MySQL高级语句(第一部分)
- MySQL高级语句(第一部分)
- 一、MySQL进阶查询
- 1、select ----显示表格中一个或数个字段的所有数据记录
- 2、distinct ----不显示重复的数据记录
- 3、where ----有条件查询
- 4、and or ----且 或
- 5、in ----显示已知的值的数据记录
- 6、between ----显示两个值范围内的数据记录
- 7、通配符
- 8、like ----模糊匹配
- 9、order by
- 10、group by----汇总分组
- 11、having
- 12、别名 ----字段別名 表格別名
- 13、子查询
- 14、exists
- 15、练习
- 二、MySQL数据库函数
- 1、数学函数
- 2、聚合函数
- 3、字符串函数
- 3.1 trim
- 3.2 concat
- 3.3 substr
- 3.4 length
- 3.5 replace
- 三、连接查询
- 1、表连接
- 2、union语句
- 3、多表查询之求交集值
- 4、多表查询之求无交集值
- 四、SQL语句执行顺序
MySQL高级语句(第一部分)
一、MySQL进阶查询
先建立www数据库,再建立location 表和Store_Info 表,用于测试和演示
create database www;use www;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
1、select ----显示表格中一个或数个字段的所有数据记录
语法:select "字段" from "表名";
举例
select * from store_info;
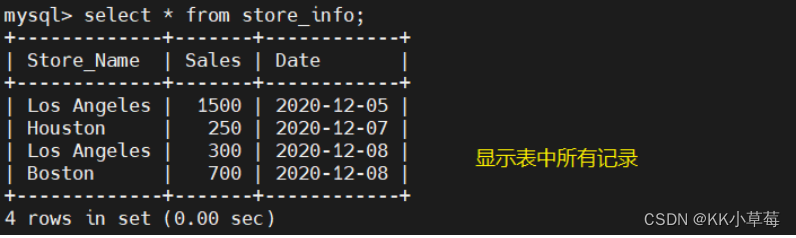
select store_name from store_info;

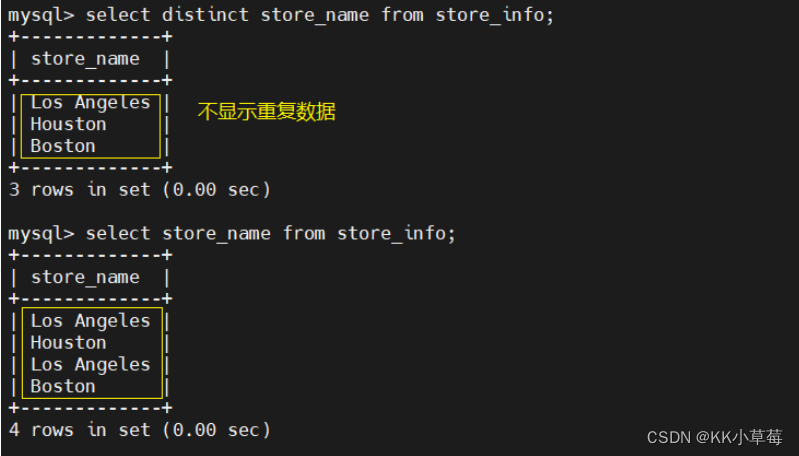
2、distinct ----不显示重复的数据记录
语法:select distinct "字段" from "表名";
举例:
select distinct store_name from store_info;
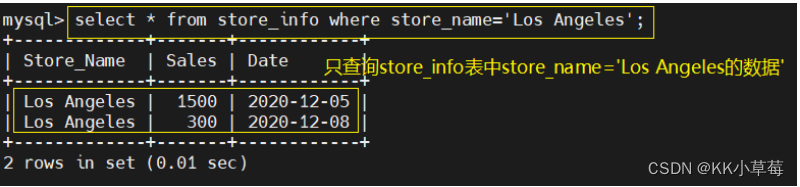
3、where ----有条件查询
语法:select "字段" from "表名" where "条件";
举例
select * from store_info where store_name='Los Angeles';
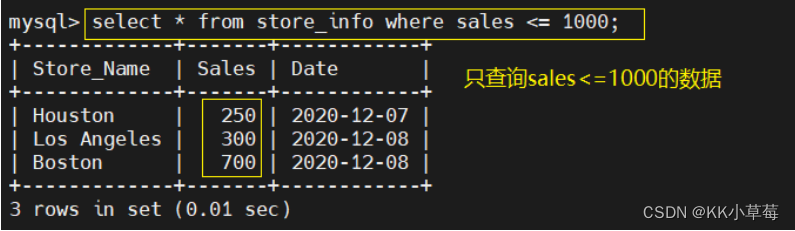
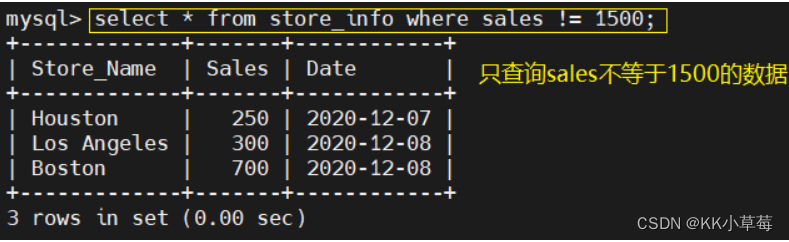
select * from store_info where sales <= 1000;
select * from store_info where sales != 1500;
# !=不等于
4、and or ----且 或
语法:select "字段" from "表名" where "条件1" {[and|or] "条件2"}+ ;
举例
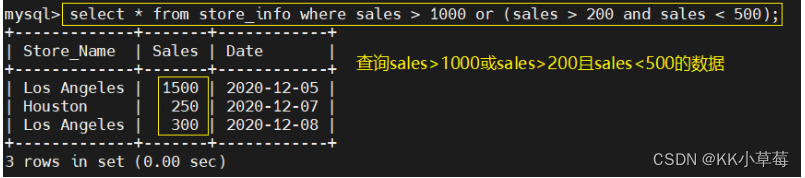
select * from store_info where sales > 1000 or (sales > 200 and sales < 500);
#sales>1000或sales>200且sales<500
5、in ----显示已知的值的数据记录
语法:select "字段" from "表名" where "字段" in ('值1', '值2', ...);
举例
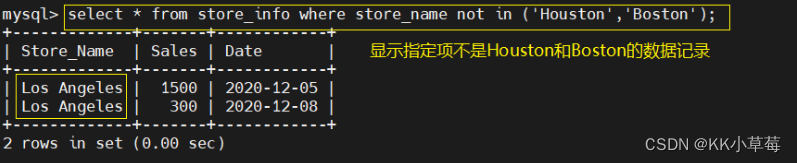
select * from store_info where store_name in ('Houston','Boston');
#显示指定项的数据记录

