【算法训练-排序算法 二】【手撕排序】快速排序、堆排序、归并排序
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【手撕排序系列】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为:目标公司+最近一年+出现频率排序,由高到低的去牛客TOP101去找,只有两个地方都出现过才做这道题(CodeTop本身汇聚了LeetCode的来源),确保刷的题都是高频要面试考的题。手撕排序系列共3道常考题,分别是【快速排序、归并排序、堆排序】这个顺序也是面试出现频度的顺序

明确目标题后,附上题目链接,后期可以依据解题思路反复快速练习,题目按照题干的基本数据结构分类,且每个分类的第一篇必定是对基础数据结构的介绍。
快速排序【MID】
首先来最高频的题目,快速排序
题干

解题思路
使用快速排序的思路来解决,快速排序(Quick Sort)是一种基于分治思想的排序算法,它通过将数组分成较小和较大的两部分,并分别对这两部分进行排序,最终将整个数组排序。快速排序是一种高效的排序算法,通常在平均情况下具有较快的执行速度。

下面是快速排序的基本思想和步骤:
-
[划分]选择基准元素(Pivot): 从数组中选择一个元素作为基准元素。
-
[划分]划分(Partition): 将数组分成两部分,使得基准元素左边的元素都小于等于基准元素,右边的元素都大于基准元素。这一步骤通常称为“划分”。
-
[解决]递归排序: 递归地对基准元素左边和右边的子数组进行排序。也就是说,对小于基准元素的子数组和大于基准元素的子数组分别执行快速排序。
-
[合并] 合并: 由于子数组都是在原数组中进行排序,所以最终整个数组也就被排序了。
这些步骤使得较大问题被分解成较小的子问题,这些子问题又能通过递归地应用快速排序来解决。在最好情况下,每次划分都能将数组均匀分成两半,这使得算法的时间复杂度为O(n log n)。
然而,需要注意的是,快速排序的性能高度依赖于基准元素的选择。最坏情况下,如果每次划分都使数组分成极不平衡的两部分,算法的时间复杂度可能会退化到O(n^2)。为了应对这种情况,通常可以选择合适的基准元素,如随机选择或者采用三数取中等方法。
总之,快速排序是一种常用且高效的排序算法,尤其适用于大规模数据的排序。
代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:快速排序(分治算法)、二分查找
技巧:双指针
import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** @param n int整型 the n* @return int整型*/public int[] sortArray(int[] nums) {return quikSort(nums, 0, nums.length - 1);}// 对数组进行快速排序private int[] quikSort(int[] nums, int start, int end) {int privot;if (start < end) {// 1 获取数组基准值元素位置privot = partition(nums, start, end);// 2 分治:左半边元素快排quikSort(nums, start, privot - 1);// 3 分治:右半边元素快排quikSort(nums, privot + 1, end);}return nums;}// 单次归位基准值方法private int partition(int[] nums, int start, int end) {// 0 随机选择基准数大小,并与最左侧位置交换int randomValueIndex = new Random().nextInt(end - start + 1) + start;swap(nums, start, randomValueIndex);// 1 数组左边第一个为基准值,双指针分别执行开始和结束int privot = nums[start];int i = start;int j = end;// 2 开始交互,直到ij碰面,顺排while (i < j) {// 2-1 从右边开始找,如果值一直大于基准值则一直循环,直到找到小于基准值的元素,终止// 需要注意,满足条件情况下,因为基准值在最左边,最后要与j交换,所以j停止元素一定要小于基准值,所以优先满足j的条件,j要先走while (i < j && nums[j] >= privot) {j--;}// 2-2 从左边开始找,如果值一直小于基准值则一直循环,直到找到大于基准值的元素,终止while (i < j && nums[i] <= privot) {i++;}// 2-3 找到要交换的元素,且依然满足i<j的条件,交换if (i < j) {swap(nums, i, j);}}// 3 i和j碰面,说明该交换的元素已经交换完了,最后交换基准值与碰面的值swap(nums, start, j);// 4 返回基准值的当前位置,需要按此位置分割return j;}// 元素交换方法private void swap(int[] numbers, int i, int j) {int temp = numbers[i];numbers[i] = numbers[j];numbers[j] = temp;}}
需要注意,为了保证平衡性,可以选择随机找个值作为基准值
int randomValueIndex = new Random().nextInt(end - start + 1) + start;
swap(partNums, start, randomValueIndex);
复杂度分析
快速排序的时间复杂度和空间复杂度如下:
时间复杂度:
-
平均情况: 在平均情况下,快速排序的时间复杂度为O(n log n),其中n是待排序数组的长度。这是因为每次划分都能将数组大致均匀地分成两部分,导致递归的深度大约为log n,而每次划分的过程需要O(n)的时间。
-
最坏情况: 在最坏情况下,如果每次划分都导致一个极不平衡的分割(例如每次选取的基准元素都是当前子数组的最大或最小元素),那么快速排序的时间复杂度可能退化到O(n^2)。这是因为需要执行n次划分,每次划分都需要O(n)的时间。为了避免最坏情况,通常采用随机选择基准元素或者三数取中法来减少极端情况的发生。
-
最好情况: 快速排序的最好情况时间复杂度为O(n log n),与平均情况相同。这种情况发生在每次划分都能将数组准确地分成相等的两部分时。
空间复杂度:
快速排序的空间复杂度主要取决于递归调用的深度和每次划分所使用的额外空间。
-
递归调用的深度: 在递归调用中,每次只需要保存一个基准元素的索引和部分数组的边界信息。因此,递归调用的深度为O(log n)。
-
每次划分所使用的额外空间: 每次划分需要O(1)的额外空间来存储基准元素和进行交换。
综合考虑,快速排序的空间复杂度为O(log n)。这是因为虽然递归调用的深度为O(log n),但在每层递归中所需的额外空间是常数级别的。这使得快速排序在空间上比某些其他排序算法(如归并排序)更加节省。
归并排序【MID】
然后再做一道次高频的题目:归并排序,题干与快排一样
题干

