Spark基础
一、spark基础

1、为什么使用Spark
Ⅰ、MapReduce编程模型的局限性
(1) 繁杂
只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
(2) 处理效率低
Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据 任务调度与启动开销大
(3) 不适合迭代处理、交互式处理和流式处理
Ⅱ、Spark是类Hadoop MapReduce的通用并行框架
(1) Job中间输出结果可以保存在内存,不再需要读写HDFS
(2) 比MapReduce平均快10倍以上
Ⅲ、Spark VS Hadoop
| Hadoop | Spark | |
| 类型 | 分布式基础平台,包含计算、存储、调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算、交互式计算、流计算 |
| 价格 | 对机器要求低,便宜 | 对内存有要求,相对较贵 |
| 编程范式 | Map+Reduce,API较为底层,算法适应性差 | RDD组成DAG有向无环图,API较为顶层,方便使用 |
| 数据存储结构 | MpaReduce中间计算结果存在HDFS磁盘上,延迟大 | RDD中间运算结果存在内存中,延迟小 |
| 运行方式 | Task以进程方式维护,任务启动慢 | Task以线程方式维护,任务启动快 |
2、Spark简介
诞生于加州大学伯克利分校AMP实验室,是一个基于内存的分布式计算框架
发展历程:
2009年诞生于加州大学伯克利分校AMP实验室
2010年正式开源 2013年6月正式成为Apache孵化项目
2014年2月成为Apache顶级项目
2014年5月正式发布Spark 1.0版本
2014年10月Spark打破MapReduce保持的排序记录
2015年发布了1.3、1.4、1.5版本
2016年发布了1.6、2.x版本
......
Hadoop 之父 Doug Cutting 指出:
Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark
(大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
3、Spark优势
(1)速度快
基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上
(2)易用性
支持Java、Scala、Python、R语言 交互式shell方便开发测试
(3)通用性
一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
(4)多种运行模式
YARN、Mesos、EC2、Kubernetes、Standalone、Local
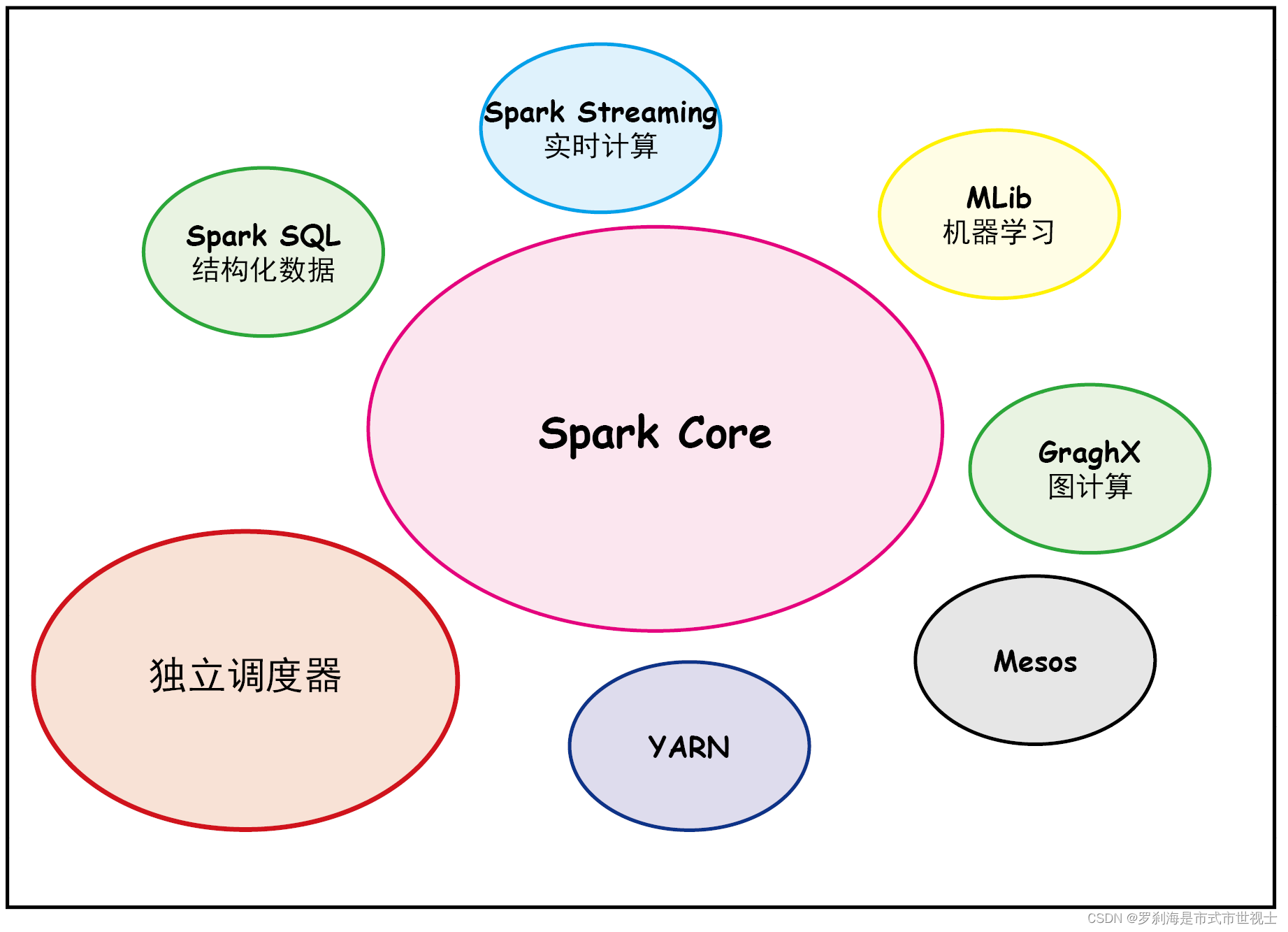
4、Spark技术栈
(1)Spark Core
核心组件,分布式计算引擎。
实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
(2)Spark SQL
高性能的基于Hadoop的SQL解决方案。
Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
(3)Spark Streaming
可以实现高吞吐量、具备容错机制的准实时流处理系统。
Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
(4)Spark GraphX(图计算)
分布式图处理框架。
Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
(5)Spark MLlib
构建在Spark上的分布式机器学习库。
提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
(6)其他
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
二、安装spark
spark下载地址https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
1、通过Xftp上传文件

