决策树C4.5算法的技术深度剖析、实战解读
目录
- 一、简介
- 决策树(Decision Tree)
- 例子:
- 信息熵(Information Entropy)与信息增益(Information Gain)
- 例子:
- 信息增益比(Gain Ratio)
- 例子:
- 二、算法原理
- 信息熵(Information Entropy)
- 例子:
- 信息增益(Information Gain)
- 例子:
- 信息增益比(Gain Ratio)
- 例子:
- 三、算法流程
- 步骤1:数据准备
- 概念:
- 例子:
- 步骤2:计算信息熵
- 概念:
- 例子:
- 步骤3:选择最优特征
- 概念:
- 例子:
- 步骤4:递归构建决策树
- 概念:
- 例子:
- 步骤5:决策树剪枝(可选)
- 概念:
- 例子:
- 四、案例实战
- 数据集选择
- 概念:
- 例子:
- 数据预处理
- 概念:
- 例子:
- Python实现代码
- 输入和输出:
- 处理过程:
- 五、算法优缺点
- 优点
- 易于理解和解释
- 概念:
- 例子:
- 能够处理非线性关系
- 概念:
- 例子:
- 对缺失值有较好的容忍性
- 概念:
- 例子:
- 缺点
- 容易过拟合
- 概念:
- 例子:
- 对噪声和异常值敏感
- 概念:
- 例子:
- 计算复杂度可能较高
- 概念:
- 例子:
- 六、与其他类似算法比较
- C4.5 vs ID3
- 特征选择准则
- 概念:
- 例子:
- 对连续属性的处理
- 概念:
- 例子:
- C4.5 vs CART
- 输出类型
- 概念:
- 例子:
- 特征选择准则
- 概念:
- 例子:
- C4.5 vs Random Forests
- 模型复杂性
- 概念:
- 例子:
- 鲁棒性
- 概念:
- 例子:
- 七、总结
在本篇深入探讨的文章中,我们全面分析了C4.5决策树算法,包括其核心原理、实现流程、实战案例,以及与其他流行决策树算法(如ID3、CART和Random Forests)的比较。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、简介
C4.5算法是一种广泛应用于机器学习和数据挖掘的决策树算法。它是由Ross Quinlan教授在1993年提出的,作为其早期ID3(Iterative Dichotomiser 3)算法的一种扩展和改进。这个算法被设计用来将一个复杂的决策问题分解成一系列简单的决策,然后构建一个决策树模型来解决这个问题。
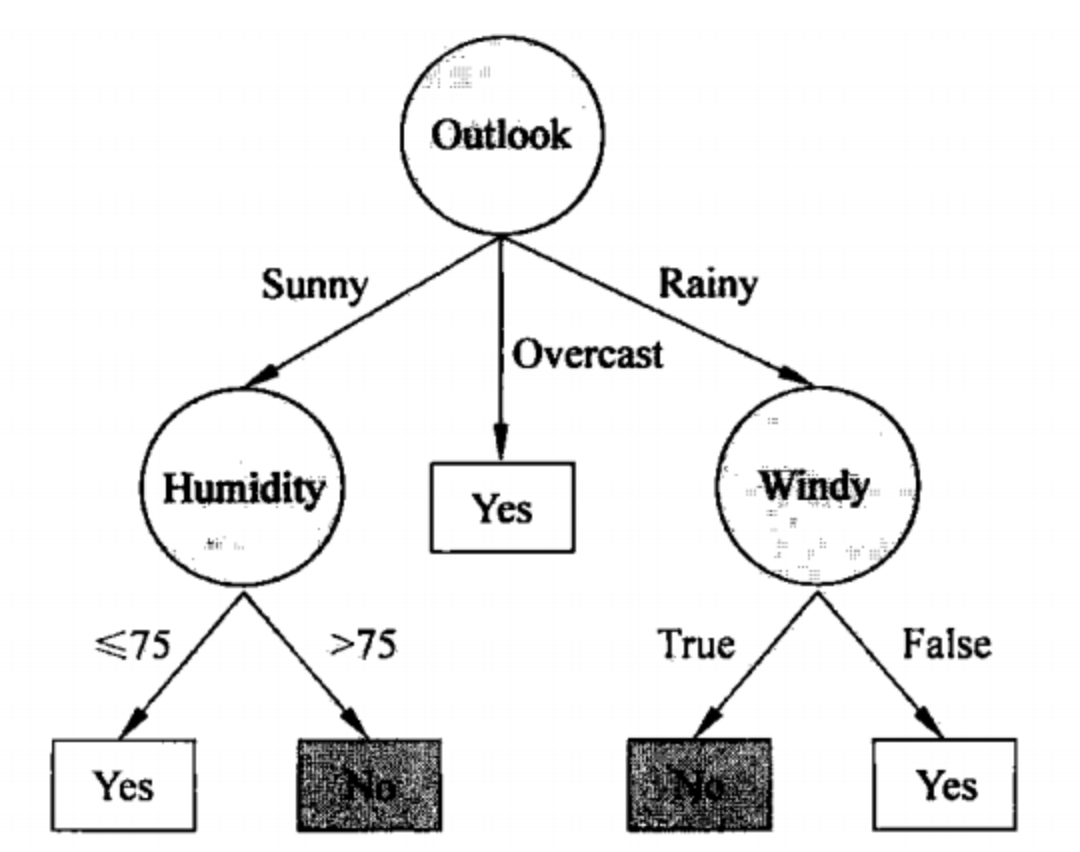
决策树(Decision Tree)
决策树是一种树形结构模型,用于在给定一组特征的情况下进行决策或分类。在这个模型中,每一个内部节点代表一个特征测试,每一个分支代表一个测试结果,而每一个叶子节点代表一个决策结果。
例子:
假设我们有一个数据集,其中包括天气、温度和是否进行户外活动。一个决策树可能会首先根据“天气”进行分支:如果是晴天,则推荐进行户外活动;如果是雨天,则进一步根据“温度”进行分支。
信息熵(Information Entropy)与信息增益(Information Gain)
信息熵是用于度量数据不确定性的一个指标,而信息增益则表示通过某个特征进行分裂后,能够为我们带来多少“信息”以减少这种不确定性。
例子:
考虑一个数据集,其中有两个类别A和B。如果所有实例都属于类别A,那么信息熵就是0,因为我们完全确定了任何实例都属于类别A。但如果一半属于类别A,另一半属于类别B,信息熵就是最高的,因为数据最不确定。
信息增益比(Gain Ratio)
与信息增益类似,信息增益比也是用于评估特征的重要性,但它还考虑了特征可能带来的分裂数(即特征值的数量)。
例子:
假设有一个特征“颜色”,它有很多可能的值(红、蓝、绿等)。即使“颜色”能提供很高的信息增益,由于它导致树分裂过多,因此信息增益比可能会相对较低。
通过这些核心概念和改进,C4.5算法不仅在计算效率上有所提升,而且在处理连续属性、缺失值以及减枝优化等方面都有显著的优势。
二、算法原理
在深入了解C4.5算法之前,有必要明确几个核心概念和度量指标。本节将重点介绍信息熵、信息增益、以及信息增益比,这些都是C4.5算法决策树构建中的关键因素。
信息熵(Information Entropy)
信息熵是用来度量一组数据的不确定性或混乱程度的。它是基于概率论的一个概念,通常用以下数学公式来定义:
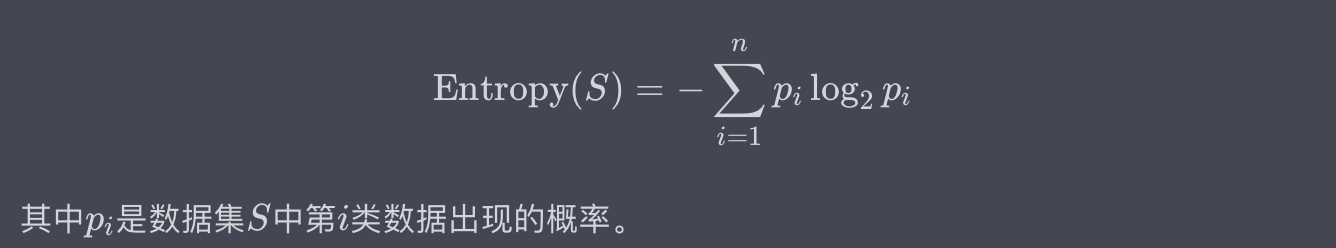
例子:
假设我们有一个数据集,包含10个样本,其中5个样本为正类(Yes),5个样本为负类(No)。信息熵可以计算为:

信息增益(Information Gain)
信息增益表示通过某个特征进行分裂后,数据集不确定性(即信息熵)下降的程度。信息增益通常用以下数学公式来定义:

例子:
考虑一个简单数据集,其中有一个特征“天气”,它有两个可能的值:“晴天”和“雨天”。通过计算,我们发现通过“天气”这个特征进行分裂后,信息增益是0.2。这意味着使用这个特征进行分裂能让数据集的不确定性下降0.2。
信息增益比(Gain Ratio)
信息增益比是信息增益与该特征导致的数据集分裂复杂度(Split Information)的比值。用数学公式表示为:

例子:
如果在前面的“天气”特征例子中,我们计算出Split Information是0.5,那么信息增益比就是0.2 / 0.5 = 0.4。
通过信息熵、信息增益和信息增益比这三个关键概念,C4.5算法能有效地选择最优特征,进行数据集的分裂,从而构建出高效且准确的决策树。这不仅解决了ID3算法在某些方面的不足,也使得决策树模型更加适用于实际问题。
三、算法流程
在这一部分中,我们将深入探讨C4.5算法的核心流程。流程通常可以分为几个主要步骤,从数据预处理到决策树的生成,以及后续的决策树剪枝。下面是更详细的解释:
步骤1:数据准备
概念:
在决策树的构建过程中,首先需要准备一个训练数据集。这个数据集应该包含多个特征(或属性)和一个目标变量(或标签)。数据准备阶段也可能包括数据清洗和转换。
例子:
比如,在医疗诊断中,特征可能包括病人的年龄、性别和症状等,而目标变量可能是病人是否患有某种疾病。
步骤2:计算信息熵
概念:
信息熵是一个用于衡量数据不确定性的度量。在C4.5算法中,使用信息熵来评估如何分割数据。
例子:
假如有一个数据集,其中有两个分类:“是”和“否”,每个分类包含50%的数据。在这种情况下,信息熵是最高的,因为数据具有最高程度的不确定性。
步骤3:选择最优特征
概念:
在决策树的每一个节点,算法需要选择一个特征来分割数据。选择哪个特征取决于哪个特征会导致信息熵最大的下降(或信息增益最大)。
例子:
在预测是否会下雨的任务中,可能有多个特征如气温、湿度等。如果发现通过“湿度”这一特征分割数据会得到信息增益最大,那么该节点就应该基于“湿度”来分割。
步骤4:递归构建决策树
概念:
一旦选择了最优特征并根据该特征分割了数据,算法将在每个分割后的子集上递归地执行同样的过程,直到满足某个停止条件(如,所有数据都属于同一类别或达到预设的最大深度等)。
例子:
考虑一个用于分类动物的决策树。首先,根据“是否有脊椎”这一特征来分割数据,然后,在“有脊椎”的子集中进一步基于“是否能飞”来分割,以此类推。
步骤5:决策树剪枝(可选)
概念:
决策树剪枝是一种优化手段,用于去除决策树中不必要的节点,以防止过拟合。
例子:
如果一个节点的所有子节点都对应着同一个类别标签,那么这个节点可能是不必要的,因为它的父节点已经能准确分类。
四、案例实战
在本节中,我们将使用一个实际的数据集来展示如何应用C4.5算法。通过这个案例,您将更清楚地了解如何将理论应用到实际问题中。我们将使用Python和Scikit-learn库来实现这一算法(注意,Scikit-learn的DecisionTreeClassifier提供了一个参数criterion='entropy',用于实现C4.5的信息增益准则)。
数据集选择
概念:
在机器学习项目中,选择合适的数据集是非常关键的一步。数据集应该是问题相关、丰富而且干净的。
例子:
为了本例,我们将使用经典的Iris数据集,该数据集用于分类三种不同的鸢尾花。
数据预处理
概念:
数据预处理是准备数据用于机器学习模型的过程。这可能包括标准化、缺失值处理等。
例子:
在Iris数据集中,所有的特征都是数值型的,不需要进一步的转换或标准化。
