Pandas进阶修炼120题-第五期(一些补充,101-120题)
目录
- 往期内容:
- 第一期:Pandas基础(1-20题)
- 第二期:Pandas数据处理(21-50题)
- 第三期:Pandas金融数据处理(51-80题)
- 第四期:当Pandas遇上NumPy(81-100题)
- 第五期:一些补充(101-120题)
- 第五期 一些补充
- 101.从CSV文件中读取指定数据
- 102.从CSV文件中读取指定数据
- 103.从上一题数据中,对薪资水平列每隔20行进行一次抽样
- 其他采样示例
- 104.将数据取消使用科学计数法
- 标准答案:round方法,实际上修改了数据值,谨慎使用
- 推荐方法:pd.set_option('display.float_format')
- 两种方法的区别
- 105.将上一题的数据转换为百分数
- 标准答案:df.style.format()方法 不会更改数据
- 直接修改法:当数据类型为numpy.ndarray时 会更改数据本身
- 直接修改法2:当数据类型为dataframe时 会修改数据本身
- 再拓展 : "{:.2f}%".format(p) 与'{0:.2%}'.format(p)
- 106.查找上一题数据中第3大值的行号
- 方法一:
- 方法二:
- 107.反转df的行
- 方法一:
- 方法二:本质是和方法一一样,但是有个容易忽略的点
- 108.按照多列对数据进行合并
- 109.按照多列对数据进行合并
- 110.再次读取数据1并显示所有的列
- 拓展:pd.set_option("display.max_columns", None)
- 111.查找secondType与thirdType值相等的行号
- 方法一:布尔索引
- 方法二:loc方法
- 方法三:np.where()
- 112.查找薪资大于平均薪资的第三个数据
- 方法一:找到薪资大于均值的数据,选择第三个
- 方法二:np.argwhere()
- 113.将上一题数据的salary列开根号
- 114.将上一题数据的linestaion列按_拆分
- 115.查看上一题数据中一共有多少列
- 116.提取industryField列以'数据'开头的行
- 117.按列制作数据透视表
- 118.同时对salary、score两列进行计算
- 119.对salary求平均,对score列求和
- 120.计算并提取平均薪资最高的区
自己再写一遍的pandas习题,相比于标准答案添加了自己的理解与注释,也可直接下载链接上的原习题(未加注释的初始版带答案)
链接:https://pan.baidu.com/s/1arrqcBFZKqJngzRzUB2QfA?pwd=29eb
提取码:29eb
–来自百度网盘超级会员V3的分享
往期内容:
-
第一期:Pandas基础(1-20题)
-
第二期:Pandas数据处理(21-50题)
-
第三期:Pandas金融数据处理(51-80题)
-
第四期:当Pandas遇上NumPy(81-100题)
-
第五期:一些补充(101-120题)
第五期 一些补充
import numpy as np
import pandas as pd
101.从CSV文件中读取指定数据
# 备注:从数据1中的前10行中读取positionName, salary两列
df = pd.read_csv('pandas120_101_120_1.csv',encoding = 'gbk',usecols=['positionName','salary'],nrows=10)
df
| positionName | salary | |
|---|---|---|
| 0 | 数据分析 | 37500 |
| 1 | 数据建模 | 15000 |
| 2 | 数据分析 | 3500 |
| 3 | 数据分析 | 45000 |
| 4 | 数据分析 | 30000 |
| 5 | 数据分析 | 50000 |
| 6 | 数据分析 | 30000 |
| 7 | 数据建模工程师 | 35000 |
| 8 | 数据分析专家 | 60000 |
| 9 | 数据分析师 | 40000 |
102.从CSV文件中读取指定数据
# 备注:从数据2中读取数据并在读取数据时将薪资大于10000的为改为高
df = pd.read_csv('pandas120_101_120_2.csv',converters={'薪资水平':lambda x: '高' if float(x) > 10000 else '低'})
df
| 学历要求 | 薪资水平 | |
|---|---|---|
| 0 | 本科 | 高 |
| 1 | 硕士 | 高 |
| 2 | 本科 | 低 |
| 3 | 本科 | 高 |
| 4 | 不限 | 高 |
| ... | ... | ... |
| 1149 | 硕士 | 高 |
| 1150 | 本科 | 高 |
| 1151 | 本科 | 高 |
| 1152 | 本科 | 高 |
| 1153 | 本科 | 高 |
1154 rows × 2 columns
converters:是一个参数,允许你为某些列定义转换函数,这个函数会在读取数据时应用
使用方法:
- 以字典键值对的形式出现.
- 键是你想要做出修改的列名,本例中键是 “薪资水平”
- 值就是一个 lambda 函数.
本例中:
- x “薪资水平” 这一列的一个值.
- float(x) 将x转化为浮点类型.
- 检查 x 代表的值是否大于 10,000.
- 如果是, 返回字符串 ‘高’.
- 如果不是, 返回字符串 ‘低’.
其他用法示例:
1:将字符串日期转换为真正的日期:
converters={'date_column': pd.to_datetime}2:将某些特定的字符串值映射为 NaN:
converters={'some_column': lambda x: np.nan if x == 'unknown' else x}
3:对数值数据进行缩放:
converters={'value_column': lambda x: float(x) / 1000}
当使用 pandas 读取数据时,其他一些参数可以在加载数据时进行筛选或处理。以下是一些这样的参数及其功能:
-
dtype:- 用于指定列的数据类型。
- 例如,你可以使用
dtype={'column_name': int}来确保特定的列为整数类型。
-
usecols:- 允许你选择要加载的列。
- 例如,
usecols=['A', 'C']只会加载名为 ‘A’ 和 ‘C’ 的列。
-
skiprows:- 允许你跳过文件的前几行。
- 如果你知道前两行是无关的标题或其他信息,你可以使用
skiprows=2来跳过它们。
-
nrows:- 指定要读取的行数。
- 如果你只想加载文件的前 100 行,可以使用
nrows=100。
-
na_values:- 指定应被解释为 NaN(即缺失数据)的值。
- 例如,如果你的数据集中使用 “unknown” 或 “-” 表示缺失值,你可以使用
na_values=['unknown', '-']。
-
parse_dates:- 尝试将数据解析为日期。
- 可以指定要解析为日期的列,例如
parse_dates=['date_column']。
-
date_parser:- 用于解析日期的函数。
- 当与
parse_dates一起使用时,它可以自定义日期解析的方式。
-
skipfooter:- 跳过文件的最后几行。
- 如果你知道文件的最后三行是汇总或其他不需要的信息,你可以使用
skipfooter=3。
-
squeeze:- 如果解析的数据只有一列,则返回 Series 而不是 DataFrame。
- 设置为
True时,如果数据只有一列,将返回一个 Series 对象。
这些参数都可以帮助你在加载数据时根据需要对数据进行预处理和筛选。当然,这只是其中的一部分参数,pandas 为数据加载提供了丰富的选项。你可以参考 pandas 官方文档来了解更多详细信息。
103.从上一题数据中,对薪资水平列每隔20行进行一次抽样
df.iloc[::20,:][['薪资水平']]
| 薪资水平 | |
|---|---|
| 0 | 高 |
| 20 | 高 |
| 40 | 高 |
| 60 | 高 |
| 80 | 高 |
| 100 | 高 |
| 120 | 高 |
| 140 | 高 |
| 160 | 高 |
| 180 | 高 |
| 200 | 高 |
| 220 | 高 |
| 240 | 高 |
| 260 | 高 |
| 280 | 低 |
| 300 | 高 |
| 320 | 高 |
| 340 | 低 |
| 360 | 高 |
| 380 | 高 |
| 400 | 高 |
| 420 | 高 |
| 440 | 高 |
| 460 | 低 |
| 480 | 高 |
| 500 | 高 |
| 520 | 高 |
| 540 | 高 |
| 560 | 高 |
| 580 | 高 |
| 600 | 高 |
| 620 | 高 |
| 640 | 高 |
| 660 | 低 |
| 680 | 低 |
| 700 | 高 |
| 720 | 高 |
| 740 | 高 |
| 760 | 高 |
| 780 | 高 |
| 800 | 高 |
| 820 | 高 |
| 840 | 高 |
| 860 | 低 |
| 880 | 高 |
| 900 | 高 |
| 920 | 高 |
| 940 | 高 |
| 960 | 高 |
| 980 | 高 |
| 1000 | 高 |
| 1020 | 高 |
| 1040 | 高 |
| 1060 | 高 |
| 1080 | 高 |
| 1100 | 高 |
| 1120 | 高 |
| 1140 | 高 |
其他采样示例
以下是一些常用的采样方法:
-
随机采样:
使用 DataFrame 的sample()方法,你可以轻松地进行随机抽样。# 抽取 10% 的数据 sample_df = df.sample(frac=0.1)# 或者直接抽取 10 行数据 sample_df = df.sample(n=10) -
分层采样:
如果你想根据某个特定的列进行分层抽样,你可以使用groupby配合sample。例如,假设你想根据 “薪资水平” 列进行分层,每层抽取 5 个样本:sample_df = df.groupby('薪资水平').apply(lambda x: x.sample(n=5)).reset_index(drop=True) -
时间序列数据的采样:
如果你的数据是时间序列数据,你可能会想要按特定的频率进行采样。这时,你可以使用resample方法。# 假设 'date' 是一个日期列,并且已经被设置为索引 # 以下代码每月抽取最后一个观测值 sample_df = df.resample('M').last() -
系统采样:
你已经看到了如何使用iloc进行系统采样(例如每隔 20 行)。这是一种简单且常用的方法。 -
权重采样:
如果你希望根据某列的值作为权重进行抽样,你可以使用sample方法的weights参数。# 假设 'weights_column' 是权重列 sample_df = df.sample(n=10, weights='weights_column') -
条件采样:
你可以使用布尔索引来根据某些条件对数据进行筛选。# 例如,选择所有薪资大于 10000 的行 high_salary_df = df[df['薪资水平'] > 10000]
选择哪种抽样方法取决于你的具体需求和数据的特性。在实际应用中,可能需要结合多种方法来达到理想的抽样效果。
104.将数据取消使用科学计数法
df = pd.DataFrame(np.random.random(10)**10,columns = ['column1'])
df
| column1 | |
|---|---|
| 0 | 1.265021e-08 |
| 1 | 7.763215e-05 |
