MySQL架构 InnoDB存储引擎
1. 什么是Mysql?
- 我们在开发的时候,我们都需要对业务数据进行存储,这个时候,你们就会用到MySQL、Oracal等数据库。
- MySQL它是一个关系型数据库,这种关系型数据库就有Oracal、 MySQL,以及最近很火的PgSQL等。
那什么是关系型数据库呢?
- 就是它是基于我们的SQL语句去执行操作的。
- 其实就是关系表数据库,由表结构来存储数据与数据之间的关系,同时用SQL(Structured query language)结构化查询语句来进行数据操作。
- 关系型数据库,对应会有一个非关系型数据库,像我们用的比较多的 Redis 这种Key - Value结构数据存储、hbase这种列存储格式、MongoDB这种文档存储等等。
那么关系型数据库相比非关系型数据的区别:
- 关系型数据库都是用表来进行维护,所以格式一致,可以统一用SQL语言来进行操作
- 关系型数据库都是表结构,所以灵活度不够,操作复杂的海量数据性能比较差,所以我们才会有表结构、索引以及索引优化。
- 虽然性能可能会比较慢,但是能做复杂的关联查询操作。 比如一对一, 一对多,多对多等等。
MySQL 的优势:
- 易用性:开发者可以在几分钟内安装好MySQL,数据库易于管理。
- 可靠性: MySQL 是最成熟、使用最广泛的数据库之一。超过 25 年,它已经在各种场景中进行了测试,其中包括许多世界上最大的公司。由于MySQL 的可靠性,组织依赖 MySQL 来运行关键业务应用程序。
- 可扩展性: MySQL 可扩展以满足最常访问的应用程序的需求。MySQL 的本机复制架构使 Facebook 等组织能够扩展应用程序以支持数十亿用户。
- 高性能: MySQL HeatWave比其他数据库服务更快且成本更低,多项标准行业基准测试证明了这一点,包括 TPC-H、TPC-DS 和 CH-benCHmark。
- 高可用性: MySQL 为高可用性和灾难恢复提供了一套完整的本机、完全集成的复制技术。对于关键业务应用程序,并满足服务级别协议承诺,客户可以实现 零数据丢失以及秒级的故障转移恢复。
- 安全性: 数据安全需要保护和遵守行业和政府法规,包括欧盟通用数据保护条例、支付卡行业数据安全标准、健康保险可移植性和责任法案以及国防信息系统局的安全技术实施指南。MySQL 企业版提供高级安全功能,包括身份验证/授权、透明数据加密、审计、数据屏蔽和数据库防火墙。
- 灵活性: MySQL 文档存储为用户开发传统 SQL 和 NoSQL 无模式数据库应用程序提供了最大的灵活性。开发人员可以在同一个数据库和应用程序中混合和匹配关系数据和 JSON 文档。
Mysql服务安装
- 见官网:https://dev.mysql.com/doc/refman/8.0/en/installing.html
Mysql连接或者断开服务器
- 官网:https://dev.mysql.com/doc/refman/8.0/en/connecting-disconnecting.html
Mysql里面的基本库表信息
库基本操作
- 我们叫它数据库,数据库,所以,在表的前面还有库的概念,操作查询库信息,这些基本操作就不演示了。
- 官网:https://dev.mysql.com/doc/refman/8.0/en/database-use.html
查询所有的库:
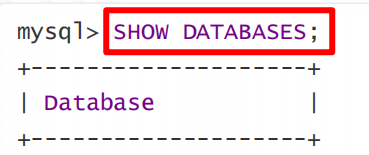
创建库:

查询当前选择的库:
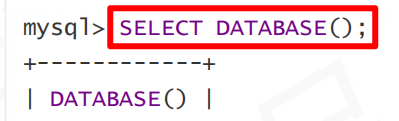
表基本操作
- 官网:MySQL :: MySQL 8.0 Reference Manual :: 13.1.20 CREATE TABLE Statement
系统库表
- 我们发现除了我们自己创建的库以外,还有很多系统的库、以及表来保证MySQL的系统运行。
官网:MySQL :: MySQL 8.0 参考手册 :: 5.3 mysql 系统架构
三个系统库:
- mysql库:这一个系统库是来保证我的数据库服务正常运行的一个系统表全部在这个库里面。
- information_schema库:包括InnoDB里面的数据、日志、事务、表;还有PROCESSLIST表:它记录了当前正在运行的数据库有多少个连接和查询进程的信息;ENGINES表:存储引擎插件表。
- performance_schema库 - 性能库:这个库里面所有的数据是当前只存在内存里面的,这个库下面所有的事件、锁(比如data_locks表) - 我会去锁哪些数据。这些数据它只针对我当前的服务,如果重启了,所有的数据会丢失,所以这个它只存在当前内存。
mysql系统库下几个重要的表:
- 数据字典表(Data Dictionary Tables)
- 授权表(Grant System Tables)
- 对象信息表(Object Information System Tables):plugin 插件注册表 等待
- 日志系统表(Log System Tables):
- general_log:一般查询日志表。
- slow_log:慢查询日志表。
日志配置:
show variables like 'general_log'; //一般查询日志,默认关闭
SELECT @@long_query_time;
show global variables like 'long_query_time';
show global variables like 'min_examined_row_limit'; //至少需要检索这么多行
show global variables like 'slow_query_log'; //是否开启慢日志查询 默认关闭
SET GLOBAL slow_query_log=1;
set global long_query_time=0.1; //超过100毫秒
log_output=table |file |none //设置是放在文件中,还是在mysql.slow_log表中Sql语句的执行流程
- 客户端发送一条语句给到服务器,然后服务器它能给你一个它的数据。
一. 跟服务器建立连接:
- 只有建立连接以后,我才能够发送SQL语句给到服务器,服务器它才能够去进行接收,这样才能进行网络IO。
连接管理
- 首先,我们得有连接,那么Mysql里面就有一个连接层,来管理连接,我们看下跟连接有关的变量/参数
- 变量:随着我的服务的运行,它会变更的,这些变量会随着我的客户端连接的变多而变多。
MySQL的四个线程状态变量:MySQL :: MySQL 8.0 参考手册 :: 5.1.6 服务器状态变量参考
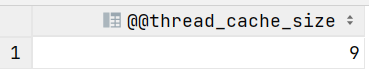
- Thread_cached:是MySQL的一个状态变量,表示MySQL线程缓存中当前缓存的线程数,是为了我的服务,不用每一次客户端建立连接的时候都去创建一个线程,以此减少线程的创建和销毁的开销,提高数据库性能,所以它有一个缓存的线程数。当一个客户端连接到MySQL数据库服务器时,服务器会为该连接创建一个线程来处理客户端的请求。线程缓存的作用就是在该连接请求结束后,将这些线程缓存在内存中,以便下次有新的连接请求时能够复用这些线程,而不需要重新创建。thread_cache_size是MySQL的一个静态配置参数,用来配置线程缓存的大小,默认是-1,需要手动调整(在MySQL配置文件当中配置)并重启MySQL服务才能生效,最大是16384。
- Thread_connected:我当前打开的线程数,就是我现在有多少个线程是打开的。
- Thread_created:总共创建的线程数,即创建的线程总数。创建的线程总数越多,我们的thread_cache_size 可以对应的更大,来提升线程的缓存命中率。
- Threads_running:正在运行的线程数
-- 查看MySQL的四个Thread线程状态变量
show status like 'Thread%';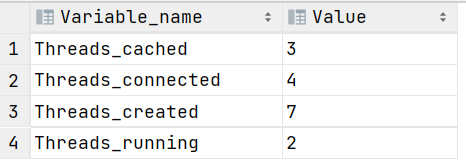
-- 查询thread_cache_size系统变量
select @@thread_cache_size;
查看当前正在运行的线程:
-- 显示当前正在运行的线程
show full PROCESSLIST;
该查询将返回一个结果集,包含所有当前连接的信息。每一行代表一个连接,每个连接的信息包括
id:线程 ID
State:连接状态
User:操作的用户名
Host:主机 / IP
db:操作的数据库
command:当前连接执行的命令:Sleep-休眠、Query-查询
Time:这个状态持续的时间,单位是s
info - 信息:查询会有查询的信息,但是长度有限制,可能不全
删除阻塞线程
- 官网:https://dev.mysql.com/doc/refman/8.0/en/kill.html
使用PROCESSLIST表可以查看当前正在运行的连接-线程,假如当前有客户端连接已经阻塞了,那么此时你可以去把它KILL掉:
demo
SELECT * FROM product_new --表中有500W数据,查询很慢2. 会话二:
SHOW PROCESSLIST; -- 查看当前线程执行结果:
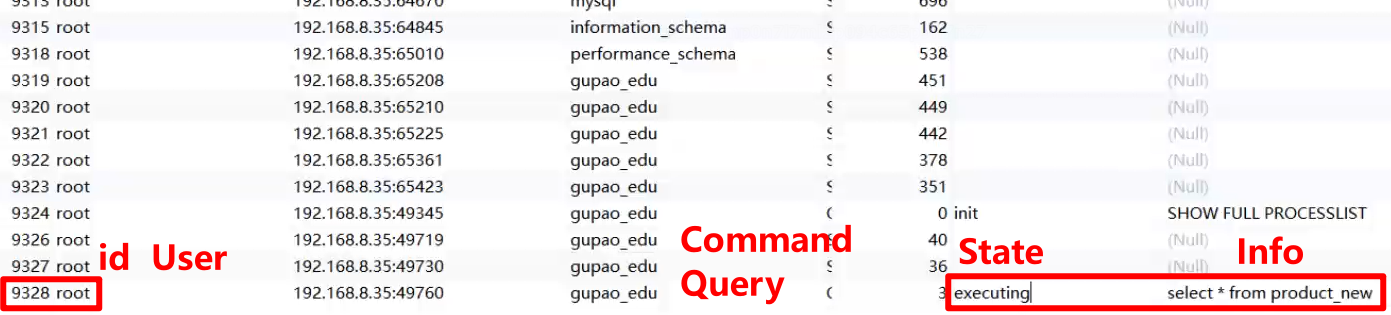
3. 关闭查询query:
KILL QUERY 9328; -- 终止查询 
4. 杀死 / 关闭连接线程 - Connection Thread
KILL 2280; -- kill 连接线程查看会话一的结果:
- [Err] - Lost connection to MySQL server during query - 丢失连接Connection

