【动手学深度学习-Pytorch版】Transformer代码总结
本文是纯纯的撸代码讲解,没有任何Transformer的基础内容~ 是从0榨干Transformer代码系列,借用的是李沐老师上课时讲解的代码。 本文是根据每个模块的实现过程来进行讲解的。如果您想获取关于Transformer具体的实现细节(不含代码)可以转到李宏毅老师的录播课:
油管需要翻墙~
在Transformer代码实现部分,首先需要准备Encoder和Decoder中每个层需要用到的模块,包括Encoder和Decoder中的嵌入层、位置编码、多头注意力、Add&Norm、基于位置的前馈网络(三维MLP)和Decoder中的掩蔽多头注意力以及全连接层。
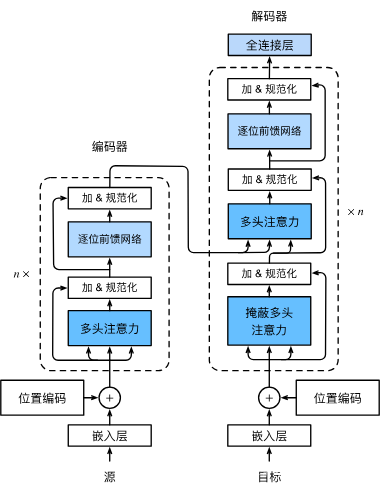
下面依次实现它们,并用于生成EncoderBlock和DecoderBlock。【当然具体的Transformer细节可以从上一篇转载文章中看到,也可以从下面视频中看到】
【转载】Transformer模型详解(图解最完整版)
【论文必读#6:Transformer】GPT时代AI GC基础模型全解读】
基于位置的前馈网络
它其实相当于一个2层的多层感知机,中间使用激活函数ReLU()。需要注意的是:在Pytorch中如果输入不是二维的,那前面的所有维度默认都是样本的维度,而最后一个维度当做feature的维度。在基于位置的前馈网络中,输入向量X的维度为(批量大小,时间步数或序列长度,隐单元数或特征维度),输出向量O的维度为(批量大小,时间步数,ff_num_outputs)
"""在pytorch中如果输入不是二维的,那前面的所有维度默认都是样本的维度,后面的维度当做feature的维度"""
# @save
# 基于位置的前馈网络---》是一个输入是三维的MLP
class PositionWiseFFN(nn.Module):def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):res_t2 = self.dense1(X)print('res_t2.shape:', res_t2.shape) # [2,3,4]res_t3 = self.relu(res_t2)print('res_t3.shape:', res_t3.shape) # [2,3,4]res_t4 = self.dense2(res_t3)print('res_t4.shape:', res_t4.shape) # [2,3,8--->受一开始实例初始化时的num_outputs控制]return self.dense2(self.relu(self.dense1(X)))ffn = PositionWiseFFN(4, 4, 8)
ffn.eval() # 6 x 4 · 4 x 4
res_t1 = ffn(torch.ones((2, 3, 4)))[0]
print('res_t1.shape:', res_t1.shape) # torch.Size([3, 8])
可以看到,最终输出的最后一个维度不是由数据的最后维度控制的,而是在模型创建时的最后一个维度控制的。并且,在res_t1 = ffn(torch.ones((2, 3, 4)))[0]中,pytorch会将前两个维度看作是输入特征的维度。
Add & Norm
Add层即残差连接层,而Norm层则是用来进行normalization的。且残差连接要求两个输入的特征形状必须相同,以便在加法操作以后输出张量的形状相同。
当然在做normalization时会有层归一化和批量归一化,那这里为什么要用层归一化,而不是批量归一化呢?
