特征向量中心度(eigenvector centrality)算法原理与源码解析
前言
随着图谱应用的普及,图深度学习技术也逐渐被越来越多的数据挖掘团队所青睐。传统机器学习主要是对独立同分布个体的统计学习,而图深度学习则是在此基础上扩展到了非欧式空间的图数据之上,通过借鉴NLP和CV方向的模型思想,衍生了很多对图谱这种非序列化数据的建模分析手段,帮助分析人员洞察数据之间隐含的复杂关系特征。
在深度学习技术没有普及之前,已经存在大量的图谱数据分析工作,而这些工作的主要思路是通过抽取图中节点的统计信息作为特征,并用作分类模型的输入。今天,在这里介绍的其中一个经典的图分析算法叫做特征向量中心度(eigenvector centrality),它的作用是衡量节点在整个网络中的重要性。图数据一个最常用的数据结构就是邻接矩阵,而这个算法的主要思想就是用到了矩阵分解的思想,经典的图深度学习算法GCN也是基于拉普拉斯矩阵的谱分解和傅立叶变换实现的。所以对于新人来说,特征向量中心度可以做为图数据挖掘的经典入门算法之一。
参考资料
[1] William L. Hamilton. Graph Representation Learning. Morgan and Claypool publishers, 2020
[2] Xinyu Chen. 幂迭代法[OL]. https://zhuanlan.zhihu.com/p/336250805
[3] Power method for approximating eigenvalues, https://ergodic.ugr.es/cphys/lecciones/fortran/power_method.pdf
[4] 柴静. 线性代数-山东大学. https://www.bilibili.com/video/av370427050/?p=42&vd_source=9ca707c71dee64c77d2f5f3d824e1c19
定义问题
 图片引用自 :《交网络舆情中意见领袖主题图谱构建及关系路径研究_基于网络谣言话题的分析》
图片引用自 :《交网络舆情中意见领袖主题图谱构建及关系路径研究_基于网络谣言话题的分析》
我们首先来定义特征向量中心度算法所要解决的问题。如上图所示,这是微博谣言话题中意见领袖节点关系图谱的一部分。如果用最简单直观的图统计方法来分析这个图谱,那就是使用节点的出入度的大小(有多少邻节点)来衡量这个节点在图谱中的重要性。我们可以看到”天涯历知幸“、“来去之间”和“开水族馆的XX”三位博主的出入度最高,是重要的意见领袖。但是,如果仅仅是通过博主周围的邻居节点的数量来衡量其影响力又是有失偏颇的,因为这些转发和关注的微博用户有可能是僵尸粉(现在僵尸粉都很智能的)。所以,我们还需要找到一种方式,不仅仅是通过当前节点关联的邻居节点数量来横量其重要性,还要将邻居节点本身的重要性也一起考虑进去。回到上图,“鸟窝里的猫妖”和“筆木鱼_”这两个节点虽然它的邻居节点数量很少,但是它们都关注转发了”天涯历知幸“、“来去之间”和“开水族馆的XX”三位重要博主的博文,所以他们也应该是重要的谣言传播者。
算法原理
我们先定义eue_{u}eu 节点的特征向量中心度由下面的递归等式表示:
eu=1λ∑v∈νA[u,v]ev∀u∈νe_{u} = {\frac{1}{\lambda}\sum_{v\in \nu} } A[u,v] e_{v}\;\; \forall u \in \nueu=λ1∑v∈νA[u,v]ev∀u∈ν, (1),
这个等式的意思是eue_{u}eu 节点的中心度是其周围邻节点eve_{v}ev 中心度总和的1λ\frac{1}{\lambda}λ1, 其中λ\lambdaλ是一个常量。ν\nuν是图上所有节点的集合。AAA是邻接矩阵,A∈R∣ν∣×∣ν∣A \in \mathbb{R}^{|\nu| \times |\nu|}A∈R∣ν∣×∣ν∣, A[u,v]=1A[u,v] = 1A[u,v]=1 代表节点uuu和节点vvv之间相连(节点之间存在边关系),A[u,v]=0A[u,v] = 0A[u,v]=0 代表节点uuu和节点vvv之间不相连。