解题思路
基本思路:借助额外空间,合并两个有序数组,得到更长的有序数组。归并排序算法主要依赖归并(Merge)操作。归并操作指的是将两个已经排序的序列合并成一个序列的操作
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
接下来实现递归的归并排序
代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:归并排序
技巧:双指针
import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** @param n int整型 the n* @return int整型*/public int[] sortArray(int[] nums) {mergeSort(nums, 0, nums.length - 1);return nums;}// 对数组进行递归的归并排序private void mergeSort(int[] nums, int left, int right) {// 1 与快排不同的是,分割点直接选择中间位置int middle = left + (right - left) / 2;// 2 只要start<end,就一直进行归并if (left < right) {// 2-1 先分别归并左右两边,左右两边有序了,则最终有序mergeSort(nums, left, middle);mergeSort(nums, middle + 1, right);// 2-2 最后合并左右两边有序数组merge(nums, left, middle, right);}}// 单次划分的归并private void merge(int[] nums, int left, int middle, int right) {// 1 设置归并临时结果集,大小为归并后的总长度int[] result = new int[right - left + 1];// 2 定义两个排序数组的指针和结果集指针int i = left;int j = middle + 1;int k = 0;// 3 开始比较已排序集合值并将结果加入结果集while (i <= middle && j <= right) {if (nums[i] < nums[j]) {result[k++] = nums[i++];} else {result[k++] = nums[j++];}}// 4 如果有一个已经用完了,补充另一个排序数组while (i <= middle) {result[k++] = nums[i++];}while (j <= right) {result[k++] = nums[j++];}// 5 需要把这一段合并后已排序结果合并到整体nums的分段上for (int index = 0; index < result.length; index++) {nums[left + index] = result[index];}}}
复杂度分析
时间复杂度:O(NlogN),这里 N 是数组的长度;
空间复杂度:O(N),辅助数组与输入数组规模相当。
堆排序【MID】
最后做一道频度最低的题目:堆排序
题干
题干与快排及归并排序一致

