python-pytorch 利用pytorch对堆叠自编码器进行训练和验证
利用pytorch对堆叠自编码器进行训练和验证
- 一、数据生成
- 二、定义自编码器模型
- 三、训练函数
- 四、训练堆叠自编码器
- 五、将已训练的自编码器级联
- 六、微调整个堆叠自编码器
一、数据生成
随机生成一些数据来模拟训练和验证数据集:
import torch# 随机生成数据
n_samples = 1000
n_features = 784 # 例如,28x28图像的像素数
train_data = torch.rand(n_samples, n_features)
val_data = torch.rand(int(n_samples * 0.1), n_features)
二、定义自编码器模型
import torch.nn as nnclass Autoencoder(nn.Module):def __init__(self, input_size, hidden_size):super(Autoencoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(input_size, hidden_size),nn.Tanh())self.decoder = nn.Sequential(nn.Linear(hidden_size, input_size),nn.Tanh())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x三、训练函数
定义一个函数来训练自编码器:
def train_ae(model, train_loader, val_loader, num_epochs, criterion, optimizer):for epoch in range(num_epochs):# Trainingmodel.train()train_loss = 0for batch_data in train_loader:optimizer.zero_grad()outputs = model(batch_data)loss = criterion(outputs, batch_data)loss.backward()optimizer.step()train_loss += loss.item()train_loss /= len(train_loader)print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {train_loss:.4f}")# Validationmodel.eval()val_loss = 0with torch.no_grad():for batch_data in val_loader:outputs = model(batch_data)loss = criterion(outputs, batch_data)val_loss += loss.item()val_loss /= len(val_loader)print(f"Epoch {epoch+1}/{num_epochs}, Validation Loss: {val_loss:.4f}")四、训练堆叠自编码器
使用上面定义的函数来训练自编码器:
from torch.utils.data import DataLoader# DataLoader
batch_size = 32
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=False)# 训练第一个自编码器
ae1 = Autoencoder(input_size=784, hidden_size=400)
optimizer = torch.optim.Adam(ae1.parameters(), lr=0.001)
criterion = nn.MSELoss()
train_ae(ae1, train_loader, val_loader, 10, criterion, optimizer)# 使用第一个自编码器的编码器对数据进行编码
encoded_train_data = []
for data in train_loader:encoded_train_data.append(ae1.encoder(data))
encoded_train_loader = DataLoader(torch.cat(encoded_train_data), batch_size=batch_size, shuffle=True)encoded_val_data = []
for data in val_loader:encoded_val_data.append(ae1.encoder(data))
encoded_val_loader = DataLoader(torch.cat(encoded_val_data), batch_size=batch_size, shuffle=False)# 训练第二个自编码器
ae2 = Autoencoder(input_size=400, hidden_size=200)
optimizer = torch.optim.Adam(ae2.parameters(), lr=0.001)
train_ae(ae2, encoded_train_loader, encoded_val_loader, 10, criterion, optimizer)# 使用第二个自编码器的编码器对数据进行编码
encoded_train_data = []
for data in train_loader:encoded_train_data.append(ae2.encoder(data))
encoded_train_loader = DataLoader(torch.cat(encoded_train_data), batch_size=batch_size, shuffle=True)encoded_val_data = []
for data in val_loader:encoded_val_data.append(ae2.encoder(data))
encoded_val_loader = DataLoader(torch.cat(encoded_val_data), batch_size=batch_size, shuffle=False)# 训练第三个自编码器
ae3 = Autoencoder(input_size=400, hidden_size=200)
optimizer = torch.optim.Adam(ae3.parameters(), lr=0.001)
train_ae(ae3, encoded_train_loader, encoded_val_loader, 10, criterion, optimizer)# 使用第三个自编码器的编码器对数据进行编码
encoded_train_data = []
for data in train_loader:encoded_train_data.append(ae3.encoder(data))
encoded_train_loader = DataLoader(torch.cat(encoded_train_data), batch_size=batch_size, shuffle=True)encoded_val_data = []
for data in val_loader:encoded_val_data.append(ae3.encoder(data))
encoded_val_loader = DataLoader(torch.cat(encoded_val_data), batch_size=batch_size, shuffle=False)五、将已训练的自编码器级联
class StackedAutoencoder(nn.Module):def __init__(self, ae1, ae2, ae3):super(StackedAutoencoder, self).__init__()self.encoder = nn.Sequential(ae1.encoder, ae2.encoder, ae3.encoder)self.decoder = nn.Sequential(ae3.decoder, ae2.decoder, ae1.decoder)def forward(self, x):x = self.encoder(x)x = self.decoder(x)return xsae = StackedAutoencoder(ae1, ae2, ae3)六、微调整个堆叠自编码器
在整个数据集上重新训练堆叠自编码器来完成。
train_autoencoder(sae, train_dataset)相关文章:

python-pytorch 利用pytorch对堆叠自编码器进行训练和验证
利用pytorch对堆叠自编码器进行训练和验证 一、数据生成二、定义自编码器模型三、训练函数四、训练堆叠自编码器五、将已训练的自编码器级联六、微调整个堆叠自编码器 一、数据生成 随机生成一些数据来模拟训练和验证数据集: import torch# 随机生成数据 n_sample…...
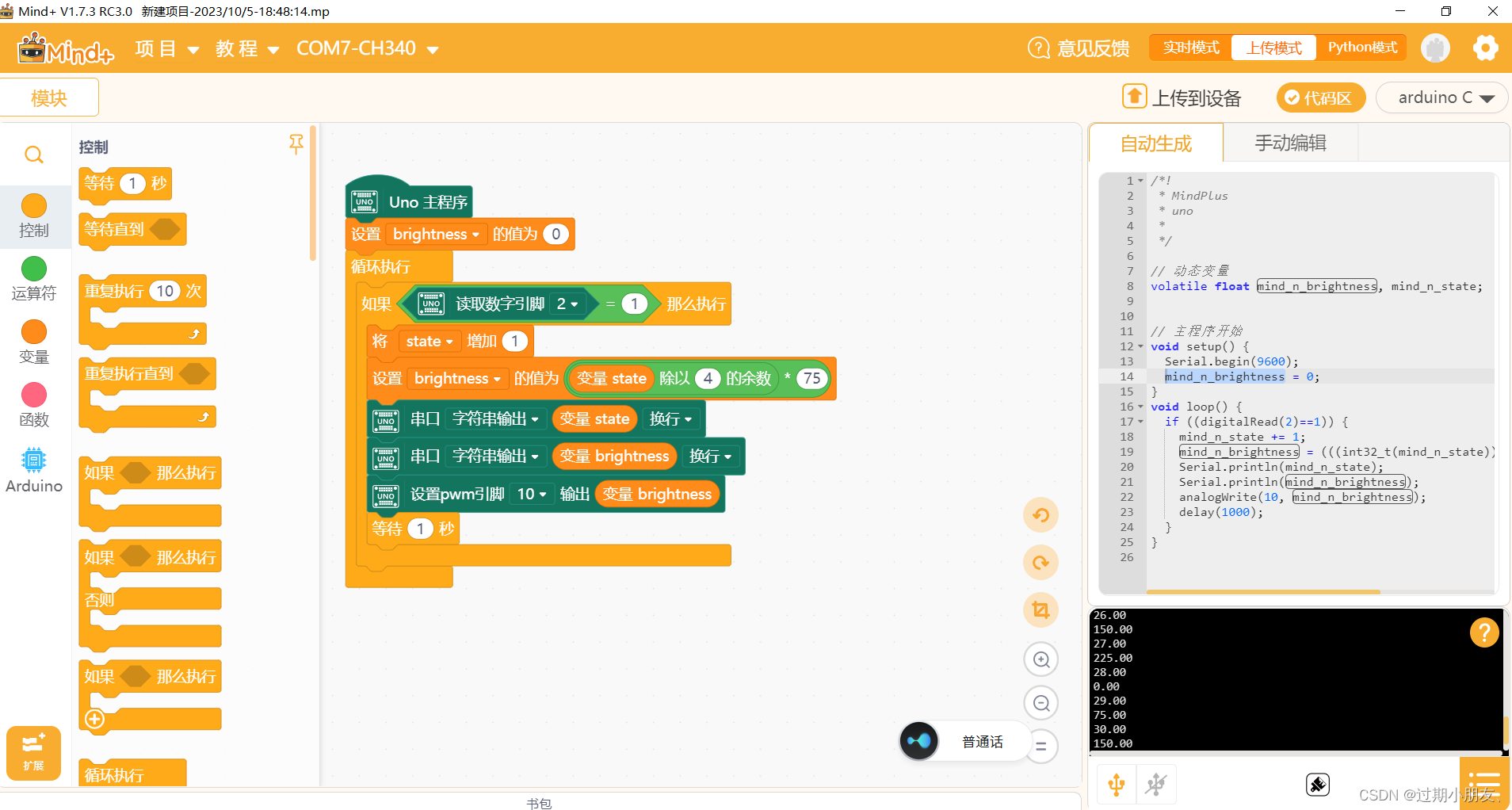
制作 3 档可调灯程序编写
PWM 0~255 可以将数据映射到0 75 150 225 尽可能均匀电压间隔...

