Google云平台构建数据ETL任务的最佳实践
在数据处理中,我们经常需要构建ETL的任务,对数据进行加载,转换处理后再写入到数据存储中。Google的云平台提供了多种方案来构建ETL任务,我也研究了一下这些方案,比较方案之间的优缺点,从而找到一个最适合我业务场景的方案。
假设我们的业务场景需要定期从Kafka中获取数据,经过一些数据清洗,数据关联,数据Enrich操作之后,把数据写入到Bigquery数据仓库,从而方便以后生成统计分析报表。
Google云平台提供了几个方案来完成这个任务:
1. Datafusion,通过在UI界面设计ETL pipeline,然后把Pipeline转换为Spark应用,部署在Dataproc上运行。
2. 编写Spark应用代码,然后在Dataproc上运行或者在K8S集群上通过Spark operator来调度执行。
3. 编写Apache Beam代码,通过Dataflow runner在VM上执行任务。
方案一的优点是基本不需要编写代码,在图形界面上即可完成Pipeline的设计。缺点是如果有一些额外的需求可能不太方便实现,另外最主要是太贵。Datafusion需要单独部署在一个Instance上24小时运行,这个Instance企业版的收费大概一小时要几美元。另外Pipeline运行的时候会调度Dataproc的Instance,这里会产生额外的费用。
方案二的优点是可以灵活的通过Spark代码来完成各种需求。缺点也是比较贵,因为Dataproc是基于Hadoop集群的,需要有Zookeeper, driver和executor这几个VM。如果采用K8S集群,则Spark operator也是需要单独24小时运行在一个pod上,另外还有额外的driver, executor的Pod需要调度执行。
方案三是综合考虑最优的方案,因为Beam的代码是提供了一个通用的流批处理框架,可以运行在Spark,Flink,Dataflow等引擎上,而Dataflow是Google提供的一个优秀的引擎,在运行任务时,Dataflow按需调度VM来运行,只收取运行时的费用。
因此,对于我的这个业务场景,使用方案三是最合适的。下面我将介绍一下整个实现的过程。
Beam批处理任务的实现
在Dataflow的官方Template里面,有一个消费Kafka数据写入到Bigquery的例子,但是这个是流处理方式实现的,对于我的业务场景来说,并不需要这么实时的处理数据,只需要定期消费即可,因此用批处理的方式更合适,这样也能大幅节约费用。
Beam的Kafka I/O connector是默认处理的数据是无边界的,即流式数据。要以批处理的方式来处理,需要调用withStartReadTime和withStopReadTime两个方法获取要读取的Kafka topic的start和end offset,这样就可以把数据转换为有边界数据。调用这两个方法需要注意的是,如果Kafka没有任何一条消息的时间戳是大于等于这个时间戳的话,那么会报错,因此我们需要确定一下具体的时间戳。
以下的代码是检查Kafka消息的所有分区是否存在消息的时间戳是大于我们指定的时间戳,如果不存在的话,那么我们需要找出这些分区里面的最晚时间戳里面的最早的一个。例如Topic有3个分区,要指定的时间戳是1697289783000,但是3个分区里面的所有消息都小于这个时间戳,因此我们需要分别找出每个分区里面的消息的最晚的时间戳,然后取这3个分区的最晚时间戳里面最早的那个,作为我们的指定时间戳。
public class CheckKafkaMsgTimestamp {private static final Logger LOG = LoggerFactory.getLogger(CheckKafkaMsgTimestamp.class);public static KafkaResult getTimestamp(String bootstrapServer, String topic, long startTimestamp, long stopTimestamp) {long max_timestamp = stopTimestamp;long max_records = 5L;Properties props = new Properties();props.setProperty("bootstrap.servers", bootstrapServer);props.setProperty("group.id", "test");props.setProperty("enable.auto.commit", "true");props.setProperty("auto.commit.interval.ms", "1000");props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// Get all the partitions of the topicint partition_num = consumer.partitionsFor(topic).size();HashMap<TopicPartition, Long> search_map = new HashMap<>();ArrayList<TopicPartition> tp = new ArrayList<>();for (int i=0;i<partition_num;i++) {search_map.put(new TopicPartition(topic, i), stopTimestamp);tp.add(new TopicPartition(topic, i));}// Check if message exist with timestamp greater than search timestampBoolean flag = true;ArrayList<TopicPartition> selected_tp = new ArrayList<>();//LOG.info("Start to check the timestamp {}", stopTimestamp);Map<TopicPartition, OffsetAndTimestamp> results = consumer.offsetsForTimes(search_map);for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : results.entrySet()) {OffsetAndTimestamp value = entry.getValue();if (value==null) { //there is at least one partition don't have timestamp greater or equal to the stopTimeflag = false;break;}}// Get the latest timestamp of all partitions if the above check result is false// Note the timestamp is the earliest of all the partitions. if (!flag) {max_timestamp = 0L;consumer.assign(tp);Map<TopicPartition, Long> endoffsets = consumer.endOffsets(tp);for (Map.Entry<TopicPartition, Long> entry : endoffsets.entrySet()) {Long temp_timestamp = 0L;int record_count = 0;TopicPartition t = entry.getKey();long offset = entry.getValue();if (offset < 1) {LOG.warn("Can not get max_timestamp as partition has no record!");continue;}consumer.assign(Arrays.asList(t));consumer.seek(t, offset>max_records?offset-5:0);Iterator<ConsumerRecord<String, String>> records = consumer.poll(Duration.ofSeconds(2)).iterator();while (records.hasNext()) {record_count++;ConsumerRecord<String, String> record = records.next();LOG.info("Topic: {}, Record Timestamp: {}, recordcount: {}", t, record.timestamp(), record_count);if (temp_timestamp == 0L || record.timestamp() > temp_timestamp) {temp_timestamp = record.timestamp();}}//LOG.info("Record count: {}", record_count);if (temp_timestamp > 0L && temp_timestamp > startTimestamp) {if (max_timestamp == 0L || max_timestamp > temp_timestamp) {max_timestamp = temp_timestamp;}selected_tp.add(t);LOG.info("Temp_timestamp {}", temp_timestamp);LOG.info("Selected topic partition {}", t);LOG.info("Partition offset {}", consumer.position(t));//consumer.seek(t, -1L);}}} else {selected_tp = tp;}consumer.close();LOG.info("Max Timestamp: {}", max_timestamp);return new KafkaResult(max_timestamp, selected_tp);}