| 2 | 5.331380e-01 |
| 3 | 3.177901e-07 |
| 4 | 1.341835e-03 |
| 5 | 1.488887e-05 |
| 6 | 3.226127e-12 |
| 7 | 1.604492e-08 |
| 8 | 1.836409e-01 |
| 9 | 4.988592e-02 |
标准答案:round方法,实际上修改了数据值,谨慎使用
df.round(5)
| column1 | |
|---|---|
| 0 | 0.00000 |
| 1 | 0.00008 |
| 2 | 0.53314 |
| 3 | 0.00000 |
| 4 | 0.00134 |
| 5 | 0.00001 |
| 6 | 0.00000 |
| 7 | 0.00000 |
| 8 | 0.18364 |
| 9 | 0.04989 |
推荐方法:pd.set_option(‘display.float_format’)
# 设置展示方式
pd.set_option('display.float_format','{:.10f}'.format)
df
| column1 | |
|---|---|
| 0 | 0.0000000127 |
| 1 | 0.0000776321 |
| 2 | 0.5331379960 |
| 3 | 0.0000003178 |
| 4 | 0.0013418353 |
| 5 | 0.0000148889 |
| 6 | 0.0000000000 |
| 7 | 0.0000000160 |
| 8 | 0.1836408734 |
| 9 | 0.0498859185 |
# 重置展示方式
pd.reset_option('display.float_format')
两种方法的区别
这里我们看到了两列的对比:
- display_setting 列:这列展示了在应用
pd.set_option('display.float_format', '{:.10f}'.format)设置后的数据显示效果。所有的浮点数都显示为10位小数,但实际的数据值没有改变。
如果您想要取消之前设置的 display.float_format 选项并恢复到 Pandas 的默认显示设置,您可以使用 pd.reset_option() 方法。具体来说,为了重置浮点数的显示格式,可以这样做:
pd.reset_option('display.float_format')
执行上述代码后,Pandas 将不再使用您之前设置的浮点数格式,并恢复为默认的显示设置。
- rounded 列:这列展示了在应用
df.round(5)后的数据。这是DataFrame中的实际数据,四舍五入到了5位小数。
从这个对比中,您可以看到这两个操作在这个特定的DataFrame上产生了相同的显示效果。但重要的是要记住,它们在操作和目的上是完全不同的。pd.set_option 只更改显示,而 df.round 更改实际数据。
105.将上一题的数据转换为百分数
df
| column1 | |
|---|---|
| 0 | 1.265021e-08 |
| 1 | 7.763215e-05 |
| 2 | 5.331380e-01 |
| 3 | 3.177901e-07 |
| 4 | 1.341835e-03 |
| 5 | 1.488887e-05 |
| 6 | 3.226127e-12 |
| 7 | 1.604492e-08 |
| 8 | 1.836409e-01 |
| 9 | 4.988592e-02 |
标准答案:df.style.format()方法 不会更改数据
df.style.format({'column1':'{0:.2%}'.format})
| column1 | |
|---|---|
| 0 | 0.00% |
| 1 | 0.01% |
| 2 | 53.31% |
| 3 | 0.00% |
| 4 | 0.13% |
| 5 | 0.00% |
| 6 | 0.00% |
| 7 | 0.00% |
| 8 | 18.36% |
| 9 | 4.99% |
这是一个很好的方式来格式化 pandas DataFrame 的显示样式,而不真正更改 DataFrame 中的数据。
代码解析:
- 使用
df.style.format()来更改 DataFrame 的显示样式。 - 通过传递一个字典
{ 'data': '{0:.2%}'.format }来指定列'data'的格式。 - 字符串
'{0:.2%}'是一个格式字符串,它会将数值转换为百分数并保留两位小数。.2%是一个特殊的格式,它会自动将数字乘以 100 并添加百分号,这意味着不需要额外的乘以 100 的操作。
.format是一个方法,它将被应用于列'data'中的每个值来格式化显示。
要注意的是,使用 df.style.format() 只会更改 DataFrame 的显示样式,而不会更改 DataFrame 中的实际数据。
提问:修改的样式如何恢复?
答:当您使用 df.style.format() 方法更改了 DataFrame 的显示样式,实际上您并没有修改 DataFrame 本身的数据,只是修改了其显示的样式。
要“取消”样式更改并返回到原始显示,您只需直接调用 DataFrame 的名称。例如,如果您的 DataFrame 名称是 df,只需再次输入 df 即可。
但如果您已经将样式化的 DataFrame 分配给了另一个变量,例如 styled_df = df.style.format(...), 则原始的 df 仍然保持不变。在这种情况下,直接调用 df 会显示原始的未格式化数据。
总之,只需再次引用原始 DataFrame 的名称即可返回到未格式化的显示。
df
| column1 | |
|---|---|
| 0 | 1.265021e-08 |
| 1 | 7.763215e-05 |
| 2 | 5.331380e-01 |
| 3 | 3.177901e-07 |
| 4 | 1.341835e-03 |
| 5 | 1.488887e-05 |
| 6 | 3.226127e-12 |
| 7 | 1.604492e-08 |
| 8 | 1.836409e-01 |
| 9 | 4.988592e-02 |
直接修改法:当数据类型为numpy.ndarray时 会更改数据本身
# 数据准备
numbers = np.random.random(10)**10
print(numbers)# 转换数据为百分数
percentages = numbers * 100# 将数字列表转化为百分数形式的字符串
formatted_percentages = ["{:.2f}%".format(p) for p in percentages]
formatted_percentages
[2.73666561e-10 1.57123441e-12 5.26265187e-02 9.85684929e-142.58206465e-07 1.14402849e-04 5.41450503e-01 7.71294410e-023.59544557e-02 7.83249726e-01]['0.00%','0.00%','5.26%','0.00%','0.00%','0.01%','54.15%','7.71%','3.60%','78.32%']
关键代码解析:[“{:.2f}%”.format§ for p in percentages]
当然可以,这段代码是一个列表推导式(list comprehension),用于格式化和转换数字列表为百分数字符串列表。下面是对这段代码的详细解析:
-
列表推导式:
[expression for item in iterable]是一个简洁的方法来创建列表。它遍历每一个item在iterable中,并使用expression计算得到新的值,最后将这些值组合成一个新的列表。 -
"{:.2f}%".format(p):这是一个字符串格式化表达式。"{:.2f}"是一个格式字符串,它告诉 Python 如何格式化一个浮点数。.表示小数点。2表示小数点后保留两位数字。f表示浮点数格式。
%是添加在字符串末尾的,将数字转换为百分比的形式。.format(p)是一个方法,用于将浮点数p插入到格式字符串中,产生一个格式化后的字符串。
-
for p in percentages:这是一个循环,它会遍历percentages列表中的每一个值,并将每个值赋给变量p。
所以,这个列表推导式的工作方式是:对于 percentages 列表中的每一个数字 p,它都会创建一个新的字符串,其中 p 被格式化为百分数形式,并保留两位小数。最后,这些格式化的字符串被组合成一个新的列表。
直接修改法2:当数据类型为dataframe时 会修改数据本身
如果这列数据是一个 pandas DataFrame 的列,您可以使用 pandas 的 .apply() 方法来格式化每个值。以下是步骤:
- 首先,确保您已导入 pandas 库。
- 使用
.apply()方法并传递一个 lambda 函数来格式化每个值。
假设您的 DataFrame 名称为 df 并且要格式化的列名为 'column_name',那么您可以按以下方式操作:
df['column_name'] = df['column_name'].apply(lambda x: "{:.2f}%".format(x*100))
# 使用刚才的 `percentages` 数据来创建一个简单的 DataFrame,并将其转换为百分数格式
df2 = pd.DataFrame({'Values':percentages})# 将Values列转换为百分数格式
df2['Values'] = df2['Values'].apply(lambda x:"{:.2f}%".format(x))df2
| Values | |
|---|---|
| 0 | 0.00% |
| 1 | 0.00% |
| 2 | 5.26% |
| 3 | 0.00% |
| 4 | 0.00% |
| 5 | 0.01% |
| 6 | 54.15% |
| 7 | 7.71% |
| 8 | 3.60% |
| 9 | 78.32% |
再拓展 : “{:.2f}%”.format§ 与’{0:.2%}'.format§
总结一下:
“{:.2f}%”.format§ 是手动添加百分号的方式,您需要确保值已经乘以 100。
‘{0:.2%}’.format§ 会自动乘以 100 并添加百分号。
# 示例:
a = 0.5
print('{:.2f}%'.format(a))
print('{0:.2%}'.format(a))
0.50%
50.00%
此外:在字符串格式化中,{} 中的数字(如 {0})表示参数的位置索引。当使用 .format() 方法传递多个参数时,这可以帮助您指定哪个参数应该放在哪个位置。例如:
"{} {}".format("Hello", "World") # 输出 "Hello World"
"{1} {0}".format("Hello", "World") # 输出 "World Hello"
但在大多数情况下,当您只有一个参数并且按顺序插入它们时,位置索引是可以省略的,因此以下两种写法是等效的:
"{:.2%}".format(value)"{0:.2%}".format(value)
106.查找上一题数据中第3大值的行号
方法一:
查找某列数据中第3大值的行号。
选择了列 ‘column1’ 中的前三个最大值,然后直接从返回的索引中选择最后一个,即第3大值的索引。
# type(df['column1'].nlargest(3)) pandas.core.series.Seriesdf['column1'].nlargest(3).index[-1]
9
方法二:
使用 df['column1'].argsort() 会返回一个整数索引的 Series,该 Series 描述了如何对 df['column1'] 进行排序以使其按升序排列。