源码分享-M3U8数据流ts的AES-128解密并合并---GoLang实现
之前使用C语言实现了一次,见M3U8数据流ts的AES-128解密并合并。 学习了Go语言后,又用Go重新实现了一遍。源码如下,无第三方库依赖。 package mainimport ("crypto/aes""crypto/cipher""encoding/binary"&quo…...

CSDN Q: “这段代码算是在STC89C52RC51单片机上完成PWM呼吸灯了吗?“
这是 CSDN上的一个问题 这段代码算是在STC89C52RC51单片机上完成PWM呼吸灯了吗,还是说得用上定时器和中断函数#include <regx52.h> 我个人认为: 效果上来说, 是的! 码以 以Time / 100-Time 调 Duty, 而 for i loop成 Period, 加上延时, 实现了 PWM周期, 虽然…...
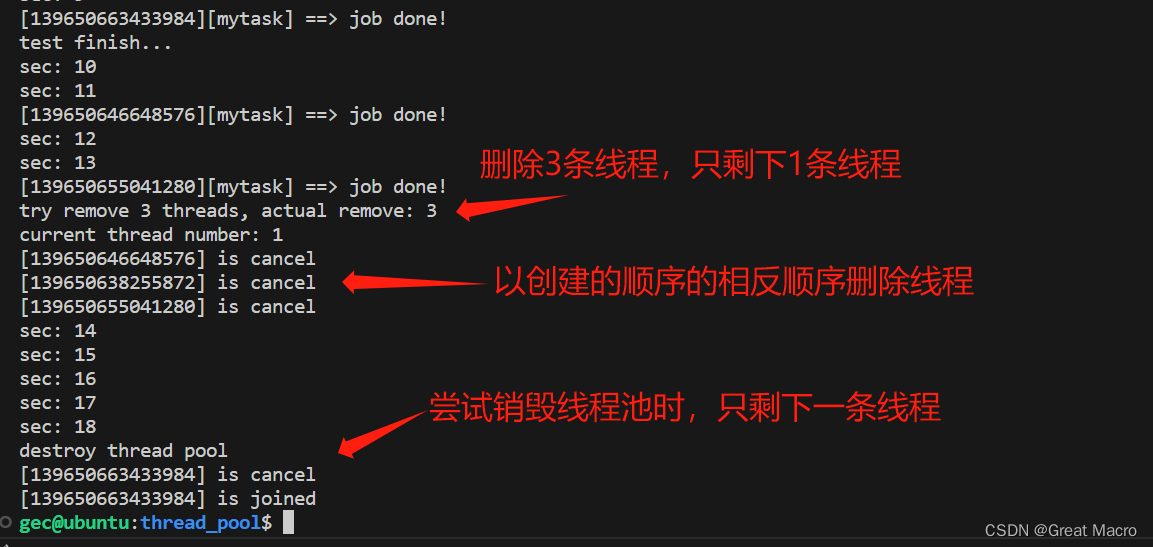
Linux系统编程系列之线程池
Linux系统编程系列(16篇管饱,吃货都投降了!) 1、Linux系统编程系列之进程基础 2、Linux系统编程系列之进程间通信(IPC)-信号 3、Linux系统编程系列之进程间通信(IPC)-管道 4、Linux系统编程系列之进程间通信-IPC对象 5、Linux系统…...

Linux CentOS7 vim多文件与多窗口操作
窗口是可视化的分割区域。Windows中窗口的概念与linux中基本相同。连接xshell就是在Windows中新建一个窗口。而vim打开一个文件默认创建一个窗口。同时,Vim打开一个文件也就会建立一个缓冲区,打开多个文件就会创建多个缓冲区。 本文讨论vim中打开多个文…...