select * from store_info where store_name not in ('Houston','Boston');
6、between ----显示两个值范围内的数据记录
语法:select "字段" from "表名" where "字段" between '值1' and '值2';
举例
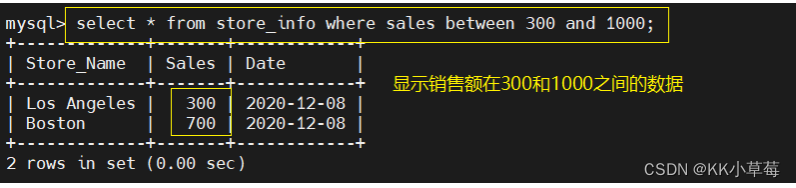
select * from store_info where sales between 300 and 1000;
7、通配符
----通常通配符都是跟 like 一起使用的
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
8、like ----模糊匹配
----匹配一个模式来找出我们要的数据记录
模糊匹配默认会扫描全表,索引不生效
语法:select "字段" from "表名" where "字段" like {模式};
举例
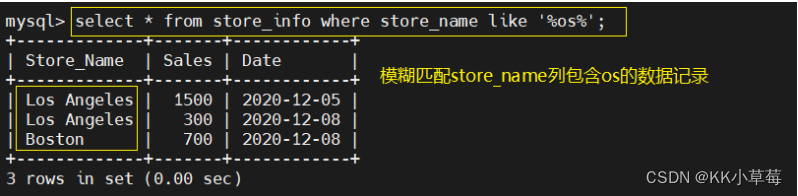
select * from store_info where store_name like '%os%';
#模糊匹配store_name列包含os的数据记录
9、order by
----按关键字排序
语法:select "字段" from "表名" [where "条件"] order by "字段" [asc, desc];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
#举例
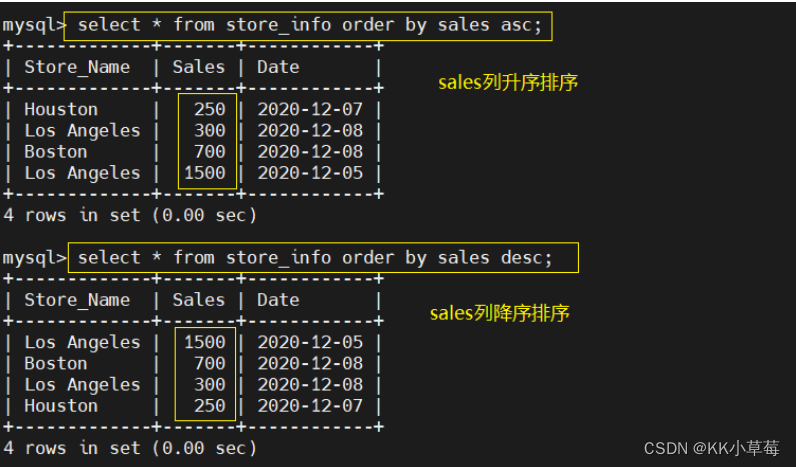
select * from store_info order by sales asc;
#升序排序
select * from store_info order by sales desc;
#降序排序
10、group by----汇总分组
----对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:select "字段1", sum("字段2") from "表名" group by "字段1";
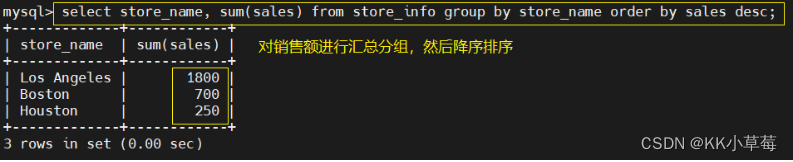
select store_name, sum(sales) from store_info group by store_name order by sales desc;
#汇总销售总额然后排序
11、having
----用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:select "字段1", sum("字段2") from "表格名" group by "字段1" having (函数条件);
select store_name, sum(sales) from store_info group by store_name having sum(sales) > 1500;
#返回sales>1500的数据