2、解压文件至指定的安装目录
tar -zxvf /opt/install/scala-2.12.10.tgz -C /opt/soft/
tar -zxvf /opt/install/spark-3.1.2-bin-hadoop3.2.tgz -C /opt/soft/
3、进入安装目录更改名字
mv ./scala-2.12.10.tgz ./scala212
mv ./spark-3.1.2-bin-hadoop3.2.tgz ./spark3124、配置环境变量
#SCALA
export SCALA_HOME=/opt/soft/scala212
export PATH=$SCALA_HOME/bin:$PATH
#SPARK
export SPARK_HOME=/opt/soft/spark312
export PATH=$SPARK_HOME/bin:$PATH
!!! source /etc/profile
5、启动Scala
6、Spark环境部署
(1)进入/opt/soft/spark312/conf拷贝文件
cp ./workers.template ./workers
cp ./spark-env.sh.template ./spark-env.sh
(2)配置workers
# 编辑文件
vim workers
# 配置文件
localhost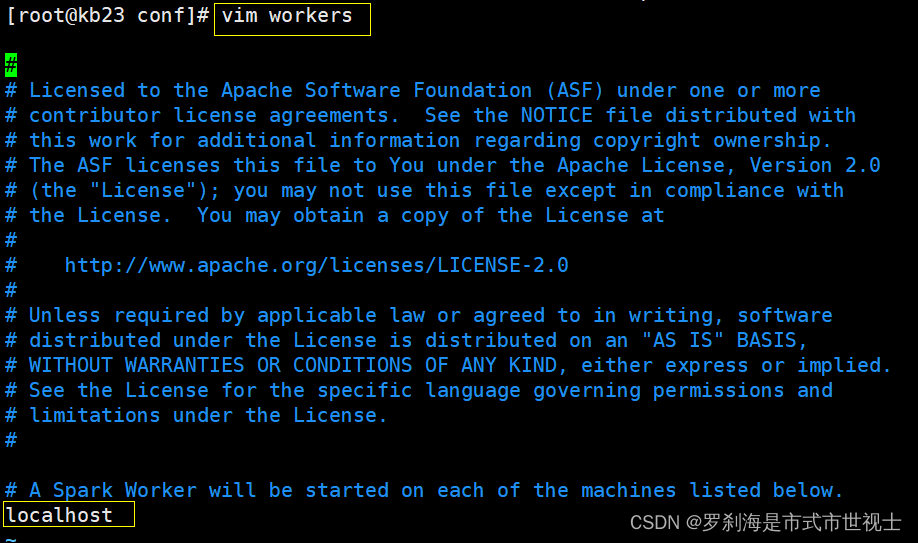
(3)配置spark-env.sh
# 编辑文件
vim ./spark-env.sh
# 配置文件
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=192.168.91.11