SPI 通信协议
1. SPI通信 1. 什么是SPI通信协议 2. SPI的通信过程 在一开始会先把发送缓冲器的数据(8位)。一次性放到移位寄存器里。 移位寄存器会一位一位发送出去。但是要先放到锁存器里。然后从机来读取。从机的过程也一样。当移位寄存器的数据全部发送完。其实…...
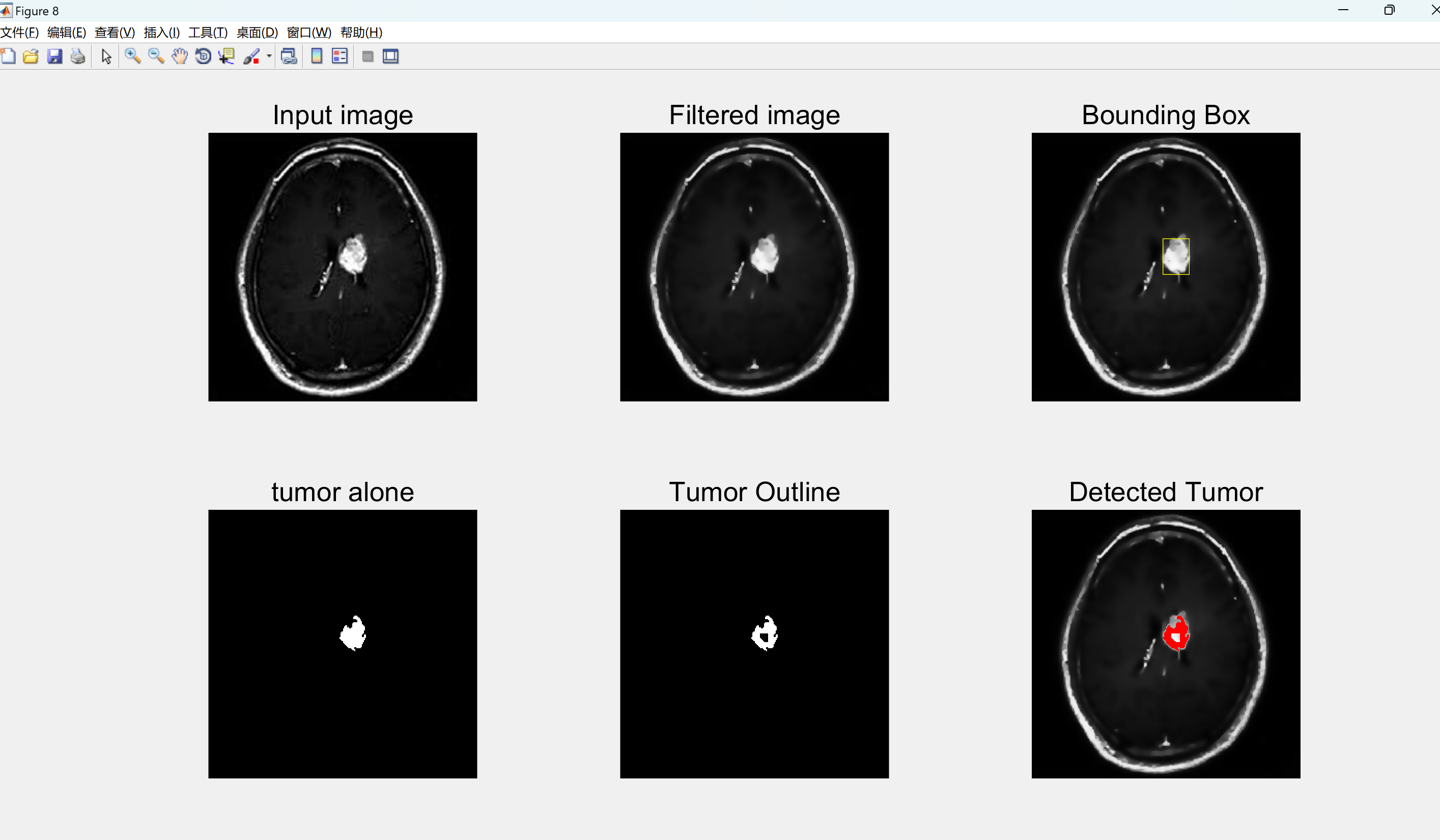
【图像处理】使用各向异性滤波器和分割图像处理从MRI图像检测脑肿瘤(