解题思路
这里简单介绍下:数组中下标为 i 的节点的左子节点,就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 2i 的节点
1 建堆
我们首先将数组原地建成一个堆。所谓“原地”就是,不借助另一个数组,就在原数组上操作。建堆的过程是从后往前处理数组,并且每个数据都是从上往下堆化,因为叶子节点往下堆化只能自己跟自己比较,所以我们直接从最后一个非叶子节点开始,依次堆化就行了

2 排序
建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了

代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:堆排序
技巧:双指针
import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** @param n int整型 the n* @return int整型*/public int[] sortArray(int[] nums) {heapSort(nums);return nums;}// 1 堆排序函数private void heapSort(int[] nums) {// 1 构建大顶堆,此时数组0的位置即为堆顶元素,也就是数组最大值int heapSize = nums.length;buildMaxHeap(nums, heapSize);// 2 将堆顶元素与数组末尾元素交换for (int i = nums.length - 1; i >= 1; i--) {// 2-1 交换末尾元素与堆顶元素swap(nums, i, 0);// 2-2 缩小堆的生成范围,不包含末尾元素,因为末尾元素已调整完heapSize--;// 2-3 因为将一个末尾元素放到了堆顶,且其不一定是剩余元素中最大的,所以需要重新进行堆调整heapify(nums, 0, heapSize);}}// 2 构建大顶堆函数private void buildMaxHeap(int[] nums, int heapSize) {for (int i = heapSize / 2; i >= 0; i--) {heapify(nums, i, heapSize);}}// 3 堆调整函数private void heapify(int[] nums, int i, int heapsize) {// 逐层的进行元素调整:这里包含=号是因为要允许存在只有左节点的情况while (2 * i + 1 <= nums.length) {// 1 确定节点的左右节点位置int leftChild = 2 * i;int rightChild = 2 * i + 1;int maxPos = 0;// 2 当前层:进行堆调整,获取(当前、左子节点、右子节点)中值最大的索引,与堆顶进行交换maxPos = i;if (leftChild < heapsize && nums[i] < nums[leftChild] ) {maxPos = leftChild;}if ( rightChild < heapsize && nums[maxPos] < nums[rightChild] ) {maxPos = rightChild;}// 3 如果maxPos不是i,则交换if (i != maxPos) {swap(nums, i, maxPos);// 继续下沉进行堆调整i = maxPos;} else {break;}}}// 4元素交换方法private void swap(int[] numbers, int i, int j) {int temp = numbers[i];numbers[i] = numbers[j];numbers[j] = temp;}
}
复杂度分析
在堆排序算法中,建立堆的时间复杂度通常为O(n),其中n是要排序的元素数量。这是因为堆的构建分为两个阶段:堆的构建和堆的调整。