12、别名 ----字段別名 表格別名
语法:select "表格別名"."字段1" [as] "字段別名" from "表格名" [as] "表格別名";
#举个例子
select a.store_name store, sum(a.sales) as "total sales" from store_info as a group by a.store_name;
#sum函数别名定义为total sales,as可省略,store_info表,别名定义为a,别名定义后,当前SQL语句中所有用到store_info表的地方,都能用a代替

13、子查询
----连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:select "字段1" from "表格1" where "字段2" [比较运算符] (select "字段1" from "表格2" where "条件");
#外查询 (#内查询)
#内查询的结果,作为外查询的参数[比较运算符]
#可以是符号的运算符,例如 =、>、<、>=、<=
#也可以是文字的运算符,例如 like、in、between
#举例1
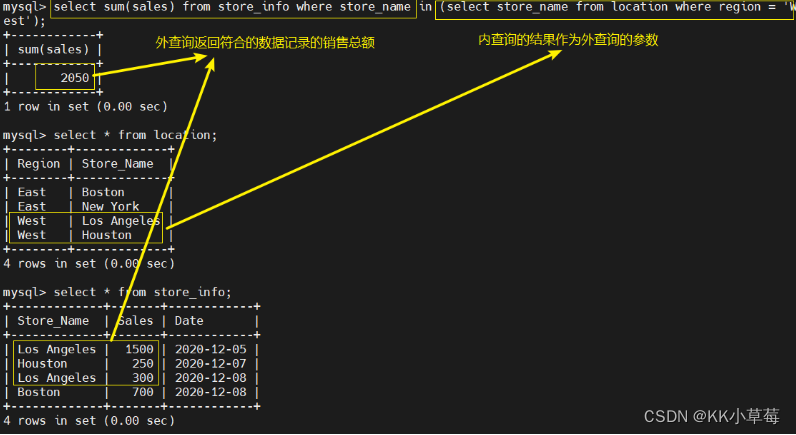
select sum(sales) from store_info where store_name in (select store_name from location where region = 'West');
#外查询返回符合的数据记录的销售总额
#内查询的结果作为外查询的参数
#举例2
select sum(A.sales) from store_info as A where A.store_name in (select store_name from location as B where B.store_name = A.store_name);
#store_info表 别名为A表,在当前语句中,可以直接用a代替store_info使用
#location表 别名为B表

14、exists
用来测试内查询有没有产生任何结果,类似布尔值是否为真
如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果
语法:select "字段1" from "表格1" where exists (select * from "表格2" where "条件";
#举个例子
select sum(sales) from store_info where exists (select * from location where region = 'West');
#存在region为West的数据记录继续执行外查询
select sum(sales) from store_info where exists (select store_name from location where region ='Westt');
#不存在region为Westt的数据记录不会继续执行外查询,返回Null
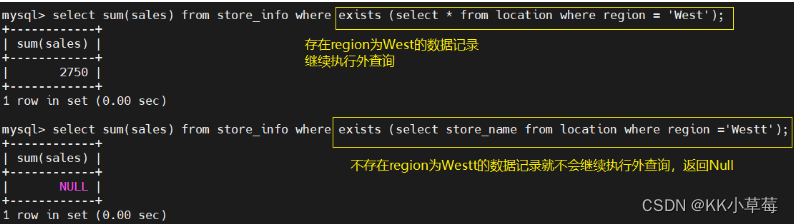
15、练习
group by store_name having count(store_name) >=2;select store_name from store_info group by store_name having count(store_name) >=2;select store_name,count(store_name) from store_info group by store_name having count(store_name) >=2;

二、MySQL数据库函数
1、数学函数
| 数字函数 | 功能 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2…) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2…) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
select abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
#-1的绝对值,随机数,5 3取余数,2的3次方,1.89四舍五入

select round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);
#1.8937第三位四舍五入,1.235取2位小数,大于或者等于5.2的整数,<=2.1的整数,合集中的最小值