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
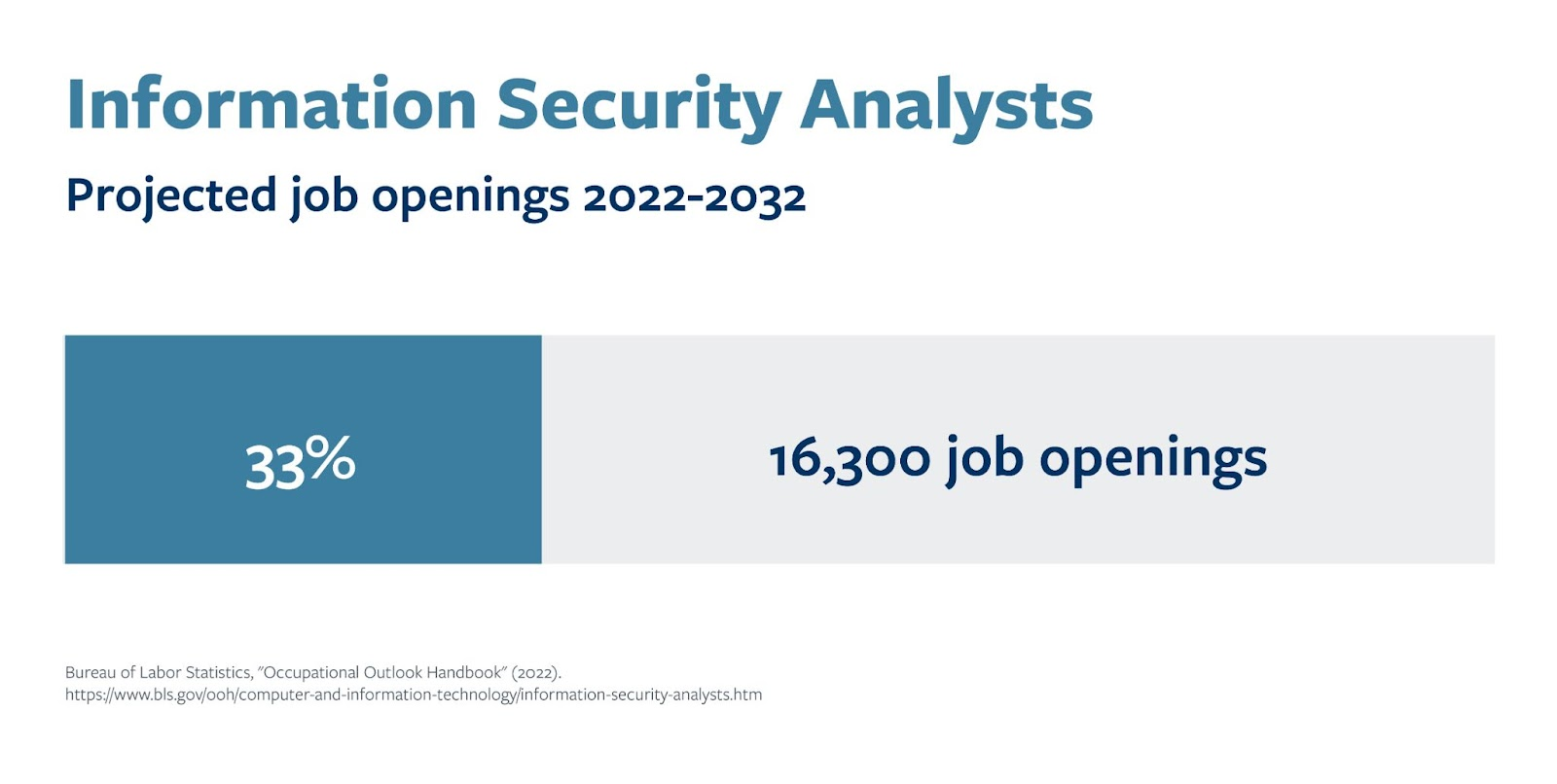
5个适合初学者的初级网络安全工作,网络安全就业必看
前言 网络安全涉及保护计算机系统、网络和数据免受未经授权的访问、破坏和盗窃 - 防止数字活动和数据访问的中断 - 同时也保护用户的资产和隐私。鉴于公共事业、医疗保健、金融以及联邦政府等行业的网络犯罪攻击不断升级,对网络专业人员的需求很高,这并…...