Python实现代码
下面是使用Python和Scikit-learn实现C4.5算法的代码。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化决策树分类器
clf = DecisionTreeClassifier(criterion='entropy')# 训练模型
clf.fit(X_train, y_train)# 测试模型
score = clf.score(X_test, y_test)
print(f'Accuracy: {score * 100:.2f}%')
输入和输出:
- 输入:Iris数据集的特征和标签
- 输出:模型的准确率
处理过程:
- 加载Iris数据集。
- 将数据集划分为训练集和测试集。
- 初始化一个使用信息熵作为分裂准则的决策树分类器。
- 使用训练集训练分类器。
- 使用测试集评估分类器。
五、算法优缺点
C4.5算法作为决策树家族中的一员,广泛应用于分类问题。然而,和所有算法一样,C4.5也有其优缺点。这一节将详细地探讨这些方面。
优点
易于理解和解释
概念:
决策树是白盒模型,这意味着与黑盒模型(如神经网络)相比,决策树更容易理解和解释。
例子:
假设你有一个决策树模型用于信用评分。每个节点都清晰地描述了哪个特征被用于分割,比如年收入或债务比率。这使得银行能轻易地解释给客户为什么他们的贷款申请被拒绝。
能够处理非线性关系
概念:
C4.5能很好地处理特征与目标变量之间的非线性关系。
例子:
考虑一个电子商务网站,其中用户年龄和购买意愿之间可能存在非线性关系。年轻人和老年人可能更倾向于购买,而中年人可能相对较少。C4.5算法能捕捉到这种非线性关系。
对缺失值有较好的容忍性
概念:
C4.5算法可以容忍输入数据的缺失值。
例子:
在医疗诊断场景中,患者的某些检查结果可能不完整或缺失,C4.5算法仍然可以进行有效的分类。
缺点
容易过拟合
概念:
C4.5算法非常容易产生过拟合,尤其是当决策树很深的时候。
例子:
如果一个决策树模型在股票市场预测问题上表现得异常好,那很可能是该模型已经过拟合了,因为股票价格受到多种不可预测因素的影响。
对噪声和异常值敏感
概念:
由于决策树模型在构建时对数据分布的微小变化非常敏感,因此噪声和异常值可能会极大地影响模型性能。
例子:
在识别垃圾邮件的应用中,如果训练数据包含由于标注错误而导致的噪声,C4.5算法可能会误将合法邮件分类为垃圾邮件。
计算复杂度可能较高
概念:
由于需要计算所有特征的信息增益或增益率,C4.5算法在特征维度非常高时可能会有较高的计算成本。
例子:
在基因表达数据集上,由于特征数可能达到数千或更多,使用C4.5算法可能会导致计算成本增加。
六、与其他类似算法比较
决策树算法有多个不同的实现,如ID3、CART(分类与回归树)和Random Forests。在这一节中,我们将重点比较C4.5与这些算法的主要区别和适用场景。
C4.5 vs ID3
特征选择准则
概念:
ID3算法使用信息增益作为特征选择的准则,而C4.5使用的是信息增益率。
例子:
假设你正在对文本数据进行分类,其中一个特征是文本长度。ID3可能会倾向于使用这个特征,因为它可能具有高信息增益。然而,C4.5通过使用增益率,可能会减少这种偏向,从而选出更有区分度的特征。
对连续属性的处理
概念:
C4.5能够直接处理连续属性,而ID3不能。
例子:
在房价预测模型中,房屋面积是一个连续属性。C4.5能够自然地处理这种类型的数据,而ID3需要先将其离散化。
C4.5 vs CART
输出类型
概念:
CART支持分类和回归两种输出,而C4.5主要用于分类。
例子:
如果你的目标是预测一个连续的输出变量(如房价),那么CART可能是一个更好的选择。