export SPARK_DRIVER_MEMORY=2G
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312
# 保存退出
:wq
# 刷新
source
7、启动交互式平台
spark-shell8、Spark运行模式
(1)local 本地模式(单机)
学习测试使用,分为local单线程和local-cluster多线程。
(2)standalone 独立集群模式
学习测试使用,典型的Master/slave。
(3)standalone-HA 高可用模式
生产环境使用,基于standalone模式,使用zk搭建高可用,避免Master是有单点故障的。
(4)on yarn 集群模式
生产环境使用,运行在yarn负责资源管理,Spark负责任务调度和计算。
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
(5)on mesos 集群模式
国内使用较少,运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算。
(6)on cloud 集群模式
中小型公司未来会更多的使用云服务,比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3。
相关文章:
Spark基础
一、spark基础 1、为什么使用Spark Ⅰ、MapReduce编程模型的局限性 (1) 繁杂 只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码 (2) 处理效率低 Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据 任务调度与启动开销大 (…...
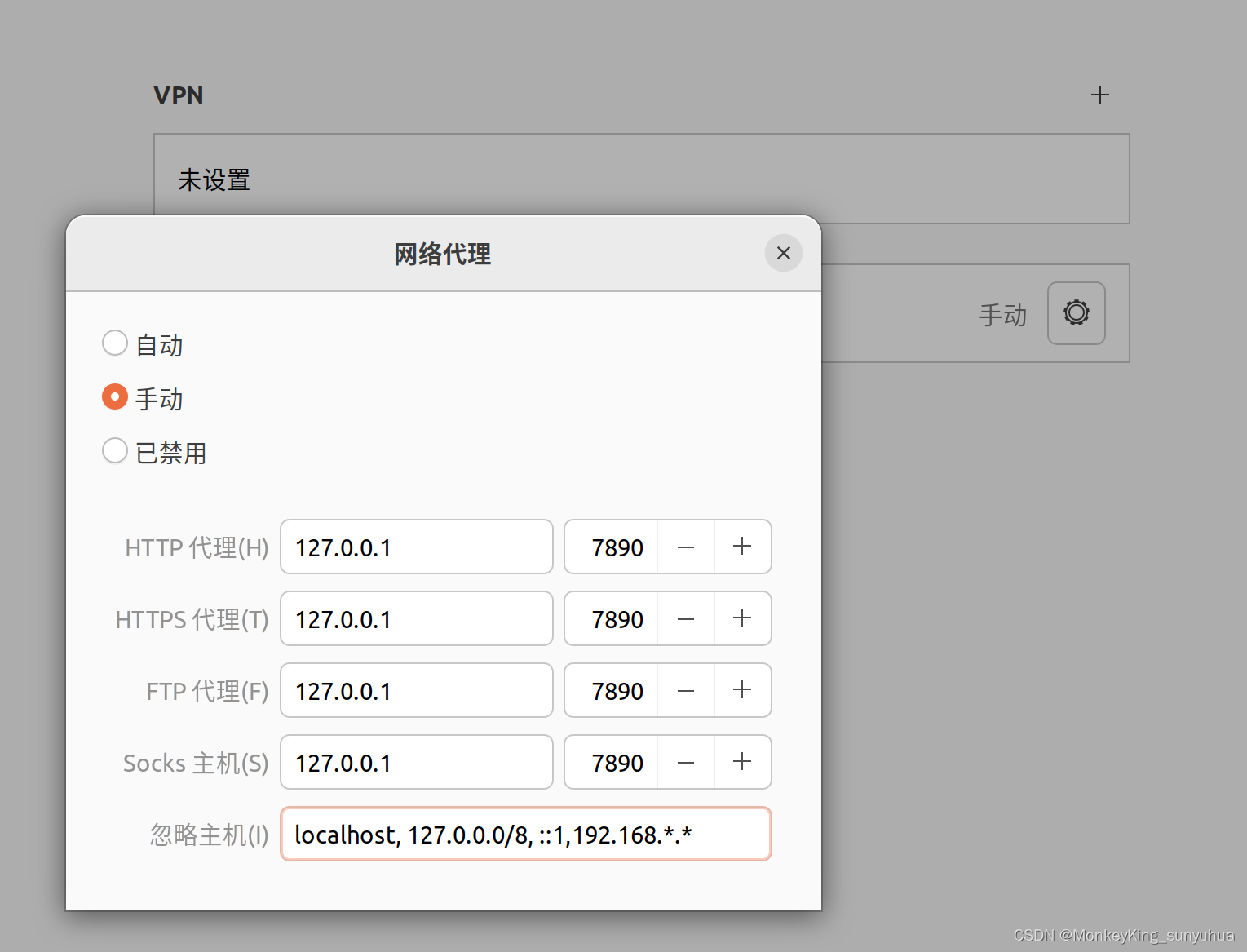
localhost和127.0.0.1都可以访问项目,但是本地的外网IP不能访问
使用localhost和127.0.0.1都可以访问接口,比如: http://localhost:8080/zhgl/login/login-fy-list或者 http://127.0.0.1:8080/zhgl/login/login-fy-list返回json {"_code":10000,"_msg":"Success","_data":…...
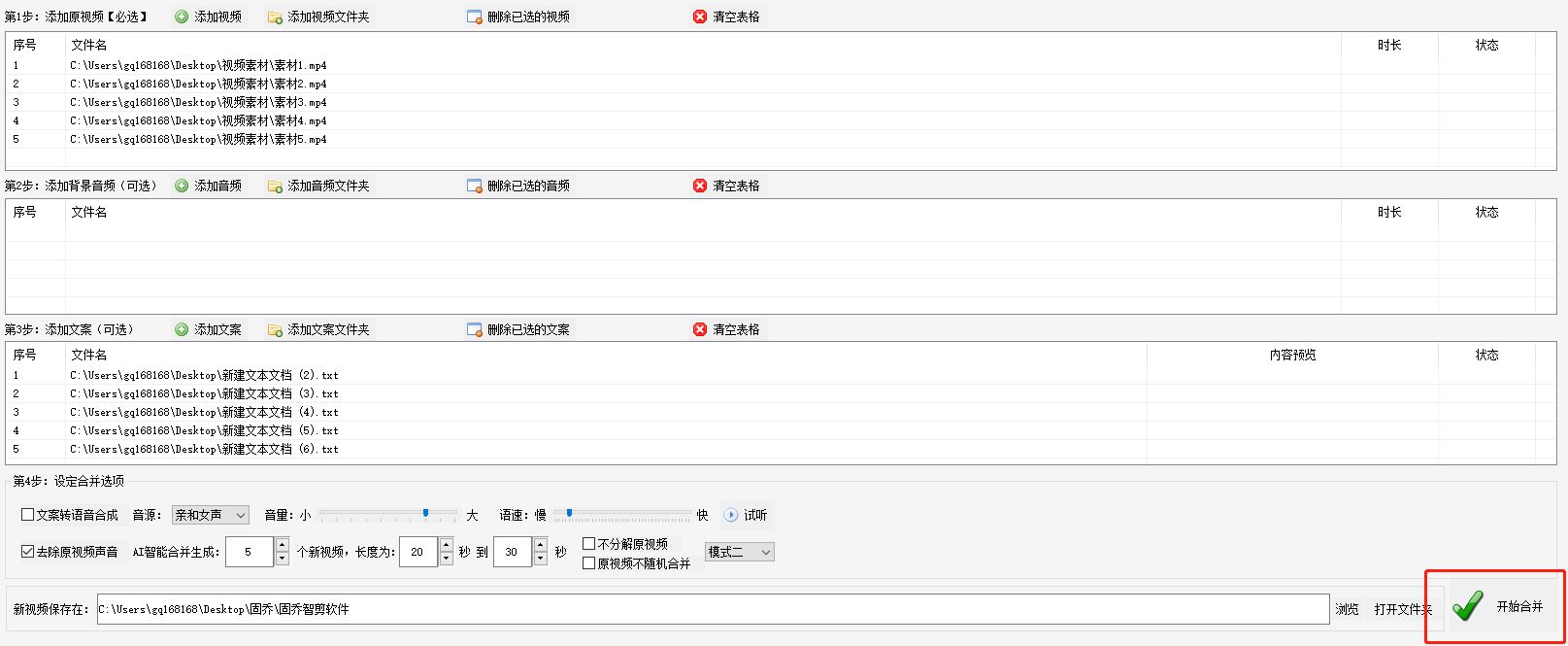
快速掌握批量合并视频
在日常的工作和生活中,我们经常需要对视频进行编辑和处理,而合并视频、添加文案和音频是其中常见的操作。如何快速而简便地完成这些任务呢?今天我们介绍一款强大的视频编辑软件——“固乔智剪软件”,它可以帮助我们轻松实现批量合…...
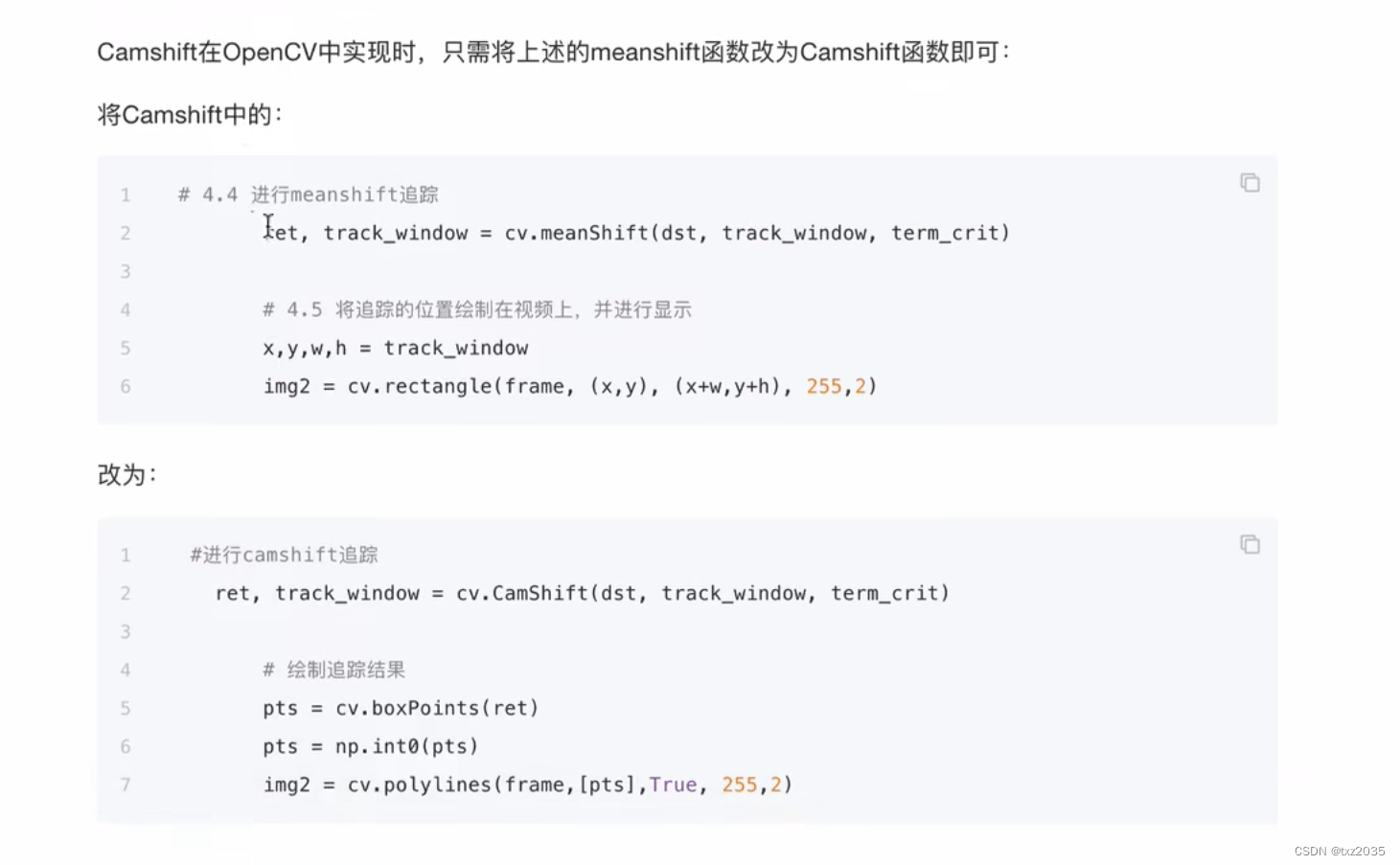
OpenCV利用Camshift实现目标追踪
目录 原理 做法 代码实现 结果展示 原理 做法 代码实现 import numpy as np import cv2 as cv# 读取视频 cap cv.VideoCapture(video.mp4)# 检查视频是否成功打开 if not cap.isOpened():print("Error: Cannot open video file.")exit()# 获取第一帧图像&#x…...

