【Zookeeper专题】Zookeeper经典应用场景实战(一)
目录
- 前置知识
- 课程内容
- 一、Zookeeper Java客户端实战
- 1.1 Zookeeper 原生Java客户端使用
- 1.2 Curator开源客户端使用
- 快速开始
- 使用示例
- 二、Zookeeper在分布式命名服务中的实战
- 2.1 分布式API目录
- 2.2 分布式节点的命名
- 2.3 分布式的ID生成器
- 三、zookeeper实现分布式队列
- 3.1 设计思路
- 3.2 使用Apache Curator实现分布式队列
- 学习总结
- 感谢
前置知识
在学习本节课之前,至少需要掌握Zookeeper的节点特性,以及基本操作。
《【Zookeeper专题】Zookeeper特性与节点数据类型详解》
课程内容
一、Zookeeper Java客户端实战
Zookeeper的客户端有很多,这边主要介绍的是两种:
- Zookeeper官方的Java客户端API
- 第三方的Java客户端API,Curator
ZooKeeper官方的客户端API提供了基本的操作,例如:创建会话、增删查改节点等(就是对原有命令交互式客户端的封装)。不过,Zookeeper官方客户端封装度比较低,使用起来不是很方便。这种不方便体现在:
- ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册
- 会话超时之后没有实现重连机制
- 异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常
- 仅提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口
- 创建节点时如果抛出异常,需要自行检查节点是否存在
- 无法实现级联删除
当然不便之处不止这些,不管怎样,在实际开发中,我们通常不是很建议使用官方API的。
1.1 Zookeeper 原生Java客户端使用
使用前,先引入客户端的依赖:
<!-- zookeeper client -->
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.0</version>
</dependency>
然后是代码示例:
public class ZkClientDemo {private static final String CONNECT_STR="localhost:2181";private final static String CLUSTER_CONNECT_STR="192.168.65.156:2181,192.168.65.190:2181,192.168.65.200:2181";public static void main(String[] args) throws Exception {final CountDownLatch countDownLatch=new CountDownLatch(1);ZooKeeper zooKeeper = new ZooKeeper(CLUSTER_CONNECT_STR,4000, new Watcher() {@Overridepublic void process(WatchedEvent event) {if(Event.KeeperState.SyncConnected==event.getState() && event.getType()== Event.EventType.None){//如果收到了服务端的响应事件,连接成功countDownLatch.countDown();System.out.println("连接建立");}}});System.out.printf("连接中");countDownLatch.await();//CONNECTEDSystem.out.println(zooKeeper.getState());//创建持久节点zooKeeper.create("/user","fox".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}
}
客户端主要的API有:
create(path, data, acl,createMode):创建一个给定路径的 znode,并在 znode 保存 data[]的数据,createMode指定 znode 的类型。
delete(path, version):如果给定 path上的znode的版本和给定的version匹配,删除znode。
exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。
setData(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置 znode 数据。
getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode 设置一个 watch。
sync(path):把客户端 session 连接节点和 leader 节点进行同步
以上这些API主要的特点如下:
- 所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化
- 所有更新 znode 数据的 API 都有两个版本,即:无条件更新版本和条件更新版本。如果 version 为 -1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来自服务端的响应(不过ZK有一点不好的是,对于同步异步方法没有在方法名上显示注明sync/async,而是体现在请求参数callback上)
例如,这边简单演示一下同步跟异步创建节点方法。
// 同步创建,并且返回创建节点的路径信息
@Test
public void createTest() throws KeeperException, InterruptedException {String path = zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);log.info("created path: {}",path);
}// 异步创建
// 看最后一个lambda表达式
@Test
public void createAsycTest() throws InterruptedException {zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT,(rc, path, ctx, name) -> log.info("rc {},path {},ctx {},name {}",rc,path,ctx,name),"context");TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
其余API这里就不演示了,大家伙感兴趣的可以回头去试试。
1.2 Curator开源客户端使用
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册Watcher的问题以及NodeExistsException异常等。Curator还为ZooKeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
快速开始
引入maven依赖
Curator的使用包含了几个包:
- curator-framework是对ZooKeeper的底层API的一些封装
- curator-client提供了一些客户端的操作,例如重试策略等
- curator-recipes封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等
<!-- zookeeper client -->
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.0</version>
</dependency><!--curator-->
<dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>5.1.0</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions>
</dependency>
创建一个客户端
在使用curator-framework包操作ZooKeeper前,首先要创建一个客户端实例。这是一个CuratorFramework类型的对象,有两种方法:
- 使用工厂类CuratorFrameworkFactory的静态newClient()方法
// 重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3)
//创建客户端实例
CuratorFramework client = CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy);
//启动客户端
client.start();
- 使用工厂类CuratorFrameworkFactory的静态builder构造者方法
//随着重试次数增加重试时间间隔变大,指数倍增长baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1)))
