AlexNet网络复现
1. 引言
在现代计算机视觉领域,深度学习已经成为了一个核心技术,其影响力远超过了传统的图像处理方法。但深度学习,特别是卷积神经网络(CNN)在计算机视觉的主导地位并不是从一开始就有的。在2012年之前,计算机视觉的许多任务都是由一系列手工设计的特征和浅层的机器学习模型完成的。
2012年,一个特殊的网络结构名为AlexNet在ImageNet Large Scale Visual Recognition Challenge(ILSVRC)上取得了出色的成果,这一结果震惊了整个计算机视觉和机器学习社区。AlexNet不仅在分类精度上大幅领先,更重要的是,它开启了一个全新的时代——深度学习的时代。
2. AlexNet背景与重要性
在深度学习成为主流之前,计算机视觉任务主要依赖于手工设计的特征,如SIFT、HOG等,与浅层机器学习模型相结合,如SVM。这些方法虽然在某些任务上有所成功,但总体上受限于其手工设计的特征提取和有限的模型容量。
为了推进计算机视觉的发展,ImageNet项目应运而生,这是一个包含数百万张标注图像的大型数据库。基于此,ImageNet Large Scale Visual Recognition Challenge(ILSVRC)被创建出来,旨在激励研究人员开发更好的图像分类方法。ILSVRC迅速成为了计算机视觉领域的标杆比赛。
2012年,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton合作设计的AlexNet在ILSVRC中大放异彩,它的错误率比第二名低了10%以上,这在当时是一个令人震惊的进步。它使用的深度卷积神经网络架构和其他创新技术,标志着深度学习在计算机视觉领域的崛起。
深度结构: 与之前的模型相比,AlexNet具有更深的网络结构,这使得它能够学习到更复杂的特征表示。
GPU计算: AlexNet的训练利用了GPU并行计算的优势,从而大大加速了深度网络的训练速度。
创新性技术: 如ReLU激活函数、Dropout等技术,都首次在这样的大规模图像任务中显示了其效果和价值。
启发后续研究: AlexNet的成功激励了更多的研究人员转向深度学习,导致了后续的VGG、GoogLeNet、ResNet等一系列网络的诞生。
3. 网络结构详解
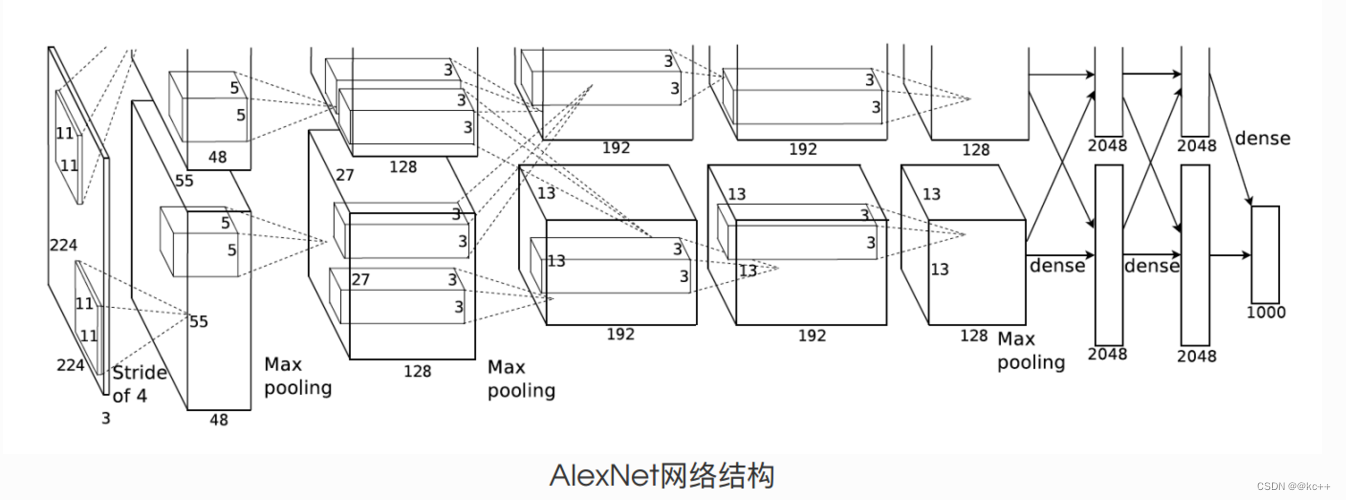
3.1. 卷积层
卷积层是CNN中的核心部分,它通过卷积操作提取输入图像的特征。AlexNet包含多个卷积层,这些卷积层的过滤器数量和大小各异,以捕捉不同级别的特征。
滤波器 :AlexNet使用了大小为11x11、5x5和3x3的滤波器。
步长与填充:初始的卷积层使用了较大的步长(如步长为4的11x11滤波器),这有助于减少网络的计算复杂性。
3.2. 激活函数: ReLU
ReLU(Rectified Linear Unit)在AlexNet中首次在大规模网络中获得了广泛应用,因为它帮助网络更快地收敛并减轻了梯度消失的问题。
特性:ReLU的定义为f(x) = max(0, x),它是非线性的,但计算简单。
优势:相较于Sigmoid或Tanh激活函数,ReLU可以加速SGD的收敛速度。
3.3. 池化
池化层在CNN中用于降低特征的空间维度,从而减少计算量。同时,它还能增加特征的平移不变性。
类型:AlexNet主要使用最大池化。
池化窗口与步长:在AlexNet中,池化窗口为3x3,步长为2。
3.4 全连接层
AlexNet包含3个全连接层,它们用于将前面的特征图汇集到一起,为分类做最后的决策。
神经元数量:前两个全连接层包含4096个神经元,而最后一个全连接层(输出层)根据类别数量决定(在ImageNet挑战中为1000个类别)。
3.5 正则化:Dropout
Dropout是一种正则化技巧,它在训练期间随机“丢弃”神经元,从而防止网络过拟合。
位置:AlexNet在前两个全连接层之后应用了Dropout。
丢弃率:训练期间,每个神经元被丢弃的概率为0.5。
4. 主要特点与创新
4.1 深度结构
相较于其它前期的网络模型,AlexNet有着更深的层次结构,包括五个卷积层,接着是三个全连接层。这种深度结构允许网络学习更丰富和复杂的特征表示。
4.2 ReLU激活函数
之前的神经网络主要采用sigmoid或tanh作为激活函数。AlexNet采用ReLU作为其激活函数,这一简单的变动大大加速了网络的训练,并提高了模型的表现。
4.3 GPU并行计算
由于其深度结构,AlexNet的计算需求远超过当时的CPU能力。为了解决这个问题,设计者利用了两个GPU进行并行计算。这不仅大大加速了训练速度,而且开启了后续深度学习模型利用GPU进行训练的趋势。
4.4 局部响应归一化 (LRN)
虽然后续的研究表明LRN可能不是必要的,但在AlexNet中,作者介绍了局部响应归一化作为一种规范化技术,它在某种程度上模拟了生物神经元的侧抑制机制,有助于增强模型的泛化能力。
4.5 Dropout
为了防止这样一个大型网络过拟合,AlexNet引入了Dropout技术。通过随机关闭一部分神经元,Dropout可以在训练过程中有效地模拟集成学习,从而增强模型的泛化性。