使用pywin32读取doc文档的方法及run输出乱码 \r\x07
想写一个读取doc文档中表格数据,来对文档进行重命名。经查资料,py-docx无法读取doc文档,原因是这种是旧格式。所以,采用pywin32来进行读取。 import win32com.client as win32word win32.gencache.EnsureDispatch(Word.Applicati…...

一天一八股——TCP保活keepalive和HTTP的Keep-Alive
TCP属于传输层,关于TCP的设置在内核态完成 HTTP属于用户层的协议,主要用于web服务器和浏览器之间的 http的Keep-Alive都是为了减少多次建立tcp连接采用的保持长连接的机制,而tcp的keepalive是为了保证已经建立的tcp连接依旧可用(双端依旧可以…...

头部品牌停业整顿,鲜花电商的中场战事迎来拐点?
鲜花电商行业再次迎来标志性事件,曾经4年接连斩获6轮融资的明星品牌花加,正式宣布停业整顿。 梳理来看,2015年是鲜花电商赛道的发展爆发期,彼时花加等品牌相继成立,并掀起一波投资热潮,据媒体统计…...
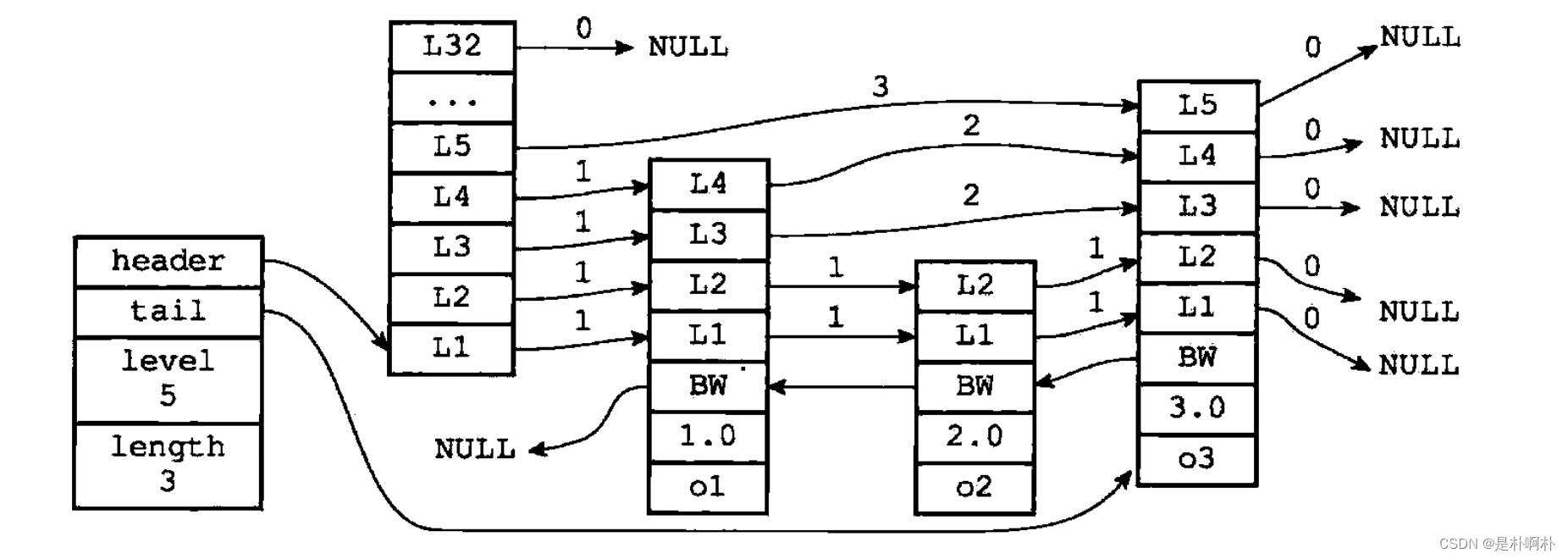
深入解读redis的zset和跳表【源码分析】
1.基本指令 部分指令,涉及到第4章的api,没有具体看实现,但是逻辑应该差不多。 zadd <key><score1><value1><score2><value2>... 将一个或多个member元素及其score值加入到有序集key当中。根据zslInsert zran…...
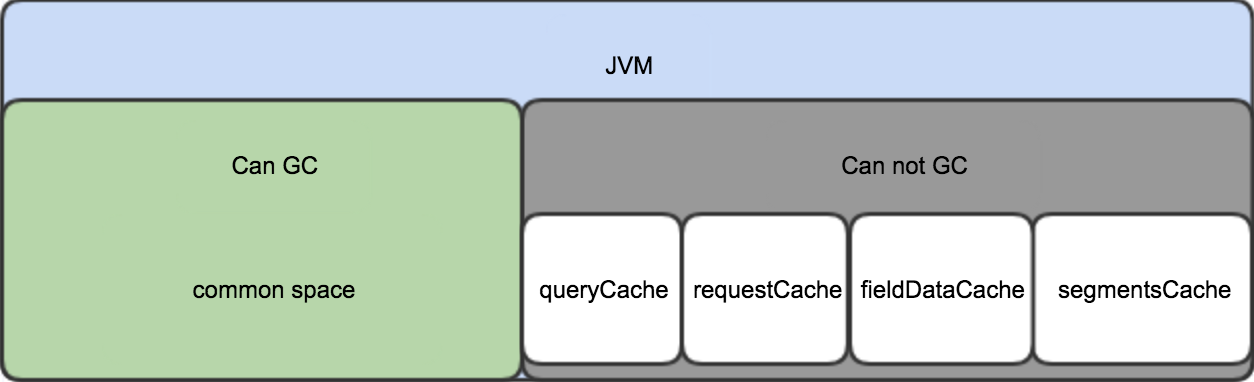
elasticsearch内存占用详细分析
内存占用 ES的JVM heap按使用场景分为可GC部分和常驻部分。 可GC部分内存会随着GC操作而被回收; 常驻部分不会被GC,通常使用LRU策略来进行淘汰; 内存占用情况如下图: common space 包括了indexing buffer和其他ES运行需要的clas…...