因为批量归一化是对每个特征/通道里面的元素进行归一化,不适合序列长度会变的NLP应用。而层归一化是对每一个样本里面的元素进行归一化,可以用于Seq2Seq。
LayerNorm会把每个样本(所有特征)变成均值为0方差为1;BatchNorm会把每个特征变成均值为0方差为1
# @save
class AddNorm(nn.Module):"""先进行残差连接再进行规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
多头注意力机制
多头注意力机制,在前面的注意力章节已经实现了,这里直接调用的D2L库中的多头注意力类。当然,你也可以在D2L库中直接copy到工程里:
D2L库函数
class MultiHeadAttention(d2l.Module):"""Multi-head attention.Defined in :numref:`sec_multihead-attention`"""def __init__(self, num_hiddens, num_heads, dropout, bias=False, **kwargs):super().__init__()self.num_heads = num_headsself.attention = d2l.DotProductAttention(dropout)self.W_q = nn.LazyLinear(num_hiddens, bias=bias)self.W_k = nn.LazyLinear(num_hiddens, bias=bias)self.W_v = nn.LazyLinear(num_hiddens, bias=bias)self.W_o = nn.LazyLinear(num_hiddens, bias=bias)def forward(self, queries, keys, values, valid_lens):# Shape of queries, keys, or values:# (batch_size, no. of queries or key-value pairs, num_hiddens)# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)# After transposing, shape of output queries, keys, or values:# (batch_size * num_heads, no. of queries or key-value pairs,# num_hiddens / num_heads)queries = self.transpose_qkv(self.W_q(queries))keys = self.transpose_qkv(self.W_k(keys))values = self.transpose_qkv(self.W_v(values))if valid_lens is not None:# On axis 0, copy the first item (scalar or vector) for num_heads# times, then copy the next item, and so onvalid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)# Shape of output: (batch_size * num_heads, no. of queries,# num_hiddens / num_heads)output = self.attention(queries, keys, values, valid_lens)# Shape of output_concat: (batch_size, no. of queries, num_hiddens)output_concat = self.transpose_output(output)return self.W_o(output_concat)def transpose_qkv(self, X):"""Transposition for parallel computation of multiple attention heads.Defined in :numref:`sec_multihead-attention`"""# Shape of input X: (batch_size, no. of queries or key-value pairs,# num_hiddens). Shape of output X: (batch_size, no. of queries or# key-value pairs, num_heads, num_hiddens / num_heads)X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)# Shape of output X: (batch_size, num_heads, no. of queries or key-value# pairs, num_hiddens / num_heads)X = X.permute(0, 2, 1, 3)# Shape of output: (batch_size * num_heads, no. of queries or key-value# pairs, num_hiddens / num_heads)return X.reshape(-1, X.shape[2], X.shape[3])def transpose_output(self, X):"""Reverse the operation of transpose_qkv.Defined in :numref:`sec_multihead-attention`"""X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)EncoderBlock
下面实现编码器中的一个块(EncoderBlock),其中包括两个子层:多头注意力和基于位置的前馈网络。
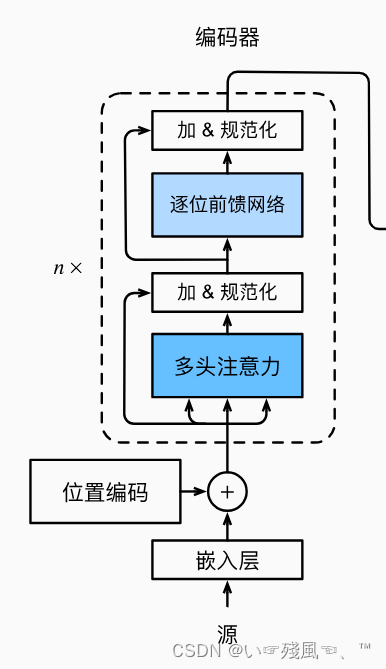
EncoderBlock的forward()函数比较简单,就是将传入的特征X(前提是已经进行了Embedding)依次传入:
多头注意力
self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias)
加 & 规范化
self.addnorm1 = AddNorm(norm_shape, dropout)
形成特征向量Y,然后再将Y传入逐位前馈网络和加 & 规范化层形成最终的输出
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
最后整合所有代码,利用forward函数进行前向传播:
# @save ffn 前馈神经网络
class EncoderBlock(nn.Module):def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):# print('EncoderBlock中的X',X)# with open('D://pythonProject//f-write//D2L-Transformer/encoder-X.txt', 'w') as f:# f.write(str(X))# X传入的是size还是数据?---->数据Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))
Transformer的编码器和解码器有一个非常好的特性,就是它们的任何层都不会改变其输入的形状,即永远保持:输出形状 = 输入形状
"""Transformer编码器的任何层都不会改变其输入的形状"""
"""Transformer编码器的输出形状 = 输入形状"""
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
# key_size = 24 query_size = 24 value_size = 24
# num_hiddens = 24
# norm_shape = [100,24] ffn_num_input = 24
# ffn_num_hiddens = 48 num_heads = 8
# dropout = 0.5
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
res = encoder_blk(X, valid_lens).shape
print('encoder_blk(X,valid_lens).shape:', res)
# encoder_blk(X,valid_lens).shape: torch.Size([2, 100, 24])
TransformerEncoder
官网上给出了一个关于TransformerEncoder中对于输入特征向量X进行缩放的一段话:
由于这里使用的是值范围在-1和1之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
那这里有一个问题:矩阵相加满足广播机制,为什么要进行缩放嘞?答案就是如果不进行缩放,那么位置信息就会掩盖词嵌入特征的权重,更为完整的解释在下方,原出处是在D2L该章节的讨论区:
token是one-hot,经过embedding相当于从词嵌入矩阵W中取特定行,
而W被 Xavier初始化,其方差和嵌入维数成反比。也就是嵌入维数越大,
方差越小,权重越集中于0,后续再和positional encoding相加,
词嵌入特征由于绝对值太小,可能被位置信息掩盖,难以影响模型后续计
算。因此需要放大W的方差,最直接的方法就是乘以维度的平方根。
解决了输入特征X的缩放问题,再来看下面Encoder的代码就很简单了:
# @save
class TransformerEncoder(d2l.Encoder):"""Transformer编码器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block" + str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因为位置编码值在-1到1之间# 因此嵌入值乘以嵌入维度的平方根进行缩放,# 然后再与位置编码相加# with open('D://pythonProject//f-write//D2L-Transformer/TransformerEncoder-X1-encoder.txt', 'w') as f:# f.write(str(X))X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))# with open('D://pythonProject//f-write//D2L-Transformer/TransformerEncoder-X2-encoder.txt', 'w') as f:# f.write(str(X))self.attention_weights = [None] * len(self.blks)# 列表:[None, None, None, None, None...]with open('D://pythonProject//f-write//D2L-Transformer/TransformerEncoder-self.blks.txt', 'w') as f:f.write(str(self.blks))# print(self.blks)"""拿到每一层的注意力权重并保存起来"""for i, blk in enumerate(self.blks):X = blk(X, valid_lens)self.attention_weights[i] = blk.attention.attention.attention_weightsreturn X
在上面的TransformerEncoder类中主要干了下面几个活:
首先,在__init__函数中,利用for循环依次创建了多个EncoderBlock,这里Block的大小也就是下图中n的值:
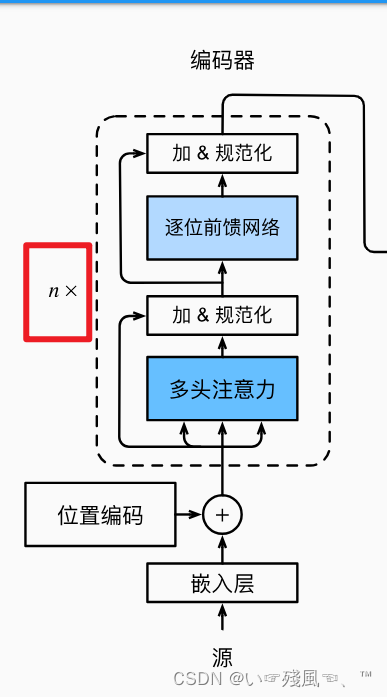
想必看完了上面的Transformer论文讲解视频,初学者也会恍然大悟,其实Transformer就是一个串并联电池组,其中这里的n就是左侧串联电池组的个数。
其次,要对输入特征X进行Embedding词嵌入。由上面Block的代码可得知,它并没有干词嵌入的活,所以在Encoder中要先进行词嵌入,才能将生成的嵌入信息传入到Block中。
最后,保存每个电池中的注意力权重。并返回经过处理后的特征向量X。
下面我们将指定超参数进行Encoder模型的训练:
vocab_size = 200
key_size = 24
query_size = 24
value_size = 24
num_hiddens = 24
norm_shape = [100, 24]
ffn_num_input = 24
ffn_num_hiddens = 48
num_heads = 8
num_layers = 2
dropout = 0.5
"""指定了超参数来创建一个两层Transformer编码器"""
"""Transformer编码器输出的形状是(批量大小,时间步数,num_hiddens)"""
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
res = encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
print('encoder-shape:',res)
DecoderBlock
在DecoderBlock中,第一个子层——掩蔽多头注意力的输入来自于上一个编码器的输出。同时掩蔽自注意力中的参数dec_valid_lens是为了便于任何查询只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算,这样就可以在解码器中保留自回归的属性,仅仅对已知的数据进行建模,即 X t X_t Xt仅仅依赖于 X t − 1 X_{t-1} Xt−1以及该时刻以前的上下文信息。因此,在下面代码中,我们通过state[2]存储每个层的key value对的信息,用dec_valid_lens变量存储实际的掩码长度。