-
堆的构建:首先,将待排序的n个元素按照从左到右的顺序依次插入堆中,这个过程是线性时间的,即O(n)。
-
堆的调整:然后,需要对堆进行调整以满足堆的性质(通常是最大堆或最小堆)。这个调整阶段的时间复杂度取决于堆的高度,通常为O(log n)。在堆排序的整个过程中,堆的调整阶段需要执行n次,所以总时间复杂度是O(n log n)。
总的来说,堆排序的建堆阶段的时间复杂度是O(n),而排序阶段的时间复杂度是O(n log n)。因此,堆排序的总时间复杂度为O(n + n log n),通常被表示为O(n log n),因为在渐进分析中,线性时间的操作通常被忽略。
由于堆是原地构建,所以空间复杂度为O(N)
拓展知识:分治算法、堆的基本概念、算法比较
1 分治算法
分治法是一种解决问题的算法设计范式,它将一个问题分解成多个相似的子问题,然后解决这些子问题,并将它们的解合并以得出原始问题的解。分治法的核心思想是将大问题分解成更小的、相似的子问题,通过解决子问题来解决原始问题。
分治法通常包含三个步骤:分解(Divide)、解决(Conquer)、合并(Combine)。
-
分解(Divide): 将原始问题划分为更小、相似的子问题。这一步骤通常是递归地进行的,即将问题逐步分解为更小规模的子问题。
-
解决(Conquer): 递归地解决子问题。当子问题足够小,可以直接求解时,就停止分解,转而解决这些子问题。
-
合并(Combine): 将子问题的解合并以得出原始问题的解。这是分治法的关键步骤,将各个子问题的解整合起来形成更大问题的解。
分治法通常用于解决一些可以被分解成相似子问题的问题,如排序、搜索、求解最短路径等。典型的分治算法包括归并排序和快速排序。以下是一个分治法的示例:
归并排序:
-
分解(Divide): 将数组分成两半,分别对这两半进行排序。
-
解决(Conquer): 对分解得到的子数组递归地进行排序,直到子数组长度足够小。
-
合并(Combine): 将排好序的子数组合并,得到完整的有序数组。
分治法的优点在于它可以将问题分解成独立的子问题,每个子问题的求解都相对简单。这使得算法设计和理解变得更加清晰。然而,分治法有时会在子问题的合并阶段引入额外的开销,因此在设计分治算法时需要权衡分解和合并的成本。
堆的基本概念
在计算机科学中,一个"堆"(Heap)通常指的是一种特殊的数据结构,它是一种树状结构,通常用于优先队列和堆排序等算法。
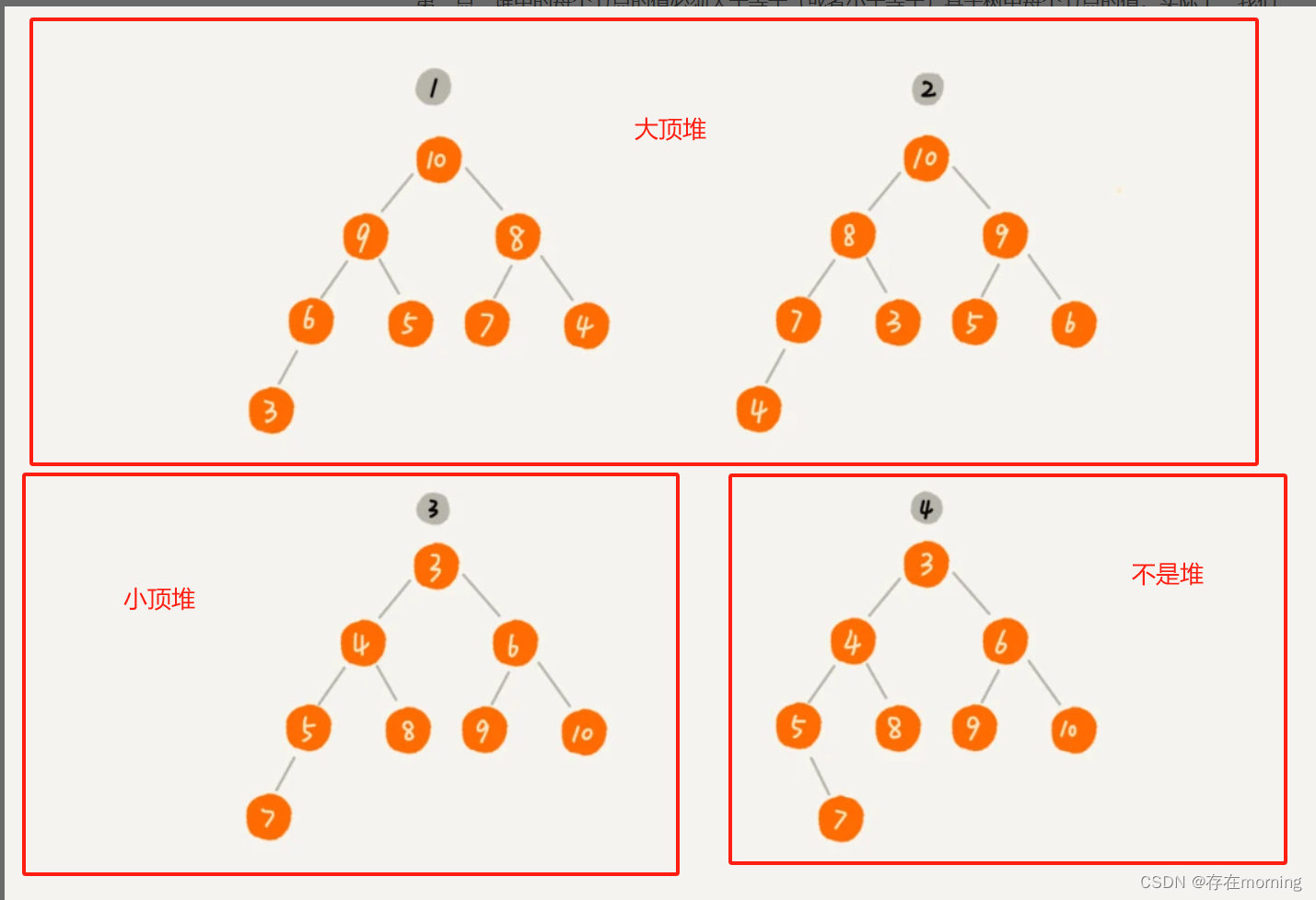
堆具有以下特点:
-
完全二叉树结构:堆通常是一棵完全二叉树,这意味着树的所有层级都被填满,除了最底层,最底层的节点从左向右依次填充。这个特性使得堆可以有效地使用数组来表示,因为树的节点可以在数组中按照特定的规则排列,从而节省内存和提高访问效率。
-
堆序性质:堆被维护为满足"堆序性质"(Heap Property)的树,这意味着在最大堆(Max Heap)中,对于任意节点i,其父节点的值必须大于或等于i的值;而在最小堆(Min Heap)中,父节点的值必须小于或等于i的值。这个性质使得在堆中的根节点永远是最大值(最大堆)或最小值(最小堆)。
堆被广泛用于解决一些基本问题,如:
-
优先队列:通过使用最小堆或最大堆,可以实现高效的优先队列,其中具有最高(或最低)优先级的元素在队列的顶部。
-
堆排序:堆排序是一种基于堆数据结构的排序算法,它利用堆的特性来进行排序。在堆排序中,首先将未排序的元素构建为一个堆,然后反复删除堆顶元素,将其放入已排序部分,直到堆为空。
-
调度算法:堆可以用于操作系统中的进程调度,其中具有最高优先级的进程被安排在最前面。
-
最短路径算法:一些最短路径算法,如Dijkstra算法,使用最小堆来快速查找最小距离的节点。
总之,堆是一种重要的数据结构,它提供了高效的方式来管理数据,特别是在需要按优先级对数据进行操作时。最大堆和最小堆分别用于找到最大值和最小值,这使得堆在许多领域中非常有用。
