接口自动化测试框架(pytest+allure+aiohttp+ 用例自动生成)
近期准备优先做接口测试的覆盖,为此需要开发一个测试框架,经过思考,这次依然想做点儿不一样的东西。
- 接口测试是比较讲究效率的,测试人员会希望很快能得到结果反馈,然而接口的数量一般都很多,而且会越来越多,所以提高执行效率很有必要
- 接口测试的用例其实也可以用来兼做简单的压力测试,而压力测试需要并发
- 接口测试的用例有很多重复的东西,测试人员应该只需要关注接口测试的设计,这些重复劳动最好自动化来做
- pytest和allure太好用了,新框架要集成它们
- 接口测试的用例应该尽量简洁,最好用yaml,这样数据能直接映射为请求数据,写起用例来跟做填空题一样,便于向没有自动化经验的成员推广 加上我对Python的协程很感兴趣,也学了一段时间,一直希望学以致用,所以http请求我决定用aiohttp来实现。 但是pytest是不支持事件循环的,如果想把它们结合还需要一番功夫。于是继续思考,思考的结果是其实我可以把整个事情分为两部分。 第一部分,读取yaml测试用例,http请求测试接口,收集测试数据。 第二部分,根据测试数据,动态生成pytest认可的测试用例,然后执行,生成测试报告。 这样一来,两者就能完美结合了,也完美符合我所做的设想。想法既定,接着 就是实现了。
第一部分(整个过程都要求是异步非阻塞的)
读取yaml测试用例
一份简单的用例模板我是这样设计的,这样的好处是,参数名和aiohttp.ClientSession().request(method,url,**kwargs)是直接对应上的,我可以不费力气的直接传给请求方法,避免各种转换,简洁优雅,表达力又强。
args:- post- /xxx/add
kwargs:-caseName: 新增xxxdata:name: ${gen_uid(10)}
validator:-json:successed: True
异步读取文件可以使用aiofiles这个第三方库,yaml_load是一个协程,可以保证主进程读取yaml测试用例时不被阻塞,通过await yaml_load()便能获取测试用例的数据
async def yaml_load(dir='', file=''):"""异步读取yaml文件,并转义其中的特殊值:param file::return:"""if dir:file = os.path.join(dir, file)async with aiofiles.open(file, 'r', encoding='utf-8', errors='ignore') as f:data = await f.read()data = yaml.load(data)# 匹配函数调用形式的语法pattern_function = re.compile(r'^\${([A-Za-z_]+\w*\(.*\))}$')pattern_function2 = re.compile(r'^\${(.*)}$')# 匹配取默认值的语法pattern_function3 = re.compile(r'^\$\((.*)\)$')def my_iter(data):"""递归测试用例,根据不同数据类型做相应处理,将模板语法转化为正常值:param data::return:"""if isinstance(data, (list, tuple)):for index, _data in enumerate(data):data[index] = my_iter(_data) or _dataelif isinstance(data, dict):for k, v in data.items():data[k] = my_iter(v) or velif isinstance(data, (str, bytes)):m = pattern_function.match(data)if not m:m = pattern_function2.match(data)if m:return eval(m.group(1))if not m:m = pattern_function3.match(data)if m:K, k = m.group(1).split(':')return bxmat.default_values.get(K).get(k)return datamy_iter(data)return BXMDict(data)
可以看到,测试用例还支持一定的模板语法,如${function}、$(a:b)等,这能在很大程度上拓展测试人员用例编写的能力
http请求测试接口
http请求可以直接用aiohttp.ClientSession().request(method,url,**kwargs),http也是一个协程,可以保证网络请求时不被阻塞,通过await http()便可以拿到接口测试数据
async def http(domain, *args, **kwargs):"""http请求处理器:param domain: 服务地址:param args::param kwargs::return:"""method, api = argsarguments = kwargs.get('data') or kwargs.get('params') or kwargs.get('json') or {}# kwargs中加入tokenkwargs.setdefault('headers', {}).update({'token': bxmat.token})# 拼接服务地址和apiurl = ''.join([domain, api])async with ClientSession() as session:async with session.request(method, url, **kwargs) as response:res = await response_handler(response)return {'response': res,'url': url,'arguments': arguments}
收集测试数据
协程的并发真的很快,这里为了避免服务响应不过来导致熔断,可以引入asyncio.Semaphore(num)来控制并发