其他连接相关配置参数:
show status like 'Max_used_connections%';
- Max_used_connections 自服务启动以来最大的连接数
- Max_used_connections_time 达到这个峰值的时间
几个全局系统变量:
-- 查询最大连接数 默认151
SELECT @@max_connections;
select @@GLOBAL.max_connections;-- 手动设置最大连接数
SET @@GLOBAL.max_connections = 1000;-- 查询服务器超时等待时间 默认28800s - 8h
SELECT @@wait_timeout;
select @@GLOBAL.wait_timeout;-- 手动设置服务器最大等待时间
SET @@GLOBAL.wait_timeout = 1000;
- max_connections:最大的连接数,即我的服务最多能开启的连接数,超过该值不允许建立连接,默认151,最小1,最大 100000。如果开启太大,同时会有很多的客户端来进行连接操作,MySQL性能可能会跟不上;如果开启太小,可能在高并发场景下导致并发量上不来。
- wait_timeout:最大的等待时间 / 服务器超时等待时间 / 非交互连接等待的时间(单位s),默认28800s,也就是8小时,用于指定一个连接在空闲状态下的最长等待时间。如果一个连接在8小时内没有进行任何操作,那么MySQL服务器会自动关闭该连接,以释放资源。wait_timeout => 服务器什么时候会自动关闭?
跟服务器建立完连接之后,此时就代表客户端能跟服务端去进行通信了,也就是客户端能向服务端去发送SQL语句的请求了。
MySQL Server中的第一层 - 网络连接层
二. 解析器
- 当建立连接后,客户端向服务端去发送SQL语句请求时需要解析SQL语句,会把一条SQL语句解析生成语法树;因为MySQL不是人,不会一眼看到SQL语句就知道要做什么事情。
- 所以它会借用解析器去把SQL语句解析出来,看是否符合我们的SQL语法,最终生成一个语法树(理解为一个数据结构)。
解析器分为词法解析跟语法解析!
词法解析(器)
- 将SQL语句打碎,转化成一个一个关键单词 => 然后交给语法解析器去构建语法树,判断语法是否正确
语法解析(器)
- 语法解析已经知道每个SQL语句的单词了,那么在语法解析的时候,会去构建语法树,接着会去判断 / 检查语法是否正确,比如,where是不是写出where1,from写成from1;
- 表名、列名是否存在、用户是否有操作权限等等。
- 如果发现语法错误,则MySQL直接抛出相应的错误信息,并拒绝执行该SQL语句。
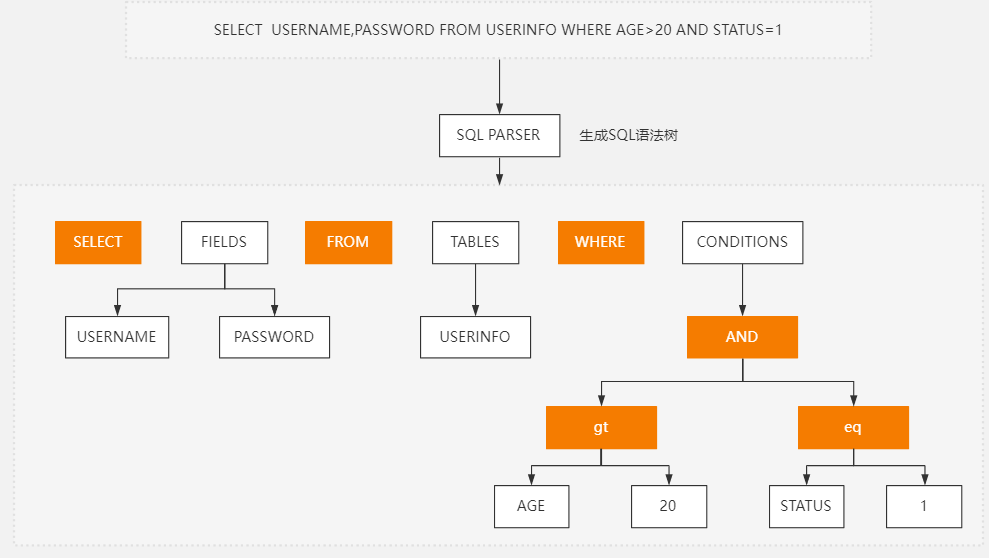 总结:
总结:
- 先将输入的SQL语句解析为语法树,然后对语法树进行语法检查,这样可以确保在执行之前先判断SQL语句是否符合MySQL的语法规则,避免执行无效或错误的语句。
三. 预处理器 / 预编译器(可做可不做)
预处理 / 预编译的两个作用:
- 提升性能
- 防止SQL注入,更安全
MyBatis中的SQL注入是MyBatis去做的参数化,而这里的SQL注入是我们的MySQL服务器自己能支持的,预处理器它是我们的MySQL服务能支撑的。
什么是预处理?
- 以我们的工作场景为例,一个查询接口,SQL语句都是一样的,但是每次查询的参数都不一样,所以我们想只需要变更参数部分就行。
- 那么,我们就是在拼接SQL语句的时候,将用户的输入跟语句拼接成一个SQL语句给到MySQL执行。
- 但是会发生一个SQL注入问题!
什么是SQL注入?
- 因为参数是客户端传过来的,所以可以传任何值,那么就有可能传入任何值就有了SQL注入问题。
-- 要执行的SQL语句
select * from emp where password = '';-- SQL注入演示-客户端传入查询的参数为: ' or '1' = '1
select * from emp where password = '' or '1' = '1';那么能不能把这个参数化的事情交给MySQL自己做呢?
- 当然可以,这个就是预处理。
- 如果你需要参数化,你只要告诉MySQL,传一个预处理语句就行,MySQL会将参数与语句编译分开。
预处理操作解决SQL注入
预处理语句的工作流程 / 预处理语句为什么能够防止SQL注入?
- 首先在应用程序中,应该去创建一个预处理语句,将SQL查询与占位符(通常使用问号?来表示)组合起来,形成一个带有参数占位符的SQL查询语句。
- 接着,应用程序将这个预处理语句发送到MySQL服务器进行编译。服务器会对SQL语句进行语法解析和执行计划生成,但不会执行实际的查询。
- 在执行查询之前,应用程序通过绑定参数的方式将实际的参数值与占位符关联起来,这样可以防止SQL注入攻击,因为用户输入的参数不会直接嵌入到查询语句中,而是作为参数传递给服务器,并允许在多次执行中重复使用预处理语句(因为预处理语句只需编译一次,再次执行时就无需重新编译,以此提高性能)。
- 一旦参数绑定完成,应用程序可以多次执行相同的预处理语句,通过更改参数值来获取不同的结果。
预处理Demo,防止SQL注入:
-- 创建预处理语句
-- PREPARE 预处理名字 from 'SQL语句';
PREPARE select_user from 'select * from emp where password = ?'-- 绑定参数(设置参数值)
SET @passsword = '123456';-- 执行预处理语句
-- EXECUTE 预处理名字 USING @绑定参数名;
EXECUTE select_user USING @passsword;-- 清除预处理语句
-- DEALLOCATE PREPARE 预处理名字;
DEALLOCATE PREPARE select_user;预处理主要做主要做以下2个事情:
- 将语句编译、优化跟参数分开处理,当执行SQL语句相同,参数不同的场景,提升性能。
- 因为是参数化去执行的,而不是拼接参数,从而解决了SQL注入问题。
比如我们经常被问的Mybatis里面#跟$符号的区别:
- #符号执行SQL时,会将#{...}替换成?,生成预编译SQL / 预处理SQL,然后进行预处理,能防止SQL注入,并且必须传入参数;
- $符号会拼接SQL,直接将${...}参数拼接在SQL语句中,存在SQL注入问题。
四. 优化器 - 决定怎么做
- 根据上面的流程,我们知道要去执行什么语句,但是具体怎么执行会有很多的方式,比如走哪个索引,要不要回表,要不要去在内存里面排序,你的语句是不是可以优化等等。
-- 获取MySQL数据库中的全局优化器开关配置信息
SELECT @@GLOBAL.optimizer_switch;
- 优化器说明:https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html,里面包含了每个优化选项说明.
- 优化方式官网地址:https://dev.mysql.com/doc/refman/8.0/en/optimization.html;这个里面就有很多优化器的实践,比如优化sql语句等等。
- 优化器它是基于服务,觉得自己最快的一些方式去执行这个语句,优化后会生成一个最优的执行计划,并将该执行计划传递给存储引擎层,所以这个语句到底怎么走,优化器来决定。
- 它是基于内存与CPU或性能的消耗得到一个算法或者说得到哪一个执行计划它是最快的。
- 当前,优化器里面有一些东西它是可以自己设置的,比如说要不要索引下推,比如说要不要回表,比如说要不要去用联合索引,要不要用hash_join,要不要用跳跃扫描skip_scan,要不要用mrr,mrr是它底层的一个算法,能够更快的跟我的磁盘去进行交互等等。
MySQL Server中的第二层 - 核心服务层,核心服务层不牵扯到数据的存储与查询。
五. 执行器 - 去操作数据的
- 根据执行计划,去调用数据存储的地方,也就来到了我们MySQL Server中的第三层 - 存储引擎层!
- 存储引擎层是真正的跟数据进行交互的,是真正的来保存以及怎么去查询数据的,所以存储引擎层决定了我这个数据以什么样子的方式来保存,比如说你是保存到磁盘,还是保存到内存,还是磁盘跟内存都有。
- 执行器去根据表设置的存储引擎,调用不同存储引擎的API接口获取数据。
- 至于这个数据是怎么存的,这个数据有哪些优化(比如内存去缓存)等等,就是每个存储引擎自己去做的事情,也就来到了我们MySQL Server中的第三层中的存储引擎层,并且存储引擎是跟MySQL解耦的,存储引擎跟MySQL的开发者都不是同一批人。
- 存储引擎它是我们MySQL的一个插件,你如果有能力,MySQL都支持你自己写存储引擎。
- 基于不同的一些场景,比如说有一些场景我要去保证性能,有一些场景我要去保证一致性,所以它会有不同的存储方案,这里就牵扯到我们不同的存储引擎。
那么官网提供了哪些存储引擎?
- 官网:MySQL :: MySQL 8.0 Reference Manual :: 16 Alternative Storage Engines
可以通过语句查询当前服务器支持哪些存储引擎:
SHOW ENGINES; -- 查询当前服务器支持的存储引擎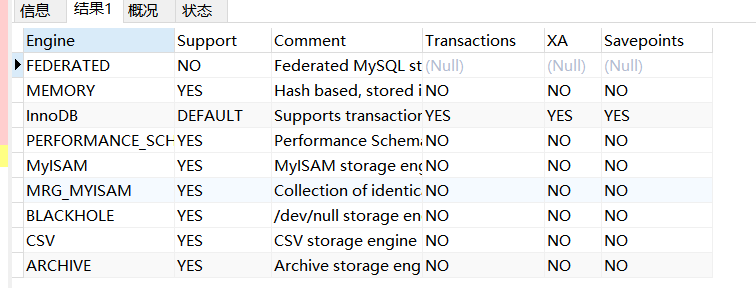
InnoDB
- MySQL 8.0默认的存储引擎。InnoDB是一个事务安全(兼容ACID) 的MySQL存储引擎,具有提交、回滚和崩溃恢复功能,以保护用户数据。
- InnoDB支持行级别的锁(没有升级到更粗粒度的锁)和Oracle风格一致的非锁读取提高了多用户并发性和性能。
- InnoDB将用户数据存储在聚集索引中,以减少常见的基于主键的查询的I/O。
- 为了维护数据的完整性,InnoDB还支持外键引用完整性约束。
MyISAM
- 这些表占用空间很小。
- 表级锁限制了读/写工作负载的性能,因此它经常用于Web和数据仓库配置中的只读或以读为主的工作负载中,所以它的性能要比InnoDB要高。
Memory
- Memory它只是把数据存储在内存,它不会做持久化。
不同的存储引擎会有自己不同的存储实现方式 / 存储方案,不管是什么存储引擎,它一定要做的事情是把这个数据保存起来,是用内存还是磁盘,还是都用,或者磁盘的文件格式等等都会不一样。
- 既然要保存,那么就一定要有个数据的目录,这个目录,也就是我们的一个变量,这个变量就是代表你保存到哪里。
接下来我们看下数据到底存储在哪里,以什么样的方式存储?
数据存储地址
SQL语句查询:
-- 查询数据库的数据目录
select @@datadir;
show variables like '%datadir%';
该目录就是我们的数据库的数据目录,我们的数据保存在该目录下。
相关文章:
MySQL架构 InnoDB存储引擎
1. 什么是Mysql? 我们在开发的时候,我们都需要对业务数据进行存储,这个时候,你们就会用到MySQL、Oracal等数据库。 MySQL它是一个关系型数据库,这种关系型数据库就有Oracal、 MySQL,以及最近很火的PgSQL等。…...