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.128.129:2181").sessionTimeoutMs(5000) // 会话超时时间.connectionTimeoutMs(5000) // 连接超时时间.retryPolicy(retryPolicy).namespace("base") // 包含隔离名称.build();
client.start();
buidler调用链函数说明:
- connectionString:服务器地址列表,在指定服务器地址列表的时候可以是一个地址,也可以是多个地址。如果是多个地址,那么每个服务器地址列表用逗号分隔, 如 host1:port1,host2:port2,host3;port3
- retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接 ZooKeeper 服务端。而 Curator 提供了 一次重试、多次重试等不同种类的实现方式。在 Curator内部,可以通过判断服务器返回的 keeperException 的状态代码来判断是否进行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR 表示系统或服务端错误
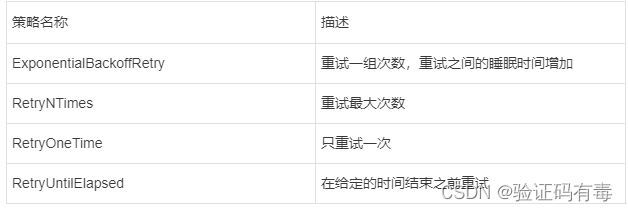
- 超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。sessionTimeoutMs 作用在服务端,而 connectionTimeoutMs 作用在客户端。
使用示例
创建节点
创建节点的方式如下面的代码所示,回顾我们之前课程中讲到的内容,描述一个节点要包括节点的类型,即临时节点还是持久节点、节点的数据信息、节点是否是有序节点等属性和性质。
@Test
public void testCreate() throws Exception {String path = curatorFramework.create().forPath("/curator-node");curatorFramework.create().withMode(CreateMode.PERSISTENT).forPath("/curator-node","some-data".getBytes())log.info("curator create node :{} successfully.",path);
}
在 Curator 中,可以使用 create 函数创建数据节点,并通过 withMode 函数指定节点类型(持久化节点,临时节点,顺序节点,临时顺序节点,持久化顺序节点等),默认是持久化节点,之后调用 forPath函数来指定节点的路径和数据信息。
一次性创建带层级结构的节点
@Test
public void testCreateWithParent() throws Exception {String pathWithParent="/node-parent/sub-node-1";String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent);log.info("curator create node :{} successfully.",path);
}
获取数据
@Test
public void testGetData() throws Exception {byte[] bytes = curatorFramework.getData().forPath("/curator-node");log.info("get data from node :{} successfully.",new String(bytes));
}
更新数据
我们通过客户端实例的 setData() 方法更新 ZooKeeper 服务上的数据节点,在setData 方法的后边,通过 forPath 函数来指定更新的数据节点路径以及要更新的数据。
@Test
public void testSetData() throws Exception {curatorFramework.setData().forPath("/curator-node","changed!".getBytes());byte[] bytes = curatorFramework.setData().forPath("/curator-node");log.info("get data from node /curator-node :{} successfully.",new String(bytes));
}
删除节点
@Test
public void testDelete() throws Exception {String pathWithParent="/node-parent";curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);
}
guaranteed:该函数的功能如字面意思一样,主要起到一个保障删除成功的作用,其底层工作方式是:只要该客户端的会话有效,就会在后台持续发起删除请求,直到该数据节点在 ZooKeeper 服务端被删除。
deletingChildrenIfNeeded:指定了该函数后,系统在删除该数据节点的时候会以递归的方式直接删除其子节点,以及子节点的子节点。
异步接口
Curator 引入了BackgroundCallback 接口,用来处理服务器端返回来的信息,这个处理过程是在异步线程中调用,默认在 EventThread 中调用,也可以自定义线程池。
public interface BackgroundCallback
{/*** Called when the async background operation completes** @param client the client* @param event operation result details* @throws Exception errors*/public void processResult(CuratorFramework client, CuratorEvent event) throws Exception;
}
如上接口,主要参数为 client 客户端,和服务端事件 event。inBackground异步处理默认在EventThread中执行
@Test
public void test() throws Exception {curatorFramework.getData().inBackground((item1, item2) -> {log.info(" background: {}", item2);}).forPath(ZK_NODE);TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
或者使用自定义线程池:
@Test
public void test() throws Exception {ExecutorService executorService = Executors.newSingleThreadExecutor();curatorFramework.getData().inBackground((item1, item2) -> {log.info(" background: {}", item2);},executorService).forPath(ZK_NODE);TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
Curator 监听器
我们知道,ZK的一大特色便是他们的监听机制。Curator在监听方面,相比于原生的客户端,Curator将重复注册、事件信息等进行了高度封装,让用户做到开箱即用。并且在监听事件返回了详细的信息,包括变动的节点路径,节点值等等,这是原生API所没有的。
Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一个本地缓存视图与远程 Zookeeper 视图的对比过程。
官方推荐的节点监听API有:
NodeCache(已过期):对某一个节点进行监听,监听事件包括指定路径的增删改等操作
@Slf4j
public class NodeCacheTest extends AbstractCuratorTest{public static final String NODE_CACHE="/node-cache";@Testpublic void testNodeCacheTest() throws Exception {createIfNeed(NODE_CACHE);NodeCache nodeCache = new NodeCache(curatorFramework, NODE_CACHE);nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {log.info("{} path nodeChanged: ",NODE_CACHE);printNodeData();}});nodeCache.start();}public void printNodeData() throws Exception {byte[] bytes = curatorFramework.getData().forPath(NODE_CACHE);log.info("data: {}",new String(bytes));}