async def entrace(test_cases, loop, semaphore=None):"""http执行入口:param test_cases::param semaphore::return:"""res = BXMDict()# 在CookieJar的update_cookies方法中,如果unsafe=False并且访问的是IP地址,客户端是不会更新cookie信息# 这就导致session不能正确处理登录态的问题# 所以这里使用的cookie_jar参数使用手动生成的CookieJar对象,并将其unsafe设置为Trueasync with ClientSession(loop=loop, cookie_jar=CookieJar(unsafe=True), headers={'token': bxmat.token}) as session:await advertise_cms_login(session)if semaphore:async with semaphore:for test_case in test_cases:data = await one(session, case_name=test_case)res.setdefault(data.pop('case_dir'), BXMList()).append(data)else:for test_case in test_cases:data = await one(session, case_name=test_case)res.setdefault(data.pop('case_dir'), BXMList()).append(data)return resasync def one(session, case_dir='', case_name=''):"""一份测试用例执行的全过程,包括读取.yml测试用例,执行http请求,返回请求结果所有操作都是异步非阻塞的:param session: session会话:param case_dir: 用例目录:param case_name: 用例名称:return:"""project_name = case_name.split(os.sep)[1]domain = bxmat.url.get(project_name)test_data = await yaml_load(dir=case_dir, file=case_name)result = BXMDict({'case_dir': os.path.dirname(case_name),'api': test_data.args[1].replace('/', '_'),})if isinstance(test_data.kwargs, list):for index, each_data in enumerate(test_data.kwargs):step_name = each_data.pop('caseName')r = await http(session, domain, *test_data.args, **each_data)r.update({'case_name': step_name})result.setdefault('responses', BXMList()).append({'response': r,'validator': test_data.validator[index]})else:step_name = test_data.kwargs.pop('caseName')r = await http(session, domain, *test_data.args, **test_data.kwargs)r.update({'case_name': step_name})result.setdefault('responses', BXMList()).append({'response': r,'validator': test_data.validator})return result
事件循环负责执行协程并返回结果,在最后的结果收集中,我用测试用例目录来对结果进行了分类,这为接下来的自动生成pytest认可的测试用例打下了良好的基础
def main(test_cases):"""事件循环主函数,负责所有接口请求的执行:param test_cases::return:"""loop = asyncio.get_event_loop()semaphore = asyncio.Semaphore(bxmat.semaphore)# 需要处理的任务# tasks = [asyncio.ensure_future(one(case_name=test_case, semaphore=semaphore)) for test_case in test_cases]task = loop.create_task(entrace(test_cases, loop, semaphore))# 将协程注册到事件循环,并启动事件循环try:# loop.run_until_complete(asyncio.gather(*tasks))loop.run_until_complete(task)finally:loop.close()return task.result()
第二部分
动态生成pytest认可的测试用例
首先说明下pytest的运行机制,pytest首先会在当前目录下找conftest.py文件,如果找到了,则先运行它,然后根据命令行参数去指定的目录下找test开头或结尾的.py文件,如果找到了,如果找到了,再分析fixture,如果有session或module类型的,并且参数autotest=True或标记了pytest.mark.usefixtures(a...),则先运行它们;再去依次找类、方法等,规则类似。大概就是这样一个过程。
可以看出,pytest测试运行起来的关键是,必须有至少一个被pytest发现机制认可的testxx.py文件,文件中有TestxxClass类,类中至少有一个def testxx(self)方法。
现在并没有任何pytest认可的测试文件,所以我的想法是先创建一个引导型的测试文件,它负责让pytest动起来。可以用pytest.skip()让其中的测试方法跳过。然后我们的目标是在pytest动起来之后,怎么动态生成用例,然后发现这些用例,执行这些用例,生成测试报告,一气呵成。
# test_bootstrap.py
import pytestclass TestStarter(object):def test_start(self):pytest.skip('此为测试启动方法, 不执行')
我想到的是通过fixture,因为fixture有setup的能力,这样我通过定义一个scope为session的fixture,然后在TestStarter上面标记use,就可以在导入TestStarter之前预先处理一些事情,那么我把生成用例的操作放在这个fixture里就能完成目标了。
# test_bootstrap.py
import pytest@pytest.mark.usefixtures('te', 'test_cases')
class TestStarter(object):def test_start(self):pytest.skip('此为测试启动方法, 不执行')
pytest有个--rootdir参数,该fixture的核心目的就是,通过--rootdir获取到目标目录,找出里面的.yml测试文件,运行后获得测试数据,然后为每个目录创建一份testxx.py的测试文件,文件内容就是content变量的内容,然后把这些参数再传给pytest.main()方法执行测试用例的测试,也就是在pytest内部再运行了一个pytest!最后把生成的测试文件删除。注意该fixture要定义在conftest.py里面,因为pytest对于conftest中定义的内容有自发现能力,不需要额外导入。