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,i,**kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = i # 用于表示这是第i个DecoderBlock块# 掩蔽???多头注意力self.attention1 = d2l.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout)# 加 & 规范化self.addnorm1 = AddNorm(norm_shape,dropout)# 多头注意力self.attention2 = d2l.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout)# 加 & 规范化self.addnorm2 = AddNorm(norm_shape,dropout)# 逐位前馈网络self.ffn = PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)# 加 & 规范化self.addnorm3 = AddNorm(norm_shape,dropout)def forward(self,X,state):enc_outputs,enc_valid_lens = state[0],state[1]# 训练阶段,输出序列的所有词元都在同一时间处理# 因此state[2][self.i]初始化为None# 预测阶段,输出序列是通过词元一个接着一个解码的# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示"""训练时,由于每次都需要调用init_state函数,因此重新训练一个batch时,state[2]始终是一个None列表,当测试时,由于每次根据当前时间步的词元预测下一个词元时都不会重新调用init_state()函数,不会重新初始化state,因此state[2]里面保存的是之前时间步预测出来的词元信息(存的是decoder每层第一个掩码多头注意力state信息)"""if state[2][self.i] is None:print('state[2][self.i]--->为空')key_values = Xelse:# 在predict的时候,key和values是之前得到的上下文信息print('state[2][self.i]--->不为空')key_values = torch.cat((state[2][self.i],X),axis=1)state[2][self.i] = key_values# 在我们训练的时候会执行model.train(),这时候将training设置为True,# 在执行eval()的时候,将training设置为false。if self.training:batch_size,num_steps,_ = X.shape"""训练时执行当前时间步的query时只看它前面的keys,values,不看它后面的keys,values。因为预测时是从左往右预测的,右边还没有预测出来,因此右侧的keys是没有的,看不到右侧的keys;训练时预测当前时间步词元能看到后面的目标词元,因此需要dec_valid_lens"""# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]"""dec_valid_lens用于掩蔽注意力遮掉后面的长度"""dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:"""测试时预测当前时间步的词元只能看到之前预测出来的词元,后面还没预测的词元还看不到,因此dec_valid_lens可以不需要"""dec_valid_lens = None# 第一层:掩蔽多头注意力X2 = self.attention1(X,key_values,key_values,dec_valid_lens)# 第二层:加 & 规范化Y = self.addnorm1(X,X2)# 编码器-解码器注意力# enc_outputs的开头:(batch_size,num_steps,num_hiddens)# 第三层:多头注意力 它的key和value来自于Encoder的OutputY2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)# 第四层:加 & 规范化Z = self.addnorm2(Y, Y2)# 第五层 + 第六层:逐位前馈网络 + 加&规范化return self.addnorm3(Z, self.ffn(Z)), state
在上述代码中__init_()函数定义了一个解码器块用到的注意力机制、Add&Norm层以及FFN层。
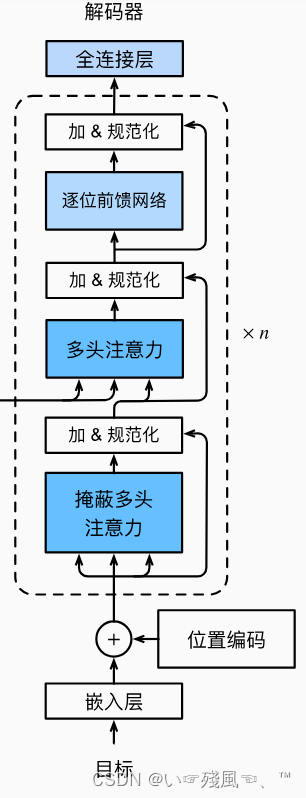
难点在于forward函数:它将获取的上下文信息(包括编码器的输出信息、编码器输出信息实际的tokens长度)分别放到了变量enc_outputs以及变量enc_valid_lens中。那问题来了:state里面究竟存放的是什么信息?要回答这个问题,需要用到下面实例化的代码:
"""为了便于在“编码器-解码器”注意力中进行缩放点积计算和残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
"""
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
res = decoder_blk(X, state)[0].shape
print('decoder_blk.shape:',res)
在上述代码中初始化state的时候state的形状以及存放的内容就是forward()函数接收到的state信息:
- state[0] : 编码器的输出信息
- state[1] : 编码器的输出信息有效长度valid-lens
- state[2]: 这里一开始初始化为空,而在DecoderBlock中可以发现,后面将使用它作为每一个DecoderBlock中的key_value值的存储。
对于state[2]的内容,在TransformerDecoder也有用到。TransformerDecoder的__init__()函数中初始化Block时会将局部变量i的值传到DecoderBlock中,作为每一个Bock的下标。
for i in range(num_layers):#print('执行了~')self.blks.add_module("block"+str(i),DecoderBlock(key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,i))
而DecoderBlock中也是巧用了其传过来的变量i,这里的i依旧可以看做是每一个Block的索引值。同时,DecoderBlock会将state[2]变成一个二维数组,第二个维度就是每一个层的state[2]信息,即key value pair的内容。训练时,由于每次都需要调用init_state函数,因此重新训练一个batch时,state[2]始终是一个None列表,当测试时,由于每次根据当前时间步的词元预测下一个词元时都不会重新调用init_state()函数,不会重新初始化state,因此state[2]里面保存的是之前时间步预测出来的词元信息(存的是decoder每层第一个掩码多头注意力state信息)。