3 排序算法比较
以下是快速排序、归并排序和堆排序的比较,包括时间复杂度、空间复杂度和一些其他关键特点:
| 特性 | 快速排序 | 归并排序 | 堆排序 |
|---|---|---|---|
| 时间复杂度 | 平均情况 O(n log n) | 平均情况 O(n log n) | 平均情况 O(n log n) |
| 最坏情况 O(n^2) | 最坏情况 O(n log n) | 最坏情况 O(n log n) | |
| 最佳情况 O(n log n) | 最佳情况 O(n log n) | 最佳情况 O(n log n) | |
| 稳定性 | 不稳定 | 稳定 | 不稳定 |
| 空间复杂度 | 平均情况 O(log n) | 平均情况 O(n) | 平均情况 O(1) |
| 最坏情况 O(n) | 最坏情况 O(n) | 最坏情况 O(1) | |
| 适用性 | 通常用于大型数据集 | 通常用于大型数据集 | 通常用于内存受限情况 |
| 且需要稳定排序时 | |||
| 分治策略 | 是 | 是 | 是 |
| 额外的数据移动 | 较多 | 较少 | 较少 |
| 需要的额外空间 | 递归调用的栈空间 | 辅助数组 | 常数额外空间 |
| (in-place) | |||
| 实现复杂度 | 中等 | 中等 | 相对较高 |
总结:
- 快速排序通常在平均情况下具有较好的性能,但在最坏情况下性能较差,因此不适用于某些特定情况。
- 归并排序具有一致的性能,但需要较大的额外内存空间,通常不适用于内存受限的情况。
- 堆排序通常需要较少的额外内存空间,但在排序稳定性和实现复杂性方面有一些局限性,适合内存受限的情况。
选择排序算法应根据具体情况和性能要求来决定,没有一种算法适用于所有情况。
4 稳定性分析
“稳定性"是指排序算法在处理具有相等键值的元素时,能否保持它们在原始序列中的相对顺序。一个排序算法被称为"稳定”,如果对于相等的元素,它们的相对顺序在排序后仍然保持不变。相反,如果排序算法不能保持相等元素的相对顺序,那么它被称为"不稳定"。
下面是对快速排序、归并排序和堆排序的稳定性解释:
-
快速排序:快速排序是一个不稳定的排序算法。在快速排序中,相等元素的相对顺序可能会发生变化,具体取决于选择的划分策略和元素交换操作。
-
归并排序:归并排序是一个稳定的排序算法。在归并排序中,相等元素的相对顺序始终保持不变。这是因为在合并过程中,如果有相等的元素,它们会按照它们在原始数组中的顺序放置在合并后的数组中。
-
堆排序:堆排序通常是一个不稳定的排序算法。虽然堆排序的堆构建过程可能会改变相等元素的相对顺序,但在堆化和排序的过程中,相等元素的相对顺序通常不会被保持。
稳定性在某些应用中很重要,特别是在需要按多个条件进行排序或者需要保持原始数据的某种有序性时。在这些情况下,稳定的排序算法更有用。如果稳定性不是关键因素,那么可以选择性能更高的不稳定排序算法。
相关文章:
【算法训练-排序算法 二】【手撕排序】快速排序、堆排序、归并排序
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【手撕排序系列】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为&…...
C# RestoreFormer 图像修复
效果 项目 代码 using Microsoft.ML.OnnxRuntime; using Microsoft.ML.OnnxRuntime.Tensors; using OpenCvSharp; using System; using System.Collections.Generic; using System.Drawing; using System.Drawing.Imaging; using System.Windows.Forms;namespace 图像修复 {pu…...