2、聚合函数
| 聚合函数 | 功能 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
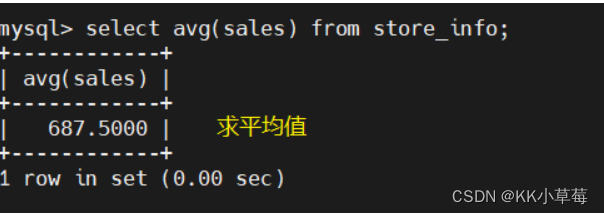
avg
select avg(sales) from store_info;
#求平均值
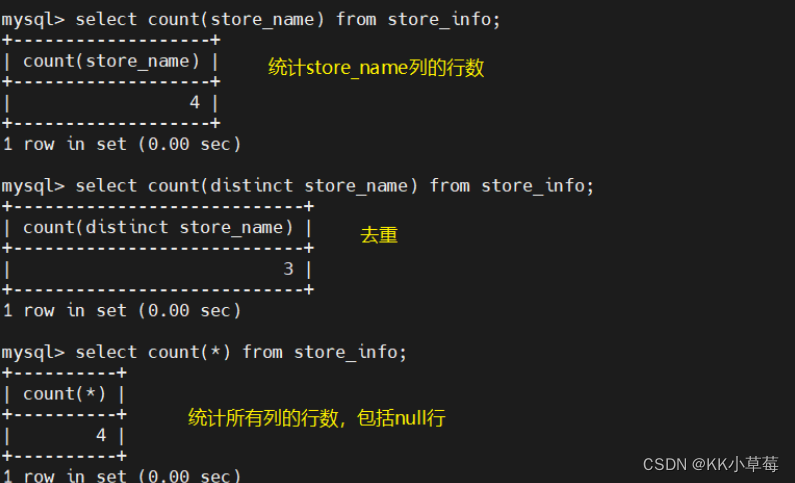
count
#count(*) 包括了所有的列的行数,在统计结果的时候,不会忽略列值为 NULL
#count(列名) 只包括列名那一列的行数,在统计结果的时候,会忽略列值为 NULL 的行
select count(store_name) from store_info;
#非null行数,重复的单独计数
select count(distinct store_name) from store_info;
#去重
select count(*) from store_info;
#统计所有列的行数,包括null行
max和min
select max(sales) from store_info;
#返回最大值
select min(sales) from store_info;
#返回最小值
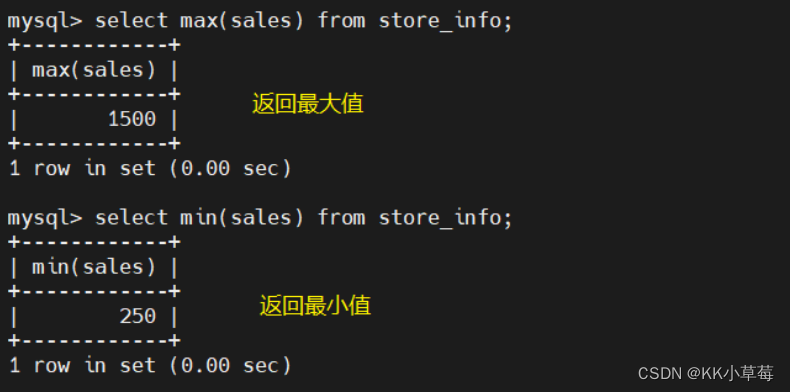
sum
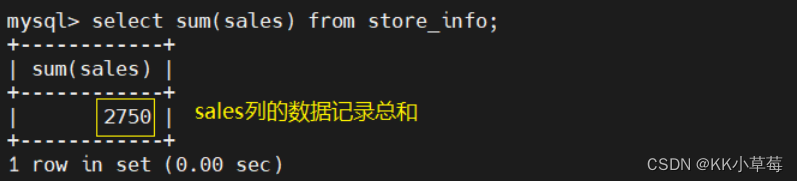
select sum(sales) from store_info;
#sales列的数据记录的和
3、字符串函数
| 字符串函数 | 功能 |
|---|---|
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
3.1 trim
select trim ([ [位置] [要移除的字符串] from ] 字符串);
#[位置]:的值可以为 leading (起头), trailing (结尾), both (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
select trim(leading 'Los' from (select store_name from location where store_name='Los Angeles'));
#去除store_name字段中Los Angeles的Los ,只提取Angeles
select trim(trailing 'York' from (select store_name from location where store_name='New York'));
#去除store_name字段中New York的York ,只提取New