对应代码:
if state[2][self.i] is None:print('state[2][self.i]--->为空')key_values = Xelse:# 在predict的时候,key和values是之前得到的上下文信息print('state[2][self.i]--->不为空')key_values = torch.cat((state[2][self.i],X),axis=1)state[2][self.i] = key_values
对于dec_valid_lens的处理同样是通过判断模型的状态来进行的,首先,训练时执行当前时间步的query时只看它前面的keys,values, 不看它后面的keys,values。因为预测时是从左往右预测的,右边还没有预测出来,因此右侧的keys是没有的,看不到右侧的keys;训练时预测当前时间步词元能看到后面的目标词元,因此需要dec_valid_lens。这里会将dec_valid_lens利用torch.arange()生成一个在1到num_steps + 1中的数,同时repeat成(batch_size, 1)
其次,测试时预测当前时间步的词元只能看到之前预测出来的词元,后面还没预测的词元还看不到,因此dec_valid_lens可以不需要。
if self.training:batch_size,num_steps,_ = X.shape"""训练时执行当前时间步的query时只看它前面的keys,values,不看它后面的keys,values。因为预测时是从左往右预测的,右边还没有预测出来,因此右侧的keys是没有的,看不到右侧的keys;训练时预测当前时间步词元能看到后面的目标词元,因此需要dec_valid_lens"""# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]"""dec_valid_lens用于掩蔽注意力遮掉后面的长度"""dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:"""测试时预测当前时间步的词元只能看到之前预测出来的词元,后面还没预测的词元还看不到,因此dec_valid_lens可以不需要"""dec_valid_lens = None
最后是堆叠电池——将特征信息X依次输入到DecoderBlock中需要实现的掩蔽多头注意力、加 & 规范化、注意力机制、加 & 规范化、逐位前馈网络 + 加&规范化中。
当然,正如编码器部分所述的那样,Transformer的解码器与编码器的输入输出都是保持同样的特征维度的,下面是一个测试实例:
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
res = decoder_blk(X, state)[0].shape
print('decoder_blk.shape:',res)
TransformerDecoder
在TransformerDecoder中的主要任务是生成多个DecoderBlock。最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。另外,解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
块的堆叠是在__init__()中完成的,上面也讲过:
初始化state时是根据上面Block所列的state的每一个索引存储值进行初始化的。第一个是编码器的输出、第二个是编码器输出信息的实际长度、第三个是存储的每个Block中的key 与 value的值(当然他们初始化都为None):
forward()函数中主要是保存了解码器中每一个的自注意权重:

全部代码:
"""最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。"""
"""解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要"""
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self,vocab_size,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout,**kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size,num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens,dropout)self.blks = nn.Sequential()for i in range(num_layers):#print('执行了~')self.blks.add_module("block"+str(i),DecoderBlock(key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,i))# 用dense作为输出self.dense = nn.Linear(num_hiddens,vocab_size)def init_state(self,enc_outputs,enc_valid_lens,*args):return [enc_outputs,enc_valid_lens,[None] * self.num_layers]def forward(self,X,state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self._attention_weights = [[None] * len(self.blks) for _ in range(2)]for i,blk in enumerate(self.blks):X,state = blk(X,state)# 解码器自注意力权重self._attention_weights[0][i] = blk.attention1.attention.attention_weights"""编码器-解码器 自注意力权重"""self._attention_weights[1][i] = blk.attention2.attention.attention_weightsreturn self.dense(X),state@propertydef attention_weights(self):return self._attention_weights
训练
训练部分主要是实例化“编码器-解码器”架构,编码器2层,解码器2层,使用4头注意力。同时为了进行Seq2Seq上的学习,下面使用了“英语-法语”机器翻译数据集上训练Transformer模型。这里有一个棘手的问题在D2L讨论区被提出:为什么用于残差连接和归一化的参数norm_shape不是根据train的num_steps为10而设置层[10,32]?