K8S-CNI
CNI的设计思想即为:Kubernetes在启动Pod的pause容器之后,直接调用CNI网络插件,从而实现为Pod内部应用容器月在的Network Namespace配置符合预期的网络信息。 这里面需要特别关注两个方面:Container必须有自己的网络命名空间的环境,也就是end…...
和命令 (数据类型 四))
Redis 集合类型(Set)和命令 (数据类型 四)
集合类型是一个无序、不重复的数据集合,它可以用于存储唯一的值,并提供了对集合进行交集、并集、差集等操作。 常用集合类型命令: 添加操作: sadd key member1 member2 …:向集合中添加一个或多个成员。 # 添加三个…...
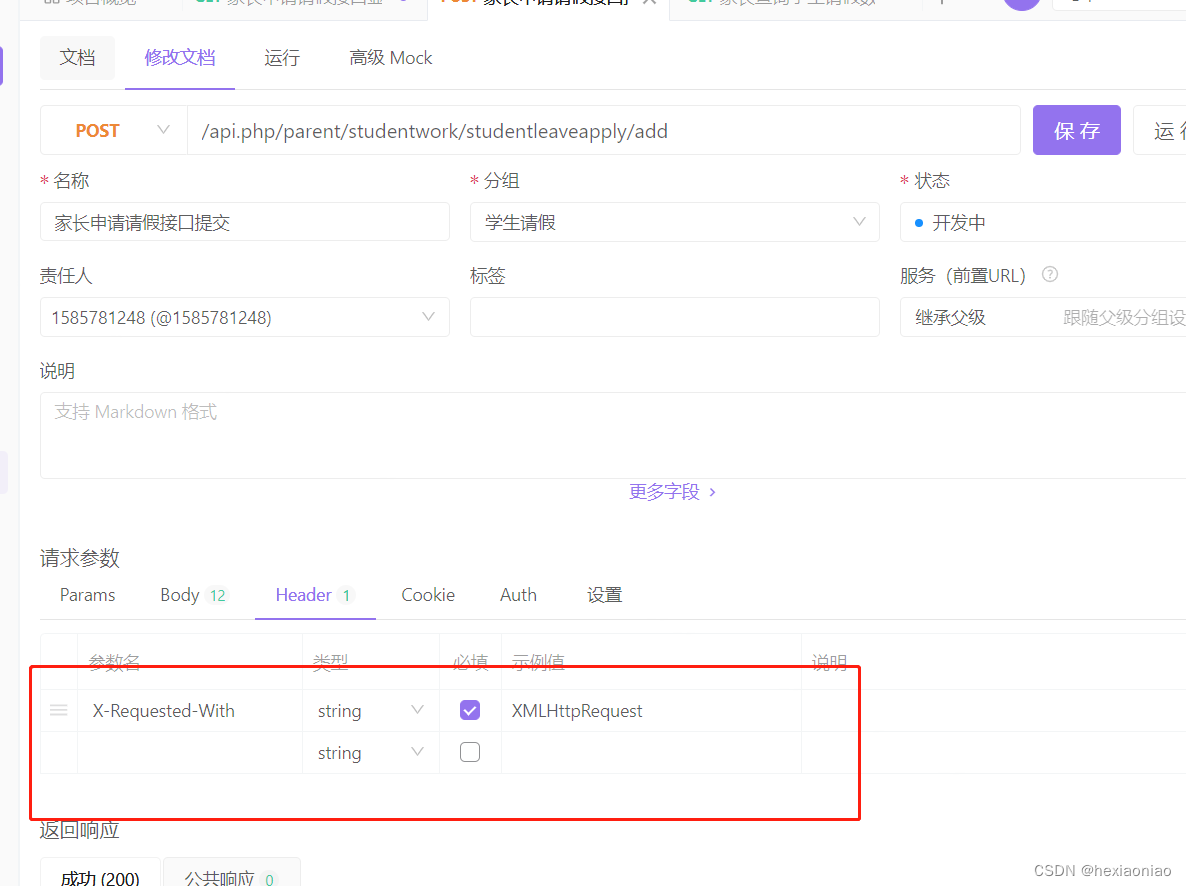
thinkphp5 如何模拟在apifox里面 post数据接收
tp5里面控制器写的方法想直接apifox里面请求接受 必须带上这个参数 header里面 X-Requested-With:XMLHttpRequest...