}
PathChildrenCache(已过期):对指定路径节点的一级子目录监听,不对该节点的操作监听。换句话说就是对其子目录的增删改操作监听
@Slf4j
public class PathCacheTest extends AbstractCuratorTest{public static final String PATH="/path-cache";@Testpublic void testPathCache() throws Exception {createIfNeed(PATH);PathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, PATH, true);pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {log.info("event: {}",event);}});// 如果设置为true则在首次启动时就会缓存节点内容到Cache中pathChildrenCache.start(true);}
}
TreeCache(已过期):综合NodeCache和PathChildrenCahce的特性,是对整个目录进行监听,可以设置监听深度
public class TreeCacheTest extends AbstractCuratorTest{public static final String TREE_CACHE="/tree-path";@Testpublic void testTreeCache() throws Exception {createIfNeed(TREE_CACHE);TreeCache treeCache = new TreeCache(curatorFramework, TREE_CACHE);treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {log.info(" tree cache: {}",event);}});treeCache.start();}
}
CuratorCache:上面的几个节点缓存API其实已经过期了,最近的版本开始使用CuratorCache单个接口来替代它们,在使用上也更为简单。我们来小小的看一下该类的创建api
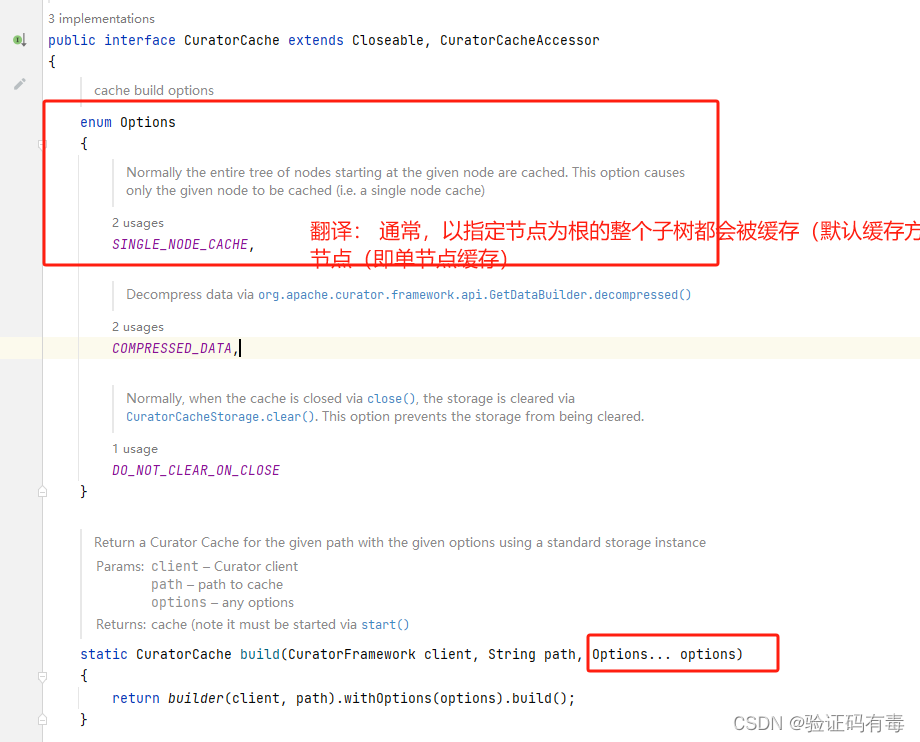
如上所示,构建节点缓存的build()方法提供了一个可选的参数options。Options是一个内部枚举类型,如果不指定,默认是缓存【给定节点开始的整个节点树】。
下面是一个简单的使用示例:
package org.tuling.zk.curator;import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.imps.CuratorFrameworkState;
import org.apache.curator.framework.recipes.cache.CuratorCache;
import org.apache.curator.framework.recipes.cache.CuratorCacheListener;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;public class TestCuratorCache {private final static String CLUSTER_CONNECT_STR="114.132.46.145:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curator= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curator.start();assert curator.getState().equals(CuratorFrameworkState.STARTED);curator.blockUntilConnected();if(curator.checkExists().forPath("/father") != null) {curator.delete().deletingChildrenIfNeeded().forPath("/father");}// 创建CuratorCache实例,基于路径/father/son/grandson1(这里说的路径都是基于命名空间下的路径)// 缓存构建选项是SINGLE_NODE_CACHECuratorCache cache = CuratorCache.build(curator, "/father/son/grandson1",CuratorCache.Options.SINGLE_NODE_CACHE);// 创建一系列CuratorCache监听器,都是通过lambda表达式指定CuratorCacheListener listener = CuratorCacheListener.builder()// 初始化完成时调用.forInitialized(() -> System.out.println("[forInitialized] : Cache initialized"))// 添加或更改缓存中的数据时调用.forCreatesAndChanges((oldNode, node) -> System.out.printf("[forCreatesAndChanges] : Node changed: Old: [%s] New: [%s]\n",oldNode, node))// 添加缓存中的数据时调用.forCreates(childData -> System.out.printf("[forCreates] : Node created: [%s]\n", childData))// 更改缓存中的数据时调用.forChanges((oldNode, node) -> System.out.printf("[forChanges] : Node changed: Old: [%s] New: [%s]\n",oldNode, node))// 删除缓存中的数据时调用.forDeletes(childData -> System.out.printf("[forDeletes] : Node deleted: data: [%s]\n", childData))// 添加、更改或删除缓存中的数据时调用.forAll((type, oldData, data) -> System.out.printf("[forAll] : type: [%s] [%s] [%s]\n", type, oldData, data)).build();// 给CuratorCache实例添加监听器cache.listenable().addListener(listener);// 启动CuratorCachecache.start();// 创建节点/father/son/grandson1curator.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/father/son/grandson1", "data".getBytes());// 创建节点/father/son/grandson1/testcurator.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/father/son/grandson1/test", "test".getBytes());// 创建节点/father/son/grandson1/test/test2curator.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/father/son/grandson1/test/test2", "test2".getBytes());// 更改节点/father/son/grandson1的数据curator.setData().forPath("/father/son/grandson1", "new data".getBytes());// 更改节点/father/son/grandson1/test的数据curator.setData().forPath("/father/son/grandson1/test", "new test".getBytes());// 删除节点/father/son/grandson1curator.delete().deletingChildrenIfNeeded().forPath("/father/son/grandson1");Thread.sleep(10000000);}
}
二、Zookeeper在分布式命名服务中的实战
所谓命名服务,其实就是为系统中的资源提供标识能力,被命名的服务比如是:集群中的某个机器,提供服务的地址或者远程对象。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。典型的,用到了分布式命名服务的场景有:
- 分布式API目录
- 分布式节点命名
- 分布式ID生成器
2.1 分布式API目录
分布式API目录,即:为分布式系统中各种API接口服务的名称、链接地址,提供类似JNDI(Java命名和目录接口)中的文件系统的功能。借助于ZooKeeper的树形分层结构就能提供分布式的API调用功能。