特征选择准则
概念:
CART使用“基尼不纯度”或“均方误差”作为特征选择准则,而C4.5使用信息增益率。
例子:
在一个医疗诊断应用中,假设某个特征在两个类别中的分布相差非常大,C4.5可能会优先选择这个特征,而CART则可能不会。
C4.5 vs Random Forests
模型复杂性
概念:
Random Forests是一个集成方法,通常包括多个决策树,因此模型更为复杂。
例子:
在一个高维数据集(例如图像分类)上,Random Forests可能会比C4.5表现得更好,但需要更多的计算资源。
鲁棒性
概念:
由于Random Forests是一个集成方法,它通常更不容易过拟合,并且对噪声和异常值有更好的鲁棒性。
例子:
在金融欺诈检测的应用中,由于数据通常非常不平衡并且包含许多噪声,使用Random Forests通常会获得比C4.5更好的结果。
七、总结
决策树算法,尤其是C4.5算法,因其直观、易于理解和实施而得到了广泛的应用。在本篇文章中,我们从算法原理、流程、案例实战、优缺点,以及与其他类似算法的比较多个角度对C4.5算法进行了深入的探讨。
-
特征选择的多样性:C4.5算法通过使用信息增益率来优化特征选择,提供了一个在某些情况下比ID3更合适的选择。这一点在处理高维数据或特征间存在依赖的情况下尤为重要。
-
适用性与局限性:虽然C4.5在处理分类问题时非常强大,但它也有自己的局限,比如容易过拟合和对噪声敏感。理解这些局限不仅有助于我们在具体应用中做出更明智的决策,还促使我们去探索如何通过集成方法或参数调优来改进算法。
-
与其他算法的相对位置:当我们将C4.5与CART、Random Forests等其他决策树算法比较时,可以看出每种算法都有其独特的应用场景和局限性。例如,在需要模型解释性的场合,C4.5和CART可能更为合适;而在高维复杂数据集上,Random Forests可能更具优势。
-
复杂性和计算成本:C4.5虽然是一个相对简单的算法,但在处理大规模或高维数据时,其计算成本也不容忽视。这提醒我们,在实际应用中需要综合考虑算法性能和计算成本。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
决策树C4.5算法的技术深度剖析、实战解读
目录 一、简介决策树(Decision Tree)例子: 信息熵(Information Entropy)与信息增益(Information Gain)例子: 信息增益比(Gain Ratio)例子: 二、算…...
LLMs Python解释器程序辅助语言模型(PAL)Program-aided language models (PAL)
正如您在本课程早期看到的,LLM执行算术和其他数学运算的能力是有限的。虽然您可以尝试使用链式思维提示来克服这一问题,但它只能帮助您走得更远。即使模型正确地通过了问题的推理,对于较大的数字或复杂的运算,它仍可能在个别数学操…...
【12】c++设计模式——>单例模式练习(任务队列)
属性: (1)存储任务的容器,这个容器可以选择使用STL中的队列(queue) (2)互斥锁,多线程访问的时候用于保护任务队列中的数据 方法:主要是对任务队列中的任务进行操作 &…...
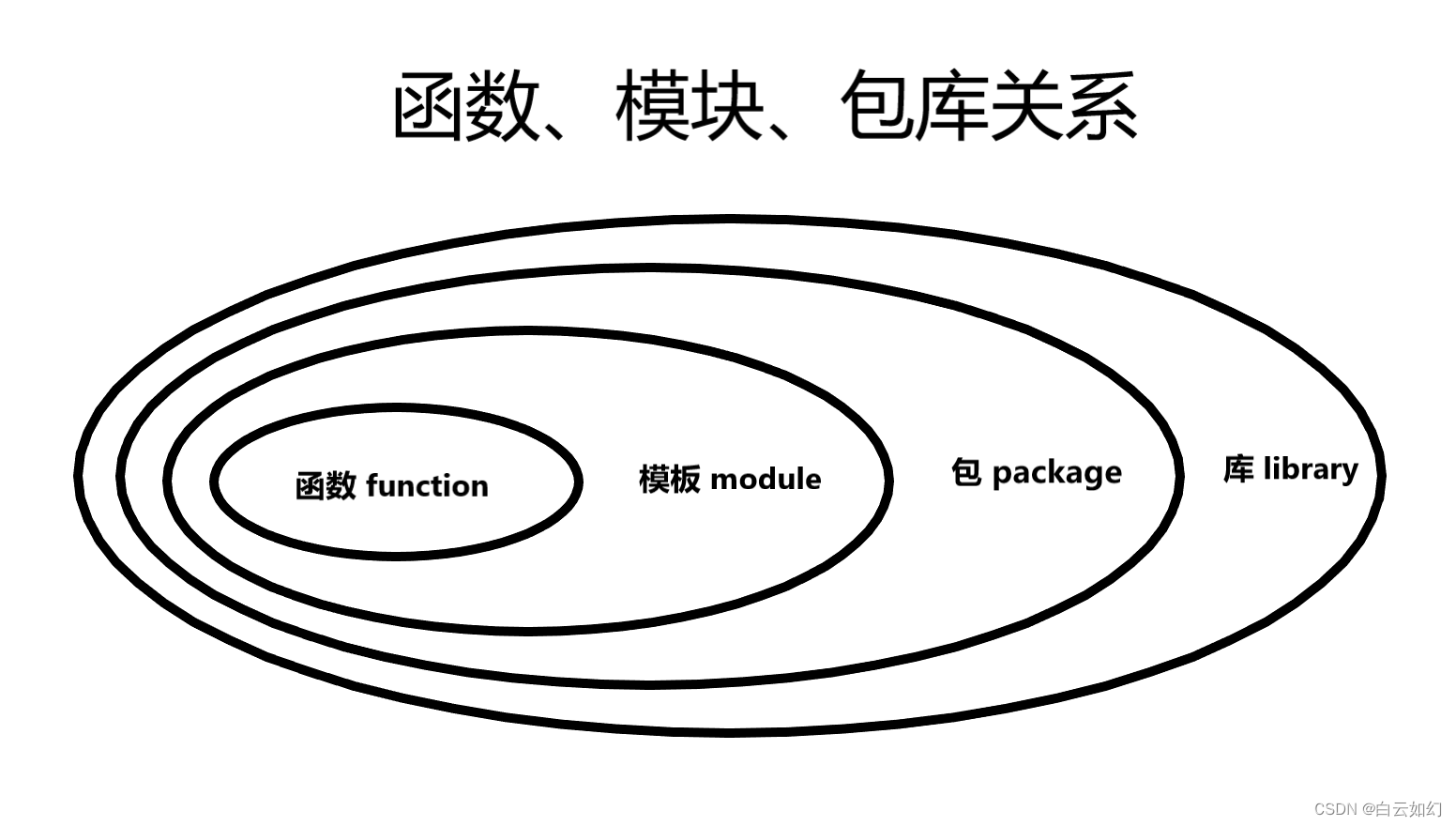
Python之函数、模块、包库
函数、模块、包库基础概念和作用 A、函数 减少代码重复 将复杂问题代码分解成简单模块 提高代码可读性 复用老代码 """ 函数 """# 定义一个函数 def my_fuvtion():# 函数执行部分print(这是一个函数)# 定义带有参数的函数 def say_hello(n…...