建造者模式 创建型模式之三
想要搞清楚建造者模式,首先先要了解建造者模式种四个角色的定位 1.Product:表示被构造的复杂对象,就是我们要建造的东西,比如我们要做一个手机,手机就是product。 2.Builder:建造者,这里需要着…...
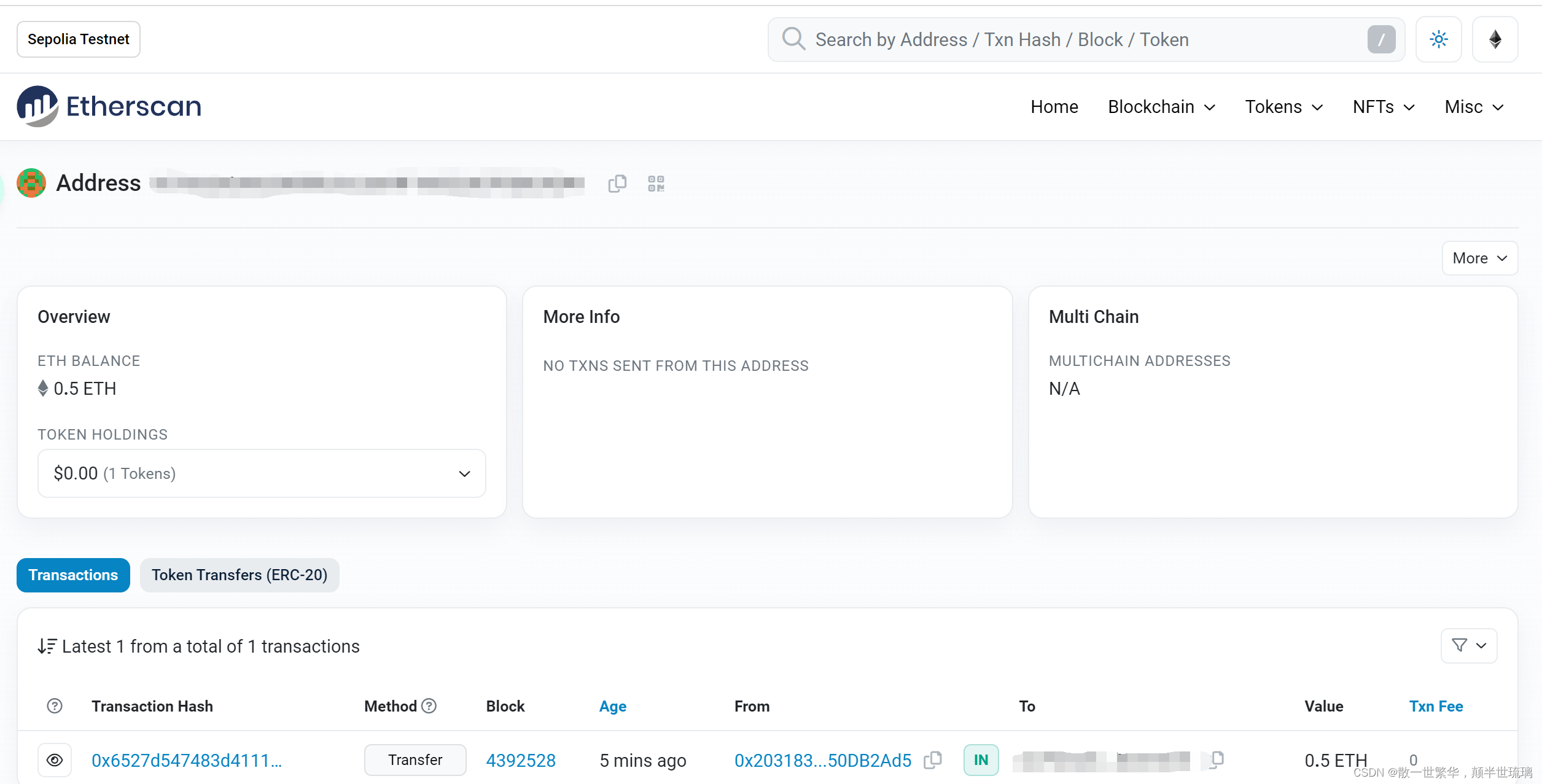
发布以太坊测试网络中的第一笔交易
1.安装以太坊钱包 要想发送发布以太坊测试网络中的第一笔交易,首先需要创建一个管理账户的钱包,这个钱包可以理解为管理私钥的容器,具体按照步骤为:打开Chrome浏览器应用商店搜索MetaMask,选择对应的钱包添加至Chrome…...