3.2 concat
字段名 不要加 ' '
字符串 要加' '
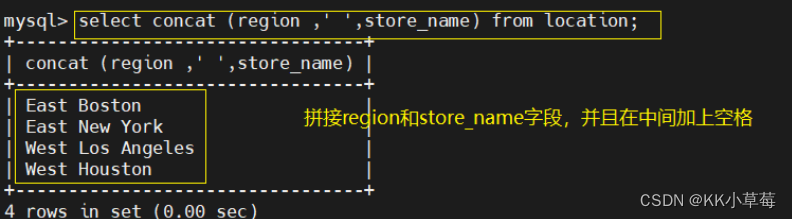
select concat (region ,' ',store_name) from location;
#拼接region和store_name字段,并且在中间加上空格
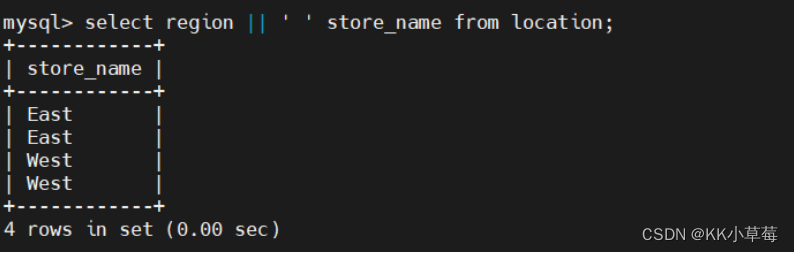
select region || ' ' store_name from location;
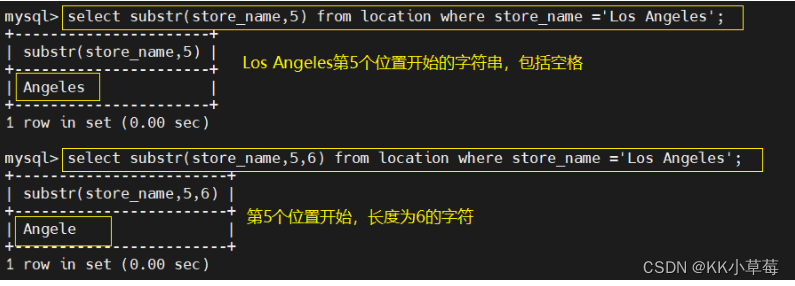
3.3 substr
select substr(store_name,5) from location where store_name ='Los Angeles';
#Los Angeles第5个位置开始的字符串
select substr(store_name,5,6) from location where store_name ='Los Angeles';
#第5个位置开始,长度为6的字符
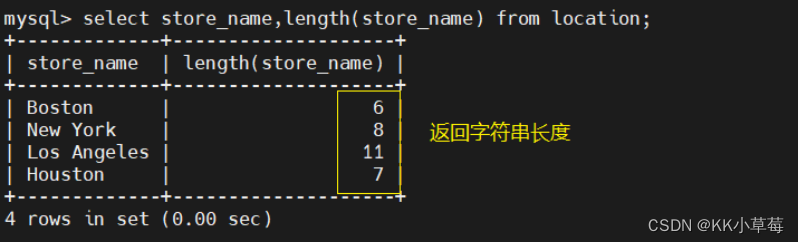
3.4 length
select store_name,length(store_name) from location;
#返回字段store_name中字符串的长度
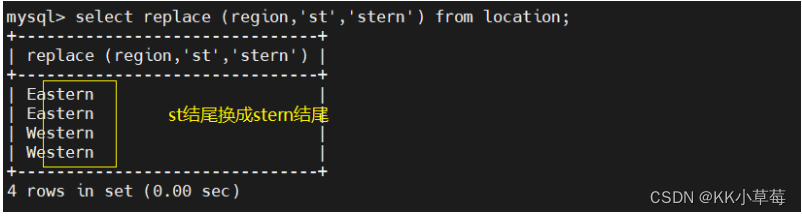
3.5 replace
select replace (region,'st','stern') from location;
#把region字段,st结尾替换成stern结尾
三、连接查询
1、表连接
| 表连接 | 概述 | |
|---|---|---|
| inner join | 内连接 | 只返回两个表中联结字段相等的行记录 |
| left join | 左连接 | 返回包括左表中的所有记录和右表中联结字段相等的记录,不相等的部分返回NULL |
| right join | 右连接 | 返回包括右表中的所有记录和左表中联结字段相等的记录,不相等的部分返回NULL |
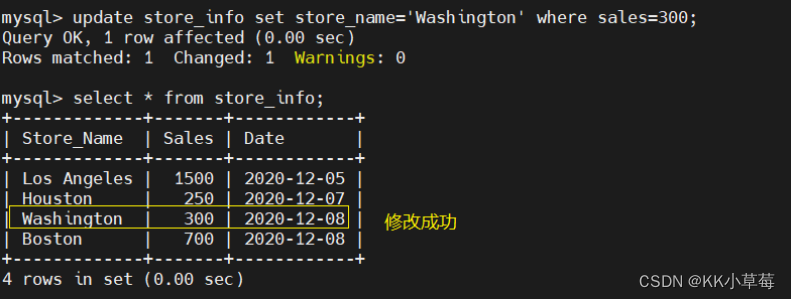
修改表数据
update store_info set store_name='Washington' where sales=300;
内连接一:
select * from location A inner join store_info B on A.store_name = B.store_name;
内连接二:
select * from location A, store_info B where A.store_name = B.store_name;
#通过多表查询实现
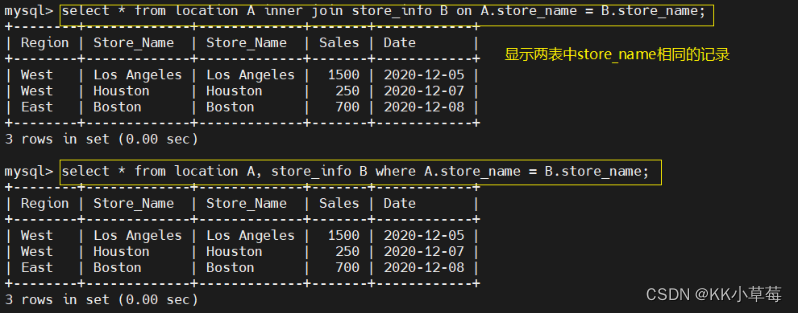
右连接:
select * from location A right join store_info B on A.store_name = B.store_name;
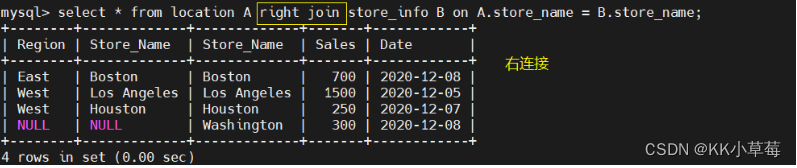
左连接:
select * from location A left join store_info B on A.store_name = B.store_name;
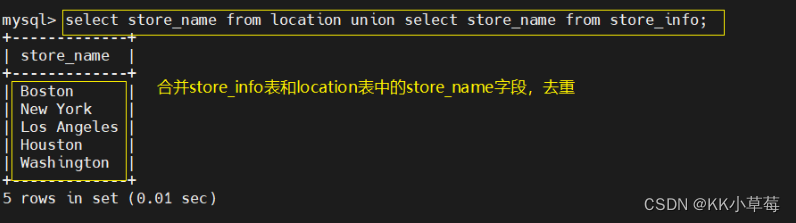
2、union语句
联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
union:生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[select 语句 1] union [select 语句 2];
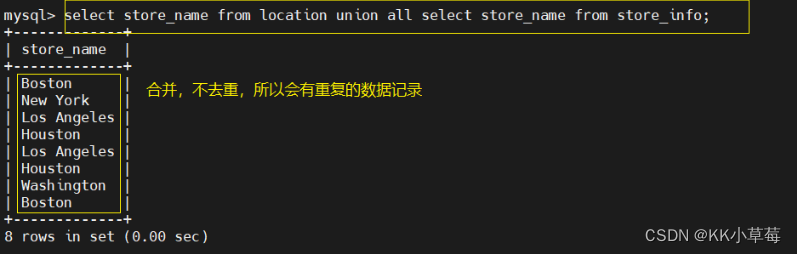
select store_name from location union select store_name from store_info;
#合并store_info表和location表中的store_name字段,去重
union all :将生成结果的数据记录值都列出来,无论有无重复
语法:[select 语句 1] union all [select 语句 2];
select store_name from location union all select store_name from store_info;
#合并,不去重,所以会有重复的数据记录
3、多表查询之求交集值
取两个SQL语句结果的交集
基本语法
select A.字段 from 左表 A inner join 右表 B on A.字段 = B.字段;
select A.字段 from 左表 A inner join 右表 B using(同名字段);select A.字段 from 左表 A, 右表 B where A.字段 = B.字段;
#多表查询select A.字段 from 左表 A where A.字段 in (select B.字段 from 右表 B);
#子查询select A.字段 from 左表 A left join 右表 B on A.字段 = B.字段 where B.字段 is not null;
select B.字段 from 左表 A right join 右表 B on A.字段 = B.字段 where A.字段 is not null;
举例
#方式一
select A.store_name from location A inner join store_info B on A.store_name = B.store_name;
#返回两表中字段相等的记录