4.6 大数据和数据增强
AlexNet在ImageNet上训练,该数据集包含超过1500万的高分辨率图像和1000个类别。此外,为了进一步扩充数据并提高模型的鲁棒性,设计者还采用了多种数据增强技术,如图像旋转、裁剪和翻转。
4.7 叠加的卷积层
与之前的网络设计不同,AlexNet在没有池化的情况下叠加了多个卷积层,这允许模型捕捉更为复杂的特征组合。
5. 实践:搭建AlexNet
5.1 model
import torch.nn as nn
import torchclass AlexNet(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(AlexNet, self).__init__()# 特征提取层self.features = nn.Sequential(# 第一卷积层nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),# 第二卷积层nn.Conv2d(48, 128, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),# 第三、四、五卷积层nn.Conv2d(128, 192, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(192, 192, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(192, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)# 分类层self.classifier = nn.Sequential(# Dropout层可以减少过拟合nn.Dropout(p=0.5),# 全连接层nn.Linear(128 * 6 * 6, 2048),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(2048, 2048),nn.ReLU(inplace=True),nn.Linear(2048, num_classes),)if init_weights:self._initialize_weights()def forward(self, x):# 通过特征提取层x = self.features(x)# 展平特征图x = torch.flatten(x, start_dim=1)# 通过分类层x = self.classifier(x)return xdef _initialize_weights(self):# 初始化权重for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)5.2 train
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet# 配置参数
BATCH_SIZE = 32
EPOCHS = 10
LR = 0.0002
SAVE_PATH = './AlexNet.pth'def load_data(data_root):"""加载数据集"""data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}train_dataset = datasets.ImageFolder(root=os.path.join(data_root, "train"), transform=data_transform["train"])validate_dataset = datasets.ImageFolder(root=os.path.join(data_root, "val"), transform=data_transform["val"])nw = min([os.cpu_count(), BATCH_SIZE if BATCH_SIZE > 1 else 0, 8])train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=nw)validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=4, shuffle=False, num_workers=nw)return train_loader, validate_loaderdef save_class_indices(dataset, save_path='class_indices.json'):"""保存类别和对应的编码到json文件中"""flower_list = dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())with open(save_path, 'w') as f:json.dump(cla_dict, f, indent=4)def train_one_epoch(net, data_loader, optimizer, loss_function, device):"""训练一个epoch"""net.train()running_loss = 0.0for images, labels in tqdm(data_loader, file=sys.stdout):optimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()running_loss += loss.item()return running_loss / len(data_loader)def validate(net, data_loader, device):"""验证模型"""net.eval()acc = 0.0with torch.no_grad():for images, labels in tqdm(data_loader, file=sys.stdout):outputs = net(images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, labels.to(device)).sum().item()return acc / len(data_loader.dataset)def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(f"Using {device} device.")data_root = os.path.abspath(os.path.join(os.getcwd(), "./.."))image_path = os.path.join(data_root, "data_set", "flower_data")assert os.path.exists(image_path), f"{image_path} path does not exist."train_loader, validate_loader = load_data(image_path)save_class_indices(train_loader.dataset)print(f"Using {len(train_loader.dataset)} images for training, {len(validate_loader.dataset)} images for validation.")net = AlexNet(num_classes=5, init_weights=True).to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=LR)best_acc = 0.0for epoch in range(EPOCHS):train_loss = train_one_epoch(net, train_loader, optimizer, loss_function, device)val_acc = validate(net, validate_loader, device)if val_acc > best_acc:best_acc = val_acctorch.save(net.state_dict(), SAVE_PATH)print(f"Epoch {epoch + 1}/{EPOCHS} - Train loss: {train_loss:.4f} - Val Accuracy: {val_acc:.4f}")print('Finished Training')if __name__ == '__main__':main()5.3 predict
import os
import json
import argparseimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import AlexNet# 定义命令行参数解析函数
def parse_args():parser = argparse.ArgumentParser(description="预测输入图片的分类")parser.add_argument("img_path", help="待预测图片的路径")parser.add_argument("--model_path", default="./AlexNet.pth", help="已训练的AlexNet模型的路径")parser.add_argument("--class_indices", default="./class_indices.json", help="类别索引的json文件路径")return parser.parse_args()# 加载和预处理图片
def load_image(img_path, transform):img = Image.open(img_path)img = transform(img)return torch.unsqueeze(img, dim=0)# 加载模型
def load_model(model_path, device, num_classes=5):model = AlexNet(num_classes=num_classes).to(device)model.load_state_dict(torch.load(model_path))return model# 使用模型进行预测