No module named ipykernel解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
Java 基于 SpringBoot 的校园疫情防控系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1 简介2.主要技术3 需求分析4系统设计4.1功能结构4.2 数据库设计4.2.1 数据库E/R图4.2.2 数据库表…...

windows的ui自动化测试相关
一个python第三方模块uiautomation github上也有源码,可以看下 uiautomation模块项目地址:https://github.com/yinkaisheng/Python-UIAutomation-for-Windows uiautomation模块项目地址...
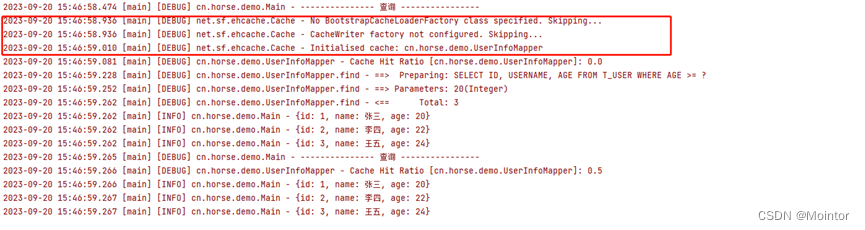
Mybatis 二级缓存(使用Ehcache作为二级缓存)
上一篇我们介绍了mybatis中二级缓存的使用,本篇我们在此基础上介绍Mybatis中如何使用Ehcache作为二级缓存。 如果您对mybatis中二级缓存的使用不太了解,建议您先进行了解后再阅读本篇,可以参考: Mybatis 二级缓存https://blog.c…...
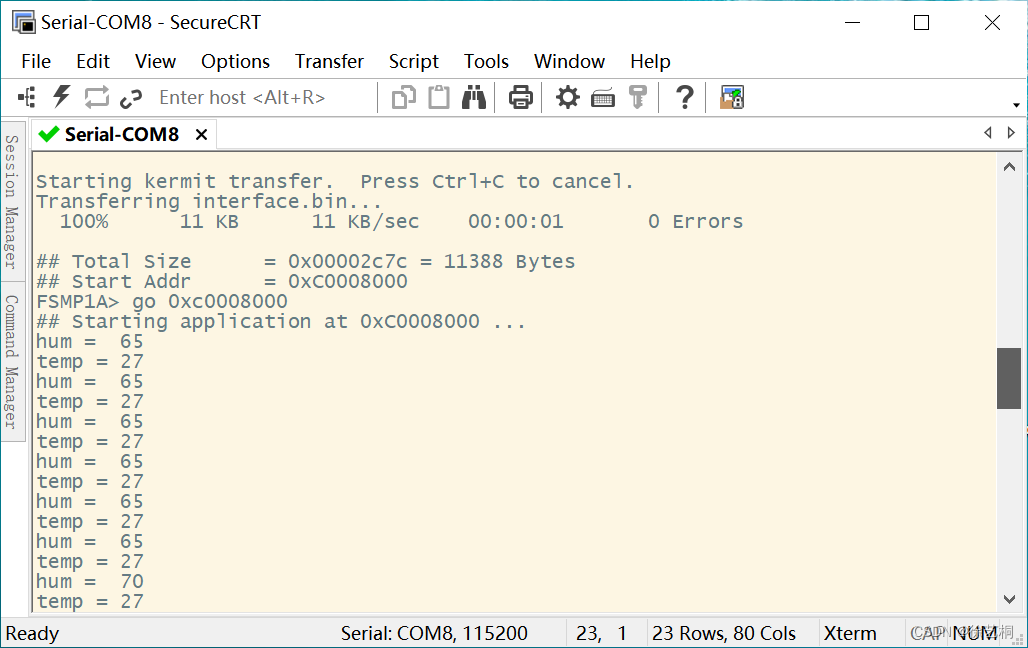
C语言 Cortex-A7核 IIC实验
iic.h #ifndef __IIC_H__ #define __IIC_H__ #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_rcc.h" /* 通过程序模拟实现I2C总线的时序和协议* GPIOF ---> AHB4* I2C1_SCL ---> PF14* I2C1_SDA ---> PF15** */#define SET_SDA_OUT do{…...
【每日一题】2769. 找出最大的可达成数字
2769. 找出最大的可达成数字 - 力扣(LeetCode) 给你两个整数 num 和 t 。 如果整数 x 可以在执行下述操作不超过 t 次的情况下变为与 num 相等,则称其为 可达成数字 : 每次操作将 x 的值增加或减少 1 ,同时可以选择将 …...
开源电子合同签署平台小程序源码 在线签署电子合同小程序源码 合同在线签署源码
聚合市场上各类电子合同解决方案商,你无需一个一个的对接电子合同厂商, 费时,费力,因为这个工作我们已经做了适配,你只需要一个接口就能使用我们的所有服务商, 同时你还可以享受我们的接口渠道价格。 Mini-…...
36 二叉树中序遍历
二叉树中序遍历 题解1 递归题解2 迭代 给定一个二叉树的根节点 root ,返回它的 中序 遍历 。 提示: 树中节点数目在范围 [0, 100] 内-100 < Node.val < 100 进阶: 递归算法很简单,你可以通过迭代算法完成吗? 题解1 递归…...

