【多任务案例:猫狗脸部定位与分类】
【猫狗脸部定位与识别】
- 1 引言
- 2 损失函数
- 3 The Oxford-IIIT Pet Dataset数据集
- 4 数据预处理
- 4 创建模型输入
- 5 自定义数据集加载方式
- 6 显示一批次数据
- 7 创建定位模型
- 8 模型训练
- 9 绘制损失曲线
- 10 模型保存与预测
1 引言
猫狗脸部定位与识别分为定位和识别,即定位猫狗脸部位置,识别脸部是狗还是猫。

针对既要预测类别还要定位目标位置的问题,首先使用卷积模型提取图片特征,然后分别连接2个输出,一个做回归输出位置(xim,ymin,xmax,ymax);另一个做分类,输出两个类别概率(0,1)。
2 损失函数
回归问题使用L2损失–均方误差(MSE_loss),分类问题使用交叉熵损失(CrossEntropyLoss),将两者相加即为总损失。
3 The Oxford-IIIT Pet Dataset数据集
数据来源:https://www.robots.ox.ac.uk/~vgg/data/pets/

包含两类(猫和狗)共37种宠物,每种宠物约有200张图。
dataset文件结构如下:
±–dataset
| ±–annotations
| | ±–trimaps
| | —xmls
| —images
images包含所有猫狗图片,annotation包含标签数据和trimaps(三元图[0,1,2])标签图,xmls包含脸部坐标位置和种类。
4 数据预处理
(1)导入基本库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import dataimport numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineimport torchvision
from torchvision import transforms
import osfrom lxml import etree # etree网页解析模块 # 安装 lxml : conda install lxml
from matplotlib.patches import Rectangle # Rectangle画矩形
import globfrom PIL import Image
(2)读取一张图片
BATCH_SIZE = 4
pil_img = Image.open(r'dataset/images/Abyssinian_1.jpg')
np_img = np.array(pil_img)
print(np_img.shape)
plt.imshow(np_img)
plt.show()

(3) 打开一个xml文件
xml = open(r'dataset/annotations/xmls/Abyssinian_1.xml').read()
sel = etree.HTML(xml)
width = sel.xpath('//size/width/text()')[0]height = sel.xpath('//size/height/text()')[0]
xmin = sel.xpath('//bndbox/xmin/text()')[0]
ymin = sel.xpath('//bndbox/ymin/text()')[0]
xmax = sel.xpath('//bndbox/xmax/text()')[0]
ymax = sel.xpath('//bndbox/ymax/text()')[0]width = int(width)
height = int(height)
xmin = int(xmin)
ymin = int(ymin)
xmax = int(xmax)
ymax = int(ymax)plt.imshow(np_img)
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')
ax = plt.gca()
ax.axes.add_patch(rect)
plt.show()

(4)当图片的尺寸发生变化时,脸部的定位坐标要相对原来的宽高按比例缩放(xmin=xmin* new_ width/old_width)
img = pil_img.resize((224, 224))xmin = xmin*224/width
ymin = ymin*224/height
xmax = xmax*224/width
ymax = ymax*224/heightplt.imshow(img)
rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')
ax = plt.gca()
ax.axes.add_patch(rect)
plt.show()