答案简洁表示就是在测试时会出现矩阵维度不适导致运算错误,具体来讲:
因为这里考虑到了train时的num_steps是10,但是在predict的时候num_steps则为1。所以为了适应不同的时间步,且训练和预测都使用同一个网络,所以这里norm_shape为[32]。将其改为[10,32]时训练误差减小很多:loss 0.005, 3700.9 tokens/sec on cpu
但是测试时会报错:
RuntimeError: Given normalized_shape=[10, 32], expected input with shape [*, 10, 32], but got input of size[1, 1, 32]
其余内容和序列到序列的学习部分内容就大同小异了~
"""训练"""
"""实例化编码器-解码器架构
编码器:2层
解码器:2层
使用:4头注意力
为了进行序列到序列的学习,下面在“英语-法语”机器翻译数据集上训练Transformer模型
"""
num_hiddens,num_layers,dropout,batch_size,num_steps = 32,2,0.1,64,10
lr,num_epochs,device = 0.005,200,d2l.try_gpu()
ffn_num_input,ffn_num_hiddens,num_heads =32,64,4
key_size,query_size,value_size = 32,32,32norm_shape = [32]
# norm_shape = [10,32]
"""
这里的norm_shape为什么不设置成[10,32]?
因为这里考虑到了train时的num_steps是10,但是在predict的时候num_steps则为1
所以为了适应不同的时间步,且训练和预测都使用同一个网络,所以这里norm_shape为[32]将其改为[10,32]时训练误差减小很多:loss 0.005, 3700.9 tokens/sec on cpu
但是测试时会报错:
RuntimeError: Given normalized_shape=[10, 32], expected input with shape [*, 10, 32], but got input of size[1, 1, 32]
"""
train_iter,src_vocab,tgt_vocab = d2l.load_data_nmt(batch_size,num_steps)
encoder = TransformerEncoder(len(src_vocab),key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout)
decoder = TransformerDecoder(len(tgt_vocab),key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout)
net = d2l.EncoderDecoder(encoder,decoder)
d2l.train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)
plt.show()engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
当进行最后一个英语到法语的句子翻译工作时,让我们可视化Transformer的注意力权重。编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)【来自于D2L官网描述】
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,-1, num_steps))
res = enc_attention_weights.shape
print('enc_attention_weights.shape',res)接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值的不同的表示子空间来表示不同的注意力。
d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))
plt_show.show()
为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作。例如用零填充被掩蔽住的注意力权重。值得注意的是,解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \dec_attention_weights.permute(1, 2, 3, 0, 4)
res_dec_self_attention_weight_shape = dec_self_attention_weights.shape
res_dec_inter_attention_weight_shape = dec_inter_attention_weights.shape
print('res_dec_self_attention_weight_shape:',res_dec_self_attention_weight_shape)
print('res_dec_inter_attention_weight_shape:',res_dec_inter_attention_weight_shape)
由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
plt_show.show()
与编码器的自注意力的情况类似,通过指定输入序列的有效长度, 输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))
plt_show.show()
相关文章:
【动手学深度学习-Pytorch版】Transformer代码总结
本文是纯纯的撸代码讲解,没有任何Transformer的基础内容~ 是从0榨干Transformer代码系列,借用的是李沐老师上课时讲解的代码。 本文是根据每个模块的实现过程来进行讲解的。如果您想获取关于Transformer具体的实现细节(不含代码)可…...

做外贸独立站选Shopify还是WordPress?
现在确实会有很多新人想做独立站,毕竟跨境电商平台内卷严重,平台规则限制不断升级,脱离平台“绑架”布局独立站,才能获得更多流量、订单、塑造品牌价值。然而,在选择建立外贸独立站的过程中,选择适合的建站…...

echarts的bug,在series里写tooltip,不起作用,要在全局先写tooltip:{}才起作用,如果在series里写的不起作用就写到全局里
echarts的bug,在series里写tooltip,不起作用,要在全局先写tooltip:{show:true}才起作用,如果在series里写的不起作用就写到全局里 series里写tooltip不起作用,鼠标悬浮在echarts图表上时不显示提示 你需要…...

jmeter分布式压测
一、什么是压力测试? 压力测试(Stress Test),也称为强度测试、负载测试,属于性能测试的范畴。 压力测试是模拟实际应用的软硬件环境及用户使用过程的系统负荷,长时间或超大负荷地运行被测软件系统ÿ…...

consulmanage部署
一、部署consul 使用yum方式部署consul yum install -y yum-utils yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo yum -y install consul 执行以下命令获取uuid密钥并记录下来 uuidgen 编辑consul配置文件 vi /etc/consul.d/consul.h…...
大数据软件项目的验收流程
大数据软件项目的验收流程是确保项目交付符合预期需求和质量标准的关键步骤。以下是一般的大数据软件项目验收流程,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.项目验收计划制定: 在…...

《第一行代码Andorid》阅读笔记-第一章
这篇文章是我自己的《第一行代码Andorid》的阅读笔记,虽然大量参考了别人已经写好的一些笔记和代码但是也有自己的提炼和新的问题在里面,我也会放上参考文章链接。 学习重点 Android系统的四大组件: (1)活动ÿ…...