#方式二
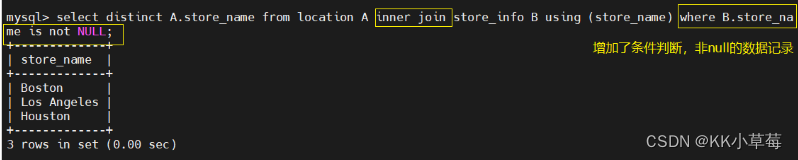
select A.store_name from location A inner join store_info B using (store_name);
#字段相同时,可以直接使用using(字段)

#取两个SQL语句结果的交集,且没有重复
select distinct A.store_name from location A inner join store_info B on A.store_name = B.store_name;
#inner join返回两表中相等的部分,distinct去重

select distinct A.store_name from location A inner join store_info B using (store_name) where B.store_name is not NULL;
#增加了条件判断,非null的数据记录
select A.store_name from (select B.store_name from location B inner join store_info C on B.store_name = C.store_name) A group by A.store_name;
#通过子查询+内连接查询+group by排序,返回store_name中相等的行记录

select A.store_name from (select distinct store_name from location union all select distinct store_name from store_info) A group by A.store_name having count( *) > 1;#首先,子查询`select distinct store_name from location`从“location”表中选择所有不重复的店铺名称。
#然后,子查询`select distinct store_name from store_info`从“store_info”表中选择所有不重复的店铺名称。
#使用`union all`将两个子查询的结果合并,并作为临时表A。
#最后,对临时表A按照店铺名称进行分组,使用`having count(*) > 1`筛选出出现次数大于1的店铺名称。

4、多表查询之求无交集值
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
求左表无交集
select A.字段 from 左表 A left join 右表 B on A.字段 = B.字段 where B.字段 is null;select 字段 from 左表 where 字段 not in (select 字段 from 右表);求右表无交集
select B.字段 from 左表 A right join 右表 B on A.字段 = B.字段 where A.字段 is null;select 字段 from 右表 where 字段 not in (select 字段 from 左表);求多表的无交集
select A.字段 from (select distinct 字段 from 左表 union all select distinct 字段 from 右表) A group by A.字段 having count(A.字段)=1;
举例
select distinct store_name from location where (store_name) not in ( select store_name from store_info);
#返回所有在"location"表中出现但在"store_info"表中不存在的店铺名称,即无交集值#子查询`select store_name from store_info`从"store_info"表中选择所有的店铺名称。
#主查询`select distinct store_name from location`从"location"表中选择所有不重复的店铺名称。
#使用`where (store_name) not in`条件将主查询中的店铺名称过滤掉那些在子查询结果中出现的店铺名称。

select distinct A.store_name from location A left join store_info B using (store_name) where B.store_name is NULL;
#返回在"location"表中出现但在"store_info"表中不存在的店铺名称#使用`left join`将"location"表(作为左表,记为A)和"store_info"表(作为右表,记为B)按照店铺名称进行连接。
#使用`using (store_name)`条件指定以店铺名称为连接的字段。
#使用`where B.store_name is NULL`条件过滤掉在连接结果中,店铺名称在"location"表中出现但在"store_info"表中没有匹配的记录。
#最后,使用`distinct`关键字来返回不重复的店铺名称。

select A.store_name from (select distinct store_name from location union all select distinct store_name from store_info) as A group by A.store_name having count(*)=1;
#返回只在"location"表或"store_info"表中出现一次的店铺名称,即只出现在其中一个表中但没有重复出现的店铺名称#子查询`select distinct store_name from location`从"location"表中选择所有不重复的店铺名称。
#子查询`select distinct store_name from store_info`从"store_info"表中选择所有不重复的店铺名称。
#使用`union all`将两个子查询的结果合并。
#将合并结果作为临时表A,并使用`as A`来给临时表起一个别名。
#在临时表A的基础上,使用`group by A.store_name`对店铺名称进行分组。
#使用`having count(*) = 1`筛选出出现次数为1的店铺名称。