4 创建模型输入
xml和images数量不一致,并不是所有图片都具有标签,所以需要逐一找出具有位置信息的图片并保存地址
images = glob.glob('dataset/images/*.jpg')
print(images[:5])
print(len(images)) xmls = glob.glob('dataset/annotations/xmls/*.xml')
print(len(xmls)) # xml和images数量不一致,并不是所有图片都具有标签,所以需要逐一找出具有位置信息的图片并保存地址
print(xmls[:5]) xmls_names = [x.split('/')[-1].split('.xml')[0] for x in xmls]
print(xmls_names[:3])
print(len(xmls_names))# 遍历所有具有定位坐标的图片,并保存图片路径
imgs = [img for img in images if img.split('/')[-1].split('.jpg')[0] in xmls_names]print(len(imgs))
print(imgs[:5])# 重新定义尺寸为224,并将定位和类别保存到labels中
scal = 224
name_to_id = {'cat':0, 'dog':1}
id_to_name = {0:'cat', 1:'dog'}
def to_labels(path):xml = open(r'{}'.format(path)).read()sel = etree.HTML(xml)name = sel.xpath('//object/name/text()')[0]width = int(sel.xpath('//size/width/text()')[0])height = int(sel.xpath('//size/height/text()')[0])xmin = int(sel.xpath('//bndbox/xmin/text()')[0])ymin = int(sel.xpath('//bndbox/ymin/text()')[0])xmax = int(sel.xpath('//bndbox/xmax/text()')[0])ymax = int(sel.xpath('//bndbox/ymax/text()')[0])return (xmin/width, ymin/height, xmax/width, ymax/height, name_to_id.get(name))
labels = [to_labels(path) for path in xmls]np.random.seed(2022)
index = np.random.permutation(len(imgs))# 划分训练集和测试集
images = np.array(imgs)[index]
print(images[0])
labels = np.array(labels, np.float32)[index]
print(labels[0])sep = int(len(imgs)*0.8)
train_images = images[ :sep]
train_labels = labels[ :sep]
test_images = images[sep: ]
test_labels = labels[sep: ]
输出如下:
['dataset/images/german_shorthaired_102.jpg','dataset/images/havanese_150.jpg','dataset/images/great_pyrenees_143.jpg','dataset/images/Bombay_41.jpg','dataset/images/newfoundland_2.jpg']
7390
3686['dataset/annotations/xmls/american_bulldog_178.xml','dataset/annotations/xmls/scottish_terrier_114.xml','dataset/annotations/xmls/american_pit_bull_terrier_179.xml','dataset/annotations/xmls/Birman_171.xml','dataset/annotations/xmls/staffordshire_bull_terrier_107.xml']['american_bulldog_178','scottish_terrier_114','american_pit_bull_terrier_179']36863686['dataset/images/german_shorthaired_102.jpg','dataset/images/havanese_150.jpg','dataset/images/great_pyrenees_143.jpg','dataset/images/samoyed_137.jpg','dataset/images/newfoundland_189.jpg']['dataset/annotations/xmls/american_bulldog_178.xml','dataset/annotations/xmls/scottish_terrier_114.xml','dataset/annotations/xmls/american_pit_bull_terrier_179.xml','dataset/annotations/xmls/Birman_171.xml','dataset/annotations/xmls/staffordshire_bull_terrier_107.xml']dataset/images/pug_184.jpg
[0.19117647 0.21 0.8 0.624 1. ]
5 自定义数据集加载方式
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),
])class Oxford_dataset(data.Dataset):def __init__(self, img_paths, labels, transform):self.imgs = img_pathsself.labels = labelsself.transforms = transformdef __getitem__(self, index):img = self.imgs[index]label = self.labels[index]pil_img = Image.open(img) pil_img = pil_img.convert("RGB")pil_img = transform(pil_img)return pil_img, label[:4],label[4] # 图片像素(3, 224, 224),定位4个值,分类1个值def __len__(self):return len(self.imgs)train_dataset = Oxford_dataset(train_images, train_labels, transform)
test_dataset = Oxford_dataset(test_images, test_labels, transform)
train_dl = data.DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True)
test_dl = data.DataLoader(test_dataset,batch_size=BATCH_SIZE)
6 显示一批次数据
(imgs_batch, labels1_batch,labels2_batch) = next(iter(train_dl))
print(imgs_batch.shape, labels1_batch.shape,labels2_batch.shape)plt.figure(figsize=(12, 8))
for i, (img, label_1,label_2) in enumerate(zip(imgs_batch[:6], labels1_batch[:6],labels2_batch[:6])):img = img.permute(1,2,0).numpy() #+ 1)/2plt.subplot(2, 3, i+1)plt.imshow(img)plt.title(id_to_name.get(label_2.item()))xmin, ymin, xmax, ymax = tuple(label_1.numpy()*224)rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')ax = plt.gca()ax.axes.add_patch(rect)
plt.savefig('pics/example.jpg', dpi=400)
输出如下:
(torch.Size([4, 3, 224, 224]), torch.Size([4, 4]), torch.Size([4]))
在这里插入代码片

