计算机视觉——飞桨深度学习实战-深度学习网络模型
深度学习网络模型的整体架构主要数据集、模型组网以及学习优化过程三部分,本章主要围绕着深度学习网络模型的算法架构、常见模型展开了详细介绍,从经典的深度学习网络模型以CNN、RNN为代表,到为了解决显存不足、实时性不够等问题的轻量化网络设计,以及近年来卷各大计算机视觉任务的前沿网络模型Transformer和MLP。为了进一步剖析深度学习网络模型搭建的过程,最后以LeNet模型算法为例,在飞桨深度学习框架下进行了网络搭建案例展示。学完本章,希望读者能够掌握以下知识点:
- 了解经典的网络模型(CNN和RNN);
- 熟悉前沿的网络模型(Transformer和MLP);
- 掌握使用飞桨搭建深度学习网络模型-LeNet。
在前面的学习中,我们应该大概已经了解了国内外计算机视觉的近况和历史,还有深度学习算法基础,对于深度学习的框架应该也有了一个大概的了解,上面说的这些东西自己下去了解一下就好啦,也不会太难。这篇文章主要是针对深度学习的网络模型进行阐述。在了解经典网络模型的同时,也能了解前沿的网络模型,并且会将通过一个简单的例子让大家对于深度学习网络有一个大概的印象。
在深度学习开发框架的支持下,深度学习网络模型不断更新迭代,模型架构从经典的卷积神经网络CNN,循环神经网络RNN。发展到如今的Transformer,多层感知机MLP,而他们可以统一视为通过网络部件激活函数设定,优化策略等一系列操作来搭建深度学习网络模型,并且采用非线性复杂映射将原始数据转变为更高层次等抽象的表达。
深度学习网络模型的整体架构主要包含三部分,分别为数据集,模型组网以及学习优化过程。深度学习网络模型的训练过程即为优化过程,模型优化最直接的目的是通过多次迭代更新来寻找使得损失函数尽可能小的最优模型参数。通常神经网络的优化过程可以分为两个阶段,第一阶段是通过正向传播得到模型的预测值,并将预测值与正值标签进行比对,计算两者之间的差异作为损失值;第二个阶段是通过反向传播来计算损失函数对每个参数的梯度,根据预设的学习率和动量来更新每个参数的值。
总之,一个好的网络模型通常具有以下特点,一,模型易于训练及训练步骤简单且容易收敛,二,模型精度高及能够很好的把握数据的内在本质,可以提取到有用的关键特征,三,模型泛化能力强及模型不仅在已知数据上表现良好,还而且还能够在于已知数据分布一致的未知数据集上表现其鲁棒性。
案例:
一、任务介绍
手写数字识别(handwritten numeral recognition)是光学字符识别技术(optical character recognition,OCR)的一个分支,是初级研究者的入门基础,在现实产业中也占据着十分重要的地位,它主要的研究内容是如何利用电子计算机和图像分类技术自动识别人手写在纸张上的阿拉伯数字(0~9)。因此,本实验任务简易描述如图所示:

二、模型原理
近年来,神经网络模型一直层出不穷,在各个计算机视觉任务中都呈现百花齐放的态势。为了让开发者更清楚地了解网络模型的搭建过程,以及为了在后续的各项视觉子任务实战中奠定基础。下面本节将以MNIST手写数字识别为例,在PaddlePaddle深度学习开发平台下构建一个LeNet网络模型并进行详细说明。LeNet是第一个将卷积神经网络推上计算机视觉舞台的算法模型,它由LeCun在1998年提出。在早期应用于手写数字图像识别任务。该模型采用顺序结构,主要包括7层(2个卷积层、2个池化层和3个全连接层),卷积层和池化层交替排列。以mnist手写数字分类为例构建一个LeNet-5模型。每个手写数字图片样本的宽与高均为28像素,样本标签值是0~9,代表0至9十个数字。
下面详细解析LeNet-5模型的网络结构及原理