(VP))
Educational Codeforces Round 146 (Rated for Div. 2)(VP)
写个题解 A. Coins void solve(){ll n, k; cin >> n >> k;bl ok true;if (n &1 && k %2 0) ok false;print(ok ? yes : no); } B. Long Legs void solve(){db x, y; cin >> x >> y;if (x < y) swap(x, y);int t1 ceil(sqrt(x))…...

9.30国庆
消息队列完成进程间通信 #include <myhead.h>#define size sizeof(msg_ds)-sizeof(long) //正文大小//消息结构体 typedef struct {long msgtype; //消息类型char data[1024]; //消息正文 }msg_ds;//创建子线程构造体 void *task1(void *arg) {//创造第二个key值ke…...
java基础-第4章-面向对象(二)
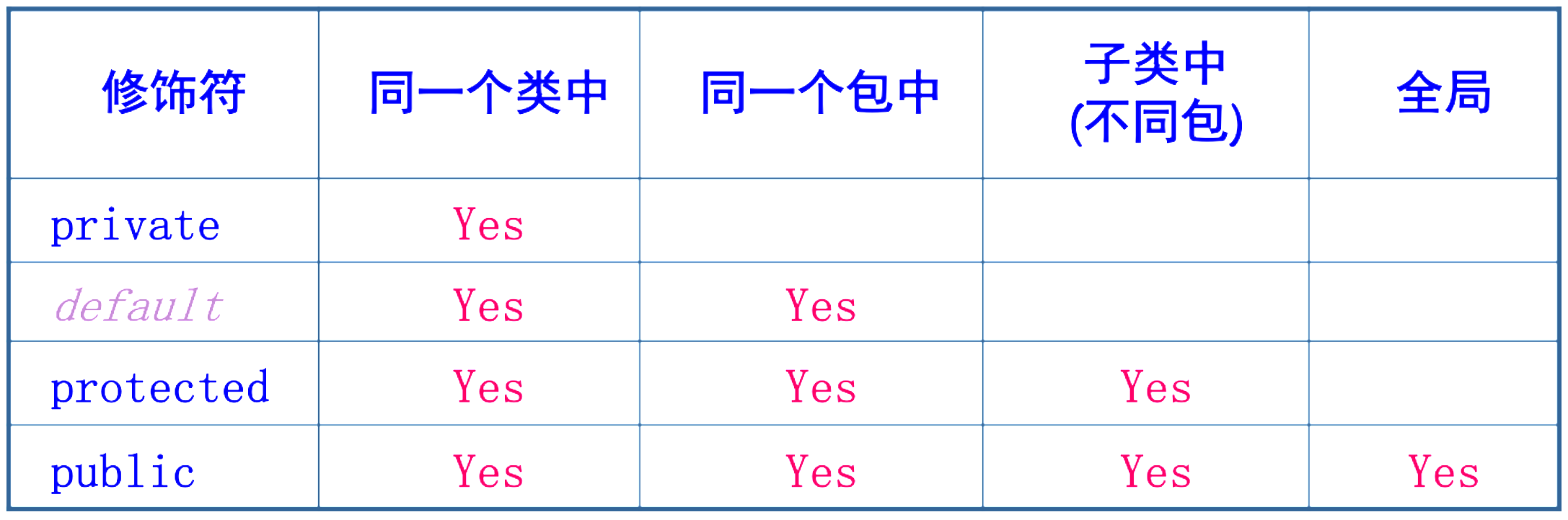
一、static关键字 静态(static)可以修饰属性和方法。 称为静态属性(类属性)、静态方法(类方法)。 静态成员是全类所有对象共享的成员。 在全类中只有一份,不因创建多个对象而产生多份。 不必创…...

flex加 grid 布局笔记
<style> .flex-container { display: flex; height: 100%; /* 设置容器的高度 */ } .wide { display: flex; padding: 10px; border: 1px solid lightgray; text-align: center; justify-content: …...

最高评级!华为云CodeArts Board获信通院软件研发效能度量平台先进级认证
9月26日,华为云CodeArts Board获得了中国信通院《云上软件研发效能度量分级模型》的先进级最高级评估,达到了软件研发效能度量平台评估的通用效能度量能力、组织效能模型、项目效能模型、资源效能模型、个人效能模型、研发效能评价模型、项目管理域、开发…...

图像上传功能实现
一、后端 文件存放在images.path路径下 package com.like.common;import jakarta.servlet.ServletOutputStream; import jakarta.servlet.http.HttpServletResponse; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annot…...