}调用以上代码,我们可以获取要选择的分区以及对应的时间戳。利用这两个信息,我们就可以把指定时间范围内的Kafka数据转换为有边界数据了。以下是Beam建立Pipeline并处理数据,然后写入到Bigquery的代码:
KafkaResult checkResult = CheckKafkaMsgTimestamp.getTimestamp(options.getBootstrapServer(), options.getInputTopic(), start_read_time, stop_read_time);
stop_read_time = checkResult.max_timestamp;
ArrayList<TopicPartition> selected_tp = checkResult.selected_tp;PCollection<String> input = pipeline.apply("Read messages from Kafka",KafkaIO.<String, String>read().withBootstrapServers(options.getBootstrapServer()).withKeyDeserializer(StringDeserializer.class).withValueDeserializer(StringDeserializer.class).withConsumerConfigUpdates(ImmutableMap.of("group.id", "telematics_statistic.app", "enable.auto.commit", true)).withStartReadTime(Instant.ofEpochMilli(start_read_time)).withStopReadTime(Instant.ofEpochMilli(stop_read_time)).withTopicPartitions(selected_tp).withoutMetadata()).apply("Get message contents", Values.<String>create());PCollectionTuple msgTuple = input.apply("Filter message", ParDo.of(new DoFn<String, TelematicsStatisticsMsg>() {@ProcessElementpublic void processElement(@Element String element, MultiOutputReceiver out) {TelematicsStatisticsMsg msg = GSON.fromJson(element, TelematicsStatisticsMsg.class);if (msg.timestamp==0 || msg.vin==null) {out.get(otherMsgTag).output(element);} else {if (msg.timestamp<start_process_time || msg.timestamp>=stop_process_time) {out.get(otherMsgTag).output(element);} else {out.get(statisticsMsgTag).output(msg);}}}}).withOutputTags(statisticsMsgTag, TupleTagList.of(otherMsgTag))); // Get the filter out msg
PCollection<TelematicsStatisticsMsg> statisticsMsg = msgTuple.get(statisticsMsgTag);
// Save the raw records to Bigquery
statisticsMsg.apply("Convert raw records to BigQuery TableRow", MapElements.into(TypeDescriptor.of(TableRow.class)).via(TelematicsStatisticsMsg -> new TableRow().set("timestamp", Instant.ofEpochMilli(TelematicsStatisticsMsg.timestamp).toString()).set("vin", TelematicsStatisticsMsg.vin).set("service", TelematicsStatisticsMsg.service).set("type", TelematicsStatisticsMsg.messageType))).apply("Save raw records to BigQuery", BigQueryIO.writeTableRows().to(options.getStatisticsOutputTable()).withSchema(new TableSchema().setFields(Arrays.asList(new TableFieldSchema().setName("timestamp").setType("TIMESTAMP"),new TableFieldSchema().setName("vin").setType("STRING"),new TableFieldSchema().setName("service").setType("STRING"),new TableFieldSchema().setName("type").setType("STRING")))).withCreateDisposition(CreateDisposition.CREATE_IF_NEEDED).withWriteDisposition(WriteDisposition.WRITE_APPEND));PipelineResult result = pipeline.run();
try {result.getState();result.waitUntilFinish();
} catch (UnsupportedOperationException e) {// do nothing
} catch (Exception e) {e.printStackTrace();
}需要注意的是,每次处理任务完成后,我们需要把当前的stopReadTime记录下来,下次任务运行的时候把这个时间戳作为startReadTime,这样可以避免某些情况下的数据缺失读取的问题。这个时间戳我们可以把其记录在GCS的bucket里面。这里略过这部分代码。
提交Dataflow任务
之后我们就可以调用Google的Cloud Build功能来把代码打包为Flex Template
首先在Java项目中运行mvn clean package,打包jar文件
然后在命令行中设置以下环境变量:
export TEMPLATE_PATH="gs://[your project ID]/dataflow/templates/telematics-pipeline.json"
export TEMPLATE_IMAGE="gcr.io/[your project ID]/telematics-pipeline:latest"
export REGION="us-west1"之后运行gcloud build的命令来构建镜像:
gcloud dataflow flex-template build $TEMPLATE_PATH --image-gcr-path "$TEMPLATE_IMAGE" --sdk-language "JAVA" --flex-template-base-image "gcr.io/dataflow-templates-base/java17-template-launcher-base:20230308_RC00" --jar "target/telematics-pipeline-1.0-SNAPSHOT.jar" --env FLEX_TEMPLATE_JAVA_MAIN_CLASS="com.example.TelematicsBatch"最后就可以调用命令来提交任务执行了:
gcloud dataflow flex-template run "analytics-pipeline-`date +%Y%m%d-%H%M%S`" --template-file-gcs-location "$TEMPLATE_PATH" --region "us-west1" --parameters ^~^bootstrapServer="kafka-1:9094,kafka-2:9094"~statisticsOutputTable="youprojectid:dataset.tablename"~serviceAccount="xxx@projectid.iam.gserviceaccount.com"~region="us-west1"~usePublicIps=false~runner=DataflowRunner~subnetwork="XXXX"~tempLocation=gs://bucketname/temp/~startTime=1693530000000~stopTime=1697216400000~processStartTime=1693530000000~processStopTime=1697216400000如果我们需要任务自动定期执行,还可以在dataflow里面import一个Pipeline,用之前指定的Template_path来导入。然后设置任务的定期周期和启动时间即可,非常方便。
相关文章:

Google云平台构建数据ETL任务的最佳实践
在数据处理中,我们经常需要构建ETL的任务,对数据进行加载,转换处理后再写入到数据存储中。Google的云平台提供了多种方案来构建ETL任务,我也研究了一下这些方案,比较方案之间的优缺点,从而找到一个最适合我…...
)
【更新】囚生CYの备忘录(202331014~)
文章目录 20221014 20221014 本以为下午怡宝的比赛至少是能跑到前三,结果连前五都没混到,赛前都知道路线不可能有5km,因为即便是绕着主校区最外沿跑一圈也才4km出头,我估摸着大概是2500米,结果实际上只有1700米&#x…...
《UnityShader入门精要》学习4
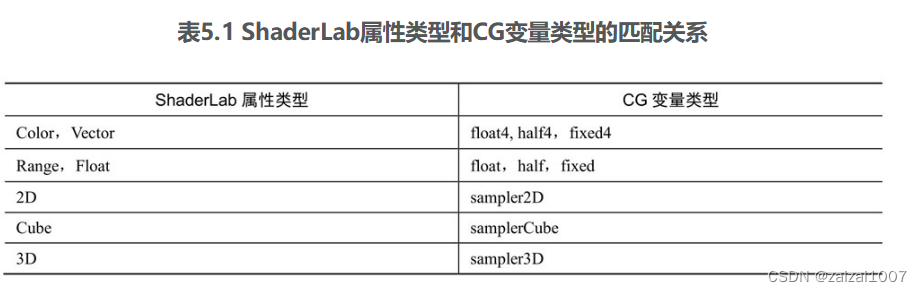
一个最简单的顶点/片元着色器 一个最简单的顶点/片元着色器 Unity Shader的基本结构。它包含了Shader、Properties、SubShader、Fallback等语义块。顶点/片元着色器的结构与之大体类似 Shader "MyShaderName" {Properties {// 属性}SubShader {// 针对显卡A的S…...
kaggle新赛:写作质量预测大赛【数据挖掘】
赛题名称:Linking Writing Processes to Writing Quality 赛题链接:https://www.kaggle.com/competitions/linking-writing-processes-to-writing-quality 赛题背景 写作过程中存在复杂的行为动作和认知活动,不同作者可能采用不同的计划修…...