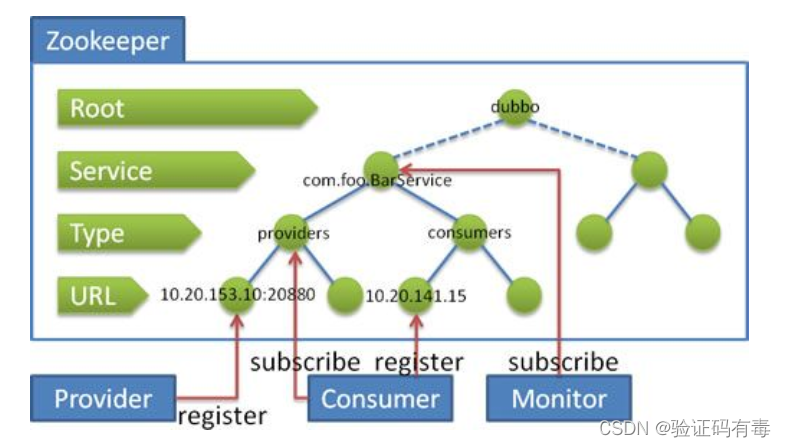
在Dubbo中,就是使用了当前方式。使用ZooKeeper维护的全局服务接口API的地址列表。大致的思路为:
- 服务提供者(Service Provider)在启动的时候,向ZooKeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址,这个操作就相当于服务的公开。
- 服务消费者(Consumer)启动的时候,订阅节点/dubbo/{serviceName}/providers下的服务提供者的URL地址,获得所有服务提供者的API
大概的模型图如下:
2.2 分布式节点的命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的,而是不断动态变化的。比如说,当业务不断膨胀和流量洪峰到来时,大量的节点可能会动态加入到集群中。而一旦流量洪峰过去了,就需要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。
如何为大量的动态节点命名呢?一种简单的办法是可以通过配置文件,手动为每一个节点命名。但是,如果节点数据量太大,或者说变动频繁,手动命名则是不现实的,这就需要用到分布式节点的命名服务。
可用于生成集群节点的编号的方案:
- 使用数据库的自增ID特性,用数据表存储机器的MAC地址或者IP来维护
- 使用ZooKeeper持久顺序节点的顺序特性来维护节点的NodeId编号
在第2种方案中,集群节点命名服务的基本流程是:
- 启动节点服务,连接ZooKeeper,检查命名服务根节点是否存在,如果不存在,就创建系统的根节点
- 在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统中节点的NODEID
- 如果临时节点太多,可以根据需要删除临时顺序ZNode节点
2.3 分布式的ID生成器
在分布式系统中,分布式ID生成器的使用场景非常之多:
- 大量的数据记录,需要分布式ID。
- 大量的系统消息,需要分布式ID。
- 大量的请求日志,如restful的操作记录,需要唯一标识,以便进行后续的用户行为分析和调用链路分析。
- 分布式节点的命名服务,往往也需要分布式ID。
- … …
传统的数据库自增主键已经不能满足需求。在分布式系统环境中,迫切需要一种全新的唯一ID系统,这种系统需要满足以下需求:
- 全局唯一:不能出现重复ID
- 高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响
市面上,分布式的ID生成器方案大致如下:
- Java的UUID
- 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID
- Twitter的SnowFlake算法(雪花算法)
- ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID
- MongoDb的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID
我们这里介绍一下,基于Zookeeper实现分布式ID生成器
基于Zookeeper实现分布式ID生成器
在ZooKeeper节点的四种类型中,其中有以下两种类型具备自动编号的能力:
PERSISTENT_SEQUENTIAL持久化顺序节点EPHEMERAL_SEQUENTIAL临时顺序节点
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编号,会记录每个子节点创建的先后顺序,这个顺序编号是分布式同步的,也是全局唯一的。
可以通过创建ZooKeeper的临时顺序节点的方法,生成全局唯一的ID:
@Slf4j
public class IDMaker extends CuratorBaseOperations {private String createSeqNode(String pathPefix) throws Exception {CuratorFramework curatorFramework = getCuratorFramework();//创建一个临时顺序节点String destPath = curatorFramework.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(pathPefix);return destPath;}public String makeId(String path) throws Exception {String str = createSeqNode(path);if(null != str){//获取末尾的序号int index = str.lastIndexOf(path);if(index>=0){index+=path.length();return index<=str.length() ? str.substring(index):"";}}return str;}
}@Test
public void testMarkId() throws Exception {IDMaker idMaker = new IDMaker();idMaker.init();String pathPrefix = "/idmarker/id-";for(int i=0;i<5;i++){new Thread(()->{for (int j=0;j<10;j++){String id = null;try {id = idMaker.makeId(pathPrefix);log.info("{}线程第{}个创建的id为{}",Thread.currentThread().getName(),j,id);} catch (Exception e) {e.printStackTrace();}}},"thread"+i).start();}Thread.sleep(Integer.MAX_VALUE);
}
测试结果如下:

基于Zookeeper实现SnowFlakeID算法
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字,这个64bit被划分成四个部分,其中后面三个部分分别表示时间戳、工作机器ID、序列号。

SnowFlakeID的四个部分,具体介绍如下:
1)第一位:占用1 bit,其值始终是0,没有实际作用
2)时间戳:占用41 bit,精确到毫秒,总共可以容纳约69年的时间
3)工作机器id:占用10 bit,最多可以容纳1024个节点
4)序列号:占用12 bit。这个值意味着,在同一毫秒同一节点上,可以生成4096个id,这已经是相当可观了
在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒最多可以生成的ID数量为: 1024 * 4096 =4194304,在绝大多数并发场景下都是够用的。
SnowFlake算法的优点:
- 生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性
- 容量大,每秒可生成几百万个ID
- ID呈趋势递增,后续插入数据库的索引树时,性能较高
SnowFlake算法的缺点:
- 依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序
- 在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险
基于ZK实现雪花算法的代码示例如下:(体现在第三部分机器id上)
public class SnowflakeIdGenerator {/*** 单例*/public static SnowflakeIdGenerator instance =new SnowflakeIdGenerator();/*** 初始化单例** @param workerId 节点Id,最大8091* @return the 单例*/public synchronized void init(long workerId) {if (workerId > MAX_WORKER_ID) {// zk分配的workerId过大throw new IllegalArgumentException("woker Id wrong: " + workerId);}instance.workerId = workerId;}private SnowflakeIdGenerator() {}/*** 开始使用该算法的时间为: 2017-01-01 00:00:00*/private static final long START_TIME = 1483200000000L;/*** worker id 的bit数,最多支持8192个节点*/private static final int WORKER_ID_BITS = 13;/*** 序列号,支持单节点最高每毫秒的最大ID数1024*/private final static int SEQUENCE_BITS = 10;/*** 最大的 worker id ,8091* -1 的补码(二进制全1)右移13位, 然后取反*/private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);/*** 最大的序列号,1023* -1 的补码(二进制全1)右移10位, 然后取反*/private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);/*** worker 节点编号的移位*/private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;/*** 时间戳的移位*/private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;/*** 该项目的worker 节点 id*/private long workerId;/*** 上次生成ID的时间戳*/private long lastTimestamp = -1L;/*** 当前毫秒生成的序列*/private long sequence = 0L;/*** Next id long.