图1 LeNet-5整体网络模型
(1)卷积层L1
L1层的输入数据形状大小为��×1×28×28Rm×1×28×28,表示样本批量为m,通道数量为1,行与列的大小都为28。L1层的输出数据形状大小为��×6×24×24Rm×6×24×24,表示样本批量为m,通道数量为6,行与列维都为24。
这里有两个问题很关键:一是,为什么通道数从1变成了6呢?原因是模型的卷积层L1设定了6个卷积核,每个卷积核都与输入数据发生运算,最终分别得到6组数据。二是,为什么行列大小从28变成了24呢?原因是每个卷积核的行维与列维都为5,卷积核(5×5)在输入数据(28×28)上移动,且每次移动步长为1,那么输出数据的行列大小分别为28-5+1=24。
(2)池化层L2
L2层的输入数据形状大小为��×6×24×24Rm×6×24×24,表示样本批量为m,通道数量为6,行与列的大小都为24。L2层的输出数据形状大小为��×6×12×12Rm×6×12×12,表示样本批量为m,通道数量为6,行与列维都为12。
在这里,为什么行列大小从24变成了12呢?原因是池化层中的过滤器形状大小为2×2,其在输入数据(24×24)上移动,且每次移动步长(跨距)为2,每次选择4个数(2×2)中最大值作为输出,那么输出数据的行列大小分别为24÷2=12。
(3)卷积层L3
L3层的输入数据形状大小为��×6×12×12Rm×6×12×12,表示样本批量为m,通道数量为6,行与列的大小都为12。L3层的输出数据形状大小为��×16×8×8Rm×16×8×8,表示样本批量为m,通道数量为16,行与列维都为8。
(4)池化层L4
L4层的输入数据形状大小为��×16×8×8Rm×16×8×8,表示样本批量为m,通道数量为16,行与列的大小都为8。L4层的输出数据形状大小为��×16×4×4Rm×16×4×4,表示样本批量为m,通道数量为16,行与列维都为4。池化层L4中的过滤器形状大小为2×2,其在输入数据(形状大小24×24)上移动,且每次移动步长(跨距)为2,每次选择4个数(形状大小2×2)中最大值作为输出。
(5)线性层L5
L5层输入数据形状大小为��×256Rm×256,表示样本批量为m,输入特征数量为256。输出数据形状大小为��×120Rm×120,表示样本批量为m,输出特征数量为120。
(6)线性层L6
L6层的输入数据形状大小为��×120Rm×120,表示样本批量为m,输入特征数量为120。L6层的输出数据形状大小为��×84Rm×84,表示样本批量为m,输出特征数量为84。
(7)线性层L7
L7层的输入数据形状大小为��×84Rm×84,表示样本批量为m,输入特征数量为84。L7层的输出数据形状大小为��×10Rm×10,表示样本批量为m,输出特征数量为10。
三、MNIST数据集
3.1 数据集介绍
手写数字分类数据集来源MNIST数据集,该数据集可以公开免费获取。该数据集中的训练集样本数量为60000个,测试集样本数量为10000个。每个样本均是由28×28像素组成的矩阵,每个像素点的值是标量,取值范围在0至255之间,可以认为该数据集的颜色通道数为1。数据分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字。
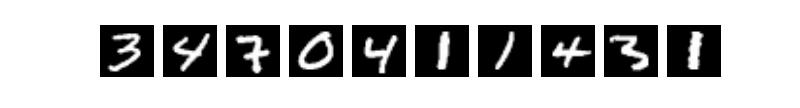
3.2 数据读取
(1)transform函数是对数据进行归一化和标准化
(2)train_dataset和test_dataset
paddle.vision.datasets.MNIST()中的mode='train'和mode='test'分别用于获取mnist训练集和测试集
#导入数据集Compose的作用是将用于数据集预处理的接口以列表的方式进行组合。
#导入数据集Normalize的作用是图像归一化处理,支持两种方式: 1. 用统一的均值和标准差值对图像的每个通道进行归一化处理; 2. 对每个通道指定不同的均值和标准差值进行归一化处理。
import paddle
from paddle.vision.transforms import Compose, Normalize
import os
import matplotlib.pyplot as plt
transform = Compose([Normalize(mean=[127.5],std=[127.5],data_format='CHW')])
# 使用transform对数据集做归一化
print('下载并加载训练数据')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('加载完成')让我们一起看看数据集中的图片是什么样子的
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
print(plt.imshow(train_data0, cmap=plt.cm.binary))
print('train_data0 的标签为: ' + str(train_label_0))AxesImage(18,18;111.6x108.72) train_data0 的标签为: [5]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingif isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingreturn list(data) if isinstance(data, collections.MappingView) else data /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/lib/type_check.py:546: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead'a.item() instead', DeprecationWarning, stacklevel=1)