【研究生学术英语读写教程翻译 中国科学院大学Unit3】
研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit5 Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见由于csdn专栏机制修改,请想获取资料的同学移步b站工房,感谢大家支持!研究生学术英语读写教程翻译 中国科学院大学…...
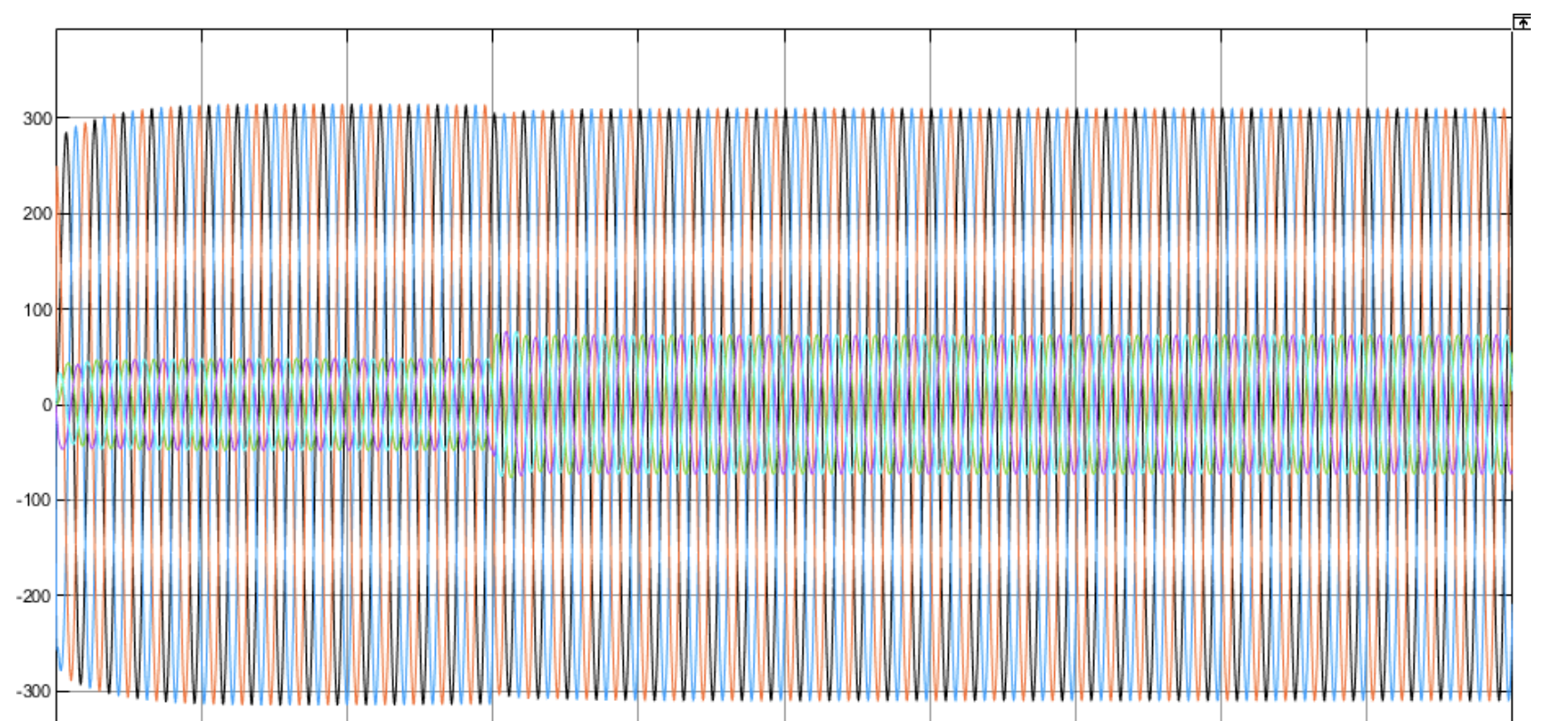
基于虚拟同步发电机控制的双机并联Simulink仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微信小程序开发——自定义堆叠图
先看效果图 点击第一张图片实现折叠,再次点击实现展开 思路 图片容器绑定点击事件获取当前图片索引,触发onTap函数,根据索引判断当前点击的图片是否为第一张,并根据当前的折叠状态来更新每张图片的位置,注意图片向上…...