** @return the nextId*/public Long nextId() {return generateId();}/*** 生成唯一id的具体实现*/private synchronized long generateId() {long current = System.currentTimeMillis();if (current < lastTimestamp) {// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1return -1;}if (current == lastTimestamp) {// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1sequence = (sequence + 1) & MAX_SEQUENCE;if (sequence == MAX_SEQUENCE) {// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳current = this.nextMs(lastTimestamp);}} else {// 当前的时间戳已经是下一个毫秒sequence = 0L;}// 更新上次生成id的时间戳lastTimestamp = current;// 进行移位操作生成int64的唯一ID//时间戳右移动23位long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;//workerId 右移动10位long workerId = this.workerId << WORKER_ID_SHIFT;return time | workerId | sequence;}/*** 阻塞到下一个毫秒*/private long nextMs(long timeStamp) {long current = System.currentTimeMillis();while (current <= timeStamp) {current = System.currentTimeMillis();}return current;}
}
三、zookeeper实现分布式队列
常见的消息队列有:RabbitMQ,RocketMQ,Kafka等。Zookeeper作为一个分布式的小文件管理系统,同样能实现简单的队列功能。但是Zookeeper不适合大数据量存储,官方并不推荐作为队列使用,但由于实现简单,集群搭建较为便利,因此在一些吞吐量不高的小型系统中还是比较好用的。
3.1 设计思路
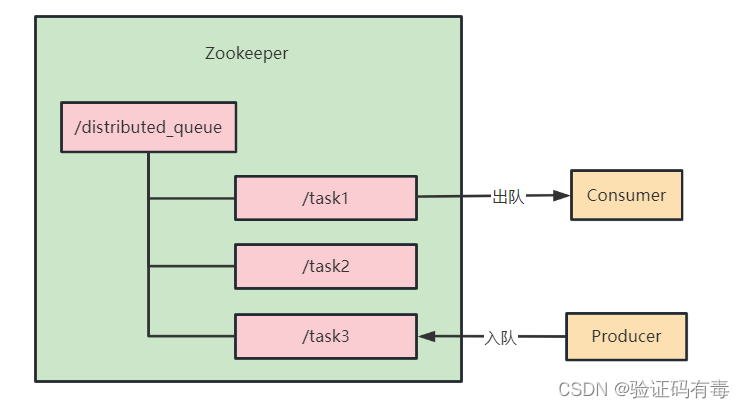
- 创建队列根节点:在Zookeeper中创建一个持久节点,用作队列的根节点。所有队列元素的节点将放在这个根节点下
- 实现入队操作:当需要将一个元素添加到队列时,可以在队列的根节点下创建一个临时有序节点。节点的数据可以包含队列元素的信息
- 实现出队操作:当需要从队列中取出一个元素时,可以执行以下操作:
- 获取根节点下的所有子节点
- 找到具有最小序号的子节点
- 获取该节点的数据
- 删除该节点
- 返回节点的数据
代码示例如下:
/*** 入队* @param data* @throws Exception*/
public void enqueue(String data) throws Exception {// 创建临时有序子节点zk.create(QUEUE_ROOT + "/queue-", data.getBytes(StandardCharsets.UTF_8),ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}/*** 出队* @return* @throws Exception*/
public String dequeue() throws Exception {while (true) {List<String> children = zk.getChildren(QUEUE_ROOT, false);if (children.isEmpty()) {return null;}Collections.sort(children);for (String child : children) {String childPath = QUEUE_ROOT + "/" + child;try {byte[] data = zk.getData(childPath, false, null);zk.delete(childPath, -1);return new String(data, StandardCharsets.UTF_8);} catch (KeeperException.NoNodeException e) {// 节点已被其他消费者删除,尝试下一个节点}}}
}
3.2 使用Apache Curator实现分布式队列
Apache Curator是一个ZooKeeper客户端的封装库,提供了许多高级功能,包括分布式队列。
public class CuratorDistributedQueueDemo {private static final String QUEUE_ROOT = "/curator_distributed_queue";public static void main(String[] args) throws Exception {CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181",new ExponentialBackoffRetry(1000, 3));client.start();// 定义队列序列化和反序列化QueueSerializer<String> serializer = new QueueSerializer<String>() {@Overridepublic byte[] serialize(String item) {return item.getBytes();}@Overridepublic String deserialize(byte[] bytes) {return new String(bytes);}};// 定义队列消费者QueueConsumer<String> consumer = new QueueConsumer<String>() {@Overridepublic void consumeMessage(String message) throws Exception {System.out.println("消费消息: " + message);}@Overridepublic void stateChanged(CuratorFramework curatorFramework, ConnectionState connectionState) {}};// 创建分布式队列DistributedQueue<String> queue = QueueBuilder.builder(client, consumer, serializer, QUEUE_ROOT).buildQueue();queue.start();// 生产消息for (int i = 0; i < 5; i++) {String message = "Task-" + i;System.out.println("生产消息: " + message);queue.put(message);Thread.sleep(1000);}Thread.sleep(10000);queue.close();client.close();}
}
学习总结
- 学习了zookeeper客户端Curator的使用
感谢
感谢【51CTO博客】大佬【作者:ITKaven】的文章。《ZooKeeper : Curator框架之数据缓存与监听CuratorCache》
相关文章:
【Zookeeper专题】Zookeeper经典应用场景实战(一)
目录 前置知识课程内容一、Zookeeper Java客户端实战1.1 Zookeeper 原生Java客户端使用1.2 Curator开源客户端使用快速开始使用示例 二、Zookeeper在分布式命名服务中的实战2.1 分布式API目录2.2 分布式节点的命名2.3 分布式的ID生成器 三、zookeeper实现分布式队列3.1 设计思路…...