<Figure size 144x144 with 1 Axes>
让我们再来看看数据样子是什么样的吧
print(train_data0)四、LeNet模型搭建
构建LeNet-5模型进行MNIST手写数字分类
#导入需要的包
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import Compose, Normalize#定义模型
class LeNetModel(paddle.nn.Layer):def __init__(self):super(LeNetModel, self).__init__()# 创建卷积和池化层块,每个卷积层后面接着2x2的池化层#卷积层L1self.conv1 = paddle.nn.Conv2D(in_channels=1,out_channels=6,kernel_size=5,stride=1)#池化层L2self.pool1 = paddle.nn.MaxPool2D(kernel_size=2,stride=2)#卷积层L3self.conv2 = paddle.nn.Conv2D(in_channels=6,out_channels=16,kernel_size=5,stride=1)#池化层L4self.pool2 = paddle.nn.MaxPool2D(kernel_size=2,stride=2)#线性层L5self.fc1=paddle.nn.Linear(256,120)#线性层L6self.fc2=paddle.nn.Linear(120,84)#线性层L7self.fc3=paddle.nn.Linear(84,10)#正向传播过程def forward(self, x):x = self.conv1(x)x = F.sigmoid(x)x = self.pool1(x)x = self.conv2(x)x = F.sigmoid(x)x = self.pool2(x)x = paddle.flatten(x, start_axis=1,stop_axis=-1)x = self.fc1(x)x = F.sigmoid(x)x = self.fc2(x)x = F.sigmoid(x)out = self.fc3(x)return outmodel=paddle.Model(LeNetModel())五、模型优化过程
5.1 损失函数
由于是分类问题,我们选择交叉熵损失函数。交叉熵主要用于衡量估计值与真实值之间的差距。交叉熵值越小,模型预测效果越好。*
�(��,�^�)=−∑�=1������(�^��)E(yi,y^i)=−∑j=1qyjiln(y^ji)
其中,��∈��yi∈Rq为真实值,���yji是��yi中的元素(取值为0或1),�=1,...,�j=1,...,q。�^�∈��y^i∈Rq是预测值(样本在每个类别上的概率)。其中,在paddle里面交叉熵损失对应的API是paddle.nn.CrossEntropyLoss()
5.2 参数优化
定义好了正向传播过程之后,接着随机化初始参数,然后便可以计算出每层的结果,每次将得到m×10的矩阵作为预测结果,其中m是小批量样本数。接下来进行反向传播过程,预测结果与真实结果之间肯定存在差异,以缩减该差异作为目标,计算模型参数梯度。进行多轮迭代,便可以优化模型,使得预测结果与真实结果之间更加接近。
六、模型训练与评估
训练配置:设定训练超参数
1、批大小batch_size设置为64,表示每次输入64张图片;
2、迭代次数epoch设置为5,表示训练5轮;
3、日志显示verbose=1,表示带进度条的输出日志信息。
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),paddle.nn.CrossEntropyLoss(),paddle.metric.Accuracy())model.fit(train_dataset,epochs=5,batch_size=64,verbose=1)model.evaluate(val_dataset,verbose=1)The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/5 step 10/938 [..............................] - loss: 2.3076 - acc: 0.1062 - ETA: 21s - 23ms/step
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop workingreturn (isinstance(seq, collections.Sequence) and
step 20/938 [..............................] - loss: 2.3023 - acc: 0.1023 - ETA: 18s - 20ms/step
step 938/938 [==============================] - loss: 0.1927 - acc: 0.7765 - 16ms/step Epoch 2/5 step 938/938 [==============================] - loss: 0.0913 - acc: 0.9584 - 17ms/step Epoch 3/5 step 938/938 [==============================] - loss: 0.0232 - acc: 0.9700 - 17ms/step Epoch 4/5 step 938/938 [==============================] - loss: 0.0057 - acc: 0.9763 - 18ms/step Epoch 5/5 step 938/938 [==============================] - loss: 0.0907 - acc: 0.9798 - 17ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 10000/10000 [==============================] - loss: 7.5607e-04 - acc: 0.9794 - 2ms/step Eval samples: 10000
{'loss': [0.00075607264], 'acc': 0.9794}
经过5个epoch世代迭代,LeNet5模型在MNIST图像分类任务上的准确度达到98%左右。
七、模型可视化
model.summary((1,1,28,28))---------------------------------------------------------------------------Layer (type) Input Shape Output Shape Param # ===========================================================================Conv2D-1 [[1, 1, 28, 28]] [1, 6, 24, 24] 156 MaxPool2D-1 [[1, 6, 24, 24]] [1, 6, 12, 12] 0 Conv2D-2 [[1, 6, 12, 12]] [1, 16, 8, 8] 2,416 MaxPool2D-2 [[1, 16, 8, 8]] [1, 16, 4, 4] 0 Linear-1 [[1, 256]] [1, 120] 30,840 Linear-2 [[1, 120]] [1, 84] 10,164 Linear-3 [[1, 84]] [1, 10] 850 =========================================================================== Total params: 44,426 Trainable params: 44,426 Non-trainable params: 0 --------------------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.04 Params size (MB): 0.17 Estimated Total Size (MB): 0.22 ---------------------------------------------------------------------------
{'total_params': 44426, 'trainable_params': 44426}
相关文章:
计算机视觉——飞桨深度学习实战-深度学习网络模型
深度学习网络模型的整体架构主要数据集、模型组网以及学习优化过程三部分,本章主要围绕着深度学习网络模型的算法架构、常见模型展开了详细介绍,从经典的深度学习网络模型以CNN、RNN为代表,到为了解决显存不足、实时性不够等问题的轻量化网络…...
实现手撸神经网咯230901)
用c动态数组(不用c++vector)实现手撸神经网咯230901
用c语言动态数组(不用c++的vector)实现:输入数据inputs = { {1, 1}, {0,0},{1, 0},{0,1} };目标数据targets={0,0,1,1}; 测试数据 inputs22 = { {1, 0}, {1,1},{0,1} }; 构建神经网络,例如:NeuralNetwork nn({ 2, 4,3,1 }); 则网络有四层、输入层2个nodes、输出层1个节点、第…...