国庆day5
QT实现TCP服务器客户端搭建的代码 ser.h #ifndef SER_H #define SER_H#include <QWidget> #include<QTcpServer> #include<QTcpSocket> #include<QMessageBox> #include<QList> QT_BEGIN_NAMESPACE namespace Ui { class …...

经典算法----迷宫问题(找出所有路径)
目录 前言 问题描述 算法思路 定义方向 回溯算法 代码实现 前言 前面我发布了一篇关于迷宫问题的解决方法,是通过栈的方式来解决这个问题的(链接:经典算法-----迷宫问题(栈的应用)-CSDN博客)ÿ…...

macOS下 /etc/hosts 文件权限问题修复方案
文章目录 前言解决方案权限验证 macOS下 etc/hosts 文件权限问题修复 前言 当在 macOS 上使用 vi编辑 /etc/hosts 文件时发现出现 Permission Denied 的提示,就算在前面加上 sudo 也照样出现一样的提示,解决方案如下; 解决方案 可以尝试使用如下命令尝试解除锁定; sudo chf…...
 playbook)
【星海出品】ansible入门(二) playbook
核心是管理配置进行批量节点部署。 执行其中的一些列tasks。 playbook由YAML语言编写。 YAML的格式如下: 文件名应该以 .yml 结尾 1.文件的第一行应该以“—”(三个连字符)开始,表明YAML文件的开始。 2.在同一行中,#之…...

Spring Boot对账号密码进行加密储存
未来避免明文硬编码,我们需要对密码进行加密保存,例如账号密码 方法 在Spring Boot中,可以使用Jasypt(Java Simplified Encryption)库来对敏感信息进行加密和解密。Jasypt提供了一种简单的方式来在应用程序中使用加密…...

总结js中常见的层次选择器
js中的层次选择器可以用于选择和操作DOM树中的元素,根据元素的层级关系进行选择。以下是js中常见的层次选择器: 1. getElementById:使用元素的ID属性进行选择。通过给元素设置唯一的ID属性,可以使用getElementById方法选择该元素…...
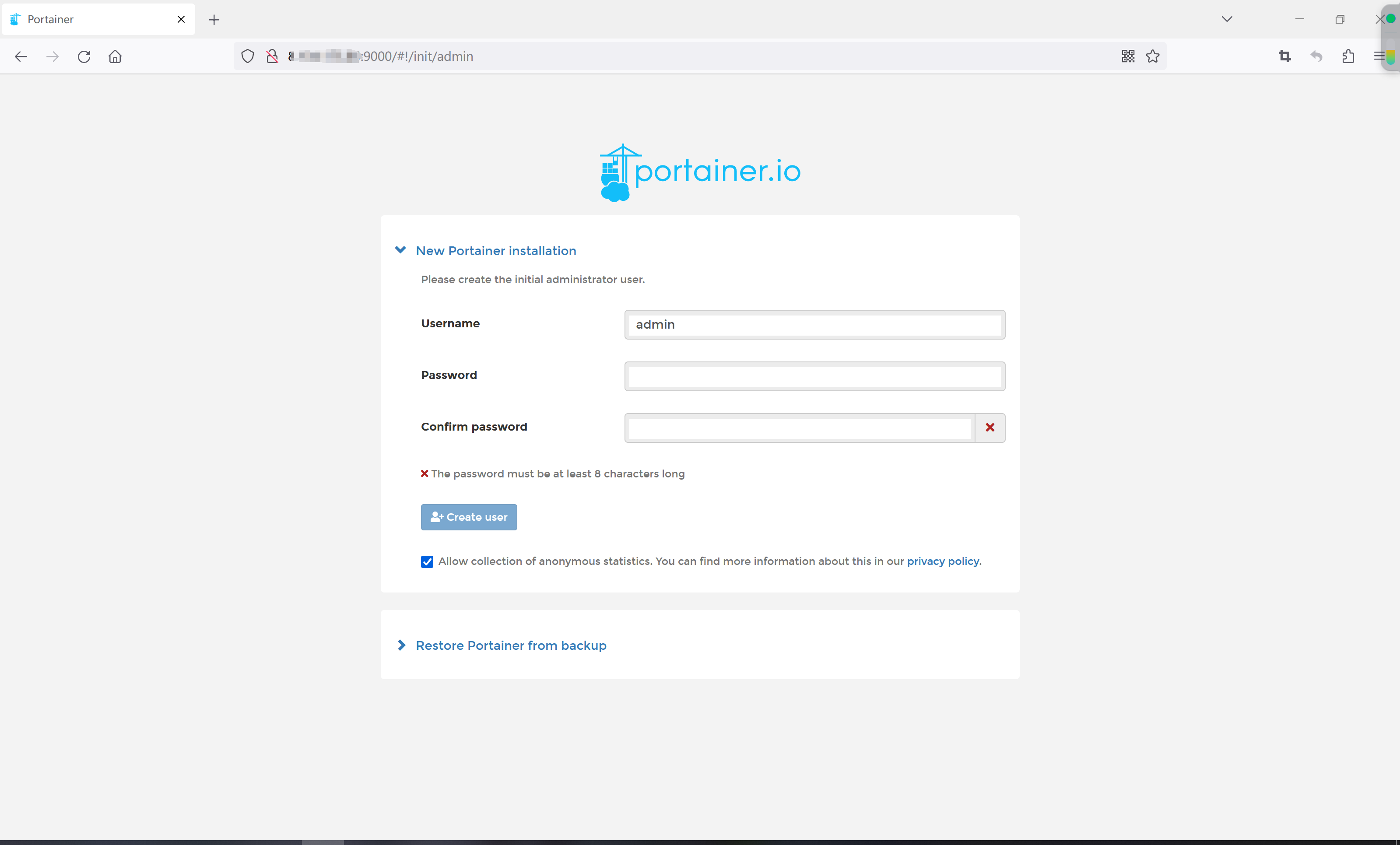
阿里云ECS服务器上启动的portainer无法访问的问题
如下图,在阿里云ECS服务器上安装并启动了portainer,但是在自己电脑上访问不了远程的portainer。 最后发现是要在网络安全组里开放9000端口号,具体操作如下: 在云服务器管理控制台点击左侧菜单中的网络与安全-安全组,然…...