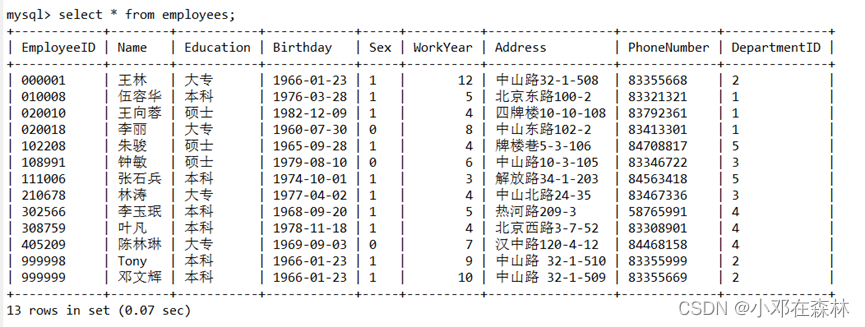
【数据库——MySQL】(15)存储过程、存储函数和事务处理习题及讲解
目录 1. 题目1.1 存储过程1.2 存储函数1.3 事务处理 2. 解答2.1 存储过程2.2 存储函数2.3 事务处理 1. 题目 1.1 存储过程 创建表 RandNumber :字段:id 自增长, data int; 创建存储过程向表中插入指定个数的随机数(1-…...

FFmpeg:打印音/视频信息(Meta信息)
多媒体文件基本概念 多媒体文件其实是个容器在容器里面有很多流(Stream/Track)每种流是由不同的编码器编码的从流中读出的数据称为包在一个包中包含着一个或多个帧 几个重要的结构体 AVFormatContextAVStreamAVPacket FFmpeg操作流数据的基本步骤 打印音/视频信息(Meta信息…...

1.Linux入门基本指令
个人主页:Lei宝啊 愿所有美好如期而遇 目录 01.ls指令 02.pwd指令 03.cd指令 04.touch指令 05.mkdir指令(重要) 06.rmdir&&rm指令(重要) 07.man指令(重要) 08.cp指令(重要) 09.mv指令(重要) 10.cat指令 nano指令 echo指令 输出重定向 追加重…...
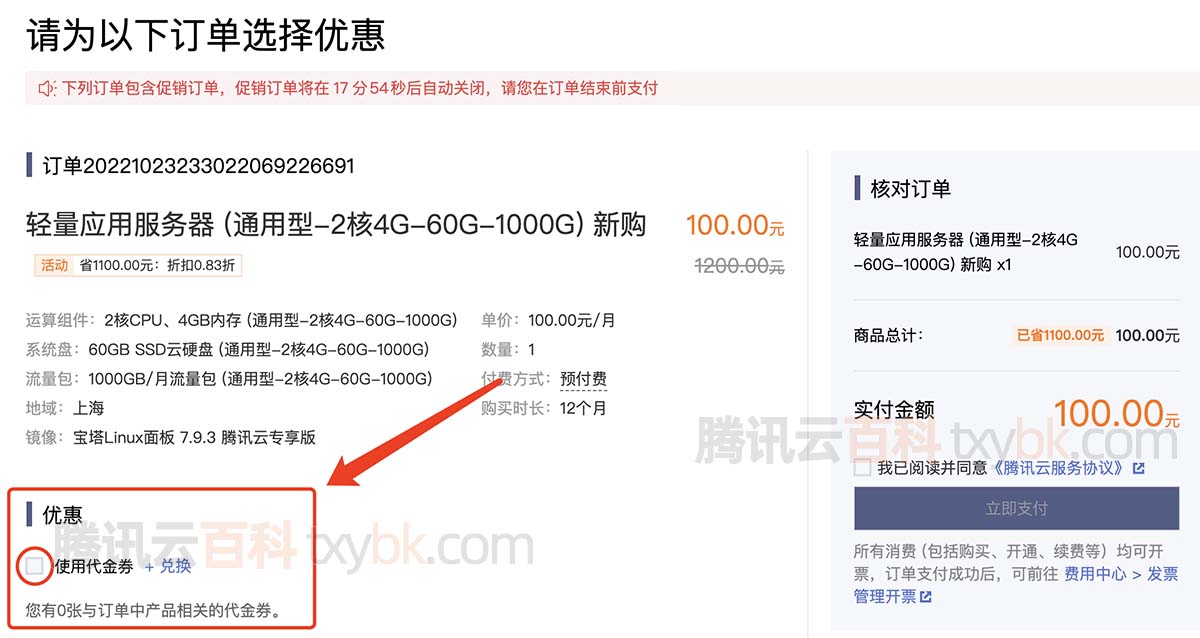
2023腾讯云服务器优惠代金券领取、查询及使用说明
腾讯云代金券领取渠道有哪些?腾讯云官网可以领取、官方媒体账号可以领取代金券、完成任务可以领取代金券,大家也可以在腾讯云百科蹲守代金券,因为腾讯云代金券领取渠道比较分散,腾讯云百科txybk.com专注汇总优惠代金券领取页面&am…...