def predict_image(img, model, class_indict, device):model.eval()with torch.no_grad():output = torch.squeeze(model(img.to(device))).cpu()probabilities = torch.softmax(output, dim=0)predicted_class = torch.argmax(probabilities).numpy()return predicted_class, probabilitiesdef main():args = parse_args() # 解析命令行参数device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定义图片预处理操作transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])img = load_image(args.img_path, transform) # 加载图片# 从json文件中读取类别索引with open(args.class_indices, "r") as f:class_indict = json.load(f)model = load_model(args.model_path, device) # 加载模型# 使用模型预测图片predicted_class, probabilities = predict_image(img, model, class_indict, device)print("预测类别: {} 概率: {:.3}".format(class_indict[str(predicted_class)],probabilities[predicted_class].numpy()))# 打印所有类别的预测概率for i in range(len(probabilities)):print("类别: {:10} 概率: {:.3}".format(class_indict[str(i)],probabilities[i].numpy()))plt.imshow(Image.open(args.img_path)) # 显示图片plt.title("预测结果: {}".format(class_indict[str(predicted_class)]))plt.show()if __name__ == '__main__':main()相关文章:
AlexNet网络复现
1. 引言 在现代计算机视觉领域,深度学习已经成为了一个核心技术,其影响力远超过了传统的图像处理方法。但深度学习,特别是卷积神经网络(CNN)在计算机视觉的主导地位并不是从一开始就有的。在2012年之前,计…...

pytorch模型量化和移植安卓详细教程
十一下雨,在家撸模型,希望对pytorch模型进行轻量化,间断摸索了几天,效果不错,做个总结分享出来。 量化是一种常见的技术,人们使用它来使模型在推断时运行更快,具有更低的内存占用和更低的功耗,而无需更改模型架构。在这篇博客文章中,我们将简要介绍量化是什么以及如何…...
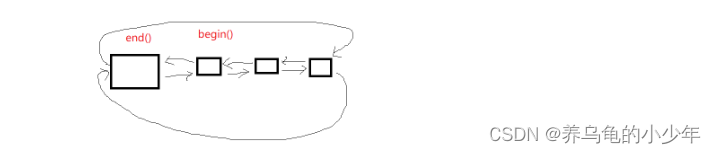
C++(List)
本节目标: 1.list介绍及使用 2.list深度剖析及模拟实现 3.list和vector对比 1.list介绍及使用 1.1list介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,…...

分布式架构篇
1、微服务 微服务架构风格,就像是把一个单独的应用程序开发为一套小服务,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是 HTTP API。这些服务围绕业务能力来构建,并通过完全自动化部署机制来独立部署。这些…...
)
ros编译报错-- Could NOT find ros_ethercat_eml (missing: ros_ethercat_eml_DIR)
– Could NOT find ros_ethercat_eml (missing: ros_ethercat_eml_DIR) – Could not find the required component ‘ros_ethercat_eml’. The following CMake error indicates that you either need to install the package with the same name or change your environment …...
VD6283TX环境光传感器驱动开发(3)----测试闪烁频率代码
VD6283TX环境光传感器驱动开发----3.测试闪烁频率代码 概述视频教学样品申请源码下载参考代码开发板设置测试结果 概述 ST提供了6283A1_AnalogFlicker代码在X-NUCLEO-6283A1获取闪烁频率,同时移植到VD6283TX-SATEL。 闪烁频率提取主要用于检测光源的闪烁频率&#…...