从上面的式子来看,如果在一个很大的图谱上做递归运算,且图谱的度数很深,甚至存在环路,则需要非常大的栈内存,同时计算效率也不高。
那么我们再对公式进行转换,假设eee是图谱上所有节点中心度的集合,也就是
e={e1,e2,e3,……,ev}Te = \big\{e_{1},e_{2},e_{3},……, e_{v} \big\}^{T}e={e1,e2,e3,……,ev}T (2),
那么将式子(2) 代入式子 (1), 得我们可以得到下面的式子(3):
λe=Ae{\lambda}e = Aeλe=Ae (3),
我们可以发现,式子(3)就是一个典型的特征值方程,其中eee是邻接矩阵AAA的特征向量,λ{\lambda}λ是邻接矩阵的特征值。
定义:设A是n阶矩阵,λ{\lambda}λ为一个数,若存在非零向量X,使得λX=AX{\lambda}X = AXλX=AX, 则称数λ{\lambda}λ为矩阵A的特征值,非零向量X为矩阵A的对应于特征值λ{\lambda}λ的特征向量。
则我们可以将图谱领接矩阵A的特征向量eee做为其每个节点的中心度度量值。同时,我们也希望衡量节点中心度的值为正数,那么通过Perron-Frobenius定理,我们可以证明特征向量eee中的每一个分量都是正值,满足节点中心度的度量值的要求。
Perron–Frobenius定理证明了存在一个方阵,如果其行列的元素为正值,则存在最大的特征值λpf{\lambda}_{pf}λpf,并且该特征值所对应的特征向量的每个元素都是正数。
由上面的公式和定理可以得知,一个矩阵如果存在最大的特征值,那么这个特征值就是该矩阵的主特征值,其对应的特征向量则是主特征向量,并且主特征向量里面的每一个元素都是正数。我们可以将邻接矩阵A的主特征向量eee的每一个分量值,作为其节点所对应的中心度度量值,它体现了节点所连接的邻节点的数量以及所连接邻节点的重要性。
那么我们来看看特征向量的一般求法,以公式(3)为例,A是n阶邻接矩阵,移项后公式(3)可以写成
(A−λE)e=0(A-{\lambda}E)e=0(A−λE)e=0 (4),
其中EEE是n阶单位矩阵。又因为eee是非零向量,那么可以进一步得出
|A−λE|=0|A-{\lambda}E|=0|A−λE|=0 (5),
解此行列式,即公式(5),获得的值λi\lambda_iλi即为矩阵A的特征值 ,再将λi\lambda_iλi值代入公式(4)中,就可以求出对应的特征向量。
例如:A=∣1−22−2−2424−2∣A = \begin{vmatrix}1&-2&2\\-2&-2&4\\2&4&-2\end{vmatrix}A=1−22−2−2424−2
那么 |A−λE|=∣1−λ−22−2−2−λ424−2−λ∣=0|A-{\lambda}E|= \begin{vmatrix}1-\lambda&-2&2\\-2&-2-\lambda&4\\2&4&-2-\lambda\end{vmatrix}=0|A−λE|=1−λ−22−2−2−λ424−2−λ=0
=(1−λ)(2+λ)2−16−16+4(2+λ)−16(1−λ)+4(2+λ)=0=(1-\lambda)(2+\lambda)^2-16-16+4(2+\lambda)-16(1-\lambda)+4(2+\lambda)=0=(1−λ)(2+λ)2−16−16+4(2+λ)−16(1−λ)+4(2+λ)=0
=−λ3−3λ2+24λ−28=0=-\lambda^3-3\lambda^2+24\lambda-28=0=−λ3−3λ2+24λ−28=0
我们看见一个3阶矩阵的行列式方程就有3个根λ1,λ2,λ3\lambda_1,\lambda_2,\lambda_3λ1,λ2,λ3。那么如果图谱是100万的节点,那么就会组成一个100万阶的邻接矩阵,它的行列式方程将有100万个根。由此可见,我们需要找到一个更加合理的办法去求出大图的特征向量。
这时候我们要引入幂迭代 (power iteration) 法。
幂迭代 (power iteration) 法是线性代数中一种非常重要的方法,可对特征值分解和奇异值分解等问题进行求解。比较特别的是,当我们要对来自真实世界的大规模数据进行奇异值分解时,基于幂迭代法的奇异值分解在保证精度的同时可以极大提高计算效率。[2]