7 创建定位模型
借用renet50网络模型的卷积部分,而分类部分自定义如下:
resnet = torchvision.models.resnet50(pretrained=True)
#print(resnet)
in_f = resnet.fc.in_features
print(in_f)
print(list(resnet.children())) # 以生成器形式返回模型所包含的所有层
输出如下:
2048
[Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False), BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True), ReLU(inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False), Sequential((0): Bottleneck((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(2): Bottleneck(
...(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))
), AdaptiveAvgPool2d(output_size=(1, 1)), Linear(in_features=2048, out_features=1000, bias=True)]
自定义分类和定位模型如下:
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv_base = nn.Sequential(*list(resnet.children())[:-1]) # 以生成器方式返回模型所包含的所有层self.fc1 = nn.Linear(in_f, 4) # 位置坐标self.fc2 = nn.Linear(in_f, 2) # 两分类概率def forward(self, x):x = self.conv_base(x)x = x.view(x.size(0), -1)x1 = self.fc1(x)x2 = self.fc2(x)return x1,x2
8 模型训练
model = Net()device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = model.to(device)
loss_mse = nn.MSELoss()
loss_crossentropy = nn.CrossEntropyLoss()from torch.optim import lr_scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.5, verbose = True)def train(dataloader, model, loss_mse,loss_crossentropy, optimizer): num_batches = len(dataloader)train_loss = 0model.train()for X, y1,y2 in dataloader:X, y1, y2 = X.to(device), y1.to(device), y2.to(device)# Compute prediction errory1_pred, y2_pred = model(X)loss = loss_mse(y1_pred, y1) + loss_crossentropy(y2_pred,y2.long())# Backpropagationoptimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():train_loss += loss.item()train_loss /= num_batchesreturn train_lossdef test(dataloader, model,loss_mse,loss_crossentropy): num_batches = len(dataloader)model.eval()test_loss = 0with torch.no_grad():for X, y1, y2 in dataloader:X, y1, y2 = X.to(device), y1.to(device), y2.to(device)# Compute prediction errory1_pred, y2_pred = model(X)loss = loss_mse(y1_pred, y1) + loss_crossentropy(y2_pred,y2.long())test_loss += loss.item()test_loss /= num_batchesreturn test_lossdef fit(epochs, train_dl, test_dl, model, loss_mse,loss_crossentropy, optimizer): train_loss = []test_loss = []for epoch in range(epochs):epoch_loss = train(train_dl, model, loss_mse,loss_crossentropy, optimizer) #epoch_test_loss = test(test_dl, model, loss_mse,loss_crossentropy) #train_loss.append(epoch_loss)test_loss.append(epoch_test_loss)exp_lr_scheduler.step()template = ("epoch:{:2d}/{:2d}, train_loss: {:.5f}, test_loss: {:.5f}")print(template.format(epoch+1,epochs, epoch_loss, epoch_test_loss))print("Done!")return train_loss, test_lossepochs = 50train_loss, test_loss = fit(epochs, train_dl, test_dl, model, loss_mse,loss_crossentropy, optimizer) #输出如下:
Using cuda deviceAdjusting learning rate of group 0 to 1.0000e-04.
epoch: 1/50, train_loss: 0.68770, test_loss: 0.69263
Adjusting learning rate of group 0 to 1.0000e-04.
epoch: 2/50, train_loss: 0.64950, test_loss: 0.69668
Adjusting learning rate of group 0 to 1.0000e-04.
epoch: 3/50, train_loss: 0.63532, test_loss: 0.71381
Adjusting learning rate of group 0 to 1.0000e-04.
epoch: 4/50, train_loss: 0.61014, test_loss: 0.74332
Adjusting learning rate of group 0 to 1.0000e-04.
epoch: 5/50, train_loss: 0.57072, test_loss: 0.76198
Adjusting learning rate of group 0 to 1.0000e-04.
epoch: 6/50, train_loss: 0.45499, test_loss: 0.93127
Adjusting learning rate of group 0 to 5.0000e-05.
epoch: 7/50, train_loss: 0.31113, test_loss: 0.96860
Adjusting learning rate of group 0 to 5.0000e-05.
epoch: 8/50, train_loss: 0.14169, test_loss: 1.35223
Adjusting learning rate of group 0 to 5.0000e-05.
epoch: 9/50, train_loss: 0.08092, test_loss: 1.50338
Adjusting learning rate of group 0 to 5.0000e-05.
epoch:10/50, train_loss: 0.06381, test_loss: 1.49817
Adjusting learning rate of group 0 to 5.0000e-05.
epoch:11/50, train_loss: 0.05252, test_loss: 1.49126
Adjusting learning rate of group 0 to 5.0000e-05.
epoch:12/50, train_loss: 0.04227, test_loss: 1.45301
Adjusting learning rate of group 0 to 5.0000e-05.
...
epoch:49/50, train_loss: 0.00632, test_loss: 2.19361
Adjusting learning rate of group 0 to 7.8125e-07.
epoch:50/50, train_loss: 0.00594, test_loss: 2.16411
Done!
9 绘制损失曲线
结果较差,需要优化网络模型,但思路不变。
plt.figure()
plt.plot(range(1, len(train_loss)+1), train_loss, 'r', label='Training loss')
plt.plot(range(1, len(train_loss)+1), test_loss, 'b', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.legend()
plt.show()