广州华锐互动:VR结绳逃生训练模拟真实火灾场景,增强训练沉浸感
随着科技的发展,虚拟现实(VR)技术已被广泛应用到各个领域,其中包括消防训练。VR消防结绳训练是一种创新的消防训练方式,它通过虚拟现实技术模拟真实的灭火场景,使消防人员能够在无风险的环境中进行高强度的…...

Flink安装及简单使用
目录 转载处(个人用最新1.17.1测试) 依赖环境 安装包下载地址 Flink本地模式搭建 安装 启动集群 查看WebUI 停止集群 Flink Standalone搭建 安装 修改flink-conf.yaml配置文件 修改workers文件 复制Flink安装文件到其他服务器 启动集群 查…...

QT信号槽
目录 信号槽的概念 按钮的常用信号 自定义槽函数 自定义信号函数 自定义槽和信号注意的事项 信号与槽的拓展 lambda表达式 信号槽的概念 信号槽是Qt框架引以为豪的机制之一。所谓信号槽,实际就是观察者模式。当某个事件发生之后,比如,…...
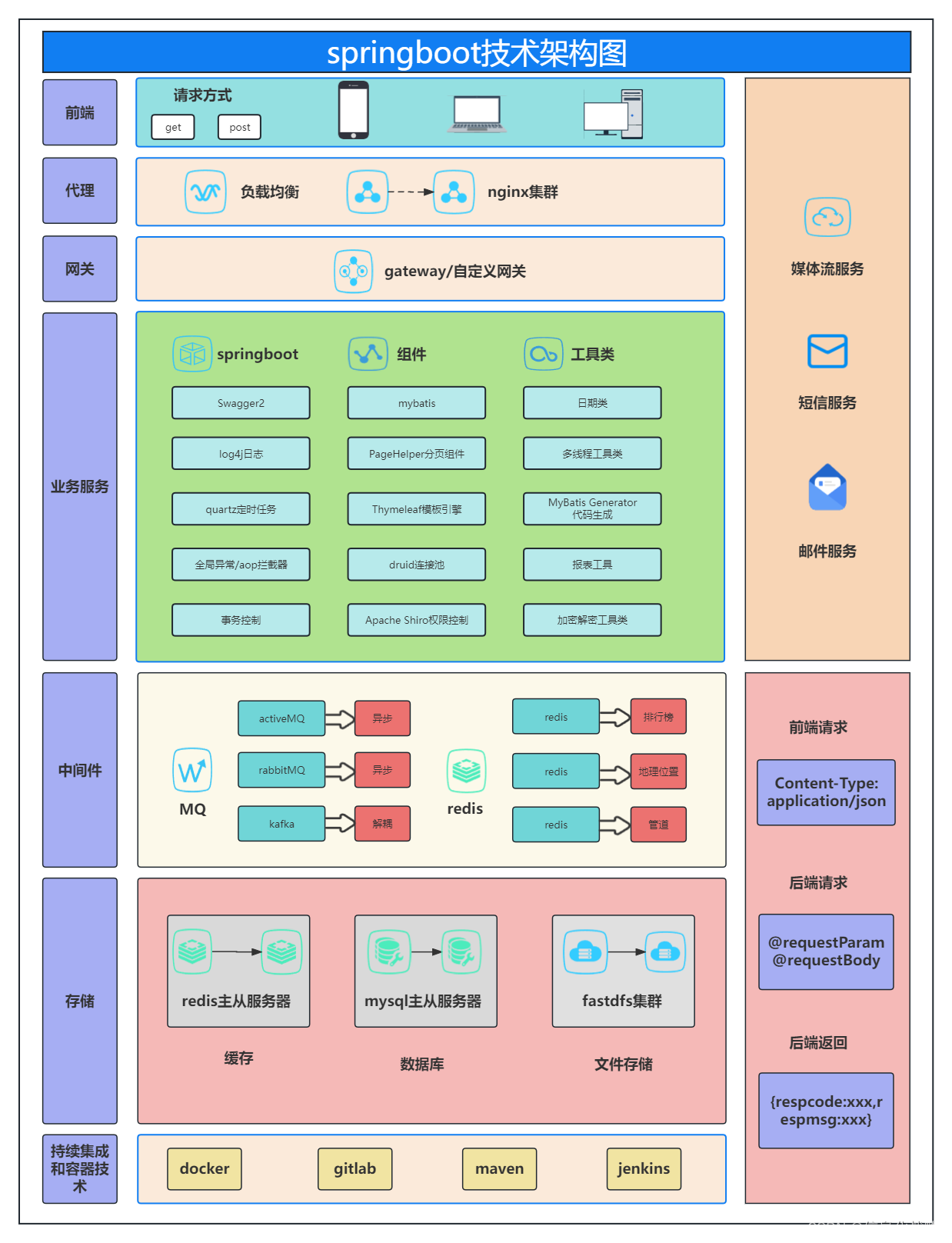
Spring Boot 技术架构图(InsCode AI 创作助手辅助)
Spring Boot 技术架构是一种用于构建现代应用程序的框架,它可以与各种前端、代理、网关、业务服务、中间件、存储、持续集成和容器服务集成在一起,以创建功能强大的应用程序。 源文件下载链接!!!!ÿ…...

