:/user/hive/warehouse内 1.3、创建数据库并指定hdfs存…...
 | 洛谷 P7910 [CSP-J 2021] 插入排序)
信息学奥赛一本通 2075:【21CSPJ普及组】插入排序(sort) | 洛谷 P7910 [CSP-J 2021] 插入排序
【题目链接】 ybt 2075:【21CSPJ普及组】插入排序(sort) 洛谷 P7910 [CSP-J 2021] 插入排序 【题目考点】 1. 排序: 插入排序 插入排序示例: #include <bits/stdc.h> using namespace std; int main() {int…...

基于微信小程序的民宿短租酒店预订系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言系统主要功能:具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计…...
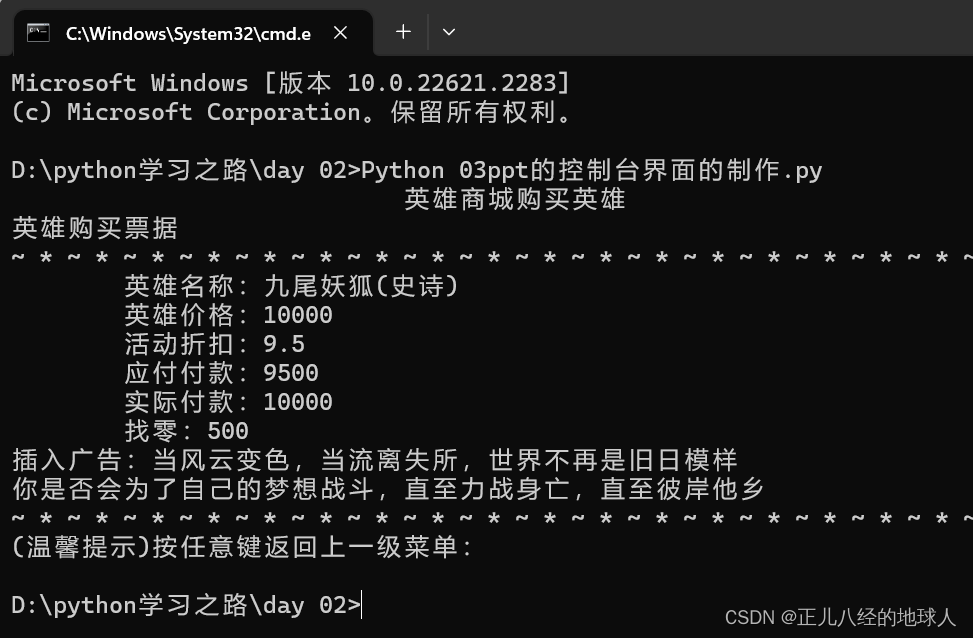
Python第二次作业(2)【控制台界面】
要求:使用Python输出五个控制台界面 第一张: 代码如下: print(" 英雄联盟商城登录界面 ") print("~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*~*") print(" 1.用户登录 &q…...
时报错的解决)
conda创建环境在Collecting package metadata (current_repodata.json)时报错的解决
conda创建环境在Collecting package metadata (current_repodata.json)时报错的解决 报错信息: Collecting package metadata (current_repodata.json): - ERROR conda.auxlib.logz:stringify(171): Traceback (most recent call last): File “C:\Users\dandelion…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...