导入导出Excel
Springboot Easyexcel导入导出excel EasyExcel 的导出导入支持两种方式进行处理*easyexcel 导出不用监听器,导入需要写监听器* 一、导入:简单实现1. 导入依赖,阿里的easyexcel插件2. 程序2-1. 实体类:2-2. 定义一个 监听类&#…...

C# Thread.Sleep(0)有什么用?
一、理论分析 回答这个要先从线程时间精度(时间片)开始说起。很多参考书说,默认情况下,时间片为15ms 左右,但是这是已经过时的知识。在老的 Windows 操作系统里,应用程序模式时时间片 15ms 左右࿰…...

二十四、【参考素描三大面和五大调】
文章目录 三种色面(黑白灰)五种色调 这个可以参考素描对物体受光的理解:素描调子的基本规律与素描三大面五大调物体的明暗规律 三种色面(黑白灰) 如下图所示,我们可以看到光源是从亮面所对应的方向射过来的,所以我们去分析图形的时候,首先要…...

【Python 千题 —— 基础篇】进制转换:十进制转二进制
题目描述 题目描述 计算机底层原理中常使用二进制来表示相关机器码,学会将十进制数转换成二进制数是一个非常重要的技能。现在编写一个程序,输入一个十进制数,将其转换成二进制数。 输入描述 输入一个十进制数。 输出描述 程序将输入的…...