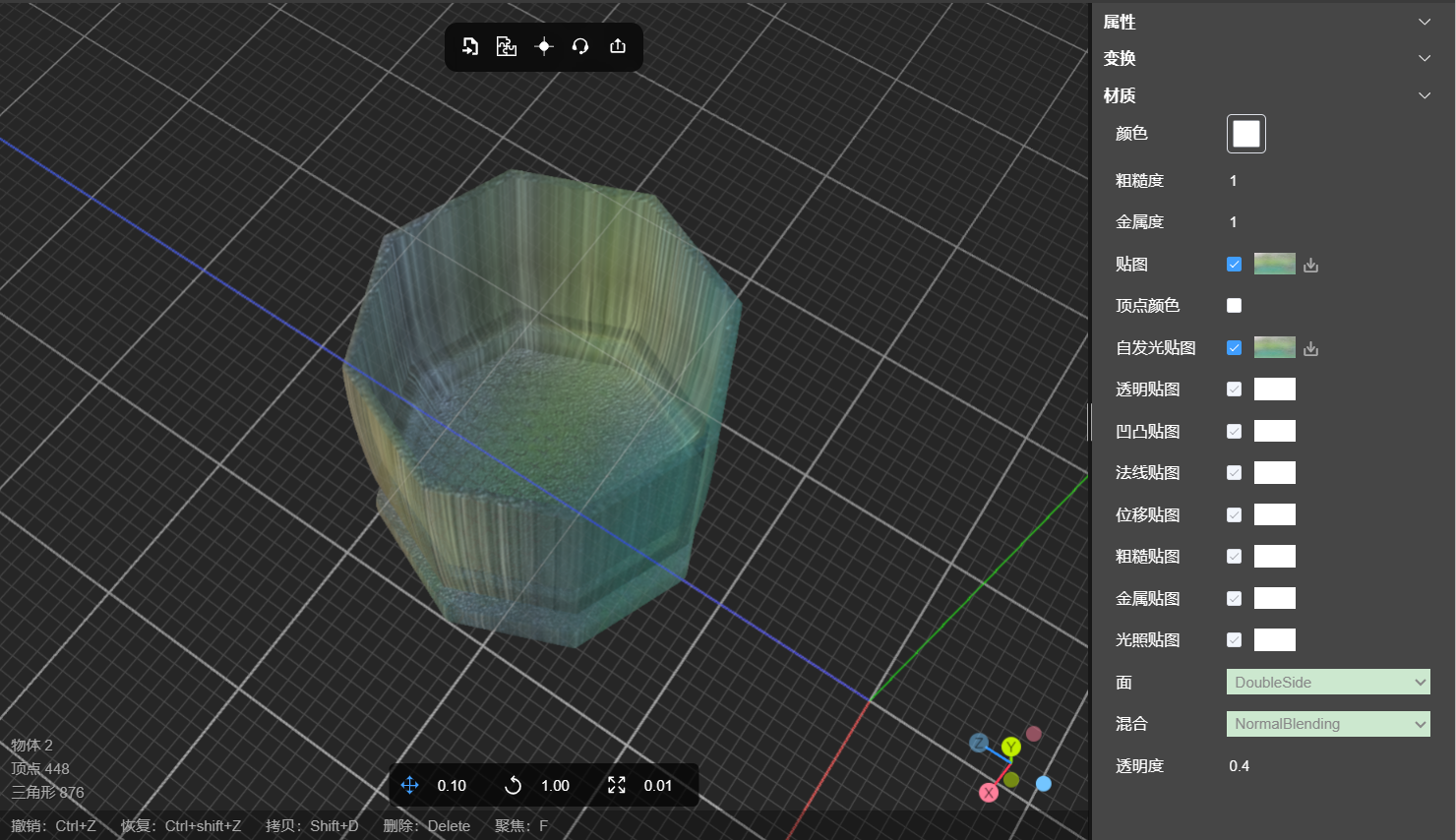
透明度和透明贴图制作玻璃水杯
1、什么是透明度 模型透明度是指一个物体或模型在呈现时的透明程度。它决定了物体在渲染时,是否显示其后面的物体或背景。 在图形渲染中,透明度通常以0到1之间的值表示。值为0表示完全透明,即物体不可见,背景或其他物体完全穿透…...