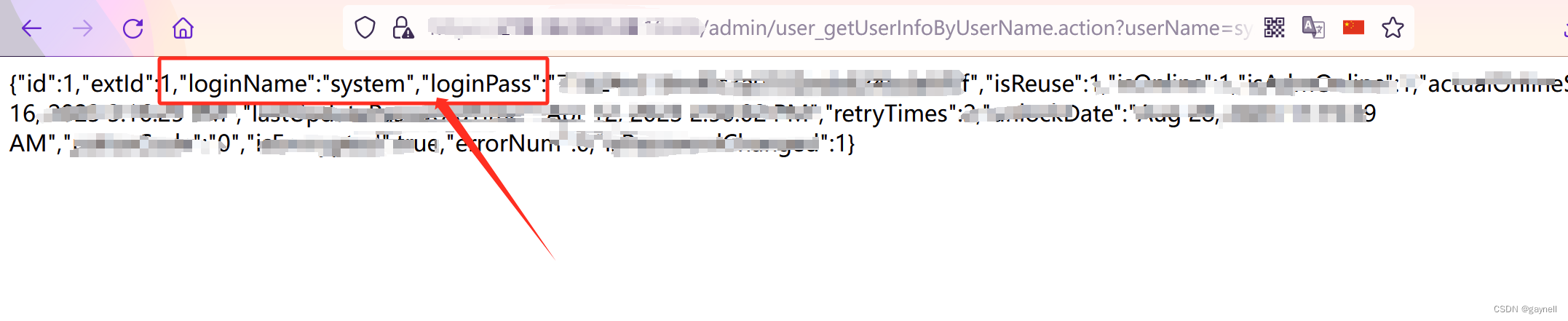
大华智慧园区管理平台任意密码读取漏洞 复现
文章目录 大华智慧园区管理平台任意密码读取漏洞 复现0x01 前言0x02 漏洞描述0x03 影响平台0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 大华智慧园区管理平台任意密码读取漏洞 复现 0x01 前言 免责声明:请勿利用文章内的相关技术从事非法测试&…...
【C++ 学习 ㉖】- 位图详解(哈希扩展)
目录 一、位图的概念 二、位图的实现 2.1 - bitset.h 2.2 - test.cpp 三、位图的应用 3.1 - 例题一 3.2 - 例题二 一、位图的概念 假设有这样一个需求:在 100 亿个整型数字中快速查询某个数是否存在其中,并假设是 32 位操作系统,4 GB…...

天启科技联创郭志强:趟遍教育行业信数化沟坎,创业智能赛道重塑行业生态
郭志强 天启科技联合创始人 近20年互联网、企业信息化、数字化实施、管理及培训经验。对于集团型企业及初创企业、传统企业及互联网企业的信息化、数字化转型有自己独到的见解和实操经验。具备跨区域、集团化信息规划、解决方案、系统架构及企业流程搭建、优化和技术团队管理能…...
Cuckoo沙箱各Ubuntu版本安装及使用
1.沙箱简介 1.1 沙箱 沙箱是一个虚拟系统程序,允许你在沙箱环境中运行浏览器或其他程序,因此运行所产生的变化可以随后删除。它创造了一个类似沙盒的独立作业环境,在其内部运行的程序并不能对硬盘产生永久性的影响。 在网络安全中ÿ…...

什么是mvvm模式,优点是什么
MVVM(Model-View-ViewModel)模式是一种设计模式。它是一种开发模式,旨在分离用户界面的开发和业务逻辑的开发。MVVM模式将应用程序分为三个部分: Model:它代表应用程序的数据模型和业务逻辑。 View:它代表…...

C/C++ 中的函数返回局部变量以及局部变量的地址?
C/C中,函数内部的一切变量(函数内部局部变量,形参)都是在其被调用时才被分配内存单元。形参和函数内部的局部变量的生命期和作用域都是在函数内部(static变量的生命期除外)。子函数运行结束时,所有局部变量的内存单元会被系统释放。在C中&…...
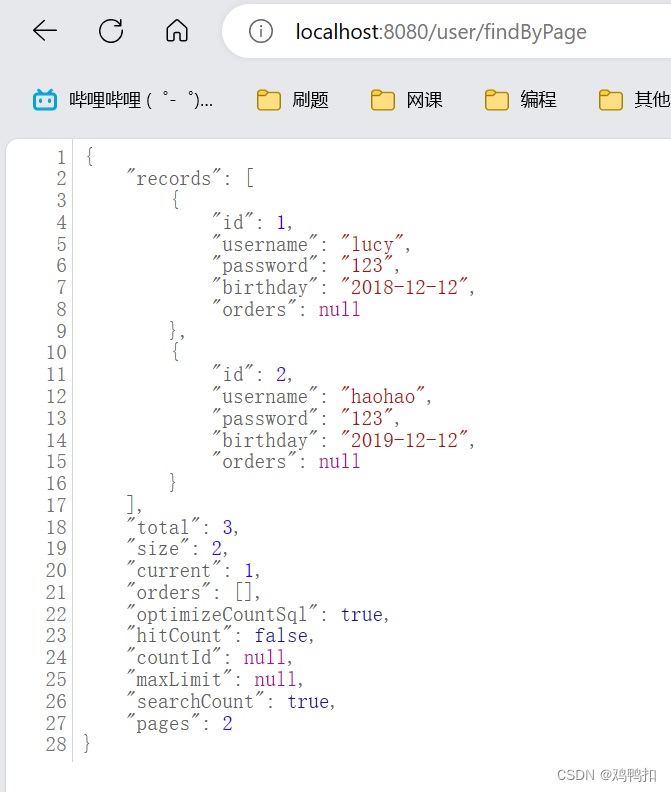
springboot和vue:七、mybatis/mybatisplus多表查询+分页查询
mybatisplus实际上只对单表查询做了增强(速度会更快),从传统的手写sql语句,自己做映射,变为封装好的QueryWrapper。 本篇文章的内容是有两张表,分别是用户表和订单表,在不直接在数据库做表连接的…...