[ spring boot入门 ] java: 错误: 无效的源发行版:17
因为我目前idea中使用的是jdK8,而在pom.xml文件里是17,所以我需要将所有地方修改为jdk8 pom.xml的jdk版本为8 maven的setting.xml文件 jdk为8 还有Java Compiler 还有Project Structure 里面的project 和 module...
【计算机组成体系结构】电路基本原理与加法器设计
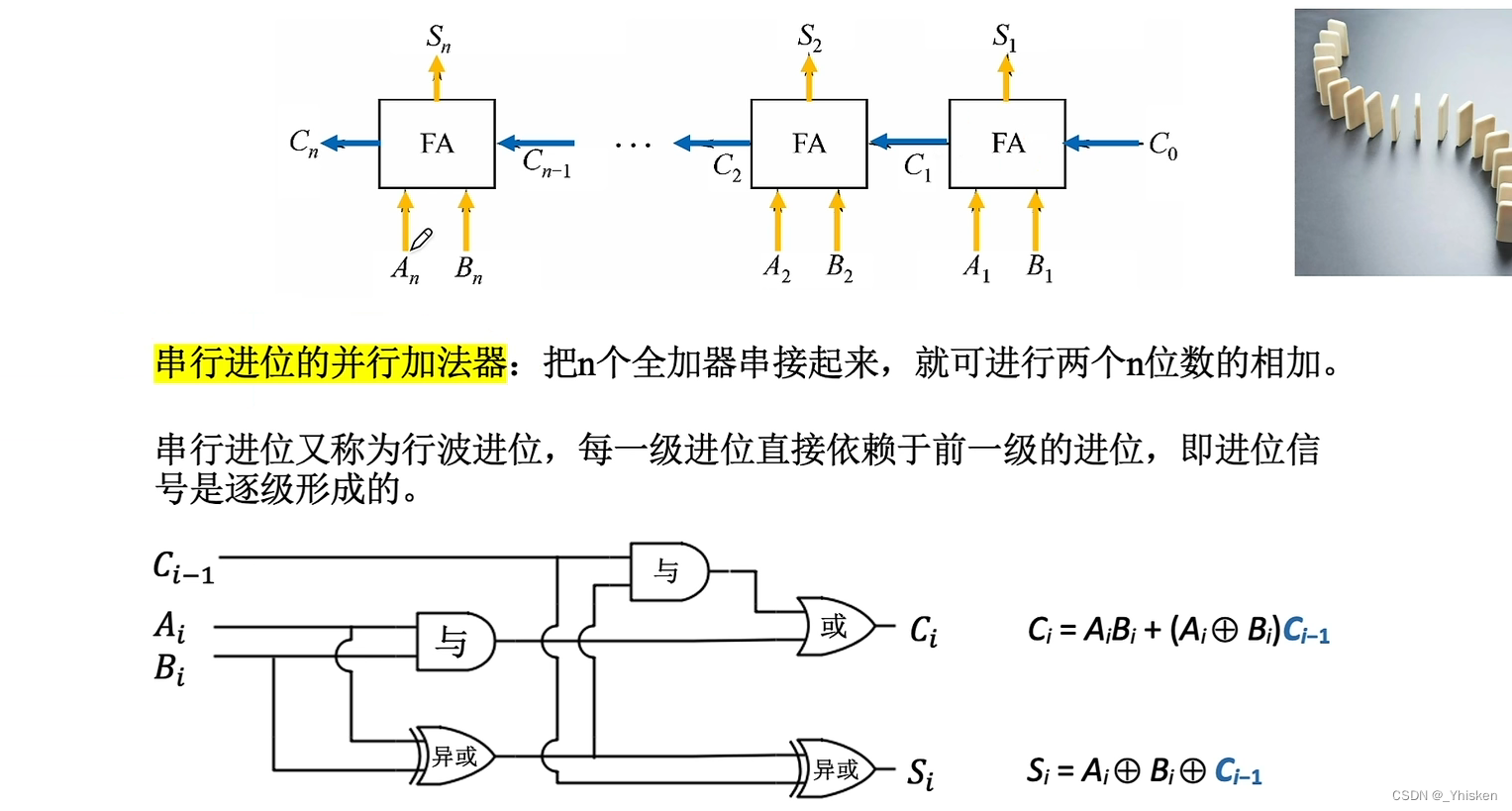
一、算术逻辑单元—ALU 1.基本的逻辑运算(1bit的运算) 基本逻辑运算分为,与、或、非。大家应该很熟悉了,与:全1为1,否则为0。或:全0为0,否则为1。非:取反。三个基本的逻…...
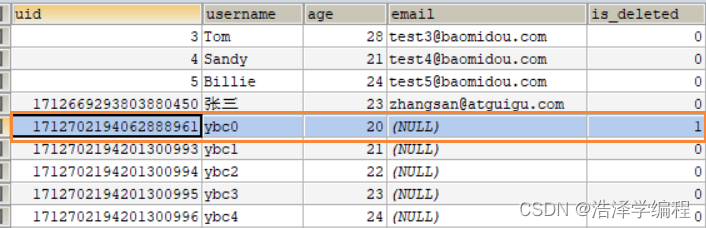
MyBatisPlus之基本CRUD、常用注解
文章目录 前言一、MyBatisPlus简介1.简介2.特性 二、基本CRUD1.依赖2.搭建基本结构3.BaseMapper4.使用插入删除(1)通过id删除记录(2)通过id批量删除记录(3)通过map条件删除记录 修改查询(1&…...