类似于Jacobi和Gauss-Seidel两个迭代算法,幂迭代 (power iteration) 法也是采取迭代计算的方式去得到一个近似值逼近主特征向量。假设我们有一个具有主特征值的邻接矩阵AAA,我们选取一个非零向量x0x_0x0作为矩阵AAA的主特征向量的初始向量,那么幂迭代的计算方法如下:
x1=Ax0x_1 = Ax_0x1=Ax0
x2=Ax1=A(Ax0)=A2x0x_2 = Ax_1=A(Ax_0)=A^2x_0x2=Ax1=A(Ax0)=A2x0
x3=Ax2=A(A2x0)=A3x0x_3 = Ax_2=A(A^2x_0)=A^3x_0x3=Ax2=A(A2x0)=A3x0
…………
xk=Axk−1=A(Ak−1x0)=Akx0x_k = Ax_{k-1}=A(A^{k-1}x_0)=A^kx_0xk=Axk−1=A(Ak−1x0)=Akx0
当k足够大的时候,也就是迭代次数足够多时,我们就能逼近矩阵AAA的主特征向量。
例如:有一个矩阵A=[2−121−5]A = \begin{bmatrix}2&-12\\1&-5\end{bmatrix}A=[21−12−5],且假设一个初始化的非零特征向量为x0=[11]x_0= \begin{bmatrix}1\\1\end{bmatrix}x0=[11]
使用幂迭代法,我们可以得到以下计算过程
x1=Ax0=[2−121−5][11]=[−10−4]=−4[2.501.00]x_1=Ax_0= \begin{bmatrix}2&-12\\1&-5\end{bmatrix} \begin{bmatrix}1\\1\end{bmatrix}=\begin{bmatrix}-10\\-4\end{bmatrix}=-4\begin{bmatrix}2.50\\1.00\end{bmatrix}x1=Ax0=[21−12−5][11]=[−10−4]=−4[2.501.00]
x2=Ax1=[2−121−5][−10−4]=[2810]=10[2.801.00]x_2=Ax_1= \begin{bmatrix}2&-12\\1&-5\end{bmatrix} \begin{bmatrix}-10\\-4\end{bmatrix}=\begin{bmatrix}28\\10\end{bmatrix}=10\begin{bmatrix}2.80\\1.00\end{bmatrix}x2=Ax1=[21−12−5][−10−4]=[2810]=10[2.801.00]
x3=Ax2=[2−121−5][2810]=[−64−22]=−22[2.911.00]x_3=Ax_2= \begin{bmatrix}2&-12\\1&-5\end{bmatrix} \begin{bmatrix}28\\10\end{bmatrix}=\begin{bmatrix}-64\\-22\end{bmatrix}=-22\begin{bmatrix}2.91\\1.00\end{bmatrix}x3=Ax2=[21−12−5][2810]=[−64−22]=−22[2.911.00]
…………
x6=Ax5=[2−121−5][−280−94]=[568190]=190[2.991.00]x_6=Ax_5= \begin{bmatrix}2&-12\\1&-5\end{bmatrix} \begin{bmatrix}-280\\-94\end{bmatrix}=\begin{bmatrix}568\\190\end{bmatrix}=190\begin{bmatrix}2.99\\1.00\end{bmatrix}x6=Ax5=[21−12−5][−280−94]=[568190]=190[2.991.00]
经过第6次的迭代,我们发现向量x6x_6x6的单位向量[2.991.00]\begin{bmatrix}2.99\\1.00\end{bmatrix}[2.991.00]已经十分接近矩阵AAA真实的主特征向量[31]\begin{bmatrix}3\\1\end{bmatrix}[31].