yolov5+车辆重识别【附代码】
本篇文章主要是实现的yolov5和reid结合的车辆重识别项目。是在我之前实现的yolov5_reid行人重识别的代码上修改实现的baseline模型。 目录 相关参考资料 数据集说明 环境说明 项目使用说明 vehicle reid训练 yolov5车辆重识别 从视频中获取想要检测的车(待检测车辆) 车…...

C语言练习百题之#ifdef和#ifndef的应用
#if, #ifdef, 和 #ifndef 是C语言预处理指令,它们可以用于条件编译,帮助控制程序的编译过程。以下是各种应用场景以及一些注意事项: 1. 使用 #ifdef 和 #ifndef 检查宏是否定义: 应用场景: 检查宏是否已经在代码中定义…...

与C语言不同的基础语法
一、不同 1.可同时定义并初始化多个变量 2.有string字符串类型 3.可在循环中定义变量 #include<iostream> using namespace std; int main() {int a1,b2;//可同时定义并初始化多个变量string name;//字符串类型 char array[3]; for(int i1;i<3;i)//for中定义i变量…...

Python文件读写实战:处理日常任务的终极工具!
更多资料获取 📚 个人网站:涛哥聊Python Python文件的读写操作时,有很多需要考虑的细节,这包括文件打开方式、读取和写入数据的方法、异常处理等。 在本文中,将深入探讨Python中的文件操作,旨在提供全面的…...

思维模型 秩序
本系列文章 主要是 分享 思维模型,涉及各个领域,重在提升认知。秩序是事物正常运行的基石。有序的安排是成功的先决条件。 1 秩序的应用 1.1 秩序在不同科学领域中的应用 物理学和天文学: 物理学家通过研究原子和分子的有序排列来理解物质的…...

pyqt5移动鼠标时显示鼠标坐标
问题: 只有按住鼠标左键或者右键移动的时候才会获取坐标值,即使对QLabel控件使用setMouseTracking(True)也无法解决。 解决方法: 在初始化构造函数中加入 self.setMouseTracking(True) self.centralwidget.setMouseTracking(True) 并且对…...
分享一下开发回收废品小程序的步骤
随着人们环保意识的不断提高,回收利用已成为日常生活中不可或缺的一部分。回收小程序作为一种便捷、高效的回收方式,越来越受到人们的关注和喜爱。本文将探讨回收小程序的意义和作用,设计理念、功能特点、使用流程以及推广策略,并…...