SQL创建与删除索引
索引创建、删除与使用: 1.1 create方式创建索引:CREATE [UNIQUE – 唯一索引 | FULLTEXT – 全文索引 ] INDEX index_name ON table_name – 不指定唯一或全文时默认普通索引 (column1[(length) [DESC|ASC]] [,column2,…]) – 可以对多列建立组合索引 …...
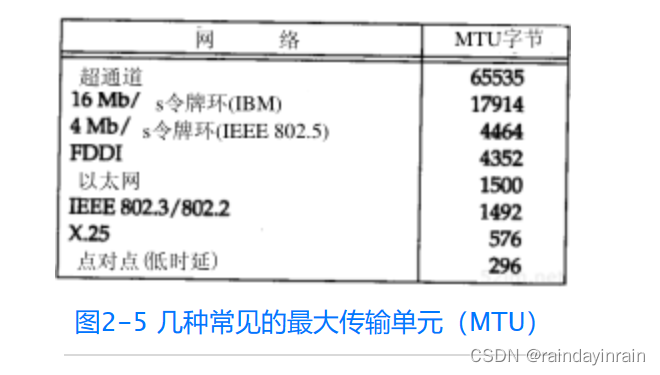
网络协议--链路层
2.1 引言 从图1-4中可以看出,在TCP/IP协议族中,链路层主要有三个目的: (1)为IP模块发送和接收IP数据报; (2)为ARP模块发送ARP请求和接收ARP应答; (3…...