当然,随着迭代次数的增大,矩阵计算中的各分量元素在计算过程中可能会出现数值溢出,所以我们需要对每个元素进行归一化处理,幂迭代法的一般性算法可以写为:
step1: xk=Axk−1x_k = Ax_{k-1}xk=Axk−1
step2: xk=xk/∥xk∥2x_k = x_k/\|x_k\|_2xk=xk/∥xk∥2
其中,∥xk∥2\|x_k\|_2∥xk∥2是特征向量的ℓ2\ell_2ℓ2范数,意思是特征向量中所有元素的平方和再开方。
有一种观点认为,特征向量中心度是在图中进行无限长度的随机游走时,一个节点被访问到的可能性的排序,从上述的幂迭代法就可以看出这个观点依据。[1]
以上就是特征向量中心度算法的基本实现原理。大家有时间也可以学习一下Rayleigh quotient表达式,它是在知道矩阵特征向量的前提下,计算矩阵对应特征值近似解的方法。
源码解析
接下来,我们将从一个开源框架SparklingGraph去学习如何用代码实现中心度的计算。因为我们平时在处理工业界的图数据时,都是上亿的节点和边,所以这也是为什么去选择一个分布式的图计算框架来讲解。
GitHub : https://github.com/sparkling-graph/sparkling-graph
因为该开源框架是基于Spark Graphx去实现的图计算方法,所以其开发语言是100%的Scala。这里建议大家具备一些Spark和Scala的基础知识,不然下面的源码解读比较难以理解。
Spark Graphx的官网: https://spark.apache.org/docs/latest/graphx-programming-guide.html
我们直接解读核心单例对象EigenvectorCentrality中的computeEigenvector方法
/*** Created by Roman Bartusiak (roman.bartusiak@pwr.edu.pl http://riomus.github.io).*/
object EigenvectorCentrality extends VertexMeasure[Double]{/*** Generic Eigenvector Centrality computation method, should be used for extensions, computations are done until @continuePredicate gives true* @param graph - computation graph* @param vertexMeasureConfiguration - configuration of computation* @param continuePredicate - convergence predicate* @param num - numeric for @ED* @tparam VD - vertex data type* @tparam ED - edge data type* @return graph where each vertex is associated with its eigenvector*/
1 def computeEigenvector[VD:ClassTag,ED:ClassTag](graph:Graph[VD,ED],vertexMeasureConfiguration: VertexMeasureConfiguration[VD,ED],continuePredicate:ContinuePredicate=convergenceAndIterationPredicate(1e-6))(implicit num:Numeric[ED])={
2 val numberOfNodes=graph.numVertices
3 val startingValue=1.0/numberOfNodes
4 var computationGraph=graph.mapVertices((_,_)=>startingValue)
5 var iteration=0
6 var oldValue=0d
7 var newValue=0d8 while(continuePredicate(iteration,oldValue,newValue)||iteration==0){
9 val iterationRDD=computationGraph.aggregateMessages[Double](
10 sendMsg = context=>{
11 context.sendToDst(num.toDouble(context.attr)*context.srcAttr)
12 context.sendToSrc(0d)
13 if(vertexMeasureConfiguration.treatAsUndirected){
14 context.sendToSrc(num.toDouble(context.attr)*context.dstAttr)
15 context.sendToDst(0d)
16 }
17 },
18 mergeMsg = (a,b)=>a+b)
19 val normalizationValue=Math.sqrt(iterationRDD.map{case (_,e)=>Math.pow(e,2)}.sum())
20 computationGraph=computationGraph.outerJoinVertices(iterationRDD)((_,_,newValue)=>if(normalizationValue==0) 0 else newValue.getOrElse(0d)/normalizationValue)
21 oldValue=newValue
22 newValue=computationGraph.vertices.map{case (_,e)=>e}.sum()/numberOfNodes
23 iterationRDD.unpersist()
24 iteration+=1
25 }
26 val out=computationGraph
27 out.unpersist(false)
28 out
29 }
需要注意的是第1行代码中computeEigenvector方法中有一个隐式变量(implicit num:Numeric[ED]),这里其实是指GraphX对象中边上的属性是要可计算的,这里相当于是边的权重值。
这个方法的输入主要是GraphX对象,它是由VertexRDD和EdgeRDD组成,由用户自己从数据源读取图数据生成。另外输入的就是封装了算法参数的VertexMeasureConfiguration对象。
第2-3行,表示计算全图的节点,所有节点的初始值为1.0/总节点数。这里相当于幂迭代法中初始化的主特征向量值。
第4行,表示用一个map方法将节点的属性都统一成我们之前的初始化值,且节点只包含这一个属性值,并以此形成后续迭代所用的计算图。
第8行到第24行就是我们之前说的幂迭代法的循环体,它的循环控制是由convergenceAndIterationPredicate这个函数实现的。
/*** Created by Roman Bartusiak (roman.bartusiak@pwr.edu.pl http://riomus.github.io).*/
object EigenvectorUtils {type ContinuePredicate=(Long,Double,Double)=>Booleandef convergenceAndIterationPredicate(delta:Double, maxIter:Long=100)(iteration:Long, oldValue:Double, newValue:Double)={Math.abs(newValue-oldValue)>delta && iteration<maxIter}
}
这个函数是用来控制循环体什么时候停止,当迭代循环的次数大于100时,或者前一次迭代计算的值和当前迭代计算的值的差的绝对值小于一个极小值,那么循环就停止。从上面的代码可以看出这个极小值默认为1e-6.