JavaScript系列从入门到精通系列第十八篇:JavaScript中的函数作用域
文章目录 前言 一:函数作用域 前言 我们刚才提到了,在<Script>标签当中进行定义的变量、对象、函数对象都属于全局作用域,全局作用域在页面打开的时候生效在页面关闭的时候失效。 一:函数作用域 调用函数时创建函数作用域…...

2025届必备的六大AI辅助写作平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 进行学术写作以及内容创作之际,使文本的AI生成痕迹得以降低,这是提升…...

macos简单配置openclaw贝
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

两条根本不同的道路:私有化部署与SaaS模式的抉择
很多企业在选型内部通讯工具时,面对的第一个问题往往是:选SaaS还是选私有化?这不是一个简单的技术偏好问题,而是一个关乎企业数据战略、安全治理与长期发展的核心决策。在“云优先”的浪潮下,公有云SaaS产品凭借开箱即…...

美团李树斌:餐饮评价资产最重要的不是多,而是“真实反映你是谁”
4月8日,美团高级副总裁李树斌在2026中国餐饮连锁峰会上表示,用户决策方式正在变化,变得更谨慎、看得更细、更信“新鲜的声音”,餐饮行业随之进入“信任竞争”时代,“真实口碑”成为长期资产。他认为,“口碑…...

HagiCode 为什么选择 Hermes 作为综合 Agent 核心一
1. 哑铃图是什么? 哑铃图(Dumbbell Plot),有时也称为DNA图或杠铃图,是一种用于比较两个相关数据点的可视化图表。 它源于人们对更有效数据比较方式的持续探索。 在传统的时间序列比较中,我们通常使用两条折…...

告别理想模型!手把手教你用ADS导入村田DesignKits,让仿真贴近真实PCB
告别理想模型!手把手教你用ADS导入村田DesignKits,让仿真贴近真实PCB 射频工程师小张最近遇到了一个棘手的问题:他在ADS中精心设计的低通滤波器,仿真结果完美符合指标,但实际打板测试时性能却大打折扣。这个困扰无数硬…...

自动驾驶模仿学习避坑指南:为什么你的多模态融合模型总在十字路口“翻车”?
自动驾驶多模态融合的十字路口困境:从特征拼接走向全局理解的工程实践 当你的自动驾驶模型在封闭测试场地表现优异,却在无保护左转和行人突然穿行的复杂路口频繁"翻车"时,问题往往不在于单个传感器的精度,而在于那些看似…...
✅)
计算机毕业设计:Python全国气象数据采集与可视化平台 Flask框架 可视化 数据分析 机器学习 天气 深度学习 AI 空气质量分析(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...
)
Python AOT编译正式落地2026:3步完成插件下载、5分钟完成生产级安装(附官方校验码)
第一章:Python AOT编译正式落地2026:里程碑意义与核心价值2026年3月,CPython官方宣布Python 3.14版本原生支持AOT(Ahead-of-Time)编译模式,标志着Python首次在标准发行版中实现无需第三方运行时干预的静态可…...

STM32F103C8T6:基于蓝牙指令的舵机角度精确控制
1. 项目背景与应用场景 想象一下这样的场景:早晨醒来,你躺在床上一键遥控窗帘缓缓打开到45度角,让阳光刚好洒在床脚;或者通过手机APP远程调节摄像头云台,让监控视角精确对准门口快递柜。这些看似简单的智能家居功能&am…...