采集EtherNET/IP转Profinet在西门子plc中的应用
远创智控网关YC-EIPM-PN,让你的设备和云平台实时连接! 远创智控YC-EIPM-PN网关产品支持各种数据接口,无论是工业领域的仪表、PLC、计量设备,还是设备数据,都能实时采集并整合。它将这些设备中的运行数据、状态数据等信…...
)
Paddle build_cinn_pass_test源码阅读(fluid目录下)
代码位置在 paddle\fluid\framework\paddle2cinn\build_cinn_pass_test.cc ,因为paddle CINN和PIR部分依旧在高频更新,所以各位看到的可能和我的不一样 inline bool CheckNodeExisted(const std::unordered_set<Node*>& nodes,const std::str…...

函数调用:为什么会发生stack overflow?
在开发软件的过程中我们经常会遇到错误,如果你用 Google 搜过出错信息,那你多少应该都访问过Stack Overflow这个网站。作为全球最大的程序员问答网站,Stack Overflow 的名字来自于一个常见的报错,就是栈溢出(stack ove…...

git log
git log -p 是一个用于显示git commit历史的命令,它会展示每个commit的详细信息,包括每个修改文件的清单、添加/删除的行所在的位置以及具体的实际更改。这个命令能够让用户深入了解仓库的历史记录。 与git log相比,git log -p 提供了更多的…...

在面试提问环节应该问那些内容
在面试提问环节应该问那些内容 薪资和福利: 你可以询问关于薪资、福利和其他福利待遇的细节,包括工资结构、健康保险、退休计划、带薪休假等。 了解关于加班、绩效奖金和涨薪机会的信息。 工作时间和灵活性: 询问工作时间、工作日和工作日…...

【vb.net】轻量JSON序列及反序列化
这个代码写的有点时间了,可能有点小bug,欢迎评论区反馈 作用是将Json文本转化成一个HarryNode类进行相关的Json对象处理或者读取,也可以将一个HarryNode对象用ToString变为Json文本。 举例: 1、读取节点数据 dim harryNode N…...

【Vue】vue2与netcore webapi跨越问题解决
系列文章 C#底层库–记录日志帮助类 本文链接:https://blog.csdn.net/youcheng_ge/article/details/124187709 文章目录 系列文章前言一、技术介绍二、问题描述三、问题解决3.1 方法一:前端Vue修改3.2 方法二:后端允许Cors跨越访问 四、资源…...
SpringSecurity + jwt + vue2 实现权限管理 , 前端Cookie.set() 设置jwt token无效问题(已解决)
问题描述 今天也是日常写程序的一天 , 还是那个熟悉的IDEA , 还是那个熟悉的Chrome浏览器 , 还是那个熟悉的网站 , 当我准备登录系统进行登录的时候 , 发现会直接重定向到登录页 , 后端也没有报错 , 前端也没有报错 , 于是我得脸上又多了一张痛苦面具 , 紧接着在前端疯狂debug…...

【21】c++设计模式——>装饰模式
装饰模式的定义 装饰模式也可以称为封装模式,所谓的封装就是在原有行为之上进行扩展,并不会改变该行为; 例如网络通信: 在进行网络通信的时候,数据是基于IOS七层或四层网络模型(某些层合并之后就是四层模型…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...