10 模型保存与预测
PATH = 'model_path/location_model.pth'
torch.save(model.state_dict(), PATH)
model = Net()
model.load_state_dict(torch.load(PATH))
model = model.cuda() #.cpu() 模型使用GPU或CPU加载plt.figure(figsize=(8, 8))
imgs, _,_ = next(iter(test_dl))
imgs =imgs.to(device)
out1,out2 = model(imgs)
for i in range(4):plt.subplot(2, 2, i+1)plt.imshow(imgs[i].permute(1,2,0).detach().cpu())plt.title(id_to_name.get(torch.argmax(out2[i],0).item()))xmin, ymin, xmax, ymax = tuple(out1[i].detach().cpu().numpy()*224)rect = Rectangle((xmin, ymin), (xmax-xmin), (ymax-ymin), fill=False, color='red')ax = plt.gca()ax.axes.add_patch(rect)
plt.savefig('pics/predict.jpg',dpi =400)

相关文章:
【多任务案例:猫狗脸部定位与分类】
【猫狗脸部定位与识别】 1 引言2 损失函数3 The Oxford-IIIT Pet Dataset数据集4 数据预处理4 创建模型输入5 自定义数据集加载方式6 显示一批次数据7 创建定位模型8 模型训练9 绘制损失曲线10 模型保存与预测 1 引言 猫狗脸部定位与识别分为定位和识别,即定位猫狗…...

.Net 锁的介绍
在.NET中,有多种锁机制可用于多线程编程,用来确保线程安全和共享资源的同步。以下是.NET中常见的锁机制: 1. **Monitor(互斥锁):** `Monitor` 是.NET中最基本的锁机制之一。它使用 `lock` 关键字实现,可以确保在同一时刻只有一个线程能够访问被锁定的代码块。`Monitor`…...