视频讲解|基于DistFlow潮流的配电网故障重构代码
目录 1 主要内容 2 视频链接 1 主要内容 该视频为基于DistFlow潮流的配电网故障重构代码讲解内容,对应的资源下载链接为基于DistFlow潮流的配电网故障重构(输入任意线路),对该程序进行了详尽的讲解,基本做到句句分析和讲解(讲解…...
Ultralytics(YoloV8)开发环境配置,训练,模型转换,部署全流程测试记录
关键词:windows docker tensorRT Ultralytics YoloV8 配置开发环境的方法: 1.Windows的虚拟机上配置: Python3.10 使用Ultralytics 可以得到pt onnx,但无法转为engine,找不到GPU,手动转也不行࿰…...

springboot之@ImportResource:导入Spring配置文件~
ImportResource的作用是允许在Spring配置文件中导入其他的配置文件。通过使用ImportResource注解,可以将其他配置文件中定义的Bean定义导入到当前的配置文件中,从而实现配置文件的模块化和复用。这样可以方便地将不同的配置文件进行组合,提高…...
阿里云服务器免费申请入口_注册阿里云免费领4台服务器
注册阿里云账号,免费领云服务器,最高领取4台云服务器,每月750小时,3个月免费试用时长,可快速搭建网站/小程序,部署开发环境,开发多种企业应用。阿里云百科分享阿里云服务器免费领取入口、免费云…...