HDLbits: Count clock
目前写过最长的verilog代码,用了将近三个小时,编写12h显示的时钟,改来改去,估计只有我自己看得懂(吐血) module top_module(input clk,input reset,input ena,output pm,output [7:0] hh,output [7:0] mm,…...

【1day】用友移动管理系统任意文件上传漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...

【c++】向webrtc学习容器操作
std::map的key为std::pair 时的查找 std::map<RemoteAndLocalNetworkId, size_t> in_flight_bytes_RTC_GUARDED_BY(&lock_);private:using RemoteAndLocalNetworkId = std::pair<uint16_t, uint16_t...
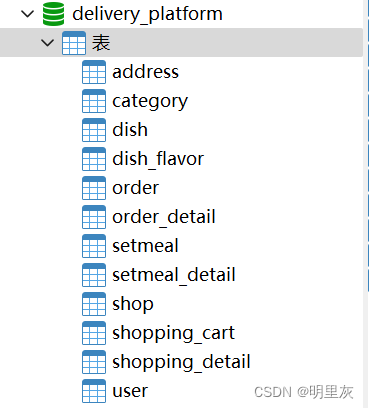
SpringBoot+Vue3外卖项目构思
SpringBoot的学习: SpringBoot的学习_明里灰的博客-CSDN博客 实现功能 前台 用户注册,邮箱登录,地址管理,历史订单,菜品规格,购物车,下单,菜品浏览,评价,…...