例如,如果您有以下 DataFrame:
import pandas as pddata = {'column1': [50, 10, 40, 30, 20]
}
df = pd.DataFrame(data)
执行 df['column1'].argsort() 会返回:
1 1
4 4
3 3
2 2
0 0
Name: column1, dtype: int64
# 首先对列进行升序排序,得到索引从小到大的排序,然后使用 `iloc[-3]` 选择第3大的值,即为原始数第三大值的索引。
df['column1'].argsort().iloc[-3]
9
注意:
argsort() 默认是按升序排列,不直接提供选项来调整排序的方向。
如果想按降序排列,可以先取反(对于数字列),然后再使用 argsort()。例如:
desc_order_index = (-df['column1']).argsort()
这样,desc_order_index 就会表示按降序排列 df['column1'] 所需的索引顺序。
如果您想获取第3大的值的行号,可以使用:
third_largest_index = (-df['column1']).argsort().iloc[2]
这将首先对列进行降序排序,然后使用 iloc[2] 选择第3大的值的索引。
107.反转df的行
方法一:
# df.iloc[::-1].reset_index(drop=True) 此方法更接近实际使用,多了一个丢弃旧索引的步骤
df.iloc[::-1]
| column1 | |
|---|---|
| 9 | 4.988592e-02 |
| 8 | 1.836409e-01 |
| 7 | 1.604492e-08 |
| 6 | 3.226127e-12 |
| 5 | 1.488887e-05 |
| 4 | 1.341835e-03 |
| 3 | 3.177901e-07 |
| 2 | 5.331380e-01 |
| 1 | 7.763215e-05 |
| 0 | 1.265021e-08 |
df[::-1]
| column1 | |
|---|---|
| 9 | 4.988592e-02 |
| 8 | 1.836409e-01 |
| 7 | 1.604492e-08 |
| 6 | 3.226127e-12 |
| 5 | 1.488887e-05 |
| 4 | 1.341835e-03 |
| 3 | 3.177901e-07 |
| 2 | 5.331380e-01 |
| 1 | 7.763215e-05 |
| 0 | 1.265021e-08 |
方法二:本质是和方法一一样,但是有个容易忽略的点
df.iloc[::-1,:]
| column1 | |
|---|---|
| 9 | 4.988592e-02 |
| 8 | 1.836409e-01 |
| 7 | 1.604492e-08 |
| 6 | 3.226127e-12 |
| 5 | 1.488887e-05 |
| 4 | 1.341835e-03 |
| 3 | 3.177901e-07 |
| 2 | 5.331380e-01 |
| 1 | 7.763215e-05 |
| 0 | 1.265021e-08 |
注意:df.iloc[::-1,:]可以达到同样的效果,但是df[::-1,:]会报错。
df.iloc[::-1]或df.iloc[::-1, :]可以用来反转 DataFrame 的行,并保留所有列。iloc用于基于整数位置的索引。df[::-1]也可以用来反转行,但不允许使用额外的列索引(:),因此df[::-1, :]会引发语法错误。
在 Pandas 中,df[::-1] 是一个简单的语法糖,它背后实际上是在使用 iloc。iloc 允许更复杂的索引选项,包括同时选择行和列,因此 df.iloc[::-1, :] 是有效的。
以下是一些例子来说明这些点:
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})# 使用 df[::-1] 反转 DataFrame 的行
df_reversed_1 = df[::-1]# 使用 df.iloc[::-1, :] 反转 DataFrame 的行
df_reversed_2 = df.iloc[::-1, :]
在这两种情况下,行都被成功反转,但索引保持不变。如果需要,您可以使用 reset_index(drop=True) 来重置索引。
108.按照多列对数据进行合并
# 输入
df1 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})df2 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})
pd.merge(df1,df2,on = ['key1','key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
109.按照多列对数据进行合并
pd.merge(df1, df2, how='left', on=['key1', 'key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
注意区分上述两种数据处理方式的区别:
result = pd.merge(df1, df2, how='left', on=['key1', 'key2'])
这行代码会执行左连接(left join)合并操作。它将根据 key1 和 key2 列合并 df1 和 df2,并保留 df1(左侧 DataFrame)中的所有行。如果 df2(右侧 DataFrame)中存在匹配的行,则 df2 的值将被添加到结果中。如果 df2 中没有匹配的行,则结果中的相应单元格将被填充为 NaN。
具体效果如下:
df1和df2中的所有列都将出现在结果 DataFrame 中。df1中的所有行都将出现在结果 DataFrame 中。- 如果
df2中有与df1匹配的行(基于key1和key2),则df2中的C和D列的值将被添加到结果中。 - 如果
df2中没有与df1匹配的行,则结果 DataFrame 中的C和D列将被填充为NaN。
让我们来执行这个操作并查看结果。
合并的结果如下:
[
\begin{array}{cccccc}
\text{key1} & \text{key2} & \text{A} & \text{B} & \text{C} & \text{D} \
\hline
\text{K0} & \text{K0} & \text{A0} & \text{B0} & \text{C0} & \text{D0} \
\text{K0} & \text{K1} & \text{A1} & \text{B1} & \text{NaN} & \text{NaN} \
\text{K1} & \text{K0} & \text{A2} & \text{B2} & \text{C1} & \text{D1} \
\text{K1} & \text{K0} & \text{A2} & \text{B2} & \text{C2} & \text{D2} \
\text{K2} & \text{K1} & \text{A3} & \text{B3} & \text{NaN} & \text{NaN} \
\end{array}
]
如您所见:
- 第一行 (
key1=K0, key2=K0) 在df2中有匹配的行,所以C和D列的值是C0和D0。 - 第二行 (
key1=K0, key2=K1) 在df2中没有匹配的行,所以C和D列的值是NaN。 - 第三和第四行 (
key1=K1, key2=K0) 在df2中有两个匹配的行,所以结果中分别有C1, D1和C2, D2。 - 第五行 (
key1=K2, key2=K1) 在df2中没有匹配的行,所以C和D列的值是NaN。
110.再次读取数据1并显示所有的列
df = pd.read_csv('pandas120_101_120_1.csv', encoding='gbk')
pd.set_option("display.max.columns", None)
df
| positionId | positionName | companyId | companyLogo | companySize | industryField | financeStage | companyLabelList | firstType | secondType | thirdType | skillLables | positionLables | industryLables | createTime | formatCreateTime | district | businessZones | salary | workYear | jobNature | education | positionAdvantage | imState | lastLogin | publisherId | approve | subwayline | stationname | linestaion | latitude | longitude | hitags | resumeProcessRate | resumeProcessDay | score | newScore | matchScore | matchScoreExplain | query | explain | isSchoolJob | adWord | plus | pcShow | appShow | deliver | gradeDescription | promotionScoreExplain | isHotHire | count | aggregatePositionIds | famousCompany | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6802721 | 数据分析 | 475770 | i/image2/M01/B7/3E/CgoB5lwPfEaAdn8WAABWQ0Jgl5s... | 50-150人 | 移动互联网,电商 | A轮 | ['绩效奖金', '带薪年假', '定期体检', '弹性工作'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['SQL', '数据库', '数据运营', 'BI'] | ['电商', '社交', 'SQL', '数据库', '数据运营', 'BI'] | ['电商', '社交', 'SQL', '数据库', '数据运营', 'BI'] | 2020/3/16 11:00 | 11:00发布 | 余杭区 | ['仓前'] | 37500 | 1-3年 | 全职 | 本科 | 五险一金、弹性工作、带薪年假、年度体检 | today | 2020/3/16 11:00 | 12022406 | 1 | NaN | NaN | NaN | 30.278421 | 120.005922 | NaN | 50 | 1 | 233 | 0 | 15.101875 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 1 | 5204912 | 数据建模 | 50735 | image1/M00/00/85/CgYXBlTUXeeAR0IjAABbroUk-dw97... | 150-500人 | 电商 | B轮 | ['年终奖金', '做五休二', '六险一金', '子女福利'] | 开发|测试|运维类 | 数据开发 | 建模 | ['算法', '数据架构'] | ['算法', '数据架构'] | [] | 2020/3/16 11:08 | 11:08发布 | 滨江区 | ['西兴', '长河'] | 15000 | 3-5年 | 全职 | 本科 | 六险一金,定期体检,丰厚年终 | disabled | 2020/3/16 11:08 | 5491688 | 1 | NaN | NaN | NaN | 30.188041 | 120.201179 | NaN | 23 | 1 | 176 | 0 | 32.559414 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 2 | 6877668 | 数据分析 | 100125 | image2/M00/0C/57/CgqLKVYcOA2ADcFuAAAE8MukIKA74... | 2000人以上 | 移动互联网,企业服务 | 上市公司 | ['节日礼物', '年底双薪', '股票期权', '带薪年假'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['数据库', '数据分析', 'SQL'] | ['数据库', 'SQL'] | [] | 2020/3/16 10:33 | 10:33发布 | 江干区 | ['四季青', '钱江新城'] | 3500 | 1-3年 | 全职 | 本科 | 五险一金 周末双休 不加班 节日福利 | today | 2020/3/16 10:33 | 5322583 | 1 | 4号线 | 江锦路 | 4号线_城星路;4号线_市民中心;4号线_江锦路 | 30.241521 | 120.212539 | NaN | 11 | 4 | 80 | 0 | 14.972357 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 3 | 6496141 | 数据分析 | 26564 | i/image2/M01/F7/3F/CgoB5lyGAQGAZeI-AAAdOqXecnw... | 500-2000人 | 电商 | D轮及以上 | ['生日趴', '每月腐败基金', '每月补贴', '年度旅游'] | 开发|测试|运维类 | 数据开发 | 数据分析 | [] | ['电商'] | ['电商'] | 2020/3/16 10:10 | 10:10发布 | 江干区 | NaN | 45000 | 3-5年 | 全职 | 本科 | 年终奖等 | threeDays | 2020/3/16 10:10 | 9814560 | 1 | 1号线 | 文泽路 | 1号线_文泽路 | 30.299404 | 120.350304 | NaN | 100 | 1 | 68 | 0 | 12.874153 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | True |
| 4 | 6467417 | 数据分析 | 29211 | i/image2/M01/77/B8/CgoB5l1WDyGATNP5AAAlY3h88SY... | 2000人以上 | 物流丨运输 | 上市公司 | ['技能培训', '免费班车', '专项奖金', '岗位晋升'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['BI', '数据分析', '数据运营'] | ['BI', '数据运营'] | [] | 2020/3/16 09:56 | 09:56发布 | 余杭区 | ['仓前'] | 30000 | 3-5年 | 全职 | 大专 | 五险一金 | disabled | 2020/3/16 09:56 | 6392394 | 1 | NaN | NaN | NaN | 30.282952 | 120.009765 | NaN | 20 | 1 | 66 | 0 | 12.755375 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 100 | 6884346 | 数据分析师 | 21236 | i/image/M00/43/F6/CgqKkVeEh76AUVPoAAA2Bj747wU6... | 500-2000人 | 移动互联网,医疗丨健康 | C轮 | ['技能培训', '年底双薪', '节日礼物', '绩效奖金'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['数据库', '商业', '数据分析', 'SQL'] | ['医疗健康', '数据库', '商业', '数据分析', 'SQL'] | ['医疗健康', '数据库', '商业', '数据分析', 'SQL'] | 2020/3/11 16:45 | 2020/3/11 | 萧山区 | NaN | 25000 | 3-5年 | 全职 | 不限 | 大牛老板,开放环境,民生行业,龙头公司 | threeDays | 2020/3/16 09:49 | 1665167 | 1 | NaN | NaN | NaN | 30.203078 | 120.247069 | NaN | 96 | 1 | 0 | 0 | 0.314259 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 101 | 6849100 | 商业数据分析 | 72076 | i/image2/M01/92/A4/CgotOV2LPUmAR_8dAAB_DlDMiXA... | 500-2000人 | 移动互联网,电商 | C轮 | ['节日礼物', '股票期权', '带薪年假', '年度旅游'] | 市场|商务类 | 市场|营销 | 商业数据分析 | ['市场', '数据分析', '行业分析', '市场分析'] | ['电商', '市场', '数据分析', '行业分析', '市场分析'] | ['电商', '市场', '数据分析', '行业分析', '市场分析'] | 2020/3/14 17:38 | 2天前发布 | 余杭区 | NaN | 35000 | 1-3年 | 全职 | 硕士 | 五险一金、带薪休假 | threeDays | 2020/3/14 17:38 | 1732416 | 1 | NaN | NaN | NaN | 30.276694 | 119.990918 | NaN | 2 | 3 | 0 | 0 | 0.283276 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 102 | 6803432 | 奔驰·耀出行-BI数据分析专家 | 751158 | i/image3/M01/64/93/Cgq2xl48z2mAeYRoAAD6Qf_Jeq8... | 150-500人 | 移动互联网 | 不需要融资 | [] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['MySQL', '数据处理', '数据分析'] | ['MySQL', '数据处理', '数据分析'] | [] | 2020/3/14 22:39 | 2天前发布 | 滨江区 | ['西兴'] | 30000 | 3-5年 | 全职 | 本科 | 奔驰 吉利 世界500强 | threeDays | 2020/3/14 22:39 | 4785643 | 1 | 1号线 | 滨和路 | 1号线_滨和路;1号线_江陵路;1号线_滨和路;1号线_江陵路 | 30.208562 | 120.219225 | NaN | 63 | 1 | 0 | 0 | 0.256719 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 103 | 6704835 | BI数据分析师 | 52840 | i/image2/M00/26/CA/CgoB5lofsguAfk9ZAACoL3r4p24... | 2000人以上 | 电商 | 上市公司 | ['技能培训', '年底双薪', '节日礼物', '绩效奖金'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['SQLServer', '数据分析'] | ['电商', '新零售', 'SQLServer', '数据分析'] | ['电商', '新零售', 'SQLServer', '数据分析'] | 2020/3/9 15:00 | 2020/3/9 | 余杭区 | ['仓前'] | 20000 | 3-5年 | 全职 | 本科 | 阿里巴巴;商业智能; | threeDays | 2020/3/16 10:15 | 5846350 | 1 | NaN | NaN | NaN | 30.280177 | 120.023521 | ['16薪', '一年调薪2次'] | 0 | 0 | 0 | 0 | 0.281062 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | True |
| 104 | 6728058 | 数据分析专家-LQ(J181203029) | 2474 | i/image2/M01/14/4D/CgoB5lyq5fqAAHHzAAAa148hbk8... | 2000人以上 | 汽车丨出行 | 不需要融资 | ['弹性工作', '节日礼物', '岗位晋升', '技能培训'] | 产品|需求|项目类 | 数据分析 | 其他数据分析 | [] | ['滴滴'] | ['滴滴'] | 2020/3/13 18:24 | 3天前发布 | 西湖区 | NaN | 21500 | 5-10年 | 全职 | 本科 | 广阔平台诱人福利 | disabled | 2020/3/13 19:51 | 6799495 | 1 | NaN | NaN | NaN | 30.290746 | 120.074315 | NaN | 0 | 0 | 0 | 0 | 0.159343 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | True |
105 rows × 53 columns
拓展:pd.set_option(“display.max_columns”, None)
pd.set_option("display.max_columns", None) 是用来设置 Pandas 显示选项的,确保当您显示 DataFrame 时,所有的列都会被显示出来,而不是被截断。
"display.max_columns"是要设置的选项的名称。None是分配给该选项的值,意味着没有列的最大数量限制。
例如,在处理具有大量列的大型 DataFrame 时,Pandas 默认只显示一部分列。使用上面的设置,您可以确保所有列都会被显示出来。
如果您想要设置其他显示选项,例如行的最大数量,您可以使用 pd.set_option("display.max_rows", None)。
这是一个例子,演示如何使用这个设置:
import pandas as pd# 设置显示选项以显示所有列
pd.set_option("display.max_columns", None)# 创建一个具有多个列的 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9],'D': [10, 11, 12],'E': [13, 14, 15]
})# 显示 DataFrame
print(df)
在这个例子中,无论您的屏幕有多宽,DataFrame 的所有列都会被显示出来。
如果您想要恢复 Pandas 的显示设置到默认值,您可以使用 pd.reset_option() 函数。您只需提供您想要重置的选项的名称作为参数。
例如:
- 要重置最大列数的显示设置,您可以使用:
pd.reset_option("display.max_columns") - 要重置最大行数的显示设置,您可以使用:
pd.reset_option("display.max_rows")
如果您想要一次重置多个选项,只需将它们作为参数传递即可:
pd.reset_option("display.max_columns", "display.max_rows")