ES6中的async、await函数
async是为了解决异步操作,其实是一个语法糖,使代码书写更加简洁。 1. async介绍 async放在一个函数的前面,await则放在异步操作前面。async代表这个函数中有异步操作需要等待结果,在一个async函数中可以存在多个await࿰…...
代码随想录算法训练营第五十六天 | 动态规划 part 14 | 1143.最长公共子序列、1035.不相交的线、53. 最大子序和(dp)
目录 1143.最长公共子序列思路代码 1035.不相交的线思路代码 53. 最大子序和(dp)思路代码 1143.最长公共子序列 Leetcode 思路 本题和718. 最长重复子数组 区别在于这里不要求是连续的了,但要有相对顺序,即:“ace” …...

【数据挖掘】2021年 Quiz 1-3 整理 带答案
目录 Quiz 1Quiz 2Quiz 3Quiz 1 Problem 1 (30%). Consider the training data shown below. Here, A A A and B B B</...

【软件设计师-中级——刷题记录6(纯干货)】
目录 管道——过滤器软件体系结构风格优点:计算机英语重点词汇:单元测试主要检查模块的以下5个特征:数据库之并发控制中的事务:并发产生的问题解决方案:封锁协议原型化开发方法: 每日一言:持续更新中... 个…...

微信小程序点单左右联动的效果实现
微信小程序点单左右联动的效果实现 原理解析: 点击左边标签会跳到右边相应位置:点击改变rightCur值,转跳相应位置滑动右边,左边标签会跳到相应的位置:监听并且设置每个右边元素的top和bottom,再判断当…...
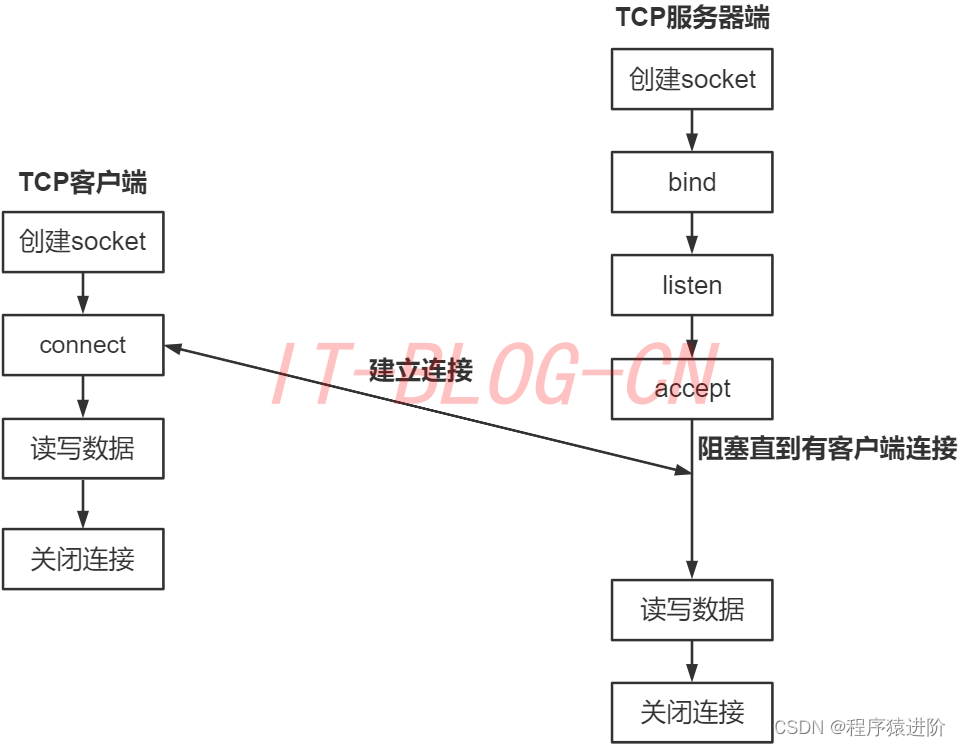
Socket通信
优质博文IT-BLOG-CN 一、简介 Socket套接字:描述了计算机的IP地址和端口,运行在计算机中的程序之间采用socket进行数据通信。通信的两端都有socket,它是一个通道,数据在两个socket之间进行传输。socket把复杂的TCP/IP协议族隐藏在…...