【前后缀技巧】2022牛客多校3 A
登录—专业IT笔试面试备考平台_牛客网 题意: 思路: 这种是典中典中典,对于gcd,背包问题都是一样的处理方式 预处理出前缀lca和后缀lca,枚举哪个消失即可,可以统计方案数 Code: #include &l…...

Ae 效果:CC Page Turn
扭曲/CC Page Turn Distort/CC Page Turn CC Page Turn (CC 翻页)主要用于模拟书页翻动的效果。通过使用该效果,用户可以创建出像书页或杂志页面翻动的视觉效果,增强影片的交互性和视觉吸引力。 ◆ ◆ ◆ 效果属性说明 Contro…...
】数据仓库实施步骤)
【数据仓库设计基础(四)】数据仓库实施步骤
文章目录 1.定义范围2.确定需求3.逻辑设计1)建立需要的数据列表2)识别数据源3)制作实体关系图 4.物理设计1)性能优化2)数仓的拓展性 5.装载数据6.…...

GridSearchCV 工具介绍
目录 1、定义 2、工作流程 3、示例代码 4、总结 1、定义 GridSearchCV 是一个用于超参数调优的工具,它在给定的参数网格中执行交叉验证,以确定最佳的参数组合。通过穷举搜索(exhaustive search)来寻找最佳参数,即…...
基于 SSM 框架的旅游文化管理平台
本系统采用基于JAVA语言实现、架构模式选择B/S架构,Tomcat7.0及以上作为运行服务器支持,基于JAVA等主要技术和框架设计,idea作为开发环境,数据库采用MYSQL5.7以上。 开发环境: JDK版本:JDK1.8 服务器&…...
chatgpt技术总结(包括transformer,注意力机制,迁移学习,Ray,TensorFlow,Pytorch)
最近研读了一些技术大咖对chatgpt的技术研讨,结合自己的一些浅见,进行些许探讨。 我们惊讶的发现,chatgpt所使用的技术并没有惊天地泣鬼神的创新,它只是将过去的技术潜能结合现在的硬件最大化的发挥出来,也正因如此&am…...

vertx的学习总结4
一、异步数据和事件流 1.为什么流是事件之上的一个有用的抽象? 2.什么是背压,为什么它是异步生产者和消费者的基础? 3.如何从流解析协议数据? 1. 答:因为它能够将连续的事件序列化并按照顺序进行处理。通过将事件…...

SpringBoot心旅售票管理系统
本心旅售票管理系统采用基于JAVA语言实现、架构模式选择B/S架构,Tomcat7.0及以上作为运行服务器支持,基于JAVA、springboot、vue等主要技术和框架设计,idea作为开发环境,数据库采用MYSQL5.7以上。 采用技术: SpringBootVueMySQL...
CUDA C编程权威指南:1-基于CUDA的异构并行计算
什么是CUDA?CUDA(Compute Unified Device Architecture,统一计算设备架构)是NVIDIA(英伟达)提出的并行计算架构,结合了CPU和GPU的优点,主要用来处理密集型及并行计算。什么是异构计算࿱…...
)
R语言易错点(持续更新中~~)
1.R向量元素的索引(下标)是从1开始的,而非0 >x [1] 1 2 4>x[3] [1] 4 2.[]和[ [ ] ] mylist<-list(stud.id1234,stud.name"Tom",stud.marksc(10,3,14,25,19)) > mylist $stud.id [1] 1234$stud.name [1] "Tom"$stud.marks [1] 10…...