如果您想要重置所有的显示选项到默认设置,您可以使用:
pd.reset_option("all")
但是注意,使用 "all" 选项时,会出现一个额外的确认提示,因为这将重置所有的选项,不仅仅是显示相关的选项。
111.查找secondType与thirdType值相等的行号
方法一:布尔索引
mask = df[df['secondType']==df['thirdType']].index
mask
Int64Index([ 0, 2, 4, 5, 6, 10, 14, 23, 25, 27, 28, 29, 30,33, 37, 38, 39, 40, 41, 48, 49, 52, 53, 55, 57, 61,65, 66, 67, 71, 73, 74, 75, 79, 80, 82, 85, 88, 89,91, 96, 100],dtype='int64')
方法二:loc方法
注意:用于基于标签的索引。当使用布尔序列进行索引时,它返回所有对应于 True 的行。
例如:df.loc[df[‘secondType’] == df[‘thirdType’]] 返回所有 secondType 和 thirdType 列值相等的行。
mask = df.loc[df['secondType'] == df['thirdType']].index
mask
Int64Index([ 0, 2, 4, 5, 6, 10, 14, 23, 25, 27, 28, 29, 30,33, 37, 38, 39, 40, 41, 48, 49, 52, 53, 55, 57, 61,65, 66, 67, 71, 73, 74, 75, 79, 80, 82, 85, 88, 89,91, 96, 100],dtype='int64')
方法三:np.where()
np.where 函数用于返回输入数组(在这种情况下是一个布尔数组)中 True 值的索引。
当您使用它来比较 DataFrame 中的两列时,它将返回一个元组,其中包含满足条件的行索引。
本例中:使用 np.where 找到 secondType 和 thirdType 值相等的行号
equal_rows = np.where(df['secondType'] == df['thirdType'])
其中,equal_rows 将是一个元组,包含一个数组,数组中的值是满足条件的行号,可以通过 equal_rows[0] 来访问这个数组。
equal_rows_index = equal_rows[0] # 结果将是一个数组:array([0, 2])
equal_rows = np.where(df.secondType == df.thirdType)
equal_rows[0]
array([ 0, 2, 4, 5, 6, 10, 14, 23, 25, 27, 28, 29, 30,33, 37, 38, 39, 40, 41, 48, 49, 52, 53, 55, 57, 61,65, 66, 67, 71, 73, 74, 75, 79, 80, 82, 85, 88, 89,91, 96, 100], dtype=int64)
112.查找薪资大于平均薪资的第三个数据
方法一:找到薪资大于均值的数据,选择第三个
mean_value = df['salary'].mean()
temp_df = df.loc[df['salary']>mean_value]['salary'].reset_index()
temp_df.loc[2,'index']
5
# 实际使用应该是要具体的值吧,以下是获取第三个值的代码
mean_value = df['salary'].mean()
temp_df = df.loc[df['salary']>mean_value]['salary'].reset_index()
temp_df.loc[2,'salary']
50000
方法二:np.argwhere()
np.argwhere(): 这是 NumPy 的一个函数,用于找出传入数组中非零(True)元素的索引。在这里,它被用于找出 ‘salary’ 列中大于平均工资的所有索引。
报错示例:np.argwhere(df[‘salary’]>df[‘salary’].mean())[2]
运行报错:ValueError: Length of values (1) does not match length of index (105)
说明:
这个错误是由于尝试使用 np.argwhere 处理 pandas 的 Series 时产生的。np.argwhere 与 pandas Series 之间存在一些不兼容的问题,特别是在返回值的形状上。这就是为什么你看到 “Length of values (1) does not match length of index (105)” 这个错误消息的原因。
为了解决这个问题,你可以将 pandas Series 转换为 NumPy 数组,然后应用 np.argwhere。以下是如何做到这一点的方法:
indices = np.argwhere(df['salary'].values > df['salary'].mean()).flatten()
index_of_third_entry = indices[2]
在这里,我们使用 .values 将 Series 转换为 NumPy 数组。flatten() 用于将结果从二维数组转换为一维数组。
temp_df = np.argwhere(df['salary'].values>df['salary'].mean()).flatten()
temp_df[2]
5
temp_df = np.argwhere(df['salary'].values>df['salary'].mean()).flatten()
df.loc[temp_df[2],'salary']
50000
113.将上一题数据的salary列开根号
np.sqrt(df['salary'])
0 193.649167
1 122.474487
2 59.160798
3 212.132034
4 173.205081...
100 158.113883
101 187.082869
102 173.205081
103 141.421356
104 146.628783
Name: salary, Length: 105, dtype: float64
df['salary'].apply(np.sqrt)
0 193.649167
1 122.474487
2 59.160798
3 212.132034
4 173.205081...
100 158.113883
101 187.082869
102 173.205081
103 141.421356
104 146.628783
Name: salary, Length: 105, dtype: float64
114.将上一题数据的linestaion列按_拆分
# 确定数据类型
df[['linestaion']].info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 105 entries, 0 to 104
Data columns (total 1 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 linestaion 45 non-null object
dtypes: object(1)
memory usage: 968.0+ bytes
# 使用str.split拆分
temp_df = df['linestaion'].str.split('_')
temp_df
0 NaN
1 NaN
2 [4号线, 城星路;4号线, 市民中心;4号线, 江锦路]
3 [1号线, 文泽路]
4 NaN...
100 NaN
101 NaN
102 [1号线, 滨和路;1号线, 江陵路;1号线, 滨和路;1号线, 江陵路]
103 NaN
104 NaN
Name: linestaion, Length: 105, dtype: object
115.查看上一题数据中一共有多少列
df.shape[1]
53
116.提取industryField列以’数据’开头的行
df[df['industryField'].str.startswith('数据')]
| positionId | positionName | companyId | companyLogo | companySize | industryField | financeStage | companyLabelList | firstType | secondType | thirdType | skillLables | positionLables | industryLables | createTime | formatCreateTime | district | businessZones | salary | workYear | jobNature | education | positionAdvantage | imState | lastLogin | publisherId | approve | subwayline | stationname | linestaion | latitude | longitude | hitags | resumeProcessRate | resumeProcessDay | score | newScore | matchScore | matchScoreExplain | query | explain | isSchoolJob | adWord | plus | pcShow | appShow | deliver | gradeDescription | promotionScoreExplain | isHotHire | count | aggregatePositionIds | famousCompany | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | 6458372 | 数据分析专家 | 34132 | i/image2/M01/F8/DE/CgoB5lyHTJeAP7v9AAFXUt4zJo4... | 150-500人 | 数据服务,广告营销 | A轮 | ['开放式办公', '扁平管理', '带薪假期', '弹性工作时间'] | 产品|需求|项目类 | 数据分析 | 其他数据分析 | ['数据分析', '数据运营'] | ['电商', '广告营销', '数据分析', '数据运营'] | ['电商', '广告营销', '数据分析', '数据运营'] | 2020/3/16 10:57 | 10:57发布 | 余杭区 | NaN | 60000 | 5-10年 | 全职 | 本科 | 六险一金、境内外旅游、带薪年假、培训发展 | today | 2020/3/16 09:51 | 7542546 | 1 | NaN | NaN | NaN | 30.281850 | 120.015690 | NaN | 83 | 1 | 24 | 0 | 1.141952 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 10 | 6804629 | 数据分析师 | 34132 | i/image2/M01/F8/DE/CgoB5lyHTJeAP7v9AAFXUt4zJo4... | 150-500人 | 数据服务,广告营销 | A轮 | ['开放式办公', '扁平管理', '带薪假期', '弹性工作时间'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['数据分析'] | ['电商', '广告营销', '数据分析'] | ['电商', '广告营销', '数据分析'] | 2020/3/16 10:57 | 10:57发布 | 