四、SQL语句执行顺序
FROM
<left table>ON
<join_condition>
<join_type>JOIN
<right_table>WHERE
<where condition>GROUP BY
<group_by_list>HAVING
<having_condition>SELECTDISTINCT
<select list>ORDER BY
<order_by_condition>LIMIT
<limit number>########################################################################################################
在SQL中,一般而言,SQL查询语句的执行顺序如下:1. FROM:指定要查询的数据表或视图。
2. JOIN:根据指定的条件连接多个表。
3. WHERE:基于指定的条件筛选出符合要求的行。
4. GROUP BY:按照指定的列进行分组。
5. HAVING:对分组后的结果进行条件筛选。
6. SELECT:选择要返回的列。
7. DISTINCT:去除重复的行。
8. ORDER BY:按照指定的列进行排序。
9. LIMIT/OFFSET:限制返回的结果数量和起始位置。
相关文章:
MySQL高级语句(第一部分)
MySQL高级语句(第一部分)一、MySQL进阶查询1、select ----显示表格中一个或数个字段的所有数据记录2、distinct ----不显示重复的数据记录3、where ----有条件查询4、and or ----且 或5、in ----显示已知的值的数据记录6、between ----显示两个值范围内的数据记录7、通配符8、l…...

Perl区分文件换行符类型
背景 在Windows上使用Perl判断文件时何种换行符时,处理CR LF类型的换行符时,也识别成了LF。 思路 Windows上的换行是 CRLF , Unix上是 LF , Mac CR在Windows平台使用Perl读取文件创建文件句柄时,未对file handler设置binmode,了…...
数据备份文件生成--根据表名生成对应的sql语句文件
最近客户有个需求,希望在后台增加手动备份功能,将数据导出下载保存。 当然,此方法不适用于海量数据的备份,这只适用于少量数据的sql备份。 这是我生成的sql文件,以及sql文件里的insert语句,已亲测&#x…...

进程同步与互斥
目录 进程同步与互斥(1) 第一节、进程间相互作用 一、相关进程和无关进程 二、与时间有关的错误 第二节、进程同步与互斥 一、进程的同步 二、进程的互斥 三、临界区 进程同步与互斥(2) 三、信号量与P、V操作的物理含义…...
mysql workbench常用操作
1、No database selected Select the default DB to be used by double-clicking its name in the SCHEMAS list in the sidebar 方法一:双击你要使用的库 方法二:USE 数据库名 2、复制表名,字段名 3、保存链接...

【操作】国标GB28181视频监控EasyGBS平台更新设备信息时间间隔
国标GB28181协议视频平台EasyGBS是基于GB28181协议的视频监控云服务平台,可支持多路设备同时接入,并对多平台、多终端分发出RTSP、RTMP、FLV、HLS、WebRTC等格式的视频流。平台可提供视频监控直播、云端录像、云存储、检索回放、智能告警、语音对讲、平台…...
TensorFlow入门(八、TensorBoard可视化工具的应用)
TensorBoard常用函数和类http://t.csdn.cn/Hqi9c TensorBoard可视化的过程: ①确定一个整体的图表,明确从这个图表中获取哪些数据的信息 ②确定在程序的哪些节点、以什么样的方式进行汇总数据的运算,以记录信息,比如在反向传播定义以后,使用tf.summary.scalar记录损失值的变…...
)
升级targetSdkVersion至33(以及迁移至Androidx)
1.设置 android.useAndroidXtrue 和 android.enableJetifiertrue 2.一键迁移至androidx:Refactor -> Migrate to Androidx 3.手动修改未能自动迁移到androidx的部分: android.support.v4.view.ViewPager.PageTransformer -> androidx.viewpager.wi…...

python3.11版本pip install ddddocr调用时报错got an unexpected keyword argument ‘det‘ 解决
一、如图出现如下问题 ddddocr.__init__() got an unexpected keyword argument det出现问题原因:python3.11默认安装版本就旧版的ddddocr1.0的,所以导致如下报错 二、解决方案一(推荐) python3.11的环境直接安装这个即可&…...

代理IP与Socks5代理:跨界电商之安全防护与智能数据引擎
第一部分:跨界电商的兴起与网络安全挑战 1.1 跨界电商的崭露头角 跨界电商已经成为全球贸易的新引擎,企业纷纷踏上了拓展国际市场的征程。 1.2 网络安全的不容忽视 跨界电商的增长也伴随着网络安全威胁的增加。黑客攻击、数据泄露和欺诈行为等风险呈…...

如何评估一个HR是否专业?看这些标准
HR在遇到优秀的人才时,以往的招聘中,我们总以惯性思维寻找吸引人才的突破口,诸如体现薪酬优厚、突出平台优势甚至提高面试话术等,却忽略了面试官本人的人格魅力,本身就是公司招聘的形象代言,因为优秀的面试…...
之—— 模板循环详细用法)
WordPress主题开发( 八)之—— 模板循环详细用法
WordPress 主题开发教程手册 — 模板循环 WordPress 主题开发中,模板循环是一个非常关键的概念,它负责默认机制来输出文章内容。模板循环会遍历当前页面获取的所有文章,然后使用主题中的模板标签将它们格式化并输出。 模板循环的应用 Word…...