第9-18行,则是使用Graphx的消息发送算子aggregateMessages,定义了图上每个节点向邻居节点所发送的消息,以及节点收到消息后的合并方法。我们从上面可以看到第11行就代表着将每一条边上的开始(source vertex)节点的值乘以当前边的权重,然后发送到结束节点(target vertex)。每个节点的初始值就是我们在第2-3行代码里定义的初始化的值。第18行就是节点对消息的聚合函数,这里看到就是全部相加。
这段代码本质就是将当前节点的所有邻居节点的中心度值发送过来,并进行聚合相加当做当前节点的中心度值。让我们回顾一下邻接矩阵,A[u,v]=1A[u,v] = 1A[u,v]=1 代表节点uuu和节点vvv之间相连,为0则不相连;所以这个聚合相加操作本质上就等于我们幂迭代法中邻接矩阵和主特征向量的矩阵相乘。这就是整个代码的核心,比较抽象,大家可以多花些时间思考和理解。
第19-20行实际上就是主特征向量的ℓ2\ell_2ℓ2范数计算,也就是归一化。
最终输出的也是一个Graphx对象,其中的VertexRDD由一个二元组(节点ID,节点的特征向量中心度)组成。
以上就是特征向量中心度的算法原理与源码解析,希望对大家有帮助。文章中有写得不正确的地方希望大家帮忙指出并给我留言,谢谢各位读者。
相关文章:
特征向量中心度(eigenvector centrality)算法原理与源码解析
前言 随着图谱应用的普及,图深度学习技术也逐渐被越来越多的数据挖掘团队所青睐。传统机器学习主要是对独立同分布个体的统计学习,而图深度学习则是在此基础上扩展到了非欧式空间的图数据之上,通过借鉴NLP和CV方向的模型思想,衍生…...
Vue3 中组件的使用(上)
目录前言:一、什么是组件二、注册组件1. 全局注册2. 局部注册二、传递数据【父 -> 子】1. 字符串数组的形式2. 对象的形式三、组件事件【子 -> 父】1. 字符串数组式声明自定义事件2. 【子组件】触发组件事件3. 【父组件】监听子组件自定义事件4. 组件事件例子…...
spring-boot、spring-cloud、spring-cloud-alibaba版本对应
一、查询 spring-boot(spring-boot-starter-parent) 版本号 https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-parent 二、查询 spring-cloud(spring-cloud-dependencies) 版本号 https://mvnrepository.com/artifact/org.springframework…...
【沐风老师】3DMAX一键楼梯脚本插件StairGenerator使用教程
3DMAX一键楼梯插件StairGenerator,不需要花费太多的时间,轻松从2D平面图生成3D楼梯模型,生成的楼梯模型细节丰富真实。 【主要功能】 1.简单:轻松实现2D到3D建模。 2.具有最详细三维结构的台阶平面图。 3.楼梯各部件完全参数化…...