余杭区 | NaN | 30000 | 不限 | 全职 | 本科 | 六险一金 旅游 带薪年假 培训发展 双休 | today | 2020/3/16 09:51 | 7542546 | 1 | NaN | NaN | NaN | 30.281850 | 120.015690 | NaN | 83 | 1 | 17 | 0 | 1.161869 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 13 | 6804489 | 资深数据分析师 | 34132 | i/image2/M01/F8/DE/CgoB5lyHTJeAP7v9AAFXUt4zJo4... | 150-500人 | 数据服务,广告营销 | A轮 | ['开放式办公', '扁平管理', '带薪假期', '弹性工作时间'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['数据分析'] | ['电商', '数据分析'] | ['电商', '数据分析'] | 2020/3/16 10:57 | 10:57发布 | 余杭区 | NaN | 30000 | 3-5年 | 全职 | 本科 | 六险一金 旅游 带薪年假 培训发展 双休 | today | 2020/3/16 09:51 | 7542546 | 1 | NaN | NaN | NaN | 30.281850 | 120.015690 | NaN | 83 | 1 | 16 | 0 | 1.075559 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 21 | 6267370 | 数据分析专家 | 31544 | image1/M00/00/48/CgYXBlTUXOaADKooAABjQoD_n1w50... | 150-500人 | 数据服务 | 不需要融资 | ['专业红娘牵线', '节日礼物', '技能培训', '岗位晋升'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['数据挖掘', '数据分析'] | ['数据挖掘', '数据分析'] | [] | 2020/3/16 11:16 | 11:16发布 | 滨江区 | NaN | 20000 | 5-10年 | 全职 | 本科 | 五险一金 | today | 2020/3/16 11:16 | 466738 | 1 | 4号线 | 中医药大学 | 4号线_中医药大学;4号线_联庄 | 30.185480 | 120.139320 | NaN | 43 | 1 | 7 | 0 | 1.290228 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 32 | 6804489 | 资深数据分析师 | 34132 | i/image2/M01/F8/DE/CgoB5lyHTJeAP7v9AAFXUt4zJo4... | 150-500人 | 数据服务,广告营销 | A轮 | ['开放式办公', '扁平管理', '带薪假期', '弹性工作时间'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['数据分析'] | ['电商', '数据分析'] | ['电商', '数据分析'] | 2020/3/16 10:57 | 10:57发布 | 余杭区 | NaN | 37500 | 3-5年 | 全职 | 本科 | 六险一金 旅游 带薪年假 培训发展 双休 | today | 2020/3/16 09:51 | 7542546 | 1 | NaN | NaN | NaN | 30.281850 | 120.015690 | NaN | 83 | 1 | 16 | 0 | 1.075712 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 37 | 6242470 | 数据分析师 | 31544 | image1/M00/00/48/CgYXBlTUXOaADKooAABjQoD_n1w50... | 150-500人 | 数据服务 | 不需要融资 | ['专业红娘牵线', '节日礼物', '技能培训', '岗位晋升'] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['增长黑客', '数据分析', '商业'] | ['增长黑客', '数据分析', '商业'] | [] | 2020/3/16 11:16 | 11:16发布 | 滨江区 | NaN | 22500 | 1-3年 | 全职 | 本科 | 五险一金 | today | 2020/3/16 11:16 | 466738 | 1 | 4号线 | 中医药大学 | 4号线_中医药大学;4号线_联庄 | 30.185480 | 120.139320 | NaN | 43 | 1 | 5 | 0 | 1.060218 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 50 | 6680900 | 数据分析师 (MJ000250) | 114335 | i/image2/M00/17/C2/CgoB5ln5lUuAM8oSAADO2Rz54hQ... | 150-500人 | 数据服务 | B轮 | ['股票期权', '弹性工作', '领导好', '五险一金'] | 产品|需求|项目类 | 产品经理 | 数据分析师 | ['需求分析', '数据'] | ['企业服务', '大数据', '需求分析', '数据'] | ['企业服务', '大数据', '需求分析', '数据'] | 2020/3/16 10:49 | 10:49发布 | 西湖区 | NaN | 27500 | 3-5年 | 全职 | 不限 | 阿里系创业、云计算生态、餐补、双休 | today | 2020/3/16 10:49 | 3859261 | 1 | NaN | NaN | NaN | 30.289482 | 120.067080 | NaN | 1 | 1 | 5 | 0 | 0.947202 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 63 | 6680900 | 数据分析师 (MJ000250) | 114335 | i/image2/M00/17/C2/CgoB5ln5lUuAM8oSAADO2Rz54hQ... | 150-500人 | 数据服务 | B轮 | ['股票期权', '弹性工作', '领导好', '五险一金'] | 产品|需求|项目类 | 产品经理 | 数据分析师 | ['需求分析', '数据'] | ['企业服务', '大数据', '需求分析', '数据'] | ['企业服务', '大数据', '需求分析', '数据'] | 2020/3/16 10:49 | 10:49发布 | 西湖区 | NaN | 27500 | 3-5年 | 全职 | 不限 | 阿里系创业、云计算生态、餐补、双休 | today | 2020/3/16 10:49 | 3859261 | 1 | NaN | NaN | NaN | 30.289482 | 120.067080 | NaN | 1 | 1 | 4 | 0 | 0.856464 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 78 | 5683671 | 数据分析实习生 (MJ000087) | 114335 | i/image2/M00/17/C2/CgoB5ln5lUuAM8oSAADO2Rz54hQ... | 150-500人 | 数据服务 | B轮 | ['股票期权', '弹性工作', '领导好', '五险一金'] | 开发|测试|运维类 | 后端开发 | 数据采集 | ['数据挖掘', '机器学习'] | ['工具软件', '大数据', '数据挖掘', '机器学习'] | ['工具软件', '大数据', '数据挖掘', '机器学习'] | 2020/3/16 10:49 | 10:49发布 | 西湖区 | NaN | 26500 | 应届毕业生 | 实习 | 本科 | 阿里系创业、云计算生态、餐补、双休 | today | 2020/3/16 10:49 | 3859261 | 1 | NaN | NaN | NaN | 30.289482 | 120.067080 | NaN | 1 | 1 | 3 | 0 | 0.898513 | NaN | NaN | NaN | 1 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 79 | 6046866 | 数据分析师 | 543802 | i/image2/M01/63/3C/CgotOV0ulwOAU8KWAAAsMECc53M... | 15-50人 | 数据服务 | 不需要融资 | [] | 产品|需求|项目类 | 数据分析 | 数据分析 | ['可视化', '数据分析', '数据库'] | ['企业服务', '可视化', '数据分析', '数据库'] | ['企业服务', '可视化', '数据分析', '数据库'] | 2020/3/16 10:19 | 10:19发布 | 西湖区 | ['西溪', '文新'] | 37500 | 1-3年 | 全职 | 本科 | 发展潜力,结合业务,项目制 | overSevenDays | 2020/3/16 10:19 | 13308385 | 1 | 2号线 | 文新 | 2号线_文新;2号线_三坝 | 30.289000 | 120.088789 | NaN | 0 | 0 | 3 | 0 | 0.902939 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 92 | 6813626 | 资深数据分析专员 | 165939 | i/image3/M01/65/71/CgpOIF5CFp2ACoo9AAD3IkKwlv8... | 150-500人 | 数据服务 | 不需要融资 | ['年底双薪', '带薪年假', '午餐补助', '定期体检'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['数据分析'] | ['数据分析'] | [] | 2020/3/15 12:21 | 1天前发布 | 余杭区 | NaN | 30000 | 3-5年 | 全职 | 不限 | 阿里旗下、大数据 | today | 2020/3/15 13:13 | 8519805 | 1 | NaN | NaN | NaN | 30.281507 | 120.018621 | NaN | 1 | 1 | 1 | 0 | 0.440405 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 94 | 6818950 | 资深数据分析师 | 165939 | i/image3/M01/65/71/CgpOIF5CFp2ACoo9AAD3IkKwlv8... | 150-500人 | 数据服务 | 不需要融资 | ['年底双薪', '带薪年假', '午餐补助', '定期体检'] | 开发|测试|运维类 | 数据开发 | 数据分析 | ['数据分析'] | ['数据分析'] | [] | 2020/3/15 12:21 | 1天前发布 | 余杭区 | NaN | 30000 | 5-10年 | 全职 | 不限 | 阿里旗下、大数据 | today | 2020/3/15 13:13 | 8519805 | 1 | NaN | NaN | NaN | 30.281507 | 120.018621 | NaN | 1 | 1 | 1 | 0 | 0.407209 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 97 | 