QT : 完成绘制时钟
1.头文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPainter> #include <QTimer> #include <QTime> #include <QPaintEvent> #include <QDebug> #include <QBrush>QT_BEGIN_NAMESPACE namespace Ui { class…...
香港云服务器和日本云服务器哪个好?(详细对比)
购置海外服务器时,您是在乎网络速度?价格?稳定性?当这几个因素同时存在,我们该如何选择?本篇针对海外热门的两个地区,中国香港和日本,这两种云服务器谁优谁劣?各有什么亮点?逐一进行对比分析。 一、速度上来看 中国香…...

Cross Attention和 Self- Attention 的区别?
Cross Attention和Self-Attention都是深度学习中常用的注意力机制,用于处理序列数据,其中Self-Attention用于计算输入序列中每个元素之间的关系,Cross Attention则是计算两个不同序列中的元素之间的关系。它们的主要区别在于计算注意力分数时…...

《从零开始的Java世界》02面向对象(基础)
《从零开始的Java世界》系列主要讲解Javase部分,从最简单的程序设计到面向对象编程,再到异常处理、常用API的使用,最后到注解、反射,涵盖Java基础所需的所有知识点。学习者应该从学会如何使用,到知道其实现原理全方位式…...

pve关闭windows虚拟机慢
背景: 在web界面关闭windows虚拟机一直转圈,使用命令行关闭报错 qm stop 155 trying to acquire lock... cant lock file /var/lock/qemu-server/lock-155.conf - got timeout解决 删除lock,然后用命令行重新关闭 rm /var/lock/qemu-serve…...

【Django】 rest_framework接口开发流程及接口功能组成
rest_framework接口开发流程及接口功能组成 使用restframework框架开发接口,方式应该有6、7种,每个人的习惯不同,用的方法也不一样,再次不再一一详述。 我比较常用:ModelSerializerGenericAPIView 原因是用视图函数装饰…...
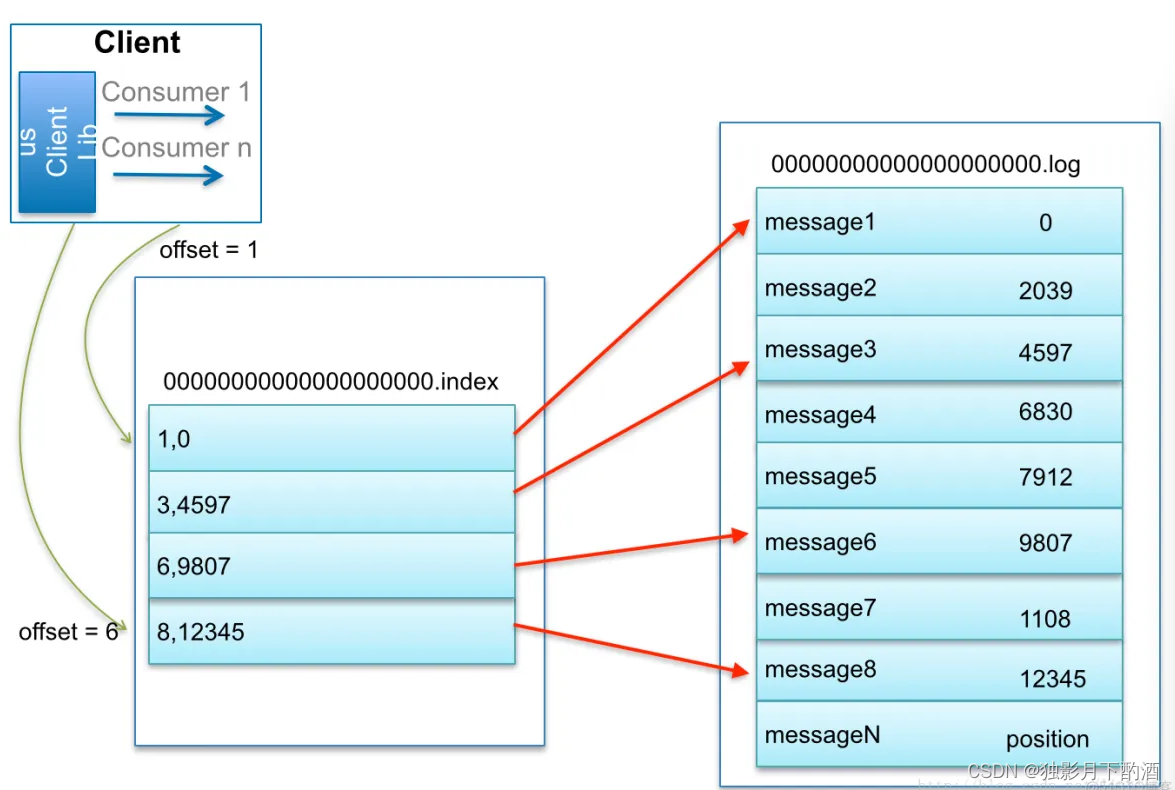
Kafka Log存储解析以及索引机制
1.概述 在Kafka架构,不管是生产者Producer还是消费者Consumer面向的都是Topic。Topic是逻辑上的概念,而Partition是物理上的概念。每个Partition逻辑上对应一个log文件,该log文件存储是Producer生产的数据。Producer生产的数据被不断追加到该…...

广告电商模式:探索新商业模式,实现三方共赢
随着互联网技术的发展,电商行业正在不断探索新的商业模式。其中,广告电商模式是一种创新的方式,它成功地将广告和电商相结合,实现了三方共赢的局面。一、广告电商模式的定义广告电商模式,顾名思义,是一种将…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...