Kafka核心原理
1、Topic的分片和副本机制 分片作用: 解决单台节点容量有限的问题,节点多,效率提升,吞吐量提升。通过分片,将一个大的容器分解为多个小的容器,分布在不同的节点上,从而实现分布式存储。 分片…...

探秘前后端开发世界:猫头虎带你穿梭编程的繁忙街区,解锁全栈之路
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

洛谷_分支循环
p2433 问题 5 甲列火车长 260 米,每秒行 12 米;乙列火车长220 米,每秒行 20 米,两车相向而行,从两车车头相遇时开始计时,多长时间后两车车尾相离?已知答案是整数。 计算方式:两车车…...

MySQL数据库入门到精通——进阶篇(3)
黑马程序员 MySQL数据库入门到精通——进阶篇(3) 1. 锁1.1 锁-介绍1.2 锁-全局锁1.3 锁-表级锁1.3.1 表级锁-表锁1.3.2 表级锁元数据锁( meta data lock,MDL)1.3.3 表级锁-意向锁1.3.4 表级锁意向锁测试 1.4 锁-行级锁1.4.1 行级锁-行锁1.4.2…...

Mind Map:大语言模型中的知识图谱提示激发思维图10.1+10.2
知识图谱提示激发思维图 摘要介绍相关工作方法第一步:证据图挖掘第二步:证据图聚合第三步:LLM Mind Map推理 实验实验设置医学问答长对话问题使用KG的部分知识生成深入分析 总结 摘要 LLM通常在吸收新知识的能力、generation of hallucinati…...
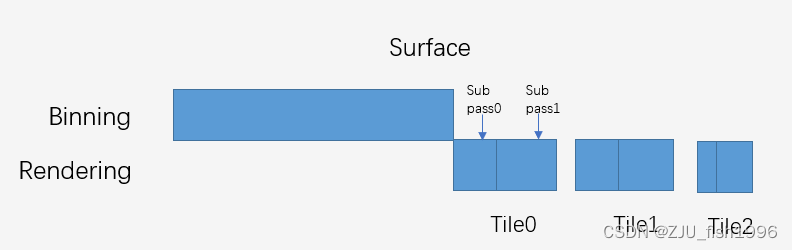
[引擎开发] 杂谈ue4中的Vulkan
接触Vulkan大概也有大半年,概述一下自己这段时间了解到的东西。本文实际上是杂谈性质而非综述性质,带有严重的主观认知,因此并没有那么严谨。 使用Vulkan会带来什么呢?简单来说就是对底层更好的控制。这意味着我们能够有更多的手段…...

docker--redis容器部署及地理空间API的使用示例-II
文章目录 Redis 地理位置类型API命令操作示例JAVA使用示例导入依赖RedisTemplate 操作GeoData示例CityInfo实体类Geo操作接口类Geo操作接口实现类SpringBoot测试类RedissonClient 操作GeoData示例docker–redis容器部署及与SpringBoot整合 docker–redis容器部署及地理空间API的…...

Vue中如何进行文件浏览与文件管理
Vue中的文件浏览与文件管理 文件浏览与文件管理是许多Web应用程序中常见的功能之一。在Vue.js中,您可以轻松地实现文件浏览和管理功能,使您的应用程序更具交互性和可用性。本文将向您展示如何使用Vue.js构建文件浏览器和文件管理功能,以及如…...
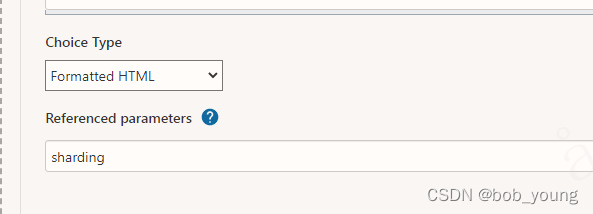
jenkins利用插件Active Choices Plug-in达到联动显示或隐藏参数,且参数值可修改
1. 添加组件 Active Choices Plug-in 如jenkins无法联网,可在以下两个地址中下载插件,然后放到/home/jenkins/.jenkins/plugin下面重启jenkins即可 Active Choices Active Choices | Jenkins plugin 2. 效果如下: sharding为空时…...