# conftest.py
@pytest.fixture(scope='session')
def test_cases(request):"""测试用例生成处理:param request::return:"""var = request.config.getoption("--rootdir")test_file = request.config.getoption("--tf")env = request.config.getoption("--te")cases = []if test_file:cases = [test_file]else:if os.path.isdir(var):for root, dirs, files in os.walk(var):if re.match(r'\w+', root):if files:cases.extend([os.path.join(root, file) for file in files if file.endswith('yml')])data = main(cases)content = """
import allurefrom conftest import CaseMetaClass@allure.feature('{}接口测试({}项目)')
class Test{}API(object, metaclass=CaseMetaClass):test_cases_data = {}
"""test_cases_files = []if os.path.isdir(var):for root, dirs, files in os.walk(var):if not ('.' in root or '__' in root):if files:case_name = os.path.basename(root)project_name = os.path.basename(os.path.dirname(root))test_case_file = os.path.join(root, 'test_{}.py'.format(case_name))with open(test_case_file, 'w', encoding='utf-8') as fw:fw.write(content.format(case_name, project_name, case_name.title(), data.get(root)))test_cases_files.append(test_case_file)if test_file:temp = os.path.dirname(test_file)py_file = os.path.join(temp, 'test_{}.py'.format(os.path.basename(temp)))else:py_file = varpytest.main(['-v',py_file,'--alluredir','report','--te',env,'--capture','no','--disable-warnings',])for file in test_cases_files:os.remove(file)return test_cases_files
可以看到,测试文件中有一个TestxxAPI的类,它只有一个test_cases_data属性,并没有testxx方法,所以还不是被pytest认可的测试用例,根本运行不起来。那么它是怎么解决这个问题的呢?答案就是CaseMetaClass。
function_express = """
def {}(self, response, validata):with allure.step(response.pop('case_name')):validator(response,validata)"""class CaseMetaClass(type):"""根据接口调用的结果自动生成测试用例"""def __new__(cls, name, bases, attrs):test_cases_data = attrs.pop('test_cases_data')for each in test_cases_data:api = each.pop('api')function_name = 'test' + apitest_data = [tuple(x.values()) for x in each.get('responses')]function = gen_function(function_express.format(function_name),namespace={'validator': validator, 'allure': allure})# 集成allurestory_function = allure.story('{}'.format(api.replace('_', '/')))(function)attrs[function_name] = pytest.mark.parametrize('response,validata', test_data)(story_function)return super().__new__(cls, name, bases, attrs)
CaseMetaClass是一个元类,它读取test_cases_data属性的内容,然后动态生成方法对象,每一个接口都是单独一个方法,在相继被allure的细粒度测试报告功能和pytest提供的参数化测试功能装饰后,把该方法对象赋值给test+api的类属性,也就是说,TestxxAPI在生成之后便有了若干testxx的方法,此时内部再运行起pytest,pytest也就能发现这些用例并执行了。
def gen_function(function_express, namespace={}):"""动态生成函数对象, 函数作用域默认设置为builtins.__dict__,并合并namespace的变量:param function_express: 函数表达式,示例 'def foobar(): return "foobar"':return:"""builtins.__dict__.update(namespace)module_code = compile(function_express, '', 'exec')function_code = [c for c in module_code.co_consts if isinstance(c, types.CodeType)][0]return types.FunctionType(function_code, builtins.__dict__)
在生成方法对象时要注意namespace的问题,最好默认传builtins.__dict__,然后自定义的方法通过namespace参数传进去。
后续(yml测试文件自动生成)
至此,框架的核心功能已经完成了,经过几个项目的实践,效果完全超过预期,写起用例来不要太爽,运行起来不要太快,测试报告也整的明明白白漂漂亮亮的,但我发现还是有些累,为什么呢?