6718750 | 旅游大数据分析师(杭州) | 122019 | i/image/M00/1A/4A/CgqKkVb583WABT4BAABM5RuPCmk9... | 50-150人 | 数据服务,企业服务 | A轮 | ['年底双薪', '股票期权', '午餐补助', '定期体检'] | 开发|测试|运维类 | 数据开发 | 数据治理 | ['数据分析', '数据处理'] | ['旅游', '大数据', '数据分析', '数据处理'] | ['旅游', '大数据', '数据分析', '数据处理'] | 2020/3/12 16:38 | 2020/3/12 | 上城区 | ['湖滨', '吴山'] | 30000 | 1-3年 | 全职 | 本科 | 管理扁平 潜力项目 五险一金 周末双休 | sevenDays | 2020/3/13 08:48 | 11347630 | 1 | 2号线 | 中河北路 | 1号线_定安路;1号线_龙翔桥;1号线_凤起路;1号线_定安路;1号线_龙翔桥;1号线_凤起... | 30.254169 | 120.164651 | NaN | 3 | 0 | 1 | 0 | 0.826756 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 98 | 6655562 | 数据分析建模工程师 | 117422215 | i/image2/M01/AF/6D/CgotOV3ki4iAOuo3AABbilI8DfA... | 50-150人 | 数据服务,信息安全 | A轮 | ['午餐补助', '带薪年假', '16到18薪', '法定节假日'] | 开发|测试|运维类 | 人工智能 | 机器学习 | ['机器学习', '建模', '数据挖掘', '算法'] | ['机器学习', '建模', '数据挖掘', '算法'] | [] | 2020/3/14 19:00 | 2天前发布 | 西湖区 | NaN | 30000 | 1-3年 | 全职 | 本科 | 海量数据 全链路建模实践 16-18薪 | threeDays | 2020/3/16 09:30 | 8810336 | 1 | 2号线 | 丰潭路 | 2号线_古翠路;2号线_丰潭路 | 30.291494 | 120.113955 | NaN | 0 | 0 | 0 | 0 | 0.356308 | NaN | NaN | NaN | 0 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
| 99 | 6677939 | 数据分析建模工程师(校招) | 117422215 | i/image2/M01/AF/6D/CgotOV3ki4iAOuo3AABbilI8DfA... | 50-150人 | 数据服务,信息安全 | A轮 | ['午餐补助', '带薪年假', '16到18薪', '法定节假日'] | 开发|测试|运维类 | 人工智能 | 算法工程师 | ['机器学习', '建模', '算法', '数据挖掘'] | ['机器学习', '建模', '算法', '数据挖掘'] | [] | 2020/3/14 19:00 | 2天前发布 | 西湖区 | NaN | 36500 | 应届毕业生 | 全职 | 本科 | 海量数据 全链路建模实践 16-18薪 | threeDays | 2020/3/16 09:30 | 8810336 | 1 | 2号线 | 丰潭路 | 2号线_古翠路;2号线_丰潭路 | 30.291494 | 120.113955 | NaN | 0 | 0 | 0 | 0 | 0.338603 | NaN | NaN | NaN | 1 | 0 | NaN | 0 | 0 | 0 | NaN | NaN | 0 | 0 | [] | False |
117.按列制作数据透视表
pd.pivot_table 来制作数据透视表
pd.pivot_table(df, values=["salary", "score"], index="positionId")
这里的意思是:
- 使用
df(一个 pandas DataFrame)作为数据源。 - 将
positionId列作为索引(行标签)。 - 对
salary和score两列的值进行聚合。默认情况下,pd.pivot_table使用mean作为聚合函数,这意味着它将为每个唯一的positionId计算salary和score的平均值。
结果将是一个新的 DataFrame,其中行标签是 positionId 的唯一值,列标签是 salary 和 score,每个单元格的值是对应 positionId 的 salary 和 score 的平均值。
如果你有其他特定的聚合函数或其他参数需要,你可以进一步定制 pd.pivot_table。例如,你可以通过添加 aggfunc 参数来指定其他聚合函数。
pd.pivot_table(df,values = ['salary','score'],index = 'positionId')
| salary | score | |
|---|---|---|
| positionId | ||
| 5203054 | 30000 | 4.0 |
| 5204912 | 15000 | 176.0 |
| 5269002 | 37500 | 1.0 |
| 5453691 | 30000 | 4.0 |
| 5519962 | 37500 | 14.0 |
| ... | ... | ... |
| 6882983 | 27500 | 15.0 |
| 6884346 | 25000 | 0.0 |
| 6886661 | 37500 | 5.0 |
| 6888169 | 42500 | 1.0 |
| 6896403 | 30000 | 3.0 |
95 rows × 2 columns
118.同时对salary、score两列进行计算
注意:内置的聚合函数需要使用字符串指定,numpy的聚合函数直接指定即可
-
内置的聚合函数:当使用pandas内置的聚合函数(如’sum’、‘mean’、'max’等)时,您应该使用它们的字符串表示。例如:
df[['salary', 'score']].agg(['sum', 'mean', 'max']) -
NumPy的聚合函数:当您想使用NumPy的聚合函数时,您应该直接传递函数,而不是它们的字符串表示。例如:
df[['salary', 'score']].agg([np.sum, np.mean, np.max])
# 内置的聚合函数需要使用字符串指定
df[['salary','score']].agg(['sum','mean','max'])
| salary | score | |
|---|---|---|
| sum | 3.331000e+06 | 1335.000000 |
| mean | 3.172381e+04 | 12.714286 |
| max | 6.000000e+04 | 233.000000 |
# numpy的聚合函数直接指定即可
df[['salary','score']].agg([np.sum,np.mean,np.max])
| salary | score | |
|---|---|---|
| sum | 3.331000e+06 | 1335.000000 |
| mean | 3.172381e+04 | 12.714286 |
| amax | 6.000000e+04 | 233.000000 |
119.对salary求平均,对score列求和
df[['salary','score']].agg([np.mean,np.sum])
| salary | score | |
|---|---|---|
| mean | 3.172381e+04 | 12.714286 |
| sum | 3.331000e+06 | 1335.000000 |
df[['salary','score']].agg(['mean','sum'])
| salary | score | |
|---|---|---|
| mean | 3.172381e+04 | 12.714286 |
| sum | 3.331000e+06 | 1335.000000 |
120.计算并提取平均薪资最高的区
df[['district','salary']].groupby(by = ['district']).mean().sort_values(by = 'district',ascending = False).head(1)
| salary | |
|---|---|
| district | |
| 西湖区 | 30893.939394 |
相关文章:
)
Pandas进阶修炼120题-第五期(一些补充,101-120题)
目录 往期内容:第一期:Pandas基础(1-20题)第二期:Pandas数据处理(21-50题)第三期:Pandas金融数据处理(51-80题)第四期:当Pandas遇上NumPy…...
NPDP产品经理知识(产品创新管理)
复习文化,团队与领导力 产品创新管理: 如何树立愿景: 如何实现产品战略 计划 实施产品开发: 商业化,营销计划,推广活动 管理产品生命周期: 新式走向市场的流程:...
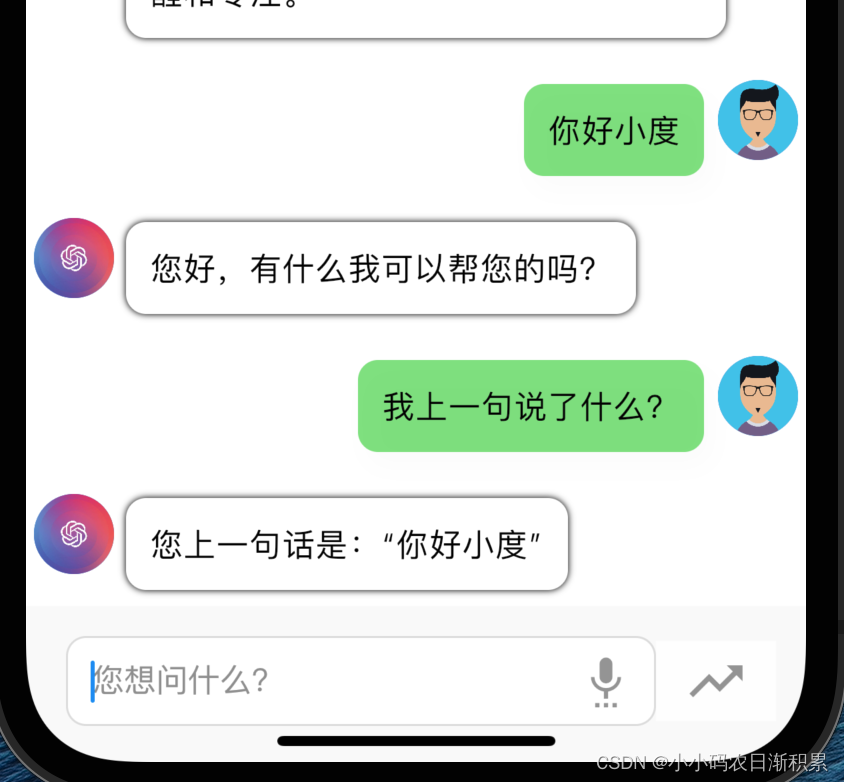
Flutter+SpringBoot实现ChatGPT流实输出
FlutterSpringBoot实现ChatGPT流式输出、上下文了连续对话 最终实现Flutter的流式输出上下文连续对话。 这里就是提供一个简单版的工具类和使用案例,此处页面仅参考。 服务端 这里直接封装提供工具类,修改自己的apiKey即可使用,支持连续…...
淘宝天猫粉丝福利购店铺优惠券去哪里找到领取网站?
淘宝天猫优惠券去哪里找到领取网站? 领取淘宝天猫粉丝福利购优惠券可通过百度搜索:草柴,进入草柴官方网站 或 手机应用商店搜索:草柴,下载安装草柴APP,就可以领取淘宝天猫优惠券; 草柴APP如何领…...

【考研复习】union有关的输出问题
文章目录 遇到的问题正确解答拓展参考文章 遇到的问题 首次遇到下面的代码时,感觉应该输出65,323。深入理解union的存储之后发现正确答案是:67,323. union {char c;int i; } u; int main(){u.c A;u.i 0x143;printf("%d,%d\n", u.c, u.i); …...
 Android 数据库Litepal)
Android学习之路(16) Android 数据库Litepal
一.LitePal的介绍 Litepal是Android郭霖大神的一个开源Android数据库的开源框架,它采用了对象关系映射(ORM)的模式,这是让我们非常好的理解的数据库,一个实体类对应我们数据库中的一个表。该库中还封装了许多的方法&a…...

Redis持久化(RDB/AOF)
"在哪里走散,你都会 找 到 我。" 认识持久化 我们在接触Mysql事务的时候,一定了解过Mysql事务的四个特性: "原子性(A)一致性(C)隔离性(I)持久性(D)" 而其中持久性其实与持久化是一回事,所谓持久与不持久&#x…...
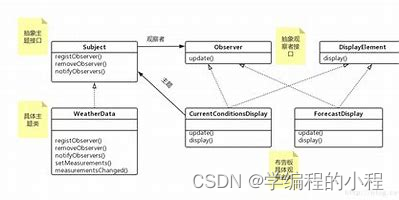
小谈设计模式(15)—观察者模式
小谈设计模式(15)—观察者模式 专栏介绍专栏地址专栏介绍 观察者模式核心思想主要角色Subject(被观察者)ConcreteSubject(具体被观察者)Observer(观察者)ConcreteObserver࿰…...
)
简单工厂模式 创建型模式(非GoF经典设计模式)
简单工厂模式是属于创建型模式,也因为工厂中的方法一般设置为静态,又叫做静态工厂方法(Static Factory Method)模式,但不属于23种GOF设计模式之一。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工…...