香蕉叶病害数据集
1.数据集 第一个文件夹为数据增强(旋转平移裁剪等操作)后的数据集 第二个文件夹为原始数据集 2.原始数据集 Cordana文件夹(162张照片) healthy文件夹(129张) Pestalotiopsis文件夹(173张照片&…...
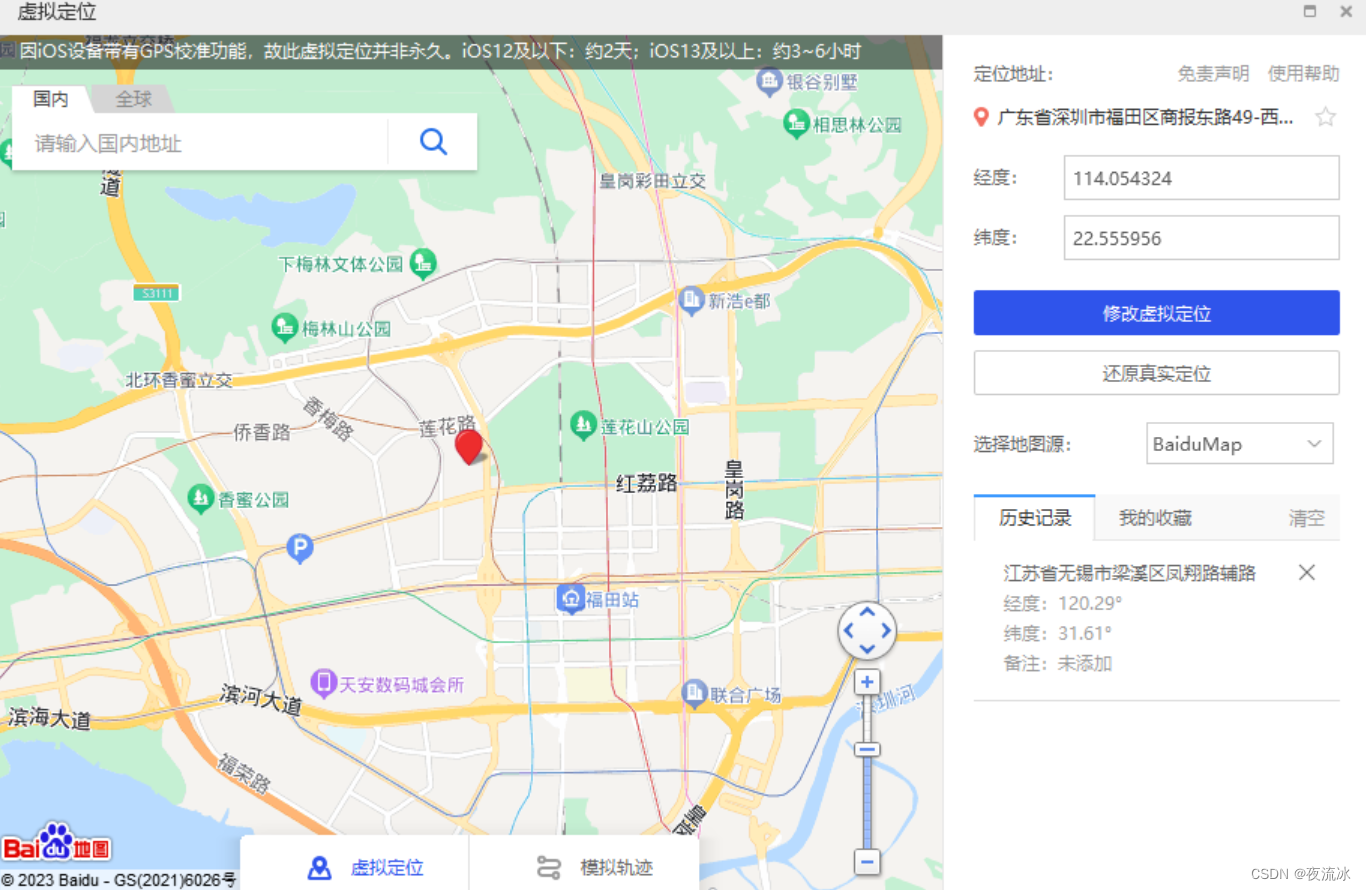
天地无用 - 修改朋友圈的定位: 高德地图 + 爱思助手
1,电脑上打开高德地图网页版 高德地图 (amap.com) 2,网页最下一栏,点击“开放平台” 高德开放平台 | 高德地图API (amap.com) 3,在新网页中,需要登录高德账户才能操作。 可以使用手机号和验证码登录。 4,…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...