568A和568B两种线序
现状 现在大家都是采用568B的线序 线序 标准568A:橙白-1,橙-2,绿白-3,蓝-4,蓝白-5,绿-6,棕白-7,棕-8 标准568B:绿白-1,绿-2,橙白-3&#x…...
kafka广播消费组停机后未删除优化
背景 kafka广播消息的时候为了保证groupId不重复,再创建的时间采用前缀时间戳的形式,这样可以保证每次启动的时候是创建的新的,但是 会出现一个问题:就是每次停机或者重启都会新建一个应用实例,关闭应用后并不会删除…...
深度学习自学笔记十三:unet网络详解和环境配置
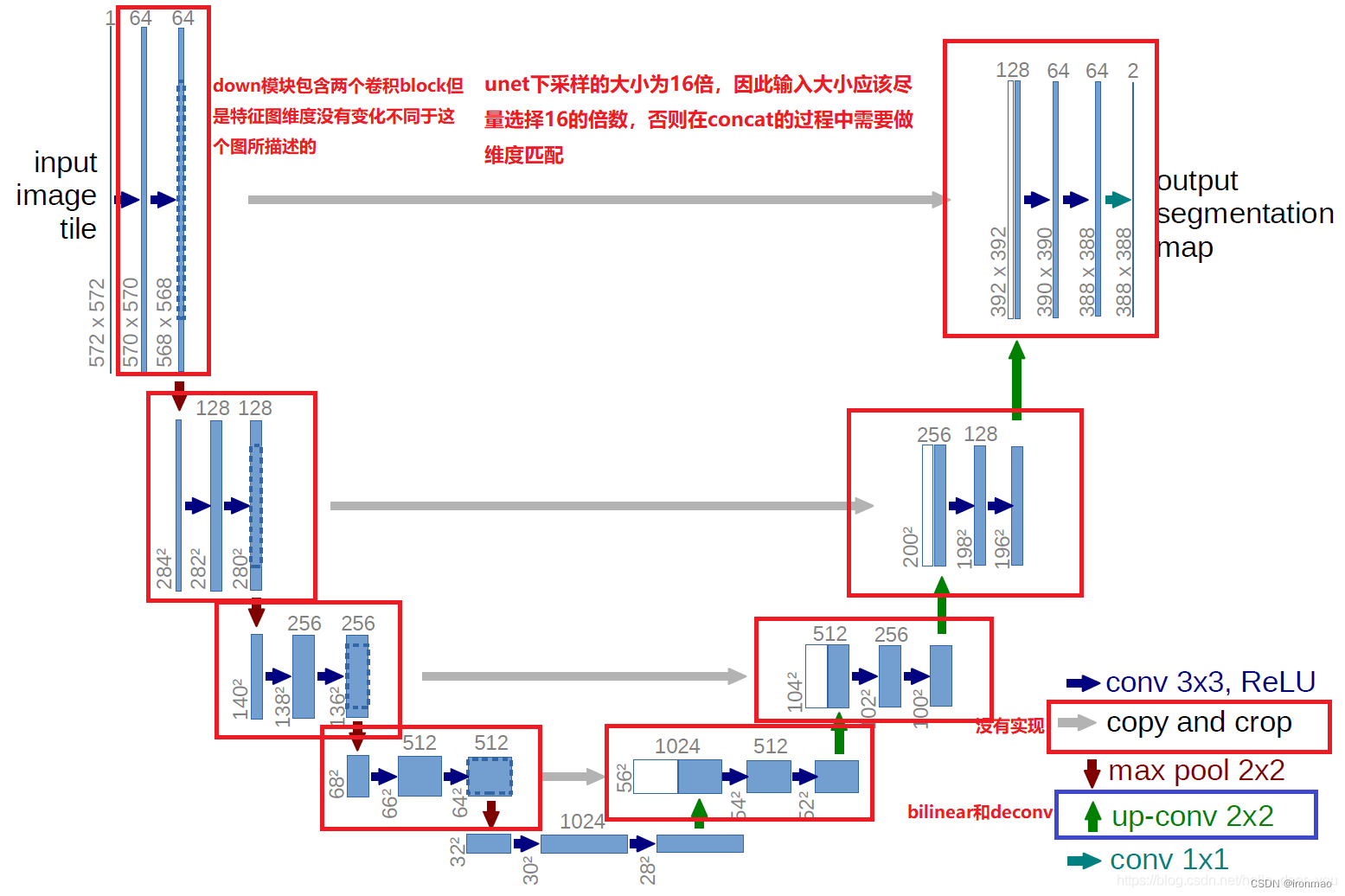
一、unet网络详解 UNet(全名为 U-Net)是一种深度学习架构,最初由Olaf Ronneberger、Philipp Fischer和Thomas Brox于2015年提出,用于图像分割任务。该网络的名称来源于其U形状的架构,该架构使得网络在编码和解码过程中…...
如何给苹果ipa和安卓apk应用APP包体修改手机屏幕上logo图标iocn?
虽然修改应用文件图标是一个简单的事情,但是还是有很多小可爱是不明白的,你要是想要明白的话,那我就让你今天明白明白,我们今天采用的非常规打包方式,常规打包方式科技一下教程铺天盖地,既然小弟我出马&…...