我目前做接口测试的流程是,如果项目集成了swagger,通过swagger去获取接口信息,根据这些接口信息来手工起项目创建用例。这个过程很重复很繁琐,因为我们的用例模板已经大致固定了,其实用例之间就是一些参数比如目录、用例名称、method等等的区别,那么这个过程我觉得完全可以自动化。
因为swagger有个网页啊,我可以去提取关键信息来自动创建.yml测试文件,就像搭起架子一样,待项目架子生成后,我再去设计用例填传参就可以了。
于是我试着去解析请求swagger首页得到的HTML,然后失望的是并没有实际数据,后来猜想应该是用了ajax,打开浏览器控制台的时,我发现了api-docs的请求,一看果然是json数据,那么问题就简单了,网页分析都不用了。
import re
import os
import sysfrom requests import Sessiontemplate ="""
args:- {method}- {api}
kwargs:-caseName: {caseName}{data_or_params}:{data}
validator:-json:successed: True
"""def auto_gen_cases(swagger_url, project_name):"""根据swagger返回的json数据自动生成yml测试用例模板:param swagger_url::param project_name::return:"""res = Session().request('get', swagger_url).json()data = res.get('paths')workspace = os.getcwd()project_ = os.path.join(workspace, project_name)if not os.path.exists(project_):os.mkdir(project_)for k, v in data.items():pa_res = re.split(r'[/]+', k)dir, *file = pa_res[1:]if file:file = ''.join([x.title() for x in file])else:file = dirfile += '.yml'dirs = os.path.join(project_, dir)if not os.path.exists(dirs):os.mkdir(dirs)os.chdir(dirs)if len(v) > 1:v = {'post': v.get('post')}for _k, _v in v.items():method = _kapi = kcaseName = _v.get('description')data_or_params = 'params' if method == 'get' else 'data'parameters = _v.get('parameters')data_s = ''try:for each in parameters:data_s += each.get('name')data_s += ': \n'data_s += ' ' * 8except TypeError:data_s += '{}'file_ = os.path.join(dirs, file)with open(file_, 'w', encoding='utf-8') as fw:fw.write(template.format(method=method,api=api,caseName=caseName,data_or_params=data_or_params,data=data_s))os.chdir(project_)
现在要开始一个项目的接口测试覆盖,只要该项目集成了swagger,就能秒生成项目架子,测试人员只需要专心设计接口测试用例即可,我觉得对于测试团队的推广使用是很有意义的,也更方便了我这样的懒人。
【整整200集】超超超详细的Python接口自动化测试进阶教程合集,真实模拟企业项目实战
相关文章:
)
接口自动化测试框架(pytest+allure+aiohttp+ 用例自动生成)
近期准备优先做接口测试的覆盖,为此需要开发一个测试框架,经过思考,这次依然想做点儿不一样的东西。 接口测试是比较讲究效率的,测试人员会希望很快能得到结果反馈,然而接口的数量一般都很多,而且会越来越…...

[Python入门教程]01 Python开发环境搭建
Python开发环境搭建 本文介绍python开发环境的安装,使用anaconda做环境管理,VS code写代码。搭建开发环境是学习的第一步,本文将详细介绍anaconda和vs code的安装过程,并测试安装结果。 视频教程链接:https://www.bil…...
)
第四章:最新版零基础学习 PYTHON 教程(第二节 - Python 数据类型—Python 字符串、列表、元组、迭代)
在在上一节文章中,我们了解了 Python 的基础知识。现在,我们继续了解更多 Python 概念。 Python 中的字符串: 字符串是字符序列,可以是字母、数字和特殊字符的组合。在Python中可以使用单引号、双引号甚至三引号来声明它。这些引号不是字符串的一部分,它们仅定义字符串…...