Office 2021 小型企业版商用办公软件评测:提升工作效率与协作能力的专业利器
作为一名软件评测人员,我将为您带来一篇关于 Office 2021 小型企业版商用办公软件的评测文章。在这篇评测中,我将从实用性、使用场景、优点和缺点等多个方面对该软件进行客观分析,在专业角度为您揭示它的真正实力和潜力。 一、实用性…...
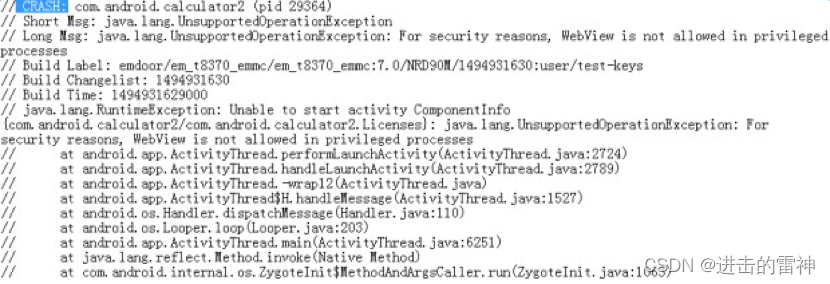
Monkey测试
一:测试环境搭建 1:下载android-sdk_r24.4.1-windows 2:下载Java 3:配置环境变量:关于怎么配置环境变量(百度一下:monkey环境搭建,) 二:monkey测试࿱…...

wzx-jmw:NFL合理,但可能被颠覆。2023-2024
As well known by all, NFL is ... 没有免费的午餐理论 No Free Lunch Theorem_免费午餐理论-CSDN博客 However, if we......
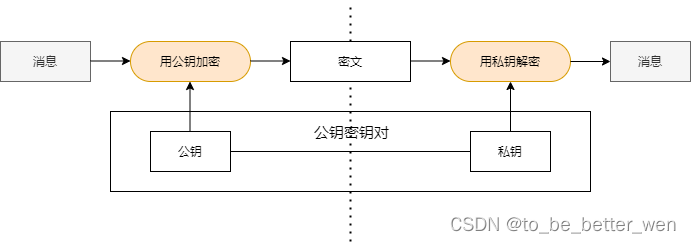
密码技术 (5) - 数字签名
一. 前言 前面在介绍消息认证码时,我们知道消息认证码虽然可以确认消息的完整性,但是无法防止否认问题。而数字签名可以解决否认的问题,接下来介绍数字签名的原理。 二. 数字签名的原理 数字签名和公钥密码一样,也有公钥和私钥&am…...
单引号和双引号的用法和区别)
php实战案例记录(10)单引号和双引号的用法和区别
在 PHP 中,单引号和双引号都被用于表示字符串。它们有一些共同之处,但也有一些明显的区别。 解析变量: 双引号允许解析变量,而单引号不会。在双引号中,你可以直接在字符串中插入变量,而不需要进行额外的连接…...
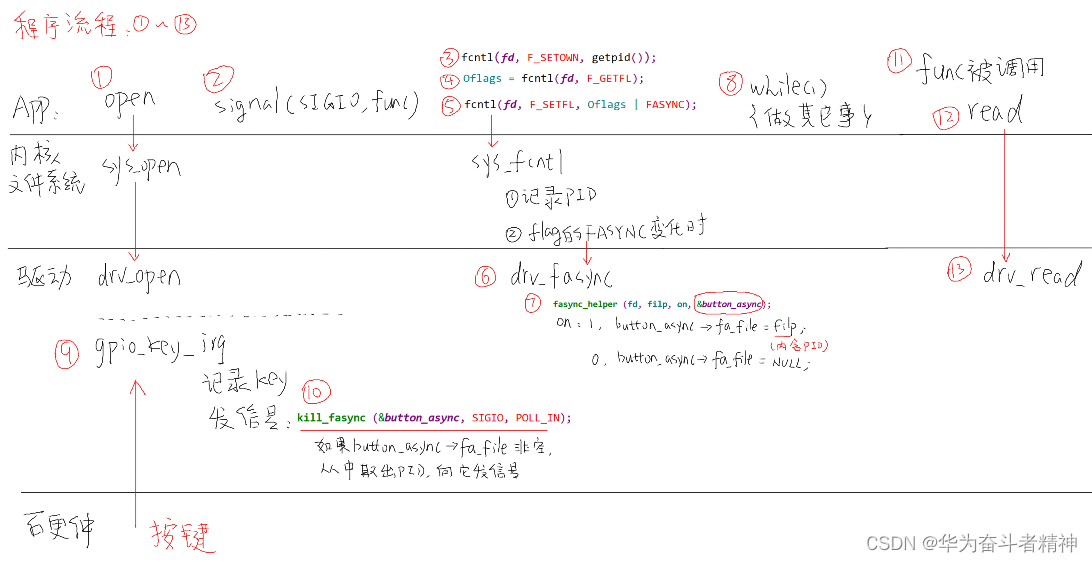
嵌入式Linux应用开发-基础知识-第十九章驱动程序基石②
嵌入式Linux应用开发-基础知识-第十九章驱动程序基石② 第十九章 驱动程序基石②19.3 异步通知19.3.1 适用场景19.3.2 使用流程19.3.3 驱动编程19.3.4 应用编程19.3.5 现场编程19.3.6 上机编程19.3.7 异步通知机制内核代码详解 19.4 阻塞与非阻塞19.4.1 应用编程19.4.2 驱动编程…...