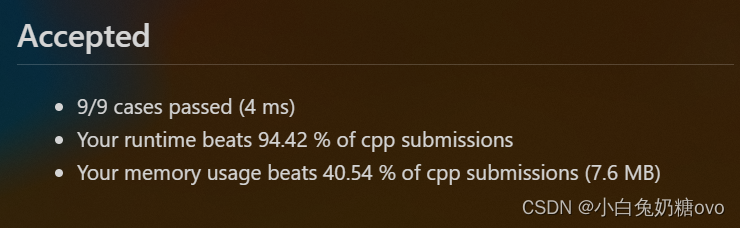
【Leetcode】 51. N 皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。 每一种…...

Java数据库连接:JDBC介绍与简单示例
Java数据库连接:JDBC介绍与简单示例 在Java程序中,操作数据库是必不可少的。JDBC(Java Database Connectivity)是Java中用于连接和操作数据库的一种技术。通过JDBC,Java程序可以与各种关系型数据库进行交互࿰…...

智慧茶园:茶厂茶园监管可视化视频管理系统解决方案
一、方案背景 我国是茶叶生产大国,茶叶销量全世界第一。随着经济社会的发展和人民生活水平的提高,对健康、天然的茶叶产品的消费需求量也在逐步提高。茶叶的种植、生产和制作过程工序复杂,伴随着人力成本的上升,传统茶厂的运营及…...
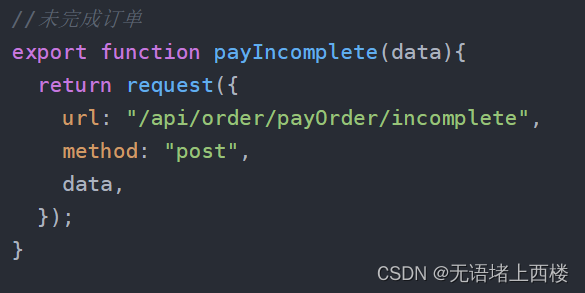
springboot整合pi支付开发
pi支付流程图: 使用Pi SDK功能发起支付由 Pi SDK 自动调用的回调函数(让您的应用服务器知道它需要发出批准 API 请求)从您的应用程序服务器到 Pi 服务器的 API 请求以批准付款(让 Pi 服务器知道您知道此付款)Pi浏览器向…...
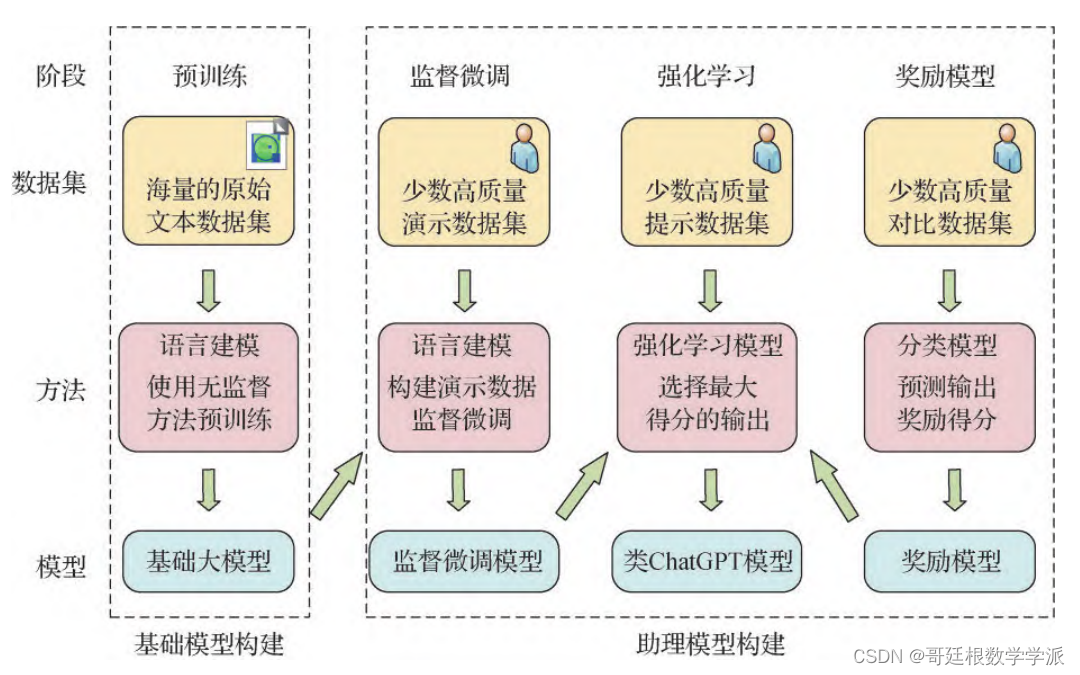
类 ChatGPT 模型存在的局限性
尽管类ChatGPT模型经过数月的迭代和完善,已经初步融入了部分领域以及人们的日常生活,但目前市面上的产品和相关技术仍然存在一些问题,以下列出一些局限性进行详细说明与成因分析: 1)互联网上高质量、大规模、经过清洗…...

Nginx的安全控制
安全控制 关于web服务器的安全是比较大的一个话题,里面所涉及的内容很多,Nginx反向代理是安全隔离来提升web服务器的安全,通过代理分开了客户端到应用程序服务器端的连接,实现了安全措施。在反向代理之前设置防火墙,…...

字符串与字符编码 - GO语言从入门到实战
字符串与字符编码 - GO语言从入门到实战 字符串 与其他主要编程语⾔的差异 基本数据类型:string 是基础数据类型,而不是引用类型或指针类型。string 在内存中占用的空间大小是固定的,且只读、不可改变。字节切片:string 是只读…...

12P4375X042-233C KJ2005X1-BA1 CE3007 EMERSON servo controller
12P4375X042-233C KJ2005X1-BA1 CE3007 EMERSON servo controller 我们提供三种不同类别的EDGEBoost I/O模块供选择,以实现最大程度的I/O定制: 数字和模拟输入/输出网络和连接边缘人工智能和存储 利用EDGEBoost I/O实现变革性技术 EBIO-2M2BK EBIO-2M2BK载板支持…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...