react框架与vue框架的区别
React和Vue都是前端开发中常用的框架,它们有一些不同的特性和优点。下面是它们的主要区别: 数据流和数据绑定:React是一种单向数据流的框架,而Vue则是双向数据绑定的框架。这意味着在React中,数据从组件的state属性流…...

C++_pen_静态与常量
成员 常成员、常对象(C推荐使用 const 而不用#define,mutable) const 数据成员只在某个对象生存周期内是常量,而对于整个类而言却是可变的(static除外) 1.常数据成员(构造函数初始化表赋值) c…...

ToDoList使用自定义事件传值
MyTop与MyFooter与App之间传递数据涉及到的就是子给父传递数据,MyList和MyItem与App涉及到爷孙传递数据。 之前的MyTop是使用props接收App传值,然后再在methods里面调用,现在使用自定义事件来处理子组件和父组件之间传递数据。 图是之前的…...
基于SSM的家庭财务管理系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...
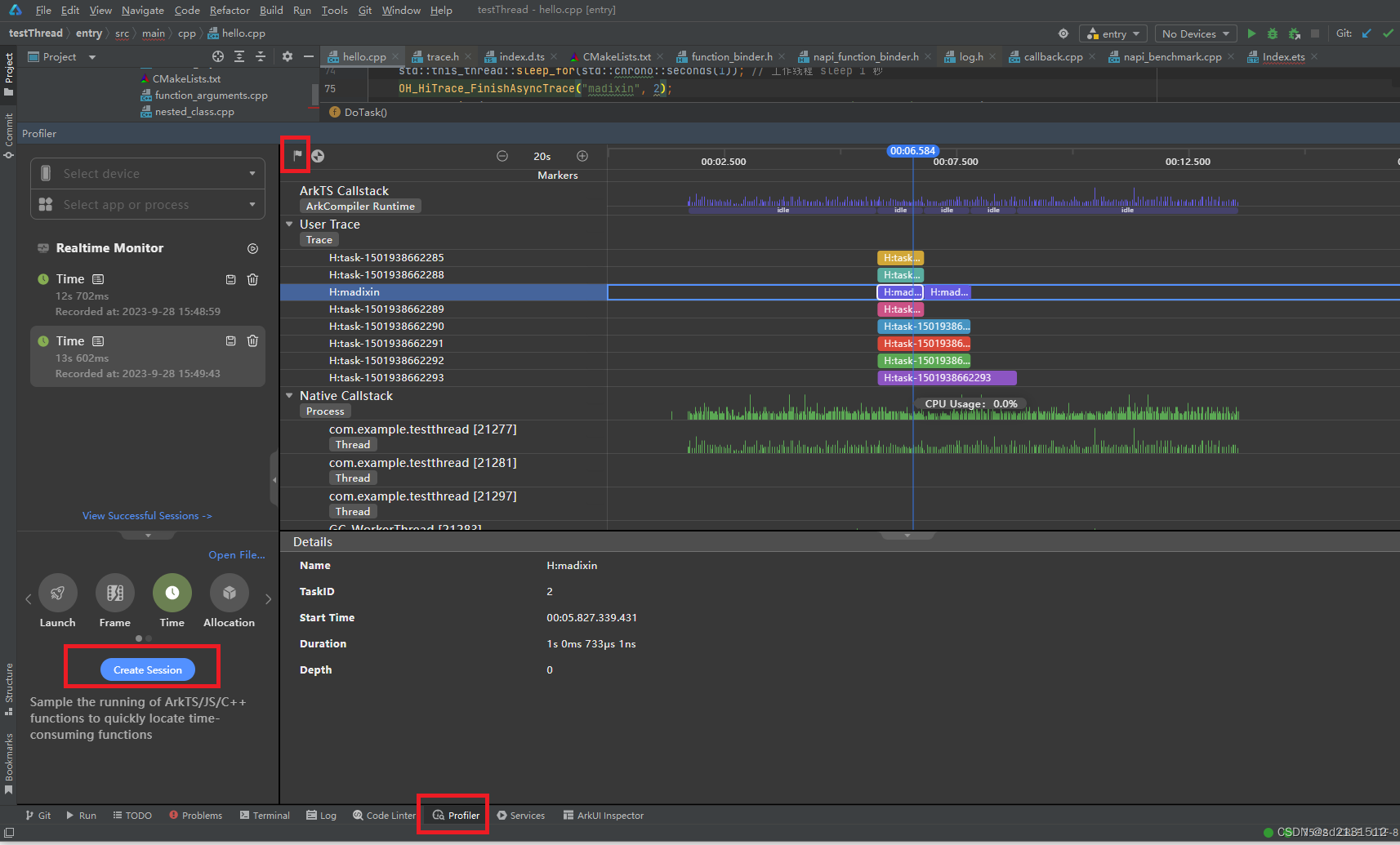
OpenHarmony Trace的使用
背景: 近期很多开发者反馈OpenHarmony三方库Imageknife有性能问题:连续拖动很多张图片时,界面有明显的卡顿现象。 因为对这个三方库的源码并不了解,因此需要了解目前Imageknife渲染花费了多少时间,最初想的是只有通过…...