TCP 如何保证有效传输及拥塞控制
TCP(传输控制协议)可以通过以下机制保证有效传输和拥塞控制: 确认机制:TCP使用确认机制来保证数据的有效传输。发送方在发送数据的同时还会发送一个确认请求,接收方收到数据后会回复确认响应。如果发送方没有收到确认响…...
PyQt5+Qt设计师初探
在上一篇文章中我们搭建好了PyQt5的开发环境,打铁到趁热我们基于搭建好的环境来简单实战一把 一:PyQt5包模块简介 PyQt5包括的主要模块如下。 QtCore模块——涵盖了包的核心的非GUI功能,此模块被用于处理程序中涉及的时间、文件、目录、数…...

rust cargo
一、cargo是什么 Cargo是Rust的构建工具和包管理器。 Cargo除了创建工程、构建工程、运行工程等功能,还具有下载依赖库、编译依赖等功能。 真正编写程序时,我们不直接用rustc,而是用cargo。 二、使用cargo (一)使用…...
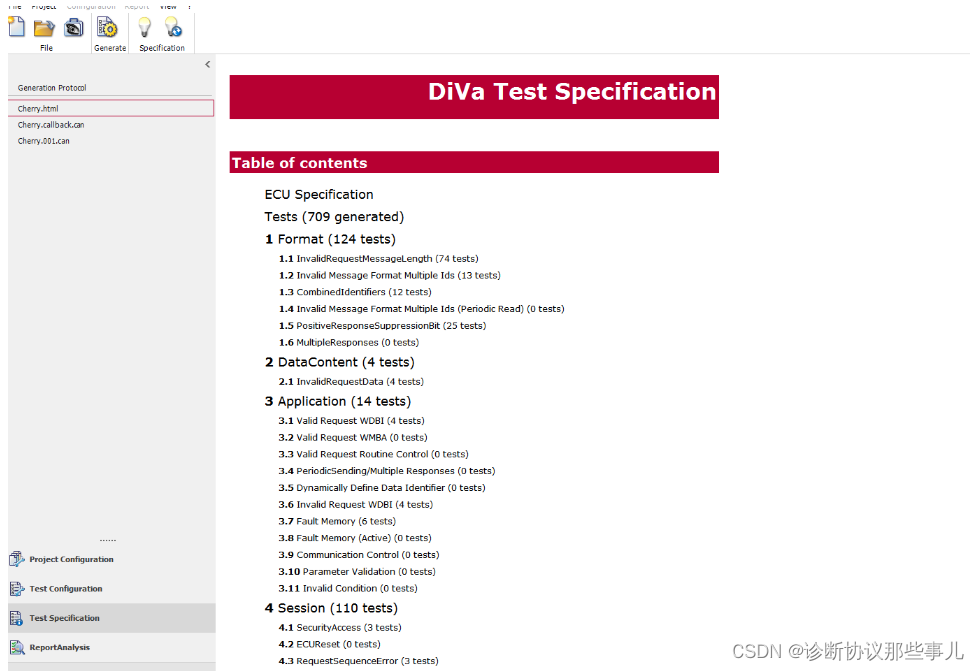
CANoe.Diva生成测试用例
Diva目录 一、CANoe.Diva打开CDD文件二、导入CDD文件三、ECU Information四、时间参数设置五、选择是否测试功能寻址六、勾选需要测试服务项七、生成测试用例 一、CANoe.Diva打开CDD文件 CANoe.Diva可以通过导入cdd或odx文件,自动生成全面的测试用例。再在CANoe中导…...

openGauss学习笔记-89 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用查询原生编译
文章目录 openGauss学习笔记-89 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用查询原生编译89.1 查询编译:PREPARE语句89.2 运行命令89.3 轻量执行支持的查询89.4 轻量执行不支持的查询89.5 JIT存储过程89.6 MOT JIT诊断89.6.1 mot_jit_detai…...
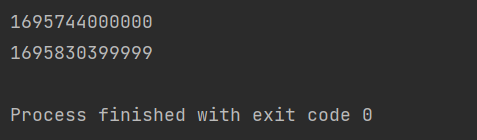
python获取时间戳
使用 datetime 库获取时间。 获取当前时间: import datetime print(datetime.datetime.now()) . 后面的是微秒,也是一个时间单位,1秒1000000微秒。 转为时间戳: import datetimedate datetime.datetime.now() timestamp date…...
2023年山东省安全员C证证考试题库及山东省安全员C证试题解析
题库来源:安全生产模拟考试一点通公众号小程序 2023年山东省安全员C证证考试题库及山东省安全员C证试题解析是安全生产模拟考试一点通结合(安监局)特种作业人员操作证考试大纲和(质检局)特种设备作业人员上岗证考试大…...