复旦MBA魏文童:构建完备管理知识体系,助力企业数字化发展
日月光华,旦复旦兮!复旦MBA如同一个巨大的磁场,吸引了诸多来自五湖四海、各行各业的职场精英。从初入职场的青涩懵懂到如今的独当一面专业干练,他们逐渐成长为职场的中坚力量,在各自领域内发光发热。作为新时代的青年&…...

【算能】在Docker中调用PCIe卡
开发需求,需要在centos下开发对应的内容 首先拉取docker 镜像 docker pull centos:centos7 然后在空白的centos容器下使用PCIe卡,这个部分特别提醒,需要挂载/dev的这个目录,才能读到内容,故而创建docker的命令 dock…...
【MySQL】表的查询与连接
文章目录 预备工作一、表的基本查询1、简单基本查询2、分组聚合统计3、基本查询练习 二、表的复合查询1、多表查询2、子查询2.1 **单行子查询**2.2 **多行子查询**2.3 **多列子查询**2.4 在from子句中使用子查询 3、合并查询 三、表的连接1、自连接2、内连接3、外连接 预备工作…...
)
AtCoder Beginner Contest 324(F)
AtCoder Beginner Contest 324 F Beautiful Path 需要一点思维的转化,一时竟然没想到。 题意 给定大小为 n n n 的有向图, m m m 条边,每条边有 b i , c i b_i,c_i bi,ci 两个属性,需要找到一条从 1 ∼ n 1\sim n 1∼n…...
-- i2s - 数字音频)
LuatOS-SOC接口文档(air780E)-- i2s - 数字音频
示例 -- 这个库属于底层适配库, 具体用法请查阅示例 -- demo/multimedia -- demo/tts -- demo/record常量 常量 类型 解释 i2s.MODE_I2S number I2S标准,比如ES7149 i2s.MODE_LSB number LSB格式 i2s.MODE_MSB number MSB格式,比如TM8211 …...

瑞芯微RK3568核心板在边缘服务器产品中的应用-迅为电子
迅为RK3568核心板在边缘服务器产品中可以发挥关键作用,为边缘计算应用提供高性能的计算和多媒体处理能力。边缘服务器通常用于处理和存储数据,执行本地计算任务,并支持与远程云服务的通信。以下是RK3568核心板在边缘服务器产品中的应用方案&a…...

pg ash自制版 pg_active_session_history
一、 实现功能 由于pgsentinel插件存在严重的内存占用问题,本篇改为自行实现,但其语句仍可以参考pgsentinel插件。PostgreSQL ash —— pgsentinel插件 学习与踩坑记录_CSDN博客 v1.0 根据pg 14版本设计及测试,仅支持收集主库信息。默认每10秒…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...