文件上传笔记
一、上传的简单绕过: 1、若是上传的文件只在前端的代码中进行了过滤: (1)可以直接在开发者工具中删除相关代码: (2)也可以通过 burpsuite 绕过: 上传时,先提前修改 php 文件的后缀…...

计算机网络 第三章数据链路层
参考视频:计算机网络 文章目录 1、数据链路层概述2、链路层基本概念:节点3、链路层基本概念:链路与数据链路、帧4、封装成帧:字符计数法和字符填充法5、封装成帧:零比特填充法6、封装成帧:违规编码法7、差…...

浅析如何在抖音快速通过新手期并积累粉丝
抖音是一款非常受欢迎的短视频分享平台,它提供了一个快速成名和积累粉丝的机会。对于新手来说,通过四川不若与众总结的以下几个步骤可以帮助你快速通过抖音的新手期。 首先,确定你的内容定位。在抖音上,有各种各样的内容类型&…...
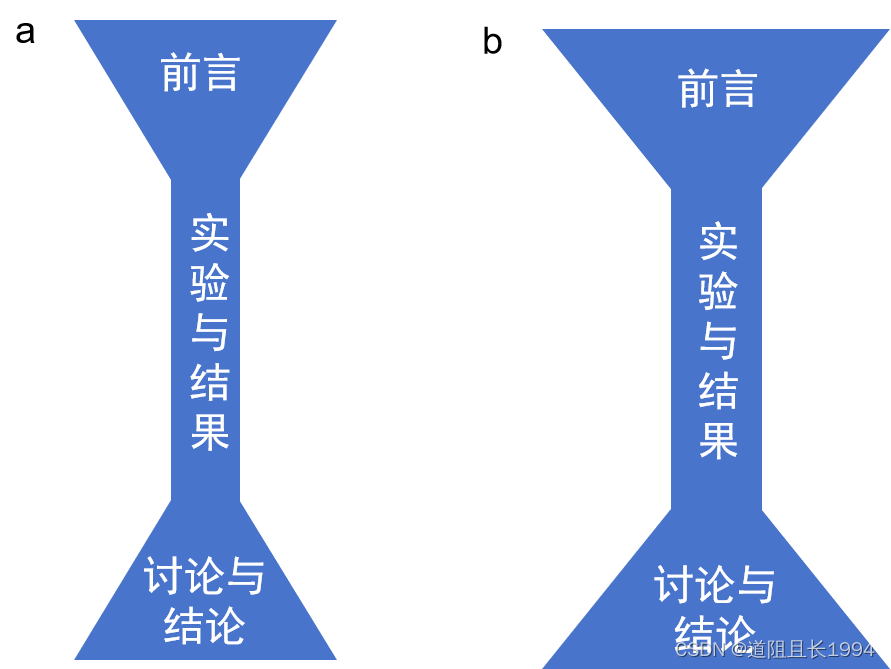
英文论文实例赏析——如何写前言?