【AI视野·今日NLP 自然语言处理论文速览 第四十七期】Wed, 4 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 4 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Contrastive Post-training Large Language Models on Data Curriculum Authors Canwen Xu, Corby Rosset, Luc…...

c++的lambda表达式
文章目录 1 lambda表达式2 捕捉列表 vs 参数列表3 lambda表达式的传递3.1 函数作为形参3.2 场景1:条件表达式3.3 场景2:线程的运行表达式 1 lambda表达式 lambda表达式可以理解为匿名函数,也就是没有名字的函数,既然是函数&#…...

电梯安全监测丨S271W无线水浸传感器用于电梯机房/电梯基坑水浸监测
城市化进程中,电梯与我们的生活息息相关。高层住宅、医院、商场、学校、车站等各种商业体建筑、公共建筑中电梯为我们生活工作提供了诸多便利。 保障电梯系统的安全至关重要!特别是电梯机房和电梯基坑可通过智能化改造提高其安全性和稳定性。例如在暴风…...

Java异常:基本概念、分类和处理
Java异常:基本概念、分类和处理 在Java编程中,异常处理是一个非常重要的部分。了解如何识别、处理和避免异常对于编写健壮、可维护的代码至关重要。本文将介绍Java异常的基本概念、分类和处理方法,并通过简单的代码示例进行说明。 一、什么…...
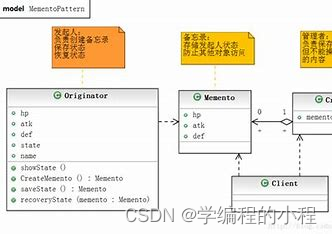
小谈设计模式(19)—备忘录模式
小谈设计模式(19)—备忘录模式 专栏介绍专栏地址专栏介绍 备忘录模式主要角色发起人(Originator)备忘录(Memento)管理者(Caretaker) 应用场景结构实现步骤Java程序实现首先ÿ…...

《数据库系统概论》王珊版课后习题
第一章 绪论 1.数据、数据库、数据库管理系统、数据库系统的概念 (1)数据(Data):数据是数据库中存储的基本对象,是描述事物的符号记录。数据有多种表现形式,它们都可以经过数字化后存入计算机…...

MariaDB 修改用户远程登录
今天修改MariaDB数据库用户的Host时出现错误: ERROR 1356 (HY000): View ‘mysql.user’ references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them 我的步骤如下: 1.登陆 2.use mysql; 3.执行…...

Elasticsearch使用mapping映射定义以及基本的数据类型
1、说明 Elasticsearch的映射相当于数据库的数据字典,它定义了每个字段的名称和能够保存的数据类型,并且内置了20多种字段类型用于支持多种多样的结构化数据,这里仅介绍几种常用的字段类型,如需要了解全部的类型,请参…...
【unity】制作一个角色的初始状态(左右跳二段跳)【2D横板动作游戏】
前言 hi~ 大家好!欢迎大家来到我的全新unity学习记录系列。现在我想在2d横板游戏中,实现一个角色的初始状态-闲置状态、移动状态、空中状态。并且是利用状态机进行实现的。 本系列是跟着视频教程走的,所写也是作者个人的学习记录笔记。如有错…...

不死马的利用与克制(基于条件竞争)及变种不死马
不死马即内存马,它会写进进程里,并且无限地在指定目录中生成木马文件 这里以PHP不死马为例 测试代码: <?phpignore_user_abort(true);set_time_limit(0);unlink(__FILE__);$file .test.php;$code <?php if(md5($_GET["pass…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...
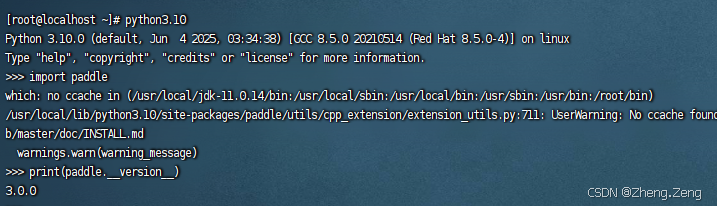
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...