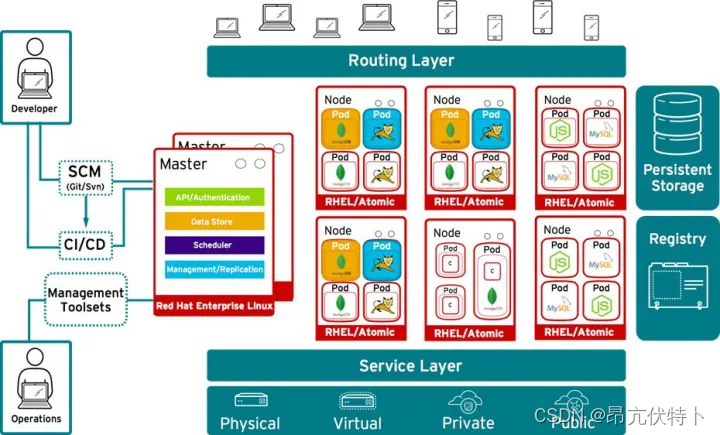
OpenShift 简介
OpenShift 是红帽 Red Hat 公司基于开源的云平台,是平台即服务(PaaS),是一种容器应用平台。允许开发人员构建、测试和部署云应用。该系统是在 K8S 核心之上添加工具,从而实现更快的应用开发、部署及扩展。 在 OpenShi…...

netty自定义封包实现
文章目录说明分享内置编码器和解码器解码器编码器代码实现创建核心类消息实体类自定义编码类自定义解码类服务端ServerHandler入口类客户端ClientHandler入口类测试参考总结说明 netty是java重要的企业级NIO,使用它可以快速实现很多功能通信功能如:http、…...