03_Node.js模块化开发
1 Node.js的基本使用 1.1 NPM nodejs安装完成后,会跟随着自动安装另外一个工具npm。 NPM的全称是Node Package Manager,是一个NodeJS包管理和分发工具,已经成为了非官方的发布Node模块(包)的标准。 2020年3月17日&…...

Nginx支持SNI证书,已经ssl_server_name的使用
整理了一些网上的资料,这里记录一下,供大家参考 什么是SNI? 传统的应用场景中,一台服务器对应一个IP地址,一个域名,使用一张包含了域名信息的证书。随着云计算技术的普及,在云中的虚拟机有了一…...
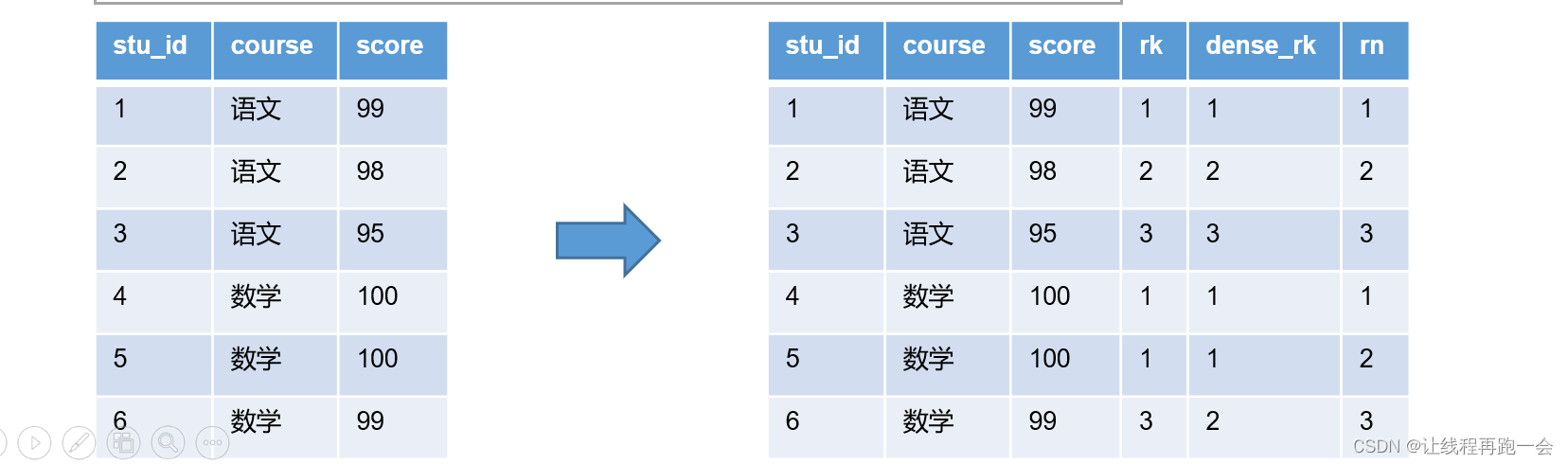
Hive【Hive(六)窗口函数】
窗口函数(window functions) 概述 定义 窗口函数能够为每行数据划分 一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。 语法 窗口函数的语法主要包括 窗口 和 函数 两个部分。其中窗口用于定义计算范围…...
Met no ‘TRANSLATIONS’ entry in project
这里写自定义目录标题 问题描述:解决方法: 问题描述: 多工程项目,执行完update Translation生成了.ts文件,也用翻译工具翻译完了,执行release时,报错“Met no ‘TRANSLATIONS’ entry in proje…...
Leetcode901-股票价格跨度
一、前言 本题基于leetcode901股票价格趋势这道题,说一下通过java解决的一些方法。并且解释一下笔者写这道题之前的想法和一些自己遇到的错误。需要注意的是,该题最多调用 next 方法 10^4 次,一般出现该提示说明需要注意时间复杂度。 二、解决思路 ①…...
“传统文化宣传片+虚拟人动捕设备”前景如何?
在数字化时代的发展下,动捕设备的加入,让传播传统文化的虚拟人更具生动表现,拉近人们与传统文化的距离,通过虚拟人动作捕捉动画宣传片,引起更多人对传统文化的关注与传承。 *图片源于网络 深圳文博会创意短片《嗨ICIF…...

节假日moc服务数据:解决用户99%的IT问题
Hi~ 伙伴们,这个国庆假期过得怎么样? 节后第一个工作日如期而至, 忙碌是消除倦怠的最佳良药。 回顾8天假日moc工程师的一组服务数据, 处理事件184起,工单23条。 其中,较为典型案例如下: 1、福建某附属医院…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...