写作与实验、统计一样重要 研究生的学习往往会遵循这样的过程:实验——数据分析——写作。虽然写作是最后进行的,但写作的学习这应该和实验的学习、数据分析的学习保持同步,因为写作与统计和实验技能一样,是科研工具箱的必…...

springBoot -md
法1 Editor.md https://blog.csdn.net/weixin_42039228/article/details/123472875 CREATE TABLE article ( id int(10) NOT NULL AUTO_INCREMENT COMMENT int文章的唯一ID, author varchar(50) NOT NULL COMMENT 作者, title varchar(100) NOT NULL COMMENT 标题, content l…...

从0开始学go第五天
gin框架返回JSON package mainimport ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/json", func(c *gin.Context) {//用map序列化//方法一:用map,后面用接口类型// data : map[string…...

大厂技术面试中的手撕代码应该如何准备?
文章目录 手撕代码是什么为什么要考察手撕代码如何准备手撕代码手撕代码注意事项华为OD算法/大厂面试高频题算法练习冲刺训练 不管是秋招还是社招,互联网大厂的技术面试中的手撕代码这一部分总是绕不过去的一关。不只是后端开发和算法岗,现在就连前端、运…...
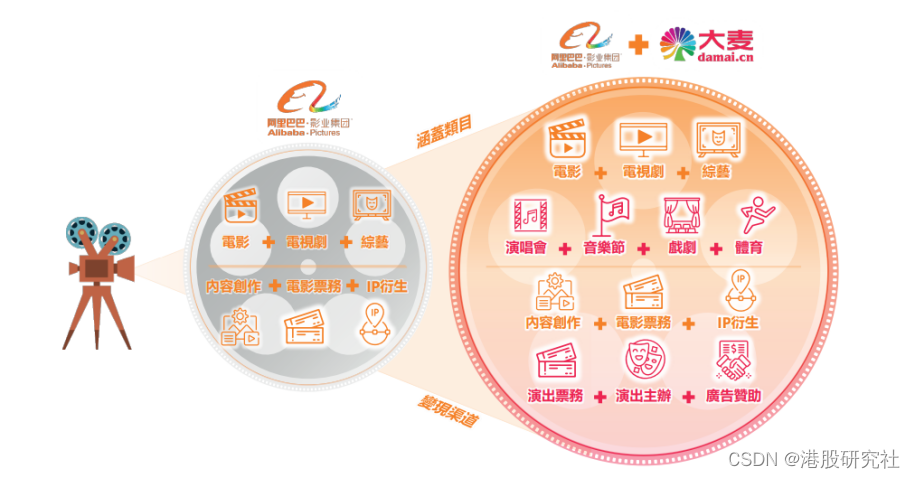
阿里影业+大麦,开启大文娱新纪元?
被“精心呵护”长达十年后,阿里大文娱在今年终于踏上了关键节点。 3月份,阿里“16N”组织大变革后,大文娱集团独自上路。8月,“分家”后的第一份财报显示,阿里大文娱集团成功大幅扭亏,实现了首次季度经调整…...