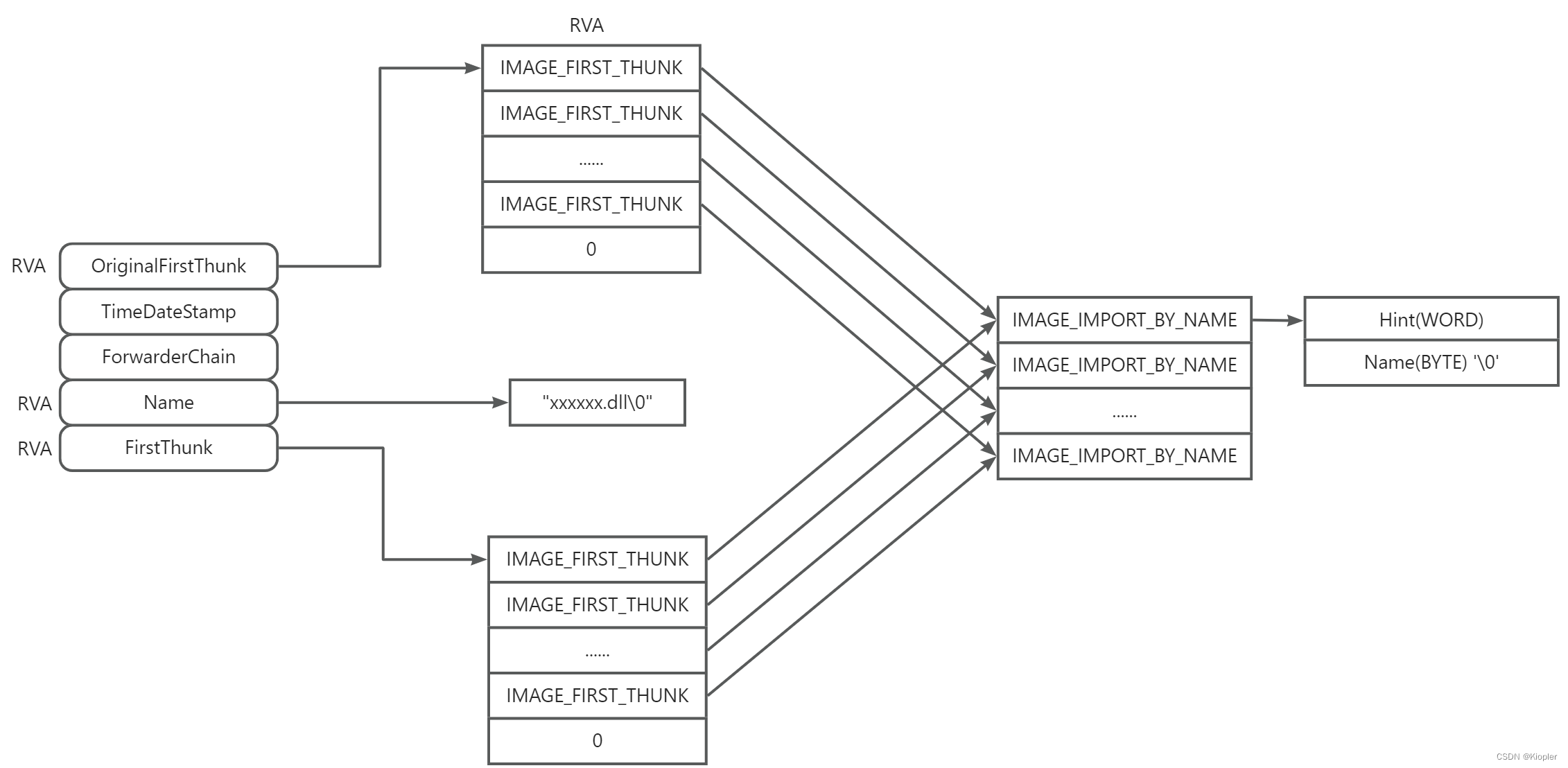
PE文件之导入表
1. 导入表 2. 显示导入表信息的例子 ; 作用: 将RVA地址转成FOA即文件偏移 ; 参数: _pFileHdr 指向读到内存中文件的基址指针 ; _dwRVA 目标RVA地址 ; 返回: 目标RVA转成文件偏移的值 RVA2FOA PROC USES esi edi edx, _pFileHdr:PTR BYTE, _dwRVA:DWORDmov esi, _pFil…...

二、码制及其转换
原码 根据我们所学可知,数字电路的逻辑电路是通过输出0和1来表示二进制数的,那么这个二进制数的正负又该怎么表示呢? 答案是在这个二进制数的最高位作为符号位来表示正负性,用0正数,用1表示负数,在这种表达…...
在pycharm中出现下载软件包失败的解决方法
一. 一般情况下我们会选择在设置中下载软件包,过程如下. 1. 直接点击左上角的文件, 再点击设置, 再点击项目, 在右边选择python解释器,点击号,输入要下载的软件包, 在下面的一系列的包中选择相对应的包,点击安装就可以了,有的时候我们下载的是最新的版本,如果要下载固定的版本…...
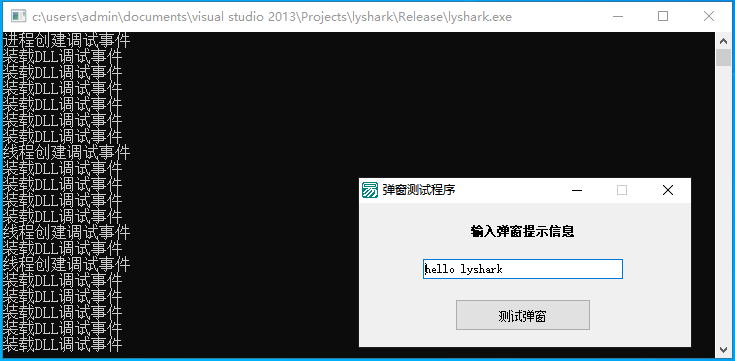
10.0 探索API调试事件原理
本章笔者将通过Windows平台下自带的调试API接口实现对特定进程的动态转存功能,首先简单介绍一下关于调试事件的相关信息,调试事件的建立需要依赖于DEBUG_EVENT这个特有的数据结构,该结构用于向调试器报告调试事件。当一个程序发生异常事件或者…...
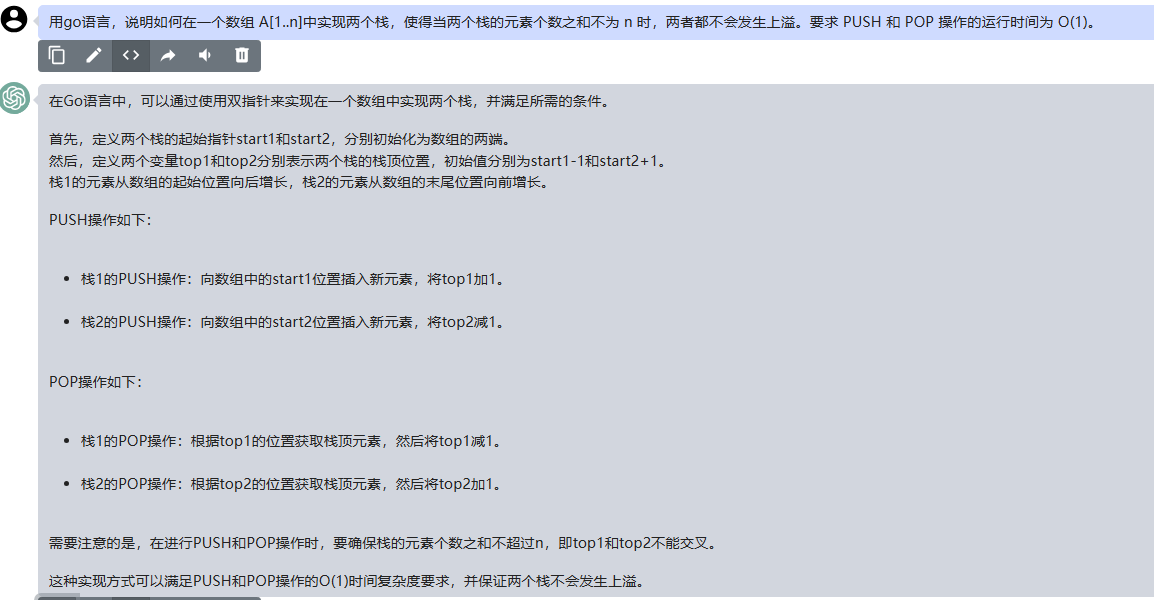
文心一言 VS 讯飞星火 VS chatgpt (104)-- 算法导论10.1 2题
二、用go语言,说明如何在一个数组 A[1…n]中实现两个栈,使得当两个栈的元素个数之和不为 n 时,两者都不会发生上溢。要求 PUSH 和 POP 操作的运行时间为 O(1)。 文心一言: 在这个问题中,我们要在一个数组 A[1…n] 中…...
检测防火墙是否开启、判断程序是否加入防火墙白名单(附源码)
VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)https://blog.csdn.net/chenlycly/article/details/124272585C软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...&a…...
vtk 动画入门 1 代码
实现效果如图: #include <vtkAutoInit.h> //VTK_MODULE_INIT(vtkRenderingOpenGL2); //VTK_MODULE_INIT(vtkInteractionStyle); VTK_MODULE_INIT(vtkRenderingOpenGL2); VTK_MODULE_INIT(vtkInteractionStyle); //VTK_MODULE_INIT(vtkRenderingFreeType); #in…...
【VR】【unity】如何在VR中实现远程投屏功能?
【背景】 目前主流的VD应用,用于娱乐很棒,但是用于工作还是无法效率地操作键鼠。用虚拟键盘工作则显然是不现实的。为了让自己的头显能够起到小面积代替多显示屏的作用,自己动手开发投屏VR应用。 【思路】 先实现C#的投屏应用。研究如何将C#投屏应用用Unity 3D项目转写。…...

OpenGl材质
在现实世界里,每个物体会对光产生不同的反应。比如,钢制物体看起来通常会比陶土花瓶更闪闪发光,一个木头箱子也不会与一个钢制箱子反射同样程度的光。有些物体反射光的时候不会有太多的散射(Scatter),因而产生较小的高光点,而有些物体则会散射很多,产生一个有着更大半径的…...

背包问题
目录 开端 01背包问题 AcWing 01背包问题 Luogu P2925干草出售 Luogu P1048采药 完全背包问题 AcWing 完全背包问题 Luogu P1853投资的最大效益 多重背包问题 AcWing 多重背包问题 I AcWing 多重背包问题 II Luogu P1776宝物筛选 混合背包问题 AcWing 混合背包问题…...
 | 抽象类和抽象接口)
JavaSE | 初始Java(十一) | 抽象类和抽象接口
抽象类概念 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的, 如果 一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类 在 Java 中,一个…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...