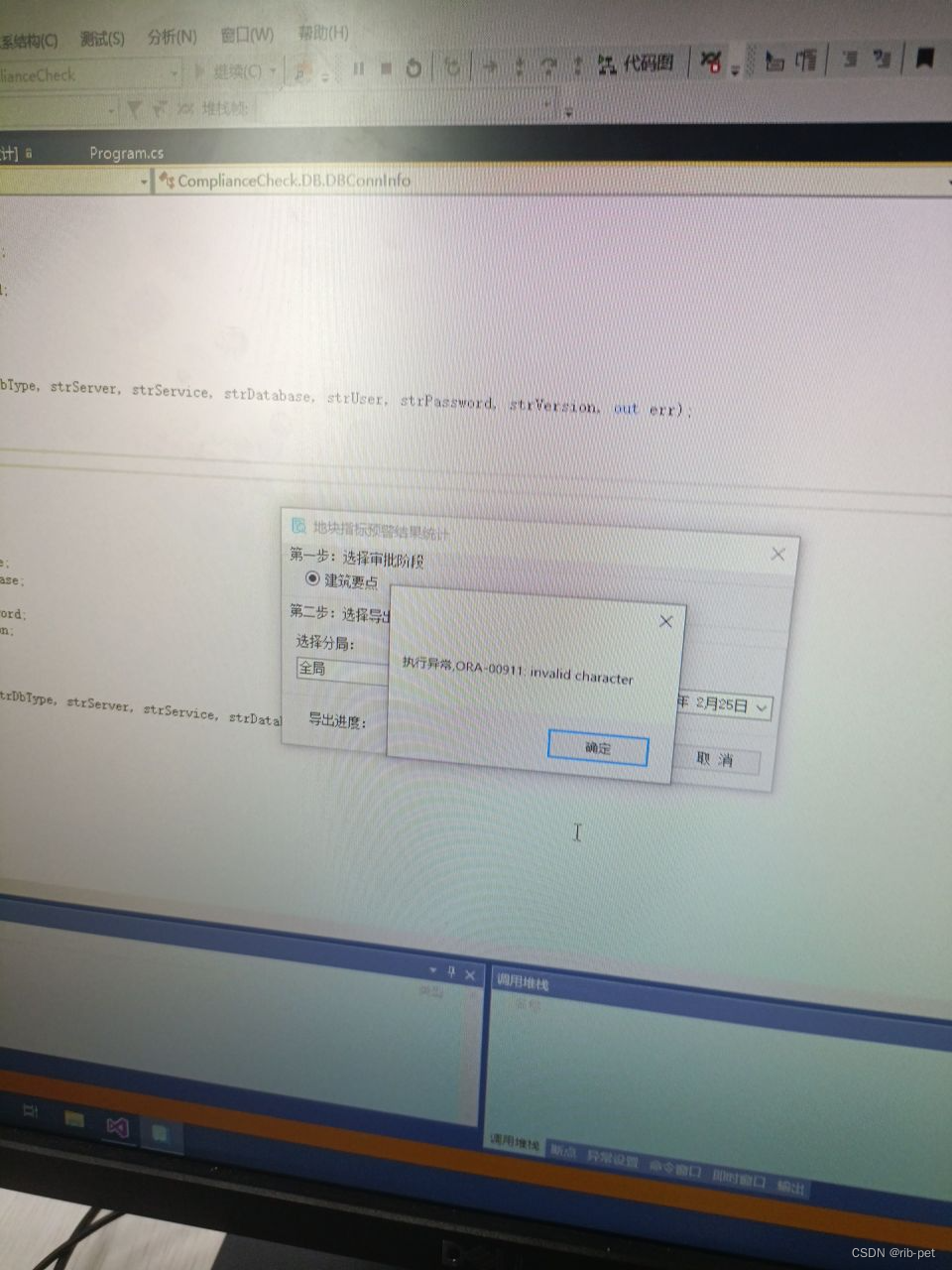
ORA error集锦
1、oralce 数据客户端需要安装的问题 保存信息为: “无法连接到数据库,因为数据库客户端软件无法加载。确保已正确安装并配置数据库客户端软件” 从百度网盘下载,并安装win32 oracle client 安装包 2、ORA错误 “执行异常,ORA-00911: inval…...
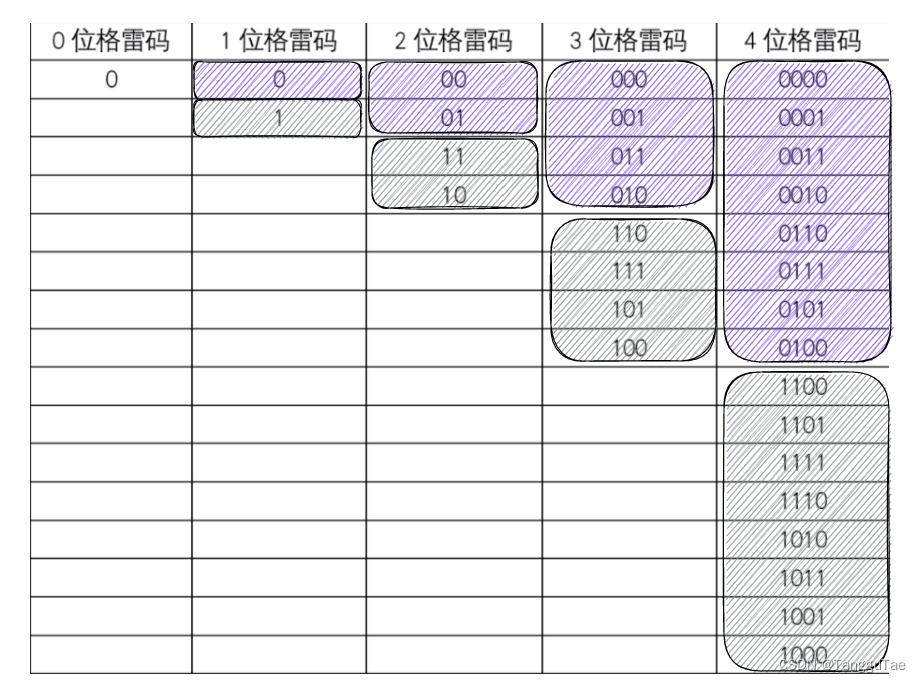
格雷码的实现
格雷码:任意两个相邻的二进制数之间只有一位不同 想必通信专业的学生应该都接触过格雷码,它出现在数电、通信原理等课程里。 如下图所示一个四位格雷码是什么样子的: 格雷码的特点: 其最大的特点是任意上下相邻的两个码值间&am…...