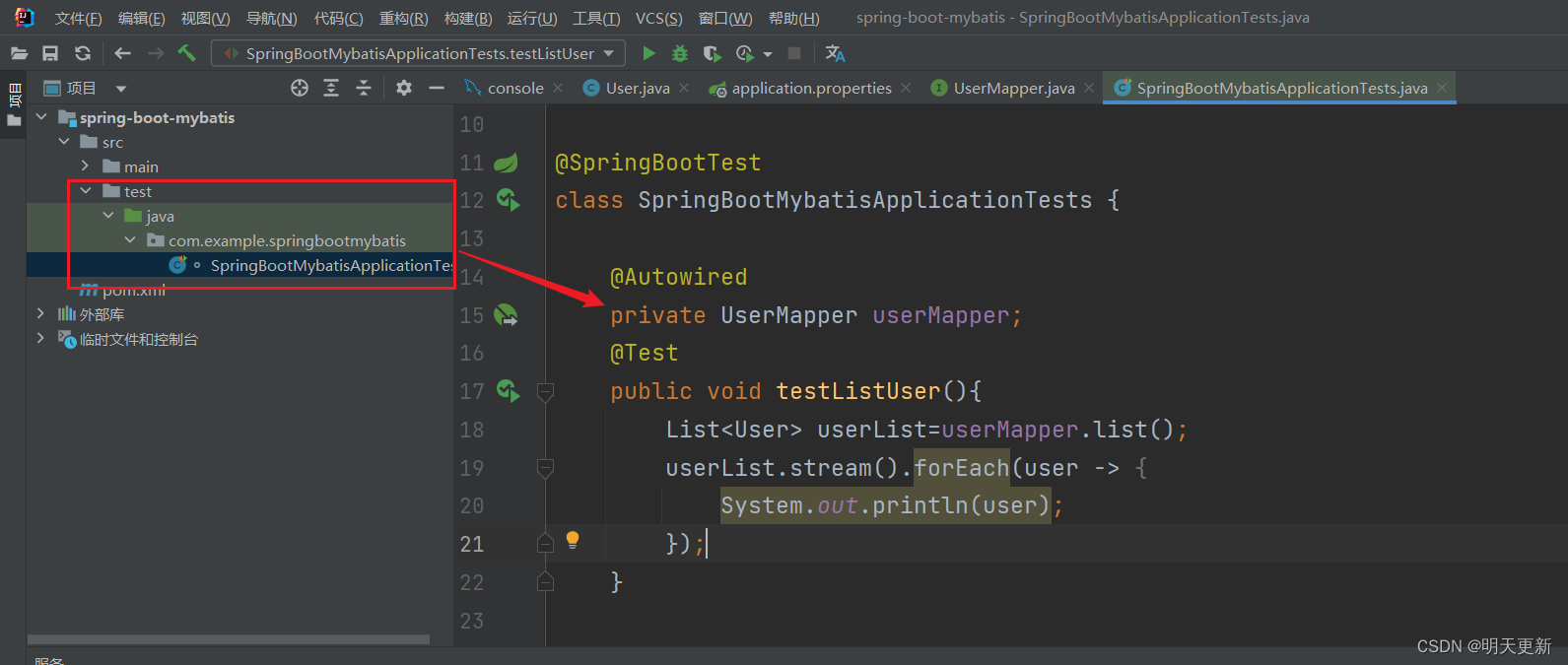
springboot整合mybatis入门程序
1.准备工作(创建springboot工程、数据库表user、实体类User) 创建数据表: create table user(id int unsigned primary key auto_increment comment ID,name varchar(100) comment 姓名,age tinyint unsigned comment 年龄,gender tinyint unsigned comment 性别, 1…...
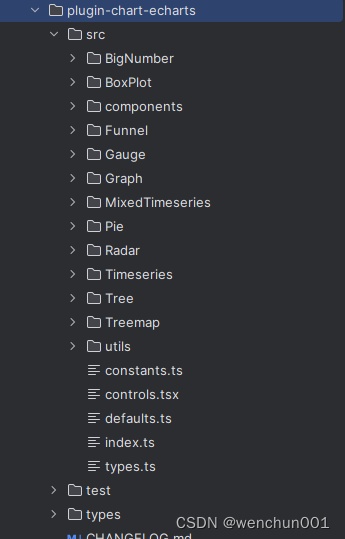
【BI看板】Superset2.0+图表二次开发初探
Superset图表功能也很丰富了,但一些个性化的定制需求就需要二次开发了。网上二开的superset版本大多是0.xxx版本的或1.5xxx版本,本次用的是2.xxx。 源码相关说明 源码目录 superset-2.0\superset-frontend\plugins\plugin-chart-echarts Yeoman 生成器 …...

微服务学习--1入门
写在前面: 最近摆了几天,现在重新开始学习。《本文没啥用》。 文章目录 概念概括优劣势特征 SpringCloud 概念 概括 微服务技术是分布式架构的一种,因为一个机器的能力有限,需要集群来进行同时解决,但是分布式也就…...
docker系列6:docker安装redis
传送门 docker系列1:docker安装 docker系列2:阿里云镜像加速器 docker系列3:docker镜像基本命令 docker系列4:docker容器基本命令 docker系列5:docker安装nginx Docker安装redis 通过前面4节,对docke…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...