Java中的Unicode字符编码与占用比特位解析
本文将详细介绍Java中Unicode字符编码与占用比特位的相关知识。我们将首先介绍Unicode字符集的基本概念,然后深入探讨Java中Unicode字符的编码方式以及占用比特位的特点。最后,我们将讨论一些特殊字符的编码情况,并给出一些在Java中处理Unico…...

AudioSeal效果展示:实测音频隐形水印,听不出区别但能精准检测
AudioSeal效果展示:实测音频隐形水印,听不出区别但能精准检测 1. 音频水印技术概述 1.1 什么是音频隐形水印 音频隐形水印是一种将数字标识信息嵌入到音频信号中的技术,这些信息对人类听觉系统几乎不可感知,但可以通过专用算法…...

【信号处理】基于预设性能的无模型自适应分数阶快速终端滑模控制在MIMO非线性系统中的研究附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

从VGG到ResNet:为什么说‘残差块’是深度学习模型‘卷’层数的救命稻草?
从VGG到ResNet:残差连接如何重塑深度神经网络的设计哲学 2014年ImageNet竞赛上,VGGNet凭借其规整的3x3卷积堆叠结构一举夺魁,将图像识别准确率提升到新高度。正当整个计算机视觉领域沉浸在"更深就一定更好"的乐观情绪中时ÿ…...

FlowState Lab少样本学习效果:仅用10条数据生成特定波动模式
FlowState Lab少样本学习效果:仅用10条数据生成特定波动模式 1. 引言:当数据稀缺遇上智能生成 想象一下这样的场景:你手里只有10条设备振动波形数据,却需要分析上千种可能的故障模式。传统方法可能需要收集数月甚至数年的运行数…...

老旧设备的开源OCR解决方案:技术适配与性能优化指南
老旧设备的开源OCR解决方案:技术适配与性能优化指南 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/GitHub…...

ofa_image-caption生产环境部署:支持批量图片处理与结果导出的企业方案
ofa_image-caption生产环境部署:支持批量图片处理与结果导出的企业方案 1. 项目背景与核心价值 在实际的企业应用中,图像内容理解已经成为许多业务场景的必备能力。无论是电商平台的商品图片描述生成,还是内容平台的海量图片标注࿰…...

c++ 字符大小写转化
#include <iostream> using namespace std;int main() {char a;cin >> a;//a-z-97-122//A-Z-65-90//差32//小写转大写 if(97<(int)a && (int)a<122){a(int)a-32;cout << a; return 0; }//大写转小写 if(65<(int)a && (int)a<90)…...

Spring Boot 中 Quartz 与 PostgreSQL 持久化实战:构建可视化定时任务管理平台
1. 为什么需要定时任务持久化 在企业级应用开发中,定时任务就像是一个不知疲倦的闹钟,每天准时叫醒你的业务逻辑。但传统的Scheduled注解方式有个致命缺陷——所有的任务配置都硬编码在代码里。想象一下,每次修改任务执行时间都需要重新部署应…...

植物大战僵尸修改工具实战指南:从入门到精通
植物大战僵尸修改工具实战指南:从入门到精通 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 认知阶段:工具核心价值与基础架构 工具定位与适用场景 植物大战僵尸修改工具是…...

紧固件包装机有哪些类型?自动化包装设备全解析_FES 2026上海紧固件展
2026第十六届上海紧固件专业展(Fastener Expo Shanghai 2026)将于6月24日至26日在国家会展中心(上海)举行。作为紧固件行业的重要展示窗口,本届展会将重点呈现制造端与后道环节的智能化升级,其中࿰…...