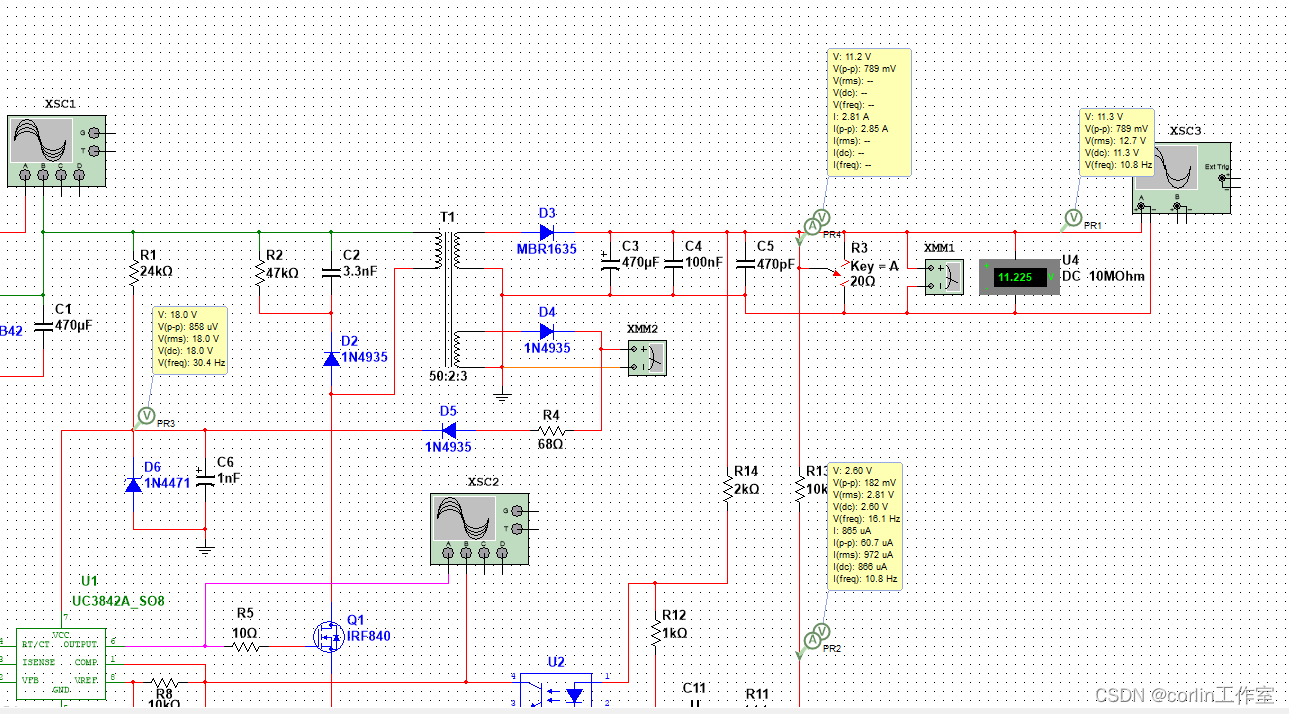
Multisim14.0仿真(二十七)基于UC3842的反激式开关电源的设计及仿真
一、UC3842简介: UC3842为固定频率电流模式PWM控制器。它们是专门为OFF−线和直流到直流转换器应用与最小的外部组件。内部实现的电路包括用于精确占空比控制的修剪振荡器、温度补偿参考、高增益误差放大器、电流传感比较器和理想适合于驱动功率MOSFET的高电流温度极…...

SpringMVC(二)@RequestMapping注解
我们先新建一个Module。 我们的依赖如下所示: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaL…...
NXP公司K60N512+PWM控制BLDC电机
本篇文章介绍了使用NXP公司提供的塔式快速原型系统来驱动控制带霍尔传感器的无刷直流电机。文章涉及的塔式快速原型系统主要包括以下四个独立板卡:1.塔式系统支撑模块(TWR-Elevator),用以连接微控制器以及周边模块;2.低…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...