trycatch、throw、throws
在Java中,try-catch、throw和throws是用于处理异常的重要关键字和机制,它们的作用如下: try-catch:try-catch 是用于捕获和处理异常的语句块。在try块中放置可能引发异常的代码。如果在try块中的代码引发了异常,控制流会跳转到与异常类型匹配的catch块。在catch块中,可以…...

问 ChatGPT 关于 GPT 的事情:数据准备篇
一、假如你是一名人工智能工程师,手里有一个65B的GPT大模型,但你需要一个6B左右的小模型,你会怎么做? 答:作为人工智能工程师,如果我手里有一个65B的GPT大模型,而我需要一个6B左右的小模型&…...

leetcode_17电话号码的组合
1. 题意 输出电话号码对应的字母左右组合 电话号码的组合 2. 题解 回溯 class Solution { public:void gen_res(vector<string> &res, vector<string> &s_m,string &digits, string &t, size_t depth) {if (depth digits.size()) {if ( !t.em…...

记录使用vue-test-utils + jest 在uniapp中进行单元测试
目录 前情安装依赖package.json配置jest配置测试文件目录编写setup.js编写第一个测试文件jest.fn()和jest.spyOn()jest 解析scss失败测试vuex$refs定时器测试函数调用n次手动调用生命周期处理其他模块导入的函数测试插槽 前情 uniapp推荐了测试方案dcloudio/uni-automator&…...

《C和指针》笔记30:函数声明数组参数、数组初始化方式和字符数组的初始化
文章目录 1. 函数声明数组参数2. 数组初始化方式2.1 静态初始化2.2 自动变量初始化 2.2 字符数组的初始化 1. 函数声明数组参数 下面两个函数原型是一样的: int strlen( char *string ); int strlen( char string[] );可以使用任何一种声明,但哪个“更…...

VBA技术资料MF64:遍历单元格搜索字符并高亮显示
【分享成果,随喜正能量】不要在乎他人的评论,不必理论与他人有关的是非,你只要做好自己就够了。苔花如米小,也学牡丹开。无论什么时候,都要有忠于自己的勇气,去做喜欢的事,去认识喜欢的人&#…...

一键智能视频编辑与视频修复算法——ProPainter源码解析与部署
前言 视频编辑和修复确实是随着电子产品的普及变得越来越重要的技能。有许多视频编辑工具可以帮助人们轻松完成这些任务如:Adobe Premiere Pro,Final Cut Pro X,Davinci Resolve,HitFilm Express,它们都提供一些视频修…...

Flutter开发环境的配置
2023-10最新版本 flutter SDK版本下载地址 https://flutter.cn/docs/development/tools/sdk/releases gradle各版本快速下载地址 https://blog.csdn.net/ii950606/article/details/109105402 JAVA SDK下载地址 https://www.oracle.com/java/technologies/downloads/#java…...