快到金3银4了,准备跳槽的可以看看
前两天跟朋友感慨,今年的铜九铁十、裁员、疫情导致好多人都没拿到offer!现在已经12月了,具体明年的金三银四只剩下两个月。 对于想跳槽的职场人来说,绝对要从现在开始做准备了。这时候,很多高薪技术岗、管理岗的缺口和市场需求也…...

最新BlackArch发布,提供1400款渗透测试工具
近日,BlackArch Linux新版本发布,此版本为白帽子和安全研究人员提供了大约1400款渗透测试工具,如果你是一位白帽子或者安全研究人员,这个消息无疑会让你很感兴趣。BlackArch Linux是一款基于Arch Linux的发行版,主要面…...
重走前端路JS进阶篇:This 指向与箭头函数
JavaScript 高级 This 指向规则 案例 function foo() {console.log(this)}// 1 调用方式1foo();// 2 调用方式2 放入对象中调用var obj {name: "why",foo: foo}obj.foo()// 调用方式三 通过 call/apply 调用foo.call("abc")指向定义 this 是js 给函数的…...

Python基础:函数式编程
一、概述 Python是一门多范式的编程语言,它同时支持过程式、面向对象和函数式的编程范式。因此,在Python中提供了很多符合 函数式编程 风格的特性和工具。 二、lambda表达式(匿名函数) 除了 函数 中介绍的 def语句,P…...
(树链剖分)(线段树))
【YBT2023寒假Day14 C】字符串题(SAM)(树链剖分)(线段树)
字符串题 题目链接:YBT2023寒假Day14 C 题目大意 对于一个字符串 S 定义 F(S) 是 fail 树上除了 0 点其它点的深度和。 G(S) 是 S 每个子串 S’ 的 F(S’) 之和。 然后一个空串,每次在后面加一个字符,要你维护这个串的 G 值。 思路 考虑…...

Tailwind CSS 在Vue中的使用
什么是Tailwind CSS? Tailwind CSS 是一个功能类优先的 CSS 框架,它集成了诸如 flex, pt-4, text-center 和 rotate-90 这样的的类,支持 hover 和 focus 样式,它们能直接在脚本标记语言中组合起来,构建出任何设计。 …...
)
三层楼100人办公网络如何规划设计实施(实战案例)
如何设计组网 1.采用防火墙+三层交换机+二层POE交换机+AP的方案 2.三层交换机作为网络的核心,提供网络的配置、划分和各个VLAN间的数据交换,而每个VLAN由二层交换机组建 3.网络主干设备的选型,建议网络主干设备或核心层设备选择具备第3层交换功能的高性能主干交换机。 4…...
Redis:实现全局唯一ID
Redis:实现全局唯一ID一. 概述二. 实现(1)获取初始时间戳(2)生成全局ID三. 测试为什么可以实现全局唯一?其他唯一ID策略补充:countDownLatch一. 概述 全局ID生成器:是一种在【分布式…...

webpack打包基本原理——实现webpack打包核心功能
webpack打包的基本原理 核心功能就是把我们写的模块化代码转换成浏览器能够识别运行的代码,话不多说我们一起来了解它 首先我们建一个空项目用 npm init -y 创建一个初始化的,在跟目录下创建src文件夹,src下创建index.js,add.js…...
git的使用(终端输入指令) 上
git目录前言1.创建仓库2.创建文件和修改数据状态分区3 .删除、撤销重置 、和比较前言 今天带大家手把手敲一遍 git 流程: 安装一下git(详细观看我之前发的git文档࿰…...

react定义css样式,使用less,css模块化
引入外部 css文件 import ./index.css此时引入的样式是全局样式 使用less 安装 npm i style-loader css-loader sass-loader node-sass -D生成config文件夹 npm run eject配置 以上代码运行完,会在根目录生成config文件夹 进入 config > webpack.config.js 查找…...

基于JavaWeb的学生管理系统
文章目录 项目介绍主要功能截图:登录用户信息管理院系信息管理班级信息管理新增学生课程管理成绩管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系�…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...