python使用mitmproxy和mitmdump抓包在手机上抓包(三)
现在手机的使用率远超过电脑,所以这篇记录用mitmproxy抓手机包,实现手机流量监控。 环境:win10 64位,Python 3.10.4,雷电模拟器4.0.78,android版本7.1.2(设置-拉至最底部-关于平板电脑…...
react create-react-app v5 从零搭建(使用 npm run eject)
前言: 好久没用 create-react-app做项目了,这次为了个h5项目,就几个页面,决定自己搭建一个(ps:mmp 好久没用,搭建的时候遇到一堆问题)。 我之前都是使用 umi 。后台管理系统的项目 使用 antd-…...

计算机毕业设计springboot任我行——旅游推荐系统的开发 基于SpringBoot的“智游云“——个性化旅游行程规划系统 基于协同过滤算法的“旅途通“——智慧旅游服务平台设计与实现
计算机毕业设计springboot任我行——旅游推荐系统的开发407g1l6t (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。在互联网与移动设备全面普及的今天,旅游业正经历着前…...
)
Linux环境下用Docker Compose一键部署RuoYi-Cloud(附完整配置文件和脚本)
Linux环境下用Docker Compose高效部署RuoYi-Cloud微服务系统 在当今快速迭代的软件开发环境中,微服务架构因其灵活性和可扩展性受到广泛青睐。RuoYi-Cloud作为一款基于Spring Cloud的微服务快速开发框架,为开发者提供了开箱即用的解决方案。本文将详细介…...

Stable Diffusion Anything V5商业应用:自动生成商品主图实战
Stable Diffusion Anything V5商业应用:自动生成商品主图实战 1. 引言:电商视觉内容的生产痛点 在当今电商行业,商品主图的质量直接影响着点击率和转化率。传统商品摄影面临三大核心挑战: 成本高昂:专业摄影棚、器材…...

建筑设计师用飞扬就会 BIM 设计了
告别复杂建模、告别多软件切换、告别图模不一,飞扬集成设计系统让每一位习惯 CAD 的建筑设计师,零基础也能快速上手 BIM 正向设计,用熟悉的操作逻辑,做出专业级 BIM 成果。零门槛转型:CAD 老设计师也能直接上手不用重新…...

50. 随机数排序
50. 随机数排序 题目描述 生成 N 个 1 到 500 的随机数,你需要删除掉其中重复的数字,即相同的数字只保留一个,把其余相同的数字去掉,然后再把这些数从小到大进行输出。 输入描述 第一行先输入随机整数的个数 N 。 接下来一行包含 …...

AppKit:嵌入式Linux C++应用开发框架
1. 项目概述AppKit 是一个面向嵌入式 Linux 平台的 C14 应用开发框架,其设计目标明确指向两个核心工程诉求:提升应用层开发效率与增强运行时健壮性。在资源受限、实时性要求严苛、长期稳定运行成为刚需的嵌入式 Linux 场景中,开发者常面临重复…...
:Spring Boot后端与Docker Compose串联)
从零开始!Vue3+SpringBoot前后端分离项目Docker部署实战(中):Spring Boot后端与Docker Compose串联
📝 前言 在[上一篇文章]中,我们已经在 CentOS 服务器上配置好了 Docker,并优雅地实现了 MySQL 数据的一键初始化和持久化。 本篇我们将继续向核心迈进:把我们的 Spring Boot 后端项目进行打包镜像化,同时利用 Docker C…...

终极ShopXO秒杀功能优化指南:从0到1打造高并发促销系统
终极ShopXO秒杀功能优化指南:从0到1打造高并发促销系统 【免费下载链接】ShopXO开源商城 🔥🔥🔥ShopXO企业级免费开源商城系统,可视化DIY拖拽装修、包含PC、H5、多端小程序(微信支付宝百度头条&抖音QQ快手)、APP、…...

UNIT-00:Berserk Interface 探讨操作系统原理:虚拟内存、进程调度与文件系统
UNIT-00:Berserk Interface 探讨操作系统原理:虚拟内存、进程调度与文件系统 操作系统听起来总是有点高深莫测,什么内核、调度、内存管理,一堆术语让人头大。但如果你拆开来看,它其实就是一个超级管家,负责…...

Qt导航栏组件C01:IDE风格项目浏览器
目录 一、引言 二、最终效果预览 三、核心实现原理 3.1 布局结构设计 3.2 核心技术点 四、代码实现详解 4.1 项目结构 4.2 导航组件的核心代码 4.3 样式表设计 五、总结 源码下载 系列编号:C-01 导航风格:深色单栏侧边栏,多级树形文件导航,支持文件类型过滤与名称搜索,右侧…...