【超详细】Wireshark教程----Wireshark 分析ICMP报文数据试验
一,试验环境搭建 1-1 试验环境示例图 1-2 环境准备 两台kali主机(虚拟机) kali2022 192.168.220.129/24 kali2022 192.168.220.3/27 1-2-1 网关配置: 编辑-------- 虚拟网路编辑器 更改设置进来以后 ,先选择N…...
之rm)
Linux命令(92)之rm
linux命令之rm 1.rm介绍 linux命令rm是用来删除一个或多个文件/目录,由于其删除的不可逆性,建议在日常工作中一定要慎用 2.rm用法 rm [参数] 文件/目录 rm常用参数 参数说明-r递归删除文件或目录-f不提示强制删除-i删除文件或目录前进行确认-v详细显…...
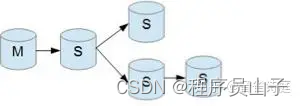
Mysql主从复制数据架构全面解读
大家好,我是山子,今天给大家分析Mysql 实现主从复制的方方面面,主从复制当然也是我们做读写分离的前提,以下内容是从各网络平台摘录整理总结归纳在一起的;内容已经从主从复制的各方面的维度进行了阐述;非常…...
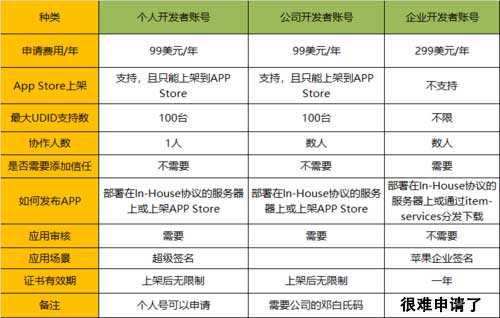
ios证书类型及其作用说明
ios证书类型及其作用说明 很多刚开始接触iOS证书的开发者可能不是很了解iOS证书的类型功能和概念。下面对iOS证书的几个方面进行介绍。 apple开发账号分类: 免费账号: 无需支付费用给apple,使用个人信息注册的账号 可以开发测试安装&…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

MySQL 部分重点知识篇
一、数据库对象 1. 主键 定义 :主键是用于唯一标识表中每一行记录的字段或字段组合。它具有唯一性和非空性特点。 作用 :确保数据的完整性,便于数据的查询和管理。 示例 :在学生信息表中,学号可以作为主键ÿ…...

C# WPF 左右布局实现学习笔记(1)
开发流程视频: https://www.youtube.com/watch?vCkHyDYeImjY&ab_channelC%23DesignPro Git源码: GitHub - CSharpDesignPro/Page-Navigation-using-MVVM: WPF - Page Navigation using MVVM 1. 新建工程 新建WPF应用(.NET Framework) 2.…...

十二、【ESP32全栈开发指南: IDF开发环境下cJSON使用】
一、JSON简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,具有以下核心特性: 完全独立于编程语言的文本格式易于人阅读和编写易于机器解析和生成基于ECMAScript标准子集 1.1 JSON语法规则 {"name"…...

Spring Boot SQL数据库功能详解
Spring Boot自动配置与数据源管理 数据源自动配置机制 当在Spring Boot项目中添加数据库驱动依赖(如org.postgresql:postgresql)后,应用启动时自动配置系统会尝试创建DataSource实现。开发者只需提供基础连接信息: 数据库URL格…...

小白的进阶之路系列之十四----人工智能从初步到精通pytorch综合运用的讲解第七部分
通过示例学习PyTorch 本教程通过独立的示例介绍PyTorch的基本概念。 PyTorch的核心提供了两个主要特性: 一个n维张量,类似于numpy,但可以在gpu上运行 用于构建和训练神经网络的自动微分 我们将使用一个三阶多项式来拟合问题 y = s i n ( x ) y=sin(x) y=sin(x),作为我们的…...

ubuuntu24.04 编译安装 PostgreSQL15.6+postgis 3.4.2 + pgrouting 3.6.0 +lz4
文章目录 下载基础包下载源码包编译 PG编译 postgis编译安装 pgrouting下载源码包配置编译参数编译安装 初始化数据库建表并检查列是否使用了 lz4 压缩算法检查 postgis 与 pgrouting 是否可以成功创建 下载基础包 sudo apt update && sudo apt upgrade -y sudo apt i…...